2025年12月11日
Augment Code Review在唯一的AI辅助代码审查公共基准测试中取得了最高的准确度,在整体质量上比Cursor Bugbot、CodeRabbit等其他系统高出约10个百分点。一个关键原因是什么?我们选择GPT-5.2作为代码审查的基础模型------以及我们的模型无关方法让我们能够为软件开发生命周期的每个阶段选择最佳工具。Augment Code Review最初基于GPT-5构建,但随着我们观察到OpenAI最新推理模型的质量提升,我们升级到了5.2版本。

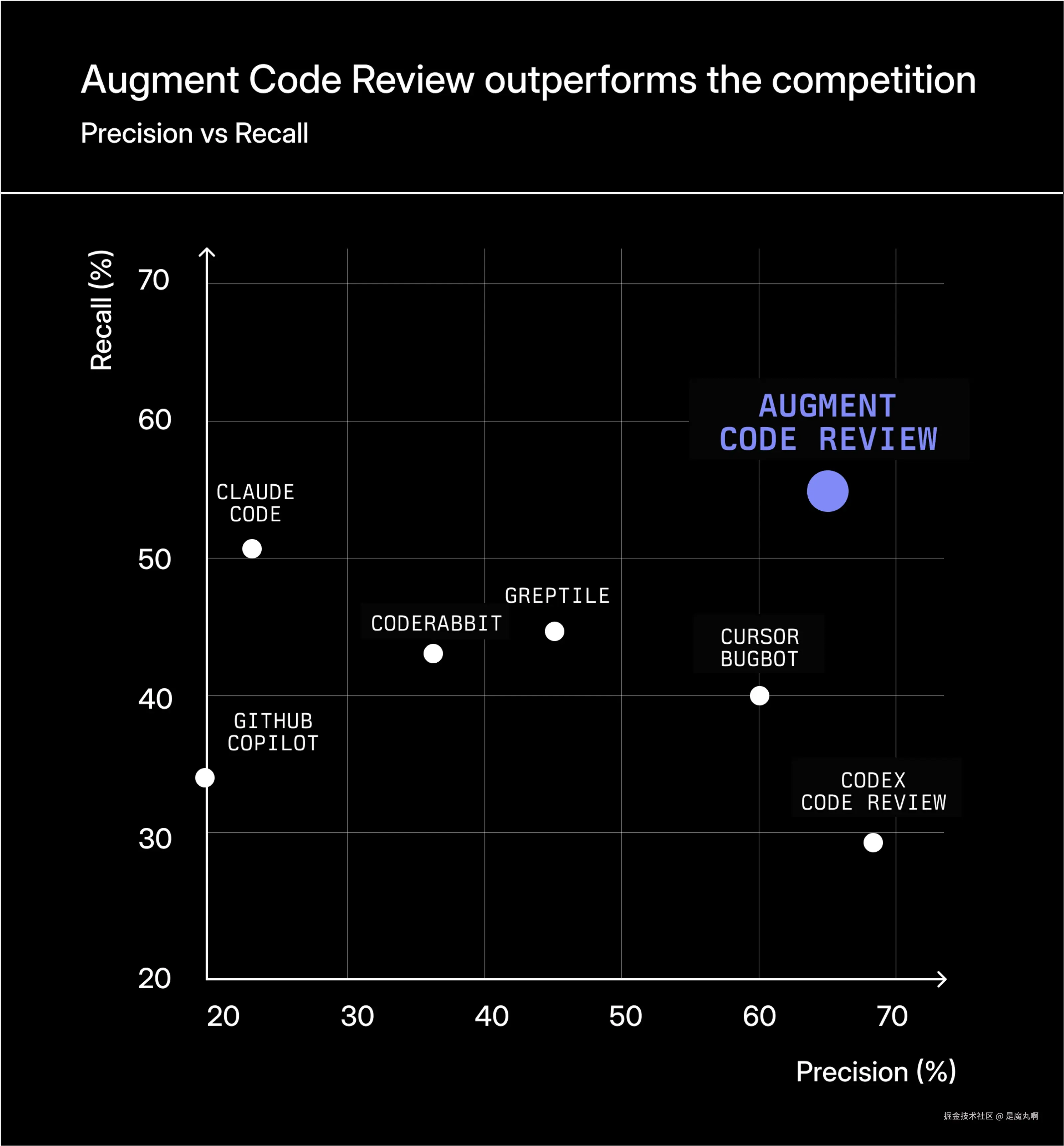
什么造就了一个出色的代码审查模型?
代码审查与交互式编码有着根本不同的要求。有三个主要因素使一个模型在代码审查方面表现出色:
首先,原始推理能力。 给定一段代码,模型能否深入推理其正确性,识别细微的bug,并理解架构影响?
其次,在agent harness中有效的工具使用。 最佳的代码审查需要全面的上下文:依赖链、调用站点、类型定义、测试文件和历史变更。一个出色的审查模型需要做出正确的工具调用来收集所有相关信息,而不仅仅是孤立地检查差异。
第三,强大的指令遵循能力以平衡precision和recall。 我们仔细调优了prompts中的每一句话,以捕获正确的问题集,并在precision和recall之间做出正确的权衡。模型需要忠实地遵循这些细致的指令,捕获真正的bug,同时避免低信噪比的干扰。
为什么GPT-5.2在代码审查方面表现出色
GPT-5.2在所有三个要求上都表现出色。它在进行彻底的工具调用来拉取全面上下文方面表现出色。它比针对交互速度优化的模型花费更多时间并进行更多推理,但这正是我们在异步代码审查中想要的------在那里正确性比延迟更重要。
这种深思熟虑、推理充分的方法与Augment的Context Engine完美配合。GPT-5.2持续检索评估大型、长期代码库中正确性所需的正确依赖项、调用站点和跨文件关系。它能捕获需要深度推理的那类跨系统问题和架构问题:那些真正导致事故的bug。
为什么在代码审查中选择GPT-5.2而不是Sonnet
我们广泛评估了GPT和Anthropic的Sonnet模型系列用于代码审查。虽然Sonnet模型在交互式用例方面表现出色,以更低的延迟提供快速、高质量的响应,但GPT-5.2在我们的异步代码审查工作负载中被证明更优秀。
关键差异归结为优化目标。Sonnet模型针对交互式场景进行了优化:快速迭代、对话流程和快速反馈循环。当开发者在等待响应时,它们表现出色。但代码审查根本不同。它是异步的,不需要立即响应,并受益于更深、更详尽的推理。
GPT-5.2花费更多时间并做出更多工具调用,但产生更充分推理的分析。对于代码审查来说,这种权衡是完全正确的。我们宁愿等待额外的30秒来捕获一个微妙的并发bug,也不愿得到一个快速但肤浅的审查,错过跨系统问题。
这不是对模型质量的判断。两个系列在它们优化的领域都表现卓越。这是关于将正确的模型匹配到正确的用例。在我们IDE中的交互式编码中,Sonnet的速度优势很重要。对于代码审查,GPT-5.2的深思熟虑的推理获胜。
Augment的优势:设计上模型无关
Augment的核心优势之一是我们是模型无关的。
随着模型的不断发展,我们可以为每个特定工作采用最佳工具。这种务实的、用例驱动的方法是我们如何保持基准领先的性能,同时为开发人员在开发的每个阶段提供最佳体验。
鉴于GPT-5.2在代码审查中的强劲表现,我们的团队目前正在评估是否在模型选择器中为通用代码生成用例提供它。该模型详尽的推理方法需要针对交互式工作流程进行一些额外的调优,但我们正在探索如何将其能力带到开发生命周期的更多部分。
准备看到GPT-5.2驱动的代码审查实际运行了吗? Augment Code Review现已为所有Augment Code用户可用。了解更多 →或阅读完整的基准测试分析 →

Akshay Utture
Akshay Utture构建智能agents,使软件开发更快、更安全、更可靠。在Augment Code,他领导公司AI Code Review agent背后的工程工作,将研究级程序分析和现代GenAI技术结合起来,自动化SDLC中最耗时的部分之一。在加入Augment之前,Akshay在Uber花费了几年时间推进自动代码审查和修复系统,并在AWS的Automated Reasoning Group、Google的Android Static Analysis团队和UCLA进行研究。他的工作处于AI、软件工程和编程语言理论的交叉点。
提升你的编码能力
修复bug、编写测试、更快交付