"监控告警量下降了40%,但我们的工程师却更疲惫了。"
这是某头部电商平台SRE负责人在季度复盘会上抛出的真实困境。根据Gartner 2023年AIOps市场报告,高达73%的企业在部署AIOps后未能实现预期的MTTR(平均修复时间)缩减 ,反而陷入了"工具越智能,人越被动"的怪圈。这并非技术本身的失败,而是我们用 "打地鼠"式的线性思维 去驾驭指数级增长的系统复杂性,所必然付出的代价。
在微服务、云原生、AI大模型叠加的当代技术栈中,系统的动态性、关联性和涌现性已远超人类直觉的边界。告警不再是孤立的信号,而是系统结构发出的"人声";故障不再是偶发的事件,而是因果回路累积的"显影"。本文将揭示:AIOps的失效,本质是思维框架的失效。通过一套三维思考支架,我们将系统思考的底层逻辑注入智能运维实践,让工具回归工具,让思维驾驭复杂。
第一维:深度思考------穿透告警风暴,捕获结构信号
1.1 事件层的认知陷阱:当告警成为噪声
2022年阿里巴巴"双十一"大促期间,其监控体系曾面临每分钟超50万条原始告警的峰值冲击。即便经过传统压制策略处理,工程师仍需面对每小时**2000+**个待研判事件。这种"告警海啸"并非特例,而是现代分布式系统的常态。我们习惯性地在事件层"打补丁":增加抑制规则、调升阈值、屏蔽非核心指标。但效果如同堵不住的筛子------压下葫芦浮起瓢。
冰山模型 在运维场景的映射揭示了真相:我们看到的告警(事件) ,只是系统行为的水面尖峰。其下隐藏着:
- 行为模式层:告警的时空聚类规律、周期性与趋势性变化
- 系统结构层:监控策略、变更频率、容量模型之间的因果反馈
- 心智模式层:团队对"监控覆盖度=系统可控性"的深层假设
1.2 从压制到洞察:因果回路图的实战绘制
让我们用**因果回路图(CLD)**解剖告警风暴的真实结构。基于阿里公开的技术实践,典型运维系统存在以下反馈关系:
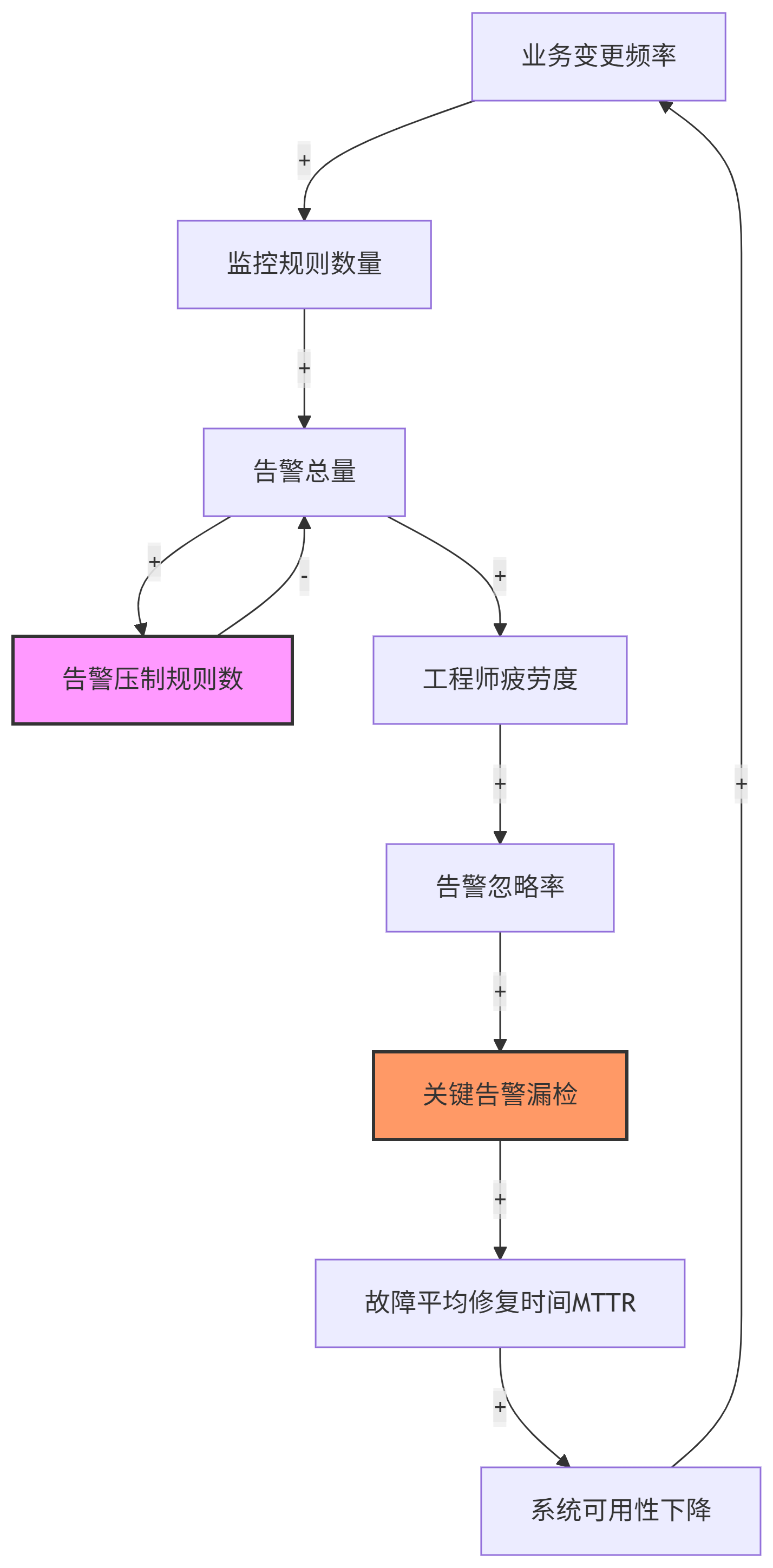
关键洞察:
- 增强回路R1 :
监控规则↑ → 告警总量↑ → 压制规则↑ → 告警总量↓看似有效,实则掩盖了真实问题 - 调节回路B1 :
工程师疲劳度↑ → 告警忽略率↑ → 关键告警漏检↑形成自我调节的失效边界 - 时间延迟 :压制规则效果显现需要15-30分钟,但故障扩散速度达秒级,存在节奏错配
1.3 心智模式的重构:从"全覆盖"到"高信噪比"
阿里SRE团队在2023年监控体系升级中,主动下线了23%的低价值指标,并引入"监控熵值"评估模型。其计算公式开源如下:
# 监控熵值 = 信息增益 - 维护成本
def calculate_monitoring_entropy(metric_id, alert_frequency, false_positive_rate, maintenance_hours):
"""
计算单个监控项的熵值,正值代表价值监控,负值建议下线
"""
# 信息增益:告警频率 × (1 - 误报率) × 根因关联度权重
information_gain = alert_frequency * (1 - false_positive_rate) * 0.7
# 维护成本:人工时 × 工程师时薪 + 存储成本
maintenance_cost = maintenance_hours * 500 + 50 # 假设时薪500元,存储成本50元/月
return information_gain - maintenance_cost
# 示例:某磁盘利用率监控,每天告警20次,误报率30%,每月维护2小时
entropy = calculate_monitoring_entropy("disk_usage", 20, 0.3, 2)
print(f"监控熵值: {entropy:.2f}") # 负值,建议优化或下线这一实践背后的思维转变,是从"监控是成本中心"到"监控是决策资产"。真正的深度思考,敢于对"监控全覆盖"这一工业时代执念开刀。
第二维:广度思考------打破工具孤岛,构建全局韧性
2.1 本位主义的工具链困局
某电商平台的AIOps实践暴露典型问题:Prometheus负责指标监控、ELK处理日志、Jaeger追踪调用链、LTS存储时序数据,各系统API打通但数据语义未对齐 。一次购物车故障中,四系统分别发出"接口超时"、"错误日志激增"、"调用链断裂"、"CPU飙升"告警,SRE耗费47分钟 才拼凑出完整根因------缓存穿透导致数据库连接池耗尽。工具连接了,但思维未连接。
2.2 思考的罗盘 ® :绘制跨域影响拓扑
广度思考的本质,是识别监控体系中所有利益相关者 及其双向影响链。基于阿里技术中台实践,可构建如下影响矩阵:
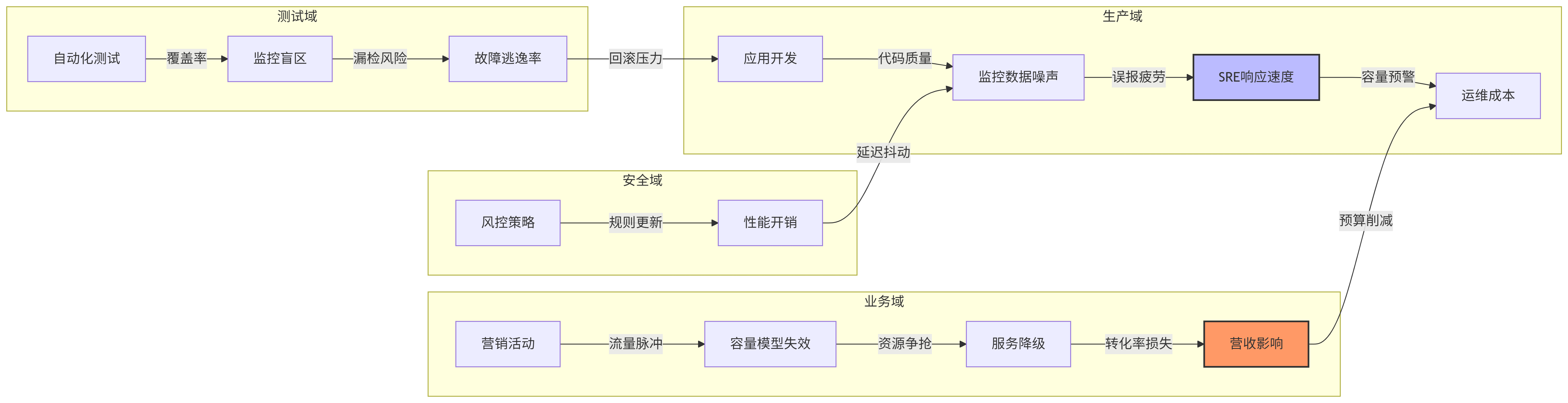
核心发现 :监控系统的价值不在采集,而在影响业务决策的效率。传统AIOps工具链集成聚焦"数据流",而广度思考要求对齐"价值流"。
2.3 边界重构:SLO驱动的责任契约
阿里在2023年全面推行SLO-as-a-Service 模式,将监控边界从技术指标扩展至业务体验。其核心是建立 "错误预算" 跨部门契约:
# SLO定义示例(开源自阿里云SLO规范)
apiVersion: slo.alibabacloud.com/v1
kind: ServiceLevelObjective
metadata:
name: order-create-slo
spec:
service: order-service
indicator:
latency:
target: 99% requests < 500ms
period: 7d
availability:
target: 99.95%
period: 30d
stakeholders:
- dept: biz-dev
responsibility: "代码性能优化"
budget: 60% # 拥有60%的错误预算分配权
- dept: sre
responsibility: "容量保障"
budget: 40%
escalation: "当错误预算消耗>80%时,触发跨部门复盘"这种设计用经济契约替代行政命令,让各域在清晰边界内自主决策,避免了补偿反馈------即SRE过度监控导致开发团队产生"被替代"抵触,反而降低协作效率。
2.4 全局韧性设计:监控的价值流图
广度思考的最终产出,是识别整个监控体系的价值衰减节点。借鉴精益价值流分析,可绘制:
|----------|--------|-------------|-------------------------------|
| 价值阶段 | 耗时 | 衰减原因 | 系统思考对策 |
| 数据采集 | 10s | 采样率过高导致资源争抢 | 调节回路:引入动态采样,CPU>80%时自动降频 |
| 数据清洗 | 30s | 正则表达式性能瓶颈 | 增强回路:将清洗结果缓存,复用率>60%直接返回 |
| 异常检测 | 5s | 模型推理延迟 | 延迟管理:异步推理+熔断降级 |
| 根因定位 | 15min | 跨系统数据关联人工耗时 | 广度对齐:建立统一实体关系图谱 |
| 业务决策 | 2h | 技术语言转业务语言 | 心智模式:SLO直接绑定GMV/转化率 |
第三维:角度思考------超越静态阈值,驾驭故障演化
3.1 动态性复杂的根源:微服务的"蝴蝶效应"
静态阈值在微服务架构下失效的根本原因是因果关系的时空错位 。一次看似无关的推荐算法模型更新(耗时50ms),可能通过调用链传递,导致下游用户画像服务线程池打满,最终引发登录接口超时。阿里技术团队曾复盘一个P2级故障:根因是3周前 的JVM参数调优,改变了GC停顿模式,在特定营销活动流量特征 下触发连锁反应。这种 "时间延迟 × 空间耦合" 的动态复杂性,是传统AIOps无法预测的。
3.2 环形思考法 ® :故障不是因果链,而是因果环
将线性根因分析转为环形演化推演,是角度思考的核心。以"缓存雪崩"为例:
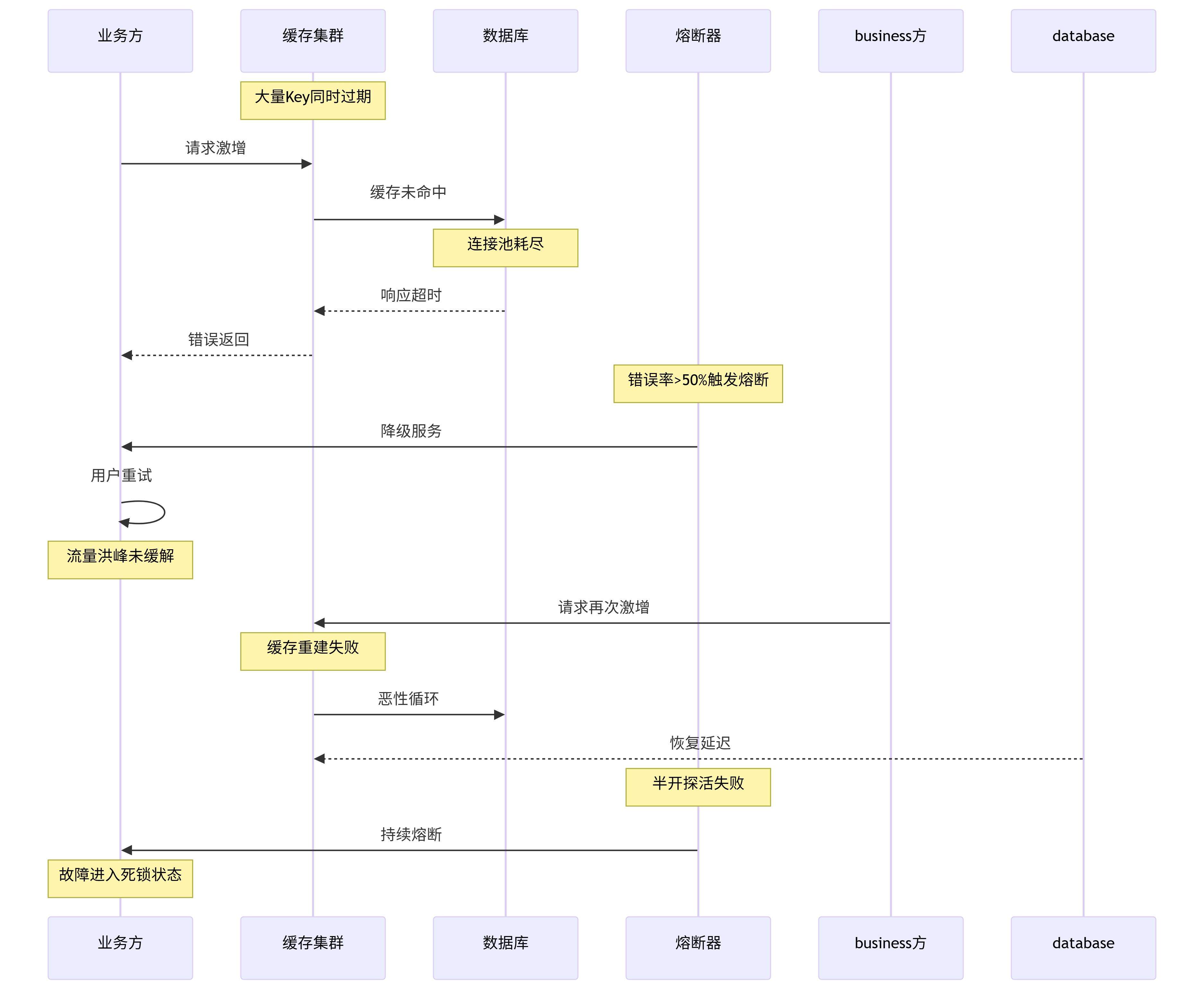
四步环形推演:
- 找问题:缓存雪崩导致服务不可用
- 找原因:Key未设置随机过期时间
- 找结果:数据库被打垮 → 缓存无法重建
- 找回路 :缓存重建失败 → 请求持续击穿的死循环
3.3 时间延迟的精确管理:节奏匹配四象限
角度思考必须量化延迟类型与时长。基于阿里公开的智能巡检实践,可建立延迟管理矩阵:
# 延迟类型识别与对策
class DelayManager:
def __init__(self):
self.delay_patterns = {
"信息延迟": {"threshold": 30, "strategy": "异步缓冲"},
"物理延迟": {"threshold": 180, "strategy": "预热池"},
"认知延迟": {"threshold": 600, "strategy": "决策升级"},
"组织延迟": {"threshold": 3600, "strategy": "SLO熔断"}
}
def match_strategy(self, metric_name, delay_seconds):
"""根据延迟时长匹配应对策略"""
for delay_type, config in self.delay_patterns.items():
if delay_seconds <= config["threshold"]:
return {
"type": delay_type,
"action": config["strategy"],
"confidence": 1 - (delay_seconds / config["threshold"])
}
return {"type": "组织延迟", "action": "SLO熔断", "confidence": 0.1}
# 示例:弹性扩容延迟评估
manager = DelayManager()
result = manager.match_strategy("ecs_scaling", 240) # 4分钟物理延迟
print(result) # {'type': '物理延迟', 'strategy': '预热池', 'confidence': 0.33}3.4 成长上限基模:AI依赖导致的技能退化
阿里高级技术专家在QCon 2023分享中警示: "AIOps越精准,初级工程师的排障能力退化越快" 。这是一个典型的成长上限结构:
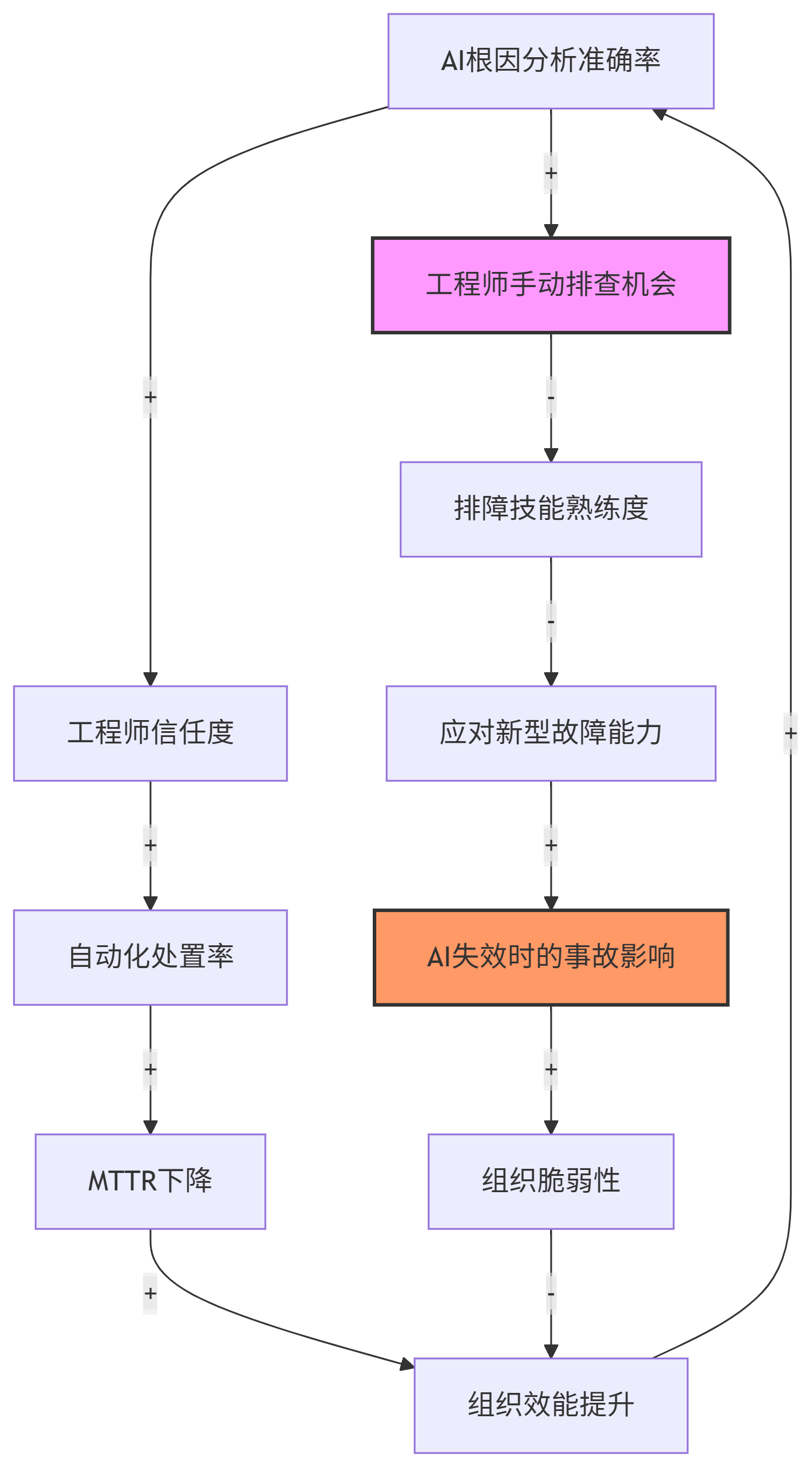
突破策略 :阿里实施" AI建议 + 强制人工验证 "的混合模式。对于AI置信度>90%的判障结果,仍需工程师在15分钟内提交验证报告,否则触发告警升级。这既保持了AI效率,又维持了人类对系统结构的理解能力。
整合实践:某电商大促的真实三维推演
2023年"618"期间,阿里某业务线遭遇"购物车加载缓慢"故障,综合应用三维思考支架的复盘过程:
深度扫描
- 事件:接口P99延迟从200ms飙升至3s
- 模式:故障发生前48小时,缓存命中率呈"阶梯式下降",每6小时跌落5%
- 结构 :因果回路图揭示,是推荐算法AB实验 的缓存淘汰策略与营销弹窗的流量特征产生共振
- 心智:挑战"缓存策略应由开发团队独立决策"的假设,建立SRE参与的联合评审机制
广度对齐
- 利益相关者:AB实验平台、推荐算法团队、购物车开发、SRE、业务运营
- 影响链:运营调整弹窗策略 → 流量特征改变 → 缓存命中率下降 → 购物车性能劣化 → 转化率损失 → 运营预算削减
- 杠杆解:在AB实验平台增加"缓存影响评估"卡点,自动模拟新策略对下游核心链路的缓存压力
角度推演
- 时间延迟 :缓存淘汰策略生效延迟30分钟 ,与营销弹窗的实时调整节奏错配
- 环形演化:缓存命中率下降 → 数据库压力上升 → 慢查询增多 → 线程池阻塞 → 接口超时 → 用户重试 → 流量洪峰 → 缓存进一步失效
- 动态对策 :部署 "延迟感知"的熔断器 ,当缓存命中率低于阈值时,自动将推荐接口降级为默认策略,而非等待数据库崩溃
极简工具箱:AIOps系统思考五星检查清单
五星检查清单(可直接嵌入On-Call手册)
☆ 深度检查:结构信号捕获
#!/bin/bash
# 每日结构健康度扫描脚本(开源自阿里SRE实践)
# 运行时机:每日10:00,输出到钉钉群
echo "===== 深度扫描:识别调节回路失效信号 ====="
# 1. 告警压制率 > 30% 且 故障漏检率 > 5%
suppress_rate=$(promql 'sum(rate(alert_suppressed_total[1d])) / sum(rate(alert_total[1d])) * 100')
miss_rate=$(promql 'sum(increase(incident_missed_total[1d])) / sum(increase(incident_total[1d])) * 100')
if (( $(echo "$suppress_rate > 30 && $miss_rate > 5" | bc -l) )); then
echo "🚨 危险:告警压制过度,调节回路失效!建议立即复盘压制规则"
fi
# 2. 监控熵值持续为负的指标TOP10
echo "===== 低价值监控识别(熵值<-100)====="
mysql -e "SELECT metric_name, entropy FROM monitoring_entropy WHERE entropy < -100 ORDER BY entropy LIMIT 10"☆☆ 广度检查:跨域影响对齐
# 每周SLO对齐度评估(基于阿里SLO规范)
def check_slo_alignment():
"""
检查各利益相关方的SLO消耗是否匹配其责任权重
返回:失调度 > 20% 的部门列表
"""
slo_data = fetch_slo_consumption()
misalignment = []
for dept, config in slo_data.items():
actual_consumption = config['actual_error_budget'] / config['total_error_budget']
expected_consumption = config['responsibility_weight']
if abs(actual_consumption - expected_consumption) > 0.2:
misalignment.append({
'dept': dept,
'actual': f"{actual_consumption:.1%}",
'expected': f"{expected_consumption:.1%}",
'issue': "预算消耗与责任不匹配,需启动跨部门对齐"
})
return misalignment
# 输出结果直接触发周会讨论☆☆☆ 角度检查:延迟节奏匹配
# 延迟感知告警规则(Prometheus格式)
groups:
- name: delay_aware_alerts
rules:
# 物理延迟:弹性扩容超过3分钟未生效
- alert: ScalingDelayAbnormal
expr: (time() - kube_node_created) > 180 and node_cpu_utilization > 85
for: 2m
labels:
severity: critical
delay_type: physical_scaling
annotations:
summary: "扩容延迟异常,当前CPU{{ $value }}%,已触发SLO熔断"
# 认知延迟:AI根因分析建议超过10分钟未验证
- alert: AIVerificationOverdue
expr: (time() - ai_recommendation_timestamp) > 600 and ai_verification_status == 0
labels:
severity: warning
delay_type: cognitive
annotations:
summary: "AI建议验证超时,排障技能可能退化"结语:从工具驱动到思维驱动
AIOps的终极挑战,不是算法的精准度,而是人类能否以系统之眼看系统。三重思考维度分别破解了运维复杂性的关键症结:
- 深度:穿透告警表象,在结构层寻找杠杆解
- 广度:打破本位孤岛,在价值流中构建韧性
- 角度:超越静态阈值,在演化中驾驭节奏
首周行动清单:
- 周一:选择过去一周最疲劳的On-Call班次,用冰山模型写出四层诊断(事件→模式→结构→心智)
- 周三 :在团队周会中,用思考的罗盘 **®**画出你负责系统的三个利益相关方及其影响链
- 周五:针对一个高频告警,绘制其因果回路图,并标注至少两个时间延迟节点
进阶挑战 :在下一次架构评审中,强制要求展示新组件的因果回路图,并回答:"这个设计会增强哪个回路,抑制哪个回路?三个月后可能产生什么副作用?"
开放性问题:
- 你的AIOps系统中,哪个"增强回路"正在让事情变好,哪个"调节回路"又悄悄设置了成长上限?
- 如果只能保留30%的监控指标,你会选择哪些?这个选择揭示了你怎样的"心智模式"?
- 当AI给出的根因分析与你的直觉冲突时,你会如何设计实验来验证两者的反馈结构?
系统思考不是替代AIOps,而是为智能注入智慧。当工具开始思考结构,当工程师开始绘制回路,复杂性便不再是诅咒,而是可被设计的风景。