八、微调后模型使用及效果验证
8.1 加载模型(通过 Lora 适配器)
微调任务完成后,我们进入在启动微调时,设定的输出目录:
bash
[INFO|2025-11-23 22:33:07] tokenization_utils_base.py:2421 >> chat template saved in saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03/chat_template.jinja
[INFO|2025-11-23 22:33:07] tokenization_utils_base.py:2590 >> tokenizer config file saved in saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03/tokenizer_config.json
[INFO|2025-11-23 22:33:07] tokenization_utils_base.py:2599 >> Special tokens file saved in saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03/special_tokens_map.json
[WARNING|2025-11-23 22:33:07] logging.py:148 >> No metric eval_accuracy to plot.
[INFO|2025-11-23 22:33:07] trainer.py:4643 >>
***** Running Evaluation *****
[INFO|2025-11-23 22:33:07] trainer.py:4645 >> Num examples = 432
[INFO|2025-11-23 22:33:07] trainer.py:4648 >> Batch size = 1
[INFO|2025-11-23 22:36:31] modelcard.py:456 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
bash
(lf) gpu3090@DESKTOP-8IU6393:~$ ls
'=0.39.0' libriphone sample_best.ckpt
LLaMA-Factory libriphone.zip sample_log.txt
M5-应用集成 llama.cpp saves
Q1 llamaboard_cache snap
Q1.zip llamaboard_config submission.csv
WA_Fn-UseC_-Telco-Customer-Churn.csv merge summaries
anaconda3 model.ckpt test
cookies.txt models tmpg00x95ve.mp3
covid_test.csv outputs train
covid_train.csv pred.csv unsloth_compiled_cache
downloads prediction.csv valid
food11.zip runs "算命大师模型_ipynb"的副本.ipynb
(lf) gpu3090@DESKTOP-8IU6393:~$ cd saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03
(lf) gpu3090@DESKTOP-8IU6393:~/saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03$ ls
README.md checkpoint-300 eval_results.json trainer_log.jsonl
adapter_config.json checkpoint-400 llamaboard_config.yaml trainer_state.json
adapter_model.safetensors checkpoint-500 merges.txt training_args.bin
added_tokens.json checkpoint-600 running_log.txt training_args.yaml
all_results.json checkpoint-700 special_tokens_map.json training_eval_loss.png
chat_template.jinja checkpoint-800 tokenizer.json training_loss.png
checkpoint-100 checkpoint-900 tokenizer_config.json vocab.json
checkpoint-200 checkpoint-918 train_results.json
(lf) gpu3090@DESKTOP-8IU6393:~/saves/Qwen3-4B-Instruct-2507/lora/train_2025-11-23-18-07-03$可以看到输出的所有文件:
包括这几类:
- 模型权重文件
- adapter_model.safetensors:LoRA 适配器的权重文件(核心增量参数)
- checkpoint-100/200/...:不同步数的训练检查点(含模型参数,用于恢复训练)
- 配置文件
- adapter_config.json:LoRA 训练配置(如秩、目标层等)
- tokenizer_config.json / special_tokens_map.json:分词器配置
- training_args.yaml / training_args.bin:训练超参数(学习率、批次等)
- 日志与结果
- trainer_log.jsonl / running_log.txt:训练过程日志
- all_results.json / train_results.json:训练指标(损失、精度等)
- training_loss.png:损失曲线可视化图
- 分词器数据
- merges.txt:BPE 分词合并规则
- tokenizer.json / vocab.json:分词器词表与编码规则
- added_tokens.json:训练中新增的自定义 Token
在 LoRA 微调中,只会训练插入的低秩矩阵(适配器),原模型参数被冻结不变,因此输出目录中仅包含 Lora 适配器,不包含模型原始权重。如果要得到微调后的完整模型,需后续手动合并适配器与原模型。
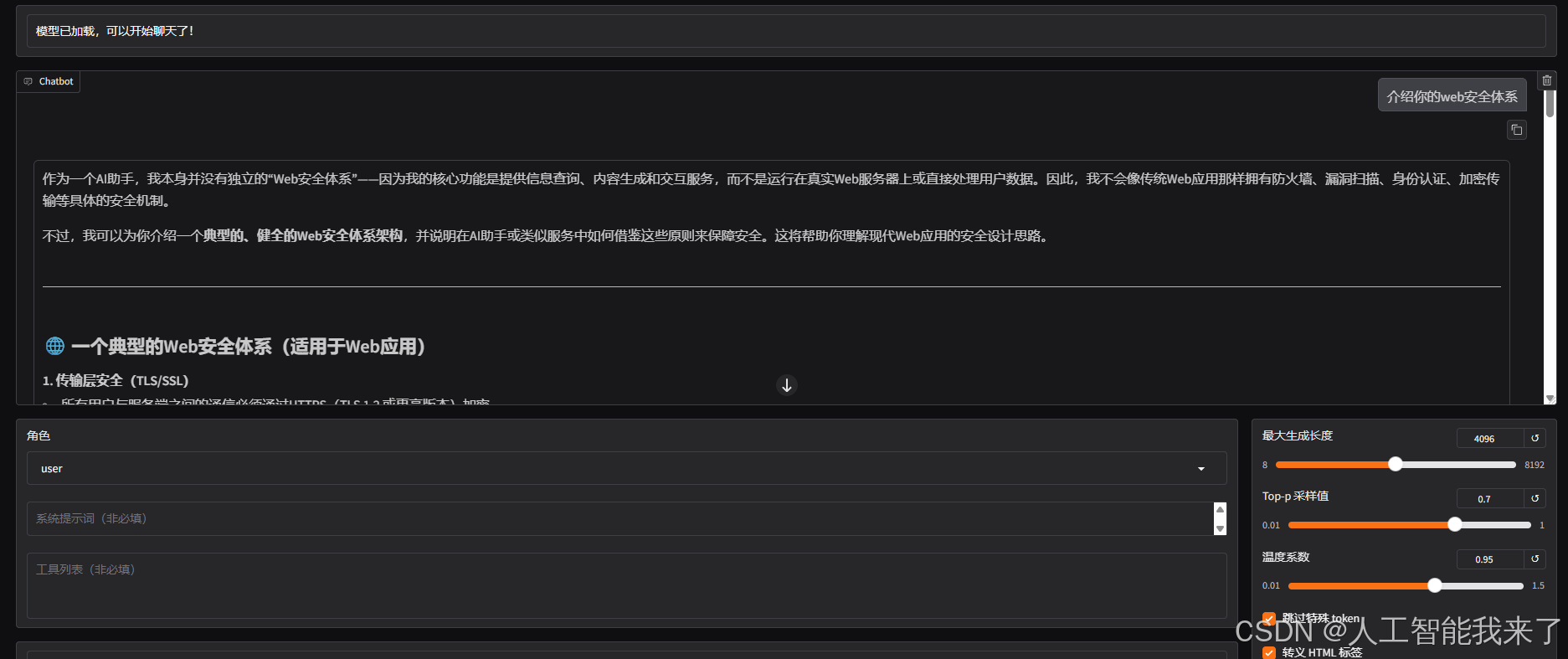
下面,我们可能想快速对微调后的模型效果进行简单的验证,可以在 Webui 中通过检查点路径,加载这个适配器,并且重新加载模型,注意检查点路径填写微调后的输出目录,模型路径还填写微调前基础模型的路径:
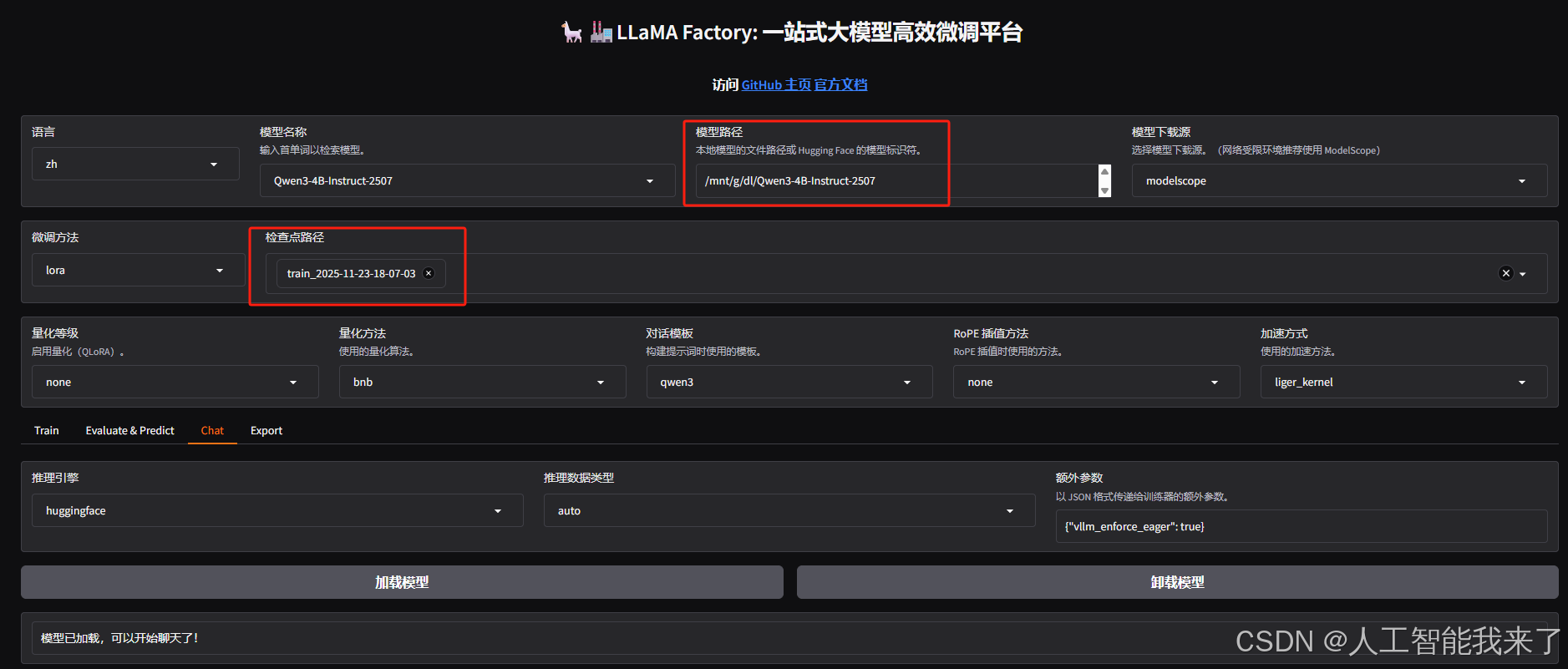
效果验证(注意调一下最大生成长度,默认的 1024 比较小,非常容易截断):
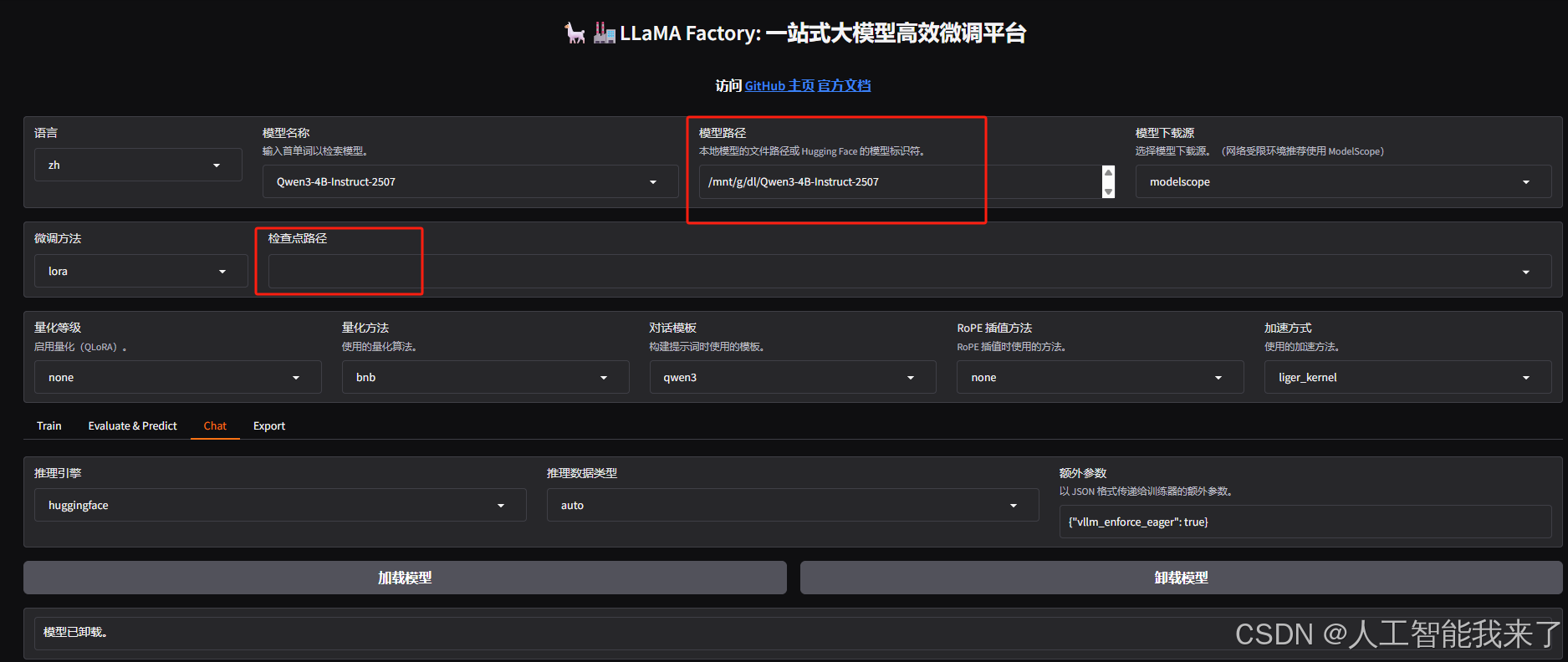
作为对比,可以直接去掉上面的检查点路径,重新加载(先卸载)模型,就可以得到原始模型的回答结果:
8.2 模型合并和导出
以上的使用方式只适用于临时测试,后续使用微调后的模型我们不可能每次都同时加载一个适配器和模型,所以为了后续方便使用,我们需要将原始模型和 Lora 适配器进行合并,然后导出。
我们重新把微调输出目录填入检查点路径,然后重新加载模型,并设定一个导出目录(这里可以设定模型输出后的量化等级、以及一键上传 Hugging Face 等等,大家可以选择设置):
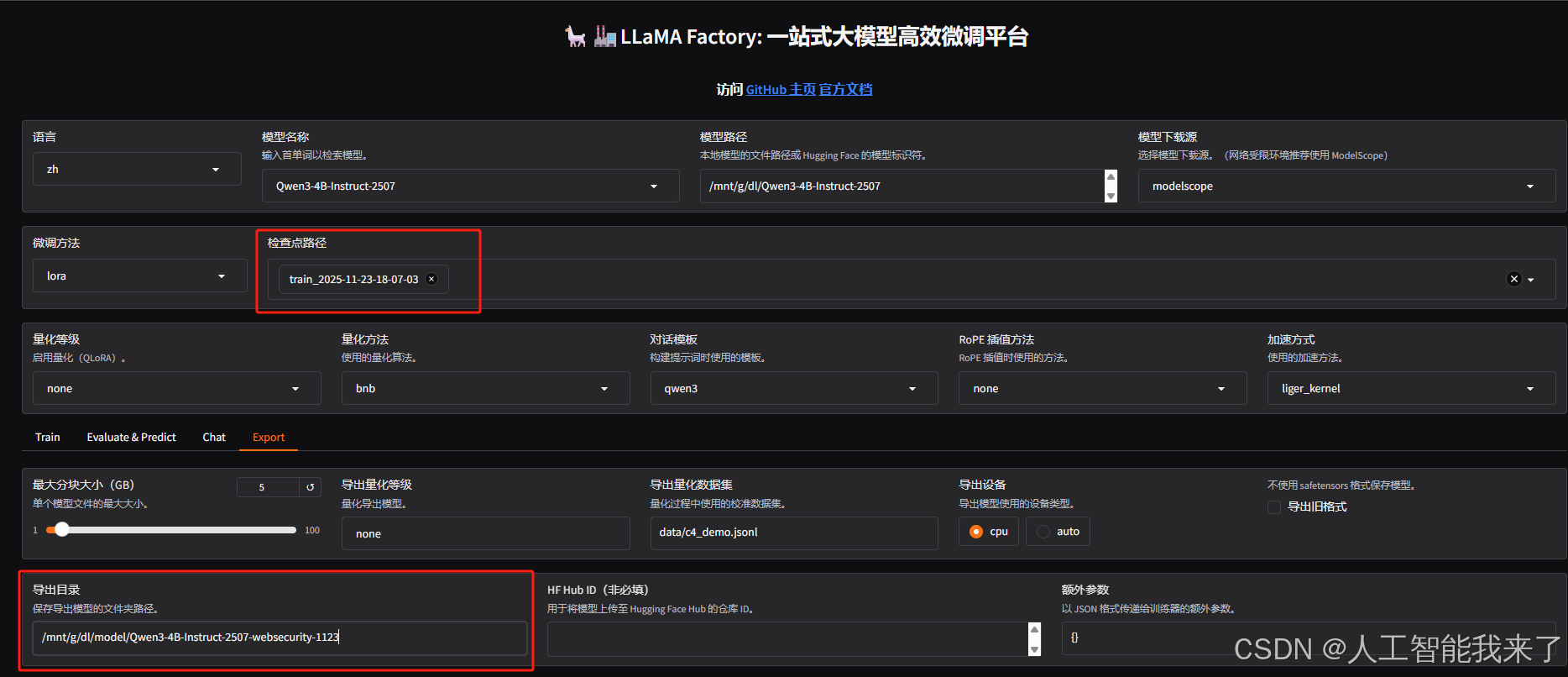
导出成功后,我们进入导出目录,可以看到合并后的模型文件:
bash
(lf) gpu3090@DESKTOP-8IU6393:~$ cd /mnt/g/dl/model/Qwen3-4B-Instruct-2507-websecurity-1123
(lf) gpu3090@DESKTOP-8IU6393:/mnt/g/dl/model/Qwen3-4B-Instruct-2507-websecurity-1123$ ls
Modelfile generation_config.json model.safetensors.index.json vocab.json
added_tokens.json merges.txt special_tokens_map.json
chat_template.jinja model-00001-of-00002.safetensors tokenizer.json
config.json model-00002-of-00002.safetensors tokenizer_config.json
(lf) gpu3090@DESKTOP-8IU6393:/mnt/g/dl/model/Qwen3-4B-Instruct-2507-websecurity-1123$然后我们清空检查点路径,将合并后的模型目录填入模型路径,重新加载模型。
重新测试,可以得到和之前一样的效果。