目录
[一、火山引擎大模型与 LangChain 的集成](#一、火山引擎大模型与 LangChain 的集成)
[1. 官方SDK缺失](#1. 官方SDK缺失)
[2. ChatOpenAI 方式的流式局限](#2. ChatOpenAI 方式的流式局限)
[三、利用 ChatDeepSeek 实现推理与回答的完整流式输出](#三、利用 ChatDeepSeek 实现推理与回答的完整流式输出)
[1. 核心 ChatDeepSeek 初始化](#1. 核心 ChatDeepSeek 初始化)
[2. 编写流式解析逻辑](#2. 编写流式解析逻辑)
[3. Agent 创建与执行](#3. Agent 创建与执行)
环境配置详见:https://blog.csdn.net/W_Meng_H/article/details/155595693
一、火山引擎大模型与 LangChain 的集成
1. 官方SDK缺失
目前 LangChain 官方仓库中 没有 直接针对火山引擎大模型服务的模型类。通常需要自行封装 Volcano Engine 的 HTTP API,或者寻找其他兼容的第三方 LangChain 封装。
火山引擎提供的兼容方案:https://www.volcengine.com/docs/82379/1330626?lang=zh#langchain-openai-sdk
2. ChatOpenAI 方式的流式局限
为了快速兼容,我尝试使用 LangChain 中通用的 ChatOpenAI 类,可以实现模型的对接,但是,这种方式往往只能流式输出模型的"最终回答"(Final Answer)部分。 对于 Agent 在执行工具调用之前的 "思考过程"(Reasoning/Thought),ChatOpenAI 的流式机制可能无法捕获或有效解析这部分信息。
二、官方社区的解决方案
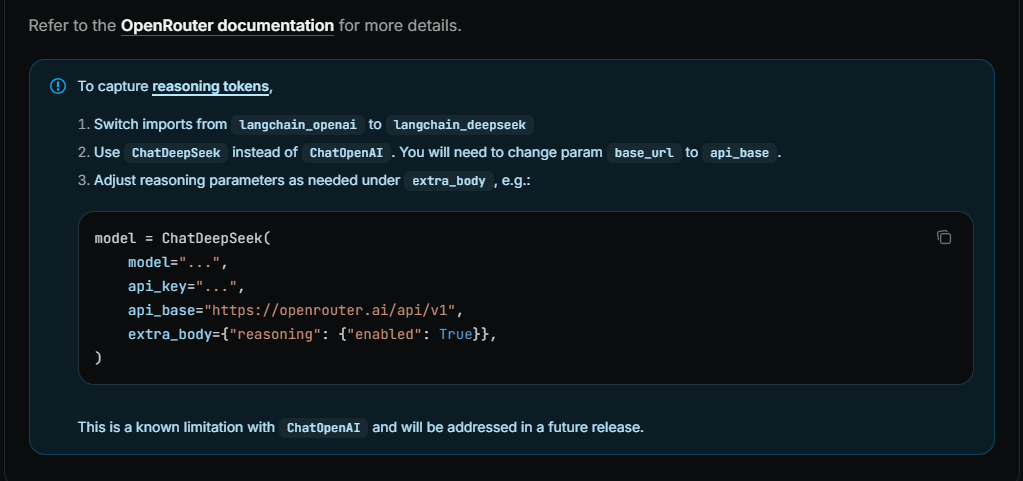
正是由于上述的流式输出痛点,在查阅 GitHub Issues 和相关官方文档后,我找到了 LangChain-DeepSeek 项目。它的 ChatDeepSeek 类在设计时,考虑到了大模型在流式输出中包含的 additional_kwargs 字段,尤其是用于承载 推理信息 的内容(在火山引擎中对应于reasoning_content 字段)。
官方链接:https://docs.langchain.com/oss/python/integrations/chat#example-openrouter
三、利用 ChatDeepSeek 实现推理与回答的完整流式输出
我们使用 LangChain-DeepSeek 提供的 ChatDeepSeek 类,直接传入火山引擎的 API Key 和 Base URL,并开启 streaming。
1. 核心 ChatDeepSeek 初始化
python
from langchain_deepseek.chat_models import ChatDeepSeek
# 初始化 ChatDeepSeek
volcano_chat = ChatDeepSeek(
api_key=VOLC_API_KEY,
api_base=VOLC_BASE_URL,
model=VOLC_MODEL_NAME, # 火山引擎的模型名称
top_p=MODEL_TOP_P,
streaming=True,
# 请求体中开启 thinking 字段,让模型返回思考过程
extra_body={"thinking": {"type": "enabled"}}
)2. 编写流式解析逻辑
由于 ChatDeepSeek 能够将推理内容放入 message_chunk.additional_kwargs 中,我们需要一个自定义的流式解析函数来区分和打印 思考内容 和 最终回答。
我们使用两个全局变量 REASONING_BUFFER 和 AGENT_STAGE 来管理输出状态:
-
AGENT_STAGE = 0 (思考阶段): 累积并实时打印 reasoning_content 内容。
-
AGENT_STAGE = 1 (回答阶段): 在 content 首次出现时,打印思考总结并切换阶段,然后开始打印 content。
python
# 引入 REASONING_BUFFER 和 AGENT_STAGE
REASONING_BUFFER = ""
AGENT_STAGE = 0 # 0: 思考阶段, 1: 最终回答阶段
def format_stream_step(step: Dict[str, Any]) -> None:
global REASONING_BUFFER, AGENT_STAGE
message_chunk = step[0]
# 提取 reasoning 内容
reasoning = message_chunk.additional_kwargs.get('reasoning_content', '')
content = message_chunk.content or ''
# 1. 累积思维内容 (STAGE 0)
if reasoning.strip():
REASONING_BUFFER += reasoning
if AGENT_STAGE == 0:
print(f"{reasoning}", end="", flush=True) # 实时打印思考
# 2. 如果 Content 出现 (触发 STAGE 切换)
if content:
if AGENT_STAGE == 0:
# 首次出现 Content,代表思考结束或工具结果返回
print("\n" + "=" * 20 + "流式推理过程" + "=" * 20)
if REASONING_BUFFER.strip():
print(f"🧠 [思考总结]: {REASONING_BUFFER}\n", end="", flush=True)
# 切换到回答阶段
print(f"🤔 [回答]: ", end="", flush=True)
AGENT_STAGE = 1
# 2b. 打印正文内容 (Answer)
if AGENT_STAGE == 1:
print(content, end="", flush=True)3. Agent 创建与执行
最后,我们将 ChatDeepSeek 模型、和动态 System Prompt 中间件组合成一个完整的 Agent。
python
# 创建Agent
agent = create_agent(
model=volcano_chat,
middleware=[user_role_prompt]
)
# 执行并遍历流
stream = agent.stream(...)
for step in stream:
format_stream_step(step)
print("\n\n推理完成!")四、总结
通过使用 ChatDeepSeek 作为代理,并编写自定义的流式解析逻辑,我们实现了:
-
完整流式体验: 思考过程和最终回答都能实时打印。
-
Agent 透明化: 用户能清晰看到 Agent 是如何思考、决定调用工具,并最终给出答案的全过程。
-
兼容性增强: 成功将 LangChain Agent 的能力与 Volcano Engine 的强大模型结合起来。