文章目录
- abstract
- pretrain
-
- [Muon优化器+QK-Clip 技术](#Muon优化器+QK-Clip 技术)
- 架构&加速优化
- [training recipe](#training recipe)
- post-train
-
- [SFT for agent](#SFT for agent)
- RL
- Q&A
abstract
- 预训练:改进MuonClip 优化器提升训练稳定性
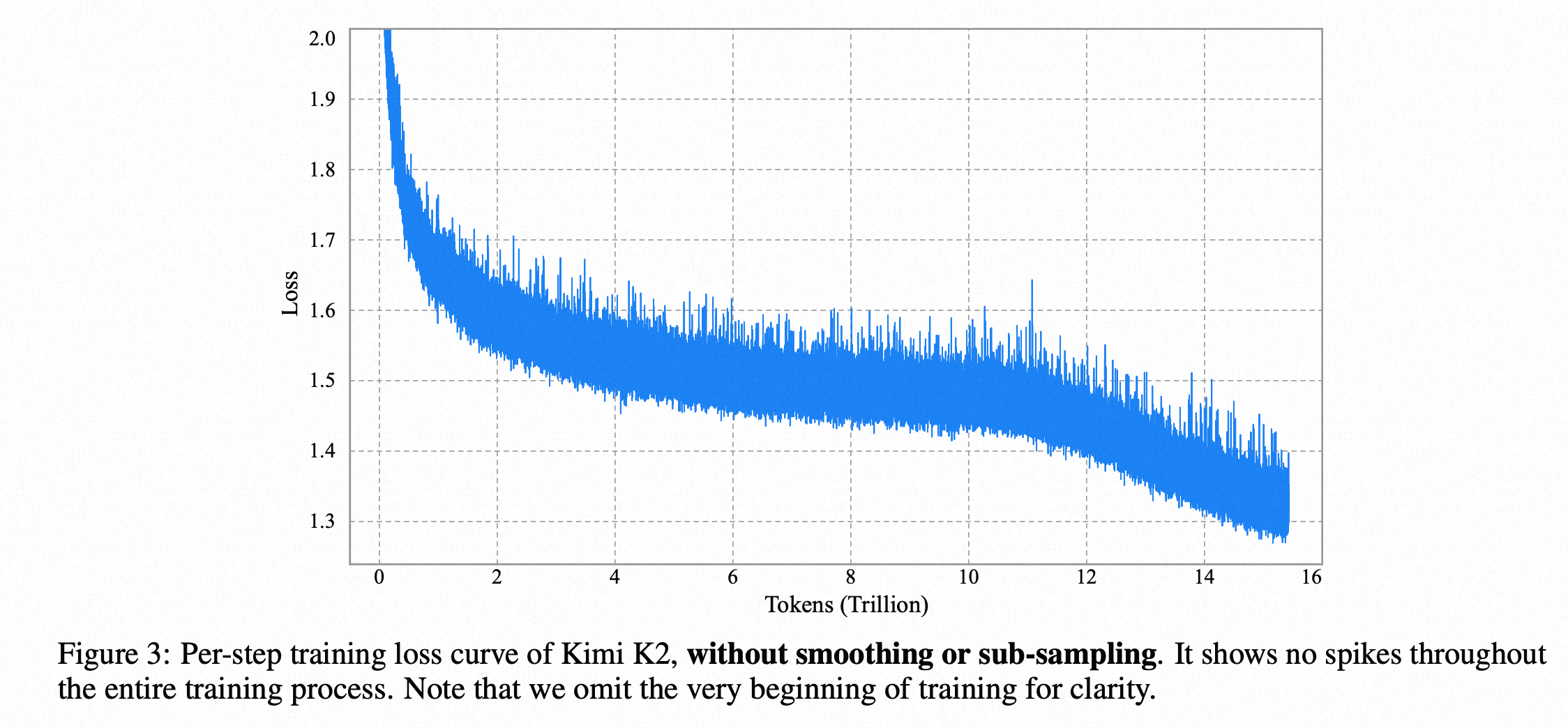
- 1T -32B-MOE模型,使用 15.5 万亿个 token 进行预训练的整个过程中,没有出现过一次损失尖峰,训练过程极其平滑稳定。这在万亿参数模型的训练中是一个非常了不起的工程成就。
- 有 384 个专家,每次激活 8 个。这个"稀疏度"(384/8 = 48)比之前的很多模型都要高。报告指出,根据他们的"稀疏度缩放定律"(Sparsity Scaling Law),在计算量不变的情况下,专家越多(越稀疏),模型性能越好。
- 数据增强策略 (Rephrasing):
- 背景:高质量数据有限,简单地重复训练会导致模型"死记硬背"(过拟合)。
- 解决方案: 数据改写(Rephrasing)。用一个强大的模型将高质量的原始文本用不同的风格、角度、句式重新写一遍,生成内容一致但表达方式不同的新数据。
- 效果: 这种方法既增加了数据量,又避免了过拟合,有效提升了"令牌效用"(Token Utility)。实验证明,用10份改写数据训练1遍的效果,远好于用1份原始数据训练10遍。
- 后训练:重点打造agent的能力
-
agent 调用训练:围绕海量的工具生成调用的轨迹数据(超过3000个真实工具和20000个合成工具)。模拟"用户"和"智能体"的对话。智能体尝试调用工具解决任务,其思考、调用、碰壁、修正的全过程(即"轨迹")被记录下来。然后用"裁判"模型选择出成功的轨迹用作训练数据。
-
RL:
- 可验证奖励 (Verifiable Rewards): 对于有明确对错的任务(如数学题、编程题、遵循精确指令),奖励信号是客观的(例如,代码跑通了单元测试就给高分)。
- 自评判奖励 (Self-Critique Rubric Reward): 对于主观任务(如创意写作、开放式问答),没有标准答案。Kimi K2 会自己生成多个回答,然后自己扮演"裁判",根据一套内部准则(Rubrics)来评判哪个回答更好,从而产生学习信号。
-
pretrain
Muon优化器+QK-Clip 技术
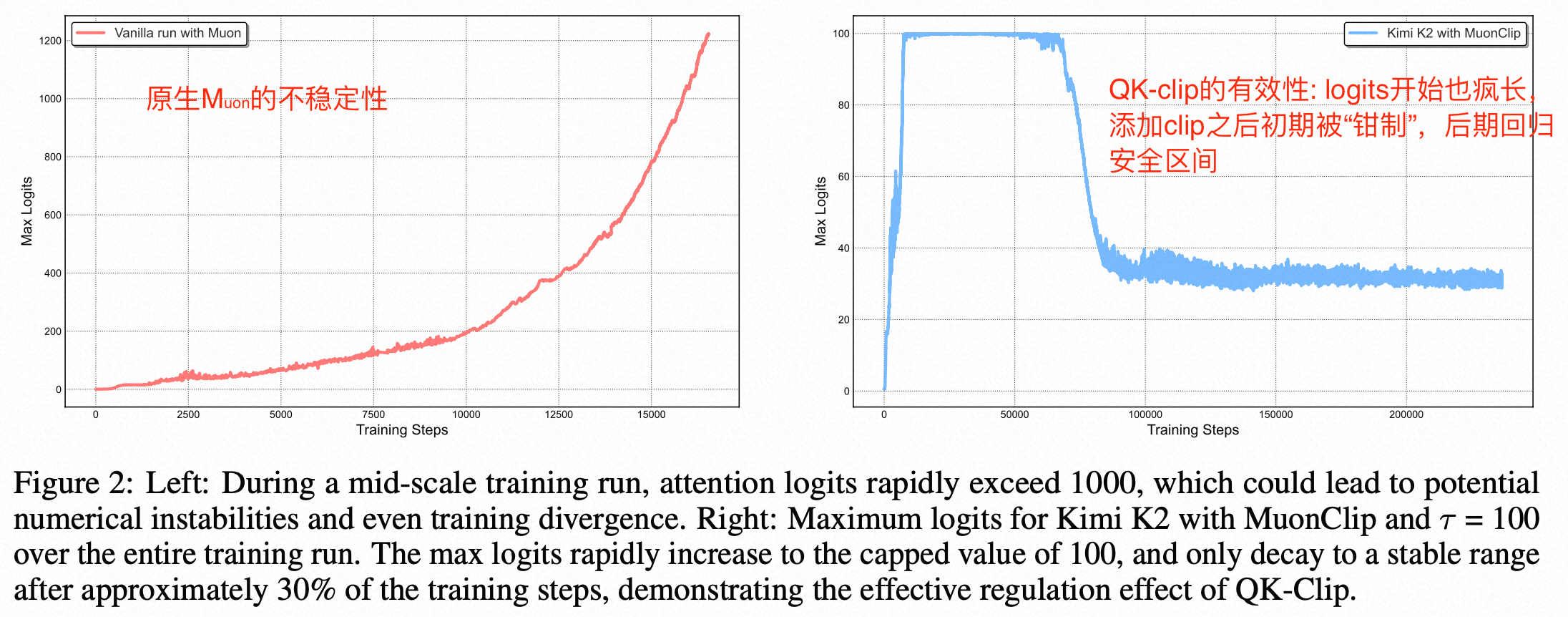
-
Muon优化器和adam 优化器对比
- AdamW 为每个参数计算方向和布长
- Muon 只为整个网络层计算方向,步长是固定的
- 比如对于1024*1024 的权重矩阵,AdamW计算矩阵中每一个参数的梯度,将整个矩阵看成一个整体,通过msign数学操作进行归一化变换,代表整体变换趋势;
-
为什么Muon比adam 学习效率更高?
- adamw 参数各自为战,信息比较片面;Muon 整个层可以看做一个低秩矩阵,对网络层更高效、更协调的更新,从而提升了学习效率。因此Muon优化器可以用更少的token 数据学到更多的知识
-
为什么Muon比adam更不稳定?
- 梯度的大小并不仅仅是噪声,它也包含了重要的警告信号。但是Muon的梯度中将大小信息抹掉了。而adamW看到大梯度,它的自适应机制会减小学习率
- 容易产生"正反馈循环"(恶性循环):初始训练中,注意力权重矩阵的梯度(G)可能会偶然比较大,但是Muon会忽视这个大小信号,再次增大Wq 和 Wk ,导致logits 尖峰;
-
QK-Clip 的精妙之处
- 实现原理:监测注意力计算中的一个关键值(logits),一旦这个值超过设定的安全阈值,就会自动缩放相关的模型权重,从而防止其失控。QK-Clip 强行打破了上面描述的那个恶性循环,从而在享受Muon高速性能的同时,保证了训练的稳定。
- 计算一个缩放因子 γ = τ / m a x ( L o g i t s ) γ = τ / max(Logits) γ=τ/max(Logits)。在这个例子里,γ = 100 / 120,约等于 0.83。
然后,它会用这个因子来缩小权重W_q_w = W_q_old \*
KaTeX parse error: Double subscript at position 4: W_q_̲new = W_q_old *...
KaTeX parse error: Double subscript at position 4: W_k_̲new = W_k_old *...
架构&加速优化
- 架构:
- 稀疏度缩放定律:实验发现,在激活参数量(即计算成本)固定的情况下,增加专家总数(即提高稀疏度)可以持续降低损失,提升模型性能。因此,Kimi K2 采用了 48 的稀疏度(384 个专家中激活 8 个)。
- 注意力头数量:之前的模型(如 DeepSeek-V3)为了计算效率,将注意力头数量设为层数的两倍。但团队发现,这在长文本推理时会带来巨大的计算开销,而性能提升却很小(只有 0.5% - 1.2%)。因此,为了平衡性能和长文本推理效率,Kimi K2 将注意力头数量减少到 64 个。
- 训练加速
- 并行策略:将模型按"层"、"专家"等维度切块,分给不同的GPU管理。
- 显存优化(压缩货物):
- 选择性重计算:计算开销不大,但显存占用巨大的激活值(LayerNorm, SwiGLU 等),forward的时候不存,backword的时候再算一遍;
- FP8 存储:MoE 和 SwiGLU 模块的输入激活值对精度不那么敏感。存的时候按照fp8存,算的时候再转换成高精度
- CPU 卸载:对于所有经过上述两步优化后仍然占用显存的激活值,gpu计算的时候搬运到cpu,设计考虑计算、通信高度重叠
training recipe
- 预训练初期chunk size= 4096,然后用 32k 序列长度训练,最后使用 YaRN 方法将上下文窗口扩展到 128k。
- 学习率采用了分段策略:两部分数据质量基本一致,都是预训练数据,但是配比可能有些差别;
- 恒定学习率:10T token的,学习率稍大,用于在海量数据上进行快速、充分的探索和学习。
- 余弦衰减:5.5T token。用于在训练末期进行精细的调整和稳定的收敛。
post-train
SFT for agent
- 背景:教会模型使用工具很难,因为真实的交互环境构建成本高、规模小。
三步走的合成流程 (见 Figure 8): - 工具、智能体和任务生成:首先,从 GitHub 等来源收集了 3000+ 真实工具,并用"领域进化"的方法合成了 20000+ 虚拟工具(覆盖金融、软件、机器人等领域)。然后,为这些工具自动生成了数千个具有不同能力和专长的"智能体"角色,并为每个智能体生成了从简单到复杂的任务,每个任务都附带一个明确的成功标准(Rubric)。
- 轨迹生成:通过一个模拟环境进行多轮对话。其中包含:
- 用户模拟器:扮演不同风格的用户向智能体提问。
- 工具执行环境:一个"世界模型",当智能体调用工具时,它会模拟工具的执行结果,并返回成功、失败或错误信息。
- 质量评估和筛选:一个"裁判"模型会根据任务的成功标准来评估整个交互轨迹。只有成功完成任务的轨迹才会被保留下来用于训练。为了保证真实性,对于编码等任务,团队也使用了真实的沙箱环境来执行代码,将模拟的多样性和真实世界的可靠性结合起来。
RL
新增加的技巧:
- 预算控制:对每个任务设置最大生成长度,超出则惩罚,鼓励模型生成简洁有效的回答。
- PTX 损失:在 RL 训练中混入少量高质量的 SFT 数据,防止模型"忘本"。
- 温度衰减:在训练初期使用较高的采样温度鼓励探索,后期降低温度以实现稳定利用。
架构优化: - 共置架构:在同一批 GPU 上部署"推理引擎"(用于生成 RL 经验)和"训练引擎"(用于更新模型)。两者分时工作,高效利用资源。
- 高效的引擎切换:为了在推理和训练之间快速切换,团队开发了一个分布式的**"检查点引擎"(Checkpoint Engine)**。它负责高效地将训练好的新模型参数,以流水线的方式重新分片并广播给所有推理节点,整个更新过程在 30 秒内完成。
- 高效的系统启动:优化了从磁盘加载万亿模型参数的流程,通过并行读取和广播,最大化 I/O 效率,减少了因系统故障重启而浪费的时间。
- 智能体式 Rollout:为了支持长周期的、需要与外部环境(如代码解释器)交互的智能体任务,系统支持:
- 异步环境交互:将耗时的环境交互部署为独立服务,并通过大量并发任务来摊销等待延迟。
- 部分 Rollout:允许未完成的长任务被"暂停",在下一轮 RL 迭代中继续执行,防止"长尾任务"阻塞整个流程。(相当于存档,下个周期,新任务从0开始,rollout的任务从上次暂停的地方开始)
Q&A
- "损失尖峰"(Loss Spike)产生的原因
Answer:(1)脏数据;(2)学习率过高;(3)大模型训练不稳定,中间数值异常:attention中某些数值过大,经过softmax函数后会产生极端的结果(一个接近1,其他全是0),这会导致梯度(模型调整方向的信号)也变得极端巨大,从而引发"尖峰";