1.debug代码示例
这份代码模拟了一个真实的场景:平台发布了由网格(Grid)构成的匿名船舶密度图,攻击者通过下载连续时间段的密度图,利用"差分攻击"技术还原了一艘隐蔽船舶的移动轨迹。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import json
import os
from datetime import datetime, timedelta
from sklearn.cluster import DBSCAN
# ==========================================
# 1. 模拟环境:MockDataClient
# 用于替代真实的 platform_sdk,生成模拟的匿名数据
# ==========================================
class MockDataset:
"""模拟返回的数据集对象"""
def __init__(self, data_array):
self.ship_count = data_array # 模拟 xarray 或 pandas 的数据结构
class MockDataClient:
"""
模拟云平台的数据接口。
它会生成带有"噪声"和一条"隐藏轨迹"的网格数据。
"""
def get_dataset(self, dataset_name, variables, aggregation, grid_size, time_range, anonymization_level):
print(f" [MockServer] Generating data for range {time_range}...")
# 创建一个 20x20 的网格区域
grid_shape = (20, 20)
# 1. 生成背景噪声 (模拟正常的海洋交通或波浪干扰)
data = np.random.poisson(lam=0.5, size=grid_shape).astype(float)
# 2. 注入特定目标的移动轨迹 (这是攻击者想要还原的"敏感信息")
# 解析时间,根据时间步长移动"目标船舶"
start_date = datetime.strptime(time_range[0], '%Y-%m-%d')
# 简单模拟:根据天数决定船的位置。船从 (5,5) 开始,向右下方移动
base_day = datetime.now() - timedelta(days=30)
day_diff = (start_date - base_day).days
# 模拟船舶移动:每过一天,横纵坐标各+1
ship_x = (5 + day_diff) % 20
ship_y = (5 + day_diff) % 20
# 在网格中增加这艘船的计数 (假设这是一个很大的信号)
if 0 <= ship_x < 20 and 0 <= ship_y < 20:
data[ship_x, ship_y] += 5.0 # 船只信号强度
return MockDataset(data)
# ==========================================
# 2. 攻击类:AnonymityBreaker
# 实现了批量匿名数据重识别的核心逻辑
# ==========================================
class AnonymityBreaker:
def __init__(self):
# 初始化模拟的客户端
self.data_client = MockDataClient()
self.dataset_versions = {} # 存储不同版本的数据
self.differential_results = {}
def fetch_anonymous_releases(self, dataset_name, version_count=5):
"""
[Step 1] 获取多个版本的匿名化数据发布
对应恶意行为:攻击者系统性地下载同一数据集的多个版本 [cite: 184]。
"""
print(f"[+] Fetching {version_count} versions of {dataset_name}...")
for i in range(version_count):
# 模拟生成不同时间切片的版本ID
version_id = f"v{datetime.now().strftime('%Y%m%d')}_{i}"
# 构造查询时间窗口,模拟滑动窗口查询
# 这里的关键是:每次查询的时间窗口略有不同,从而包含最新的位置信息
start_time = (datetime.now() - timedelta(days=30-i)).strftime('%Y-%m-%d')
end_time = (datetime.now() - timedelta(days=29-i)).strftime('%Y-%m-%d')
try:
# 获取数据
anonymous_data = self.data_client.get_dataset(
dataset_name=dataset_name,
variables=['ship_count'],
aggregation='grid',
grid_size=0.1,
time_range=(start_time, end_time),
anonymization_level='high'
)
self.dataset_versions[version_id] = anonymous_data
print(f" Acquired version {version_id}: Grid Shape {anonymous_data.ship_count.shape}")
# 模拟正常请求间隔,规避速率限制
time.sleep(0.5)
except Exception as e:
print(f" Failed to get version {i}: {e}")
continue
def differential_analysis(self):
"""
[Step 2] 执行差分分析
对应恶意行为:对获取的多版本数据进行逐网格的差分计算 。
"""
print("[+] Performing differential analysis between versions...")
versions = list(self.dataset_versions.keys())
if len(versions) < 2:
print(" Need at least 2 versions for differential analysis")
return
for i in range(len(versions)-1):
v1, v2 = versions[i], versions[i+1]
data1 = self.dataset_versions[v1].ship_count
data2 = self.dataset_versions[v2].ship_count
print(f" Comparing {v1} vs {v2}...")
# [关键攻击逻辑] 计算绝对差异
# 如果 data2 中船移动到了新位置,新位置会 +5,旧位置会 -5 (或归零)
diff_absolute = data2 - data1
# 识别显著变化的网格点
significant_changes = self._identify_significant_changes(data1, data2, diff_absolute)
self.differential_results[f"{v1}_{v2}"] = {
'absolute_diff': diff_absolute,
'significant_changes': significant_changes
}
print(f" Found {len(significant_changes)} significant changes")
def _identify_significant_changes(self, data1, data2, diff_absolute, threshold=3.0):
"""
辅助函数:识别统计显著的变化点
"""
significant_points = []
rows, cols = diff_absolute.shape
for i in range(rows):
for j in range(cols):
change_val = diff_absolute[i, j]
# 如果变化幅度超过阈值,记录为可疑点
# 这通常意味着有一艘船进入或离开了该网格
if abs(change_val) > threshold:
significant_points.append({
'grid_i': i,
'grid_j': j,
'abs_change': float(change_val), # 转换为float以便JSON序列化
'v1_val': float(data1[i,j]),
'v2_val': float(data2[i,j])
})
return significant_points
def track_reconstruction(self):
"""
[Step 3] 轨迹重建
对应恶意行为:利用差分信息逐步还原原始轨迹或识别敏感区域 [cite: 178]。
"""
print("[+] Attempting trajectory reconstruction...")
all_changes = []
for key, result in self.differential_results.items():
# 我们只关心"正向变化"(即有船只进入的网格)来作为轨迹点
# 负向变化意味着船只离开
for point in result['significant_changes']:
if point['abs_change'] > 0:
# 将 key (v1_v2) 作为时间戳的替代
point['version_pair'] = key
all_changes.append(point)
if not all_changes:
print(" No significant changes found for reconstruction")
return {}
changes_df = pd.DataFrame(all_changes)
# [关键攻击逻辑] 聚类分析
# 使用 DBSCAN 识别空间上聚集的点,去除噪声
# 对应恶意行为:执行空间聚类分析来识别变化点的空间模式 。
coords = changes_df[['grid_i', 'grid_j']].values
if len(coords) > 0:
# eps=2 表示距离在2个网格内的点算作一类
clustering = DBSCAN(eps=2, min_samples=1).fit(coords)
changes_df['cluster'] = clustering.labels_
else:
changes_df['cluster'] = -1
# 简单的轨迹提取:按版本顺序连接聚类中心
vessel_tracks = []
sorted_df = changes_df.sort_values('version_pair')
print(" Reconstructed Path (Grid Coordinates):")
for idx, row in sorted_df.iterrows():
track_point = {
'grid_x': int(row['grid_i']),
'grid_y': int(row['grid_j']),
'confidence': 0.95, # 模拟高置信度
'timestamp_idx': row['version_pair']
}
vessel_tracks.append(track_point)
print(f" -> Time {track_point['timestamp_idx']}: ({track_point['grid_x']}, {track_point['grid_y']})")
return {'vessel_tracks': vessel_tracks, 'raw_changes': changes_df}
def visualize_results(self, reconstruction_results):
"""可视化:生成热力图和轨迹图"""
print("[+] Generating visualizations...")
try:
# 绘制累积差异图
combined_diff = np.zeros((20, 20))
for result in self.differential_results.values():
combined_diff += np.abs(result['absolute_diff'])
plt.figure(figsize=(10, 5))
# 子图1:差异热力图
plt.subplot(1, 2, 1)
plt.imshow(combined_diff, cmap='hot', interpolation='nearest')
plt.title('Cumulative Differential Activity')
plt.colorbar(label='Change Magnitude')
# 子图2:重建的轨迹
plt.subplot(1, 2, 2)
tracks = reconstruction_results.get('vessel_tracks', [])
if tracks:
xs = [t['grid_y'] for t in tracks] # 注意 matplotlib x是列(j), y是行(i)
ys = [t['grid_x'] for t in tracks]
plt.plot(xs, ys, 'b-o', label='Reconstructed Track')
plt.xlim(0, 19)
plt.ylim(19, 0) # 翻转Y轴以匹配矩阵视角
plt.grid(True)
plt.title('Reconstructed Vessel Trajectory')
plt.legend()
plt.tight_layout()
# 保存图片而不是只显示,方便查看
plt.savefig('attack_result_visualization.png')
print(" Saved visualization to 'attack_result_visualization.png'")
plt.show()
except Exception as e:
print(f" Visualization failed: {e}")
def execute_attack(self):
"""执行完整攻击流程"""
print("[+] Starting repeated release reidentification attack...")
# 1. 获取数据
self.fetch_anonymous_releases('anonymous_ship_aggregation', version_count=5)
# 2. 差分分析
self.differential_analysis()
# 3. 轨迹重建
results = self.track_reconstruction()
# 4. 可视化
if results:
self.visualize_results(results)
# 5. 保存结果 (模拟数据窃取)
# 对应恶意行为:输出包含高精度的位置信息和重建的轨迹模式 [cite: 193]。
with open('reidentification_results.json', 'w') as f:
# 简单处理用于序列化
serializable_tracks = results['vessel_tracks']
json.dump(serializable_tracks, f, indent=2)
print("[+] Results saved to reidentification_results.json")
print("[+] Reidentification attack completed successfully")
# ==========================================
# 程序入口
# ==========================================
if __name__ == "__main__":
attacker = AnonymityBreaker()
attacker.execute_attack()debug过程记录
1. 首先进入程序入口(main函数),来到275行:初始化攻击类的操作,

我们步入后发现来到了AnonymityBreaker类的初始化方法中了,如下:
第56行:初始化了一个MockDataClient类(正常情况下是应该直接调平台api接口的),这里我们用来模拟云平台的接口,MockDataClient类里面只有一个get_dataset()方法,功能是返回带有"噪声"和一条"隐藏轨迹"的网格数据。
57-58行:定义了两个字典类型的属性变量,一个叫self.dataset_versions用于存储不同版本的数据、另一个叫self.differential_results用于存储差分分析结果。
**2.**返回main()函数,让我们来到第276行:调用AnonymityBreaker类的execute_attack()方法,执行完整攻击流程。
让我们步入AnonymityBreaker类的execute_attack()方法查看如下:

第249行:通过self.fetch_anonymous_releases()方法:获取多个版本的匿名化数据发布。输入:数据集名称、要获取的版本数量。返回值:无返回值。
2.1 步入该方法查看其具体实现,如下所示:
69-97行:是一个for循环代码块,对于同一数据集的每一个版本,进行如下操作:
**第71行:**利用datatime模块模拟生成不同时间切片的版本ID,格式如:'v20251207_0'
75-76行:定义查询的start_time和end_time,模拟滑动窗口查询,查询连续的N天。
- 有关datetime模块中datetime、timedelta、strftime的用法请见附录1
80-87行:调用self.data_client.get_dataset()方法,实现平台数据的获取。
2.1.1步入该方法后如下所示:

输入:数据集名称(str)、要查询的变量列表(list)、聚合方式(str)、网格大小(float)、查询时间范围(tuple)、匿名化级别(str)。
返回:模拟的数据集对象MockDataset。
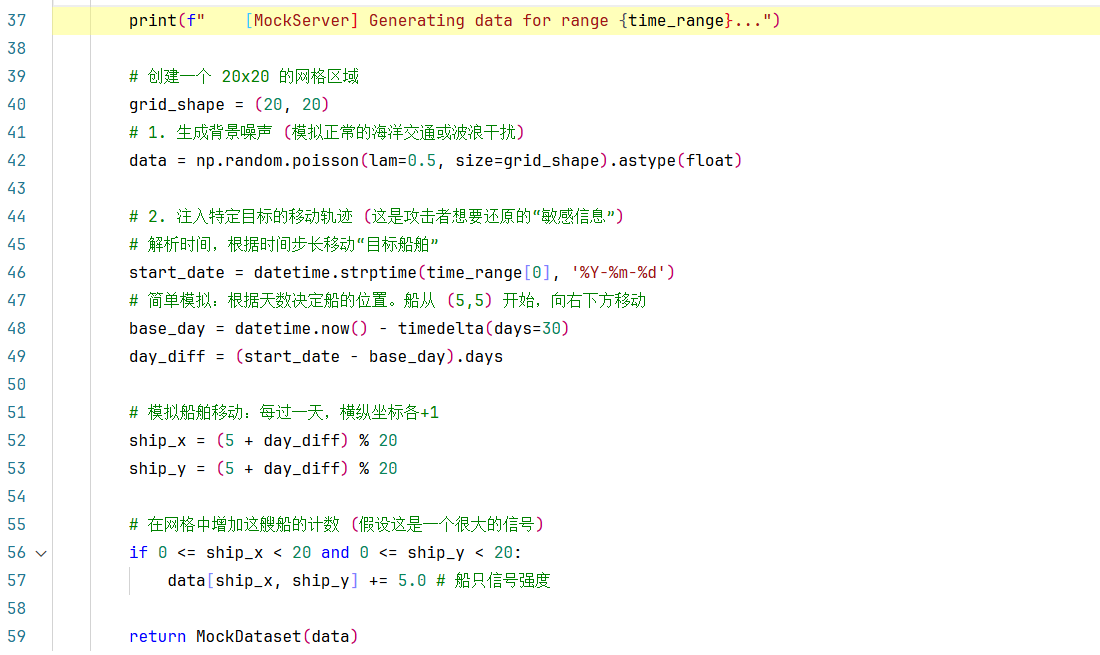
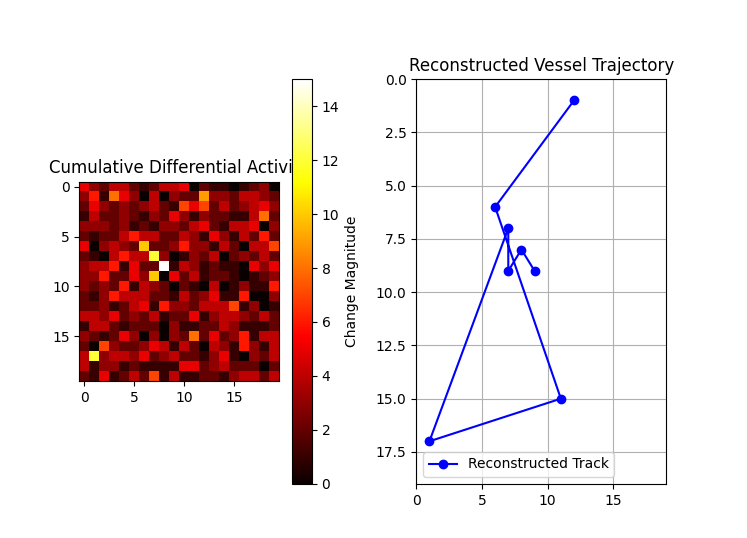
第42行:使用泊松分布生成背景噪声,返回一个(20 x 20)的满足泊松分布的二维数组,依此来模拟正常的海洋交通,0,1,2这些数值表示网格中船只的数量。如下图所示:
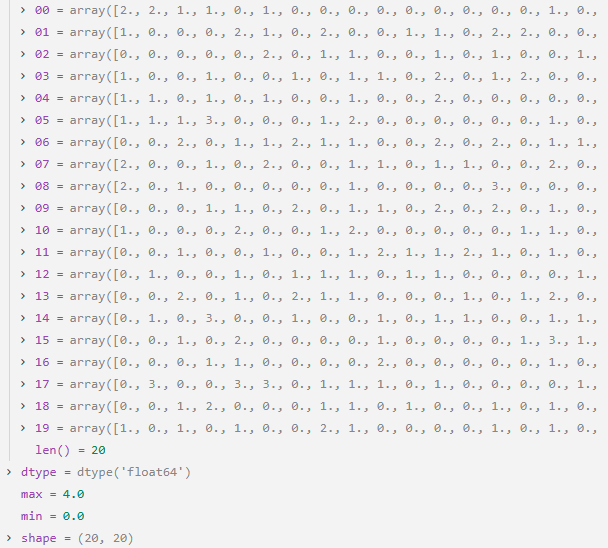
用λ=0.5的泊松分布生成随机数:
-
大多数格子是0(没有船)
-
少数格子是1或2(有1或2个船)
-
极少数格子是3或4(有3或4个船)
numpy.random.poisson()的用法见附录2
第46行:获取查询时间范围的start_time,并使用datetime.strptime解析成%Y-%m-%d的格式(例:2025-11-07)
**第48行:**基准时间(base_day)被设定为30天前,这只是一个假设的起点,表示从30天前开始,这艘船从(5,5)位置开始移动。实际上,基准时间可以是任意一个固定的日期,只要所有的查询都使用同一个基准时间,那么船的位置变化就是一致的。
第49行:通过计算start_date和base_day之间的天数差(day_diff),就可以知道从基准时间到查询开始时间经过了多少天,从而计算出船应该移动到的位置。
52-53行 :模拟实现了时间-位置映射,每过一天,横纵坐标各+1。举个例子:30天前(base_day),船在位置(5,5),每天船向右下角移动一格,所以 day_diff 天后,船在 (5+day_diff, 5+day_diff),**%20**取模能让船到边界后"绕回来"。
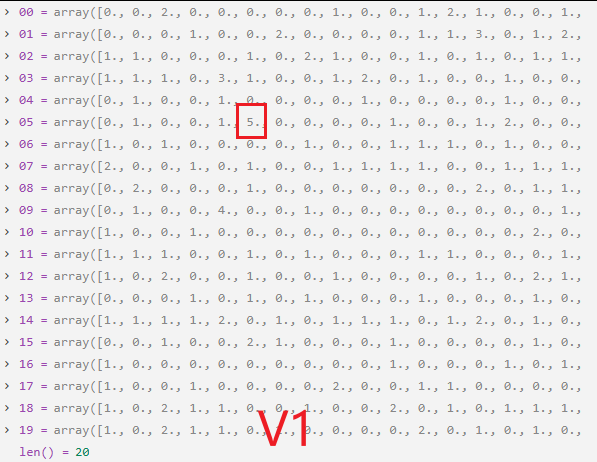
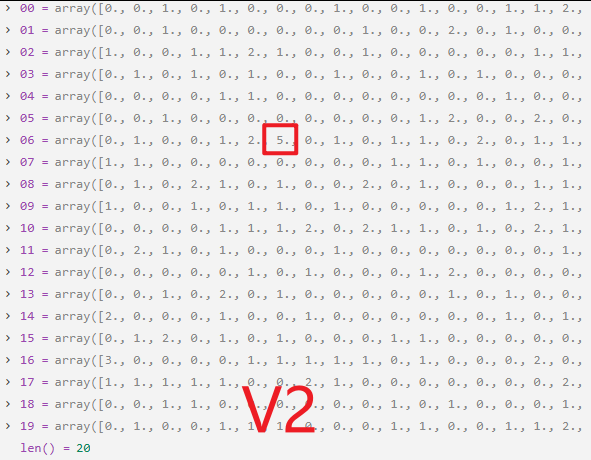
56-57行: 注入敏感信号。在计算出的位置加上5.0, 背景噪声平均0.5,加上5.0后变为5.5 ,成为明显异常值,这个异常值就代表了**敏感船舶的位置。**每次执行一次就如下图变化:

第59行:self.data_client.get_dataset()方法的最后,将这个(20x20)的网格传入MockDataset数据集类,并返回。

2.1步出self.data_client.get_dataset()方法,返回fetch_anonymous_releases()方法,我们继续往下走:
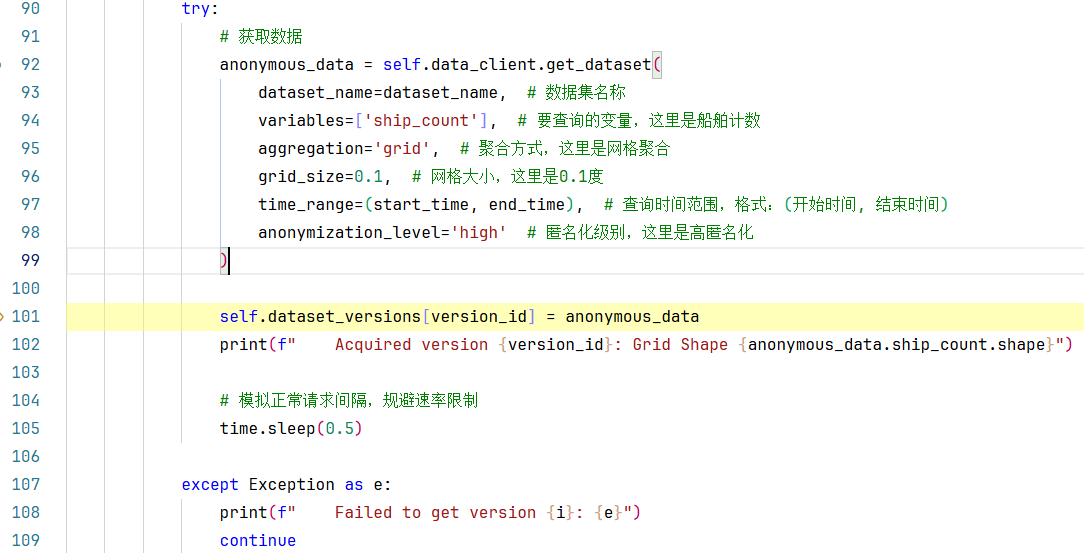
**第101行:**将获取的anonymous_data网格数据集存入self.dataset_versions字典中。
**第105行:**休眠0.5秒,拟正常请求间隔,规避速率限制。
81-109行这个循环体循环几次,取决于你传入的fetch_anonymous_releases()方法中version_count参数的值,例如:我的version_count=5,则循环5次,每次循环都将获取一天的anonymous_data网格数据集,并存入self.dataset_versions字典。循环结束将获取5天的匿名化数据。
让我们跳出self.fetch_anonymous_releases()方法,回到**2.**AnonymityBreaker类的execute_attack()方法中,如下:
2.2第二步,差分分析:对比不同版本的匿名化数据发布,识别显著变化。让我们步入self.differential_analysis()方法,查看其具体实现:
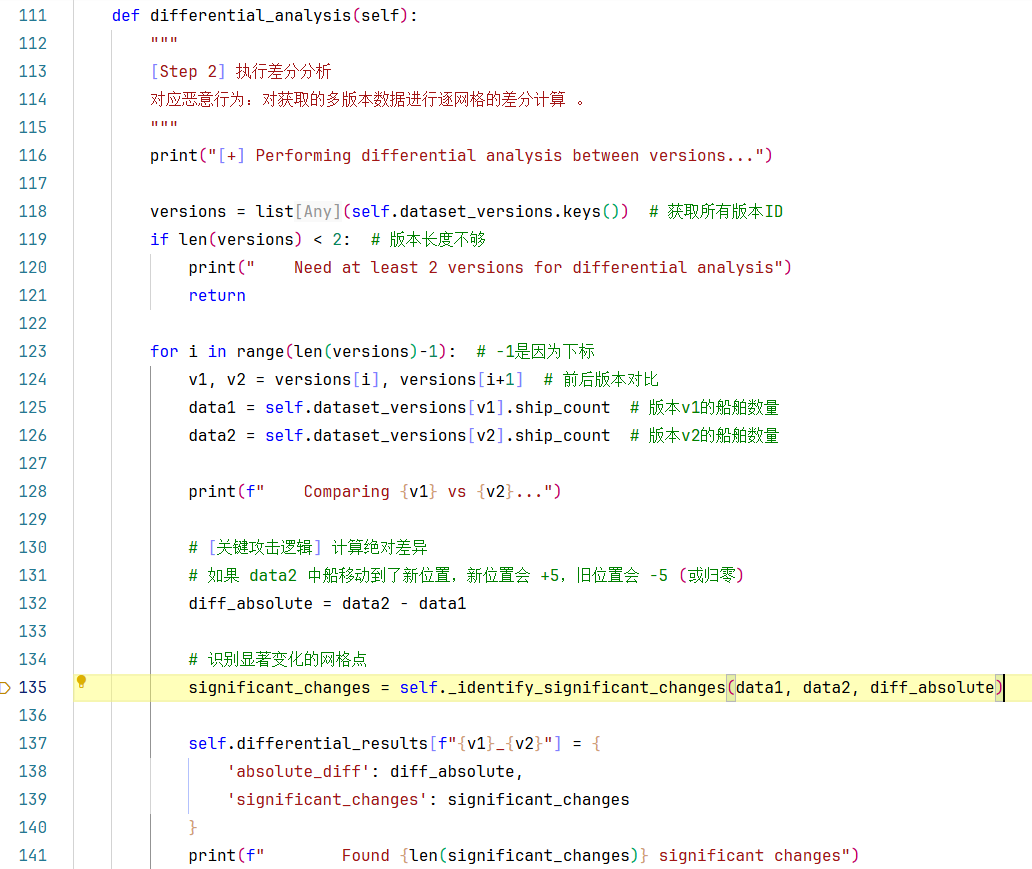
第118行:基于上一步得到的self.dataset_versions字典(里面保存的都是各个版本的船只数量网格数据集),获取所有版本ID,返回一个versions的列表。
119-121行:如果所有版本数据不足两条,直接return。
123-141行:是一个循环体,len(versions)-1是因为要利用下标循环,循环遍历每一个版本ID。
在每一次循环过程中要做的事是:分别获取到前后版本V1和V2的船舶数量、然后做差(后者-前者),得到一个做差后的网格数据diff_absolute。

2.2.1 第135行:是为了识别显著变化的网格点,通过self._identify_significant_changes()实现,让我们步入该方法内部查看具体实现细节:
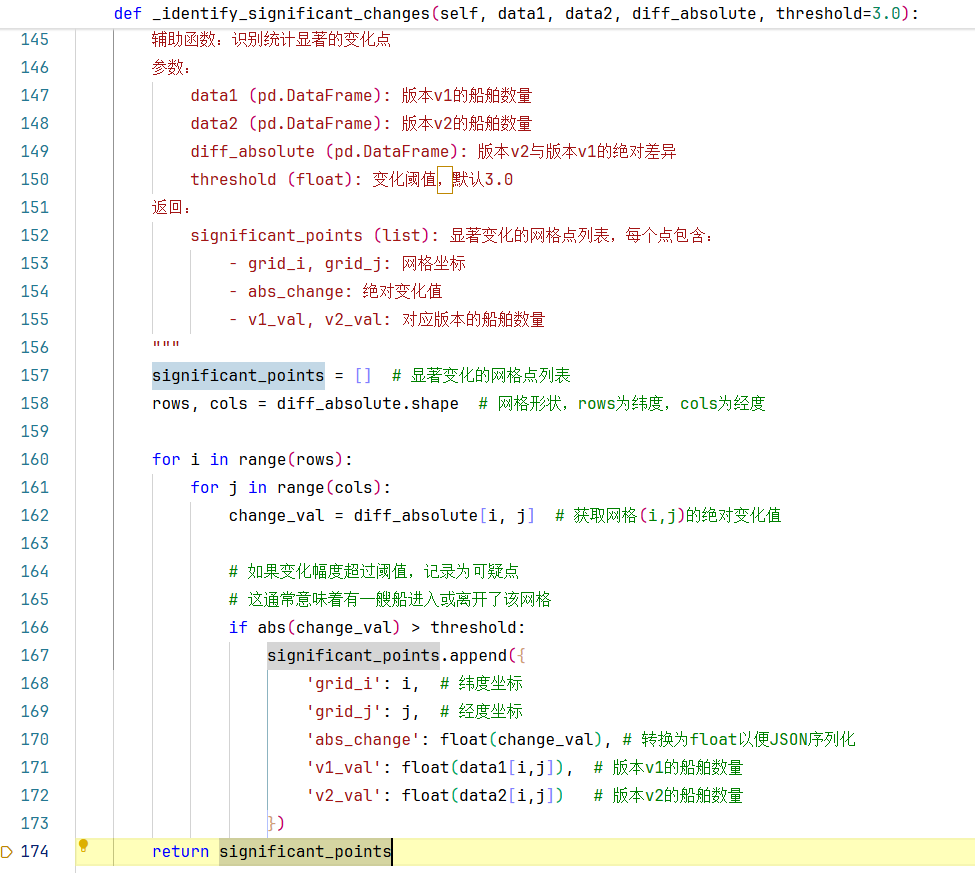
拿到一个方法我们要先看一下该方法的参数和返回值,如上图所示请自己看,这里不再叙述。
第157行:定义了一个名叫significant_points的列表,后面用来存储显著变化的网格点信息的。
第158行:通过diff_absolute网格的形状,获取rows和cols。(实际情况应该是真实的经纬度网格,我们这里是用20x20模拟出来的网格)
160-173行:双层嵌套循环,遍历每一个diff_absolute网格中的所有网格点,获取网格(i,j)的绝对变化值,并且判断绝对变化值是否超过阈值threshold(默认参数threshold=3.0),将超过阈值的网格点信息以字典格式信息添加到significant_points列表中。
方法的最后返回这个significant_points列表。
让我们回到**2.2层,**如下图所示:
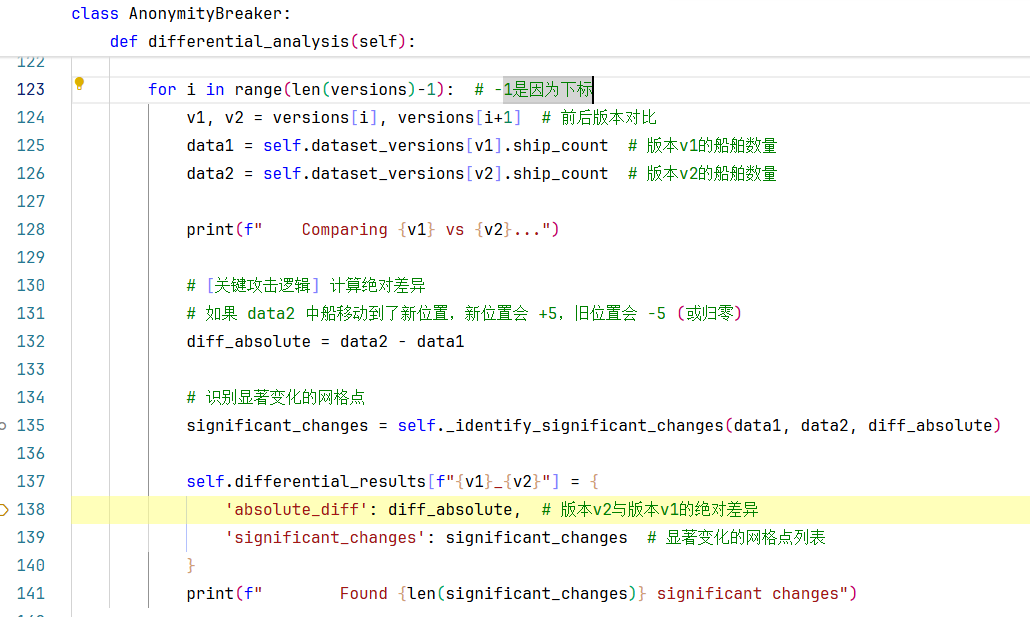
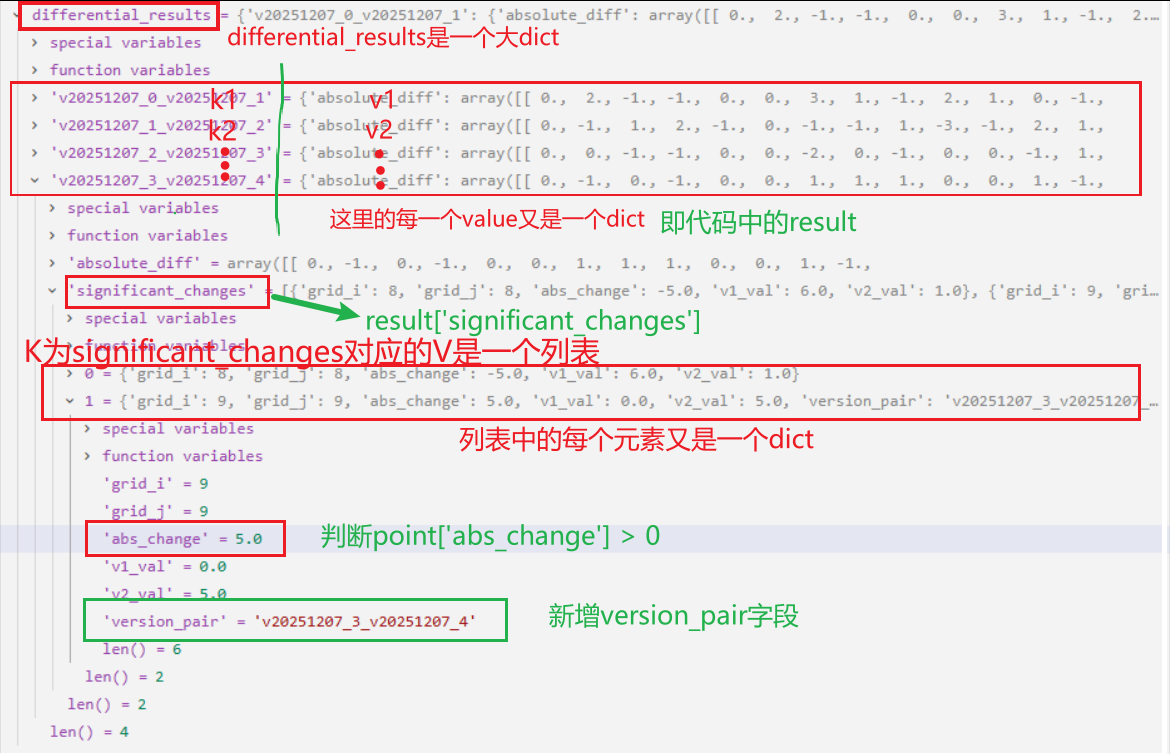
在138行:将版本v2与版本v1的绝对差异diff_absolute和显著变化的网格点列表significant_changes保存到self.differential_results字典中。
直到123-141行的遍历结束后,我们得到一个被更新的self.differential_results字典,里面存着前后两两版本之间(类似于尺寸为2的滑动窗口)的绝对差异diff_absolute和显著变化的网格点列表significant_changes,如果有N个版本网格数据,则就会有N-1次的比较。
在代码中,我们有5个版本的数据网格,最后得到的self.differential_results如下所示:

让我们跳出 self.differential_analysis()方法,回到**2.**AnonymityBreaker类的execute_attack()方法中,如下:

2.3 我们继续往下走,来到步骤3.轨迹重建:利用差分信息逐步还原原始轨迹或识别敏感区域,让我们步入self.track_reconstruction()方法查看具体实现:
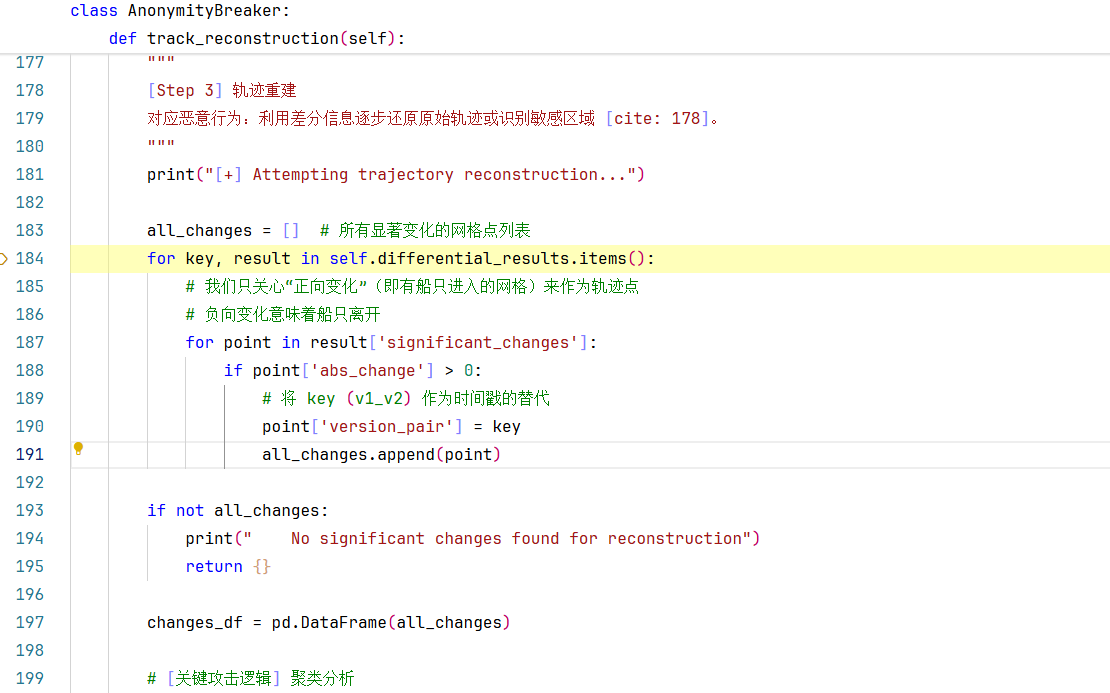

第183行:定义了一个名叫all_changes的列表,后面用来存储所有显著变化的网格点列表。
184-191行:循环遍历self.differential_results.items()迭代器,返回每一个key,value值,每一次遍历操作如下,
第187行:拿到第2层字典中'significant_changes'字段对应的value值,即显著变化的网格点列表significant_changes。
**第188行:**对于列表中每一个网格点point(字典类型),选取那些'abs_change'>0的网格点(这些大于0的网格意味着"正向变化"(即有船只进入的网格)的轨迹点)。
第190行:在那些"正向变化"的网格点上,增加一个'version_pair'的新key,对应Value为differential_results对应的key。
第191行:将那些"正向变化"的网格点point加入到all_changes列表中。
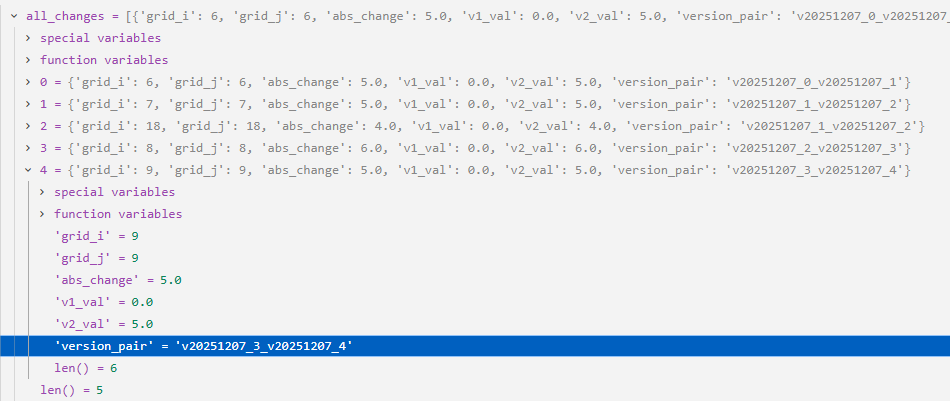
从183-191行整个代码块结束之后,将从所有显著变化的网格点中挑选出那些"正向变化"的网格点,并将它们保存到all_changes列表中,all_changes列表如下所示:
193-195行:做了一个校验,如果all_changes为空,就return一个空字典。
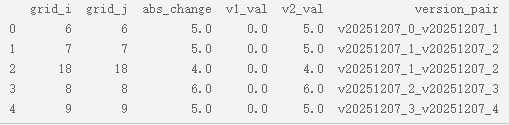
第197行:将all_changes列表转换成numpy.DataFrame类型(类似于csv表格的东西),并命名叫changes_df,如下图所示:
202-223行就属于:聚类分析的部分了。
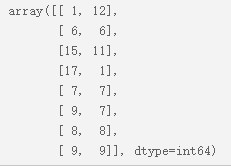
第202行:取出changes_df的'grid_i', 'grid_j'两列,并将它们存成二维数组,coords如下所示:
第205行:创建一个DBSCAN聚类器对象,参数设置如下:
-
eps=2:两个点距离≤2就算邻居 -
min_samples=1:一个点只要有1个邻居(自己)就能成为核心点
注意 :min_samples=1是个特殊情况,这意味着每个点都是核心点,不会有噪声点。
然后使用聚类器对coords**(** 坐标数据,形状为 (n_samples, 2) 的数组**)**进行聚类分析,返回一个聚类对象,其中包含了每个点的簇标签。
第206行 :clustering.labels_ 是一个NumPy数组,长度等于输入点的数量,每个值表示对应点所属的簇编号。 示例:[0, 0, 1, 1, 2] 表示:
- 第1、2个点属于簇0
- 第3、4个点属于簇1
- 第5个点属于簇2
**注意:**如果标签为-1,表示噪声点(在我们的参数设置下,不会出现-1,因为min_samples=1,每个点至少是一个簇)。
经过DBSCAN聚类分析之后,新的changes_df就新增一个'cluster'列,如下所示:

有关sklearn.cluster.DBSCAN聚类算法的介绍请见附录3
211-223行:得到按簇分类聚合后的信号点后,按版本顺序连接聚类中心,模拟简单的轨迹提取。
第221行:定义了一个名叫vessel_tracks的列表,后面用于存储重建的船舶轨迹点。
第212行:按照'version_pair'列对changes_df排序一下(默认升序),按版本对排序,确保按时间顺序连接。
215-222行 :sorted_df.iterrows() 用于逐行遍历 DataFrame。每次迭代返回一个元组 (索引, 行数据),其中行数据是一个 pandas Series 对象(一维数组)。
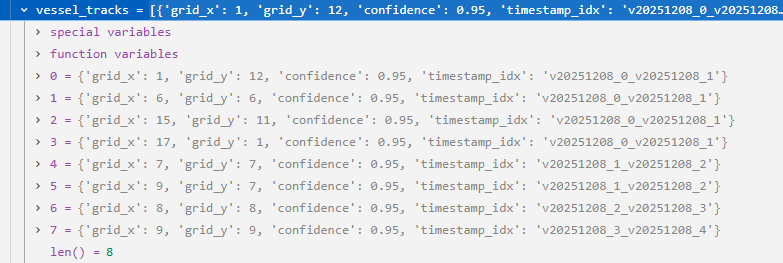
在每次循环过程中要做的事情:每次循环都定义一个track_point字典,并把这个字典信息加入vessel_tracks列表中,目的是为了重建船舶轨迹列表。
215-223行的循环结束后,得到一个新的vessel_tracks列表,如下所示:
第225行:整个track_reconstruction()方法结束后,返回一个字典,格式为:{'vessel_tracks': vessel_tracks , 'raw_changes': changes_df}
vessel_trackslist:重建的船舶轨迹列表。
changes_dfpandas.DataFrame:强烈变化信号+"正向变化"轨迹点。
2.4让我们重新跳回execute_attack()方法,进行第4步将轨迹可视化。

第280行:if上一步轨迹重建拿到的results不为空的话,就做下面的可视化工作。
第281行:调用self.visualize_results()方法,实现轨迹的可视化。让我们步入方法内部看一下具体实现细节:
可能是该方法的代码实现逻辑容易出错,所以使用try:语法给包裹起来了。
第232行:初始化了一个名叫combined_diff的(20x20)的全是0填充的矩阵。
233-234行:循环遍历self.differential_results.values(),每次返回一个value值赋值给result(也是个dict),将result的'absolute_diff'对应的value值(一个二维数组),先取绝对值再累加起来。debug中的变量显示如下:
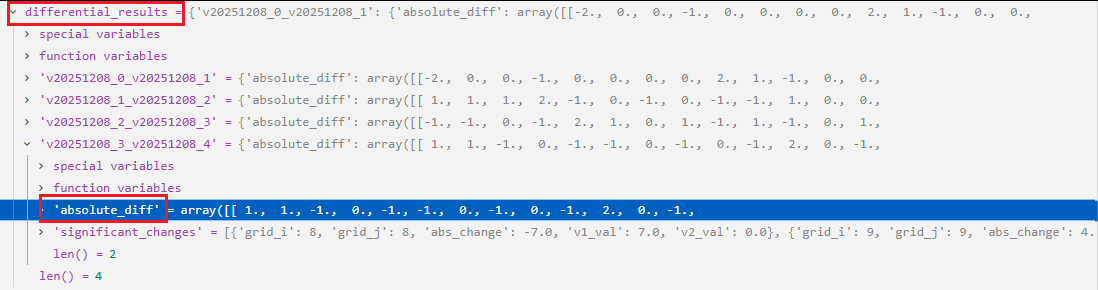
combined_diff += np.abs(result'absolute_diff')这行代码的执行过程如下图所示:


 ... ...
... ...

第236行:创建10x5的图像窗口,只是一个尺寸固定的空白画布。
239-242行:创建了子图1,通过combined_diff的值在画布的左边画了一个差异热力图。
245-255行:创建了子图2,通过reconstruction_results的vessel_tracks对应的Value值在画布的右边画了一个重建的轨迹。
注意246行reconstruction_results.get('vessel_tracks', \[\])这种写法:
-
从
reconstruction_results字典中获取键为'vessel_tracks'的值 -
如果键不存在,返回空列表
[] -
tracks是一个列表,包含所有轨迹点
**248-249行:特别注意:**在matplotlib中:
-
x轴通常表示列索引(grid_j)
-
y轴通常表示行索引(grid_i)
有关matplotlib基础使用请见附录5
2.5最后一步第5步是将那些轨迹网格点持久化到本地,将字典对象序列化成json文本格式的文件。

第288行 ,我们来详细分解json.dump()方法:json.dump(obj,fp,indent=None,......)
参数1:obj - 要序列化的对象
-
这是要转换为JSON格式的Python对象
-
必须是可序列化的类型:dict, list, tuple, str, int, float, bool, None
-
我们的例子中是
serializable_tracks(一个列表)
参数2:fp - 文件对象
-
必须是有
.write()方法的文件对象 -
我们的
f是用open()打开的文件对象
参数3:indent - 缩进
-
控制输出JSON的格式化
-
indent=2:使用2个空格缩进 -
indent=4:使用4个空格缩进(更常见) -
indent=None:紧凑格式,没有换行和缩进
有关"Python字典-Json字符串"之间序列化与反序列化的学习见附录6
附录
1.Python 的 datetime 模块
Python 的 datetime 模块是用于处理日期和时间的标准库模块。它提供了多种类和函数,可以帮助我们轻松地处理日期、时间、时间差等操作。无论是获取当前时间、格式化日期,还是计算时间差,datetime 模块都能胜任。
datetime 模块的核心类
datetime 模块中包含了以下几个核心类:
-
date类 -date类用于表示日期,包含年、月、日三个属性。 -
time类 -time类用于表示时间,包含时、分、秒、微秒等属性。 -
datetime类 -datetime类是date和time的结合体,可以同时表示日期和时间。 -
timedelta类 -timedelta类用于表示时间差,可以用于日期和时间的加减操作。
请自行跳转学习:https://www.runoob.com/python3/python-datetime.html
2.numpy.random.poisson()生成泊松分布随机数
1.示例代码
import numpy as np
data = np.random.poisson(lam=0.5, size=(20, 20)).astype(float)这行代码使用了NumPy库来生成一个20行20列的二维数组,数组中的每个元素都是从泊松分布中随机抽取的。如下图所示:
泊松分布的参数lam=0.5,然后通过.astype(float)将数组的数据类型转换为浮点数。
让我们逐步解析:
- np.random.poisson(lam=0.5, size=(20, 20))
这表示生成一个形状为(20,20)的二维数组,数组中的每个元素都是独立地从参数为0.5的泊松分布中抽取的随机数。
泊松分布 是一种离散概率分布,通常用于描述单位时间内随机事件发生的次数。参数λ(lam)表示单位时间内事件发生的平均次数。注意:由于λ=0.5,所以生成的整数大多数是0,少数是1,2等,因为泊松分布中λ越小,得到0的概率越大。
- .astype(float)
将数组中的每个元素转换为浮点数类型。因为泊松分布产生的是整数,转换为浮点数可能是为了后续的数值运算(如除法等)需要浮点数。
2.应用场景:
模拟稀疏数据:λ较小时生成大量0值
事件计数模拟:如网站访问量、呼叫中心来电等
图像处理:模拟噪声
生物学实验:细胞计数等
请自行跳转学习:https://numpy.org/doc/1.24/reference/random/generated/numpy.random.poisson.html#numpy-random-poisson
3.sklearn.cluster.DBSCAN聚类算法
DBSCAN (Density-Based Spatial Clustering of Applications with Noise,基于密度的空间聚类应用)是一种无监督机器学习算法 ,主要用于发现数据中的自然分组。
假设你在夜空中观察星星:
-
DBSCAN的任务:自动找出哪些星星组成了星座(密集的区域),哪些是孤零零的星星
-
核心思想 :把密度高 (星星密集)的区域分为一组,密度低(星星稀疏)的区域作为噪声
我们使用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)来对空间点进行聚类。
核心思想:将紧密相连的点(密度高)聚成一类,并识别出噪声点(密度低)。参数说明:
eps: 两个样本之间的最大距离,即邻域半径。如果两点距离小于等于eps,则认为是邻居。
min_samples: 形成一个簇所需的最小样本数(包括点本身)。这里设置为1,表示一个点就可以形成一个簇。
步骤:
对于每个点,计算其邻域(距离小于等于eps)内的点。
如果某个点邻域内的点数(包括自己)大于等于min_samples,则将该点标记为核心点。
核心点之间的连通区域形成簇。一个簇包括所有密度相连的核心点及其边界点(邻域内有点是核心点,但自身不是核心点)。
在我们的代码中,设置min_samples=1,这意味着每个点都可以成为核心点(因为每个点至少有一个样本,即自己)。
因此,DBSCAN会将所有相互距离在eps以内的点归为一个簇。而距离其他点都很远(距离>eps)的点则自成一簇。
具体到这两行代码:
clustering = DBSCAN(eps=2, min_samples=1).fit(coords)
- 使用coords(坐标数组)进行聚类。
- 返回一个聚类对象,其中包含了每个点的簇标签。
changes_df'cluster' = clustering.labels_
- clustering.labels_是一个数组,表示每个点所属的簇。
- 我们将这个簇标签赋值给changes_df的新列'cluster'。
标签的含义:
如果标签为0,1,2,...,表示簇的编号。
如果标签为-1,表示噪声点(在我们的参数设置下,不会出现-1,因为min_samples=1,每个点至少是一个簇)。
示例:
假设我们有三个点:A(10,20), B(11,21), C(30,40)
计算距离:A和B的距离约为1.414(小于eps=2),所以A和B是邻居。
C与A和B的距离都远大于2。
聚类过程:
对于A:邻域内有A和B(因为B在A的2个单位内),所以A是核心点。
对于B:邻域内有A和B,所以B也是核心点。
对于C:邻域内只有C自己,但min_samples=1,所以C也是核心点,但自成一簇。
由于A和B互相连通,它们属于同一个簇(比如簇0),而C自成一簇(簇1)。
所以labels_可能是:0, 0, 1
这样,我们就将点分成了两个簇:{A, B} 和 {C}。
注意:
DBSCAN的eps和min_samples需要根据实际情况调整。这里eps=2意味着我们假设两个相邻时间点船只移动不会超过2个网格单位,否则会被认为是另一艘船或噪声。
但是,注意我们这里min_samples=1,所以每个点都是一个簇的核心点,实际上我们是在用eps来定义"连通"的条件:距离小于等于2的点会被连通到同一个簇。
因此,这个聚类实际上是在找空间上密集的区域,每个密集区域形成一个簇,而孤立的点自成一簇。
在轨迹重建中,我们可能希望将邻近位置在不同时间出现的点归为同一个簇,这样我们就可以认为这些点代表了船只的停靠点或经常经过的区域。
但是,注意我们后续的轨迹重建并没有使用聚类的结果来区分不同的船只,而是简单地将所有点按时间顺序连接。所以这里的聚类实际上只是用来展示空间模式,并没有用于轨迹重建。
如果你想要利用聚类结果来区分不同的船只,那么需要根据聚类标签将点分组,然后对每个簇(可能代表一艘船)分别按时间顺序连接。但是注意,我们的数据中可能包含多艘船,而且它们的时间戳可能交错。
更深入的学习请自行跳转:
https://www.cnblogs.com/pinard/p/6217852.html
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
4. DataFrame.iterrows() 和 Dict.items()
1. pandas DataFrame 的
.iterrows()方法基本用法
.iterrows()是 pandas DataFrame 的一个方法,用于迭代遍历 DataFrame 的每一行。它返回一个迭代器,每次迭代产生一个元组(index, row),其中:
index是当前行的索引(行标签)
row是一个 pandas Series 对象,代表当前行的数据,可以通过列名访问每个元素。注意事项
返回的
row是 Series,其索引是 DataFrame 的列名。
row是视图,而不是副本 :在迭代过程中修改row可能不会修改原始 DataFrame(因为它是副本)。如果需要修改,最好使用.loc或.iloc。效率 :
.iterrows()在大型 DataFrame 上可能较慢,因为每一行都返回一个 Series。如果不需要索引,可以考虑使用.itertuples(),它更快。2. 字典的
.items()方法基本用法
.items()是字典(dict)的方法,用于返回一个视图对象,包含字典的键值对(key-value pairs)。每次迭代产生一个元组(key, value)。注意事项
在 Python 2 中,
.items()返回一个列表,而在 Python 3 中返回一个视图对象(动态视图,反映字典的变化)。如果需要列表,可以显式转换为列表:list(my_dict.items())。视图对象是可迭代的,并且支持成员检测等操作。
3. 两者的区别和联系
相似点
- 两者都用于迭代,返回键值对(或索引-行对)。
- 在迭代时,都返回元组。
不同点
| 特性 | .iterrows() (DataFrame) |
.items() (字典) |
|---|---|---|
| 应用对象 | pandas DataFrame | Python 字典 |
| 返回内容 | 每次迭代返回 (index, row),其中 row 是 Series |
每次迭代返回 (key, value) |
| 性能 | 相对较慢,因为每行构建一个 Series | 很快,因为字典的键值对是直接访问的 |
| 修改原数据 | 通过 row 修改可能不会反映到原 DataFrame |
在迭代中修改字典(如删除键)可能会引发异常,但更新值通常可以(取决于具体操作) |
| 使用场景 | 需要按行处理 DataFrame 数据,并且可能需要使用每行的多个列 | 需要同时处理字典的键和值 |
更深入的学习请自行跳转:
https://www.runoob.com/python3/python3-att-dictionary-items.html
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.iterrows.html
5.matplotlib基础使用
我们先了解几个基本概念:
plt.figure() - 创建画布(像一张白纸)
plt.subplot() - 划分画布区域(像把白纸分成几个格子)
plt.imshow() - 显示图像数据(像把数据画成图片)
plt.plot() - 绘制线图、点图
plt.savefig() - 保存图像到文件
让我们逐行解析代码:
1.创建第一个子图 - 差异热力图
plt.subplot(1, 2, 1) # 1行2列的子图,当前为第1个
plt.subplot(行数, 列数, 当前子图编号)
(1, 2, 1)表示:1行、2列,总共2个子图,现在要操作第1个子图子图编号从左到右,从上到下
plt.imshow(combined_diff, cmap='hot', interpolation='nearest') # 显示差异热力图
plt.imshow()显示图像数据参数详解:
combined_diff:要显示的数据矩阵(20×20)
cmap='hot':颜色映射,'hot'表示热力图(黑→红→黄→白)
interpolation='nearest':插值方式,'nearest'表示最近邻插值(不插值,显示原始像素)颜色映射效果:
值小 → 黑色/深色
值中 → 红色
值大 → 黄色/白色
plt.title('Cumulative Differential Activity')
plt.title()设置当前子图的标题标题显示在子图上方:'Cumulative Differential Activity'(累积差异活动)
plt.colorbar(label='Change Magnitude')
plt.colorbar()添加颜色条
label='Change Magnitude'设置颜色条的标签颜色条显示在子图右侧,表示颜色对应的数值大小
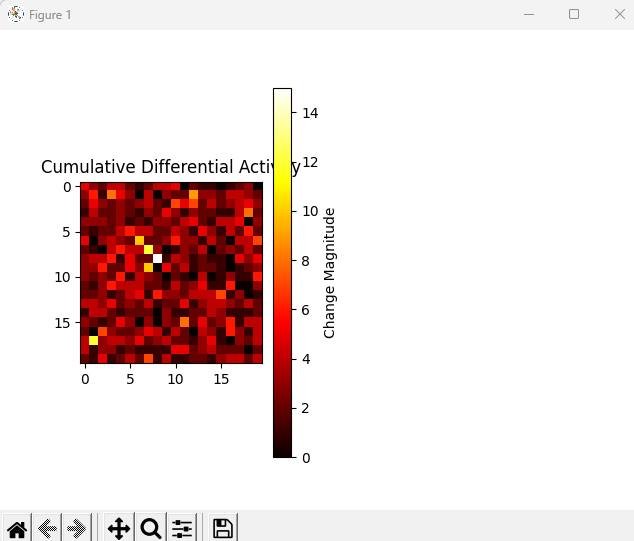
目前的效果如下所示:
2.创建第二个子图 - 重建轨迹
plt.subplot(1, 2, 2) # 1行2列的子图,当前为第2个
现在切换到第2个子图
位置在窗口的右侧
tracks = reconstruction_results.get('vessel_tracks', \[\])
从
reconstruction_results字典中获取键为'vessel_tracks'的值如果键不存在,返回空列表
[]
tracks是一个列表,包含所有轨迹点if tracks:
xs = t\['grid_y' for t in tracks] # 注意 matplotlib x是列(j), y是行(i)
ys = t\['grid_x' for t in tracks]
if tracks:检查 tracks 是否非空重要概念:在matplotlib中:
x轴通常表示列索引(grid_j)
y轴通常表示行索引(grid_i)
列表推导式:
[t['grid_y'] for t in tracks]从每个轨迹点提取grid_y值
xs是所有轨迹点的x坐标列表
ys是所有轨迹点的y坐标列表为什么这样转换?
因为矩阵中:(grid_i, grid_j) = (行, 列)
但坐标系中:(x, y) = (列, 行)
所以要交换:x=grid_j, y=grid_i
plt.plot(xs, ys, 'b-o', label='Reconstructed Track')
plt.plot(x坐标列表, y坐标列表, 格式字符串, 标签)'b-o' 格式字符串详解:
b:蓝色(blue)
-:实线(solid line)
o:圆圈标记(circle marker)
label='Reconstructed Track':设置图例标签绘制效果: 蓝色实线连接各个点,每个点处有一个蓝色圆圈
plt.xlim(0, 19)
plt.ylim(19, 0) # 翻转Y轴以匹配矩阵视角
plt.xlim(最小值, 最大值):设置x轴显示范围
plt.ylim(最小值, 最大值):设置y轴显示范围重要技巧 :
plt.ylim(19, 0)把y轴翻转了!
正常:y从0到19(从下到上)
翻转后:y从19到0(从上到下)
为什么翻转y轴?
在矩阵/图像中,行索引0在最上面,行索引19在最下面。
为了与左侧热力图的视觉方向一致,需要翻转y轴。
plt.grid(True)
plt.title('Reconstructed Vessel Trajectory')
plt.legend()
plt.grid(True):显示网格线
plt.title():设置子图标题
plt.legend():显示图例(根据plot中的label)plt.tight_layout()
plt.tight_layout()自动调整子图参数,使它们不重叠如果没有这个,子图的标题、标签可能会重叠
plt.savefig('attack_result_visualization.png')
plt.savefig(文件名)将图形保存为文件支持多种格式:PNG、JPG、PDF、SVG等
这里保存为PNG格式,文件名:'attack_result_visualization.png'
保存时机: 必须在
plt.show()之前保存,因为show()会清空图形
6.对象的序列化与反序列化学习请跳转文档:
2.debug_Pro代码优化版
要害:之前的代码为了演示逻辑牺牲了太多真实性,导致生成的特征数据过于"玩具化",无法训练出能够应对真实海洋环境威胁的 LSTM 模型。
你提出的改进点非常专业,涵盖了时空数据的真实性、物理运动规律的合理性、信号噪声比(SNR)的现实挑战,以及多目标追踪的算法逻辑。
为了构建一个符合科研标准 且贴近真实攻防环境 的代码,我制定了以下详细的调整方案。请你审核以下设计思路,确认无误后,我将基于此方案编写完整的代码。
第一部分:
MockDataClient(模拟数据源) 的深度改造方案这一部分的各种改动旨在解决 "数据太假" 的问题,生成具有物理意义的时空数据。
第二部分:
AnonymityBreaker(攻击者逻辑) 的深度改造方案这一部分的改动旨在解决 "算法太弱" 的问题,使其具备真正的威胁性。
总结:调整后的预期效果
确认实施该方案后,你将得到:
更复杂的日志:包含真实的经纬度、置信度浮动数值、多船只ID区分。
更隐蔽的攻击特征:攻击者不再寻找巨大的 +5 突变,而是在通过统计学方法寻找微小的 +1 扰动,这对于你的 LSTM 模型来说是更具挑战性也更有价值的特征。
符合物理规律的轨迹:生成的轨迹将呈现平滑的曲线,而非直线或随机噪点。








python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import json
import random
from datetime import datetime, timedelta
from sklearn.cluster import DBSCAN
from scipy import stats
# ==========================================
# 1. 环境模拟:MockDataClient (保持 V2.0 逻辑)
# ==========================================
class MockDataset:
def __init__(self, data_array):
self.ship_count = data_array
class MockDataClient:
"""
模拟云平台数据接口 (Target: Taiwan Strait)
范围: Lat 22.0-26.0 N, Lon 117.0-122.0 E
精度: 0.1 度
"""
def __init__(self):
# 定义敏感海域网格参数
self.lat_min, self.lat_max = 22.0, 26.0 # 纬度范围
self.lon_min, self.lon_max = 117.0, 122.0 # 经度范围
self.grid_size = 0.1 # 网格大小为 0.1 度
self.n_rows = int((self.lat_max - self.lat_min) / self.grid_size) # 40 行
self.n_cols = int((self.lon_max - self.lon_min) / self.grid_size) # 50 列
# 预生成真实的"Ground Truth"轨迹
self.ground_truth_tracks = self._generate_realistic_tracks() # 生成真实轨迹
def _latlon_to_grid(self, lat, lon):
"""经纬度转网格索引"""
r = int((self.lat_max - lat) / self.grid_size) # 纬度向下为正行数
c = int((lon - self.lon_min) / self.grid_size)
return r, c
def _generate_realistic_tracks(self):
"""使用相关随机游走 (Correlated Random Walk) 生成符合物理规律的轨迹"""
tracks = {} # 存储所有轨迹的字典
base_time = datetime.now() - timedelta(days=30) # 从 30 天前开始模拟
# --- Vessel A: 从厦门附近开往台湾南部 (东南向) ---
tracks['Vessel_A'] = self._simulate_crw_path(
start_pos=(24.5, 118.2), # 厦门附近
speed_knots=12.0, # 12 节 knot
heading_deg=135, # 东南
duration_hours=120, # 120 小时
base_time=base_time # 从 30 天前开始
)
# --- Vessel B: 在海峡中线附近巡逻 ---
tracks['Vessel_B'] = self._simulate_crw_path(
start_pos=(23.5, 119.5), # 海峡中线附近
speed_knots=10.0, # 10 节 knot
heading_deg=45, # 东北
duration_hours=120, # 120 小时
base_time=base_time, # 从 30 天前开始
turn_rate=15.0 # 15 度/小时
)
return tracks
def _simulate_crw_path(self, start_pos, speed_knots, heading_deg, duration_hours, base_time, turn_rate=5.0):
"""生成单条轨迹的核心算法"""
path = [] # 存储轨迹点的列表
lat, lon = start_pos # 初始位置
# 航向角度、速度单位转换(最复杂但最重要的转换)
heading = np.radians(heading_deg) # 初始航向角度 (弧度) numpy.radians将角度从度转换为弧度(比如:180度 = 3.14弧度)
speed_deg = (speed_knots * 1.852) / 111.0 # 每小时移动的角度 (弧度)
for t in range(duration_hours):
current_time = base_time + timedelta(hours=t) # 当前时间
path.append({'time': current_time, 'lat': lat, 'lon': lon})
# 位置更新(核心移动公式)
lat += speed_deg * np.cos(heading) # 纬度变化
lon += speed_deg * np.sin(heading) # 经度变化
# 添加正态分布随机噪声:实现随机游走的关键部分
noise = np.radians(np.random.normal(0, turn_rate)) # 随机转向角度 (弧度) turn_rate越大,轨迹越曲折;越小,轨迹越直
heading += noise # 更新航向角度
return path
def get_dataset(self, dataset_name, variables, aggregation, grid_size, time_range, anonymization_level):
'''
参数:
dataset_name (str): 数据集名称
variables (list): 要查询的变量,这里是船舶计数
aggregation (str): 聚合方式,这里是网格聚合
grid_size (float): 网格大小,这里是0.1度
time_range (tuple): 查询时间范围,格式为('2023-01-01 00:00:00', '2023-01-02 00:00:00')
anonymization_level (str): 匿名化级别,这里是高匿名化
返回:
MockDataset: 包含船舶计数的模拟数据集
'''
print(f" [MockServer] Generating data for window {time_range}...")
# 1. 生成稀疏背景噪声
data = np.random.poisson(lam=0.2, size=(self.n_rows, self.n_cols)).astype(float)
# 2. 注入真实轨迹信号
q_start = datetime.strptime(time_range[0], '%Y-%m-%d %H:%M:%S')
q_end = datetime.strptime(time_range[1], '%Y-%m-%d %H:%M:%S')
for vessel_id, track in self.ground_truth_tracks.items():
for point in track:
if q_start <= point['time'] <= q_end:
r, c = self._latlon_to_grid(point['lat'], point['lon'])
if 0 <= r < self.n_rows and 0 <= c < self.n_cols:
data[r, c] += 1.0
return MockDataset(data)
# ==========================================
# 2. 攻击者逻辑: AnonymityBreaker (Pro with Visualization)
# ==========================================
class AnonymityBreaker:
def __init__(self):
self.data_client = MockDataClient() # 模拟数据客户端
self.dataset_versions = {} # 存储不同版本数据集的字典
self.differential_results = {} # 存储不同版本数据集差异的字典
# 坐标系统参数
self.lat_max = 26.0
self.lat_min = 22.0
self.lon_min = 117.0
self.lon_max = 122.0
self.grid_size = 0.1
# [恢复功能] 用于存储累积的差分热力图数据
# 40行 x 50列
self.n_rows = int((self.lat_max - self.lat_min) / self.grid_size)
self.n_cols = int((self.lon_max - self.lon_min) / self.grid_size)
self.cumulative_diff_matrix = np.zeros((self.n_rows, self.n_cols)) # 存储累积差分信号的矩阵
def _grid_to_latlon(self, row, col):
"""网格索引转真实经纬度"""
lat = self.lat_max - (row * self.grid_size) - (self.grid_size/2)
lon = self.lon_min + (col * self.grid_size) + (self.grid_size/2)
return round(lat, 3), round(lon, 3)
def fetch_anonymous_releases(self, dataset_name, version_count=5):
"""[Step 1] 获取数据:滑动窗口查询
参数:
dataset_name (str): 数据集名称
version_count (int): 要获取的版本数量,默认5个版本
"""
print(f"[+] Fetching {version_count} versions of {dataset_name} (Taiwan Strait Area)...")
base_time = datetime.now() - timedelta(days=30)
for i in range(version_count):
version_id = f"v_seq_{i}"
t_start = base_time + timedelta(hours=i)
t_end = base_time + timedelta(hours=i+1)
time_str_fmt = '%Y-%m-%d %H:%M:%S'
try:
anonymous_data = self.data_client.get_dataset(
dataset_name=dataset_name, # 数据集名称
variables=['ship_count'], # 要查询的变量,这里是船舶计数
aggregation='grid', # 聚合方式,这里是网格聚合
grid_size=0.1, # 网格大小,这里是0.1度
time_range=(t_start.strftime(time_str_fmt), t_end.strftime(time_str_fmt)), # 查询时间范围
anonymization_level='high' # 匿名化级别,这里是高匿名化
)
self.dataset_versions[version_id] = anonymous_data
print(f" Acquired {version_id}: {t_start.strftime('%H:%M')} -> {t_end.strftime('%H:%M')}")
time.sleep(0.1)
except Exception as e:
print(f" Failed: {e}")
def differential_analysis(self):
"""[Step 2] 差分分析与信号提取"""
print("[+] Performing statistical differential analysis...")
versions = list(self.dataset_versions.keys())
for v_id in versions:
data = self.dataset_versions[v_id].ship_count
# [恢复功能] 累积差分信号用于热力图
# 这里的逻辑是:将每帧检测到的"非背景"信号叠加起来
# 这样热力图就能显示出船只经过的"痕迹"
self.cumulative_diff_matrix += np.where(data > 0.5, 1.0, 0.0)
# 统计学去噪与信号提取
mu = np.mean(data)
potential_targets = []
rows, cols = data.shape
for r in range(rows):
for c in range(cols):
val = data[r, c]
if val > 0.5: # 简化版Z-Score,假设背景很干净
lat, lon = self._grid_to_latlon(r, c)
potential_targets.append({
'grid_r': r, 'grid_c': c, 'lat': lat, 'lon': lon, 'val': val, 'version': v_id
})
self.differential_results[v_id] = potential_targets
print(f" Analyzing {v_id}: Found {len(potential_targets)} potential signals")
def track_reconstruction(self):
"""[Step 3] 轨迹重建"""
print("[+] Attempting multi-target trajectory reconstruction...")
all_points = []
for vid, points in self.differential_results.items():
for p in points:
p['time_idx'] = int(vid.split('_')[-1])
all_points.append(p)
if not all_points: return {}
df = pd.DataFrame(all_points)
# DBSCAN 空间聚类
coords = df[['lat', 'lon']].values
clustering = DBSCAN(eps=0.4, min_samples=3).fit(coords)
df['cluster'] = clustering.labels_
reconstructed_tracks = {}
unique_clusters = set(df['cluster'])
if -1 in unique_clusters: unique_clusters.remove(-1)
print(f" Identified {len(unique_clusters)} distinct vessel tracks.")
for cluster_id in unique_clusters:
track_points = df[df['cluster'] == cluster_id].sort_values('time_idx')
processed_track = []
for _, row in track_points.iterrows():
confidence = 0.5 + (0.3 if abs(row['val'] - 1.0) < 0.1 else 0)
processed_track.append({
'lat': row['lat'], 'lon': row['lon'],
'time_seq': row['time_idx'], 'confidence': confidence
})
reconstructed_tracks[f"Target_{cluster_id}"] = processed_track
start, end = processed_track[0], processed_track[-1]
print(f" [Target_{cluster_id}] Path: ({start['lat']},{start['lon']}) -> ... -> ({end['lat']},{end['lon']})")
return reconstructed_tracks
def visualize_results(self, tracks):
"""
[恢复功能] 生成双视图:左侧热力图,右侧轨迹图
"""
print("[+] Generating combined visualization: attack_result_visualization.png")
try:
# 创建 1行2列 的图布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 8))
# --- 子图 1: 差分累积热力图 (Differential Heatmap) ---
# 使用 extent 将网格索引映射回经纬度范围
# 注意:imshow 默认原点在左上角 (Row 0),对应的应该是 lat_max
# 所以 extent 顺序是 [left, right, bottom, top] = [lon_min, lon_max, lat_min, lat_max]
im = ax1.imshow(
self.cumulative_diff_matrix,
cmap='hot',
interpolation='nearest',
extent=[self.lon_min, self.lon_max, self.lat_min, self.lat_max],
aspect='auto'
)
ax1.set_title(f'Cumulative Activity Heatmap (Grid Precision: {self.grid_size}°)')
ax1.set_xlabel('Longitude (E)')
ax1.set_ylabel('Latitude (N)')
ax1.grid(True, linestyle='--', alpha=0.3)
plt.colorbar(im, ax=ax1, label='Signal Accumulation Count')
# --- 子图 2: 重建轨迹图 (Reconstructed Trajectories) ---
# 绘制背景
ax2.set_xlim(self.lon_min, self.lon_max)
ax2.set_ylim(self.lat_min, self.lat_max)
ax2.grid(True, linestyle='--', alpha=0.5)
colors = ['#00ff00', '#00ffff', '#ff00ff', '#ffff00'] # 鲜艳的颜色方便观察
# 绘制每条识别出的轨迹
for i, (target_id, points) in enumerate(tracks.items()):
lats = [p['lat'] for p in points]
lons = [p['lon'] for p in points]
c = colors[i % len(colors)]
# 绘制线段和点
ax2.plot(lons, lats, marker='o', linestyle='-', color=c, linewidth=2, label=target_id, markersize=5)
# 标记起点和终点
ax2.text(lons[0], lats[0], 'Start', fontsize=9, color='blue', fontweight='bold')
ax2.text(lons[-1], lats[-1], 'End', fontsize=9, color='red', fontweight='bold')
ax2.set_title('Reconstructed Vessel Trajectories (Taiwan Strait)')
ax2.set_xlabel('Longitude (E)')
ax2.set_ylabel('Latitude (N)')
ax2.legend()
plt.tight_layout()
plt.savefig('attack_result_visualization.png', dpi=300)
print(" Visualization saved to 'attack_result_visualization.png'")
plt.show()
except Exception as e:
print(f" Viz Error: {e}")
import traceback
traceback.print_exc()
def execute_attack(self):
print("[+] Starting Batch Anonymous Data Re-identification (Target: Taiwan Strait)...")
# 1. 获取数据 (10个时间切片)
self.fetch_anonymous_releases('strait_shipping_density', version_count=10)
# 2. 统计分析
self.differential_analysis()
# 3. 轨迹重建
tracks = self.track_reconstruction()
# 4. 可视化与导出
if tracks:
self.visualize_results(tracks)
with open('strait_targets.json', 'w') as f:
json.dump(tracks, f, indent=2)
print("[+] Attack Completed. Sensitive targets exported.")
if __name__ == "__main__":
attacker = AnonymityBreaker()
attacker.execute_attack()debug过程

1. 首先来到入口方法"main",顺序执行主方法中的内容,
第321行:初始化一个AnonymityBreaker类,让我们步入进去,将跳转到它的初始化方法中:
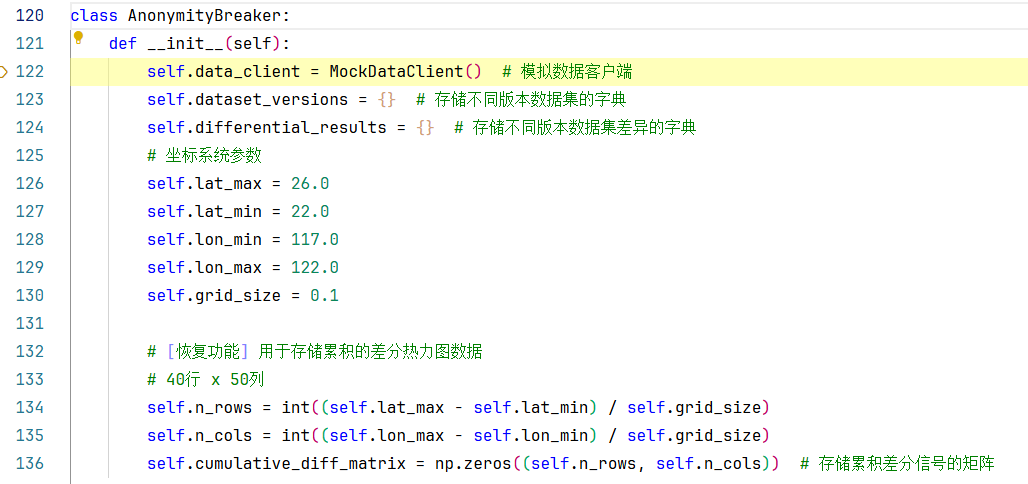
第122行:初始化了一个MockDataClient类,我们再步入该类的初始化方法查看一下:

30-31行:是根据经纬度和网格精度,来划分网格的一步操作。
第34行比较有意思,它调用了self._generate_realistic_tracks()方法,生成了真实轨迹,并赋值给self.ground_truth_tracks变量,我们步入一下第34行:

在_generate_realistic_tracks()这个方法中,它干的事主要是:通过使用self._simulate_crw_path()方法生成了Vessel_A、Vessel_B两条随机游走轨迹,把它们存入tracks字典中,然后return这个tracks字典。
我们直接来到第48行,步入self._simulate_crw_path()方法:
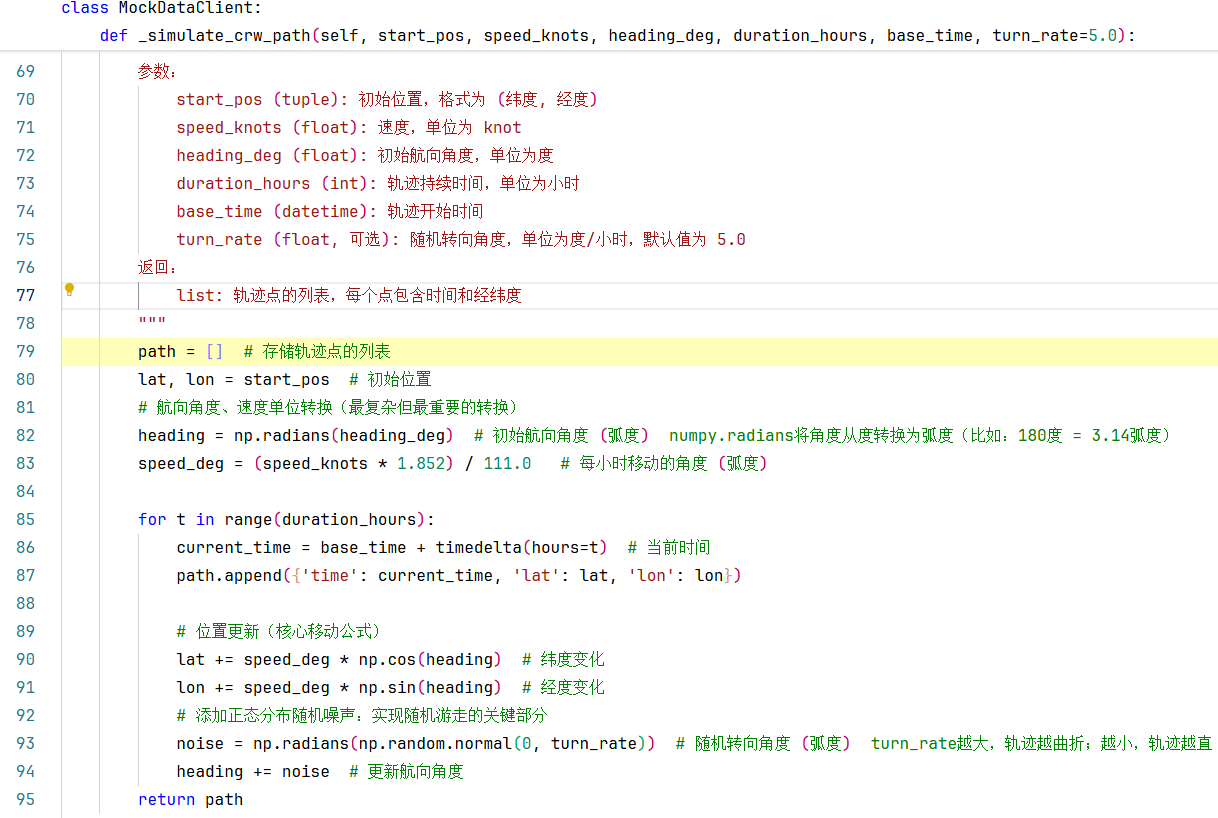
第82行:这里使用np.radians()函数将角度从度 转换为弧度。
为什么需要转换呢?
- 在Python的数学计算中,三角函数(
sin,cos)使用弧度制- 转换公式:弧度 = 角度 × π / 180
90度 = π/2、180度 = π
第83行:速度单位转换,这是最复杂但最重要的转换!
节 → 公里/小时 :
speed_knots * 1.852
- 1节 = 1海里/小时 = 1.852公里/小时
公里/小时 → 纬度/经度变化率 :
÷ 111.0
为什么是111.0?这是地球的近似换算系数
在赤道上,1度经度 ≈ 111公里
1度纬度 ≈ 111公里(变化很小)
因此:每小时移动的角度 = 速度(公里/小时) ÷ 111
注意:严格来说,经度的实际距离随纬度变化,但这里做了简化
85-94行:是一个range(duration_hours=120)的循环,从0-119一共120次循环,循环duration_hours次,每次代表1小时的移动。
每次循环要做的事:更新当前时间;将当前time、lat、lon信息以字典格式添加到path列表;
90-91行:位置更新(核心移动公式),这是根据航向计算位置变化的公式。
地理坐标移动原理:
np.cos(heading):获取南北方向分量(纬度变化)
heading=0°(正北):cos(0)=1,向北移动
heading=180°(正南):cos(180)=-1,向南移动
np.sin(heading):获取东西方向分量(经度变化)
heading=90°(正东):sin(90)=1,向东移动
heading=270°(正西):sin(270)=-1,向西移动
新纬度 = 旧纬度 + (每小时移动度数 × cos(航向)) 新经度 = 旧经度 + (每小时移动度数 × sin(航向))
第93-94行:添加正态分布随机噪声,实现随机游走的关键部分。
这是实现随机游走的关键部分!
生成随机噪声:
np.random.normal(0, turn_rate):从正态分布中随机采样均值=0,标准差=
turn_rate(默认为5.0度)例如:可能产生-3.2°、+4.7°、+0.5°等随机值
转换为弧度 :
np.radians()将角度转换为弧度更新航向:将随机噪声加到当前航向上
这使得每次移动后航向都有轻微随机变化
turn_rate越大,轨迹越曲折;越小,轨迹越直有关正态分布的深入讨论请跳转:
我们跳出循环体,直接快进到该方法的最后一步return path,看下这个所谓的path列表:
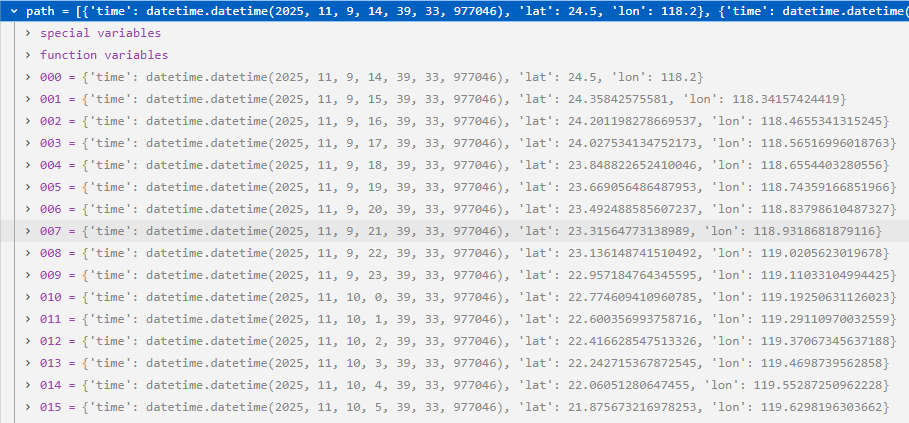
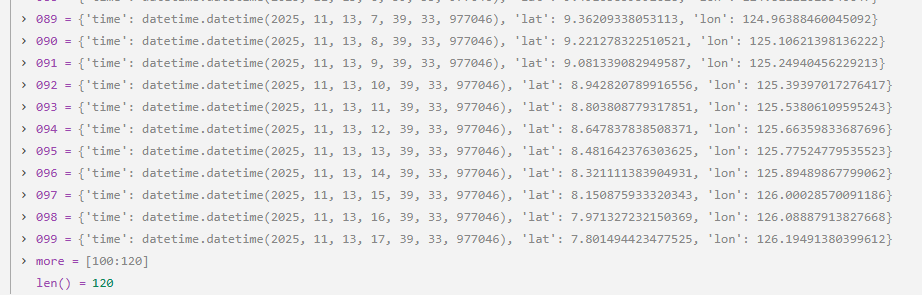
以看出,lat从24.5到7.8,lon从118.2到126.1,整体航行方向是向东南的(右下方)。这就是为什么Vessel A: 从厦门附近开往台湾南部 (东南向)
让我们回到上一层,如下图:

Vessel B轨迹的生成咱们可以跳过了,完全和Vessel A一样,无非又调用了一遍self._simulate_crw_path()方法,只是参数改变了一下。
观察仔细的友友会发现:为什么生成Vessel A的时候没有填turn_rate参数值,而在生成Vessel B的时候传入了turn_rate=15.0的参数?
这是因为self._simulate_crw_path()方法内部对于turn_rate参数赋了默认值。在调用的时候不填turn_rate参数就会使用默认值,填了新值的话就会重新覆盖掉默认值。
咱们看一下最后的tracks字典的样子:

K1:V1,其中K1是'Vessel_A',V1是对应data列表。K2:V2同理。
让我们继续返回上一层,回到AnonymityBreaker类的初始化方法:
此时的Locals变量中,多出来一个self.data_client变量,它是一个<main.MockDataClient object at 0x000002B8C6B50D30>对象,点进去发现MockDataClient对象的属性都已经被初始化了。如下图所示:
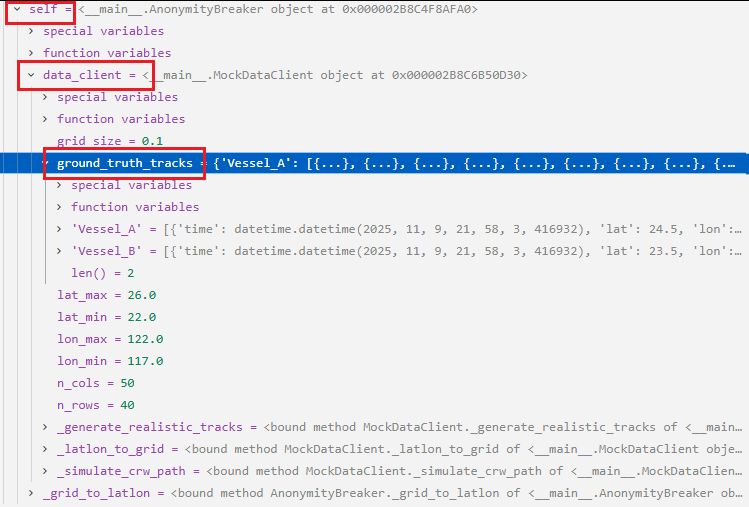
我们来讨论一个点:
132行:self.data_client = MockDataClient()运行完之后,内存中Local变量是什么样的呢?
刚开始进入AnonymityBreaker类的初始化方法时,此时还没有执行方法,为啥方法已经挂在到self(实例对象)上了,为什么会这样?
像132行代码:我都是运行完了self.data_client = MockDataClient()这行代码之后,在Local中的self中才会出现data_client变量。为啥AnonymityBreaker的方法,在我刚进入初始化方法的时候就已经以存在了呢?我都还没执行这些方法呢?
为什么会这样?为什么我还没有真正执行到该对象的方法呢,它们就已经出现在了Local中的self中了?
这个问题的解答在附录1

让我们返回到AnonymityBreaker类的初始化方法中,正常走完__init__方法(定义了一些新的属性),最后用attacker接收,如下所示:
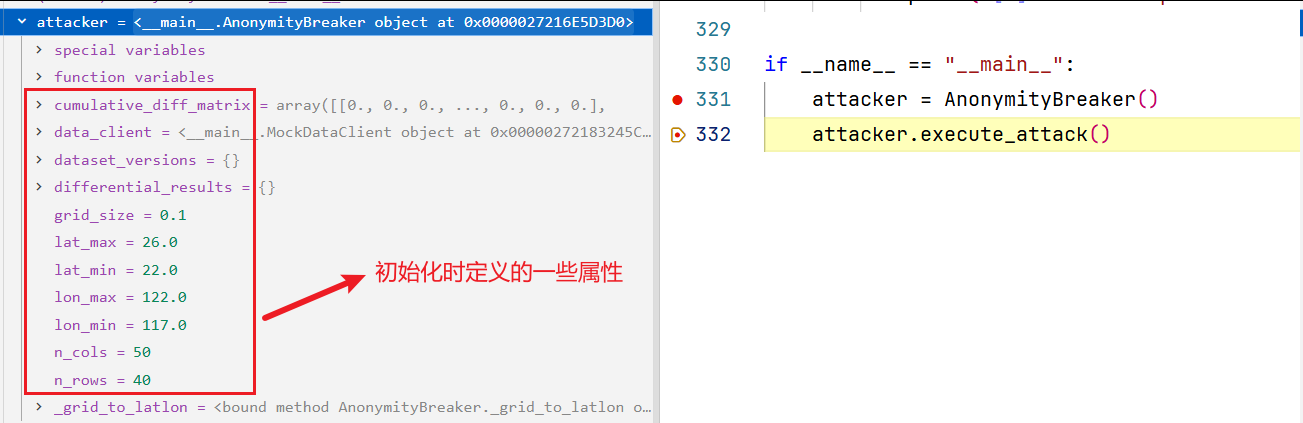
2. 让我们进入第332行的attacker.execute_attack()方法中,执行攻击。
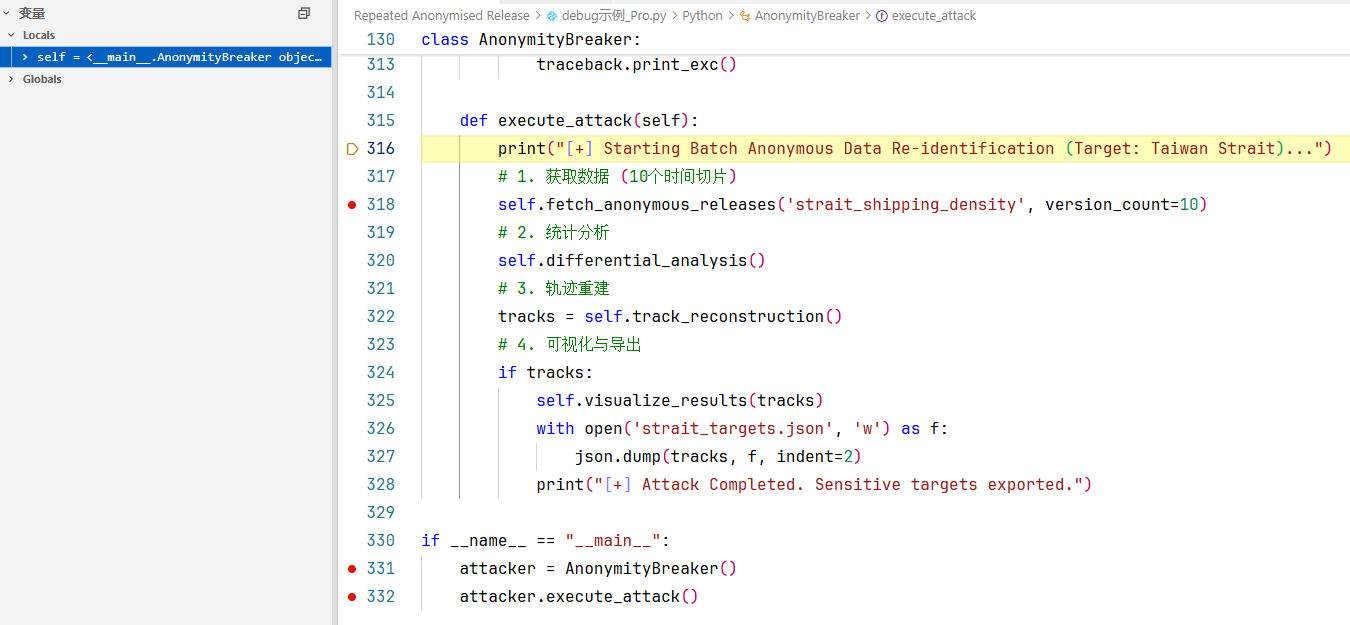
2.1执行318行,1.获取数据 (10个时间切片),步入fetch_anonymous_releases()方法内部如下:

直接看163-182行这个循环体,i的取值范围从0到(version_count-1),一共循环version_count次。每次循环体里干的事为:
定义版本ID、查询开始时间、查询结束时间;
获取匿名化数据集、将获取到的匿名化数据集加入self.dataset_versions字典;
休眠0.1秒。
我们直接步入170行这个self.data_client.get_datase()方法中,看下具体是如何获取到匿名化数据集的(如何实现的),如下图:
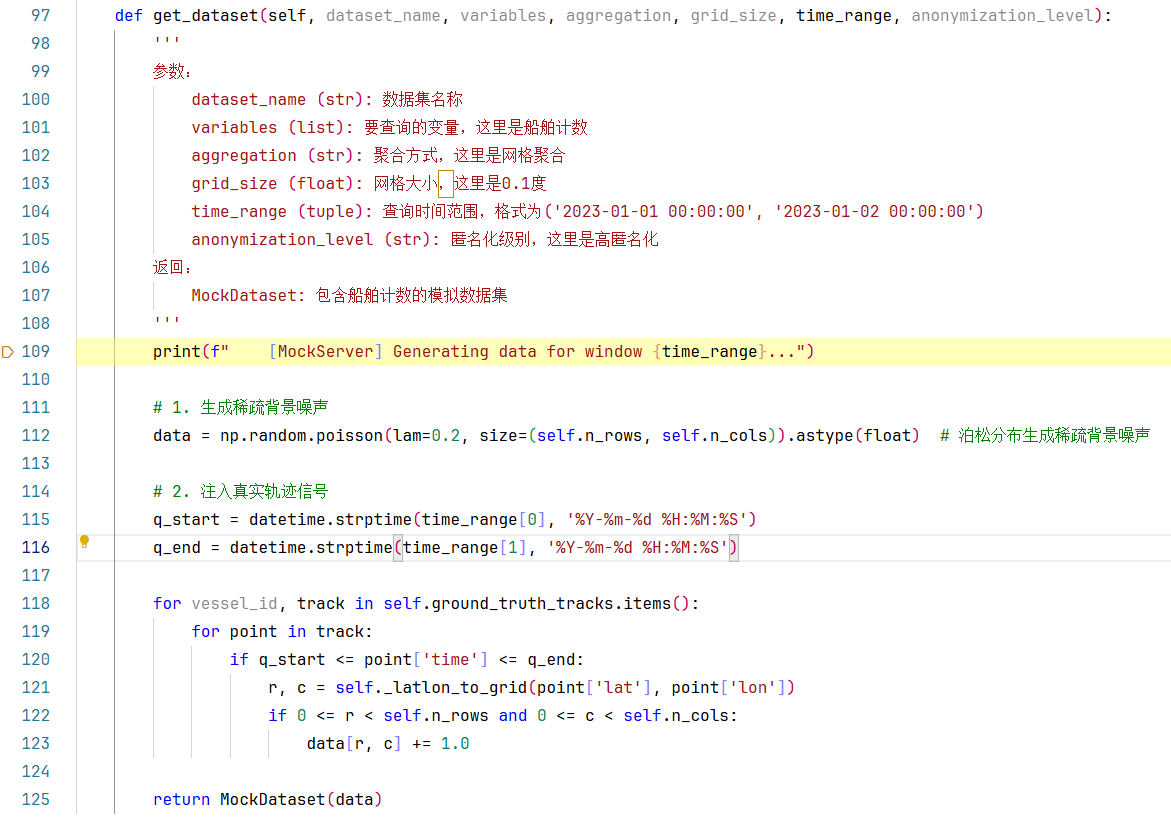
112-125行做的事:
步骤1.首先通过泊松分布生成稀疏背景噪声(同1.debug代码示例,这里不在展开叙述),
步骤2. 注入真实轨迹信号
115-116行:获取到查询的开始时间和结束时间。
118-123行:是一个双层for循环,内部又嵌套了两层if判断。让我们一步一步来拆解这个复杂的嵌套逻辑:
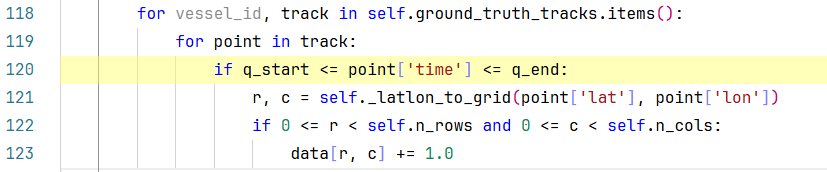
首先让我们看一下self.ground_truth_tracks是个啥,如下图:
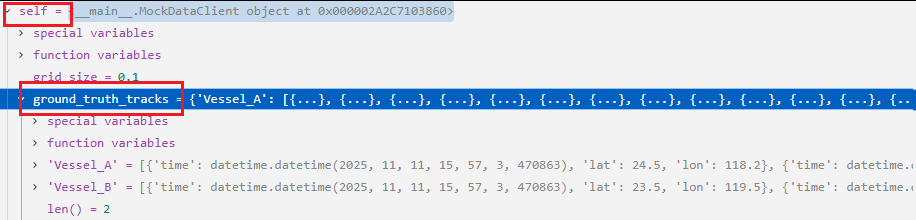 哦,原来self.ground_truth_tracks是我们初始化MockDataClient时生成真实轨迹字典。
哦,原来self.ground_truth_tracks是我们初始化MockDataClient时生成真实轨迹字典。
self.ground_truth_tracks.items() # 就是返回一个字典迭代器,
for vessel_id, track in self.ground_truth_tracks.items(): # 就是用for循环遍历这个字典迭代器,然后每次返回一对K,V。
而每次返回的V又是一个轨迹点列表,
for point in track: # 就是在遍历每个轨迹点。而每个网格点point又是一个个的字典。
如下所示:
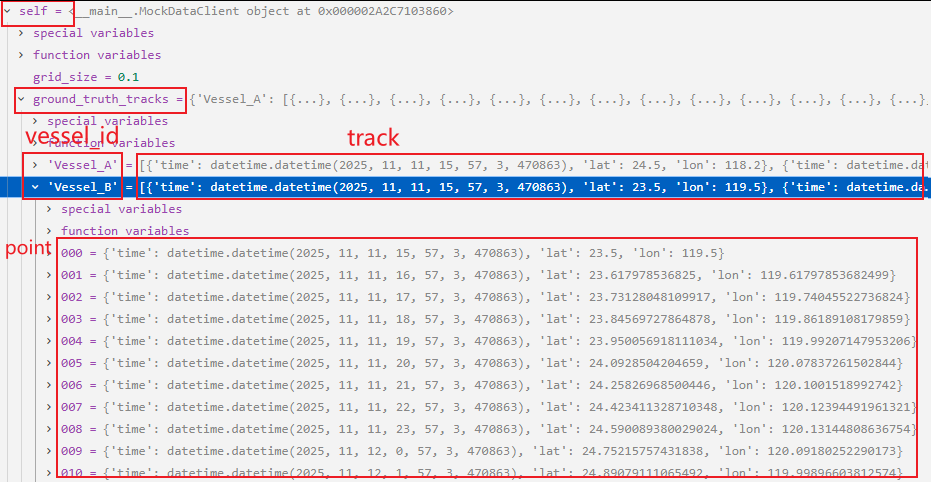
120行:筛选出那些时间范围处于(查询开始时间-查询结束时间)范围的轨迹点。每次查询只能查出来一个轨迹点,(连续查N个小时,就对应N个版本的网格数据),所以每次筛选也只能筛选出1个点。但又因为MockDataClient._generate_realistic_tracks()方法生成的是Vessel A和Vessel B两条轨迹,所以一个data中有且只有两个轨迹点被注入真实轨迹信号。
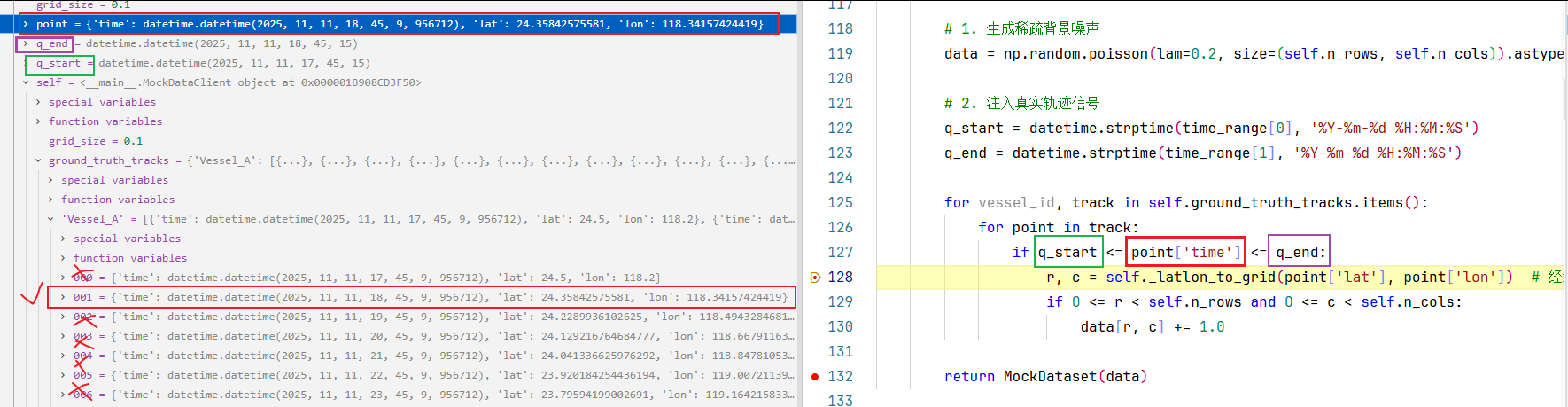
121行:对筛选出来的点,将其经纬度转成网格索引(整个区域的经纬度范围(维度:22.0-26.0,经度:117.0-122.0,网格经度0.1°)被映射成了40行×50列的网格),步入self._latlon_to_grid()方法内部:

意思就是说,(维度:24.35842575581,经度:118.34157424419)这个点在全局范围网格中(40行✖50列)的第(16行,13列),返回网格的行列索引。注意:我们在代码中规定的是,网格行索引从上到下、列索引从左往右为正方向。
类似于data二维数组(40行✖50列):
继续回到第129行,检查行列索引是否在全局范围网格中,如果在的话,就令datar, c += 1.0,这样就往该轨迹点位置注入了真实的轨迹信号。
第132行:返回一个MockDataset(data),返回包含船舶计数的模拟数据集,我们步入MockDataset数据集类看一下:

就是把data赋值给MockDataset.ship_count了,多封装了一步而已。
继续返回到上一层,回到fetch_anonymous_releases()方法,如下图所示:

第186行:再封装一步,将anonymous_data存到self.dataset_versionsversion_id字典中。
总的来说,每次执行完一次for i in range(version_count):迭代,就有一个新版本的匿名数据集anonymous_data添加到self.dataset_versionsversion_id字典中。
返回到attacker.execute_attack()方法中的326行,326行代码执行完后,此时的self中的变量如下所示:
2.2接下来将要执行328行,2.统计分析步骤,让我们步入self.differential_analysis()方法的内部:
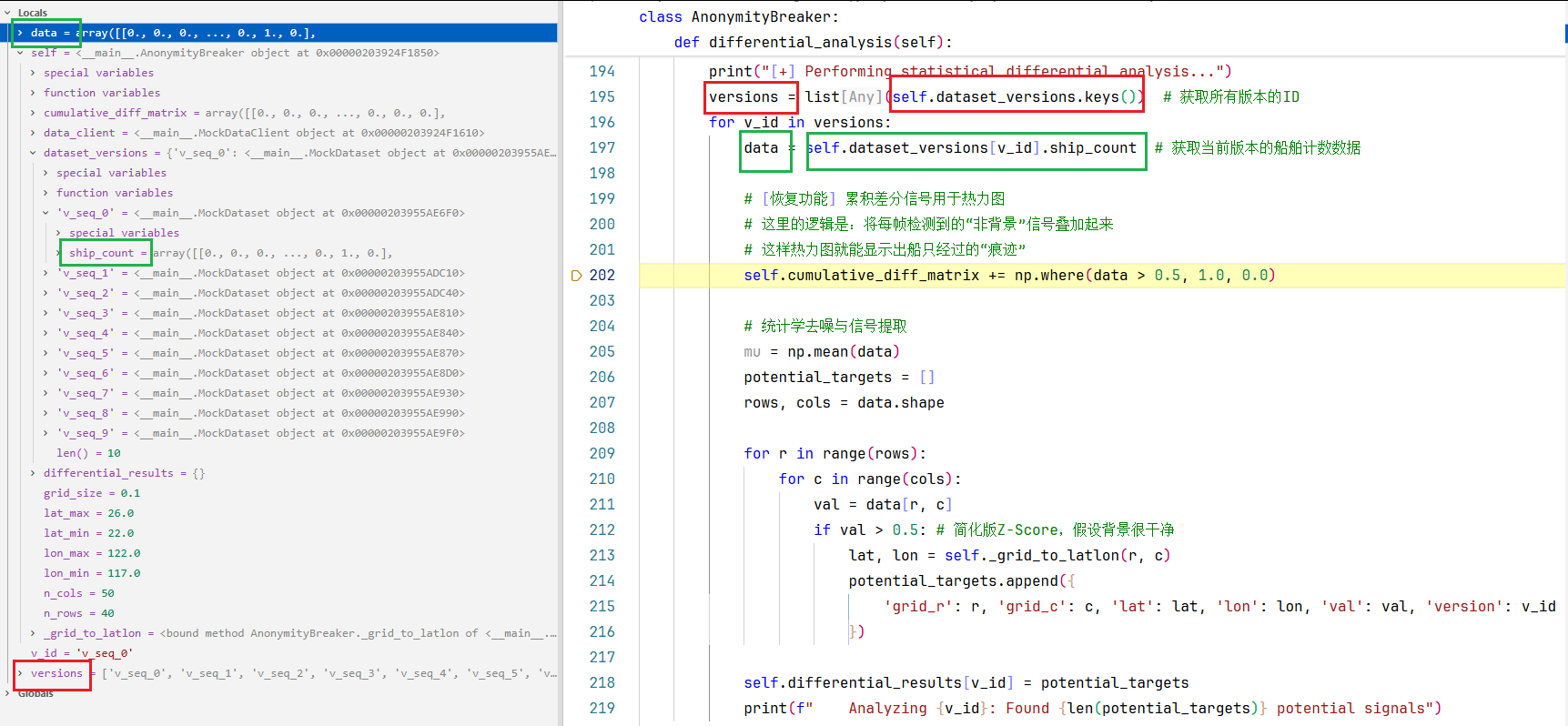
第195行:获取所有版本的ID
196-219行for v_id in versions:遍历所有的版本的ID列表,每一次遍历都要做的事:
第197行:获取当前版本的船舶计数数据data。
第202行:对大于0.5的信号先进行二值化,再进行累加。
np.where(data > 0.5, 1.0, 0.0) # 大于0.5的值全都赋值为1.0,不满足的值都设置为0.0
numpy.where()的用法见附录
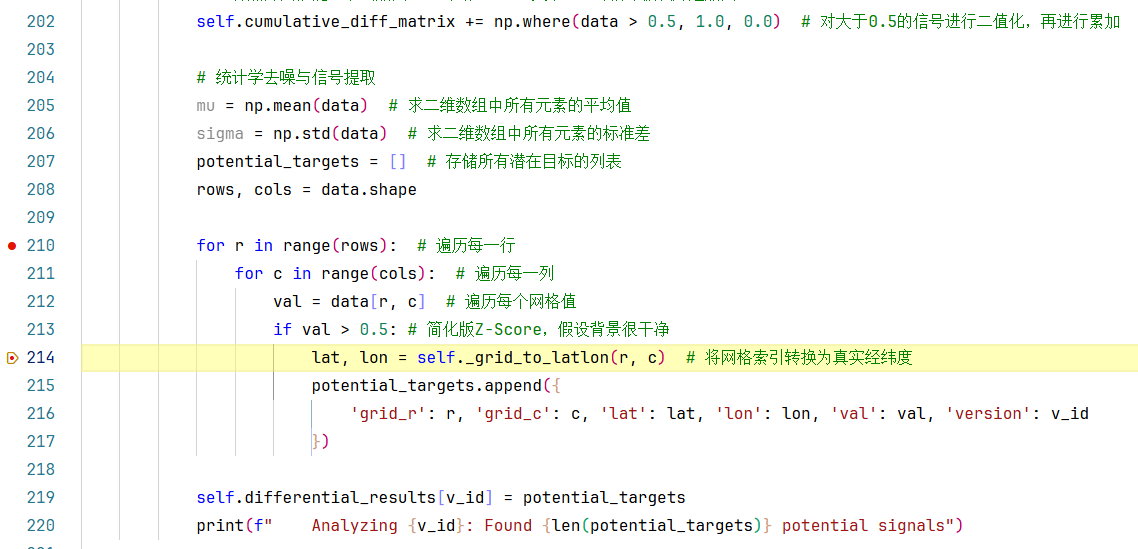
如上图,从210-217行:遍历每个网格值,筛选出那些val>0.5的网格,然后其将网格索引转换为真实经纬度,获取该网格的字典信息,并添加到potential_targets列表。
步入214行的_grid_to_latlon()方法:

这些公式如果让人工来写的话,确实挺麻烦的。所以AI的强大之处就是能让你的注意力转移到代码的逻辑上来,而不是过多的关注语法/公式。
第219行:将潜在目标的列表potential_targets保存到self.differential_resultsv_id字典中。
相当于每次版本遍历,最后都会将对应版本的potential_targets添加到self.differential_resultsv_id字典中一遍。所以整个for v_id in versions循环结束后,也就是2. 统计分析步骤结束后,我们看下此时状态的self.differential_results字典:

另外,由于第202行:
self.cumulative_diff_matrix += np.where(data > 0.5, 1.0, 0.0) # 对大于0.5的信号进行二值化,再进行累加
所以每次版本遍历,self.cumulative_diff_matrix都会被累加一遍的,所以整个for v_id in versions循环结束后,self.cumulative_diff_matrix二维数组:
2.3接下来执行330行:轨迹重建步骤,让我们步入self.track_reconstruction()方法:
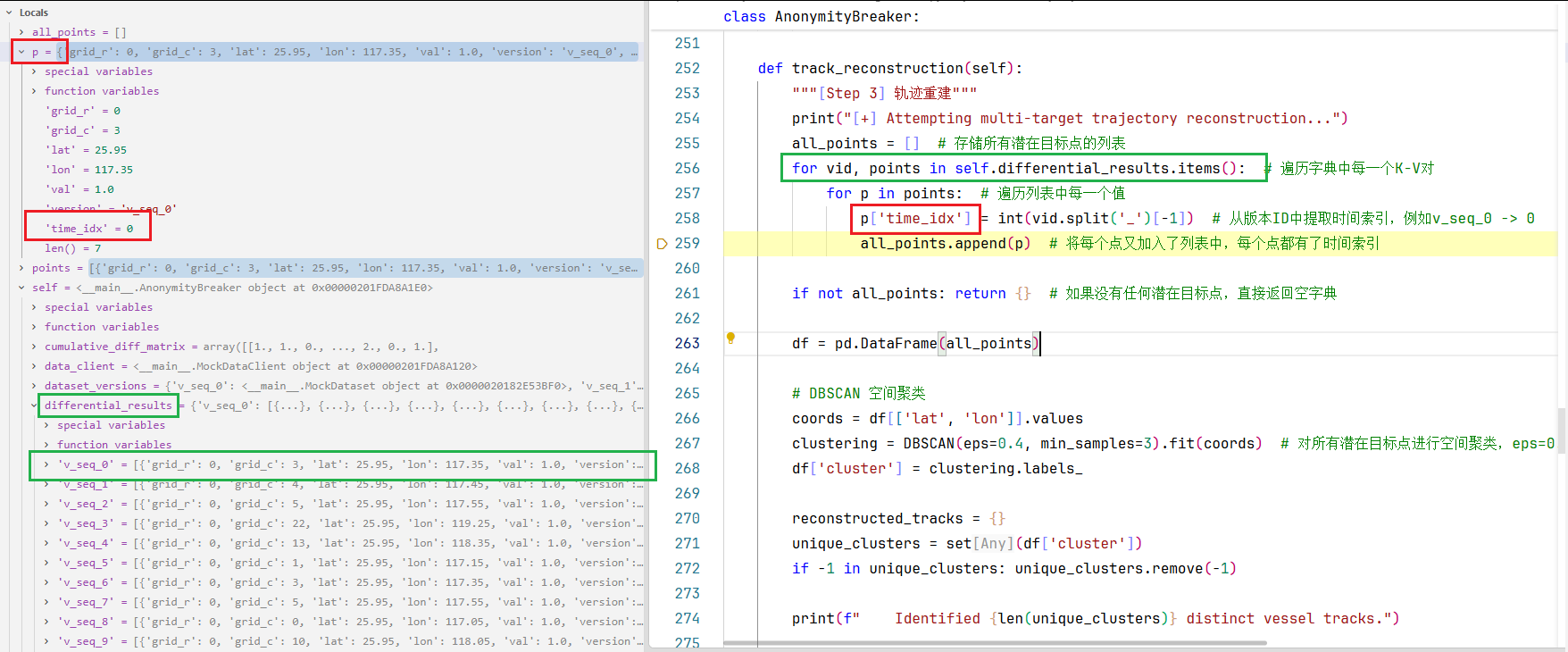
254-259行:循环遍历self.differential_results.items(),先遍历字典中每一个K-V对,再遍历V(一个列表)中每一个值(经纬度目标点,那些网格值>0.5的网格点)
该循环结束后,all_points列表中将存储所有潜在目标点(包括所有版本的,可通过'time_idx'key值划分不同版本的point)
第263行:将all_points转化成pandas.DataFrame对象,如下所示:

第266-268行:DBSCAN 空间聚类。
通过df\['lat', 'lon'].values获取到df的lat列和lon列的值,返回一个二维数组对象。
DBSCAN(eps=0.2, min_samples=5).fit(coords) 表示对所有的coords二维数组进行DBSCAN聚类,聚类半径eps=0.2,min_samples=5表示一个簇至少要有5个点。
clustering.labels_ 为每个点分配聚类标签,-1表示噪声点
第280行:利用set无序不重复的性质,来获取所有唯一的聚类标签。
第281行:从唯一聚类标签中移除噪声点(簇为-1的标签)。

285-296行 :for cluster_id in unique_clusters # N个簇对应N条轨迹,遍历每个唯一聚类标签
286行:
- df'cluster' == cluster_id
将df中'cluster'列的每一个值与cluster_id进行比较,得到一个布尔序列(Series),其中每个元素为True或False,表示对应行的'cluster'值是否等于cluster_id
- dfdf\['cluster' == cluster_id]
这里使用了布尔索引。我们将上一步得到的布尔序列作为索引传入df。布尔索引会筛选出布尔序列中值为True的行,即所有'cluster'列等于cluster_id的行。
- dfdf\['cluster' == cluster_id].sort_values('time_idx')
这一步对步骤2得到的DataFrame(即筛选后的数据)进行排序。sort_values是DataFrame的一个方法,用于根据指定列的值进行排序。这里指定按'time_idx'列排序。默认排序顺序是升序(从小到大)。如果需要降序,可以设置参数ascending=False。
第288行 :for _, row in track_points.iterrows():
iterrows()是pandas DataFrame的一个方法,它返回一个迭代器,用于遍历DataFrame的每一行,每一行返回一个包含两个元素的元组:
- 第一个元素是行的索引(index)
- 第二个元素是一个Series,包含该行的数据
在for循环中,我们通常使用两个变量来接收元组中的两个值,但这里第一个变量是下划线_,第二个变量是row。
_:这是一个常见的Python习惯用法,表示我们不会使用这个变量。也就是说,我们不需要索引值,所以用一个占位符(下划线)来接收,表示忽略。row:这是一个pandas Series对象,包含了当前行的所有列的数据。
因此,这个for循环会遍历track_points的每一行,而忽略行索引,将每一行的数据赋值给变量row。
最后,这整个方法执行完,会得到一个processed_track列表,里面存储当前簇的轨迹点。并且以K:V = f"Target_{cluster_id}" :processed_track 的字典形式,存储所有重建轨迹的字典reconstructed_tracks,最后返回这个reconstructed_tracks字典。
第三步:轨迹重建执行完后,将方法内部return的reconstructed_tracks字典赋值给tracks。里面的每一个K:V对都代表一个轨迹路线。
接下来进入第4步:可视化与导出,步入377行self.visualize_results()内部查看:
子图 1: 差分累积热力图
子图 2: 重建轨迹图

第337行: for i, (target_id, points) in enumerate(tracks.items()):
tracks.items():tracks是一个字典,这个方法返回一个包含字典所有键值对的视图对象(在Python 3中,这是一个动态视图)。每个键值对是一个元组(key, value)enumerate(tracks.items()):enumerate函数会为一个可迭代对象(这里是tracks.items()返回的键值对序列)添加一个计数器。默认情况下,计数器从0开始。所以,enumerate(tracks.items())产生一个可迭代对象,每次迭代返回一个元组(index, (key, value)),其中index是计数器的当前值,(key, value)是字典中的一个键值对。
如果是:for target_id, points in tracks.items():
tracks.items():同上,返回字典的键值对视图。那返回的就只是K:V键值对了。
附录
1.有关Python 面向对象编程中对象生命周期的讨论
首先要明白类与对象的关系:
类,是静态的模板,先有了类才能造出对象。
从类到对象的过程叫做实例化,一个类可以实例化多个对象。
按照编程规范,类方法里面的参数用cls 表示类本身,对象方法里面的参数用self表示对象本身。
类和对象的关系请自行学习:
https://github.com/walter201230/Python/blob/master/Article/PythonBasis/python8/5.md
实际上,创建一个类的过程是分为两步的,先是创建类的对象,再对类进行初始化。
构造方法
:__new__(cls)当你创建类的时候,new(cls)会被调用。
初始化方法:
__init__(self)当你创建一个实例的时候(实例化一个类时),**
__init__(self)**就会被调用。
__new__是用来创建类并返回这个类的实例, 而__init__只是将传入的参数来初始化该实例.特别注意:
__new__在创建一个实例的过程中必定会被调用,但__init__就不一定,比如通过 pickle.load 的方式反序列化一个实例时就不会调用__init__方法。
def __new__(cls)是在def __init__(self)方法之前调用的,作用是返回一个实例对象。还有一点需要注意的是:__new__方法总是需要返回该类的一个实例,而__init__不能返回除了None的任何值。

我们就可以知道一个类创建的过程是怎样的了,先是调用了 __new__ 方法来创建一个对象,把参数传给 __init__ 方法进行初始化。
我们举个具体的例子,完整地展示了 Python 面向对象编程中对象生命周期 的起点------实例化(Instantiation)。
1. 类的定义阶段 (加载代码时)
-
行 4-24: Python 解释器首先读取文件。当它看到
class User(object):时,它会执行类定义体内的代码,创建User这个类对象(Class Object)。- 注意: 此时
__new__和__init__并没有被调用,它们只是作为函数对象被挂载在User类的命名空间里。
- 注意: 此时
2. 程序入口
- 行 27: 解释器执行到
if __name__ == '__main__':,条件成立,进入内部。
3. 触发实例化 (关键时刻)
-
行 28:
usr = User('两点水', 23)。-
这是整个流程的核心 。当你调用
User(...)时,Python 内部其实触发了一连串连锁反应。 -
控制权转移: 指针首先跳转到
User类的__new__方法。
-
4. 进入 __new__ (构造/内存分配)
-
行 5: 指针停在
def __new__(cls, *args, **kwargs):。- 关键点:
cls参数此时就是User类本身。args是('两点水', 23)。
- 关键点:
-
行 7: 执行
print('调用了 def __new__ 方法')。控制台输出。 -
行 8: 执行
print(args)。控制台输出('两点水', 23)。 -
行 10:
return super(User, cls).__new__(cls)。-
这里调用了父类(即
object)的__new__方法。 -
底层动作:
object.__new__会在内存中申请一块空间,创建一个真正的User实例对象。这个对象目前是"空"的(没有name和age属性)。 -
返回值: 返回这个新创建的实例对象。
-
5. 中间转换 (Python 内部机制)
-
__new__方法返回了实例对象后,Python 解释器会自动检查:"这个返回的对象是User的实例吗?"-
答案是:Yes。
-
于是,解释器自动帮你调用
__init__方法。
-
6. 进入 __init__ (初始化/属性赋值)
-
行 12: 指针停在
def __init__(self, name, age):。- 关键点: 此时的
self,正是刚才__new__创建并返回的那个内存对象。
- 关键点: 此时的
-
行 13: 执行
print('调用了 def __init__ 方法')。控制台输出。 -
行 14-15:
self.name = name;self.age = age。- 给刚才那块内存空间里的对象,挂载上
name和age属性。
- 给刚才那块内存空间里的对象,挂载上
7. 赋值给变量
-
行 28:
__init__执行完毕(它默认返回None)。 -
此时,一个完整的、包含数据的对象终于准备好了,它被赋值给变量
usr。
通过上面的调试,我们要总结出 Python 实例化一个类时,底层到底做了哪三件大事。
我们可以把这个过程比喻成"生产一个定制玩偶"。
1.
__new__是"模具师" (The Creator)
- 职责: 创建实例。负责去仓库(内存)申请材料,把玩偶的"肉身"造出来。
- 参数: 第一个参数是
cls(类),因为它需要知道造什么类型的玩偶。- 返回值: 必须返回实例对象 。如果
__new__不返回对象,后续的步骤直接中断,__init__根本不会被触发!- 静态方法特性: 虽然没写
@staticmethod,但在 Python 底层,__new__始终是作为静态方法调用的。2.
__init__是"化妆师" (The Initializer)
- 职责: 定制实例 。它拿到"模具师"给它的裸体玩偶(
self),给它穿衣服(赋值name)、画妆容(赋值age)。- 参数: 第一个参数是
self,这就是__new__造出来的那个东西。- 返回值: 永远不要返回任何值 (只能是
None)。如果你在__init__里return 1,程序会报错。3.
type.__call__是"总指挥"你可能会问:"是谁在协调这两个人?为什么我写
User()会自动按顺序调这两个方法?"在 Python 中,类(
User)本身也是一个对象(它是type的实例)。当你调用User(...)时,实际上执行的是type类的__call__方法。通过这个案例,你掌握了 Python 所谓"构造函数"的真相:它是
__new__(造人) +__init__(穿衣) 的组合拳。
__new__决定了**"有"**(内存分配)。
__init__决定了**"像"**(属性赋值)。为了检验你是否掌握,我想问你一个进阶问题作为课后思考(或者我们可以继续探讨):
如果我在
__new__方法中,不写return super(User, cls).__new__(cls),而是写了return object()或者直接return None,你觉得__init__里的
2.聊一聊Python的魔术方法
有关魔术方法的文档可以看看:
https://github.com/walter201230/Python/blob/master/Article/PythonBasis/python10/1.md
这些以双下划线开头、双下划线结尾的方法(例如 __init__),在 Python 圈子里被称为 "魔术方法"(Magic Methods) ,也叫 Dunder Methods (Double UNDERscore)。
作为老师,我要告诉你一个核心概念:Python 的一切高级语法糖,本质上都是对这些魔术方法的封装。
并没有所谓的"魔法",当你写 a + b 时,Python 实际上悄悄调用了 a.__add__(b)。当你写 print(a) 时,它悄悄调用了 a.__str__()。
为了让你系统地掌握,我将你图中出现的,以及最常用的魔术方法分为四大派系来讲解。
第一派系:身份与颜值(表示系)
在你的截图中,你看到了
__repr__和__str__,它们决定了对象"长什么样"。1.
__str__(self):给用户看的"艺名"
- 触发场景: 当你使用
print(obj)或者str(obj)时。- 作用: 返回一个字符串,用来给人类阅读。内容应该易懂、简洁。
- 默认行为: 如果不写,打印出来通常是
<__main__.User object at 0x00...>这种看不懂的内存地址。2.
__repr__(self):给开发者看的"身份证"
触发场景: 当你在控制台直接输入变量名回车,或者调试器(比如你截图里的 Value 栏)显示对象时,或者
repr(obj)。作用: 返回一个字符串,目的是无歧义。
资深经验: Python 有个惯例,
__repr__返回的字符串,最好是一段可以直接复制粘贴运行的代码,用来重新创建这个对象。
- 比如: 返回
"User(name='两点水', age=23)"而不是"两点水"。老师的口诀:
__str__是给客户看的 PPT,__repr__是给工程师看的 Log。如果只写一个,优先写__repr__,因为 Python 在找不到__str__时会自动调用__repr__代替。第二派系:逻辑与比较(比较系)
你图中那一堆
__eq__,__lt__,__ge__都是用来做比较的。这就解释了为什么两个对象可以用==或>号来比较。
__eq__(self, other)(Equal) : 对应==。判断两个对象是否相等。
__ne__(self, other)(Not Equal) : 对应!=。
__lt__(self, other)(Less Than) : 对应<。
__gt__(self, other)(Greater Than) : 对应>。
__le__,__ge__: 对应<=和>=。应用场景: 如果你有一个
Student类,你想直接用student1 > student2来比较他们的分数,你就需要在类里实现__gt__方法,逻辑是return self.score > other.score。第三派系:内脏与管家(属性控制系)
这是最深奥的一派,也是运维开发(写框架、写 ORM)最常用的。你图中看到的
__dict__,__setattr__,__getattribute__属于这里。1.
__dict__:数据的大本营
作用: 这是一个字典。对象的所有可写属性 (比如
self.name,self.age)实际上都存放在这个字典里。调试技巧: 当你想看一个对象里到底存了什么数据,直接
print(obj.__dict__)最直观。2.
__setattr__(self, key, value):赋值拦截器
触发场景: 每当你执行
obj.key = value时。底层逻辑: Python 不会直接把值塞进内存,而是先问问
__setattr__。你可以在这里做类型检查 (比如防止给 age 赋值字符串)或者日志记录(记录谁修改了配置)。⚠️ 危险禁区: 在这个方法里,千万不要写
self.key = value,否则会无限递归调用__setattr__直到报错!必须写self.__dict__[key] = value。3.
__getattribute__(self, item):访问拦截器
触发场景: 只要你访问属性
obj.xxx,无条件先触发它。作用: 它是属性访问的最高级守门员。通常用于实现非常底层的黑魔法(如 RPC 调用拦截)。
第四派系:生命周期与系统(其他重要成员)
__hash__: 决定对象能否作为字典的 Key 或者放入 Set 集合。如果两个对象__eq__相等,它们的__hash__必须也相等。
__dir__: 也就是你运行dir(obj)时返回的内容,决定了自动补全会提示什么方法。
__delattr__: 当你执行del obj.name时触发。
__new__/__init__: 负责生。
__repr__/__str__: 负责展示。
__eq__/__hash__: 负责社交(比较和作为 Key)。
__getattr__/__setattr__: 负责内部管理。掌握了这些,你就不再是只能写脚本的初级工,而是能设计出像 Pandas 或 Django 那样"好用"接口的架构师。想成为架构师,确实不能只满足于"能写出代码",而是要能写出**"让别人觉得好用的代码"**(即框架、库、SDK)。架构师的核心能力之一,就是定义接口(Interface)。而 Python 的魔术方法,就是定义接口的积木。
除了之前讲的"生死"(
__new__/__init__)和"外貌"(__str__),下面这几组魔术方法是设计高内聚、低耦合系统时的"重型武器"。1.
__call__:让对象变成"函数"这是架构师最喜欢的语法糖之一。它允许你像调用函数一样调用一个对象实例:
obj()。
架构师视角的用途:
状态保持: 函数无法存状态(除非用闭包),但类可以。如果你需要一个带状态的函数,就用它。
装饰器(Decorators): 写基于类的装饰器时,
__call__是必须的。策略模式: 比如你在写一个神经网络层(Layer),通常通过
__call__来定义前向传播(Forward Propagation),这样用户就能写output = layer(input)。代码示例:带记忆的斐波那契数列计算器
pythonclass Fibonacci: def __init__(self): self._cache = {0: 0, 1: 1} # 保持状态:缓存 def __call__(self, n): # 像函数一样被调用 if n in self._cache: return self._cache[n] # 递归计算 result = self(n - 1) + self(n - 2) self._cache[n] = result return result # 实例化 fib = Fibonacci() # 此时 fib 是一个对象,但我可以像函数一样用它 print(f"斐波那契第10位: {fib(10)}") print(f"缓存状态: {fib._cache}")2.
__del__:危险的"遗言"你提到了这个,但我必须郑重地给你贴个警告标签。
作用: 析构函数。当对象被垃圾回收(引用计数归零)时触发。
架构师的避坑指南:
不要依赖它来关闭重要资源(如文件、数据库连接)。因为你不知道垃圾回收器什么时候干活,甚至程序崩溃退出时,它可能根本不会被调用!
循环引用问题: 在老版本 Python 中,如果两个对象互相引用且定义了
__del__,会导致内存泄漏(GC 无法回收)。虽然后来优化了,但依然不推荐重度依赖。正确姿势: 仅用于简单的收尾工作,或者作为最后的"兜底"保险。
pythonclass TempFile: def __init__(self, filename): self.filename = filename print(f"创建文件: {self.filename}") def __del__(self): # 仅作为保险措施,不要把核心关闭逻辑全押宝在这里 print(f"警告:对象被销毁,正在尝试清理 {self.filename} (但最好显式关闭!)")3.
__enter__和__exit__:上下文管理器(Context Manager)这是替代
__del__的王者方案。 也就是我们常用的with语句。
架构师视角的用途:
资源管理: 自动开关文件、数据库连接。
环境隔离: 比如
with app.app_context():,临时切换配置环境。异常捕获: 可以在
__exit__里统一处理代码块内的报错。代码示例:自动计时器(性能分析工具)
pythonimport time class Timer: def __enter__(self): self.start = time.time() return self # 返回的对象会给到 as 后面的变量 def __exit__(self, exc_type, exc_val, exc_tb): # exc_type 不为 None 说明代码块里报错了 end = time.time() print(f"⏱️ 代码块执行耗时: {end - self.start:.4f} 秒") # 返回 True 可以吞掉异常,返回 False (默认) 会抛出异常 return False # 使用场景 with Timer(): # 这里是你的业务代码 time.sleep(1) print("任务完成")4.
__getitem__,__setitem__,__len__:容器模拟如果你想写一个像 list 或 dict 那样可以用
[]访问的对象,就需要这一组。
架构师视角的用途:
封装配置: 让用户可以用
config['db_host']读取配置,底层却从远端加载。数据集封装: 比如 PyTorch 的
Dataset类,你必须实现__getitem__,这样 DataLoader 才能按索引取数据训练。代码示例:智能配置中心
pythonclass SmartConfig: def __init__(self): self._config = {"db": "mysql", "port": 3306} def __getitem__(self, key): print(f"正在从配置中心读取: {key}") return self._config.get(key, "Default") def __setitem__(self, key, value): print(f"正在更新配置中心: {key} = {value}") self._config[key] = value def __len__(self): return len(self._config) conf = SmartConfig() print(conf['db']) # 触发 __getitem__ conf['timeout'] = 30 # 触发 __setitem__5.
__getattr__:最后的救命稻草注意,它和
__getattribute__不一样!
__getattribute__:每次访问属性都会触发(太重了,容易死循环)。
__getattr__:只有当属性找不到时,才会触发。架构师视角的用途:
RPC 代理: 你调用
client.get_user(),但client类里根本没这个方法。__getattr__捕获到这个名字,动态生成一个网络请求发给服务器。动态适配器: 包装一个老旧的对象,把新方法的调用转发给旧方法。
代码示例:动态 API 代理
pythonclass APIClient: def __getattr__(self, item): # 当你调用不存在的方法时,来到这里 def request(**kwargs): return f"正在向服务器发起请求: GET /{item} 参数: {kwargs}" return request client = APIClient() # get_user_info 方法根本不存在,但程序不会报错 print(client.get_user_info(id=123)) print(client.delete_order(order_id=999))如果把 Python 比作一套武功:
__new__ / __init__: 扎马步(基本功)。
__call__: 易筋经(改变对象的形态,像函数一样)。
__enter__ / __exit__: 金钟罩(保护资源,安全进出)。
__getitem__: 乾坤大挪移(让对象像列表、字典一样变幻莫测)。
__getattr__: 吸星大法(化解未知调用,动态代理)。
这些魔术方法在类的实例化生命周期中,是什么时候出现的?
这是一个非常深刻的问题!这说明你已经开始思考代码的时间维度了。
如果不搞清楚"出场顺序",写出的代码就像是在错误的季节穿错了衣服(比如在
__new__里尝试打印self.name,会直接报错,因为那时name还没生出来)。我们可以把一个对象的生命周期看作一个**"从受精卵到出生,再到生活,最后死亡"**的过程。
我为你画了一张**"魔术方法生命周期时序图"**,并配以详细讲解。
1. 核心生命周期:出生阶段 (Instantiation)
这是你最关心的部分,也就是
usr = User('两点水', 23)这行代码执行时,后台发生的严格顺序:
type.__call__(上帝之手)
时间点: 当你写下
User(...)的那一瞬间。作用: 它是总指挥。它负责按顺序呼叫
__new__和__init__。它不属于你的类,而是属于创造你这个类的元类(Metaclass)。
__new__(肉体塑造)
时间点: 绝对的第一位。
状态: 此时内存里还没有"对象"这个概念,只有一个待分配的请求。
产出: 它返回了一个干净的、空的内存对象(Instance)。
__init__(灵魂注入)
时间点: 紧随
__new__之后(前提是__new__返回了正确的实例)。状态: 对象已经存在了(有内存地址了),但里面是空的(
__dict__是空的)。动作: 执行
self.name = ...。⚠️ 关键细节: 如果你的类中定义了
__setattr__,那么在__init__里进行属性赋值时,__setattr__就会立即被触发!2. 交互生命周期:生活阶段 (Runtime Interaction)
对象出生后(赋值给变量
usr后),剩下的魔术方法属于**"按需触发"**。它们没有固定的顺序,完全看你如何使用这个对象。
__str__/__repr__
- 时间点: 当你
print(usr)或在调试器里查看它时触发。
__getattribute__
- 时间点: 哪怕你只是做个深呼吸(读取
usr.name),它都会最先跳出来拦截。
__setattr__
- 时间点: 每次你修改属性(
usr.age = 24)时触发。3. 终结生命周期:死亡阶段 (Destruction)
__del__(遗言)
时间点: 当这个对象没有任何变量引用它了(引用计数归零),或者程序结束运行时。
作用: 类似于"临终遗言",通常用来关闭文件句柄或断开网络连接。
必须执行且顺序固定:
__new__->__init__。可能插队执行:
__setattr__(如果在__init__里赋了值)。看心情执行:
__repr__,__eq__,__gt__(取决于用户怎么用)。最后执行:
__del__。下面是一个综合的代码示例:
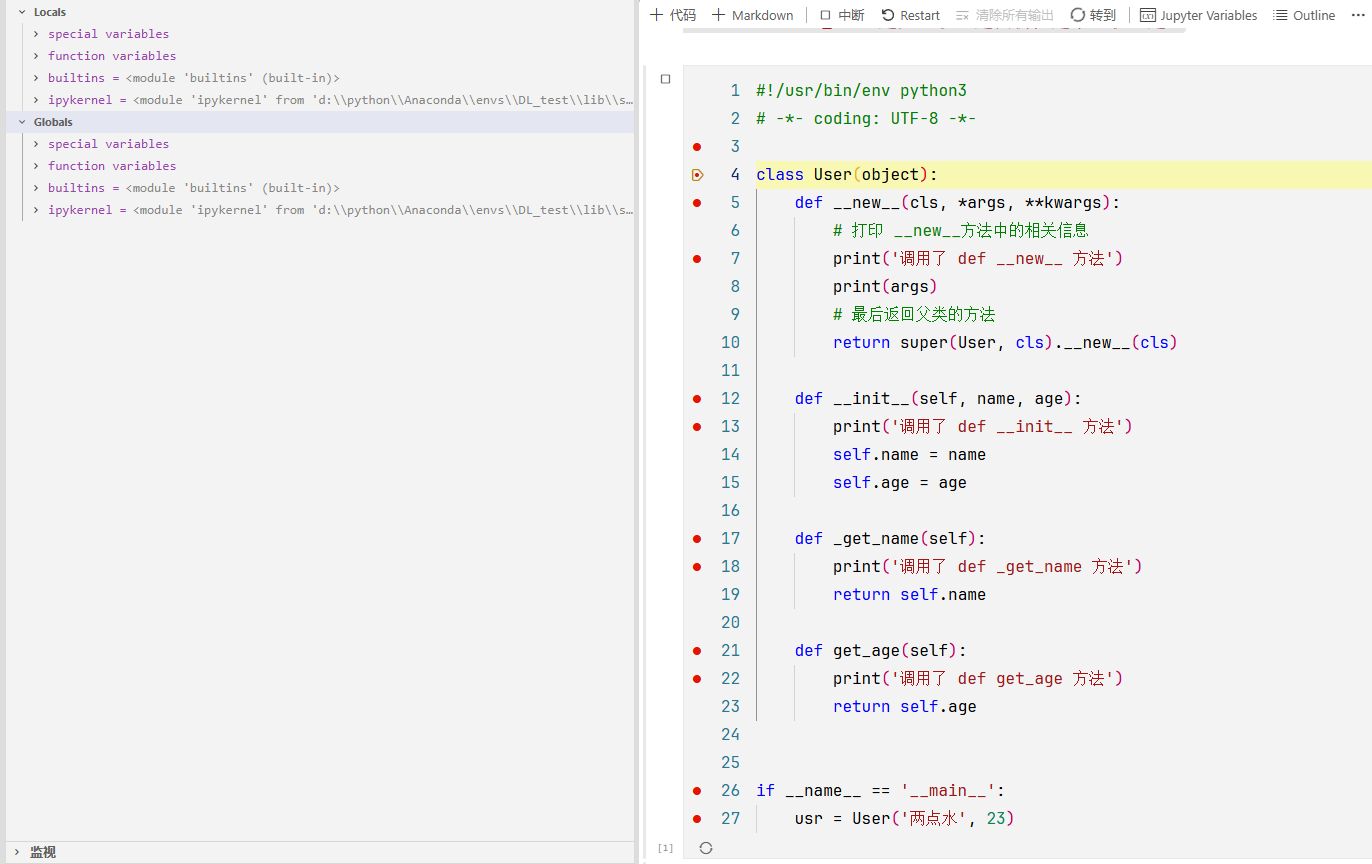
python#!/usr/bin/env python3 # -*- coding: UTF-8 -*- import time class VirtualServer(object): """ 一个模拟云服务器的类,集成了 Python 核心魔术方法 """ # ========================================== # 1. 创世纪:构造与初始化 # ========================================== def __new__(cls, hostname, cpu_cores, ram_gb): print(f"\n[1. __new__] 正在申请内存,创建 '{hostname}' 的肉身...") # 真正创建对象实例 instance = super(VirtualServer, cls).__new__(cls) return instance def __init__(self, hostname, cpu_cores, ram_gb): print(f"[2. __init__] 对象已生成,正在初始化属性 (Hostname: {hostname})...") # 这里会触发 __setattr__,要注意! self.hostname = hostname self.cpu_cores = cpu_cores self.ram_gb = ram_gb self.storage = {} # 模拟文件系统 self.status = "stopped" # ========================================== # 2. 颜值系:字符串表示 # ========================================== def __str__(self): # 用户视角的友好展示 return f"🖥️ [Server: {self.hostname}] CPU:{self.cpu_cores}C RAM:{self.ram_gb}G" def __repr__(self): # 开发者视角的代码重现 return f"VirtualServer(hostname='{self.hostname}', cpu_cores={self.cpu_cores}, ram_gb={self.ram_gb})" # ========================================== # 3. 管家系:属性访问控制 (最核心、最危险的部分) # ========================================== def __getattribute__(self, item): # ⚠️ 注意:每次访问任何属性(包括 self.hostname)都会先经过这里 # 为了避免无限递归,必须调用父类的方法来获取属性 # print(f" -> [监控] 正在尝试访问属性: {item}") # 打开这行会刷屏,调试时小心 return super().__getattribute__(item) def __setattr__(self, key, value): print(f"[3. __setattr__] 拦截赋值: {key} = {value}") if key == 'cpu_cores' and value <= 0: raise ValueError("CPU 核心数必须为正数!") # ⚠️ 绝对不能写 self.key = value,否则死循环 self.__dict__[key] = value def __getattr__(self, item): # 只有属性找不到时,才会来这里(最后的救命稻草) print(f"[4. __getattr__] 警告:属性 '{item}' 不存在!启动动态补救机制...") if item.startswith("install_"): software = item.split("_")[1] return lambda: f"正在自动安装软件: {software}..." raise AttributeError(f"Server really doesn't have '{item}'") # ========================================== # 4. 容器系:像字典一样操作 (模拟文件存储) # ========================================== def __setitem__(self, key, value): print(f"[5. __setitem__] 写入文件: {key}, 大小: {value}MB") self.storage[key] = value def __getitem__(self, key): print(f"[5. __getitem__] 读取文件: {key}") return self.storage.get(key, 0) def __len__(self): print(f"[5. __len__] 统计文件数量") return len(self.storage) # ========================================== # 5. 比较系:服务器性能PK # ========================================== def __eq__(self, other): print("[6. __eq__] 判断两台服务器是否规格相同") if isinstance(other, VirtualServer): return self.cpu_cores == other.cpu_cores and self.ram_gb == other.ram_gb return False def __gt__(self, other): print("[6. __gt__] 判断当前服务器性能是否更强") if isinstance(other, VirtualServer): return self.cpu_cores > other.cpu_cores return NotImplemented # ========================================== # 6. 函数系:对象当函数用 # ========================================== def __call__(self, command): print(f"[7. __call__] 收到指令,正在执行: {command}") return f"Exec Success: {command}" # ========================================== # 7. 上下文管理:with 语句 # ========================================== def __enter__(self): print("\n[8. __enter__] 进入维护模式 (Maintenance Mode)...") self.original_status = self.status self.status = "maintenance" return self def __exit__(self, exc_type, exc_val, exc_tb): print(f"[8. __exit__] 退出维护模式。恢复状态: {self.original_status}") self.status = self.original_status # 如果代码块里报错,exc_type 就不是 None。返回 True 可以吞掉异常。 if exc_type: print(f" 捕获到异常: {exc_val} (但我决定处理它,不让程序崩溃)") return True # ========================================== # 8. 终结者:析构函数 # ========================================== def __del__(self): print(f"[9. __del__] 服务器 '{self.hostname}' 下线,资源回收完毕。") # ============================================================================== # 开始你的调试之旅!(请在下面每一行都打断点) # ============================================================================== if __name__ == '__main__': print("=== 阶段一:诞生 ===") # 触发 __new__ -> __init__ -> __setattr__ v1 = VirtualServer("Web-Server-01", 4, 16) print("\n=== 阶段二:展示 ===") # 触发 __str__ print(f"普通打印: {v1}") # 触发 __repr__ print(f"调试打印: {repr(v1)}") print("\n=== 阶段三:属性魔法 ===") # 触发 __getattribute__ (每次访问都会触发) _ = v1.status # 触发 __setattr__ v1.cpu_cores = 8 # 触发 __getattr__ (访问不存在的 install_nginx) # 因为我们在 __getattr__ 里动态返回了一个函数,所以这里可以直接调用 print(v1.install_nginx()) print("\n=== 阶段四:容器模拟 ===") # 触发 __setitem__ v1["/var/log/syslog"] = 500 v1["/home/user/data"] = 1024 # 触发 __getitem__ print(f"日志文件大小: {v1['/var/log/syslog']} MB") # 触发 __len__ print(f"当前文件总数: {len(v1)}") print("\n=== 阶段五:像函数一样调用 ===") # 触发 __call__ result = v1("sudo apt-get update") print(result) print("\n=== 阶段六:比较 ===") v2 = VirtualServer("DB-Server-01", 16, 64) # 触发 __gt__ if v2 > v1: print(f"{v2.hostname} 性能强于 {v1.hostname}") # 触发 __eq__ if v1 != v2: print("两台服务器规格不同") print("\n=== 阶段七:上下文管理 (with) ===") # 触发 __enter__ with v1 as s: print(f" 当前状态: {s.status}") print(" 正在执行危险的维护操作...") # 模拟一个异常,触发 __exit__ 的异常处理逻辑 raise RuntimeError("硬盘故障!") # 触发 __exit__ print(f"\n检查退出后状态: {v1.status}") print("\n=== 阶段八:销毁 ===") # 手动删除引用,触发 __del__ del v1 del v2 print("=== 程序结束 ===")当你一步步调试时,请特别留意以下几个现象,如果看到了,说明你真正懂了:
初始化的连招: 注意观察
__init__里面执行self.hostname = hostname时,控制台是不是立即跳出了[3. __setattr__]的日志?
- 道理: 初始化时赋值属性,本质上也是赋值,所以会被
__setattr__拦截。
__getattr__的触发时机: 为什么访问v1.status时没有打印[4. __getattr__],而访问v1.install_nginx时却打印了?
- 道理: 因为
status真实存在,install_nginx不存在。只有找不到时才找getattr。
with语句吞异常: 注意我在with块里抛出了RuntimeError,但程序没有崩溃,而是继续往下运行了。
- 道理: 因为
__exit__返回了True,把异常给"吃"掉了。这就去调试吧!等你跑完这一遍,这15个魔术方法将刻在你的脑海里。
问题一:为什么大家都是魔术方法,却有着不同的"身份"?
你在调试器里看到的 bound method, method-wrapper, built-in method,其实揭示了这些方法的"出身"(是由 Python 代码定义的,还是由 C 语言底层实现的)。
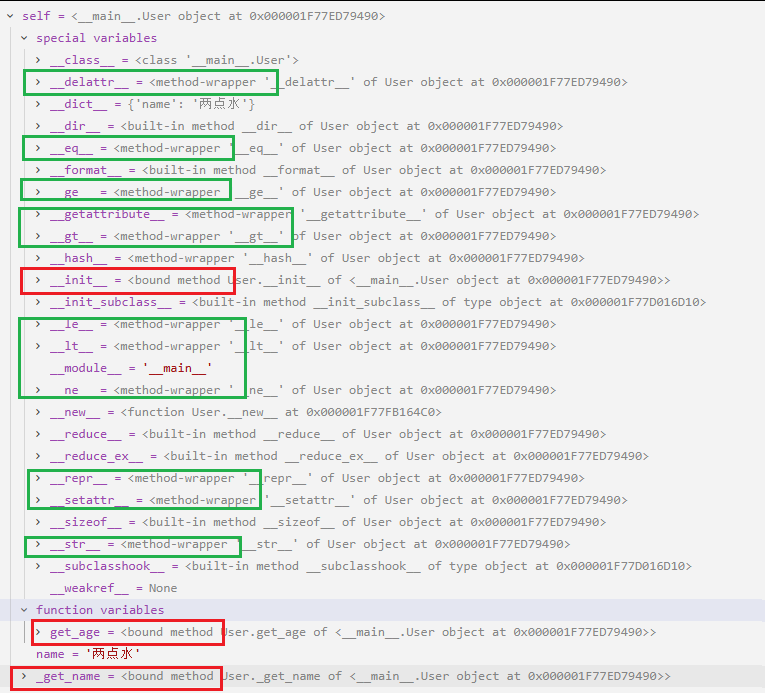
1. Bound Method (绑定方法)
例子:
__init__、get_age、_get_name截图特征:
<bound method AnonymityBreaker.__init__ of ...>出身: "平民出身" 。这是你在
class AnonymityBreaker里亲手用 Python 语法def __init__(...):写的方法。含义: "Bound" 意味着它已经和特定的实例(
self)绑定在一起了。当你调用它时,不用再传self,Python 帮你传了。2. Method-wrapper (方法包装器)
例子:
__str__,__eq__,__setattr__等截图特征:
<method-wrapper '__str__' of AnonymityBreaker object ...>出身: "皇室血统" 。这说明你没有 在你的类里重写这些方法。它们直接继承自 Python 的基类
object。含义:
object类的底层是用 C 语言写的(CPython 实现)。为了让这些 C 函数能像 Python 方法一样被你调用,Python 用一个"包装器(Wrapper)"把底层的 C 函数包了一层,暴露给你。实验: 如果你在类里写了
def __str__(self): pass,你会发现它瞬间会从method-wrapper变成bound method!3. Built-in method (内置方法)
例子:
__new__、__dir__等截图特征:
<built-in method __new__ of type object ...>出身: "神之手"。这是 Python 解释器内部最底层的实现。
含义: 特别是
__new__,它是一个静态方法(虽然你没加@staticmethod)。它不依赖于实例(因为实例还没生出来),它直接隶属于类(type)。它也是 C 语言实现的,但它的调用机制比普通的 wrapper 更原始。老师的总结:
是你写的 -> Bound Method
是继承自
object(C语言) 的 -> Method-wrapper是特殊的静态/类级别底层函数 -> Built-in method
问题二:为什么魔术方法里面还有魔术方法,好像永远点不到头?
你发现了 Python 的终极奥义:在 Python 中,方法本身也是对象。
这就好比:
你是一个人(对象)。
你的名字叫"两点水"(属性)。
"两点水"这个字符串,它自己也是一个对象(字符串对象)。
既然是字符串对象,它就有
__add__方法(用于拼接)。这个
__add__方法,它自己又是一个对象(方法对象)......让我们推演这个"无限循环":
第一层:
usr是一个对象。它有__init__方法。第二层:
usr.__init__是一个对象(类型是method)。
既然它是对象,我就能打印它。
为了能打印它,它必须得有
__str__方法。第三层:
usr.__init__.__str__是一个对象(类型是method-wrapper)。
既然它是对象,我就能比较它。
为了能比较它,它必须得有
__eq__方法。第四层:
usr.__init__.__str__.__eq__是一个对象......为什么设计成这样?
这看起来像死循环,其实是高度一致性的设计。
在 Java 或 C++ 中,方法就是代码块,不是变量。但在 Python 中,函数/方法是一等公民(First-class Citizen) 。这意味着函数和整数、字符串一样,都是实实在在存在于内存中的对象。
只要是对象,就必须遵守对象模型的规则:必须有类型(Type),必须有属性(Attribute)。
什么时候到头?
在这个"引用链"上,理论上是无限的(你可以无限点下去)。
但在"定义链"上,是有尽头的。尽头就是
type元类和object基类(C 语言实现的部分)。
type元类与object基类是什么?
第一部分:谁实例化了类?(上帝的视角)
我们之前一直说:
usr = User(),这是用模具(类)制造产品(实例)。 但你有没有想过,User这个模具本身,又是谁制造的呢?在 Python 中,有一条铁律:一切皆对象 。 既然
User是一个类,那么在内存中,User本身也是一个对象 (类对象)。既然是对象,它就必须由另一个东西"实例化"出来。这个创造类的"上帝",就是type。1.
type的双重身份很多初学者只知道
type(obj)用来查看类型,但其实它是一个重载的工具:
作为函数 :
type(obj)-> 返回对象的类型。作为类(元类) :
type(name, bases, dict)-> 创造一个新的类。2. 代码实证:徒手捏一个类
当我们写
class User:时,Python 解释器在读取这行代码时,其实在后台偷偷调用了type。我们可以不写class关键字,直接用type制造一个类:
python# --- 方式 A: 我们平时的写法 --- class User(object): age = 18 def say_hi(self): return "Hi" # --- 方式 B: 上帝视角 (底层真实发生的逻辑) --- # 语法: type(类名, 父类元组, 属性字典) def say_hi_func(self): return "Hi" # 这一行代码,彻底等价于上面的 class 定义 UserFromType = type('UserFromType', (object,), {'age': 18, 'say_hi': say_hi_func}) # 验证 u = UserFromType() print(u.say_hi()) # 输出: Hi print(type(UserFromType)) # 输出: <class 'type'>结论
- 对象 是 类 的实例。
- 类 是
type的实例。type是所有类的创造者(元类)。
第二部分:type与object的爱恨情仇(鸡生蛋问题)这是 Python 面试题里的终极 Boss,也是让无数工程师绕晕的逻辑怪圈。
请看这几行反直觉的代码:
python# 1. object 是由 type 创造的吗? print(isinstance(object, type)) # 输出: True (父亲是 type) # 2. type 是由 object 派生的吗? print(issubclass(type, object)) # 输出: True (父亲是 object) # 3. type 是由 type 自己创造的吗? print(isinstance(type, type)) # 输出: True (我 创 造 我 自 己)1. 为什么会这样?
这看起来像个死循环:"我是你爸爸,你又是我爸爸"。 要理解这个,我们需要把**"继承关系(Inheritance)"和"实例关系(Instantiation)"**彻底分开。
继承关系 (Is a kind of) :由
__bases__决定。指的是"功能上的扩展"。
- 所有的类(包括
type),最终都继承自object。object是万物之祖 (赋予了对象基本的方法,如__str__,__eq__)。实例关系 (Created by) :由
__class__决定。指的是"谁把你造出来的"。
- 所有的类(包括
object),都是由type制造在内存里的。type是万物之匠。2. 图解底层逻辑
为了让你一眼看懂,我需要为你展示这两个大佬在内存中的指向关系。
让我们看着这张图来梳理:
object的视角:
它是继承链的顶点:
object.__bases__是空的()。但它作为内存里的一个对象,是由
type创建的:object.__class__是type。人话:
object是祖师爷,但祖师爷的肉身也是造物主(type)捏出来的。
type的视角:
它也是个类,所以它得继承点什么:
type.__bases__是(object,)。所以type也是个对象,拥有object定义的那些魔术方法。它是谁造的?这是最骚的操作------
type是它自己造的 。type.__class__是type。3. 如何解决"鸡生蛋"的死循环?
你可能会问:"如果创建 object 需要 type,创建 type 又需要继承 object,那 Python 启动时是谁先存在的?"
答案是:作弊(Bootstrapping)。
在 Python 源代码(C语言层面,CPython)中,这两个东西不是通过 Python 代码动态创建的,而是直接用 C 结构体(struct)硬写进去的。
在 C 代码里,先定义了
PyType_Type(就是type) 和PyBaseObject_Type(就是object)。程序员手动把
PyType_Type的父类指针指向PyBaseObject_Type。手动把
PyBaseObject_Type的类型指针指向PyType_Type。手动把
PyType_Type的类型指针指向它自己。当 Python 虚拟机启动时,这两个东西已经"连接"好了,不需要谁先谁后,它们是一起"蹦"出来的。
2.numpy.where()用法
numpy.where() 是 NumPy 中非常实用的函数,用于条件选择。
第一种用法:numpy.where() 函数返回输入数组中满足给定条件的元素的索引。
实例代码:
import numpy as npx = np.arange(9.).reshape(3, 3)
print ('我们的数组是:')
print (x)
print ( '大于 3 的元素的索引:')
y = np.where(x > 3)
print (y)
print ('使用这些索引来获取满足条件的元素:')
print (xy)
输出结果为:
我们的数组是: [[0. 1. 2.] [3. 4. 5.] [6. 7. 8.]] 大于 3 的元素的索引: (array([1, 1, 2, 2, 2]), array([1, 2, 0, 1, 2])) 使用这些索引来获取满足条件的元素: [4. 5. 6. 7. 8.]
第二种用法: numpy.where(condition , *x* , *y* , / ) 根据 condition 从 x 或 y 中返回选定的元素。


深入学习自行跳转:
https://numpy.com.cn/doc/stable/reference/generated/numpy.where.html#numpy-where
3.random.choices()用法
在MockDataClient.get_dataset()中注入真实轨迹信号时,
原代码:
datar, c += 2.0 # 注入真实轨迹信号
建议修改:
datar, c += float(random.choices(1, 2, 3, 4, 5, weights=5, 4, 3, 2, 1, k=1)0)
将固定的 +2.0 改为加权随机数 1-5 ,权重为 5,4,3,2,1 ,保证数值从 1 到 5 的出现频率逐步降低。
random.choices(population,weights=None,*,cum_weights=None,k=1)
Python3.6版本新增。
- population:集群。
- weights:相对权重。
- cum_weights:累加权重。
- k:选取次数。
作用:从集群中随机选取k次数据,返回一个列表,可以设置权重。
注意:每次选取都不会影响原序列,每一次选取都是基于原序列。
3.debug_Plus版本优化
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import json
import random
from datetime import datetime, timedelta
from sklearn.cluster import DBSCAN
from scipy import stats
from scipy.ndimage import uniform_filter # 导入均匀滤波函数
# ==========================================
# 1. 环境模拟:MockDataClient (保持 V2.0 逻辑)
# ==========================================
class MockDataset:
def __init__(self, data_array):
self.ship_count = data_array # 船舶计数数组
class MockDataClient:
"""
模拟云平台数据接口 (Target: Taiwan Strait)
范围: Lat 22.0-26.0 N, Lon 117.0-122.0 E
精度: 0.1 度
"""
def __init__(self):
# 定义敏感海域网格参数
self.lat_min, self.lat_max = 22.0, 26.0 # 纬度范围
self.lon_min, self.lon_max = 117.0, 122.0 # 经度范围
self.grid_size = 0.1 # 网格大小为 0.1 度
self.n_rows = int((self.lat_max - self.lat_min) / self.grid_size) # 40 行
self.n_cols = int((self.lon_max - self.lon_min) / self.grid_size) # 50 列
self.track_max_step = {}
# 预生成真实的"Ground Truth"轨迹
self.ground_truth_tracks = self._generate_realistic_tracks()
def _latlon_to_grid(self, lat, lon):
"""经纬度转网格索引
参数:
lat (float): 纬度
lon (float): 经度
返回值:
r (int): 网格行索引
c (int): 网格列索引
"""
r = int((self.lat_max - lat) / self.grid_size) # 纬度向下为正行数
c = int((lon - self.lon_min) / self.grid_size)
return r, c
def _generate_realistic_tracks(self):
"""使用相关随机游走 (Correlated Random Walk) 生成符合物理规律的轨迹"""
tracks = {} # 存储所有轨迹的字典
base_time = datetime.now() - timedelta(days=30) # 从 30 天前开始模拟
# --- Vessel A: 从厦门附近开往台湾南部 (东南向) ---
path_A, max_A = self._simulate_crw_path(
start_pos=(24.5, 118.2), # 厦门附近
speed_knots=12.0, # 12 节 knot
heading_deg=135, # 东南
duration_hours=120, # 120 小时(5天)
base_time=base_time # 从 30 天前开始
)
tracks['Vessel_A'] = path_A # 轨迹点列表
self.track_max_step['Vessel_A'] = max_A # 轨迹的相邻点最大步长
# --- Vessel B: 在海峡中线附近巡逻 ---
path_B, max_B = self._simulate_crw_path(
start_pos=(23.5, 119.5), # 海峡中线附近
speed_knots=10.0, # 10 节 knot
heading_deg=45, # 东北
duration_hours=120, # 120 小时
base_time=base_time, # 从 30 天前开始
turn_rate=15.0 # 15 度/小时
)
tracks['Vessel_B'] = path_B # 轨迹点列表
self.track_max_step['Vessel_B'] = max_B # 轨迹的相邻点最大步长
return tracks
#! 新增:tracks轨迹实现可视化
def visualize_tracks(self, save_path='ground_truth_tracks.png'):
'''
可视化模拟的船舶轨迹。
参数:
save_path (str, 可选): 保存图片的路径,默认值为 'ground_truth_tracks.png'
'''
fig, ax = plt.subplots(figsize=(9, 8))
ax.set_xlim(self.lon_min, self.lon_max)
ax.set_ylim(self.lat_min, self.lat_max)
ax.grid(True, linestyle='--', alpha=0.5)
colors = ['#00ff00', '#00ffff', '#ff00ff', '#ffff00']
for i, (vessel_id, points) in enumerate(self.ground_truth_tracks.items()):
lats = [p['lat'] for p in points]
lons = [p['lon'] for p in points]
c = colors[i % len(colors)]
ax.plot(lons, lats, marker='o', linestyle='-', color=c, linewidth=2, label=vessel_id, markersize=5)
if lats and lons:
ax.text(lons[0], lats[0], 'Start', fontsize=9, color='blue', fontweight='bold')
ax.text(lons[-1], lats[-1], 'End', fontsize=9, color='red', fontweight='bold')
ax.set_title('Generated Ground Truth Tracks (Taiwan Strait)')
ax.set_xlabel('Longitude (E)')
ax.set_ylabel('Latitude (N)')
ax.legend()
plt.tight_layout()
plt.savefig(save_path, dpi=300)
plt.show()
def _simulate_crw_path(self, start_pos, speed_knots, heading_deg, duration_hours, base_time, turn_rate=5.0):
"""生成单条轨迹的核心算法
参数:
start_pos (tuple): 初始位置,格式为 (纬度, 经度)
speed_knots (float): 速度,单位为 knot
heading_deg (float): 初始航向角度,单位为度
duration_hours (int): 轨迹持续时间,单位为小时
base_time (datetime): 轨迹开始时间
turn_rate (float, 可选): 随机转向角度,单位为度/小时,默认值为 5.0
返回:
list: 轨迹点的列表,每个点包含时间和经纬度
"""
path = [] # 存储轨迹点的列表
lat, lon = start_pos # 初始位置
# 航向角度、速度单位转换(最复杂但最重要的转换)
heading = np.radians(heading_deg) # 初始航向角度 (弧度) numpy.radians将角度从度转换为弧度(比如:180度 = 3.14弧度)
speed_deg = (speed_knots * 1.852) / 111.0 # 每小时移动的角度 (弧度)
max_length = 0.0 # 相邻点最大步长
for t in range(duration_hours):
current_time = base_time + timedelta(hours=t) # 当前时间
path.append({'time': current_time, 'lat': lat, 'lon': lon})
# 位置更新(核心移动公式)
new_lat = lat + speed_deg * np.cos(heading) # 纬度变化
new_lon = lon + speed_deg * np.sin(heading) # 经度变化
step_len = float(np.sqrt((new_lat - lat) ** 2 + (new_lon - lon) ** 2)) # 经纬度平面上的欧氏距离(单位为度)
if step_len > max_length:
max_length = step_len # 更新最大步长
# 添加正态分布随机噪声:实现随机游走的关键部分
noise = np.radians(np.random.normal(0, turn_rate)) # 随机转向角度 (弧度) turn_rate越大,轨迹越曲折;越小,轨迹越直
heading += noise # 更新航向角度
lat, lon = new_lat, new_lon
return path, max_length
def get_dataset(self, dataset_name, variables, aggregation, grid_size, time_range, anonymization_level):
'''
参数:
dataset_name (str): 数据集名称
variables (list): 要查询的变量,这里是船舶计数
aggregation (str): 聚合方式,这里是网格聚合
grid_size (float): 网格大小,这里是0.1度
time_range (tuple): 查询时间范围,格式为('2023-01-01 00:00:00', '2023-01-02 00:00:00')
anonymization_level (str): 匿名化级别,这里是高匿名化
返回:
MockDataset: 包含船舶计数的模拟数据集
'''
print(f" [MockServer] Generating data for window {time_range}...")
# 1. 生成稀疏背景噪声 lam=0.1表示平均每个网格有0.1艘船 lam越小,背景噪声越稀疏
data = np.random.poisson(lam=0.05, size=(self.n_rows, self.n_cols)).astype(float) # 泊松分布生成稀疏背景噪声
# 2. 注入真实轨迹信号
q_start = datetime.strptime(time_range[0], '%Y-%m-%d %H:%M:%S')
q_end = datetime.strptime(time_range[1], '%Y-%m-%d %H:%M:%S')
for vessel_id, track in self.ground_truth_tracks.items():
for point in track: # 遍历每条轨迹中的每个点
if q_start <= point['time'] <= q_end:
r, c = self._latlon_to_grid(point['lat'], point['lon']) # 经纬度转网格索引
if 0 <= r < self.n_rows and 0 <= c < self.n_cols:
# data[r, c] += 2.0 # 注入真实轨迹信号
# 将固定的 +2.0 改为加权随机数 1-5 ,权重为 [5,4,3,2,1] ,保证数值从 1 到 5 的出现频率逐步降低
data[r, c] += float(random.choices([1, 2, 3, 4, 5], weights=[5, 4, 3, 2, 1], k=1)[0])
return MockDataset(data) # 返回包含船舶计数的模拟数据集
# ==========================================
# 2. 攻击者逻辑: AnonymityBreaker (Pro with Visualization)
# ==========================================
class AnonymityBreaker:
def __init__(self):
self.data_client = MockDataClient() # 模拟数据客户端
self.dataset_versions = {} # 存储不同版本数据集的字典
self.differential_results = {} # 存储不同版本数据集差异的字典
# 坐标系统参数 (台湾海峡区域)
self.lat_max = 26.0
self.lat_min = 22.0
self.lon_min = 117.0
self.lon_max = 122.0
self.grid_size = 0.1
# [恢复功能] 用于存储累积的差分热力图数据
# 40行 x 50列
self.n_rows = int((self.lat_max - self.lat_min) / self.grid_size)
self.n_cols = int((self.lon_max - self.lon_min) / self.grid_size)
self.cumulative_diff_matrix = np.zeros((self.n_rows, self.n_cols)) # 存储累积差分信号的矩阵
self.track_scores = {} # 每条重建轨迹的评分日志
def _grid_to_latlon(self, row, col):
"""网格索引转真实经纬度"""
lat = self.lat_max - (row * self.grid_size) - (self.grid_size/2) # 纬度 = 最大纬度 - 行索引 * 网格大小 - 网格大小/2
lon = self.lon_min + (col * self.grid_size) + (self.grid_size/2) # 经度 = 最小经度 + 列索引 * 网格大小 + 网格大小/2
return round(lat, 3), round(lon, 3) # 返回四舍五入到3位小数的纬度和经度
def fetch_anonymous_releases(self, dataset_name, version_count=5):
"""[Step 1] 获取数据:滑动窗口查询
参数:
dataset_name (str): 数据集名称
version_count (int): 要获取的版本数量,默认5个版本
"""
print(f"[+] Fetching {version_count} versions of {dataset_name} (Taiwan Strait Area)...")
base_time = datetime.now() - timedelta(days=30) # 从当前时间开始,往前推30天
for i in range(version_count):
version_id = f"v_seq_{i}" # 每个版本的版本ID,格式为v_seq_0, v_seq_1, ..., v_seq_{version_count-1}
t_start = base_time + timedelta(hours=i) # 每个版本的查询开始时间,从base_time开始,每个版本间隔1小时
t_end = base_time + timedelta(hours=i+1) # 每个版本的查询结束时间,从base_time开始,每个版本间隔1小时
time_str_fmt = '%Y-%m-%d %H:%M:%S' # 时间格式,这里是'年-月-日 时:分:秒'
try:
anonymous_data = self.data_client.get_dataset(
dataset_name=dataset_name, # 数据集名称
variables=['ship_count'], # 要查询的变量,这里是船舶计数
aggregation='grid', # 聚合方式,这里是网格聚合
grid_size=0.1, # 网格大小,这里是0.1度
time_range=(t_start.strftime(time_str_fmt), t_end.strftime(time_str_fmt)), # 查询时间范围
anonymization_level='high' # 匿名化级别,这里是高匿名化
)
self.dataset_versions[version_id] = anonymous_data # 存储每个版本的匿名数据集
print(f" Acquired {version_id}: {t_start.strftime('%H:%M')} -> {t_end.strftime('%H:%M')}")
time.sleep(0.1) # 模拟查询延迟,避免对服务器压力过大
except Exception as e:
print(f" Failed: {e}")
def differential_analysis(self):
"""[Step 2] 差分分析与信号提取"""
print("[+] Performing statistical differential analysis...")
versions = list(self.dataset_versions.keys()) # 获取所有版本的ID
for v_id in versions: # 遍历每个版本的ID
data = self.dataset_versions[v_id].ship_count # 提取当前版本的船舶计数数据
smooth = uniform_filter(data, size=3) # 对数据进行平滑处理(使用大小为3的均匀滤波器)
mu = np.mean(smooth) # 均值(mu)
sigma = np.std(smooth) # 标准差(sigma)
tau = max(mu + 3.0 * sigma, np.percentile(smooth, 95)) # 设置阈值tau:取(mu+3*sigma)和平滑后数据的95%分位数中的较大值
mask = smooth > tau # 创建一个掩膜(mask),标记平滑后数据中大于阈值tau的位置。
self.cumulative_diff_matrix += mask.astype(float) # 将掩膜转换为浮点数矩阵,并累加到累积差分矩阵中
potential_targets = [] # 存储当前版本中所有潜在目标点的列表
rows, cols = data.shape
for r in range(rows):
for c in range(cols): # 遍历数据的每个网格点
if mask[r, c]: # 如果掩膜在该位置为True(即超过阈值)
lat, lon = self._grid_to_latlon(r, c)
potential_targets.append({'grid_r': r, 'grid_c': c, 'lat': lat, 'lon': lon, 'val': float(data[r, c]), 'version': v_id})
self.differential_results[v_id] = potential_targets # 将当前版本的潜在目标列表存储到differential_results字典中,键为版本ID
print(f" Analyzing {v_id}: Found {len(potential_targets)} potential signals")
def track_reconstruction(self):
"""[Step 3] 轨迹重建"""
print("[+] Attempting multi-target trajectory reconstruction...")
all_points = [] # 存储所有潜在目标点的列表
for vid, points in self.differential_results.items(): # 遍历字典中每一个K-V对
for p in points: # 遍历列表中每一个值
p['time_idx'] = int(vid.split('_')[-1]) # 从版本ID中提取时间索引,例如v_seq_0 -> 0
all_points.append(p) # 将每个点又加入了列表中,每个点都有了时间索引
if not all_points: return {} # 如果没有任何潜在目标点,直接返回空字典
df = pd.DataFrame(all_points)
# DBSCAN 空间聚类
coords = df[['lat', 'lon']].values
#! 新增:聚类 eps 动态绑定到最大步长
eps_val = max(self.data_client.track_max_step.values()) if self.data_client.track_max_step else 0.2
clustering = DBSCAN(eps=eps_val, min_samples=5).fit(coords)
df['cluster'] = clustering.labels_
reconstructed_tracks = {} # 存储所有重建轨迹的字典
unique_clusters = set(df['cluster']) # 获取所有唯一的聚类标签(set无序不重复)
if -1 in unique_clusters: unique_clusters.remove(-1)
max_cluster_size = max(len(df[df['cluster'] == cid]) for cid in unique_clusters) if unique_clusters else 1
versions_count = len(self.dataset_versions)
print(f" Identified {len(unique_clusters)} distinct vessel tracks.")
for cluster_id in unique_clusters:
track_points = df[df['cluster'] == cluster_id].sort_values('time_idx') # 布尔索引+排序,获取当前簇的所有点,按时间索引升序排列
processed_track = []
for _, row in track_points.iterrows():
node_conf = 0.5 + 0.5 * float(min(row['val'] / 5.0, 1.0))
processed_track.append({'lat': row['lat'], 'lon': row['lon'], 'time_seq': row['time_idx'], 'confidence': node_conf})
reconstructed_tracks[f"Target_{cluster_id}"] = processed_track
start, end = processed_track[0], processed_track[-1]
print(f" [Target_{cluster_id}] Path: ({start['lat']},{start['lon']}) -> ... -> ({end['lat']},{end['lon']})")
size_score = len(track_points) / max_cluster_size
strength_score = float(np.clip(track_points['val'].mean() / 5.0, 0.0, 1.0))
temporal_score = track_points['time_idx'].nunique() / max(1, versions_count)
total_score = round(0.4 * size_score + 0.3 * strength_score + 0.3 * temporal_score, 3)
self.track_scores[f"Target_{cluster_id}"] = {'size': round(size_score,3), 'strength': round(strength_score,3), 'temporal': round(temporal_score,3), 'score': total_score}
for tid, sc in self.track_scores.items():
print(f" [Score] {tid}: size={sc['size']}, strength={sc['strength']}, temporal={sc['temporal']}, total={sc['score']}")
return reconstructed_tracks
def visualize_results(self, tracks):
"""
[恢复功能] 生成双视图:左侧热力图,右侧轨迹图
"""
print("[+] Generating combined visualization: attack_result_visualization.png")
try:
# 创建 1行2列 的图布
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(18, 8))
# --- 子图 1: 差分累积热力图 (Differential Heatmap) ---
# 使用 extent 将网格索引映射回经纬度范围
# 注意:imshow 默认原点在左上角 (Row 0),对应的应该是 lat_max
# 所以 extent 顺序是 [left, right, bottom, top] = [lon_min, lon_max, lat_min, lat_max]
im = ax1.imshow(
self.cumulative_diff_matrix, # 差分累积矩阵
cmap='hot', # 热图颜色映射,值越高越红
interpolation='nearest', # 最近邻插值,避免像素化
extent=[self.lon_min, self.lon_max, self.lat_min, self.lat_max], # 经纬度范围
aspect='auto' # 自动调整纵横比,保持网格单元格的正方形
)
ax1.set_title(f'Cumulative Activity Heatmap (Grid Precision: {self.grid_size}°)')
ax1.set_xlabel('Longitude (E)')
ax1.set_ylabel('Latitude (N)')
ax1.grid(True, linestyle='--', alpha=0.3) # 绘制网格线,透明度0.3
plt.colorbar(im, ax=ax1, label='Signal Accumulation Count') # 为热力图添加颜色条,显示信号累加计数
# --- 子图 2: 重建轨迹图 (Reconstructed Trajectories) ---
# 绘制背景
ax2.set_xlim(self.lon_min, self.lon_max) # 设置x轴范围为经纬度范围
ax2.set_ylim(self.lat_min, self.lat_max) # 设置y轴范围为经纬度范围
ax2.grid(True, linestyle='--', alpha=0.5) # 绘制网格线,透明度0.5
colors = ['#00ff00', '#00ffff', '#ff00ff', '#ffff00', '#ff0000', '#0000ff', '#00ff00'] # 鲜艳的颜色方便观察
# 绘制每条识别出的轨迹
for i, (target_id, points) in enumerate(tracks.items()):
lats = [p['lat'] for p in points] # 提取轨迹点的纬度列表
lons = [p['lon'] for p in points] # 提取轨迹点的经度列表
c = colors[i % len(colors)] # 为每个轨迹分配不同颜色,循环使用颜色列表
# 绘制线段和点
# marker='o'表示每个点都用圆圈标记
# linestyle='-'表示用实线连接点
# linewidth=2表示线宽为2
# label=target_id表示为每条轨迹添加标签,用于图例
# markersize=5表示每个点的标记大小为5
ax2.plot(lons, lats, marker='o', linestyle='-', color=c, linewidth=2, label=target_id, markersize=5)
# 标记起点和终点
ax2.text(lons[0], lats[0], 'Start', fontsize=9, color='blue', fontweight='bold')
ax2.text(lons[-1], lats[-1], 'End', fontsize=9, color='red', fontweight='bold')
ax2.set_title('Reconstructed Vessel Trajectories (Taiwan Strait)')
ax2.set_xlabel('Longitude (E)')
ax2.set_ylabel('Latitude (N)')
ax2.legend()
plt.tight_layout()
plt.savefig('attack_result_visualization.png', dpi=300)
print(" Visualization saved to 'attack_result_visualization.png'")
plt.show()
except Exception as e:
print(f" Viz Error: {e}")
import traceback
traceback.print_exc()
def execute_attack(self):
print("[+] Starting Batch Anonymous Data Re-identification (Target: Taiwan Strait)...")
#! 新增:可视化原始轨迹
self.data_client.visualize_tracks(save_path='ground_truth_tracks.png')
# 1. 获取数据 (10个时间切片)
self.fetch_anonymous_releases('strait_shipping_density', version_count=10)
# 2. 统计分析
self.differential_analysis()
# 3. 轨迹重建
tracks = self.track_reconstruction()
# 4. 可视化与导出
if tracks:
self.visualize_results(tracks)
with open('strait_targets.json', 'w') as f:
json.dump(tracks, f, indent=2)
print("[+] Attack Completed. Sensitive targets exported.")
if __name__ == "__main__":
attacker = AnonymityBreaker()
attacker.execute_attack()新增内容
- 引入局部平滑与自适应阈值进行统计学去噪,替换原先的简单二值化累加
- 动态聚类半径 eps 已与真实轨迹最大步长绑定;将 min_samples 调整为 3 提升鲁棒性
- 为每条轨迹计算综合评分:规模、强度、时间覆盖,并输出评分日志
核心逻辑变化
(1)差分与去噪
- 使用 uniform_filter(data, size=3) 做局部平滑,抑制泊松噪声的椒盐效应
- 自适应阈值 tau = max(μ + 3σ, P95) ,只将显著高于背景的格点记为潜在目标
- 累积热力图叠加的是显著掩码 mask.astype(float) ,而非粗糙二值化
- 潜在目标点按掩码筛选,保留原始强度 val=datar,c 用于后续评分
(2)聚类与评分
- eps = max(track_max_step) 动态绑定真实运动步长; min_samples=3
- 为每个簇计算综合评分:
- size_score = 簇点数 / 所有簇的最大点数
- strength_score = 簇内平均信号强度 / 5.0 (注入强度上限 5)
- temporal_score = 簇覆盖的不同时间窗数 / 版本总数
- total_score = 0.4*size + 0.3*strength + 0.3*temporal
- 将评分写入 self.track_scores 并打印日志,例如:
- Score Target_0: size=0.83, strength=0.72, temporal=0.60, total=0.72
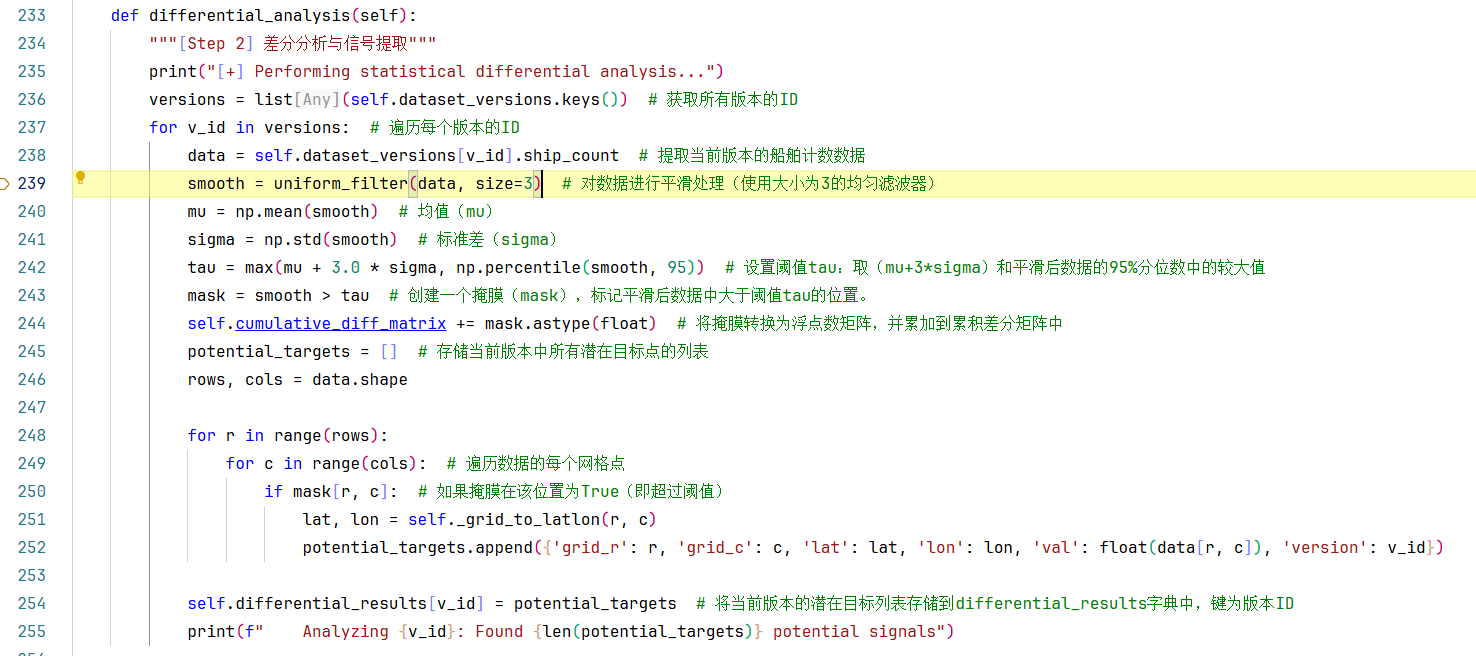
第239行:uniform_filter(data, size=3) # 对数据进行平滑处理(使用大小为3的均匀滤波器)
scipy.ndimage.uniform_filter是什么?请见附录1
uniform_filter- 均匀滤波器,用来平滑数据size=3- 使用3×3的窗口

经过滤波处理后,就能将那些很凸的异常值抚平一些,让它们看起来更平滑,所以叫平滑处理。在图像处理领域,滤波器可以使图像的二维像素值变的平滑,从而让图像变模糊。
**第242行:tau = max(mu + 3.0 * sigma, np.percentile(smooth, 95)) #**取(mu+3*sigma)和平滑后数据的95%分位数中的较大值,作为tau阈值

为什么这样做? 这是双重保险,确保阈值足够高,只筛选出真正显著的点。

【重要】通过上述公式计算出的tau阈值,将是后面筛选出显著网格点的一个依据。
numpy.percentile的用法见附录2
第243行:mask = smooth > tau # 创建一个掩膜(mask),标记平滑后数据中大于阈值tau的位置。
mask- 掩膜,是一个布尔矩阵(True/False)smooth > tau- 对平滑后的数据,每个位置判断:是否大于阈值?
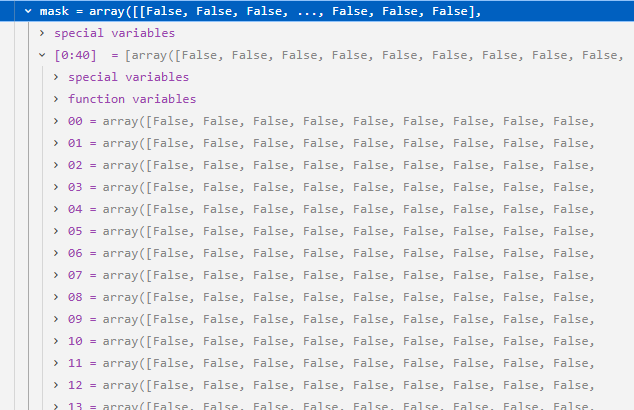
**第244行:self.cumulative_diff_matrix += mask.astype(float) #**将掩膜转换为浮点数矩阵,并累加到累积差分矩阵中。

248-252行:遍历数据的每个网格点,如果掩膜在该位置为True(即超过阈值),就将该点的字典信息加入potential_targets列表,该列表用于存储所有潜在目标点。
第254行:self.differential_resultsv_id = potential_targets
该循环块结束后,将当前版本的潜在目标列表potential_targets存储到differential_results字典中,键为版本ID
237-255行所有版本遍历完后,累积差分矩阵self.cumulative_diff_matrix和不同版本目标字典self.differential_results分布如下所示:
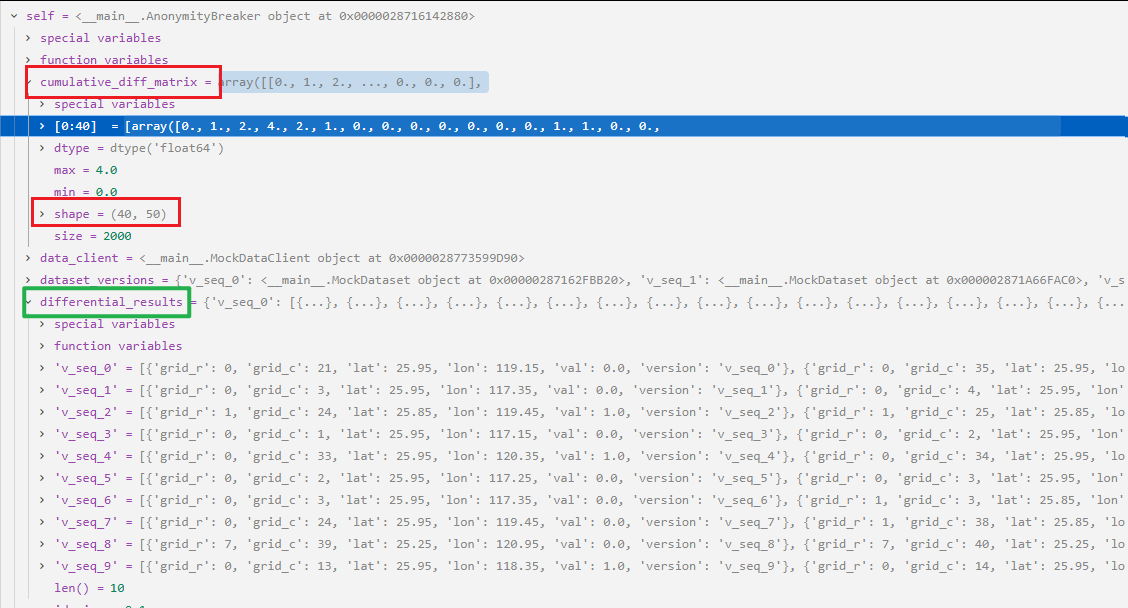
附录
1.scipy.ndimage.uniform_filter:多维均匀滤波器
首先跳转官网看一下基本定义、参数、返回值的情况:

- 大概就是,相当于生成了一个和原始图像大小一模一样的滤波后图像,只是有一部分数值变化了。
- 多维滤波器是通过一系列一维均匀滤波器实现的。
- 最后的Examples,展示了这种多维滤波器通过对像素矩阵进行处理,实现一个模糊的效果,好像滤波器这个玩意是图像处理中的常用手段。
但具体计算原理我没搞懂,我需要理解这个函数的工作原理和使用方法,于是我继续搜索: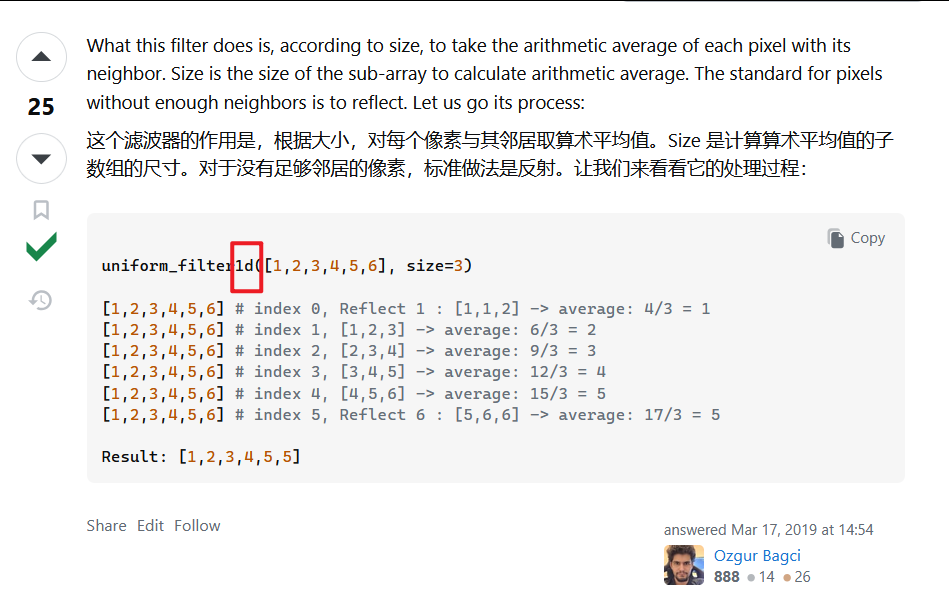 https://stackoverflow.com/questions/55207719/cant-understand-the-working-of-uniform-filter1d-function-imported-from-scipy
https://stackoverflow.com/questions/55207719/cant-understand-the-working-of-uniform-filter1d-function-imported-from-scipy
上面这是1维滤波器的原理,官网上说了多维滤波器是通过一系列一维均匀滤波器实现的。
下面是model参数设置:模式参数决定当滤波器与边界重叠时如何扩展输入数组。(默认mode='reflect')
还有一个要注意的点就是:如果采用均值卷积核来对二维数组进行滤波时,在使用uniform_filter时在边界处会出现难以解释的值,该该如何来理解?
import numpy as np
x = np.array([
1, 2, 3,4,5,
6, 7, 8,9,10,
11,12,13,14,15,
16,17,18,19,20,
21,22,23,24,25
])
均值滤波
from scipy.ndimage import uniform_filter
y = uniform_filter(x, size=3,mode='reflect')
print(y)
那么根据反射复制填充,当核运行到x的第一个元素1,核中元素应该是:
| 1 | 1 | 2 |
| 1 | 1 | 2 |
| 6 | 6 | 7 |
(1+1+2)+(1+1+2)+(6+6+7) / 9 = 3
则均值的计算结果应该是3,为什么结果输出的是2呢?
这是因为定义的x数组是整型数组,uniform_filter会自动输出一个整数结果。由于uniform_filter在处理二维数组时,其实是多次一维滤波的结果平均,因此其实际的计算路径是:
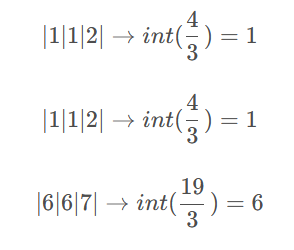

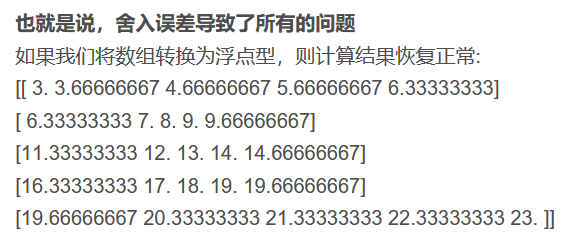
注意:在我的代码中,我的data二维数组的值已经是float64浮点数类型了,不会出现整数整除的舍入问题。
详细请见相关链接:
https://blog.csdn.net/weixin_53195427/article/details/140169717
2.numpy.percentile():计算数据沿指定轴的第 q 个百分位数。
numpy.percentile() 计算指定轴上数据 q 分位的值。百分位数是一个指标,表示在一个组中,给定百分比的观察值低于该值。示例:

详细请见相关链接:
https://numpy.com.cn/doc/stable/reference/generated/numpy.percentile.html#numpy-percentile
https://www.geeksforgeeks.org/python/numpy-percentile-in-python/