2025年12月11日
TL;DR
我们在唯一的 AI 辅助代码审查公共基准测试上评估了七个最广泛使用的 AI 代码审查工具。Augment Code Review,由 GPT-5.2 驱动,以显著优势交付了最强的性能。它的审查既具有更高的精确度,又具有大幅更高的召回率,这得益于其独特强大的 Context Engine,能够持续检索正确的文件、依赖项和调用站点。虽然许多工具由于有限的上下文而产生嘈杂的评论或遗漏关键问题,但 Augment 作为唯一能够可靠地在整个代码库中进行推理并发现人类审查者真正关心的问题的系统而脱颖而出。简而言之:如果你想要感觉像高级工程师而不是 lint 机器人的 AI 审查,Augment Code Review 是明显的领导者,并且今天对所有 Augment Code 客户普遍可用。
真正的测试:捕获错误而不制造噪音
AI 代码审查工具被营销为快速、准确和上下文感知的。但开发人员知道真正的测试是这些系统是否能够在 PR 中捕获有意义的问题而不会被噪音淹没。为了了解这些工具在实践中如何表现,我们使用唯一的 AI 代码审查公共数据集评估了七个领先的 AI 审查系统。结果清楚地表明,虽然许多工具在嘈杂或不完整的分析方面挣扎,但一个工具------Augment Code Review------明显优于其他工具。
代码审查质量如何衡量
如果审查评论与黄金评论 匹配,则被认为是正确的:即一个合格的人类审查者预期会捕获的基础事实问题。黄金评论反映的是真实正确性或架构问题,而不是风格上的吹毛求疵。
每个工具的评论被标记为:
- 真阳性: 匹配黄金评论
- 假阳性: 不正确或无关的评论
- 假阴性: 工具遗漏的黄金评论
从这些分类中我们计算:
- 精确度: 工具的可信度
- 召回率: 工具的全面性
- F-score: 整体质量
高精确度保持开发人员的参与度;高召回率是使工具真正有用的原因。只有具有强大上下文检索能力的系统才能同时实现两者。
基准测试结果
以下是结果,按 F-score 排序------整体审查质量的最佳单一衡量标准:
| 工具 | 精确度 | 召回率 | F-score |
|---|---|---|---|
| Augment Code Review | 65% | 55% | 59% |
| Cursor Bugbot | 60% | 41% | 49% |
| Greptile | 45% | 45% | 45% |
| Codex Code Review | 68% | 29% | 41% |
| CodeRabbit | 36% | 43% | 39% |
| Claude Code | 23% | 51% | 31% |
| GitHub Copilot | 20% | 34% | 25% |
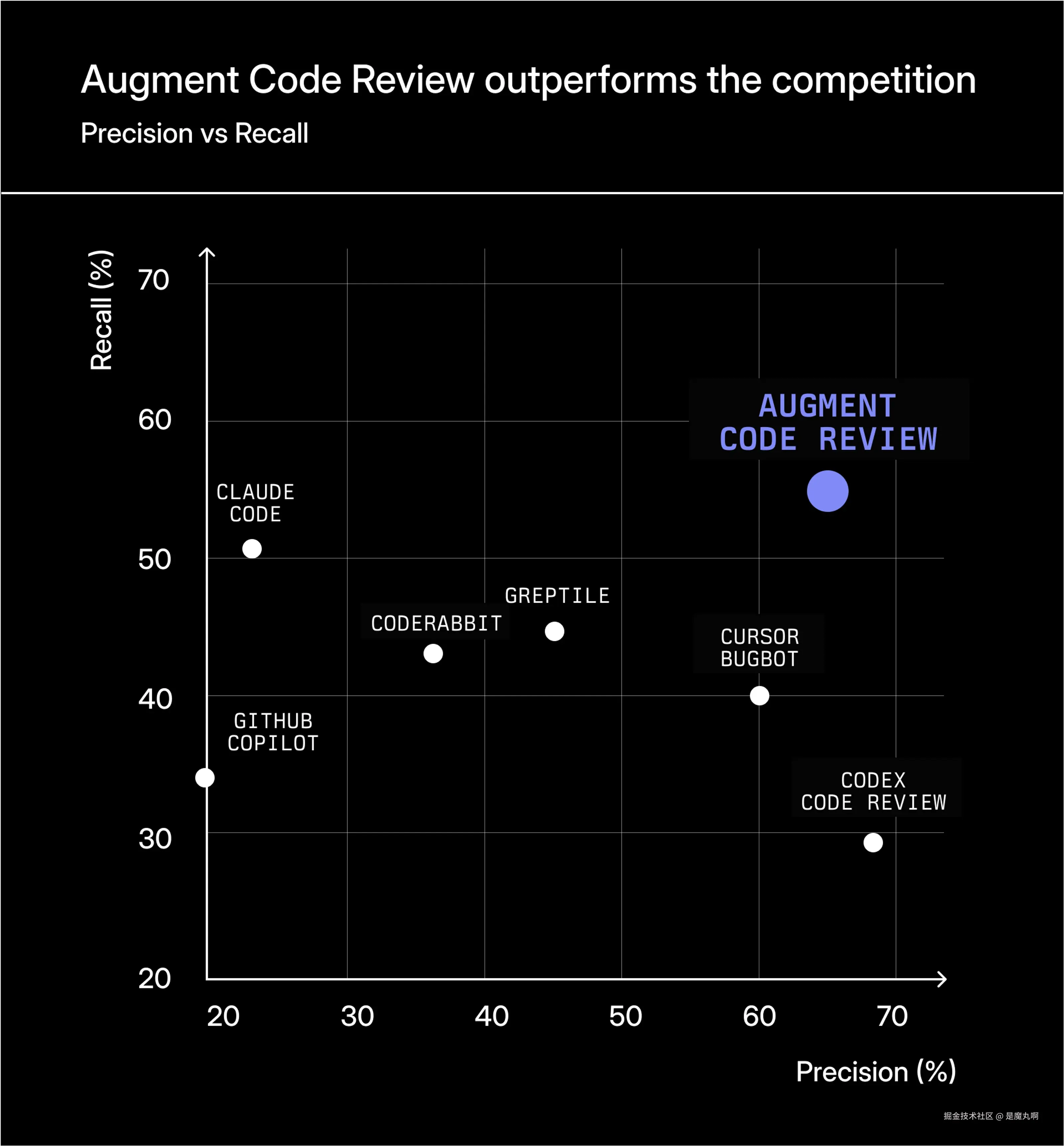
**Augment Code Review 以有意义的优势交付最高的 F-score,**重要的是,它是极少数能够同时实现高精确度和高召回率的工具之一。实现这种平衡极其困难:推动更高召回率的工具往往会变得嘈杂,而为精确度调整的工具通常会遗漏大量真实问题。例如,Claude Code 现在达到了大约 51% 的召回率------接近 Augment 的召回率------但其精确度要低得多,导致大量不正确或低价值的评论。这种信噪比权衡是 AI 代码审查的核心挑战。
**开发人员不会采用用噪音淹没 PR 的工具。**通过在实现评估中最高召回率的同时保持强精确度,Augment 在实践中提供了实质上更高的信号和更可用的审查体验。
为什么召回率是最难的前沿,以及为什么 Augment 领先
精确度可以通过过滤和保守的启发式方法来提高,但召回率需要一些根本上更难的东西:正确、完整和智能的上下文检索。
大多数工具未能检索到:
- 评估正确性所需的依赖模块
- 影响可空性或不变量的类型定义
- 跨文件的调用者/被调用者链
- 相关的测试文件和固件
- 来自先前更改的历史上下文
这些差距导致遗漏错误------不是因为模型无法对它们进行推理,而是因为模型从未看到相关的代码。
Augment Code Review 成功是因为它持续地浮现正确的上下文。
我们的检索引擎提取了模型推理跨文件逻辑、API 契约、并发行为和微妙不变量所需的文件和关系的确切集合。这直接转化为更高的召回率,而无需牺牲精确度。
为什么一些工具表现更好(以及为什么 Augment 表现最佳)
在所有七个工具中,三个因素决定了性能------而 Augment 在每个方面都表现出色。
1. 卓越的 Context Engine
这是差异化因素。Augment 持续检索了正确的依赖链、调用站点、类型定义、测试和相关模块------深度推理所需的原始材料。没有其他系统在上下文组装方面展示出可比较的准确性或完整性。
2. 模型、提示和工具的最佳组合
从强大的底层代理开始是良好代码审查的关键要求。设计良好的代理循环、上下文工程、专门的代理工具和评估在构建知道如何导航你的代码库、网络等并收集全面审查所需信息的代理方面大有帮助。
3. 专用代码审查调优
Augment 应用特定领域的逻辑来抑制 lint 级别的混乱并专注于正确性问题。这在避免其他工具中常见的垃圾行为的同时保持了高信号。
而且,Augment Code Review 随着时间推移而调优。我们能够计算 Augment 发布的每条评论是否由人类开发人员处理。这些数据帮助我们专门化和调优我们的代理工具、提示和上下文,以持续改进我们的代码审查服务。
综合起来,这些因素产生了最高的精确度、最高的召回率和最强的整体 F-score。
基准测试数据集
基准测试跨越五个数百万行的开源代码库的 50 个 pull request,包括 Sentry、Grafana、Cal.com、Discourse 和 Keycloak。这些存储库代表了真实世界的工程复杂性:多模块架构、跨文件不变量、深度依赖树和非平凡的测试套件。在这种代码上评估 AI 审查者是确定它们行为像高级工程师还是浅层 linter 的唯一方法。
我们如何改进数据集
原始公共数据集是无价的,但不完整。许多 PR 包含多个有意义的问题,这些问题在黄金集中缺失,使得无法准确测量召回率和精确度。我们通过手动审查每个 PR、验证问题并根据工具输出验证它们来扩展和纠正黄金评论。我们还调整了严重性,以便琐碎的建议不会夸大分数或不公平地惩罚工具。
所有纠正的数据和脚本都在 GitHub 上开源。
结论
AI 代码审查发展迅速,但工具之间的差距比营销页面所暗示的要大。大多数系统难以检索捕获有意义问题所需的上下文,导致低召回率和感觉浅薄或嘈杂的审查。AI 代码审查中定义性挑战不是生成------而是上下文:组装正确的文件、依赖项和不变量,以便模型能够像经验丰富的工程师一样推理。
**Augment Code Review 是此评估中唯一持续达到该标准的工具。**我们的 Context Engine 实现了远高于领域其余部分的召回率,其精确度保持了高信号。Augment 产生的评论感觉是实质性的、架构性的和真正有用的------更接近高级队友而不是自动化助手。随着代码库的增长和团队要求更深入的自动化,掌握上下文的工具将定义软件开发的下一个时代。按照这个衡量标准,Augment Code 已经遥遥领先。

Akshay Utture
Akshay Utture 构建使软件开发更快、更安全、更可靠的智能代理。在 Augment Code,他领导公司 AI Code Review 代理的工程工作,将研究级程序分析和现代 GenAI 技术结合起来,自动化 SDLC 中最耗时的部分之一。在加入 Augment 之前,Akshay 在 Uber 花了几年时间推进自动化代码审查和修复系统,并在 AWS 的 Automated Reasoning Group、Google 的 Android Static Analysis team 和 UCLA 进行研究。他的工作位于 AI、软件工程和编程语言理论的交叉点。
提升你的编码能力
修复错误、编写测试、更快发布