LangChain实战快速入门笔记(二)--LangChain使用之Model I/O
文章目录
- [LangChain实战快速入门笔记(二)--LangChain使用之Model I/O](#LangChain实战快速入门笔记(二)--LangChain使用之Model I/O)
- [一、Model I/O](#一、Model I/O)
-
- [1.Model I/O介绍](#1.Model I/O介绍)
- [2.Model I/O之调用模型1](#2.Model I/O之调用模型1)
-
- [2.1 模型的不同分类方式](#2.1 模型的不同分类方式)
- [2.2 角度1出发:按照功能不同举例](#2.2 角度1出发:按照功能不同举例)
- [2.3 角度1出发:参数位置不同举例](#2.3 角度1出发:参数位置不同举例)
-
- [2.3.1 模型调用的主要方法及参数](#2.3.1 模型调用的主要方法及参数)
- [2.3.2 模型调用推荐平台:closeai](#2.3.2 模型调用推荐平台:closeai)
- [2.3.3 方式1:硬编码](#2.3.3 方式1:硬编码)
- [2.3.4 方式2:配置环境变量](#2.3.4 方式2:配置环境变量)
- [2.3.5 方式3:使用.env配置文件](#2.3.5 方式3:使用.env配置文件)
- [2.4 角度3出发:各平台API的调用举例(了解)](#2.4 角度3出发:各平台API的调用举例(了解))
-
- [2.4.1 OpenAI 官方API](#2.4.1 OpenAI 官方API)
- [2.4.2 阿里云百炼平台](#2.4.2 阿里云百炼平台)
- [2.5 如何选择合适的大模型](#2.5 如何选择合适的大模型)
-
- [2.5.1 小结:获取大模型的标准方式](#2.5.1 小结:获取大模型的标准方式)
- [3.Model I/O之调用模型2](#3.Model I/O之调用模型2)
-
- [3.1 关于对话模型的Message(消息)](#3.1 关于对话模型的Message(消息))
- [3.2 关于多轮对话与上下文记忆](#3.2 关于多轮对话与上下文记忆)
- [3.3 关于模型调用的方法](#3.3 关于模型调用的方法)
-
- [3.3.1 流式输出与非流式输出](#3.3.1 流式输出与非流式输出)
- [3.3.2 批量调用](#3.3.2 批量调用)
- [3.3.3 同步调用与异步调用(了解)](#3.3.3 同步调用与异步调用(了解))
- [4、Model I/O之Prompt Template](#4、Model I/O之Prompt Template)
-
- [4.1 介绍与分类](#4.1 介绍与分类)
- [4.2 复习:str.format()](#4.2 复习:str.format())
-
- [4.2.1 带有位置参数的用法](#4.2.1 带有位置参数的用法)
- [4.2.2 带有关键字参数的用法](#4.2.2 带有关键字参数的用法)
- [4.2.3 使用字典解包的方式](#4.2.3 使用字典解包的方式)
- [4.3 具体使用:PromptTemplate](#4.3 具体使用:PromptTemplate)
-
- [4.3.1 使用说明](#4.3.1 使用说明)
- [4.3.2 两种实例化方式](#4.3.2 两种实例化方式)
- [4.3.3 两种新的结构形式](#4.3.3 两种新的结构形式)
- [4.3.4 format()与invoke()](#4.3.4 format()与invoke())
- [4.3.5 结合LLM调用](#4.3.5 结合LLM调用)
- [4.4 具体使用:ChatPromptTemplate](#4.4 具体使用:ChatPromptTemplate)
-
- [4.4.1 使用说明](#4.4.1 使用说明)
- [4.4.2 两种实例化方式](#4.4.2 两种实例化方式)
- [4.4.3 模板调用的几种方式](#4.4.3 模板调用的几种方式)
- [4.4.4 更丰富的实例化参数类型](#4.4.4 更丰富的实例化参数类型)
- [4.4.5 结合LLM](#4.4.5 结合LLM)
- [4.4.6 插入消息列表:MessagesPlaceholder](#4.4.6 插入消息列表:MessagesPlaceholder)
- [4.5 具体使用:少量样本示例的提示词模板](#4.5 具体使用:少量样本示例的提示词模板)
-
- [4.5.1 使用说明](#4.5.1 使用说明)
- [4.5.2 FewShotPromptTemplate的使用](#4.5.2 FewShotPromptTemplate的使用)
- [4.5.3 FewShotChatMessagePromptTemplate的使用](#4.5.3 FewShotChatMessagePromptTemplate的使用)
- [4.5.4 Example selectors(示例选择器)](#4.5.4 Example selectors(示例选择器))
-
- 举例1:
- [举例2:结合 FewShotPromptTemplate 使用](#举例2:结合 FewShotPromptTemplate 使用)
- [4.6 具体使用:PipelinePromptTemplate(了解)](#4.6 具体使用:PipelinePromptTemplate(了解))
- [4.7 具体使用:自定义提示词模版(了解)](#4.7 具体使用:自定义提示词模版(了解))
- [4.8 从文档中加载Prompt(了解)](#4.8 从文档中加载Prompt(了解))
-
- [4.8.1 yaml格式提示词](#4.8.1 yaml格式提示词)
- [4.8.2 json格式提示词](#4.8.2 json格式提示词)
- [5、Model I/O之Output Parsers](#5、Model I/O之Output Parsers)
-
- [5.1 输出解析器的分类](#5.1 输出解析器的分类)
- [5.2 具体解析器的使用](#5.2 具体解析器的使用)
-
- [①字符串解析器 StrOutputParser](#①字符串解析器 StrOutputParser)
- [②JSON解析器 JsonOutputParser](#②JSON解析器 JsonOutputParser)
- [③ XML解析器 XMLOutputParser](#③ XML解析器 XMLOutputParser)
-
- 举例1:不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
- 举例2:体会XMLOutputParser的格式
- [举例3:XMLOutputParser 的使用](#举例3:XMLOutputParser 的使用)
- 举例4:与前例类似
- [④列表解析器 CommaSeparatedListOutputParser(了解)](#④列表解析器 CommaSeparatedListOutputParser(了解))
- [⑤日期解析器 DatetimeOutputParser (了解)](#⑤日期解析器 DatetimeOutputParser (了解))
- 6、LangChain调用本地模型
- 总结
一、Model I/O
1.Model I/O介绍
Model I/O 模块是与语言模型(LLMs)进行交互的核心组件,在整个框架中有着很重要的地位。
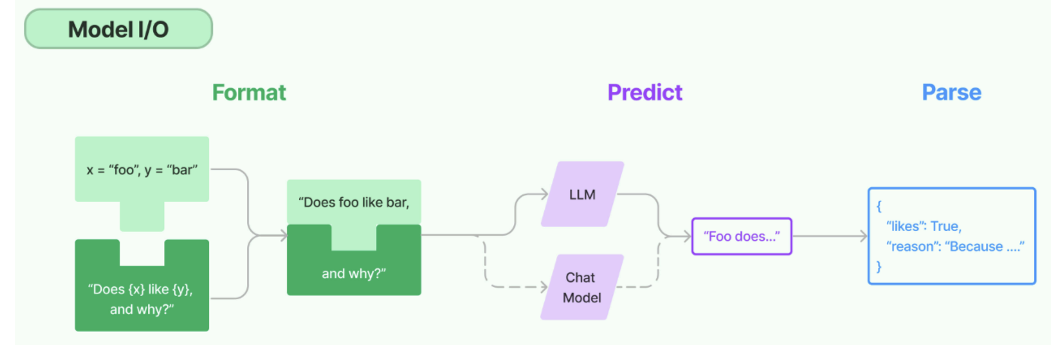
所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着Prompt Template,Model 和Output Parser。
简单来说,就是输⼊、模型处理、输出这三个步骤。
针对每个环节,LangChain都提供了模板和工具,可以快捷的调用各种语言模型的接口。
2.Model I/O之调用模型1
LangChain作为一个"工具",不提供任何 LLMs,而是依赖于第三方集成各种大模型 。比如,将OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的
应用。
2.1 模型的不同分类方式
简单来说,就是⽤谁家的API以什么⽅式调⽤哪种类型的⼤模型
(1)**角度1:**按照模型功能的不同:
①非对话模型(LLMs、Text Model)
②对话模型(Chat Models)(推荐)
③嵌入模型(Embedding Models)(暂不考虑)
(2)**角度2:**模型调用时,几个重要参数的书写位置的不同:
①硬编码:写在代码文件中
推荐)
②使用环境变量
③使用配置文件(推荐)
背景小知识:
OpenAI的GPT系列模型影响了⼤模型技术发展的开发范式和标准。所以⽆论是Qwen、ChatGLM等模型,它们的使⽤⽅法和函数调⽤逻辑基本遵循OpenAI定义的规范
,没有太⼤差异。这就使得大部分的开源项⽬能够通过⼀个较为通⽤的接口来接⼊和使⽤不同的模型。
2.2 角度1出发:按照功能不同举例
类型1:LLMs(非对话模型)
LLMs,也叫Text Model、非对话模型,是许多语言模型应用程序的支柱。主要特点如下:
(1)输入 :接受文本字符串 或PromptValue 对象
(2)输出 :总是返回文本字符串

(3)适用场景 :仅需单次文本生成任务(如摘要生成、翻译、代码生成、单次问答)或对接不支持消息结构的旧模型(如部分本地部署模型)(言外之意,优先推荐ChatModel )
(4)不支持多轮对话上下文 。每次调用独立处理输入,无法自动关联历史对话(需手动拼接历史文本)。
(5)局限性:无法处理角色分工或复杂对话逻辑。
举例:
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
##########核心代码##########
llm = OpenAI()
str = llm.invoke("写一首关于春天的诗") # 直接输入字符串
print(str)类型2:Chat Models(对话模型)
ChatModels,也叫聊天模型、对话模型,底层使用LLMs。
大语言模型调用,以 ChatModel 为主!
主要特点如下:
(1)输入 :接收消息列表ListBaseMessage 或PromptValue ,每条消息需指定角色(如SystemMessage、HumanMessage、AIMessage)
(2)输出 :总是返回带角色的
消息对象(BaseMessage 子类),通常是
AIMessage
(3)原生支持多轮对话 。通过消息列表维护上下文(例如:SystemMessage, HumanMessage, AIMessage, ...),模型可基于完整对话历史生成回复。
(4)适用场景:对话系统(如客服机器人、长期交互的AI助手)
举例:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
##########核心代码##########
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="我是人工智能助手,我叫小智"),
HumanMessage(content="你好,我是小明,很高兴认识你")
]
response = chat_model.invoke(messages) # 输入消息列表
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
print(response.content)类型3:Embedding Model(嵌入模型)
Embedding Model :也叫文本嵌入模型,这些模型将文本 作为输入并返回浮点数列表,也就是Embedding。
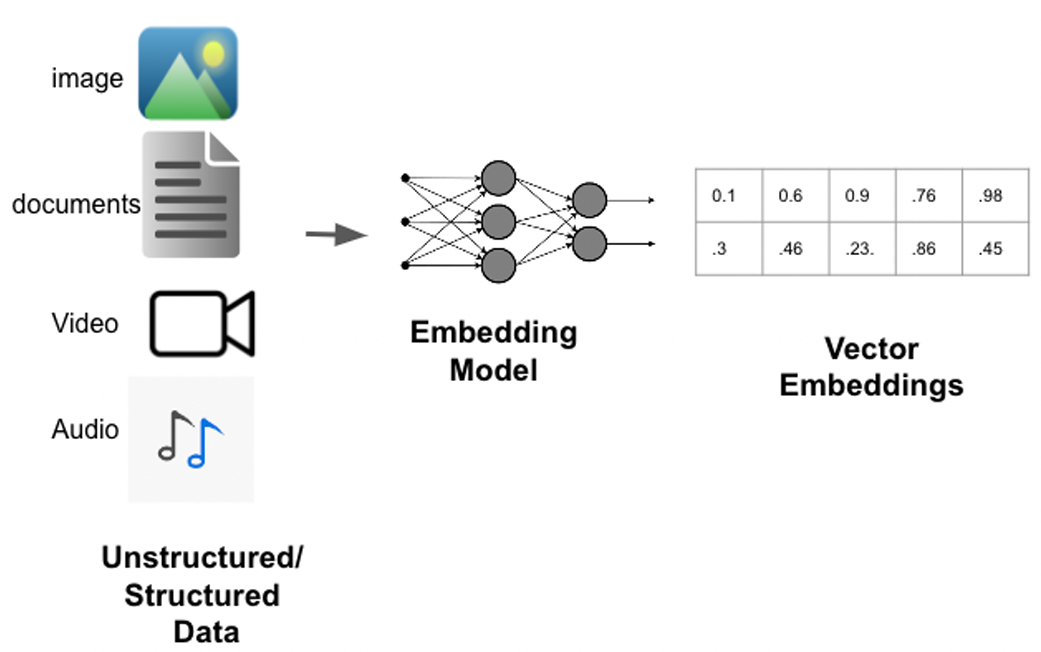
python
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
##########
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
res1 = embeddings_model.embed_query("我是文档中的数据")
print(res1)
# 打印结果: [-0.004306625574827194, 0.003083756659179926, -0.013916781172156334, ......]2.3 角度1出发:参数位置不同举例
这里以LangChain 的API为准,使用对话模型,进行测试。
2.3.1 模型调用的主要方法及参数
相关方法及属性:
**· OpenAI(...) / ChatOpenAI(...) :**创建一个模型对象(非对话类/对话类)
**· model.invoke(xxx) :**执行调用,将用户输入发送给模型
**· content :**提取模型返回的实际文本内容
模型调用函数使用时需初始化模型,并设置必要的参数。
1)必须设置的参数:
**· base_url :**大模型 API 服务的根地址
**· api_key :**用于身份验证的密钥,由大模型服务商(如 OpenAI、百度千帆)提供
· model/model_name :指定要调用的具体大模型名称(如gpt-4-turbo 、ERNIE-3.5-8K 等)
2)其它参数:
第一个------👇
· temperature :温度,控制生成文本的"随机性",取值范围为0~1。
①值越低 → 输出越确定、保守(适合事实回答)
②值越高 → 输出越多样、有创意(适合创意写作)
通常,根据需要设置如下:
①精确模式(0.5或更低):生成的文本更加安全可靠,但可能缺乏创意和多样性。
②平衡模式(通常是0.8):生成的文本通常既有一定的多样性,又能保持较好的连贯性和准确性。
③创意模式(通常是1):生成的文本更有创意,但也更容易出现语法错误或不合逻辑的内容。
第二个------👇
· max_tokens :限制生成文本的最大长度,防止输出过长。
Token是什么?
基本单位: 大模型处理文本的最小单位是token(相当于自然语言中的词或字),输出时逐个token
依次生成。
**收费依据:**大语言模型(LLM)通常也是以token的数量作为其计量(或收费)的依据。
①1个Token≈1-1.8个汉字,1个Token≈3-4个英文字母
②Token与字符转化的可视化工具:
OpenAI提供:https://platform.openai.com/tokenizer
百度智能云提供:https://console.bce.baidu.com/support/#/tokenizer
max_tokens设置建议:
①客服短回复:128-256。比如:生成一句客服回复(如"订单已发货,预计明天送达")
②常规对话、多轮对话:512-1024
③长内容生成:1024-4096。比如:生成一篇产品说明书(包含功能、使用方法等结构)
2.3.2 模型调用推荐平台:closeai
这里推荐使用的平台:
考虑到OpenAI等模型在国内访问及充值的不便,大家可以使用CloseAI网站注册和充值,
具体费用自理。
https://www.closeai-asia.com
2.3.3 方式1:硬编码
直接将 API Key 和模型参数写入代码,仅适用于临时测试 ,存在密钥泄露风险,生产环境不推荐。
python
from langchain_openai import ChatOpenAI
# 硬编码 API Key 和模型参数
llm = ChatOpenAI(
api_key="sk-xxxxxx", # 明文暴露密钥
base_url="https://api.openai-proxy.org/v1",
model="gpt-3.5-turbo",
)
# 调用示例
response = llm.invoke("解释神经网络原理")
print(response.content)2.3.4 方式2:配置环境变量
通过系统环境变量存储密钥,避免代码明文暴露。
方式1:终端设置环境变量(临时生效):
bash
export OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxx" # Linux/Mac
set OPENAI_API_KEY="sk-xxxxxxxxxxxxxxxxxxxx" # Windows方式2:从PyCharm设置
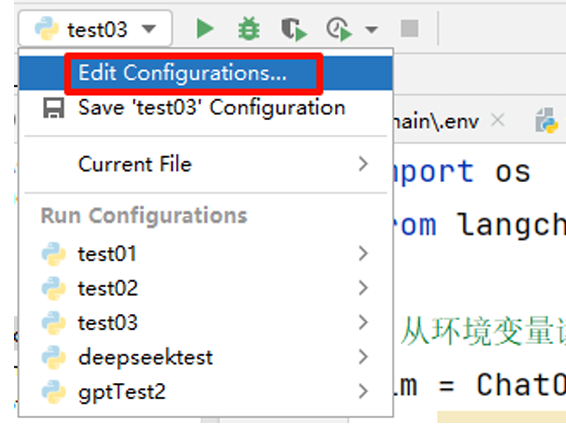

举例:
python
import os
from langchain_openai import ChatOpenAI
# 从环境变量读取密钥
llm = ChatOpenAI(
api_key=os.environ["OPENAI_API_KEY"], # 动态获取
base_url=os.environ["OPENAI_BASE_URL"],
model="gpt-4o-mini",
)
response = llm.invoke("LangChain是什么?")
print(response.content)优点 :密钥与代码分离,适合单机开发
缺点:切换终端或文件后,变量失效,需重新设置。
2.3.5 方式3:使用.env配置文件
使用 python-dotenv 加载本地配置文件,支持多环境管理(开发/生产)。
(1)安装依赖
markup
pip install python-dotenv
#或者
conda install python-dotenv(2)创建 .env 文件(项目根目录):
python
OPENAI_API_KEY= "sk-xxxxxxxxx" # 需填写自己的API KEY
OPENAI_BASE_URL="https://api.openai-proxy.org/v1(3)举例
方式1:
python
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
import os
load_dotenv() # 自动加载 .env 文件
# print(os.getenv("OPENAI_API_KEY"))
# print(os.getenv("OPENAI_BASE_URL"))
llm = ChatOpenAI(
api_key=os.getenv("OPENAI_API_KEY"), # 安全读取
base_url=os.getenv("OPENAI_BASE_URL"),
model="gpt-4o-mini",
temperature=0.7,
)
response = llm.invoke("RAG 技术的核心流程")
print(response.content)方式2:给os内部的环境变量赋值
python
from langchain_openai import ChatOpenAI
import dotenv
dotenv.load_dotenv()
import os
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_API_BASE"] = os.getenv("OPENAI_BASE_URL")
text = "猫王是猫吗?"
chat_model = ChatOpenAI(
model="gpt-4o-mini",
temperature=0.7,
max_tokens=300,
)
response = chat_model.invoke(text)
print(type(response))
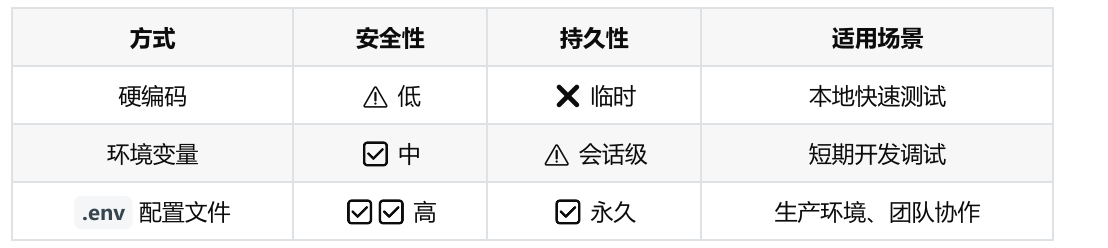
print(response.content)核心优势:
(1)配置文件可加入 .gitignore 避免泄露
(2)结合 LangChain 可扩展其它模型(如 DeepSeek、阿里云)
(3)生产环境推荐
小结:
2.4 角度3出发:各平台API的调用举例(了解)
2.4.1 OpenAI 官方API
考虑到OpenAI在国内访问及充值的不便,我们仍然使用CloseAI网站(https://www.closeaiasia.com)注册和充值,具体费用自理。
调用非对话模型:
python
from openai import OpenAI
# 从环境变量读取API密钥(推荐安全存储)
client = OpenAI(api_key="sk-zD4CB2Qe7G2Dp6veCfPRSxeDx9fQPxCUIfOFAk20ETV5B2VA", # 填写自己的api-key
base_url="https://api.openai-proxy.org/v1") # 通过代码示例获取
# 调用Completion接口
response = client.completions.create(
model="gpt-3.5-turbo-instruct", # 非对话模型
prompt="请将以下英文翻译成中文:l'Artificial intelligence will reshape the future.",
max_tokens=100, # 生成文本最大长度
temperature=0.7, # 控制随机性
)
# 提取结果
print(response.choices[0].text.strip())调用对话模型:
写法1:
python
from openai import OpenAI
client = OpenAI(api_key="sk-zD4CB2Qe7G2Dp6veCfPRSxeDx9fQPxCUIfOFAk20ETV5B2VA", #填写自己的api-key
base_url="https://api.openai-proxy.org/v1")
completion = client.chat.completions.create(
model="gpt-3.5-turbo", # 对话模型
messages=[
{"role": "system", "content": "你是一个乐于助人的智能AI小助手"},
{"role": "user", "content": "你好,请你介绍一下你自己"}
],
max_tokens=150,
temperature=0.5
)
print(completion.choices[0].message)写法2:
python
from openai import OpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "我是一位乐于助人的AI智能小助手"},
{"role": "user", "content": "你好,请你介绍一下你自己。"}
]
)
print(response.choices[0])2.4.2 阿里云百炼平台
注册与key的获取:
提前开通百炼平台账号并申请API KEY:https://bailian.console.aliyun.com/#/home[链接](https://bailian.console.aliyun.com/#/home)
模型的调用:
参考具体模型的代码示例。这里以DeepSeek为例:
python
DASHSCOPE_API_KEY="sk-f1a87324#####e6a819a482" #使用自己的api key
DASHSCOPE_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"举例1:通过OpenAI SDK
python
pip install openai
python
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv("DASHSCOPE_API_KEY"), # 如何获取API Key: https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
base_url=os.getenv("DASHSCOPE_BASE_URL")
)
completion = client.chat.completions.create(
model="deepseek-r1", # 此处以 deepseek-r1 为例,可按需更换模型名称。
messages=[
{'role': 'user', 'content': '9.9和9.11谁大'}
]
)
# 通过reasoning_content字段打印思考过程
print('思考过程:')
print(completion.choices[0].message.reasoning_content)
# 通过content字段打印最终答案
print('最终答案:')
print(completion.choices[0].message.content)举例2:通过DashScope SDK
python
pip install dashscope
python
import os
import dashscope
messages = [
{'role': 'user', 'content': '你是谁?'}
]
response = dashscope.Generation.call(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key="sk-xxx",
api_key=os.getenv('DASHSCOPE_API_KEY'),
model='deepseek-r1', # 此处以 deepseek-r1 为例,可按需更换模型名称。
messages=messages,
# result_format参数不可以设置为"text"。
result_format='message'
)
print("="*20 + "思考过程" + "="*20)
print(response.output.choices[0].message.reasoning_content)
print("="*20 + "最终答案" + "="*20)
print(response.output.choices[0].message.content)2.5 如何选择合适的大模型
没有最好的大模型,只有最适合的大模型
为什么不要依赖榜单?
(1)榜单已被应试教育污染,还算值得相信的榜单:LMSYS Chatbot Arena Leaderboard
(2)榜单体现的是整体能力,放到一件具体事情上,排名低的可能反倒更好
(3)榜单体现不出成本差异
2.5.1 小结:获取大模型的标准方式
后续的各种模型测试,都基于如下的模型展开:
非对话模型:
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI( # 非对话模型
# max_tokens=512,
# temperature=0.7,
)对话模型:
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI( # 对话模型
model="gpt-4o-mini",
# max_tokens=512,
# temperature=0.7,
)对应的配置文件:
python
OPENAI_API_KEY="sk-xxxxxx" # 从CloseAI平台,注册自己的账号,并获取API KEY
OPENAI_BASE_URL="https://api.openai-proxy.org/v1"3.Model I/O之调用模型2
3.1 关于对话模型的Message(消息)
聊天模型,出了将字符串作为输入外,还可以使用聊天消息作为输入,并返回聊天消息作为输出。
LangChain有一些内置的消息类型:
聊天消息作为输出。
🔥System Message :设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总体目标。比如"作为一个代码专家",或者"返回json格式"。通常作为输入消息序列中的第一个传递。
🔥Human Message :表示来自用户输入。比如"实现 一个快速排序方法"
🔥AI Message :存储AI回复的内容。这可以是文本,也可以是调用工具的请求
· ChatMessage :可以自定义角色的通用消息类型
· FunctionMessage/ToolMessage :函数调用/工具消息,用于函数调用结果的消息类型。
举例1:
python
from langchain_core.messages import HumanMessage, SystemMessage
messages = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="你好,请你介绍一下你自己")]
print(messages)
举例2:
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage(content=["你是一个数学家,只会回答数学问题", "每次你都能给出详细的方案"]),
HumanMessage(content="1 + 2 * 3 = ?"),
AIMessage(content="1 + 2 * 3 的结果是7"),
]
print(messages)
举例3:
python
#1.导入相关包
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
#2.直接创建不同类型消息
systemMessage = SystemMessage(
content="你是一个AI开发工程师",
additional_kwargs={"tool": "invoke_tool()"}
)
humanMessage = HumanMessage(
content="你能开发哪些AI应用?"
)
aiMessage = AIMessage(
content="我能开发很多AI应用,比如聊天机器人、图像识别,自然语言处理等"
)
#3.打印消息列表
messages = [systemMessage, humanMessage, aiMessage]
print(messages)
举例4:
python
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
ChatMessage
)
# 创建不同类型的消息
system_message = SystemMessage(content="你是一个专业的数据科学家")
human_message = HumanMessage(content="解释一下随机森林算法")
ai_message = AIMessage(content="随机森林是一种集成学习方法...")
custom_message = ChatMessage(role="analyst", content="补充一点关于超参数调优的信息")
print(system_message.content)
print(human_message.content)
print(ai_message.content)
print(custom_message.content)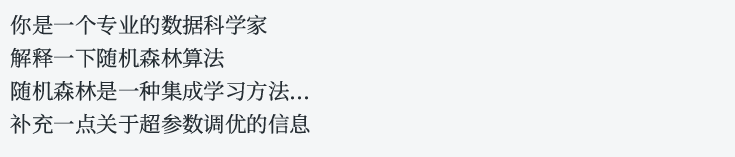
举例5:结合大模型使用
python
import os
from langchain_core.messages import SystemMessage, HumanMessage
import dotenv
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini",
)
# 组成消息列表
messages = [
SystemMessage(content="你是一个擅长人工智能相关学科的专家"),
HumanMessage(content="请解释一下什么是机器学习?")
]
response = chat_model.invoke(messages)
print(response.content)
print(type(response)) # <class 'langchain_core.messages.ai.AIMessage'>
3.2 关于多轮对话与上下文记忆
前提:获取大模型
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini"
)测试代码:
python
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="人工智能英文怎么说?"),
AIMessage(content="AI"),
HumanMessage(content="你叫什么名字"),
]
messages1 = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="很高兴认识你"),
AIMessage(content="我也很高兴认识你"),
HumanMessage(content="你叫什么名字"),
]
messages2 = [
SystemMessage(content="我是一个人工智能助手,我的名字叫小智"),
HumanMessage(content="人工智能英文怎么说?"),
AIMessage(content="AI"),
HumanMessage(content="你叫什么名字"),
]
chat_model.invoke(messages2)3.3 关于模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个"Runnable"协议。许多LangChain组件实现了 Runnable 协议,包括聊天模型、提示词模板、输出解析器、检索器、代理(智能体)等。
Runnable 定义的公共的调用方法如下:
①invoke: 处理单条输入,等待LLM完全推理完成后再返回调用结果
②stream: 流式响应,逐字输出LLM的响应结果
③batch: 处理批量输入
这些也有相应的异步方法,应该与 asyncio 的await语法一起使用以实现并发:
①astream: 异步流式响应
②ainvoke: 异步处理单条输入
③abatch: 异步处理批量输入
④astream_log: 异步流式返回中间步骤,以及最终响应
⑤astream_events: (测试版)异步流式返回链中发生的事件(在 langchain-core 0.1.14 中引入)
3.3.1 流式输出与非流式输出
在Langchain中,语言模型的输出分为了两种主要的模式:流式输出与非流式输出。
下面是两个场景:
(1)非流式输出:这是Langchain与LLM交互时的默认行为 ,是最简单、最稳定的语言模型调用方式。当用户发出请求后,系统在后台等待模型生成完整响应 ,然后一次性将全部结果返回 。
①举例:用户提问,请编写一首诗,系统在静默数秒后突然弹出了完整的诗歌。(体验较单
调)
②在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。
(2)流式输出:一种更具交互感 的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容。
①举例:用户提问,请编写一首诗,当问题刚刚发送,系统就开始一字一句 (逐个token)进行回复,感觉是一边思考一边输出。
②更像是"实时对话",更为贴近人类交互的习惯,更有吸引力。
③适合构建强调"实时反馈"的应用,如聊天机器人、写作助手等。
④Langchain 中通过设置 stream=True 并配合 回调机制 来启用流式输出。
非流式输出:
举例1:
python
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]
# 非流式调用LLM获取响应
response = chat_model.invoke(messages)
# 打印响应内容
print(response)输入结果如下,直接全部输出:

举例2:
python
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 支持多个消息作为输入
messages = [
SystemMessage(content="你是一位乐于助人的助手,你叫于老师"),
HumanMessage(content="你是谁?")
]
response = chat_model.invoke(messages)
print(response.content)
举例3:
python
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 支持多个消息作为输入
messages = [
SystemMessage(content="你是一位乐于助人的助手. 你叫于老师"),
HumanMessage(content="你是谁?")
]
response = chat_model(messages) # 特别的写法
print(response.content)第19行,底层调用BaseChatModel.call ,内部调用的还是invoke()。后续还会有这种写法出现,了
解即可。
流式输出
一种更具交互感的模型输出方式,用户不再需要等待完整答案,而是能看到模型逐个 token 地实时返回内容。适合构建强调"实时反馈"的应用,如聊天机器人、写作助手等。
Langchain 中通过设置 streaming=True 并配合 回调机制 来启用流式输出。
举例:
python
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini",
streaming=True # 启用流式输出
)
# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]
# 流式调用LLM获取响应
print("开始流式输出:")
for chunk in chat_model.stream(messages):
# 逐个打印内容
print(chunk.content, end="", flush=True) # 刷新缓冲区(无换行符,缓冲区未刷新,内容可能不会立即显示)
print("\n流式输出结束")输出结果如下(一段段文字逐个输出)

3.3.2 批量调用
举例:
python
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"),]
messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是AIGC"),]
messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是大模型技术"),]
messages = [messages1, messages2, messages3]
# 调用batch
response = chat_model.batch(messages)
print(response)
3.3.3 同步调用与异步调用(了解)
同步调用
python
import time
def call_model():
# 模拟同步API调用
print("开始调用模型...")
time.sleep(5) # 模拟调用等待,单位: 秒
print("模型调用完成。")
def perform_other_tasks():
# 模拟执行其他任务
for i in range(5):
print(f"执行其他任务 {i + 1}")
time.sleep(1) # 单位: 秒
def main():
start_time = time.time()
call_model()
perform_other_tasks()
end_time = time.time()
total_time = end_time - start_time
return f"总共耗时: {total_time}秒"
# 运行同步任务并打印完成时间
main_time = main()
print(main_time)
之前的**llm.invoke(...)**本质上是一个同步调用。每个操作依次执行,直到当前操作完成后才开始下一个操作,从而导致总的执行时间是各个操作时间的总和。
异步调用
异步调用,允许程序在等待某些操作完成时继续执行其他任务,而不是阻塞等待。这在处理I/O操作(如网络请求、文件读写等)时特别有用,可以显著提高程序的效率和响应性。
举例:
写法1:此写法适合Jupyter Notebook
python
import asyncio
import time
async def async_call(llm):
await asyncio.sleep(5) # 模拟异步操作
print("异步调用完成")
async def perform_other_tasks():
await asyncio.sleep(5) # 模拟异步操作
print("其他任务完成")
async def run_async_tasks():
start_time = time.time()
await asyncio.gather(
async_call(None), # 示例调用,使用None模拟LLM对象
perform_other_tasks()
)
end_time = time.time()
return f"总共耗时: {end_time - start_time}秒"
## 正确运行异步任务的方式
## if __name__ == "__main__":
## # 使用asyncio.run()来启动异步程序
## result = asyncio.run(run_async_tasks())
## print(result)
# 在Jupyter单元格中直接调用
result = await run_async_tasks()
print(result)
写法2:(此写法不适合Jupyter Notebook)
python
import asyncio
import time
async def async_call(llm):
await asyncio.sleep(5) # 模拟异步操作
print("异步调用完成")
async def perform_other_tasks():
await asyncio.sleep(5) # 模拟异步操作
print("其他任务完成")
async def run_async_tasks():
start_time = time.time()
await asyncio.gather(
async_call(None), # 示例调用,替换None为模拟的LLM对象
perform_other_tasks()
)
end_time = time.time()
return f"总共耗时: {end_time - start_time}秒"
# 正确运行异步任务的方式
if __name__ == "__main__":
# 使用asyncio.run()来启动异步程序
result = asyncio.run(run_async_tasks())
print(result)使用**asyncio.gather()**并行执行时,理想情况下,因为两个任务几乎同时开始,它们的执行时间将重叠。如果两个任务的执行时间相同(这里都是5秒),那么总执行时间应该接近单个任务的执行时间,而不是两者时间之和。
异步调用之ainvoke
举例1:验证ainvoke是否是异步
python
# 方式1
import inspect
print("ainvoke 是协程函数:", inspect.iscoroutinefunction(chat_model.ainvoke))
print("invoke 是协程函数:", inspect.iscoroutinefunction(chat_model.invoke))
举例2:(不能在Jupyter Notebook中测试)
python
import asyncio
import time
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY1"] = os.getenv("OPENAI_API_KEY1")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 同步调用(对照组)
def sync_test():
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"),]
start_time = time.time()
response = chat_model.invoke(messages1) # 同步调用
duration = time.time() - start_time
print(f"同步调用耗时: {duration:.2f}秒")
return response, duration
# 异步调用(实验组)
async def async_test():
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"),]
start_time = time.time()
response = await chat_model.ainvoke(messages1) # 异步调用
duration = time.time() - start_time
print(f"异步调用耗时: {duration:.2f}秒")
return response, duration
# 运行测试
if __name__ == "__main__":
# 运行同步测试
sync_response, sync_duration = sync_test()
print(f"同步响应内容:{sync_response.content[:100]}...\n")
# 运行异步测试
async_response, async_duration = asyncio.run(async_test())
print(f"异步响应内容:{async_response.content[:100]}...\n")
# 并发测试 - 修复版本
print("\n=== 并发测试 ===")
start_time = time.time()
async def run_concurrent_tests():
# 创建3个异步任务
tasks = [async_test() for _ in range(3)]
# 并发执行所有任务
return await asyncio.gather(*tasks)
# 执行并发测试
results = asyncio.run(run_concurrent_tests())
total_time = time.time() - start_time
print(f"\n3个并发异步调用总耗时:{total_time:.2f}秒")
print(f"平均每个调用耗时: {total_time / 3:.2f}秒")
4、Model I/O之Prompt Template
Prompt Template,通过模板管理大模型的输入。
4.1 介绍与分类
Prompt Template 是LangChain中的一个概念,接收用户输入,返回一个传递给LLM的信息(即提示词prompt)。
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,prompt template 是一个模板化的字符串 ,你可以将变量插入到模板 中,从而创建出不同的提示。调用时:
(1)以字典 作为输入,其中每个键代表要填充的提示模板中的变量。
(2)输出一个PromptValue 。这个 PromptValue 可以传递给 LLM 或 ChatModel,并且还可以转换为字符串或消息列表。
有几种不同类型的提示模板:
①PromptTemplate :LLM提示模板,用于生成字符串提示 。它使用 Python 的字符串来模板提示。
②ChatPromptTemplate :聊天提示模板,用于组合各种角色的消息模板 ,传入聊天模型。
③XxxMessagePromptTemplate :消息模板词模板,包括:SystemMessagePromptTemplate、
HumanMessagePromptTemplate、AIMessagePromptTemplate、
ChatMessagePromptTemplate等
④FewShotPromptTemplate :样本提示词模板,通过示例来教模型如何回答
⑤PipelinePrompt :管道提示词模板,用于把几个提示词组合在一起使用。
⑥自定义模板:允许基于其它模板类来定制自己的提示词模板。
模版导入
python
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts import (
ChatMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)4.2 复习:str.format()
Python的str.format() 方法是一种字符串格式化的手段,允许在字符串中插入变量。使用这种方法,可以创建包含占位符 的字符串模板,占位符由花括号{}标识。
● 调用format()方法时,可以传入一个或多个参数,这些参数将被顺序替换进占位符中。
● str.format()提供了灵活的方式来构造字符串,支持多种格式化选项。
在LangChain的默认设置下,PromptTemplate 使用 Python 的str.format() 方法进行模板化。这样在模型接收输入前,可以根据需要对数据进行预处理和结构化。
4.2.1 带有位置参数的用法
python
# 使用位置参数
info = "Name: {0}, Age: {1}".format("Jerry", 25)
print(info)
4.2.2 带有关键字参数的用法
python
# 使用关键字参数
info = "Name: {name}, Age: {age}".format(name= "Tom", age=25)
print(info)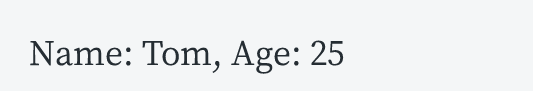
4.2.3 使用字典解包的方式
python
# 使用字典解包
person = {"name": "David", "age": 40}
info = "Name: {name}, Age: {age}".format(**person)
print(info)
4.3 具体使用:PromptTemplate
4.3.1 使用说明
PromptTemplate 类,用于快速构建 包含变量 的提示词模板,并通过 传入不同的参数值 生成自定义的提示词。
主要参数介绍:
● template: 定义提示词模板的字符串,其中包含 文本 和 变量占位符(如 {name}) ;
● input_variables: 列表,指定了模板中使用的变量名称,在调用模板时被替换;
● partial_variables: 字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换。
函数介绍:
● format (): 给 input_variables 变量赋值,并返回提示词。利用 format () 进行格式化时就一定要赋值,否则会报错。当在 template 中未设置 input_variables,则会自动忽略。
4.3.2 两种实例化方式
方式1:使用构造方法
举例1:
python
from langchain.prompts import PromptTemplate
# 定义模板:描述主题的应用
template = PromptTemplate(template="请简要描述{topic}的应用。", input_variables=["topic"])
print(template)
# 使用模板生成提示词
prompt_1 = template.format(topic="机器学习")
prompt_2 = template.format(topic="自然语言处理")
print("提示词1:", prompt_1)
print("提示词2:", prompt_2)
可以直观的看到PromptTemplate可以将template中声明的变量topic准确提取出来,使prompt更清晰。
举例2:定义多变量模板
python
from langchain.prompts import PromptTemplate
# 定义多变量模板
template = PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
input_variables=["product", "aspect1", "aspect2"]
)
# 使用模板生成提示词
prompt_1 = template.format(product="智能手机", aspect1="电池续航", aspect2="拍照质量")
prompt_2 = template.format(product="笔记本电脑", aspect1="处理速度", aspect2="便携性")
print("提示词1:", prompt_1)
print("提示词2:", prompt_2)方式2:调用from_template()
举例1:
python
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"请给我一个关于{topic}的{type}解释。"
)
# 传入模板中的变量名
prompt = prompt_template.format(type="详细", topic="量子力学")
print(prompt)
举例2:模板支持任意数量的变量,包括不含变量:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
#2.定义提示词模版对象
text = """
Tell me a joke
"""
prompt_template = PromptTemplate.from_template(text)
#3.默认使用f-string进行格式化(返回格式好的字符串)
prompt = prompt_template.format()
print(prompt)
4.3.3 两种新的结构形式
形式1:部分提示词模版
在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模版的时候只导入除已初始化的变量即可。
举例1:
方式1:实例化过程中使用partial_variables变量
python
from langchain.prompts import PromptTemplate
#方式2:
template2 = PromptTemplate(
template="{foo}{bar}",
input_variables=["foo", "bar"],
partial_variables={"foo": "hello"}
)
prompt2 = template2.format(bar="world")
print(prompt2)方式2:使用 PromptTemplate.partial() 方法创建部分提示模板(重要!!!!!)
python
from langchain.prompts import PromptTemplate
template1 = PromptTemplate(
template="{foo}{bar}",
input_variables=["foo", "bar"]
)
#方式1:
partial_template1 = template1.partial(foo="hello")
prompt1 = partial_template1.format(bar="world")
print(prompt1)举例2:
python
from langchain_core.prompts import PromptTemplate
# 完整模板
full_template = """你是一个{role},请用{style}风格回答:
问题: {question}
答案: """
# 预填充角色和风格
partial_template = PromptTemplate.from_template(full_template).partial(
role="资深厨师",
style="专业但幽默"
)
# 只需提供剩余变量
print(partial_template.format(question="如何煎牛排?"))
举例3:
python
prompt_template = PromptTemplate.from_template(
template = "请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
partial_variables= {"aspect1": "电池", "aspect2": "屏幕"}
)
prompt= prompt_template.format(product= "笔记本电脑")
print(prompt)
形式2:组合提示词(了解)
python
from langchain_core.prompts import PromptTemplate
template = (
PromptTemplate.from_template("Tell me a joke about {topic}")
+ ", make it funny"
+ "\nand in {language}"
)
prompt = template.format(topic="sports", language="spanish")
print(prompt)
4.3.4 format()与invoke()
只要对象是RunnableSerializable接口类型,都可以使用invoke(),替换前面使用format()的调用方式。
format(),返回值为字符串类型;invoke(),返回值为PromptValue类型,接着调用to_string()返回字
符串。
举例1:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
# 2.定义提示词模版对象
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 3.默认使用f-string进行格式化(返回格式好的字符串)
prompt_template.invoke({"adjective": "funny", "content": "chickens"})
举例2:
python
#1.导入相关的包
from langchain_core.prompts import PromptTemplate
# 2.使用初始化器进行实例化
prompt = PromptTemplate(
input_variables=["adjective", "content"],
template="Tell me a {adjective} joke about {content}"
)
# 3. PromptTemplate底层是RunnableSerializable接口 所以可以直接使用invoke()调用
prompt.invoke({"adjective": "funny", "content": "chickens"})举例3:
python
from langchain_core.prompts import PromptTemplate
prompt_template = (
PromptTemplate.from_template("Tell me a joke about {topic}")
+ ", make it funny"
+ " and in {language}"
)
prompt = prompt_template.invoke({"topic": "sports", "language": "spanish"})
print(prompt)4.3.5 结合LLM调用
Prompt 与大模型结合。
问题:这里的大模型,是哪类呢?非对话大模型?对话大模型?
提供大模型:(非对话大模型)
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI()提供大模型:(对话大模型)
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(
model="gpt-4o-mini"
)调用过程:
python
prompt_template = PromptTemplate.from_template(
template = "请评价{product}的优缺点,包括{aspect1}和{aspect2}。"
)
prompt = prompt_template.format(product= "电脑",aspect1= "性能",aspect2= "电池")
# prompt = prompt_template.invoke({"product":"电脑","aspect1":"性能","aspect2":"电池"})
print(type(prompt))
# llm.invoke(prompt) #使用非对话模型调用
llm1.invoke(prompt) #使用对话模型调用
4.4 具体使用:ChatPromptTemplate
4.4.1 使用说明
ChatPromptTemplate是创建聊天消息列表的提示模板。它比普通 PromptTemplate 更适合处理多角色、多轮次的对话场景。
特点:
● 支持 System/Human/AI 等不同角色的消息模板
● 对话历史维护
参数类型 :列表参数格式是tuple类型(role :str content :str 组合最常用)
元组的格式为:
(role: str | type, content: str | listdict | listobject)
● 其中 role 是:字符串(如 "system" 、"human" 、"ai")
4.4.2 两种实例化方式
方式1:使用构造方法
举例:
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
# 字符串 role + 字符串 content
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#调用format()方法, 返回字符串
prompt = prompt_template.invoke(input={"name": "小谷AI", "user_input": "你能帮我做什么?"})
print(type(prompt))
print(prompt)
方式2:调用from_messages()
举例1:
python
# 导入相关依赖
from langchain_core.prompts import ChatPromptTemplate
# 定义聊天提示词模版
chat_template = ChatPromptTemplate.from_messages(
[
("system", "你是一个有帮助的AI机器人,你的名字是{name}。"),
("human", "你好,最近怎么样?"),
("ai", "我很好,谢谢!"),
("human", "{user_input}"),
]
)
# 格式化聊天提示词模版中的变量
messages = chat_template.invoke(input={"name": "小明", "user_input": "你叫什么名字?"})
# 打印格式化后的聊天提示词模版内容
print(messages)
举例2:了解
python
# 示例1: role 为字符串
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个{role}."),
("human", "{user_input}"),
])
# 示例2: role 为消息类 不支持
from langchain_core.messages import SystemMessage, HumanMessage
# prompt = ChatPromptTemplate.from_messages([
# (SystemMessage, "你是一个{role}") # 类对象 role + 字符串 content
# (HumanMessage, ["你好!", {"type": "text"}]) # 类对象 role + list[dict] content
# ])
# 修改
prompt = ChatPromptTemplate.from_messages([
("system", ["你好!", {"type": "text"}]), # 字符串 role + list[dict] content
])4.4.3 模板调用的几种方式
invoke()\ format()\ format_messages()\ format_prompt()
● invoke (): 传入的是字典 ,返回 ChatPrompt
● Valueformat (): 传入变量的值 ,返回 str
● format_messages (): 传入变量的值 ,返回消息构成的
● listformat_prompt (): 传入变量的值,返回 ChatPromptValue
举例1: invoke()
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
# 字符串 role + 字符串 content
prompt_template = ChatPromptTemplate([
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
prompt = prompt_template.invoke({"name": "小谷AI", "user_input": "你能帮我做什么?"})
print(type(prompt))
print(prompt)
print(len(prompt.messages))
方式2:使用format()
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
# 字符串 role + 字符串 content
prompt_template = ChatPromptTemplate([
("system", "你是一个AI开发工程师. 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#方式1: 调用format()方法, 返回字符串
prompt = prompt_template.format(name="小谷AI", user_input="你能帮我做什么?")
print(type(prompt))
print(prompt)
方式3:使用format_messages()
python
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate([
("system", "你是一个AI开发工程师, 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
#调用format_messages()方法, 返回消息列表
prompt2 = prompt_template.format_messages(name="小谷AI", user_input="你能帮我做什么?")
print(type(prompt2))
print(prompt2)
结论:给占位符赋值,针对于ChatPromptTemplate,推荐使用format_messages()方法,返回消息列
表。
方式4:使用format_prompt()
python
from langchain_core.prompts import ChatPromptTemplate
#参数类型这里使用的是tuple构成的list
# 字符串 role + 字符串 content
prompt_template = ChatPromptTemplate([
("system", "你是一个AI开发工程师, 你的名字是 {name}."),
("human", "你能开发哪些AI应用?"),
("ai", "我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human", "{user_input}")
])
prompt = prompt_template.format_prompt(name="小谷AI", user_input="你能帮我做什么?")
print(prompt.to_messages())
print(type(prompt.to_messages()))
#print(prompt.to_string())
#print(type(prompt.to_string()))
4.4.4 更丰富的实例化参数类型
**本质:**不管使用构造方法、还是使用 from_message () 来创建 ChatPromptTemplate 的实例,本质上来讲,传入的都是消息构成的列表。
从调用上来讲,我们看到,不管使用构造方法,还是使用 from_message (),messages 参数的类型都是列表,但是列表的元素的类型是多样的。
元素可以是:
字符串类型、字典类型、消息类型、元组构成的列表(最常用、最基础、最简单)、Chat 提示词模板类型、消息提示词模板类型
类型1:Str类型
列表参数格式是str类型(不推荐 ),因为默认角色都是human
python
#1.导入相关依赖
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage,HumanMessage,AIMessage
#2.定义聊天提示词模版
chat_template = ChatPromptTemplate.from_messages(
[
"Hello, {name}!" # 等价于("human", "Hello, {name}!")
]
)
# 3.1格式化聊天提示词模板中的变量(自己提供的)
messages = chat_template.format_messages(name="小谷AI")
# 3.2 使用invoke执行
# messages=chat_template.invoke({"name":"小谷AI"})
#4.打印格式化后的聊天提示词模版内容
print(messages)类型2:dict类型
列表参数格式是dict类型
python
# 示例:字典形式的消息
prompt = ChatPromptTemplate.from_messages([
{"role": "system", "content": "你是一个{role}."},
{"role": "human", "content": ["复杂内容", {"type": "text"}]},
])
print(prompt.format_messages(role="教师"))类型3:Message类型
python
from langchain_core.messages import SystemMessage,HumanMessage
chat_prompt_template = ChatPromptTemplate.from_messages([
SystemMessage(content="我是一个贴心的智能助手"),
HumanMessage(content="我的问题是:人工智能英文怎么说?")
])
messages = chat_prompt_template.format_messages()
print(messages)
print(type(messages))
类型4:BaseChatPromptTemplate类型
使用 BaseChatPromptTemplate,可以理解为ChatPromptTemplate里嵌套了
ChatPromptTemplate。
举例1:不带参数
python
from langchain_core.prompts import ChatPromptTemplate
# 使用 BaseChatPromptTemplate (嵌套的 ChatPromptTemplate)
nested_prompt_template1 = ChatPromptTemplate.from_messages([("system", "我是一个人工智能助手")])
nested_prompt_template2 = ChatPromptTemplate.from_messages([("human", "很高兴认识你")])
prompt_template = ChatPromptTemplate.from_messages([
nested_prompt_template1, nested_prompt_template2
])
prompt_template.format_messages()
举例2:带参数
python
from langchain_core.prompts import ChatPromptTemplate
# 使用 BaseChatPromptTemplate (嵌套的 ChatPromptTemplate)
nested_prompt_template1 = ChatPromptTemplate.from_messages([
("system", "我是一个人工智能助手,我的名字叫{name}")
])
nested_prompt_template2 = ChatPromptTemplate.from_messages([
("human", "很高兴认识你,我的问题是{question}")
])
prompt_template = ChatPromptTemplate.from_messages([
nested_prompt_template1, nested_prompt_template2
])
prompt_template.format_messages(name="小智",question="你为什么这么帅?")
类型5:BaseMessagePromptTemplate类型
LangChain提供不同类型的MessagePromptTemplate。最常用的是
SystemMessagePromptTemplate 、
HumanMessagePromptTemplate 和
AIMessagePromptTemplate ,分别创建系统消息、人工消息和AI消息,它们是
ChatMessagePromptTemplate的特定角色子类。
基本概念:
HumanMessagePromptTemplate ,专用于生成**用户消息(HumanMessage)**的模板类,是ChatMessagePromptTemplate的特定角色子类。
● 本质 :预定义了 role="human" 的 MessagePromptTemplate,且无需无需手动指定角色
● 模板化 :支持使用变量占位符,可以在运行时填充具体值
● 格式化 :能够将模板与输入变量结合生成最终的聊天消息
● 输出类型 :生成 HumanMessage 对象(content + role="human" )
● 设计目的 :简化用户输入消息的模板化构造,避免重复定义角色
SystemMessagePromptTemplate、AIMessagePromptTemplate :类似于上面,不再赘述ChatMessagePromptTemplate ,用于构建聊天消息的模板。它允许你创建可重用的消息模板,这些模板可以动态地插入变量值来生成最终的聊天消息
● 角色指定 :可以为每条消息指定角色(如 "system"、"human"、"ai") 等,角色灵活。
● 模板化 :支持使用变量占位符,可以在运行时填充具体值
● 格式化:能够将模板与输入变量结合生成最终的聊天消息
举例1:
python
# 导入聊天消息类模板
from langchain_core.prompts import ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate
# 创建消息模板
system_template = "你是一个专家{role}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "给我解释{concept},用浅显易懂的语言"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 组合成聊天提示模板
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# 格式化提示
formatted_messages = chat_prompt.format_messages(
role="物理学家",
concept="相对论"
)
print(formatted_messages)
举例2:ChatMessagePromptTemplate的理解
python
# 1.导入相关包
from langchain_core.prompts import ChatMessagePromptTemplate
# 2.定义模版
prompt = "今天我们授课的内容是{subject}"
# 3.创建自定义角色聊天消息提示词模版
chat_message_prompt = ChatMessagePromptTemplate.from_template(
role="teacher", template=prompt
)
# 4.格式聊天消息提示词
resp = chat_message_prompt.format(subject="我爱北京天安门")
print(type(resp))
print(resp)
举例3:综合使用
python
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain_core.messages import SystemMessage, HumanMessage
# 示例1: 使用BaseMessagePromptTemplate
system_prompt = SystemMessagePromptTemplate.from_template("你是一个{role}")
human_prompt = HumanMessagePromptTemplate.from_template("{user_input}")
# 示例2: 使用BaseMessage (已实例化的消息)
system_msg = SystemMessage(content="你是一个AI工程师。")
human_msg = HumanMessage(content="你好!")
# 示例3: 使用BaseChatPromptTemplate (嵌套的ChatPromptTemplate)
nested_prompt = ChatPromptTemplate.from_messages([("system", "嵌套提示词")])
prompt = ChatPromptTemplate.from_messages([
system_prompt, # MessageLike (BaseMessagePromptTemplate)
human_prompt, # MessageLike (BaseMessagePromptTemplate)
system_msg, # MessageLike (BaseMessage)
human_msg, # MessageLike (BaseMessage)
nested_prompt # MessageLike (BaseChatPromptTemplate)
])
prompt.format_messages(role="人工智能专家",user_input="介绍一下大模型的应用场景")类似的:
python
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.prompts import HumanMessagePromptTemplate, SystemMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是一个AI开发工程师. 你的名字是{name}."),
HumanMessage(content=("你能开发哪些AI应用?")),
AIMessage(content=("我能开发很多AI应用,比如聊天机器人、图像识别,自然语言处理等.")),
HumanMessagePromptTemplate.from_template("{input}")
]
)
messages = chat_template.format_messages(input="你能帮我做什么?", name="小谷AI")
print(messages)
4.4.5 结合LLM
举例1:
python
from langchain.prompts.chat import ChatPromptTemplate
#######1、提供提示词#######
chat_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个数学家,你可以计算任何算式"),
("human", "我的问题:{question}"),
])
# 输入提示
messages = chat_prompt.format_messages(question="我今年18岁,我的舅舅今年38岁,我的爷爷今年72岁,我和舅舅一共多少岁?")
#print(messages)
#######2、提供大模型#######
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
#######3、结合提示词,调用大模型#######
# 得到模型的输出
output = chat_model.invoke(messages)
# 打印输出内容
print(output.content)
举例2:
python
from dotenv import load_dotenv
from langchain.prompts.chat import SystemMessagePromptTemplate, HumanMessagePromptTemplate, AIMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
load_dotenv()
llm = ChatOpenAI()
template = ChatPromptTemplate.from_messages(
[
SystemMessagePromptTemplate.from_template("你是{product}的客服助手,你的名字叫{name}"),
HumanMessagePromptTemplate.from_template("hello 你好吗?"),
AIMessagePromptTemplate.from_template("我很好 谢谢!"),
HumanMessagePromptTemplate.from_template("{query}"),
]
)
prompt = template.format_messages(
product="AGI课堂",
name="Bob",
query="你是谁"
)
# 提供聊天模型
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 调用聊天模型
response = chat_model.invoke(prompt)
print(response.content)
4.4.6 插入消息列表:MessagesPlaceholder
当你不确定消息提示模板使用什么角色,或者希望在格式化过程中插入消息列表时,该怎么办? 这就需要使用MessagesPlaceholder,负责在特定位置添加消息列表。
**使用场景:**多轮对话系统存储历史消息以及Agent的中间步骤处理此功能非常有用。
举例1:
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant"),
MessagesPlaceholder("msgs")
])
# prompt_template.invoke({"msgs": [HumanMessage(content="hi")]})
prompt_template.format_messages(msgs=[HumanMessage(content="hi")])
这将生成两条消息,第一条是系统消息,第二条是我们传入的 HumanMessage。 如果我们传入了 5 条消息,那么总共会生成 6 条消息(系统消息加上传入的 5 条消息)。 这对于将一系列消息插入到特定
位置非常有用。
举例2:存储对话历史内容
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage # 补充HumanMessage导入(代码中用到了)
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant."),
MessagesPlaceholder("history"),
("human", "{question}")
]
)
prompt.format_messages(
history=[HumanMessage(content="1+2*3 = ?"), AIMessage(content="1+2*3=7")],
question="我刚才问题是什么?"
)
# prompt.invoke(
# {
# "history": [("human", "what's 5 + 2"), ("ai", "5 + 2 is 7")],
# "question": "now multiply that by 4"
# }
# )举例3:
python
#1.导入相关包
from langchain_core.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate,
MessagesPlaceholder, SystemMessagePromptTemplate) # 补充SystemMessagePromptTemplate导入
from langchain_core.messages import SystemMessage # 补充SystemMessage导入
# 2.定义消息模板
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("你是{role}"),
MessagesPlaceholder(variable_name="intermediate_steps"),
HumanMessagePromptTemplate.from_template("{query}")
])
# 3.定义消息对象 (运行时填充中间步骤的结果)
intermediate = [
SystemMessage(name="search", content="北京: 晴 25℃")
]
# 4.格式化聊天消息提示词模板
prompt.format_messages(
role="天气预报员",
intermediate_steps=intermediate,
query="北京天气怎么样?"
)
举例4:作为拓展,课下看看即可
python
#1.导入相关包
from langchain_core.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate,
MessagesPlaceholder)
from langchain_core.messages import AIMessage, HumanMessage
# 2.定义HumanMessage对象
human_message = HumanMessage(content="学习编程的最好方法是什么?")
# 3.定义AIMessage对象
ai_message = AIMessage(
content="""
1.选择一门编程语言:选择一门你想学习的编程语言。
2.从基础开始:熟悉基本的编程概念,如变量、数据类型和控制结构。
3.练习,练习,再练习:学习编程的最好方法是通过实践经验\
"""
)
# 4.定义提示词
human_prompt = "用{word_count}个词总结我们到目前为止的对话"
# 5.定义提示词模版
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="conversation"),
human_message_template
]
)
# 6.格式化聊天消息提示词模板
messages1 = chat_prompt.format_messages(
conversation=[human_message, ai_message], word_count="10"
)
print(messages1)
4.5 具体使用:少量样本示例的提示词模板
4.5.1 使用说明
在构建prompt时,可以通过构建一个
少量示例列表 去进一步格式化prompt,这是一种简单但强大的指导生成的方式,在某些情况下可以显著提高模型性能 。
少量示例提示模板可以由一组示例 或一个负责从定义的集合中选择一部分示例的示例选择器构建。
● 前者:使用FewShotPromptTemplate 或FewShotChatMessagePromptTemplate
● 后者:使用Example selectors(示例选择器)
每个示例的结构都是一个字典 ,其中键 是输入变量,值是输入变量的值。
体会:zeroshot会导致低质量回答
python
from langchain_openai import ChatOpenAI
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini",
temperature=0.4)
res = chat_model.invoke("2 包 9是多少?")
print(res.content)
4.5.2 FewShotPromptTemplate的使用
举例1:
python
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
# 1、创建示例集合
examples = [
{"input": "北京天气怎么样", "output": "北京市"},
{"input": "南京下雨吗", "output": "南京市"},
{"input": "武汉热吗", "output": "武汉市"}
]
# 2、创建PromptTemplate实例
example_prompt = PromptTemplate.from_template(
template="Input: {input}\nOutput: {output}"
)
# 3、创建FewShotPromptTemplate实例
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="Input: {input}\nOutput:", # 要放在示例后面的提示模板字符串。
input_variables=["input"] # 传入的变量
)
# 4、调用
prompt = prompt.invoke({"input": "长沙多少度"})
print("===Prompt===")
print(prompt)
结合大模型调用:
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 获取大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 调用
print("===Response===")
response = chat_model.invoke(prompt)
print(response.content)
举例2:
python
# 1、创建提示模板
from langchain.prompts import PromptTemplate
# 创建提示模板,配置一个提示模板,将一个示例格式化为字符串
prompt_template = "你是一个数学专家,算式: {input} 值: {output} 使用: {description}"
# 这是一个提示模板,用于设置每个示例的格式
prompt_sample = PromptTemplate.from_template(prompt_template)
# 2、提供示例
examples = [
{"input": "2+2", "output": "4", "description": "加法运算"},
{"input": "5-2", "output": "3", "description": "减法运算"},
]
# 3、创建一个FewShotPromptTemplate对象
from langchain.prompts.few_shot import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=prompt_sample,
suffix="你是一个数学专家,算式: {input} 值: {output}",
input_variables=["input", "output"]
)
print(prompt.invoke({"input": "2*5", "output": "10"}))
# 4、初始化大模型,然后调用
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
result = chat_model.invoke(prompt.invoke({"input": "2*5", "output": "10"}))
print(result.content) # 使用: 乘法运算
4.5.3 FewShotChatMessagePromptTemplate的使用
除了FewShotPromptTemplate之外,FewShotChatMessagePromptTemplate是专门为聊天对话场景 设计的少样本(few-shot)提示模板,它继承自 FewShotPromptTemplate,但针对聊天消息的格式进行了优化。
特点:
● 自动将示例格式化为聊天消息(HumanMessage/AIMessage 等)
● 输出结构化聊天消息(ListBaseMessage )
● 保留对话轮次结构
举例1:基本结构
python
from langchain.prompts import (
FewShotChatMessagePromptTemplate,
ChatPromptTemplate
)
# 1.示例消息格式
examples = [
{"input": "1+1等于几?", "output": "1+1等于2"},
{"input": "法国的首都是?", "output": "巴黎"}
]
# 2.定义示例的消息格式提示词模版
msg_example_prompt = ChatPromptTemplate.from_messages([
("human", "{input}"),
("ai", "{output}"),
])
# 3.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=msg_example_prompt,
examples=examples
)
# 4.输出格式化后的消息
print(few_shot_prompt.format())
举例2:
使用方式:将原始输入和被选中的示例组一起加入Chat提示词模版中。
python
# 1.导入相关包
from langchain_core.prompts import (FewShotChatMessagePromptTemplate,
ChatPromptTemplate)
# 2.定义示例
examples = [
{"input": "2@2", "output": "4"},
{"input": "2@3", "output": "8"},
]
# 3.定义示例的消息格式提示词模板
example_prompt = ChatPromptTemplate.from_messages([
("human", "{input} 是多少?"),
("ai", "{output}")
])
# 4.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples, # 示例
example_prompt=example_prompt # 示例提示词模板
)
# 5.输出完整提示词的消息模板
final_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个数学家"),
few_shot_prompt,
("human", "{input}")
])
# 6.提供大模型
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini",
temperature=0.4)
chat_model.invoke(final_prompt.invoke({"input": "2@4"})).content
举例3:与前面类似
python
# 1.导入相关包
from langchain_core.prompts import (FewShotChatMessagePromptTemplate,
ChatPromptTemplate)
# 2.定义示例组
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
# 3.定义示例的消息格式提示词模板
example_prompt = ChatPromptTemplate.from_messages([("human", "What is {input}?"), ("ai", "{output}")])
# 4.定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples, # 示例组
example_prompt=example_prompt # 示例提示词模板
)
# 5.输出完整提示词的消息模板
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful AI Assistant"),
few_shot_prompt,
("human", "{input}"),
]
)
# 6.格式化完整消息
# final_prompt.format(input="What is 4+4?")
# 或者
final_prompt.format_messages(input="What is 4+4?")
4.5.4 Example selectors(示例选择器)
前面FewShotPromptTemplate的特点是,无论输入什么问题,都会包含全部示例。在实际开发中,我们可以根据当前输入,使用示例选择器,从大量候选示例中选取最相关的示例子集。
使用的好处:避免盲目传递所有示例,减少 token 消耗的同时,还可以提升输出效果。
示例选择策略 :语义相似选择、长度选择、最大边际相关示例选择等
● 语义相似选择:通过余弦相似度等度量方式评估语义相关性,选择与输入问题最相似的 k 个示例。
● 长度选择:根据输入文本的长度,从候选示例中筛选出长度最匹配的示例。增强模型对文本结构的理解。比语义相似度计算更轻量,适合对响应速度要求高的场景。
● 最大边际相关示例选择:优先选择与输入问题语义相似的示例;同时,通过惩罚机制避免返回同质化的内容

举例1:
python
pip install chromadb
python
# 1.导入相关包
from langchain_community.vectorstores import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
import os
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
# 2.定义嵌入模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 3.定义示例组
examples = [
{
"Question": "能帮我、翻译和查看这些是什么意思。",
"Answer": """
接下来要提问什么类型题?
提问:能帮我翻译和查看这些是什么意思。
中译英:能帮我翻译和查看这些是什么意思。
"""
},
{
"Question": "cragin的地址(要分出街道地址的)",
"Answer": """
接下来要提问什么类型题?
提问:cragin的地址(要分出街道地址的)
中译英:Cragin的地址(要分出街道地址的)
"""
},
{
"Question": "能推荐你所知道的运动?",
"Answer": """
接下来要提问什么类型题?
提问:能推荐你所知道的运动?
中译英:能推荐你所知道的运动吗?
"""
},
{
"Question": "《太白阴》和《虎钤经》这两本书用同一个翻译吗?",
"Answer": """
接下来要提问什么类型题?
提问:《太白阴》和《虎钤经》这两本书用同一个翻译吗?
中译英:《太白阴》和《虎钤经》这两本书用同一个翻译吗?
"""
}
]
# 4.定义示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 要进行相似性的列表
embeddings_model, # 用于测量语义相似性
Chroma, # 要用于存储嵌入并进行相似性搜索的 VectorStore 类
k=1 # 要生成的示例数量
)
# 5.选择与输入最相似的示例
question = "可预约本学期的交换项目"
selected_example = example_selector.select_examples({"question": question})
print(f"选择的示例: {selected_example}")
for i, example in enumerate(selected_example):
for k, v in example.items():
print(f"{k}: {v}")
举例2:结合 FewShotPromptTemplate 使用
这里使用FAISS,需安装:
python
pip install faiss-cpu
# 或
conda install faiss-cpu
python
# 1.导入相关包
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
# 2.定义示例的提示模板
example_prompt = PromptTemplate.from_template(
template="Input:{input}\nOutput:{output}",
)
# 3.创建一个示例的问题列表
examples = [
{"input": "高兴", "output": "悲伤"},
{"input": "高", "output": "矮"},
{"input": "强力的", "output": "无力的"},
{"input": "充实", "output": "空虚"},
{"input": "光明", "output": "阴暗"},
{"input": "温暖", "output": "寒冷"},
{"input": "富裕", "output": "贫穷"},
]
# 4.定义嵌入模型
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 5.创建语义相似性示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=2
)
# 或者
# example_selector = SemanticSimilarityExampleSelector(
# examples,
# embeddings,
# FAISS,
# k=2
# )
# 6.定义语义样本提示模板
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Input:{word}\nOutput:",
input_variables=["word"],
)
response = similar_prompt.invoke({"word": "饱满"})
print(response.text)
4.6 具体使用:PipelinePromptTemplate(了解)
用于将多个提示模板按顺序组合成处理管道 ,实现分阶段、模块化的提示构建。它的核心作用类似于软件开发中的管道模式(Pipeline Pattern),通过串联多个提示处理步骤,实现复杂的提示生成逻辑。
特点:
● 将复杂提示拆解为多个处理阶段,每个阶段使用独立的提示模板
● 前一个模板的输出作为下一个模板的输入变量
● 使用场景:解决单一超大提示模板难以维护的问题
说明 :PipelinePromptTemplate在langchain 0.3.22版本中被标记为过时,在 langchain-core==1.0
之前不会删除它。
举例:
python
from langchain_core.prompts.pipeline import PipelinePromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
# 阶段1:问题分析
analysis_template = PromptTemplate.from_template("""
分析这个问题:{question}
关键要素:
""")
# 阶段2:知识检索
retrieval_template = PromptTemplate.from_template("""
基于以下要素搜索资料:
{analysis_result}
搜索关键词:
""")
# 阶段3:生成最终回答
answer_template = PromptTemplate.from_template("""
综合以下信息回答问题:
{retrieval_result}
最终答案:
""")
# 构建管道
pipeline = PipelinePromptTemplate(
final_prompt=answer_template,
pipeline_prompts=[
("analysis_result", analysis_template),
("retrieval_result", retrieval_template)
]
)
print(pipeline.format(question="量子计算的优势是什么?"))
上述代码执行时,提示PipelinePromptTemplate已过时,代码更新如下:
python
from langchain_core.prompts.prompt import PromptTemplate
# 阶段1:问题分析
analysis_template = PromptTemplate.from_template("""
分析这个问题: {question}
关键要素:
""")
# 阶段2:知识检索
retrieval_template = PromptTemplate.from_template("""
基于以下要素搜索资料:
{analysis_result}
搜索关键词:
""")
# 阶段3:生成最终回答
answer_template = PromptTemplate.from_template("""
综合以下信息回答问题:
{retrieval_result}
最终答案:
""")
# 逐步执行管道提示
pipeline_prompts = [
("analysis_result", analysis_template),
("retrieval_result", retrieval_template)
]
my_input = {"question": "量子计算的优势是什么?"}
print(pipeline_prompts)
# [('analysis_result', PromptTemplate(input_variables=['question'], input_types={}, partial_variables={}, template='\n分析这个问题: {question}\n关键要素:\n')), ('retrieval_result', PromptTemplate(input_variables=['analysis_result'], input_types={}, partial_variables={}, template='\n基于以下要素搜索资料:\n{analysis_result}\n搜索关键词:\n'))]
for name, prompt in pipeline_prompts:
# 调用当前提示模板获取执行结果
result = prompt.invoke(my_input).to_string()
# 将结果存入字典供下一步使用
my_input[name] = result
# 生成最终答案
my_output = answer_template.invoke(my_input).to_string()
print(my_output)4.7 具体使用:自定义提示词模版(了解)
在创建prompt时,我们也可以按照自己的需求去创建自定义的提示模版。
步骤:
● 自定义类继承提示词基类模版BasePromptTemplate
● 重写format、format_prompt、from_template方法
举例:
python
# 1.导入相关包
from typing import List, Dict, Any
from langchain.prompts import BasePromptTemplate
from langchain.prompts import PromptTemplate
from langchain.schema import PromptValue
# 2.自定义提示词模板
class SimpleCustomPromptTemplate(BasePromptTemplate):
"""简单自定义提示词模板"""
template: str
def __init__(self, template: str, **kwargs):
# 使用PromptTemplate解析输入变量
prompt = PromptTemplate.from_template(template)
super().__init__(
input_variables=prompt.input_variables,
template=template,
**kwargs
)
def format(self, **kwargs: Any) -> str:
"""格式化提示词"""
# print("kwargs: ", kwargs)
# print("self.template: ", self.template)
return self.template.format(**kwargs)
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""实现抽象方法"""
return PromptValue(text=self.format(**kwargs))
@classmethod
def from_template(cls, template: str, **kwargs) -> "SimpleCustomPromptTemplate":
"""从模板创建实例"""
return cls(template=template, **kwargs)
# 3.使用自定义提示词模板
custom_prompt = SimpleCustomPromptTemplate.from_template(
template="请回答关于{subect}的问题:{question}"
)
# 4.格式化提示词
formatted = custom_prompt.format(
subject="人工智能",
question="什么是LLM?"
)
print(formatted)
4.8 从文档中加载Prompt(了解)
一方面,将想要设定prompt所支持的格式保存为JSON或者YAML格式文件。
另一方面,通过读取指定路径的格式化文件,获取相应的prompt。
目的与使用场景:
● 为了便于共享、存储和加强对prompt的版本控制。
● 当我们的prompt模板数据较大时,我们可以使用外部导入的方式进行管理和维护。
4.8.1 yaml格式提示词
asset下创建yaml文件:prompt.yaml
python
_type:
"prompt"
input_variables:
["name","what"]
template:
"请给{name}讲一个关于{what}的故事"代码:
python
from langchain_core.prompts import load_prompt
from dotenv import load_dotenv
load_dotenv()
prompt = load_prompt("asset/prompt.yaml", encoding="utf-8")
# print(prompt)
print(prompt.format(name="年轻人", what="滑稽"))
4.8.2 json格式提示词
asset下创建json文件:prompt.json
python
{
"_type": "prompt",
"input_variables": ["name", "what"],
"template": "请给{name}讲一个{what}的故事。"
}代码:
python
from langchain_core.prompts import load_prompt
from dotenv import load_dotenv
load_dotenv()
prompt = load_prompt("asset/prompt.json", encoding="utf-8")
print(prompt.format(name="张三", what="搞笑的"))
5、Model I/O之Output Parsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望model可以返回更直观、更格式化的内容 ,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的输出解析器就派上用场了。
输出解析器(Output Parser)负责获取 LLM 的输出并将其转换为更合适的格式。这在应用开发中及其重要。
5.1 输出解析器的分类
LangChain有许多不同类型的输出解析器
● StrOutputParser :字符串解析器
● JsonOutputParser :JSON解析器,确保输出符合特定JSON对象格式
● XMLOutputParser :XML解析器,允许以流行的XML格式从LLM获取结果
● CommaSeparatedListOutputParser :CSV解析器,模型的输出以逗号分隔,以列表形式返回输出
● DatetimeOutputParser :日期时间解析器,可用于将 LLM 输出解析为日期时间格式
除了上述常用的输出解析器之外,还有:
● EnumOutputParser :枚举解析器,将LLM的输出,解析为预定义的枚举值
● StructuredOutputParser :将非结构化文本转换为预定义格式的结构化数据(如字典)
● OutputFixingParser :输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合预期格式的输出,尝试修正为正确的结构化数据(如 JSON)
● RetryOutputParser :重试解析器,当主解析器(如 JSONOutputParser)因格式错误无法解析 LLM 的输出时,通过调用另一个 LLM 自动修正错误,并重新尝试解析
5.2 具体解析器的使用
①字符串解析器 StrOutputParser
StrOutputParser 简单地将任何输入 转换为字符串。它是一个简单的解析器,从结果中提取content字段
举例:将一个对话模型的输出结果,解析为字符串输出
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="将以下内容从英语翻译成中文"),
HumanMessage(content="It's a nice day today"),
]
result = chat_model.invoke(messages)
print(type(result))
print(result)
parser = StrOutputParser()
# 使用parser处理model返回的结果
response = parser.invoke(result)
print(type(response))
print(response)
②JSON解析器 JsonOutputParser
JsonOutputParser,即JSON输出解析器,是一种用于将大模型的自由文本输出转换为结构化JSON数
据的工具。
**适合场景:**特别适用于需要严格结构化输出的场景,比如 API 调用、数据存储或下游任务处理。
实现方式
● 方式1:用户自己通过提示词指明返回Json格式
● 方式2:借助JsonOutputParser的get_format_instructions(),生成格式说明,指导模型输出 JSON 结构
举例1:
python
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个靠谱的{role}"),
("human", "{question}")
])
parser = JsonOutputParser()
# 方式1:
result = chat_model.invoke(chat_prompt_template.format_messages(
role="人工智能专家",
question="人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"
))
print(result)
print(type(result))
parser.invoke(result)
# 方式2:
# chain = chat_prompt_template | chat_model | parser
# chain.invoke({
# "role": "人工智能专家",
# "question": "人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"
# })
举例2:使用指定的JSON格式
python
from langchain_core.output_parsers import JsonOutputParser
output_parser = JsonOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)基于此:
python
# 引入依赖包
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
joke_query = "告诉我一个笑话。"
# 定义Json解析器
parser = JsonOutputParser()
# 定义提示词模板
# 注意,提示词模板中需要部分格式化解析器的格式要求format_instructions
prompt = PromptTemplate(
template="回答用户的查询:\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 5.使用LCEL语法组合一个简单的链
chain = prompt | chat_model | parser
# 6.执行链
output = chain.invoke({"query": "给我讲一个笑话!"})
print(output)
③ XML解析器 XMLOutputParser
XMLOutputParser,将模型的自由文本输出转换为可编程处理的 XML 数据。
如何实现:在 PromptTemplate 中指定 XML 格式要求,让模型返回content 形式的数据。
注意 :XMLOutputParser 不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成Python字典(或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格式。
举例1:不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
python
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 测试模型的xml解析效果
actor_query = "生成汤姆·汉克斯的简短电影记录"
output = chat_model.invoke(f"{actor_query}请将影片附在<movie></movie>标签中")
print(type(output)) # <class 'langchain_core.messages.ai.AIMessage'>
print(output.content)
xml
以下是汤姆·汉克斯的一些著名电影记录,使用了<movie></movie>标签:
<movie>
<title>大白鲨</title>
<year>1975</year>
<description>汤姆·汉克斯并未参演该片,但它代表了他所崇拜的斯皮尔伯格和恐怖电影。</description>
</movie>
<movie>
<title>费城故事</title>
<year>1993</year>
<description>汉克斯在片中饰演一名因患艾滋病而遭受歧视的律师,展现了强大的表演能力。</description>
</movie>
<movie>
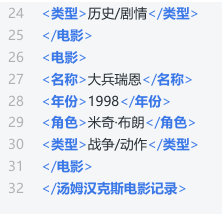
<title>拯救大兵瑞恩</title>
<year>1998</year>
<description>汤姆·汉克斯在这部二战电影中饰演一位军官,领导小队寻找失踪士兵,表现出勇气与人性。</description>
</movie>
<movie>
<title>阿甘正传</title>
<year>1994</year>
<description>汉克斯饰演智力有缺陷的阿甘,凭借其纯真和毅力走过了动荡的历史,成为经典角色。</description>
</movie>
<movie>
<title>云图</title>
<year>2012</year>
<description>这部电影展示了不同历史时期的人物,汉克斯在其中扮演多个角色,体现了人与时间的关系。</description>
</movie>
<movie>
<title>大地惊雷</title>
<year>2000</year>
<description>汉克斯在这部影片中担任制片人和主演,讲述了关于希望与重生的动人故事。</description>
</movie>
<movie>
<title>匹诺曹</title>
<year>2022</year>
<description>虽然汉克斯并没有在片中出演,但作为制片人,他对反主流的题材作出贡献。</description>
</movie>
这些电影展示了汤姆·汉克斯在不同时期所做出的多样化和深刻的艺术贡献。举例2:体会XMLOutputParser的格式
python
from langchain_core.output_parsers import XMLOutputParser
output_parser = XMLOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
举例3:XMLOutputParser 的使用
python
# 1.导入相关包
from langchain_core.output_parsers import XMLOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# 2. 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 3.测试模型的xml解析效果
actor_query = "生成汤姆·汉克斯的简短电影记录,使用中文回复"
# 4.定义XMLOutputParser对象
parser = XMLOutputParser()
# 5.定义提示词模板对象
# prompt = PromptTemplate(
# template="{query}\n{format_instructions}",
# input_variables=["query", "format_instructions"],
# partial_variables={"format_instructions": parser.get_format_instructions()},
# )
prompt_template = PromptTemplate.from_template("{query}\n{format_instructions}")
prompt_template1 = prompt_template.partial(format_instructions=parser.get_format_instructions())
response = chat_model.invoke(prompt_template1.format(query=actor_query))
print(response.content)
继续:
python
# 方式1
response = chat_model.invoke(prompt_template1.format(query=actor_query))
result = parser.invoke(response)
print(result)
print(type(result))
# 方式2
# chain = prompt_template1 | chat_model | parser
# result = chain.invoke({"query": actor_query})
# print(result)
# print(type(result))
举例4:与前例类似
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import XMLOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
actor_query = "生成周星驰的简化电影作品列表,按照最新的时间降序,必要时使用中文"
# 设置解析器 + 将指令注入提示模板。
parser = XMLOutputParser()
prompt = PromptTemplate(
template="回答用户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
output = chain.invoke({"query": actor_query})
print(output)
④列表解析器 CommaSeparatedListOutputParser(了解)
列表解析器:利用此解析器可以将模型的文本响应转换为一个用 逗号分隔的列表(Liststr)
举例1:
python
from langchain_core.output_parsers import CommaSeparatedListOutputParser
output_parser = CommaSeparatedListOutputParser()
# 返回一些指令或模板,这些指令告诉系统如何解析或格式化输出数据
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
messages = "大象,猩猩,狮子"
result = output_parser.parse(messages)
print(result)
print(type(result))
举例2:
python
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 创建解析器
output_parser = CommaSeparatedListOutputParser()
# 创建LangChain提示模板
chat_prompt = PromptTemplate.from_template(
"生成5个关于{text}的列表。\n\n{format_instructions}",
partial_variables={
"format_instructions": output_parser.get_format_instructions()
}
)
# 提示模板与输出解析器传递输出
# chat_prompt = chat_prompt.partial(format_instructions=output_parser.get_format_instructions())
# 将提示和模型合并以进行调用
chain = chat_prompt | chat_model | output_parser
res = chain.invoke({"text": "电影"})
print(res)
print(type(res))
举例3:
python
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
# 初始化语言模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
output_parser = CommaSeparatedListOutputParser()
chat_prompt = ChatPromptTemplate.from_messages([
("human", "{request}\n{format_instructions}"),
# HumanMessagePromptTemplate.from_template("{request}\n{format_instructions}"),
])
# model_request = chat_prompt.format_messages(
# request="给我5个心情",
# format_instructions=output_parser.get_format_instructions()
# )
# 方式1:
# result = chat_model.invoke(model_request)
# resp = output_parser.parse(result.content)
# print(resp)
# print(type(resp))
# 方式2:
# result = chat_model.invoke(model_request)
# resp = output_parser.invoke(result)
# print(resp)
# print(type(resp))
# 方式3:
chain = chat_prompt | chat_model | output_parser
resp = chain.invoke({
"request": "给我5个心情",
"format_instructions": output_parser.get_format_instructions()
})
print(resp)
print(type(resp))
⑤日期解析器 DatetimeOutputParser (了解)
利用此解析器可以直接将LLM输出解析为日期时间格式。
● get_format_instructions(): 获取日期解析的格式化指令,指令为:"Write a datetime string that matches the following pattern: '%Y-%m-%dT%H:%M:%S.%fZ'。
● 举例:1206-08-16T17:39:06.176399Z
举例1:
python
from langchain.output_parsers import DatetimeOutputParser
output_parser = DatetimeOutputParser()
format_instructions = output_parser.get_format_instructions()
print(format_instructions)
举例2:
python
from langchain_openai import ChatOpenAI
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import DatetimeOutputParser
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt = ChatPromptTemplate.from_messages([
("system", "{format_instructions}"),
("human", "{request}")
])
output_parser = DatetimeOutputParser()
# 方式1:
# model_request = chat_prompt.format_messages(
# request="中华人民共和国是什么时候成立的",
# format_instructions=output_parser.get_format_instructions()
# )
# response = chat_model.invoke(model_request)
# result = output_parser.invoke(response)
# print(result)
# print(type(result))
# 方式2:
chain = chat_prompt | chat_model | output_parser
resp = chain.invoke({
"request": "中华人民共和国是什么时候成立的",
"format_instructions": output_parser.get_format_instructions()
})
print(resp)
print(type(resp))6、LangChain调用本地模型
Ollama的介绍和安装参考之前写的帖子。
总结
LangChain学习的第一部分Model I/O,记得关注么么哒