欢迎来到我们的 「每周技术加速器」 专栏!
每周五,我们都会围绕一个前沿技术主题,展开一场深度的内部技术分享会。不仅是为了团队内部的碰撞与成长,也希望通过这样的形式,将我们的思考与实践记录、沉淀、分享给更多同行者。
本周,我们探讨的主题是:告别"炼丹",为什么下一代AI的竞争正转向"上下文操作系统"之争?
从提示词工程到上下文工程,从"手工调参"到"系统架构",AI开发正在经历一场静悄悄但深刻的范式迁移。本文将带你深入这场变革的核心逻辑、技术架构与未来图景。
你是否也有这样的挫败感?AI助手能在瞬间写出优美的十四行诗,却在你接个电话的功夫就忘了刚才讨论到哪儿了。它像个天才实习生,但患有严重的短期记忆丧失症------每一次对话都是一次"冷启动",每一次重启都是一次心智清零。
这正是当前大语言模型(LLM)的致命瓶颈:强大的瞬时推理能力,却没有持久的记忆系统。
2025年,一场静悄悄的革命正在发生。顶尖AI团队不再执着于"炼"出更强大的模型,而是在构建一个全新的范式------上下文工程(Context Engineering)。这就像从手工打磨单块CPU,跃迁到设计整个操作系统。而这场跃迁,将决定未来AI应用的真正壁垒。
1
从"提示词工匠"到"系统架构师"
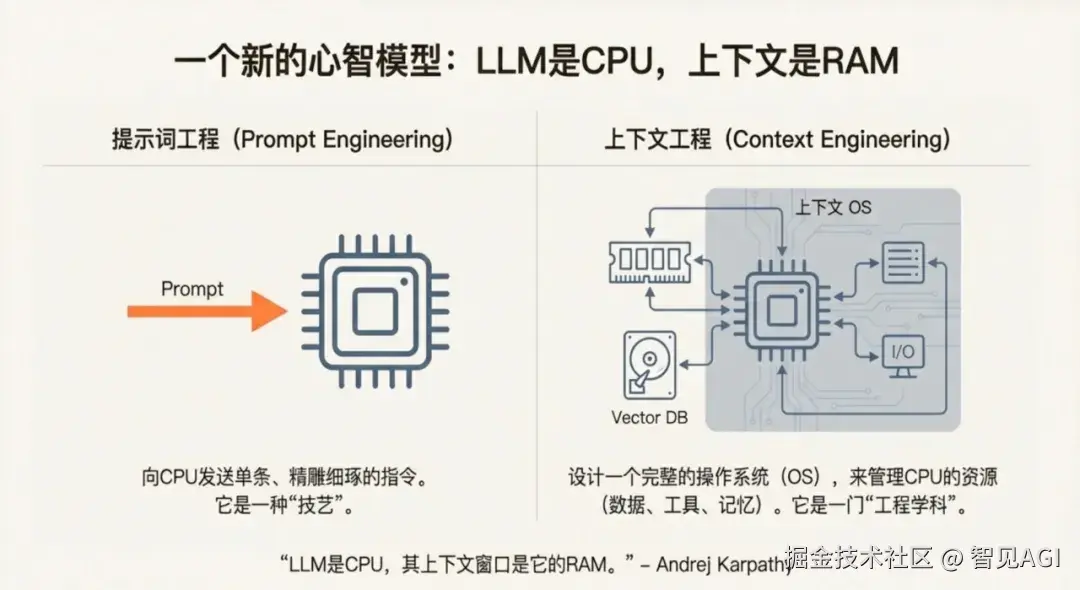
传统的提示词工程(Prompt Engineering)就像给CPU发送一条条精雕细琢的指令。你费尽心思调整每个词、每个标点,期望模型给出完美输出。这是"技艺"时代。在这个阶段,我们像手工艺人一样,执着于提示词的措辞、结构和温度参数。每个应用都需要一位"提示词调教师",用试错法寻找那个"魔法 prompt"。这种 craftsmanship 或许能产出惊艳的Demo,却难以规模化、难以维护、更难以形成系统性的护城河。你调出的完美提示,可能在下个模型版本更新后就失效了;你精心设计的few-shot示例,可能在上下文稍长时就淹没在噪声中。这本质上是在用农耕时代的精巧,应对工业时代的复杂。
但上下文工程完全不同。它将LLM视为CPU,上下文窗口视为RAM,而我们要做的,是为这个CPU设计一个完整的操作系统------管理它的内存、调度它的任务、优化它的缓存、控制它的外部交互。这是一门真正的"工程学科"。在这个新范式里,提示词只是整个系统的一个微小组件。真正的挑战在于:当上下文窗口只有128K的"RAM",而外部知识库是100TB的"硬盘"时,你如何设计虚拟内存系统?当用户请求从简单的问答变为"分析过去一年的销售数据,对比三个竞品,生成报告并发送给团队"时,你如何设计多进程调度?当API调用成本随上下文长度指数增长时,你如何设计缓存策略?当敏感数据需要跨会话记忆时,你如何设计权限隔离?这些问题,才是上下文工程的核心。
上下文工程彻底改变了我们看待LLM的视角。CPU本身并不智能,智能来自于操作系统对CPU的精妙编排------分时复用、内存分页、中断处理、设备驱动。同理,LLM的"智能"也很大程度上取决于上下文操作系统的设计。没有操作系统,CPU只是一块昂贵的硅片;没有上下文工程,LLM只是一个会遗忘的天才。如今,从OpenAI的Projects功能到Anthropic的MCP协议,从LangGraph的图调度到MemGPT的内存虚拟化,整个行业都在为这个新CPU编写操作系统。这个心智模型,正在重塑AI工程的一切实践。
2
上下文OS的四大核心功能
一个真正的AI操作系统,需要解决四个核心挑战。这些挑战不再是调优提示词的技巧,而是构建复杂软件系统的工程问题------每一个都关乎AI应用的可靠性、可扩展性和商业可行性。
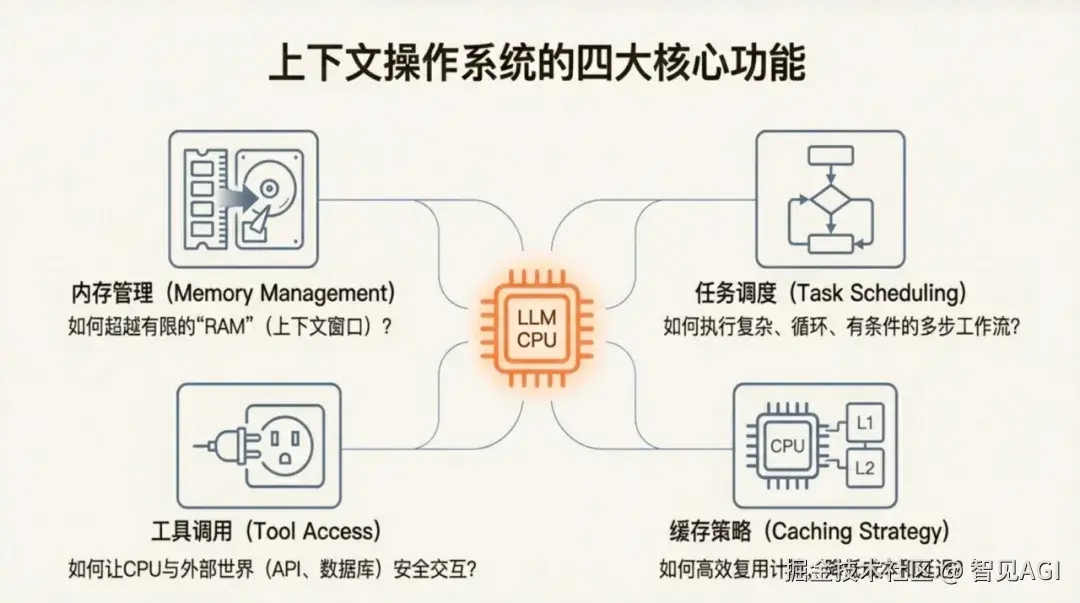
1. 内存管理:如何让AI记住该记的,忘记该忘的?
想象你的电脑只有8GB内存,却要处理100GB的数据。这正是LLM的困境------上下文窗口有限,而外部世界无限。更残酷的是,这8GB"内存"每写一次都要付费,每读一次都要耗时。
RAG(检索增强生成)就是AI的"虚拟内存"系统: 不需要把所有知识塞进RAM,而是在需要时从向量数据库(硬盘)中精准调取(Page-in)。用户提问→系统检索→加载相关片段→生成答案,这个流程本质上就是操作系统的内存分页机制。但真正的上下文工程远不止调用一个向量搜索API------它要设计分页策略(何时检索?)、替换算法(加载哪些片段?)、预取机制(如何预测下一步需要什么?)。
更前沿的是多级记忆系统,它让AI首次拥有了像人脑一样的分层记忆能力:
-
核心内存(L1 Cache):关键信息始终保留在上下文中,如用户身份、项目目标、关键约束。这相当于人类的工作记忆,访问速度最快但容量极小。
-
回忆内存(L2 Cache):可检索的近期对话历史,如前几轮的讨论要点、刚刚确认的需求。这类似于短期记忆,通过快速查询机制访问。
-
归档内存(Disk):外部持久化存储,用于长期记忆,如用户的历史偏好、项目文档库、行业知识图谱。这相当于长期记忆,容量无限但需要显式检索。
这让我们第一次能让AI在对话中真正"记住"用户偏好、项目背景和关键事实,而不是每次都要重新介绍自己。微软Copilot的"企业级RAG"正是这一理念的实践------它不仅检索文档,更记住了你在SharePoint中的权限、在Teams中的对话历史、在Outlook中的会议决策,编织成一张持续存在的上下文网络。
2. 任务调度:如何让AI执行复杂的多步骤工作流?
LLM天然适合"单步决策",但复杂任务需要循环、条件判断和多步协作。这就像CPU需要操作系统的进程调度器。你不可能用一条prompt让AI完成"调研市场→分析竞品→撰写报告→生成PPT→发送给团队"这样的全流程,AI会在中途迷失、重复或陷入死循环。
LangGraph这类框架的出现,正是将LLM从"每一步都要思考"的决策者,转变为在预设控制流中执行特定任务的"工人"。 通过图结构定义任务流程,AI可以可靠地执行调研→分析→生成→校验的完整链路,而不会在中途迷失或重复。这不再是prompt chaining那种脆弱的线性串联,而是有状态、可循环、带条件分支的确定性系统。
例如,在构建客服AI时,LangGraph可以定义:用户投诉→查询订单(工具调用)→判断责任方(条件分支)→执行退款政策(API调用)→生成回复→人类审核(人工介入点)。整个流程中,AI只负责执行特定节点的"微任务",而调度器确保流程按预设逻辑推进。这种设计大幅提升了可靠性,也让调试和监控成为可能------你不再是在调试一个黑箱prompt,而是在监控一个白盒工作流。
3. 工具调用:如何让AI安全地与外部世界交互?
没有输入输出的CPU毫无意义。同理,LLM需要与API、数据库、文件系统安全交互。但问题是,你如何确保AI不会误删生产数据库、不会泄露敏感信息、不会在费用API上发起无限循环调用?
现代上下文OS通过标准化工具接口 和权限治理 ,让AI能够查询数据库、调用API、执行代码,同时确保不会越权或造成破坏。OpenAI的Functions、Anthropic的Tool Use,都在建立这样的"系统调用"规范。但这只是开始------真正的挑战在于设计工具发现机制 (AI如何知道有哪些工具可用?)、参数验证层 (如何确保调用参数合法?)、权限上下文 (如何根据用户身份动态限制工具范围?)、熔断与限流(如何防止工具调用失控?)。
例如,在医疗AI场景中,工具调用系统不仅要让AI能查询电子病历,更要确保它只能访问当前授权患者的数据,不能跨病历查询;在财务AI中,AI可以读取报表但不能执行转账,可以分析风险但不能修改风控规则。这种精细化的治理能力,才是工具调用从Demo走向生产的关键。GitHub Copilot的代码仓库索引正是典范------它让AI能"看懂"整个代码库,但严格遵循文件权限和代码所有权。
4. 缓存策略:如何降低成本和延迟?
当上下文越来越长,成本呈指数级增长。在Llama 4 Scout支持千万级Token的时代,一次完整调用的成本可能高达数百美元。聪明的缓存策略成为生产级应用的胜负手。
对比OpenAI和Anthropic的策略:
-
OpenAI:自动缓存,精确匹配,读缓存50%折扣,适合简单原型。它的缓存像CPU的L1 Cache,完全自动但命中率有限------只有完全相同的请求前缀才能命中。
-
Anthropic:显式控制,前缀匹配,读缓存90%折扣,写缓存加收25%,适合高复用生产环境。它的缓存像Redis,需要开发者显式标记"这是可复用的前缀",但一旦命中,几乎所有Token都享受折扣。
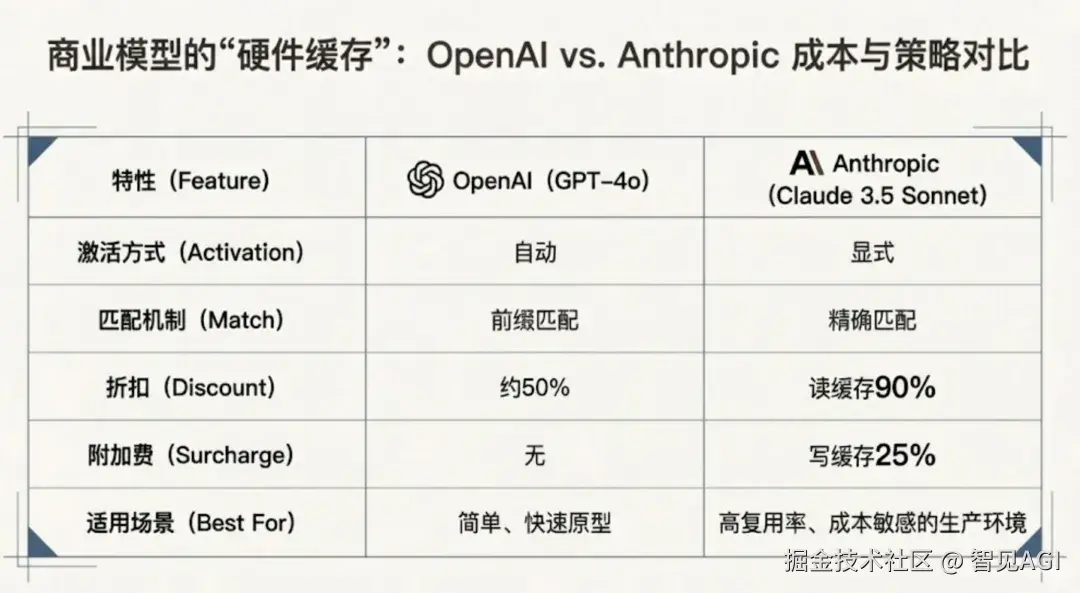
这本质上是硬件级缓存的设计哲学差异------前者省心,后者高效。在千万级Token的Llama 4时代,缓存策略直接决定商业可行性。一个智能的缓存系统会分析请求模式,自动将system prompt、工具定义、知识库片段等稳定内容标记为缓存候选,甚至根据历史访问模式预加载可能被请求的上下文。成本差异是惊人的:在高复用场景下,90%缓存折扣意味着100美元的开销降至10美元,而50%折扣只能降到50美元。对于日调用百万次的应用,这就是生存与死亡的区别。
更前沿的缓存策略甚至包括语义缓存 (相似问题共享缓存)、分层缓存 (根据访问频率自动升降级)、预测性缓存(基于用户行为预加载上下文)。这些技术,正在将上下文OS从"能用"推向"商用"。
3
当上下文太长:性能衰减与系统崩溃
然而,更长的上下文不是万能药。它更像一把双刃剑---当长度超越模型真正的"理解带宽",增长不再是优势,而是诅咒。
斯坦福、伯克利和MIT的多项独立研究揭示了一个反直觉的现象:所有模型在超过特定长度后性能都会衰减,而且衰减模式惊人地一致------先是线性增长的平台期,接着是陡峭的下滑曲线。Llama 3.1在32K后、GPT-4在64K后、Claude 3.5在100K后,表现开始显著下降。这背后的原理与CPU过载如出一辙:当任务集超过缓存容量,缓存命中率急剧下降,TLB miss频发,调度开销吞噬了并行收益。同理,当上下文超过模型的"有效注意力半径",模型开始在信息海洋中迷失,检索关键信号的成本指数级上升。
更微妙的是位置偏差(Positional Bias) ------模型对上下文不同位置的信息处理能力并不均等。早期模型呈现明显的"中间丢失"现象(Mid-Forgotten),最擅长处理开头和结尾的信息;即使是最新模型,对深度埋藏在长上下文中的关键细节,召回率也会下降30%-50%。一位开发者曾用真实案例印证:当他把500页的代码库全部塞进Claude时,AI竟"忽略"了第347页明确标注的"禁止修改此接口"注释,生成了破坏性代码。这揭示了残酷真相:质量比数量重要,设计比规模关键。
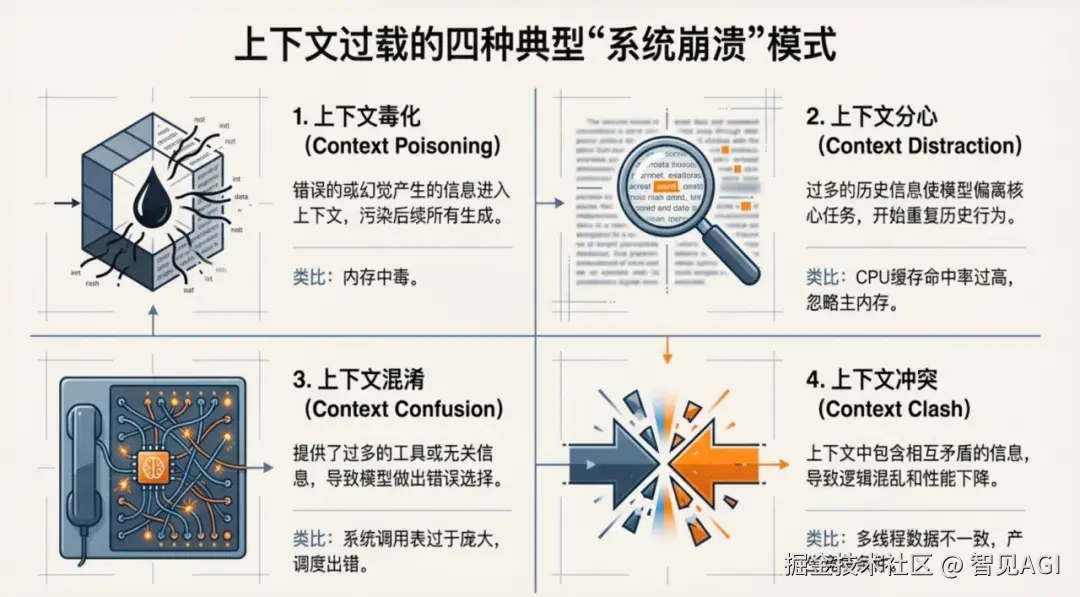
上下文过载会导致四种典型的"系统崩溃"模式,每一种都足以让生产级应用瘫痪:
1. 上下文毒化(Context Poisoning)
错误的或幻觉产生的信息进入内存,污染后续所有生成,如同病毒入侵系统缓存。想象一个客服AI在对话中错误记录了"用户VIP等级=钻石级"(实际为黄金级),这个毒化数据会污染其后的所有交互------从折扣计算到优先服务,整个对话链条建立在错误地基上。更危险的是,毒化具有级联传染性:第一轮的小幻觉,可能在多轮对话中被AI自我强化,最终生成完全脱离事实的答复。传统做法是清空对话重新开始,但这破坏了用户连续性体验。成熟的上下文OS需要内置内存校验机制------对写入核心内存的关键信息进行置信度评分和事实核查,如同ECC内存自动纠错。
2. 上下文分心(Context Distraction)
过多的历史信息使模型偏离核心任务,开始重复历史行为,如同CPU陷入局部性陷阱无法自拔。一个代码生成AI在面对"优化数据库查询"请求时,如果上下文中包含大量过往成功的API调用示例,它可能会机械地复用旧模式,而非针对当前场景设计最优方案。更严重的是行为惯性 :下图中,当用户突然切换话题(从讨论Python转向Rust),AI却因上下文惯性继续输出Python代码,直到用户多次纠正才切换轨道。这就像操作系统的进程没有及时收到中断信号。解决之道在于动态上下文窗口------实时识别话题转移,主动压缩或迁移无关历史,保持工作集的"紧凑性"。
3. 上下文混淆(Tool Confusion)
提供了过多的工具或无关信息,导致模型做出错误选择,如同系统调用表过于庞大导致调度出错。当AI面对"安排会议"的请求,若工具列表中同时包含create_calendar_event、schedule_zoom_meeting、book_conference_room,它可能因参数理解偏差而调用错误工具。某企业曾出现AI因混淆delete_file和archive_file工具,误删了重要文档的事故。这暴露了工具过载悖论:工具越多,选择越难。成熟的上下文OS会引入工具路由层------AI不直接调用工具,而是先输出意图,由路由层根据权限、成本、可靠性选择最优实现。同时,工具描述动态裁剪技术会根据当前任务只暴露相关工具子集,避免认知过载。
4. 上下文冲突(Context Clash)
上下文中包含相互矛盾的信息,导致逻辑混乱和性能下降,如同多线程数据不一致产生竞争条件。当系统prompt要求"遵循品牌A的语调",而检索到的文档却是品牌B的旧指南,AI会在两种风格间摇摆不定。法律文书场景更危险------合同条款与客户邮件承诺存在冲突,AI可能生成既不合规也不符合客户期望的混合方案。这种冲突不仅降低质量,更带来合规风险 。高级上下文OS必须实现冲突检测与消解机制:自动识别矛盾命题,标记置信度,甚至主动发起澄清对话。就像数据库的乐观锁机制,在生成前检查数据一致性,冲突时回滚到安全状态。
这四种崩溃模式往往连锁反应:一次工具调用失败写入错误信息(毒化)→ AI分心重复错误尝试(分心)→ 调用更多工具试图自纠正(混淆)→ 新旧信息冲突(冲突)→ 系统彻底失序。没有操作系统的进程隔离和内存保护,LLM应用在长上下文场景下就是脆弱的裸机程序。
这些问题揭示了残酷的工程真相:质量比数量重要,设计比规模关键。 拥有200K上下文窗口却不设计内存管理机制,就像给8位单片机接上1TB硬盘------容量无法转化为能力。未来的竞争焦点,将从"谁能塞更多Token"转向"谁能设计更智能的上下文架构"。记住,有效上下文(Effective Context) 不等于输入长度,而是模型真正能够定位、理解并正确使用的信息量。这正是上下文工程的核心使命------在有限的注意力带宽下,实现信息的最优配置。
**
**
4
未来图景:从"更长"到"更有效"
上下文工程的未来不在盲目追求更长的窗口,而在智能的设计。首先,RAG与长上下文将深度协同而非相互替代------长窗口扮演"工作台"的角色,容纳多轮对话的中间结果、推理轨迹和思维链条,而RAG则充当"智能图书馆管理员",从海量知识库中筛选高价值片段按需加载。这种分工让前者专注动态过程的承载,后者专注静态知识的精确定位,共同构建起高效的信息供给体系。其次,Agentic Retrieval将重构上下文构建方式,使上下文突破单一文档边界,跨越代码仓库、邮件线程、工单系统、日志流甚至即时通讯记录。以Azure AI Search的Agentic Retrieval为例,系统已能自动规划多步检索策略,通过Reflection & Refine机制让AI像研究员般迭代优化查询,先定位相关数据源,再深入挖掘关联信息,最后交叉验证构建完整的上下文图景。
与此同时,记忆的精细化治理正从可选项变为刚需。未来记忆不再是黑箱般的混沌状态,而是被拆解为可审计、可控制、可遗忘的资产,按对话级、项目级、人格级实现精细隔离。这种分层管理既满足了业务连续性需求,又回应了隐私与安全的严峻挑战------敏感信息必须在指定范围内可见,过期记忆应当自动归档或删除,用户有权要求"被遗忘"。记忆治理的标准化实践,将成为企业AI合规的基石。更进一步的,多模态与跨系统上下文融合将打开全新维度,下一代上下文OS将统一处理文本、图像、音频、视频乃至系统日志和传感器数据流,在数字世界与物理世界的交界处构建起真正的"工作记忆",让AI能理解会议室白板上的草图、工厂车间的设备嗡鸣或客服电话中的情绪波动。
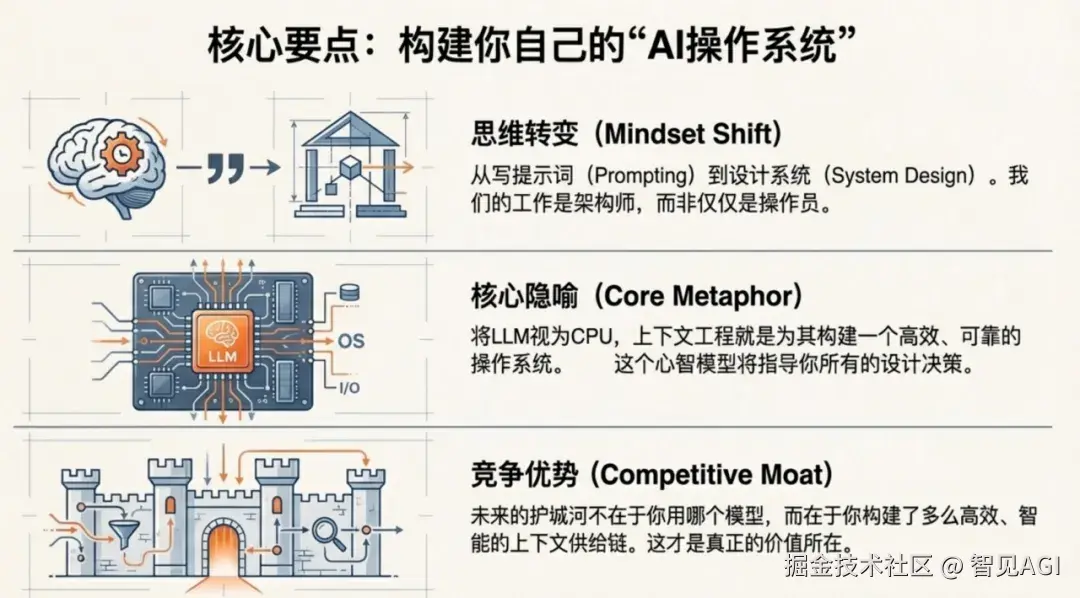
迈向终极形态,自动化与标准化将成为两大支柱。Model Context Protocol(MCP)等新兴标准正试图定义上下文交换的通用语言,让不同Agent能像调用API一样请求和共享上下文,实现跨平台、跨厂商的互操作性;而Auto-Context Engineering则致力于让AI具备自我反思能力,能够自动总结对话要点、识别信息冗余、优化内存布局,甚至动态调整检索策略。在这场变革中,行动指南已然清晰:你必须完成从提示词"操作员"到系统"架构师"的思维跃迁,将"LLM=CPU,上下文=RAM"的核心隐喻融入每一次设计决策。未来的竞争优势不在于选择GPT-5还是Claude 4,而在于你构建了多么智能、高效、可靠的上下文供应链------这才是真正的技术护城河。此刻就应评估应用是否需要多级记忆系统,设计RAG路由策略避免单点检索,实施精细化缓存策略并监控Token成本,同时采用LangGraph等框架构建有状态、可观测的工作流。
我们正站在AI工程的转折点上。当模型"智商"提升的边际效益递减,"上下文OS"的效率革命才刚刚开始。谁能率先构建出下一代操作系统,谁就能占据先机。记住,我们拥有的不是有遗忘症的天才实习生,而是一个亟待被精心设计操作系统的CPU。而你的工作,就是成为那个架构师。