NACLIP
动机
CLIP关注全局,不适合语义分割
SCCLIP使用K-K自注意力,可以关注到遥远的物体
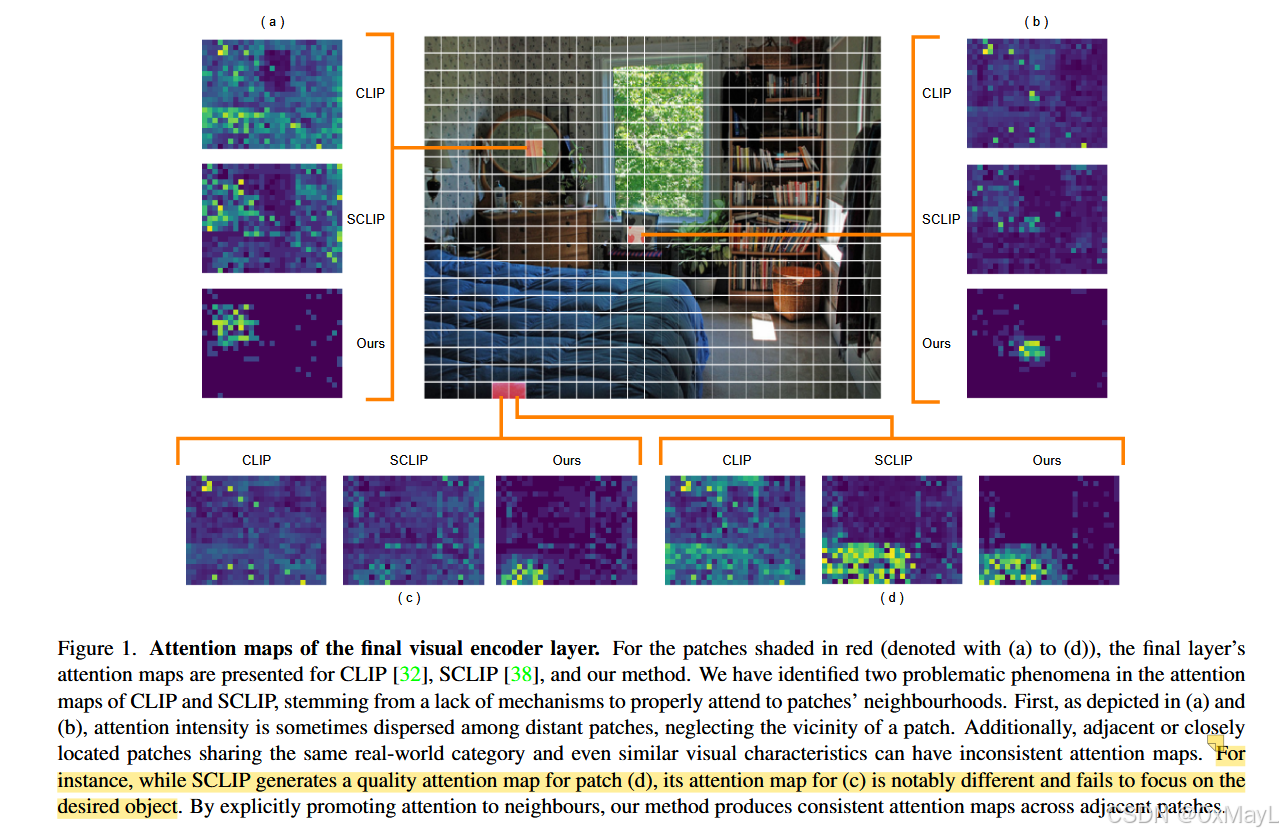
作者发现上述方法竟然无法关注到一个patch本身及其近处的物体 ,这意味着它们缺乏空间一致性 。
方法
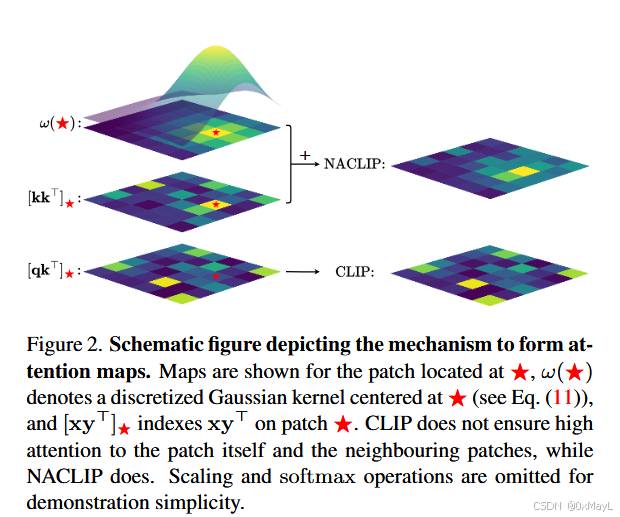
提出了一个高斯核,对于(i,j)的patch,对其注意力分数进行修正,靠近该位置的分数奖励高,远离的分数奖励低 ,与SCCLIP的KK自注意力进行叠加。
然后最后一层也是移除残差连接和FFN

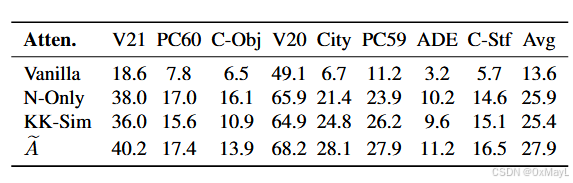
实验发现,即使只有高斯核,完全忽略KK注意力分数,表现也比KK自注意力分数好,这说明CLIP确实缺乏这种能力。
GPT总结
先直接按你给的模板,一项一项来梳理这篇 "Pay Attention to Your Neighbours: Training-Free Open-Vocabulary Semantic Segmentation (NACLIP)" 的方法。
0. 摘要翻译(意译)
传统语义分割依赖固定类别集合,而 CLIP 这类视觉-语言大模型在零样本图像级任务上泛化性很强。现有开放词表语义分割(OVSS)方法,往往需要额外监督预训练或额外预训练网络,比较不现实。本文提出一个 完全训练-free 的 OVSS 强基线------Neighbour-Aware CLIP(NACLIP) ,它是对 CLIP 的一个简单改造。核心做法是:在 CLIP 的视觉 Transformer 中显式强化 patch 的 局部邻域注意 ,从而提升定位能力,这一点在以往 OVSS 工作中被忽视。通过一些有利于分割的设计选择,在 不引入额外数据、额外预训练网络,也几乎不需要调参 的前提下,大幅提高性能。在 8 个主流分割数据集上,NACLIP 在大多数场景都达到了 SOTA,代码开源。
1. 方法动机
1.a 为什么提出这个方法?
作者关注的场景:训练-free OVSS ------
- 不再允许使用额外标注数据(像素级或图像级);
- 不再允许额外预训练模型(例如 MoCo、DeiT、Stable Diffusion);
- 希望只用一个 冻结的 CLIP 就做开放词表分割。
他们观察到:
-
CLIP 的 ViT 更擅长图像级任务而不是密集预测
- 训练时只用到 CLS token 做图像级对比学习,patch token 没有被显式用于优化。
- 自注意力和残差模块的设计偏向"全局语义",而不是"局部空间一致性"。
-
ViT 的局部性和位置信息很弱
- 只在第一层加一次 1D 位置编码,后续层中空间位置信息逐渐被"洗掉";
- 注意力经常把权重打到远处 patch 上,而忽视邻域,导致 定位不稳定、边界乱(Fig.1)。
-
现有"训练-free"方法其实并不那么"free"
- 一部分方法用了额外预训练的 ViT、MoCov2、Diffusion 等模型;
- 一部分方法有很多结构与超参,需要在验证集上调(训练-free 但不"现实")。
因此作者希望:
在完全不训练 、只改动前向过程和结构的前提下,让 CLIP 的 patch 注意力对邻域更敏感,从而提升分割质量。
1.b 现有方法的痛点 / 局限
-
需要额外数据和训练
- 全监督/弱监督 OVSS:需要像素标注或大量 image-text 对,且训练集类别与测试 open-set 高重叠,会有 dataset bias。
-
依赖额外预训练网络
- 使用 MoCov2、DeiT、Stable Diffusion、其他 UOL/生成模型等,实质上"加了另一套大模型+数据",不再纯 CLIP。
-
结构复杂 + 超参多
- 一些训练-free 方法要设计复杂 pipeline、reward 函数、超参搜索,实践中非常麻烦。
-
对"空间一致性"的忽视
-
CLIP 的 patch attention 没有显式机制保证:
- patch 至少要关注"自己"和邻域;
- 相邻 patch 的注意力图应该 相似(同一物体上)。
-
SCLIP 只强调"每个 patch 关注自身",没显式鼓励"关注邻居",导致邻近 patch 的注意力仍可能不一致(Fig.1)。
-
1.c 研究假设 / 直觉(用一句话概括)
只要在 CLIP 的最后一层显式加入"邻域注意 + 语义相似"的约束,就能在不训练的情况下大幅提升 OVSS 分割质量。
更细一点:
-
segmentation 需要的是 局部空间一致的语义,而不是纯 CLS 的全局向量;
-
如果让每个 patch:
- 按 key-key 语义相似度去互相关注;
- 再用一个 空间 Gaussian kernel 强调邻域;
那么 patch 的注意图既"语义相似"又"空间局部",适合做分割。
2. 方法设计
2.a 整体 pipeline(输入→处理→输出,带维度)
Step 1:输入和 patch 表示
-
输入图像:
X∈RH×W×CX \in \mathbb{R}^{H \times W \times C}X∈RH×W×C -
CLIP-ViT 将图像划分成 h×wh \times wh×w 个 patch(每个大小 P×PP \times PP×P):
- h=H/P,w=W/Ph = H / P, \quad w = W / Ph=H/P,w=W/P
-
每个 patch 通过线性投影到 DDD 维嵌入:
Z(0)∈Rh×w×DZ^{(0)} \in \mathbb{R}^{h \times w \times D}Z(0)∈Rh×w×D -
原始 CLIP 会把 patch 展平为长度 N=hwN = hwN=hw 的序列并加上 CLS,但在论文公式里为方便,忽略 CLS,保持 2D 网格形式。
Step 2:标准 CLIP ViT 编码(前 L−1L-1L−1 层不改)
每一层 encoder block ℓ=1,...,L\ell=1,\dots,Lℓ=1,...,L:
- LayerNorm:
Z~=LN(Z(ℓ−1))\tilde{Z} = \text{LN}(Z^{(\ell-1)})Z~=LN(Z(ℓ−1)) - 自注意力 + 残差:
Z′=Z(ℓ−1)+SA(Z~)Z' = Z^{(\ell-1)} + \text{SA}(\tilde{Z})Z′=Z(ℓ−1)+SA(Z~) - LayerNorm:
Z^=LN(Z′)\hat{Z} = \text{LN}(Z')Z^=LN(Z′) - FFN + 残差:
Z(ℓ)=Z′+MLP(Z^)Z^{(\ell)} = Z' + \text{MLP}(\hat{Z})Z(ℓ)=Z′+MLP(Z^)
其中自注意力 SA(单头情形):
-
线性投影得到 q,k,vq,k,vq,k,v:
q,k,v=ZWqkvq,k,v = ZW_{qkv}q,k,v=ZWqkv维度:
- Z∈Rh×w×DZ \in \mathbb{R}^{h \times w \times D}Z∈Rh×w×D
- q,k,v∈Rh×w×dq,k,v \in \mathbb{R}^{h \times w \times d}q,k,v∈Rh×w×d(通常 d=D/headsd = D/\text{heads}d=D/heads)
-
对于位置 (i,j)(i,j)(i,j) 的 patch,计算与所有位置 (m,n)(m,n)(m,n) 的相似度:
sim∗ij,mn=q∗ij⊤kmnd\text{sim}*{ij,mn} = \frac{q*{ij}^\top k_{mn}}{\sqrt{d}}sim∗ij,mn=d q∗ij⊤kmn -
softmax 得到注意力权重,做 value 的加权和:
αij,mn=softmax∗m,n(sim∗ij,mn), Aij=∑m,nαij,mnvmn \alpha_{ij,mn} = \text{softmax}*{m,n}(\text{sim}*{ij,mn}),\ A_{ij} = \sum_{m,n} \alpha_{ij,mn} v_{mn} αij,mn=softmax∗m,n(sim∗ij,mn), Aij=m,n∑αij,mnvmn -
最后线性变换:
SA(Z)∗ij=A∗ijWo\text{SA}(Z)*{ij} = A*{ij} W_oSA(Z)∗ij=A∗ijWo
NACLIP 只在最后一层 LLL 改动 SA 结构;前面 L−1L-1L−1 层完全用原始 CLIP 的参数和结构。
Step 3:文本编码和 patch-文本匹配
-
输入类别文本:自然语言短句 tjt_jtj(例如 "a photo of a dog")。
-
用 CLIP 的 text encoder 得到文本嵌入:
Tj∈RDT_j \in \mathbb{R}^{D}Tj∈RD -
对最后一层的 patch 表示 Zij(L)∈RDZ^{(L)}_{ij}\in\mathbb{R}^{D}Zij(L)∈RD 和所有文本向量做 cosine 相似:
sij(c)=⟨Z(L)∗ij,Tc⟩∣Z(L)∗ij∣∣Tc∣,c=1,...,C s_{ij}^{(c)} = \frac{\langle Z^{(L)}*{ij}, T_c\rangle} {|Z^{(L)}*{ij}||T_c|},\quad c=1,\dots,C sij(c)=∣Z(L)∗ij∣∣Tc∣⟨Z(L)∗ij,Tc⟩,c=1,...,C
-
对每个 patch 做 argmax 得到类别标签:
yij=argmaxcsij(c)y_{ij} = \arg\max_c s_{ij}^{(c)}yij=argcmaxsij(c) -
将 yijy_{ij}yij 扩展/上采样到原图像分辨率得到语义分割 mask。
Step 4:可选 mask refinement
- 使用 PAMR(Pixel-Adaptive Mask Refinement)对 coarse mask 做细化,保留边缘信息,提高 mIoU。
2.b 方法结构内各模块及协同关系
结构变化只发生在:最后一层视觉 encoder block。
-
局部 Gaussian 邻域模块(Spatial Kernel)
-
对于每个 patch 位置 (i,j)(i,j)(i,j),构造一个 2D 高斯核:
- 在 patch 网格坐标空间(1...h, 1...w)上高斯分布;
- 中心在 (i,j)(i,j)(i,j),越远的 patch 权重越小。
-
这给出一个矩阵
ϑ((i,j);ε)∈Rh×w\vartheta((i,j);\varepsilon)\in\mathbb{R}^{h\times w}ϑ((i,j);ε)∈Rh×w -
主要作用:强制注意力在 logits 上"加分"邻居 patch,使注意概率集中在自身和邻域。
-
-
Key-Key 相似度相似性模块(KK-Sim)
在最后一层的自注意力中 不用 q⊤kq^\top kq⊤k,改用 k⊤kk^\top kk⊤k :
sim∗ij,mn=k∗ij⊤kmnd \text{sim}*{ij,mn} = \frac{k*{ij}^\top k_{mn}}{\sqrt{d}} sim∗ij,mn=d k∗ij⊤kmn含义:
- qijq_{ij}qij 表示"这个 patch 想要什么";
- kijk_{ij}kij 表示"这个 patch 是什么";
- 用 kij⊤kmnk_{ij}^\top k_{mn}kij⊤kmn 就是在寻找 语义上相似的 patch(都是"车"的 patch 互相关注)。
-
邻域 + 语义联合注意力(A#)
在 logits 上把两部分加起来:
A\^#*{ij} = \\text{softmax}\\big(;\\frac{k*{ij}\^\\top k_{mn}}{\\sqrt{d}} * \\vartheta((i,j);\\varepsilon)_{mn}\\big);v
- 第一项:语义相似度(key-key);
- 第二项:空间邻域(高斯核);
联合作用:相似且邻近的 patch 得到更高注意力。
-
减少最后一层 FFN 与残差(Reduced Architecture)
对最后一层 LLL,作者直接把 block 改成:
Z(L)=SA~(LN(Z(L−1))) Z^{(L)} = \tilde{\text{SA}}\big(\text{LN}(Z^{(L-1)})\big) Z(L)=SA~(LN(Z(L−1)))
- 去掉:FFN + skip connection;
- 去掉:SA 的残差连接(即不再加 Z(L−1)Z^{(L-1)}Z(L−1))。
理解:
- 最后一层原本是为 CLS 图像级任务 服务的,残差+MLP 会进一步"混"空间信息,不利于 dense prediction;
- 现在最后一层变成一个 "专门为 patch 分割服务的局部注意层",输出直接给 segmentation 用。
-
整体协同
- 前 L−1L-1L−1 层:保持 CLIP 原本的强语义抽象能力;
- 最后一层:不再优化 CLS,而是专门把 patch 表示"洗一遍",引入 局部空间一致性 + 语义聚合;
- 这样在不训练参数的前提下,把 CLIP 从"图像级识别专家"转成更适合"像素级分割"的表示。
2.c 关键公式和通俗解释(带维度)
(1) 高斯核:邻域权重
连续形式:
ω(x;μ,Σ)=exp(−12(x−μ)⊤Σ−1(x−μ)) \omega(x;\mu,\Sigma) = \exp\left(-\frac{1}{2}(x-\mu)^\top\Sigma^{-1}(x-\mu)\right) ω(x;μ,Σ)=exp(−21(x−μ)⊤Σ−1(x−μ))
取各向同性 Σ=ε2I\Sigma = \varepsilon^2 IΣ=ε2I,则:
ω(x;μ,ε)=exp(−∣x−μ∣22ε2) \omega(x;\mu,\varepsilon) = \exp\left(-\frac{|x-\mu|^2}{2\varepsilon^2}\right) ω(x;μ,ε)=exp(−2ε2∣x−μ∣2)
离散到 patch 网格上(m=1...h,,n=1...wm=1\dots h,,n=1\dots wm=1...h,,n=1...w):
ϑ((i,j);ε)mn=ω((m,n);(i,j),ε) \vartheta((i,j);\varepsilon)_{mn} = \omega((m,n);(i,j),\varepsilon) ϑ((i,j);ε)mn=ω((m,n);(i,j),ε)
- ϑ((i,j);ε)∈Rh×w\vartheta((i,j);\varepsilon) \in \mathbb{R}^{h \times w}ϑ((i,j);ε)∈Rh×w
- 中心 (i,j)(i,j)(i,j) 处最大,距离越远指数衰减。
直觉 :这一张图就是"以 (i,j)(i,j)(i,j) 为中心的邻域热图"。
(2) 仅邻域注意:Neighbourhood Only
极端设置,把相似度 logits 全设为 0,只依赖高斯核:
Aij=softmax(ϑ((i,j);ε)),v A_{ij} = \text{softmax}\big(\vartheta((i,j);\varepsilon)\big),v Aij=softmax(ϑ((i,j);ε)),v
- 这里 softmax 后得到的权重只由空间距离决定,与图像内容无关。
- 实验发现:仅此一步,性能就远超原始 CLIP(表3 "N-Only" vs "Vanilla")→ 说明光靠空间局部性就已经解决了 CLIP 的一大痛点。
(3) Key-Key 相似度
标准注意力:
sim∗ij,mn=q∗ij⊤kmnd\text{sim}*{ij,mn} = \frac{q*{ij}^\top k_{mn}}{\sqrt{d}}sim∗ij,mn=d q∗ij⊤kmn
NACLIP 最后一层改为:
sim∗ij,mn=k∗ij⊤kmnd\text{sim}*{ij,mn} = \frac{k*{ij}^\top k_{mn}}{\sqrt{d}}sim∗ij,mn=d k∗ij⊤kmn
- q,k,v∈Rh×w×dq,k,v \in \mathbb{R}^{h\times w \times d}q,k,v∈Rh×w×d
- kij⊤kmnk_{ij}^\top k_{mn}kij⊤kmn 高表示"这两个 patch 本质含义相似"。
(4) 联合注意 A#(完整 self-attention)
KaTeX parse error: Expected group after '^' at position 3: A^̲#*{ij} = \text{...
- logits = "语义相似度 + 空间邻域偏置";
- 输出 patch 表示:
KaTeX parse error: Expected group after '^' at position 19: ...lde{Z}*{ij} = A^̲#*{ij} W_o \in ...
最终 Z(L)=Z~Z^{(L)} = \tilde{Z}Z(L)=Z~(因为最后一层只保留这一块)。
3. 与其他方法对比
3.a 与主流方法的本质区别
-
与 MaskCLIP / CLIP Surgery / GEM / SCLIP 等 training-free 方法相比:
-
都不 fine-tune CLIP 参数;
-
区别在于:
- 多数方法只改"如何读取 patch features(如用 value、多层聚合等)";
- NACLIP 是直接改 最后一层结构 + 注意力形式,显式加入"局部空间一致性"。
-
-
与使用额外模型的 FOSSIL / FreeSeg-Diff / PnP-OVSS 等相比:
- 那些方法引入 Diffusion、MoCo、额外 ViT 等;
- NACLIP 只用单个 CLIP,不引入新权重,结构更干净。
-
与弱/全监督 OVSS(GroupViT、TCL、SideAdapter 等)相比:
- 它们需要大量 image-text 或 pixel labels 做 adaptation;
- NACLIP 完全不训练,无法利用这些额外数据,但在多个 benchmark 上已经接近甚至超过一些"带训练"的方法。
3.b 创新点和贡献
-
显式"邻域注意 + 局部空间一致性"机制
- 高斯核加到 attention logits 上,保证每个 patch 强调自己的邻居;
- 这是 training-free OVSS 里第一篇明确把"邻域"作为 attention 目标的工作。
-
Key-Key 相似度作为注意力信号
- 在最后一层把 qk⊤qk^\topqk⊤ → kk⊤kk^\topkk⊤,强调 patch 的"本质语义相似",而不是"query 想要什么"。
-
删减最后一层结构,使其专注于 dense prediction
- 去掉 FFN 和残差,只保留改造后的自注意力;
- 强调这是"专门为分割输出 patch 表示"的最后一层。
-
在严格 training-free 设置下达到 SOTA
- 在 8 个数据集里 7 个拿到 SOTA(在只用 CLIP 的公平条件下),且对 backbone 选择较为鲁棒。
3.c 更适用的场景与适用范围
-
场景
- 没有额外标注数据,也不方便训练大模型的场景;
- 需要快速部署"开放词表语义分割"能力,只依赖一个 CLIP checkpoint;
- 想要在 inference 端做极小结构修改就获益的工业应用。
-
适用范围
- 任何有 CLIP-ViT backbone 的场景;
- 输入为自然图像的语义分割任务;
- 在不同 patch size/backbone(ViT-B/16, B/32, L/14)下,性能都较稳(表2)。
3.d 方法对比表(优缺点总结)
| 方法 | 需额外数据/模型 | 是否训练 | 结构复杂度 | 空间一致性机制 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
| CLIP baseline | 否 | 否 | 低 | 无 | 实现最简单 | 分割效果很差,注意力不局部 |
| MaskCLIP | 否 | 否 | 中 | 间接(通过 value) | 提取 dense label 简单有效 | 未显式建模邻域,局部不稳定 |
| CLIP Surgery / GEM | 否 | 否 | 中-高 | 有一定改善 | 通过多层聚合/改 attention 提升分割 | 仍未直接强制"关注邻居",对 backbone 敏感 |
| SCLIP | 否 | 否 | 中 | 关注 self,弱邻域 | 大幅提升 localization,训练-free | 邻近 patch attention 仍不稳定,只强调自注意 |
| FOSSIL / FreeSeg-Diff / PnP-OVSS | 是(Diffusion/其他 ViT) | 否或弱训练 | 高 | 有(多模块) | 性能很强,利用额外生成/检索 | 实现重,不能算"纯 CLIP training-free" |
| NACLIP | 否 | 否 | 低-中 | 显式高斯邻域 + KK 相似 | 改动小、无训练、SOTA、backbone 鲁棒 | 只改最后一层,对极端复杂场景可能仍有限制;仍依赖 CLIP 预训练的偏差 |
4. 实验表现与优势
4.a 如何验证方法有效性?(实验设计)
-
任务:完全 training-free OVSS;
-
数据集(共 8 个 benchmark):
- PASCAL VOC 2012 (V21, V20)
- ADE20K-150 (ADE)
- PASCAL Context (PC60, PC59)
- COCO-Stuff (C-Stf)
- COCO-Object (C-Obj)
- Cityscapes (City)
-
设置:
- backbone 默认 CLIP ViT-B/16;
- 图片短边 resize 到 336(City 为 560);
- sliding window 224×224, stride 112;
- 评估指标:mIoU;
- 对比对象:CLIP baseline、MaskCLIP、GroupViT、CLIP Surgery、SCLIP、GEM、CLIP-DIY、ReCo、TCL、FOSSIL、FreeSeg-Diff、PnP-OVSS 等。
-
消融实验:
- 替换 attention:Vanilla vs N-Only vs KK-Sim vs A#(表3);
- 结构减法:Vanilla vs Reduced(表4);
- 不同 backbone:B/16, B/32, L/14(表2)。
4.b 代表性指标与结论
以 带 PAMR 后处理 的公平 training-free 对比为例(下行:NACLIP vs SCLIP):
-
PASCAL VOC 2012 (V21):
- SCLIP:61.761.761.7
- NACLIP:64.164.164.1
-
PASCAL Context (PC59):
- SCLIP:36.136.136.1
- NACLIP:38.438.438.4
-
COCO-Object:
- SCLIP:32.132.132.1
- NACLIP:36.236.236.2
-
Cityscapes:
- SCLIP:34.134.134.1
- NACLIP:38.338.338.3
-
8 个 benchmark 平均(带 post-processing):
- SCLIP:40.140.140.1
- NACLIP:42.542.542.5
结论:
在不引入额外权重 & 不训练的前提下,NACLIP 在大多数数据集上明显优于所有其他"公平" training-free 方法。
4.c 哪些场景/数据集优势最明显?
-
Cityscapes(街景):
- 大量物体具有强空间结构(路、车、人、建筑),邻域一致性非常重要;
- NACLIP 在 Cityscapes 上比 SCLIP 高了 ~4.2 mIoU。
-
COCO-Object / COCO-Stuff:
- 场景复杂、多物体;
- 强调"相邻 patch 语义一致"有助于稳定物体边界和类间分割。
-
可视化(Fig.3):
- 与 CLIP 相比:NACLIP 的 segment map 轮廓更准确,类别更少混淆;
- 与 SCLIP 相比:在 bus/horse 等物体边界上更连贯,不会把旁边的 tree/sky 误分成同一类。
4.d 局限性
-
仍受限于 CLIP 预训练目标
- CLIP 预训练只关心 CLS 的图像级对比;
- 论文尝试利用 CLS token 来帮助 segmentation 的尝试基本失败,说明 CLS 信息很难传到 pixel 级。
-
只在最后一层做局部约束
- 如果中间层也加入邻域约束,可能进一步增强空间一致性,但这在 training-free 场景会改变分布,可能需要 fine-tune。
-
无法利用额外数据
- 与弱/全监督 OVSS 相比,NACLIP 没法吸收新数据中的细粒度类别知识,在复杂长尾类别上性能仍有限。
-
高分辨率 / 大 backbone 仍有性能下降
- 虽然相比 SCLIP 对 ViT-L/14 更鲁棒,但仍有 4% 左右下降。
5. 学习与应用建议
5.a 是否开源?复现的关键步骤
- 论文中给出了 GitHub 链接:
sinahmr/NACLIP(在摘要页)------是开源的。
若你自己实现 / 复现,关键步骤:
-
从官方 CLIP 加载 ViT backbone(例如 ViT-B/16)
-
保证前 L−1L-1L−1 层完全一致,不做任何修改、不训练。
-
在最后一层:
-
替换自注意力计算为:
- 使用 key-key 相似度;
- 在 logits 上加上以 (i,j)(i,j)(i,j) 为中心的 2D 高斯核;
-
去掉 FFN 和所有残差连接,只保留
Z_L = SA_tilde(LN(Z_{L-1}))。
-
-
保持 CLIP text encoder 不变,用相同的 text prompt 模板。
-
实现滑窗推理 + PAMR 后处理。
-
评估 mIoU 时注意数据集的特殊设置(如是否包含 background 类、是否剔除背景 V20/PC59 等)。
5.b 实现细节与超参数注意点
-
高斯核标准差 ε\varepsilonε
- 论文默认设置 ε=5\varepsilon = 5ε=5,对大多数数据集表现良好;
- 这是唯一比较敏感的超参之一,但作者称几乎不需要跨数据集调参。
-
patch grid 坐标系统
- 在 h×wh \times wh×w 网格上计算欧氏距离:
∣(m,n)−(i,j)∣22|(m,n)-(i,j)|_2^2∣(m,n)−(i,j)∣22 - 注意边界 patch 仍然有完整的高斯核,只是靠近边缘的权重一部分落到图外,可以简单截断。
- 在 h×wh \times wh×w 网格上计算欧氏距离:
-
多头注意力实现
- 理论上每个 head 都用同样的高斯核偏置即可;
- key-key 相似度在 head 维度内做(和原 attention 一样)。
-
数值稳定性
- 高斯核加到 logits 上前可以进行适当缩放,避免过大/过小导致 softmax 退化;
- 实现时注意保持与 CLIP 原 attention 相同的 scale(作者使用 1/d1/\sqrt{d}1/d )。
-
后处理
- 使用 PAMR 比 DenseCRF 更轻量,推荐跟论文保持一致;
- 训练-free 设置下,后处理占的比例较大,可以通过 ablation 看你自己的数据集是否需要。
5.c 迁移到其他任务的可能性
-
开放词表实例分割 / panoptic segmentation
- 当前 NACLIP 输出的是语义 mask;
- 你可以把 patch-level logits 看作 "语义特征图",然后加一个简单的聚类 / proposal / mask decoder → 类似于用 CLIP feature 做实例 mask。
-
显著性检测 / weakly-supervised mask 生成
- 只给出前景/背景 prompt,这种强化局部一致性的 attention 能产生更连贯的显著图;
- 可以作为其他任务的 pseudo label 生成器。
-
开放词表目标检测
- 从 patch-level 类别概率图中提取连通区域,做 bounding box;
- 邻域一致性保证 bounding box 边界更稳定。
-
迁移到其他 ViT-based VLM(如 Florence、EVA-CLIP)
- 只要结构是 ViT,自注意力形式相同,就可以照搬"最后一层:KK + 高斯邻域 + Reduced 架构"这一套。
6. 总结 & 速记版 pipeline
6.a 一句话概括核心思想(不超过20字)
在 CLIP 最后一层引入邻域感知注意力以增强分割。
6.b 速记版 pipeline(去掉论文专有名词)
- 把图像切成小块并提取每块的特征向量。
- 用前几层网络照常处理这些特征,不做改动。
- 在最后一层,用"相似特征 + 空间邻近"重新聚合每块的特征,并去掉多余子模块。
- 将每块特征与所有类别文本向量做相似度比较,选出得分最高的类别。
- 把得到的块级类别结果上采样成整图分割,并用简单后处理细化边界。
如果你后面想做进一步的"矩阵维度走读实现"或者"将 NACLIP 融合进你的一阶段框架(比如 ZegCLIP)",我也可以一起帮你把伪代码/源码级别的改动点梳理出来。