1 问题
问题: 探索其他指标的实现方法,例如precision, recall, f1-score?
2 方法
- 准确度(Precision):精确度是指被分类为正类别的样本中实际为正类别的比例。精确度可用于衡量模型在正类别上的准确性。
2.召回率(Recall):召回率是指实际为正类别的样本中被正确分类为正类别的比例。召回率可用于衡量模型对正类别样本的覆盖程度。
3.F1 分数(F1-Score):F1 分数是精确度和召回率的调和平均值,它提供了同时考虑精确度和召回率的指标,通常在不平衡的数据集中很有用。
准确度(Precision)
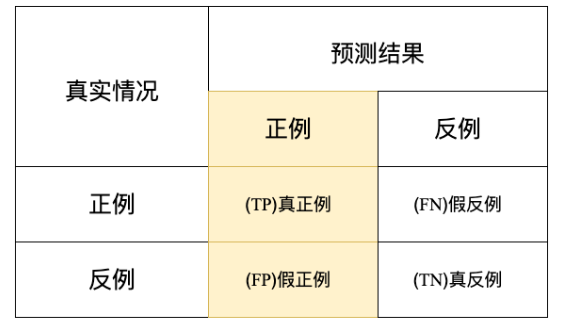
准确度P就表示在预测结果为正例的样本里,真实情况也为正例所占的比率
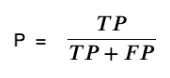
准确度
适用场景:当反例被错误的预测为正例(假正例)产生的代价很高的时候,适合用查准率,因为高查准率意味着低假正率/假阳性.比如在垃圾邮件检测中,假正例意味着非垃圾邮件(实际为负)被错误的预测为垃圾邮件(预测为正).如果一个垃圾邮件监测系统的查准率不高导致很多非垃圾邮件被归到垃圾邮箱里去,那么邮箱用户可能会丢失或者漏看一些很重要的邮件.
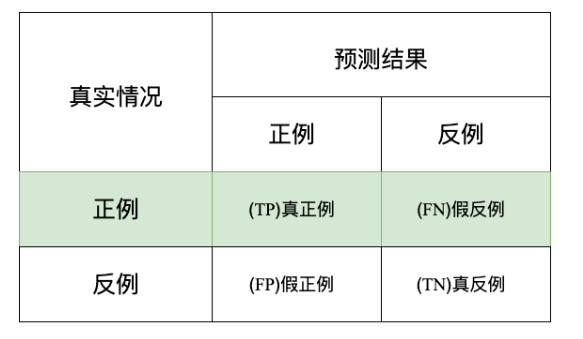
Recall 召回率是指实际为正类别的样本中被正确分类为正类别的比例。召回率可用于衡量模型对正类别样本的覆盖程度。
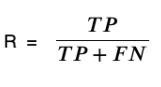
召回率
使用场景:当正例被错误的预测为反例(假反例)产生很高的代价时,用查全率,因为高查全率意味着低假反率/假阴性.比如说在银行的欺诈检测或医院的病患者检测中,如果将欺诈性交易(实际为正)预测为非欺诈性交易(预测为负),则可能会给银行带来非常严重的损失。再比如以最近的新冠疫情为例,如果一个患病者(实际为正)经过试剂检测被预测为没有患病(预测为负),这样的假反例或者说假阴性产生的风险就非常大.
F1 Score
F1是查准率和查全率的一个加权平均,F1 Score表达式如下
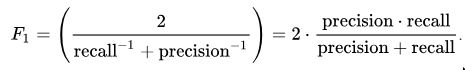
F1把假反例和假正例都考虑在内,F1比Accuracy更适用,尤其是当你的数据集类别分布不均衡时.比如说你的样本中正样本:负样本 = 100:1.
当假正例和假反例造成的代价差不多的时候直接用Accuracy就可以,但是当假正例和假反例产生的代价差别很大的时候,则可以考率更好的度量比如Precision,Recall和F1 Score.
3 结语
在机器学习的分类任务中,精确率(precision),召回率(recall),F1 score这几个评估分类效果的指标。而理解这几个评价指标各自的含义和作用对全面认识分类模型的效果有着重要的作用。