目录
[五、长查询 与 目标对 模型性能评估](#五、长查询 与 目标对 模型性能评估)
上一篇文章:推荐大模型系列-NoteLLM-2: Multimodal Large Representation Models for Recommendation(二)
一、训练细节

所有基于大语言模型(LLM)的模型,其详细训练超参数均列于表8中。此外,训练过程中采用DeepSpeed 37及零冗余优化器(ZeRO)38的第三阶段技术。
二、端到端MLRM细节
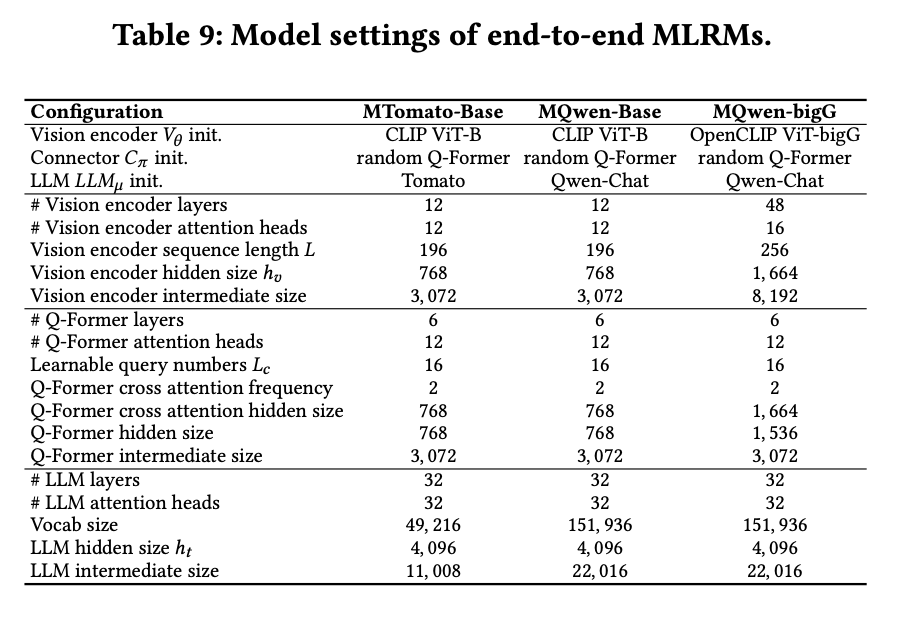
表9提供了端到端MLRM的详细信息。同时,为便于理解Tomato模型的特性,此处详述其持续预训练细节。Tomato基于LLaMA 2 47架构,原模型仅支持英文。由于目标平台面向中文市场,需增强LLaMA 2的中文理解能力,因此在持续预训练中进行了以下改进:
- 词表扩展:将原始词表从32,000个词元扩展至49,216个,新增的17,216个词元主要为中文词汇。
- 预训练数据:数据来源包含三部分:中文语料、英文语料及平台专有数据。中文语料采用开源数据集如万卷18和悟道53,总量约2T词元;为保持英文能力,引入RedPajama9数据;此外,整合了平台内高质量笔记数据30B词元,以更好地学习平台数据特性。
Tomato在提升中文理解能力的同时,英文能力与原始LLaMA 2模型相当。需说明的是,预训练细节与本文贡献无关,本文方法基于持续预训练后的模型实现。这也体现了NoteLLM-2方法的优势:在微调前可针对不同模态对基座模型进行个性化增强。
三、Qwen-VL-Chat的显著性分数分析
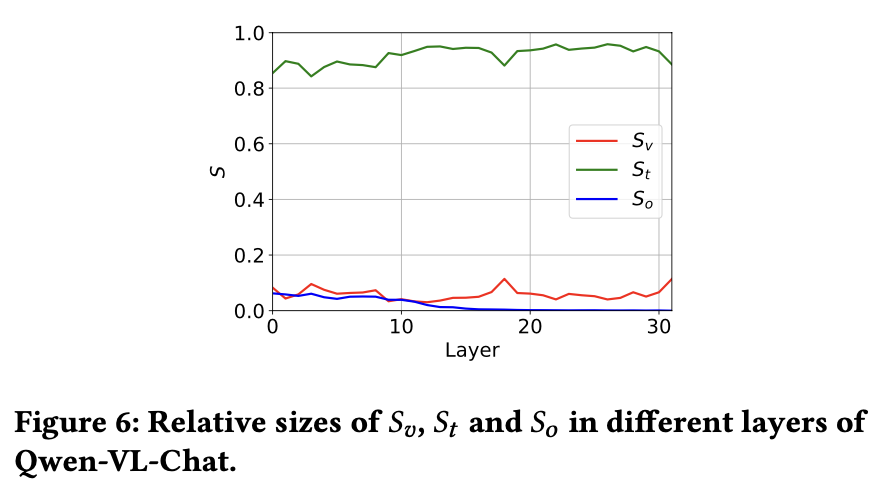
在Qwen-VL-Chat中观察到独特的显著性分数模式(如图6所示)。该模型的主要信息流为文本形式,所有层的数值均高于0.8。这一现象源于大量视觉嵌入(Qwen-VL-Chat中为256维)输入到大型语言模型(LLMs),导致图像信息流的平均显著性降低。
传统MLLMs与MLRMs的适配问题
上述结果表明,传统多模态大语言模型(MLLMs)无法直接适用于多模态大规模表征模型(MLRMs)。为适配MLRMs,需通过增加信息流密度的方式调整MLLMs的结构设计。
四、零样本多模态表示性能
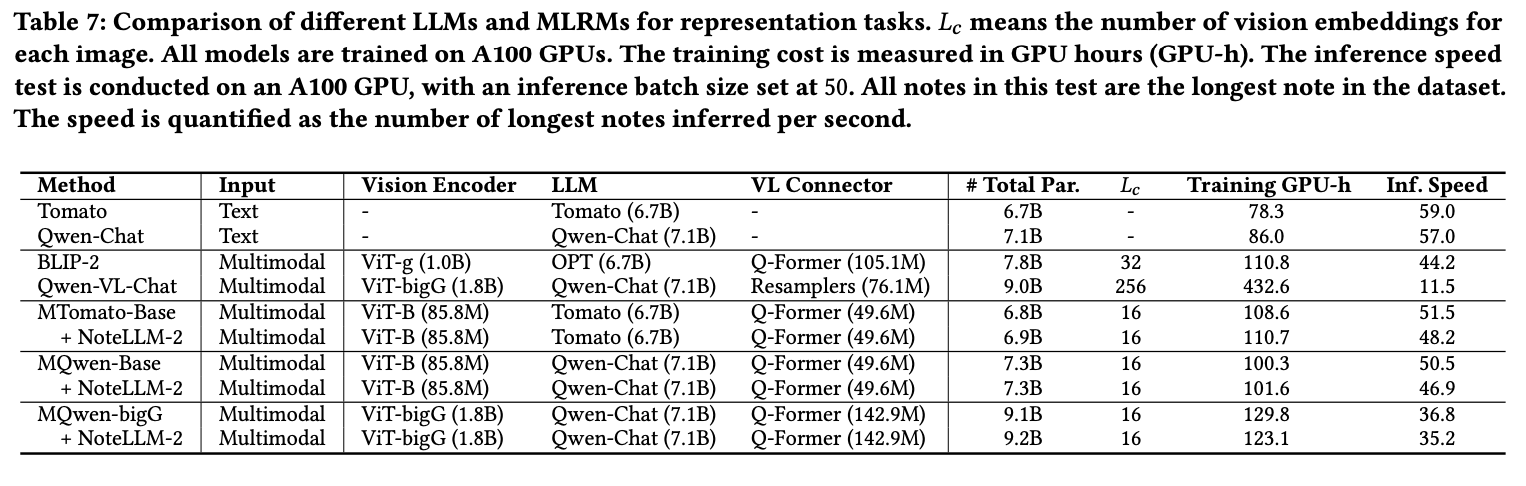
本节以零样本方式探索多模态大语言模型(MLLMs)在多模态I2I推荐任务中的表示能力。实验选取了四种主流MLLMs:BLIP-2 27、LLaVA-1.5 30、Qwen-VL 3和Qwen-VL-Chat 3,同时对比了基线方法BM25 39、Qwen-Chat 2以及基于LLaMA 2 47持续预训练的纯文本模型Tomato(该模型缺乏视觉感知能力,但使用了平台数据训练)。模型细节见表7。为分析MLLMs对不同模态的表示能力,测试时分别独立输入图像和文本。
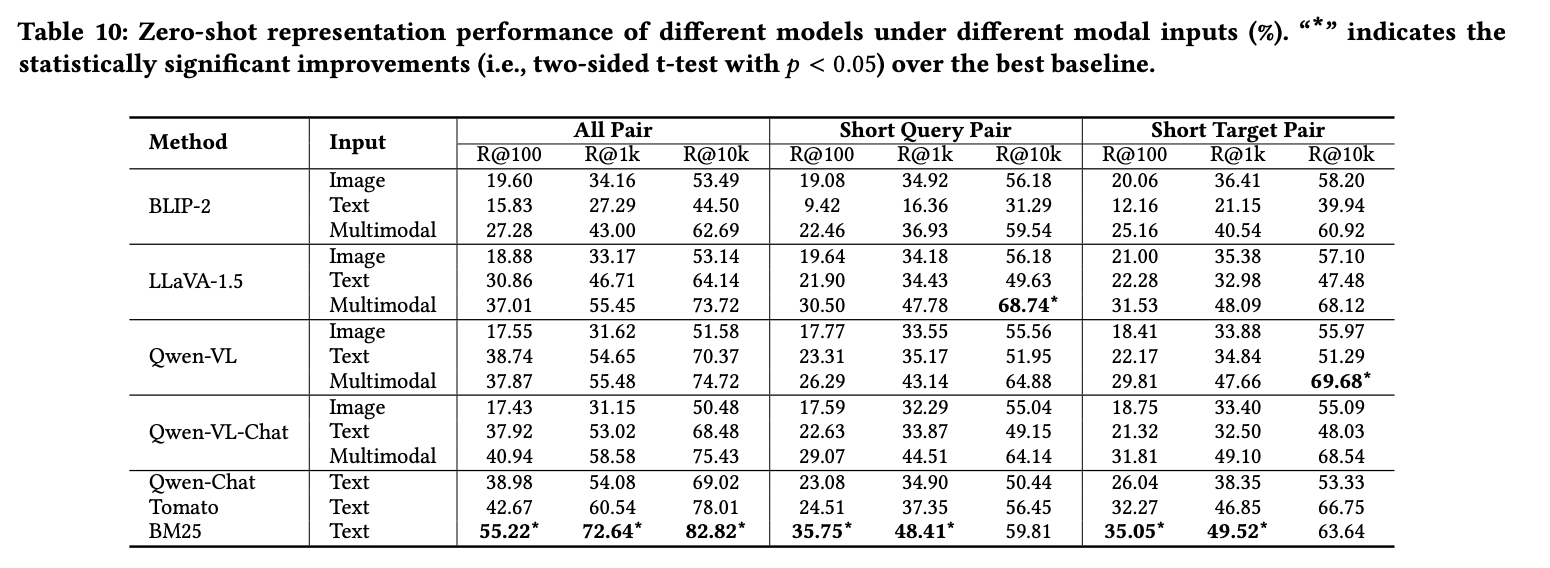
实验结果见表10,主要发现如下:现有MLLMs的零样本表示性能均逊于BM25,表明尽管MLLMs具备优秀的视觉理解能力,但其零样本多模态表示能力仍有不足,原因在于MLLMs采用语言建模损失训练,与表示任务目标不匹配,因此需要额外训练以实现任务对齐。
多数情况下,MLLMs对多模态输入的表示效果优于单模态,证明其能有效提取并融合多模态信息。同时,大多数MLLMs对文本信息的表示能力优于图像信息,这与模型参数主要源于纯文本LLMs有关,且实验场景中文本笔记比图像更具区分性。
值得注意的是,纯文本LLMs在不接收任何图像输入时,性能仍可与MLLMs相当。
五、长查询 与 目标对 模型性能评估
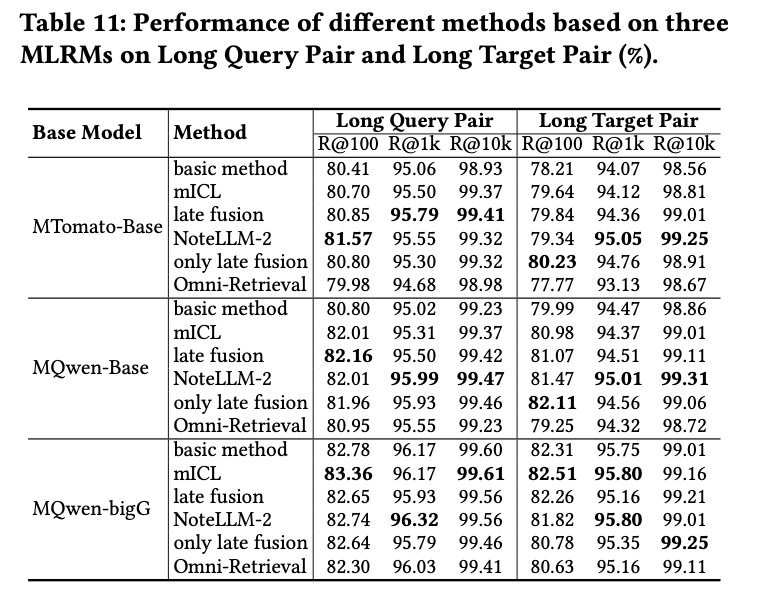
为全面评估方法的有效性,针对长查询与长目标对进行了测试。长文本定义为超过165个标记(约占测试文本的10%)的样本。测试数据集包含2,228个长查询对和2,177个长目标对。结果如表11所示。
由于大语言模型(LLMs)出色的长上下文理解能力,长文本对的性能显著优于整体数据,因长文本提供了更丰富的信息。此外,相比基础方法,所提方法在长文本对上进一步提升了效果,这表明增强对视觉信息的关注对长文本处理同样重要。
好啦,关于notellm-2这篇文章已经基本完成讲解,之后会已这篇多模态大模型展开,去调研相关paper,并进行路径整理,敬请期待~