索引(BTree索引)的正确使用,可以大大提升SQL查询的效率。但是索引并不是添加后,每次查询都会生效,下面演示一些场景下索引的使用。
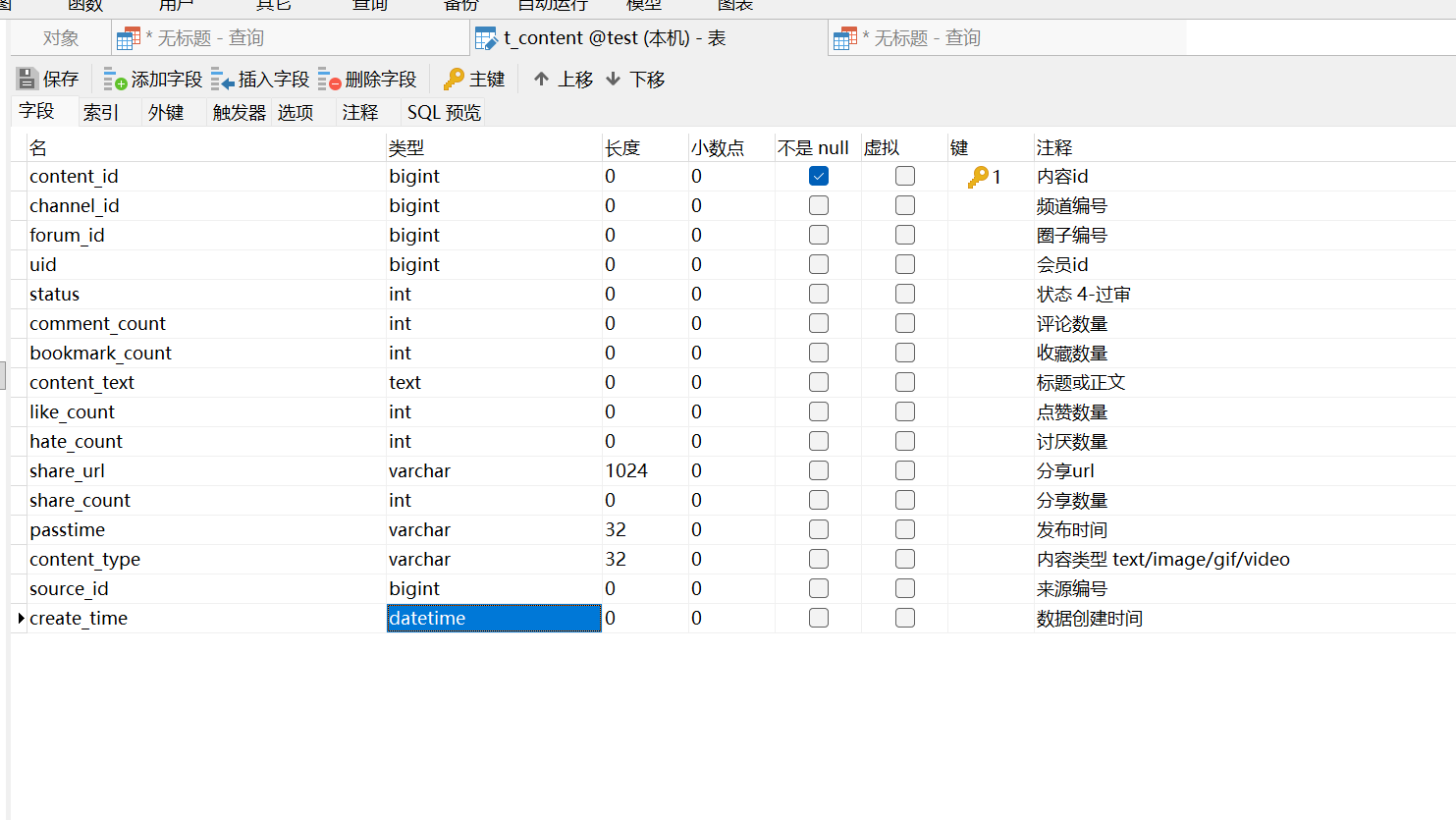
现有一张测试表,字段信息如下,下面的案例都是基于这张表的数据进行演示:
如何查看是否使用索引
使用explain关键字,可以查看当前SQL是否使用索引。
#explain是解释计划,说明SQL的执行情况
explain select * from t_content where content_id = 17076710;
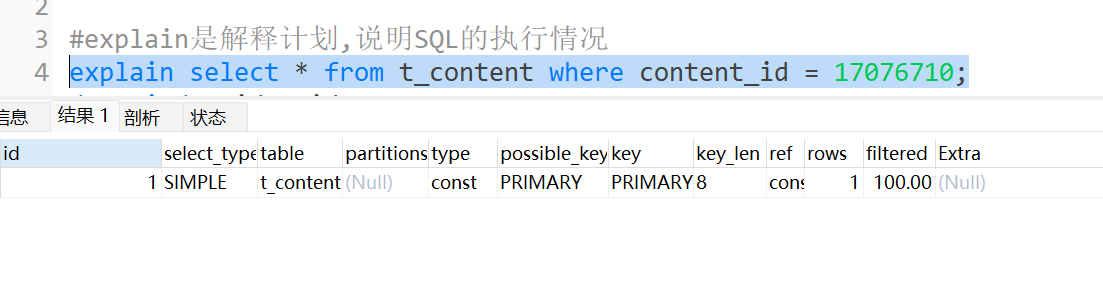
可以看到上面的结果中,key字段值为PRIMARY,是用到了主键索引。
当type值为ALL时,表示全表扫描,没有使用任何索引。
新增索引

create index idx_uid on t_content(uid);
idx_uid是索引的名称,一般索引用idx_开头,这样看名字就知道是索引。
t_content是表名称,uid是字段名称。
上面的语句表示在t_content表的uid字段上添加索引,索引的名称为idx_uid。
删除索引
drop index idx_uid on t_content;
idx_uid是索引的名称
t_content是表名称
上面的语句表示删除t_content上面的名称为idx_uid的索引。
下面的文章介绍了如何使用工具,找出冗余索引:
https://blog.csdn.net/liangmengbk/article/details/155753591
索引使用情况统计
#索引使用情况
SELECT
object_type,object_schema,object_name,index_name,
count_read,count_fetch, count_insert,
count_update,count_delete
FROM
performance_schema.table_io_waits_summary_by_index_usage
ORDER BY
sum_timer_wait desc;
上面的SQL可以快速查询出数据库用到的索引情况,查询结果如下:
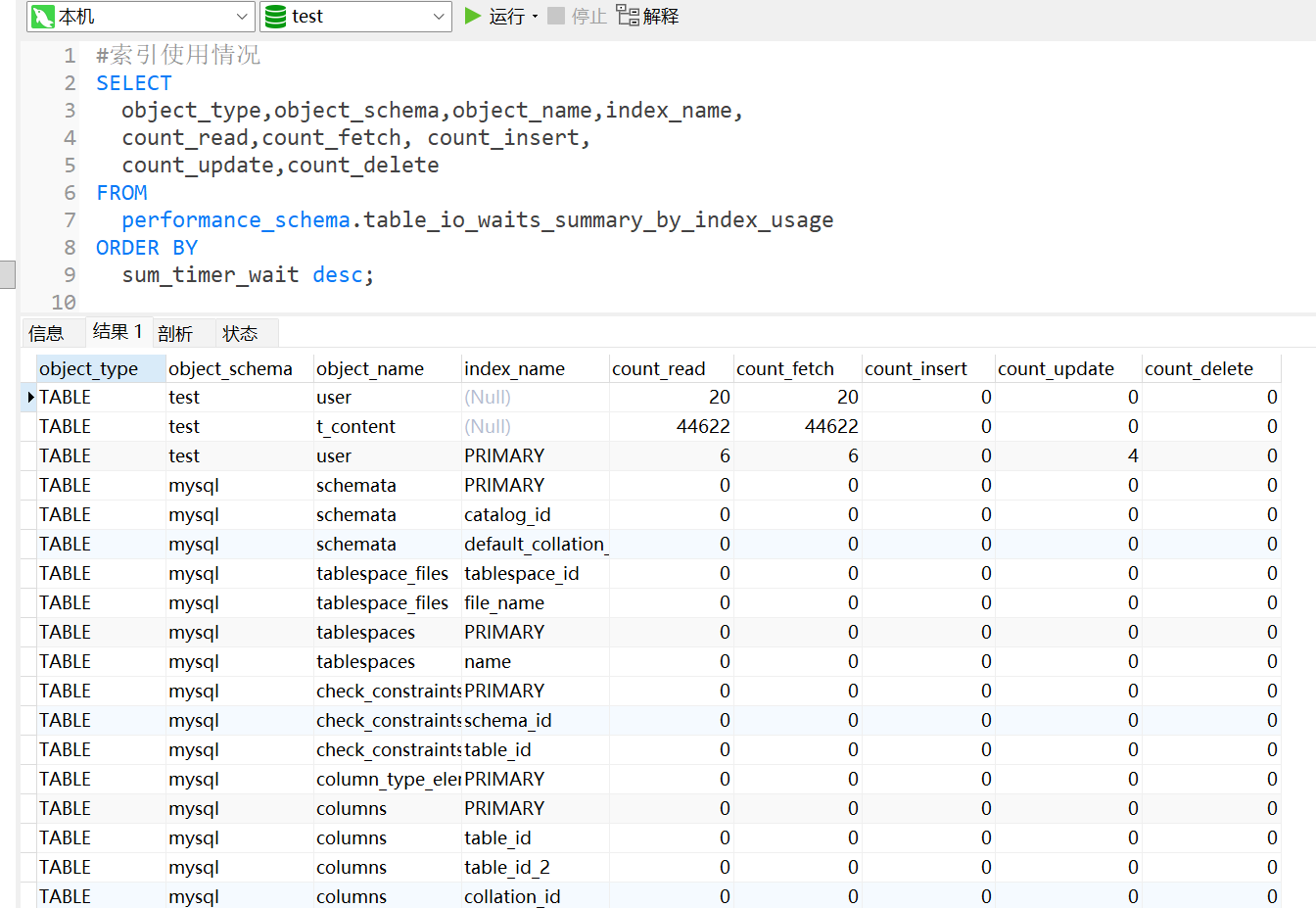
object_type:数据库对象类型,table指数据表
object_schema:数据库名称
object_name:表名称
index_name:索引名称
count_read:索引在执行过程中,读取了多少行
count_fetch:查询结果的总行数
count_insert:通过索引新增的行数
count_update:通过索引修改的行数
count_delete:通过索引删除的行数
查询结果中,后面的几个数字字段,如果都是0,则说明索引没有被使用过(冗余索引),可以考虑删除该索引。
当index_name为null时,说明之前执行的SQL中,有SQL没有使用到索引,进行了全表扫描。也就是说对于index_name为null的记录越少,说明性能越好,因为用到了索引。
减少表与索引的碎片
索引重新统计
用于对MySQL底层,数据状况进行重新统计,让查询解释器在选择时,执行最优的方案。
analyze table 表名;
例如: analyze table t_content;
optimize优化表空间,释放表空间
对表数据进行重新排列,让表以最优的形式进行排列和存储。
该操作会锁表,一定要在维护期间,否则会造成IO阻塞。
optimize table 表名;
例如: analyze table t_content;
索引有效的场景
下面的使用方式,索引会起到作用,加快查询效率。
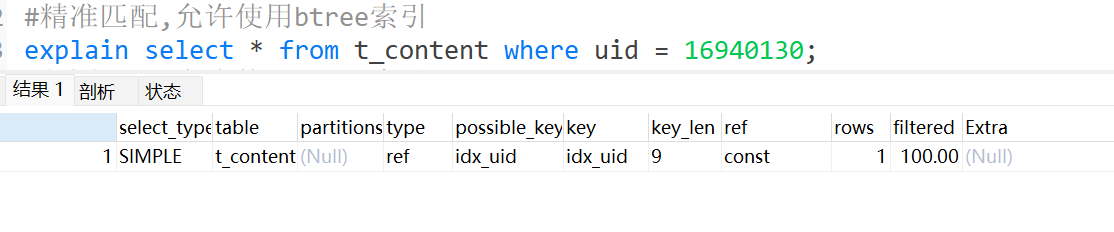
精准匹配
范围匹配

类型转换
 这种情况,虽然执行计划显示用到了索引,但是不推荐这样写法,因为uid是bigint类型,转成字符串,本身就会消耗资源,降低查询速度。最好的做法就是查询条件与定义相符的类型。
这种情况,虽然执行计划显示用到了索引,但是不推荐这样写法,因为uid是bigint类型,转成字符串,本身就会消耗资源,降低查询速度。最好的做法就是查询条件与定义相符的类型。
前缀查询

当使用like做模糊检索时,如果模糊检索的字符串,前面没有%,后面使用了%,这种情况也是可以用到索引。
IS NULL
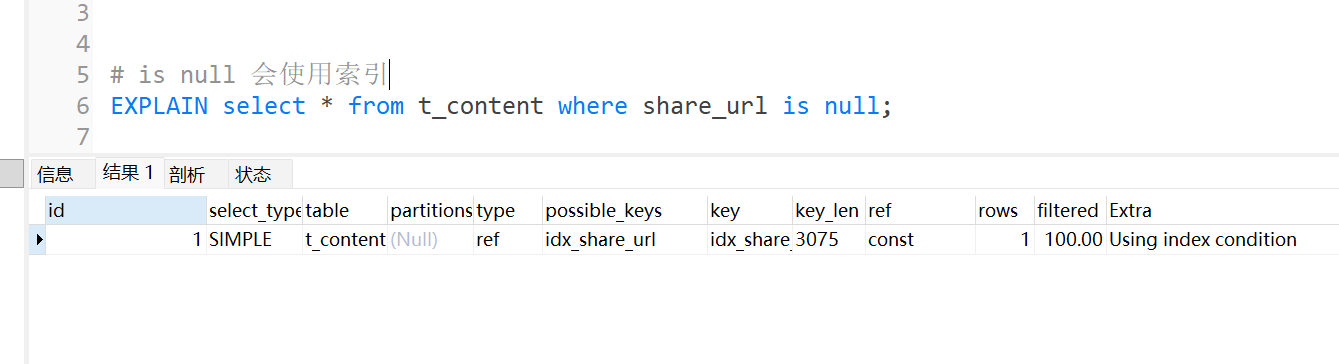
当字段上创建了索引,使用is null,索引会起作用。
复合索引查询条件包含左侧列
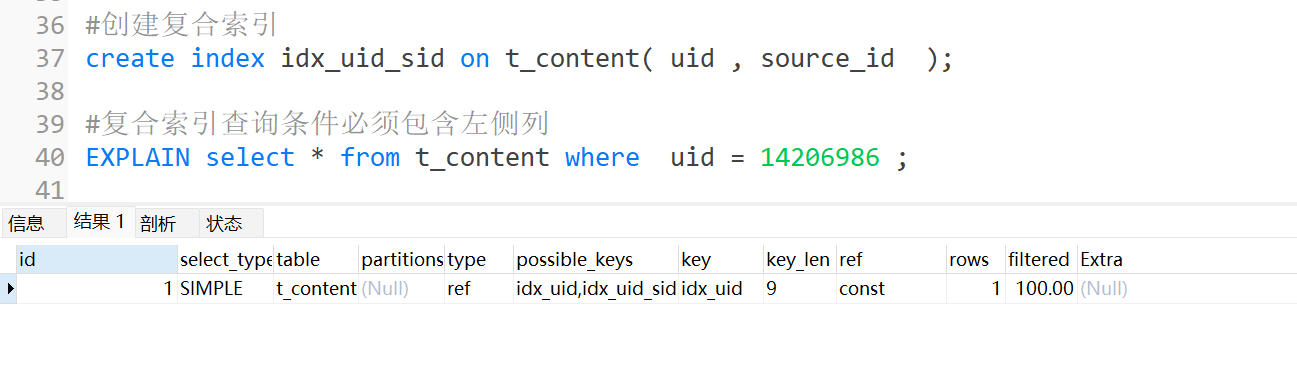
上面的查询中,用到了复合索引(多个字段组合形成一个索引),复合索引的字段顺序很重要,在上面的例子中,uid是第复合索引中的第一个字段(左侧列),在查询语句中,uid被放在了查询条件里面,此时索引生效。
复合索引排序只有索引的左侧列
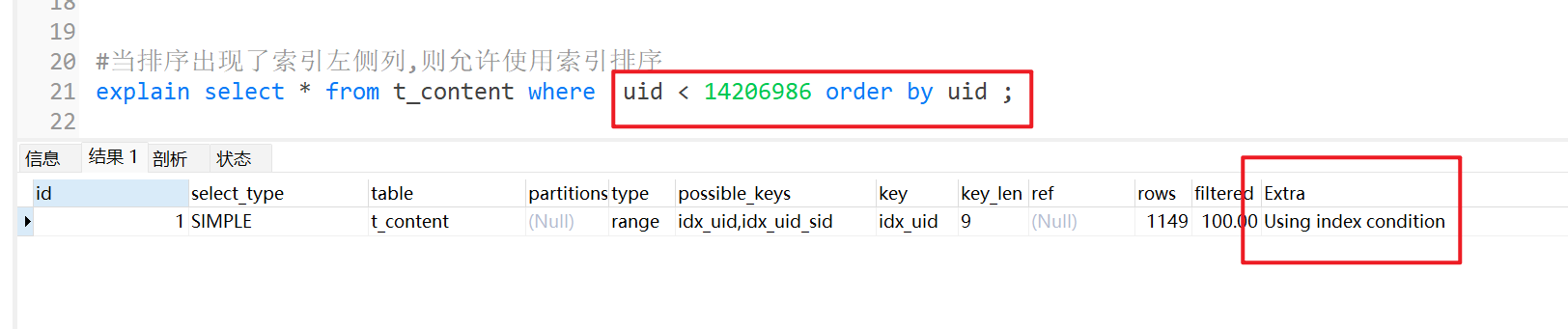
当使用复合索引的左侧列字段,进行order by排序时,也会用到索引,排序效率较高(同时支持正序和倒序)。
复合索引排序与索引字段顺序一致

order by排序的字段,与索引字段的顺序一致,uid在前,source_id在后,该方式会使用索引排序,效率高。
复合索引查询条件同时包含索引列
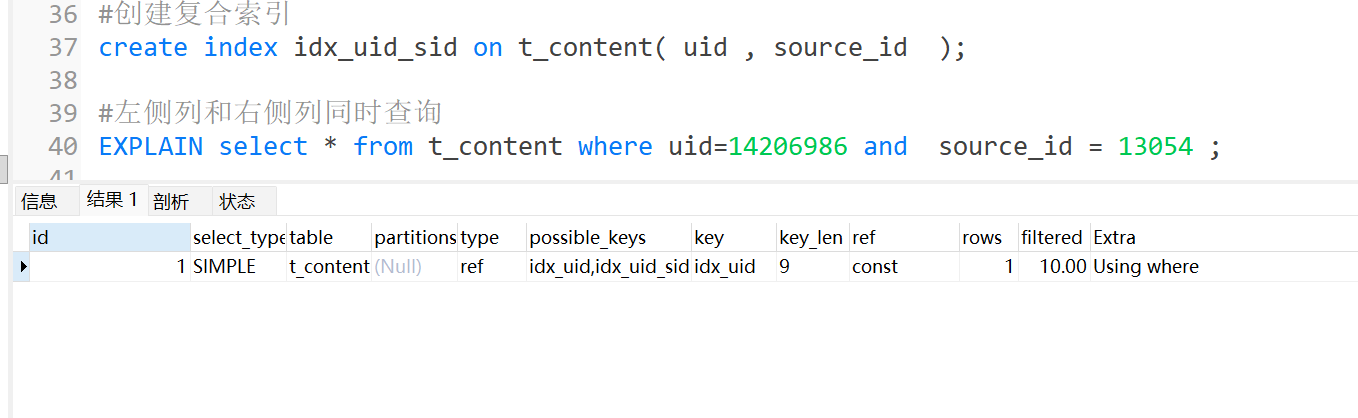
查询SQL中的where条件里面,同时用到了uid和source_id,这种情况索引有效。
如果是复合索引,查询条件中必须包含索引的左侧列字段。
索引失效的场景
下面的使用方式,索引会失效,即使添加了索引,也不会提升查询效率。
后缀查询

在like查询中,字符串开头使用了%,这种情况索引会失效。
模糊匹配

在like查询中,字符串开头和结尾都使用了%,这种情况索引会失效。
不等号
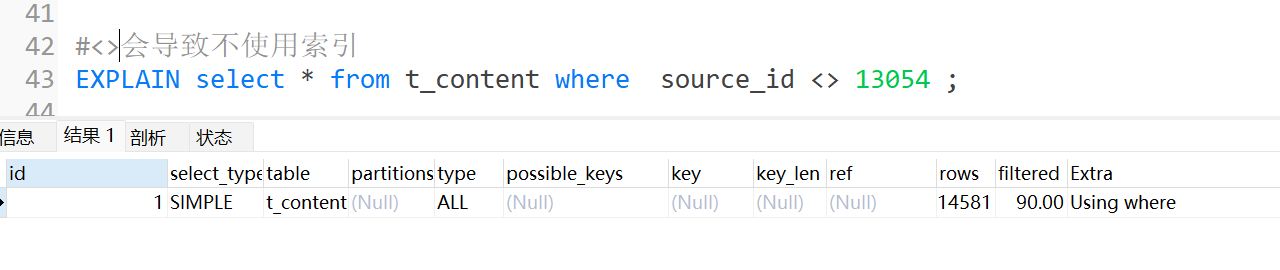
查询条件中使用不等号(<>)会导致索引失效。
NOT IN
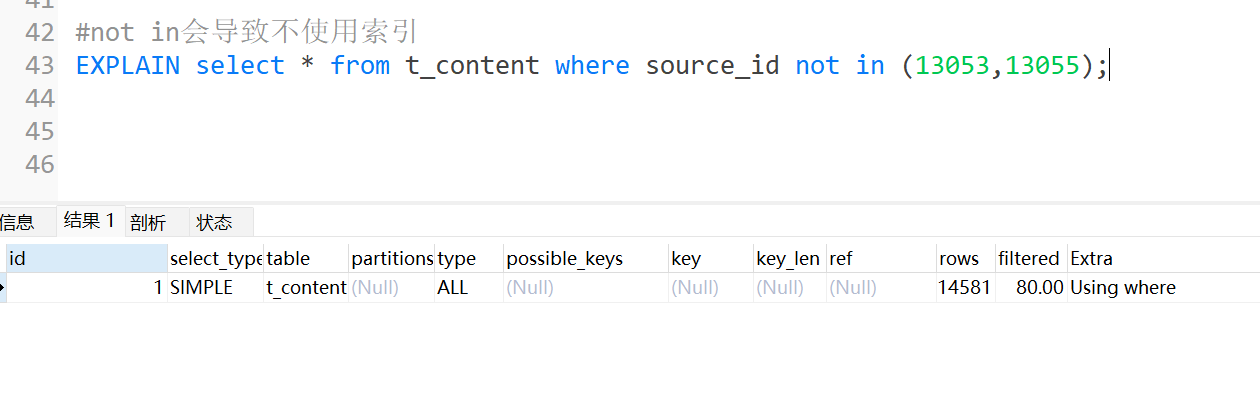
查询条件中使用not in会导致索引失效。
IS NOT NULL
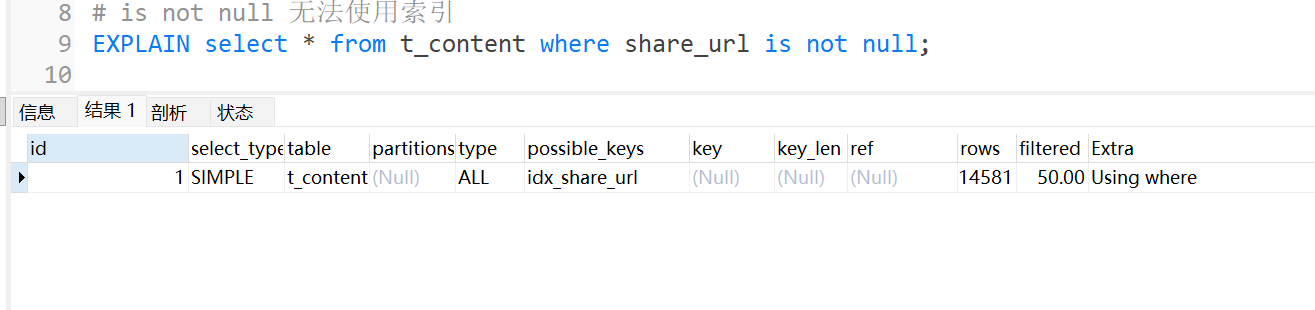
is not null不会用到索引
对索引列进行计算

uid字段上面,已经创建了索引,但是用运算后,查询时,就不会用到索引。
对索引列使用函数

uid字段上面,已经创建了索引,但是用CAST函数对字段值进行处理,查询时,就不会用到索引。
复合索引查询条件只含右侧列

在上面的示例中,复合索引包含了两个字段,uid和source_id,uid在第一位,source_id在第二位。
查询SQL中只用source_id作为查询条件,并没有使用uid,导致索引失效。
如果是复合索引,查询条件中必须包含索引的左侧列字段。
复合索引排序用右侧列

在上面的语句中,source_id字段是复合索引右侧列字段,在排序时仅用右侧列进行排序,那么排序就是Using filesort,也就是比较慢的排序方式。
复合索引排序列顺序颠倒

在上面的语句中,uid和source_id字段组成了复合索引,uid是索引的左侧字段,当使用order by进行排序时,如果source_id(索引右侧列)在前面,不会使用索引,排序就是Using filesort方式,比较慢的排序方式。
复合索引排序列左侧字段为降序

在上面的语句中,uid和source_id字段组成了复合索引,uid是索引的左侧字段,当使用order by进行排序时,如果uid(索引左侧列)为desc(降序),不会使用索引,排序就是Using filesort方式,比较慢的排序方式。