论文题目:面向视觉语言模型组合性理解的可视分析方法
期刊:计算机辅助设计与图形学学报
摘要:视觉语言预训练模型在众多基准测试中展现出了强大的跨模态理解能力, 但其"组合性理解"能力仍有待探 究. 针对来自计算机视觉领域的研究往往侧重于量化指标和模型架构, 缺乏动态探索跨模态对齐能力的有效手段的 问题, 提出交互式分析方法, 从可视化视角出发, 阐释视觉语言模型专注于独立实体元素的具体模式. 首先通过优化 传统网格布局, 增强对大规模数据集上模型跨模态对齐能力的视觉感知; 然后解释多头注意力机制在执行跨模态语 义理解的具体反应. 用户评估结果表明, 90%的参与者表示, 与仅依赖数据指标的方法相比, 本文提供了一种更新颖 且有效的方式, 有助于探究视觉语言模型中的模态隔离现象.
揭开视觉语言模型的"组合性理解"之谜:CouLens可视分析方法详解
本文详细介绍《面向视觉语言模型组合性理解的可视分析方法》这篇论文,探讨CLIP等视觉语言模型在组合性理解方面的局限性,以及如何通过可视分析方法进行深入探索。
引言:当AI看不懂"飞盘咬狗"
想象这样一个场景:你给AI展示一张狗咬飞盘的照片,并提供两个描述------"狗在咬飞盘"和"飞盘在咬狗"。作为人类,我们会毫不犹豫地选择前者,因为后者在物理和逻辑上都是荒谬的。然而,当前最先进的视觉语言模型CLIP却可能给出令人惊讶的答案:它认为"飞盘在咬狗"的匹配概率高达77.7%!
这个看似荒诞的例子揭示了一个深刻的问题:视觉语言模型在"组合性理解"方面存在严重缺陷 。浙江工业大学李童等研究者在最新论文中,提出了名为CouLens的可视分析方法,帮助我们深入理解这一现象。
什么是"组合性理解"?
在视觉语言模型的语境下,"组合性理解"指的是模型同时处理图像和文本的能力,具体包括:
- 识别文本中的单词:如"男人"、"红色"、"消防栓"
- 检测图像中的视觉元素:对应的人物、颜色、物体
- 理解模态间元素的关联:谁穿着什么、谁在哪里
- 把握共同作用机制:整个场景的语义理解
例如,对于描述"穿着白色衬衫的男人倚靠在红色消防栓旁",模型不仅需要识别各个实体,还需要理解"穿着"这个动作关系以及"白色"与"衬衫"的属性绑定。
问题的严重性
论文通过大规模实验揭示了一个令人担忧的事实:
| 数据集 | 积极匹配率 | 消极匹配率 | 边界匹配率 |
|---|---|---|---|
| ARO-R (关系扰乱) | 41.73% | 39.44% | 18.83% |
| ColPer (颜色扰乱) | 36.60% | 41.20% | 22.20% |
| CntPer (数量扰乱) | 39.20% | 38.90% | 21.90% |
| MatPer (材料扰乱) | 38.63% | 40.20% | 21.17% |
| 平均 | 39.04% | 39.93% | 21.03% |
数据显示,CLIP的积极匹配率(正确选择基准描述)平均仅为39%,甚至低于消极匹配率。这意味着模型几乎是在"随机猜测"!
更具体的失败案例包括:
- "盘子在桌子上" vs "桌子在盘子上" → 模型选择后者的概率更高
- "栅栏在长颈鹿后面" vs "长颈鹿在栅栏后面" → 模型困惑
- "站着的女人和蹲着的男人" vs "蹲着的女人和站着的男人" → 模型无法区分
CouLens:可视分析的解决方案
系统架构
CouLens的工作流程分为四个核心模块:
扰乱数据集 → CLIP图文匹配 → SemGrid拓扑优化 → 交互式可视分析
↓
BFS子域识别
↓
注意力梯度分析核心创新一:SemGrid语义网格算法
传统的网格布局算法(如SOM、RC-SOM)虽然能够保持数据的拓扑结构,但缺乏"集群意识"------无法有效聚合语义相似的样本。
SemGrid算法的创新在于引入了双重目标函数:
目标函数 = (1-λ)·‖特征距离‖ + λ·KL散度(匹配分布)其中λ参数平衡了两个因素:
- 特征距离:保持高维嵌入的邻近关系
- 匹配分布:聚合相同匹配结果的样本
实验证明,与SOM和RC-SOM相比,SemGrid的边界熵分别下降了17.5%和26.9%,呈现出更清晰的语义簇。
核心创新二:BFS子域识别
为了帮助用户快速定位具有相似语义模式的样本集合,CouLens采用广度优先搜索(BFS)算法:
- 将网格视为隐式图,单元格为节点
- 按正交方向递归搜索
- 将空间邻近且匹配类别相同的单元格归为子区域
- 通过分层采样筛选代表性子集
核心创新三:注意力梯度可视化
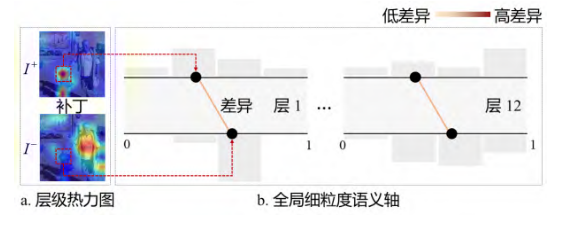
这是CouLens最具洞察力的部分。通过反向传播累积CLIP 12层注意力梯度,研究者设计了两种可视化形式:
热力图映射:将注意力分布直接叠加到原始图像和文本上
- 暖色区域 = 高注意力
- 深色文本 = 高关注度
语义轴设计:借鉴平行坐标系,展示各层注意力差异
- 上轴 = 基准语义下的补丁/令牌
- 下轴 = 扰动语义下的补丁/令牌
- 线条颜色 = 注意力差值大小
关键发现:CLIP的"Bag-of-Objects"倾向
通过CouLens的深入分析,研究者发现了CLIP的一个核心问题:它更像是在做"词袋模型"而非真正的语义理解。
发现一:对扰动不敏感
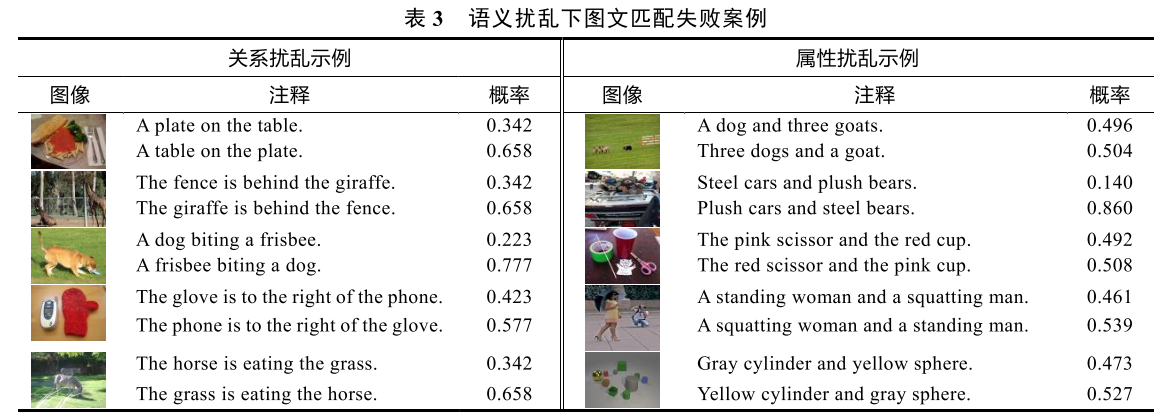
无论基准注释还是扰乱注释,CLIP的注意力分布几乎一致。例如:
- 输入"yellow cylinder and green sphere"
- 输入"green cylinder and yellow sphere"(扰乱版本)
CLIP在图像端的注意力分布几乎没有变化!这说明模型无法真正"理解"颜色与物体的绑定关系。
发现二:实体优先于关系
在文本端,CLIP明显倾向于对实体单词(如"drinks"、"airplane")分配更强的注意力,而忽视关系词(如"on"、"behind"、"wearing")。
发现三:注意力前期差异逐渐消失
通过语义轴的观察发现,在注意力机制的前期(第0-6层),基准和扰乱条件下存在轻微差异;但到了后期(第7-11层),这种差异几乎完全消失。
这意味着CLIP在最终决策时,已经"遗忘"了语义扰动带来的差异。
用户评估:90%的参与者认可
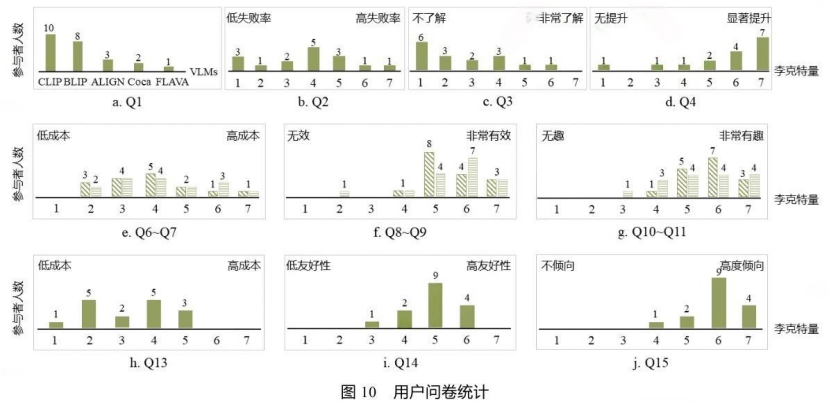
论文招募了16名参与者进行用户评估,他们来自跨模态学习、计算机视觉、自然语言处理和可视分析等相关领域。
令人惊讶的发现:近70%的参与者此前对VLMs的组合性理解缺陷并不了解!尽管他们在研究中广泛使用CLIP等模型。
积极反馈:
- 90%认为CouLens有效促进了对组合性理解缺陷的探索
- 62.5%表示热力图可视化非常直观
- 大多数认为界面设计简约、易于上手
改进建议:
- 增加批量概览功能
- 优化大规模数据处理的响应速度
- 探索其他可解释性方法
实践意义与未来展望
对研究者的启示
-
不要过度信任VLMs的跨模态能力:即使是CLIP这样的明星模型,在细粒度组合理解上也存在严重局限
-
需要更精细的评估方法:传统的准确率指标无法揭示模型的深层问题
-
可视分析是理解黑箱模型的有力工具:CouLens展示了可视化在AI可解释性研究中的价值
改进VLMs的方向
论文参与者提出了多项建议:
- 引入强化学习和反馈机制:使模型在逐步学习中自我优化
- 增强多模态交互:设计跨模态注意力机制或协同训练方法
- 自监督学习技术:增强细粒度特征对齐
- 人工引导:设计特定损失函数惩罚模态差距带来的偏差
未来研究方向
论文作者计划:
- 探究其他主流VLMs在CouLens上的适用性
- 系统评估VLMs对视觉模态扰动的敏感性
- 设计局部探索视图,提高批量样本分析效率
结语
CouLens这项工作具有重要的学术价值和实践意义。它不仅揭示了当前视觉语言模型的一个重要盲区,更提供了一套系统的可视分析方法论。
在AI大模型快速发展的今天,我们往往被模型在基准测试上的高分所迷惑,而忽视了它们在真实场景中可能存在的根本性缺陷。CouLens提醒我们:真正的智能不仅仅是识别"词袋"中的元素,更在于理解元素之间的组合关系。
正如一位参与评估的研究者所言:"CLIP似乎假设图像和文本之间存在简单的映射关系,但实际上,图像和文本之间的细粒度关系往往非常复杂。"
这或许也是当前所有AI系统面临的共同挑战:从"感知"走向真正的"理解"。