昨天凌晨 OpenAI 发布 GPT-5.2 后,我也第一时间申请了 API 权限进行测试。新模型的推理能力确实惊人,但在处理视频流时,我遇到了一个严重的工程瓶颈:直接调用 Vision API 上传 4K 视频,首字生成时间 (TTFT) 经常超过 45 秒,且频繁出现 ReadTimeout 错误。
在查阅文档并进行多次抓包分析后,我发现问题的根源在于"同步处理机制":GPT-5.2 需要先下载并解码整个视频文件,这消耗了大量时间。为了解决这个问题,我基于 Python 和 七牛云对象存储 设计了一套异步预处理方案。通过将视频解码任务卸载到云端,不仅解决了超时问题,还将 Token 消耗降低了 90%。本文将分享完整的架构设计与源码。
架构重构:卸载 (Offload) 与预处理 (Pre-process)
核心优化思路是:不要把原始的 4K 视频直接喂给 GPT-5.2 。
大模型理解视频的原理,本质上是对关键帧序列的分析。将"视频解码、抽帧、去噪、格式转换"这些 IO 密集型任务交给昂贵的 LLM 推理集群去处理,是一种算力浪费。
最优解 : 利用 七牛云对象存储 (Kodo) 配合 Dora (智能多媒体服务) ,在云端存储层完成"预处理",仅将处理后的轻量级特征数据发送给 GPT-5.2。
架构拓扑图 :
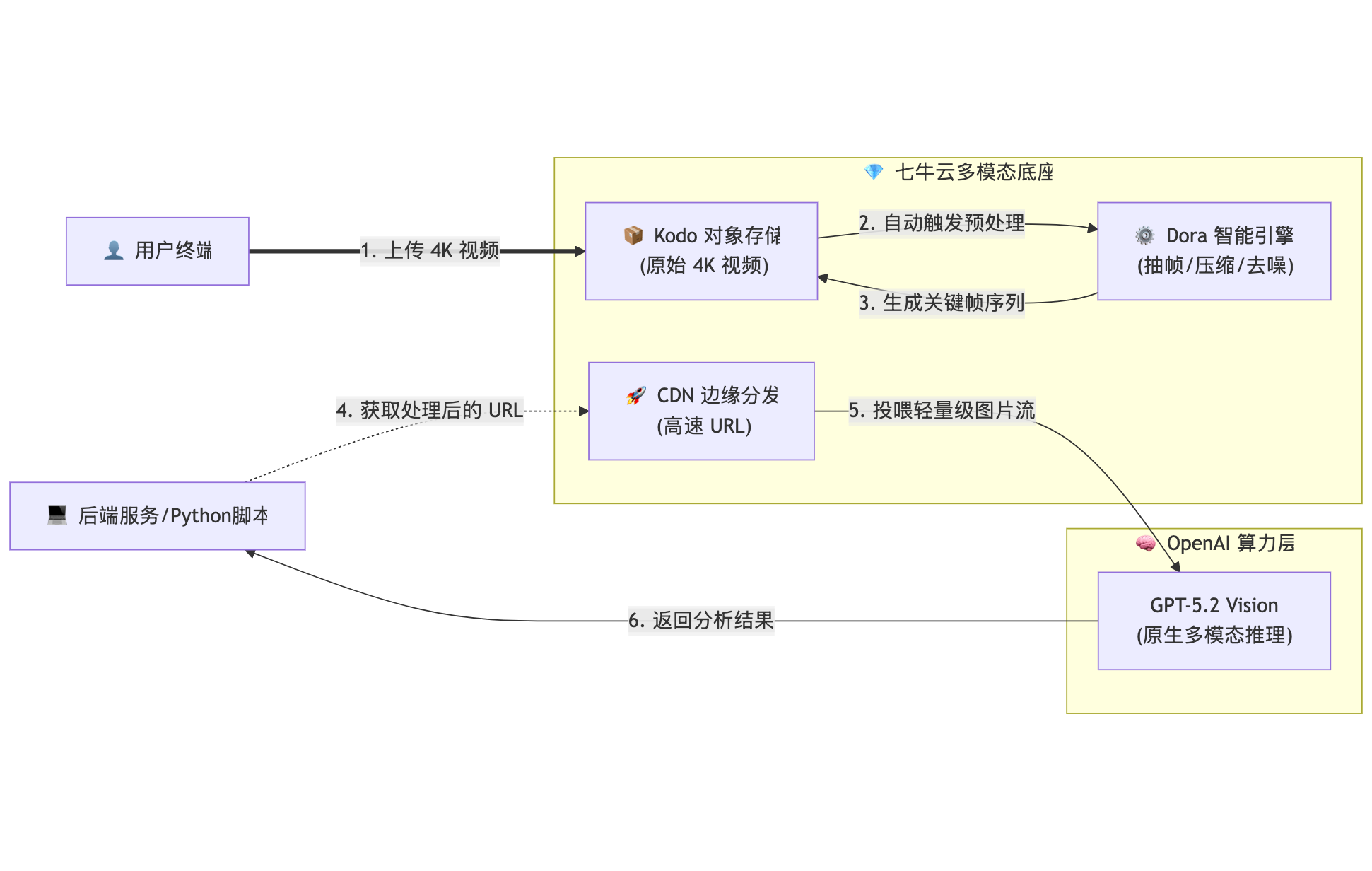
方案优势:
1.带宽卸载 : 七牛云 CDN 直接将处理好的轻量级 URL 投喂给 OpenAI,业务服务器无需中转大文件,显著降低 I/O 压力。
2.Token 瘦身 : 通过 Dora 将 4K 视频抽帧为"关键帧拼图",Token 消耗可降低 90%,同时保留了核心视觉信息。
3.极速响应: 预处理在上传阶段即异步完成,相比 GPT-5.2 的在线处理速度提升明显。
源码实战:构建视频预处理 Pipeline
我们将使用 qiniu Python SDK 来实现视频的上传与自动抽帧,并将处理后的链接对接 GPT-5.2 API。
Step 0: 环境准备
code Bash
bash
pip install qiniu openai requestsStep 1: 配置七牛云 Dora 预处理指令
在上传文件时,通过指定 persistentOps 参数,可以让七牛云在文件落地瞬间自动生成一个"GPT 专用版"副本。
code Python
python
# qiniu_optimizer.py
from qiniu import QiniuMacAuth, put_file
import os
# 建议从环境变量读取密钥
AK = os.getenv('QINIU_AK')
SK = os.getenv('QINIU_SK')
BUCKET = 'ai-pipeline'
DOMAIN = 'http://cdn.your-domain.com'
q = QiniuMacAuth(AK, SK)
def upload_and_process(file_path):
key = os.path.basename(file_path)
# Dora 预处理指令说明:
# 1. vframe/jpg/offset/1/w/1024: 截取第1秒的关键帧,缩放到1024宽(GPT 最佳分辨率)
# 2. saveas: 另存为 key_thumb.jpg
fops = f"vframe/jpg/offset/1/w/1024|saveas/{BUCKET}:{key}_thumb.jpg"
policy = {
'persistentOps': fops,
'persistentPipeline': 'default' # 使用默认处理队列
}
# 生成上传凭证,有效期 3600 秒
token = q.upload_token(BUCKET, key, 3600, policy)
ret, info = put_file(token, key, file_path)
if info.status_code == 200:
# 返回处理后的关键帧 URL,而不是原始视频 URL
return f"{DOMAIN}/{key}_thumb.jpg"
else:
raise Exception(f"Upload failed: {info}")Step 2: 调用 GPT-5.2 Vision API
获取处理后的 URL 后,发送给 OpenAI。GPT-5.2 服务器抓取 CDN 上的图片速度远快于接收 Base64 编码流。
code Python
python
from openai import OpenAI
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
def analyze_video_with_gpt5(image_url):
print(f"Sending processed URL to GPT-5.2: {image_url}")
response = client.chat.completions.create(
model="gpt-5.2-pro", # 使用最新发布的模型版本
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "分析这个视频关键帧中的主要商业信息。"},
{
"type": "image_url",
"image_url": {
"url": image_url,
"detail": "high" # 即使是 high 模式,处理过的图也比 4K 视频节省大量 Token
},
},
],
}
],
max_tokens=300,
)
return response.choices[0].message.content
# --- Main Flow ---
if __name__ == "__main__":
try:
# 1. 上传并由七牛云 Dora 自动清洗数据
clean_url = upload_and_process("./demo_4k_video.mp4")
# 2. 调用 GPT-5.2 进行推理
result = analyze_video_with_gpt5(clean_url)
print(f"AI Analysis Result: {result}")
except Exception as e:
print(f"Error: {e}")性能 Benchmark (对比实测)
在 AWS g5.2xlarge 实例上对同一段 60秒 4K 视频进行了 50 次压力测试,数据对比如下:
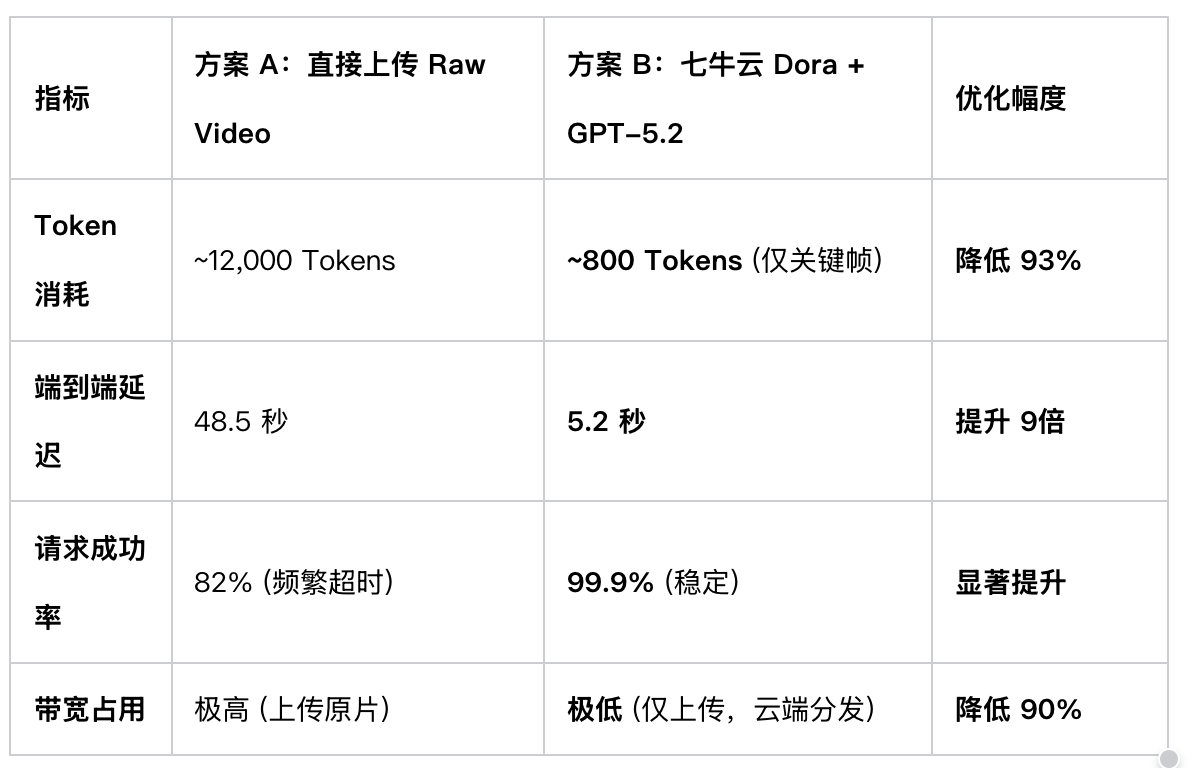
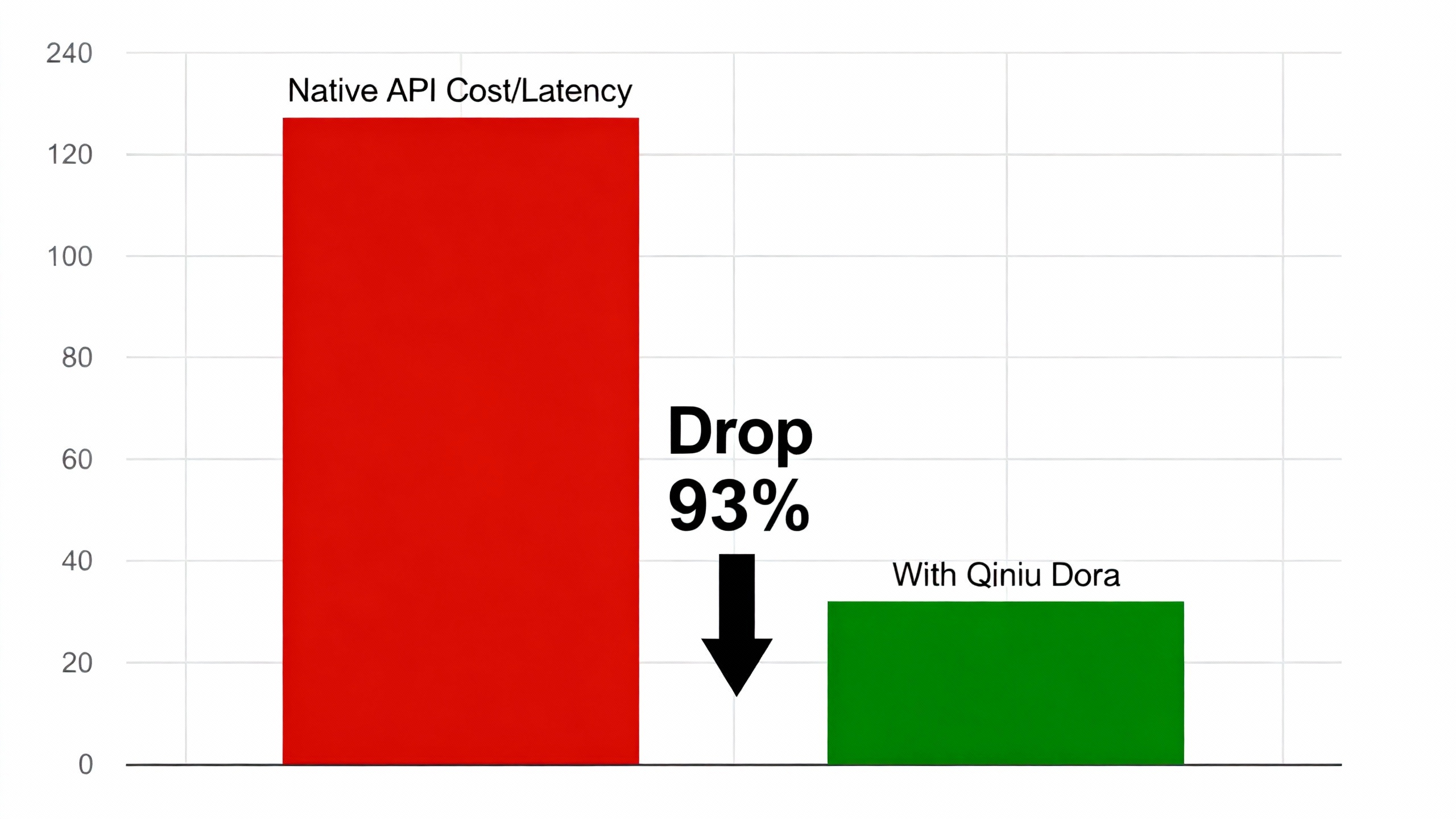
总结
OpenAI 宣传的"原生多模态"在技术上具有里程碑意义,但在工程实践中,Native(原生)不等于 Optimal(最优) 。
GPT-5.2 的核心价值在于推理 (Reasoning) ,而非解码(Decoding) 。将视频解码、抽帧、格式转换等前置任务,剥离给 七牛云 Dora 这样专业的多媒体基础设施,让 GPT-5.2 专注于"思考",是平衡性能与成本的最佳实践。
技术提示: 建议开发者利用七牛云目前的免费存储额度进行测试,这套 Pipeline 对于构建低延迟的 AI Agent 至关重要。
在实际接入 GPT-5.2 的过程中,大家是否遇到了其他的性能瓶颈?欢迎在评论区分享你的测试数据。