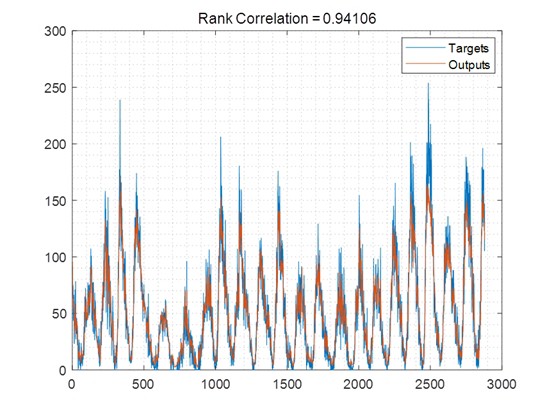
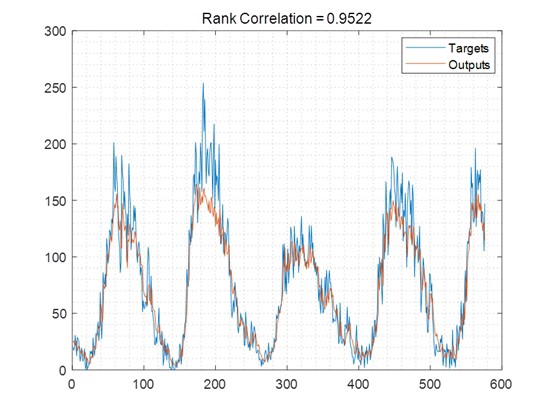
MATLAB环境下简单的基于双向长短时记忆网络的时间序列预测 1997年Schuster提出了双向循环神经网络BiRNN,其由一个正向和反向的循环神经元组成,前向神经元的输出直接作为后向神经元的输入。 受到BiRNN的启发,因此学者对LSTM进行改进,提出了双向长短时记忆网络BiLSTM。 其在处理序列数据时不仅能访问过去时刻的信息,而且能够访问未来时刻的信息。 双向长短时记忆网络能够利用双向信息更好的处理序列数据,从而提高模型的准确率。 鉴于双向长短时记忆网络的优势,本项目采用双向长短时记忆网络对若干时间序列进行预测,包括国际航空旅客人数预测、全球冰储量预测、感染水痘人数预测、极紫外光预测、事故预测和240年的太阳黑子预测,运行环境为MATLAB R2021B。 clc; clear; close all; %% ---------------------------- init Variabels ---------------------------- opt.Delays = 1 2 3 4 5 6 7 8 9 10 12 16 20; opt.dataPreprocessMode = 'Data Standardization'; % 'None' 'Data Standardization' 'Data Normalization' opt.learningMethod = 'LSTM'; % 'MLP' 'LSTM' opt.trPercentage = 0.8; % divide data into Test and Train dataset
在时间序列预测的领域里,我们总是在寻找更有效的模型。1997 年 Schuster 提出的双向循环神经网络 BiRNN 可以说是一个重要的里程碑,它由一个正向和反向的循环神经元组成,前向神经元的输出直接作为后向神经元的输入,这一独特的结构让模型对序列的处理有了新的视角。
受到 BiRNN 的启发,学者们对 LSTM(长短期记忆网络)进行改进,提出了双向长短时记忆网络 BiLSTM。这个改进可不得了,BiLSTM 在处理序列数据时,不仅能访问过去时刻的信息,还能够获取未来时刻的信息。这就好比一个人在走路,不仅能回顾走过的路,还能提前看到前方的情况,从而更好地做出决策。这种双向信息的利用,极大地提升了模型处理序列数据的能力,进而提高了模型的准确率。
鉴于双向长短时记忆网络的这些优势,我参与的这个项目决定采用 BiLSTM 对多种时间序列进行预测,像国际航空旅客人数预测、全球冰储量预测、感染水痘人数预测、极紫外光预测、事故预测以及跨度达 240 年的太阳黑子预测,运行环境则选定为 MATLAB R2021B。
下面我们来看看项目开头的一段 MATLAB 代码:
matlab
clc; clear; close all;
%% ---------------------------- init Variabels ----------------------------
opt.Delays = [1 2 3 4 5 6 7 8 9 10 12 16 20];
opt.dataPreprocessMode = 'Data Standardization'; % 'None' 'Data Standardization' 'Data Normalization'
opt.learningMethod = 'LSTM'; % 'MLP' 'LSTM'
opt.trPercentage = 0.8; % divide data into Test and Train datasetclc; clear; close all; 这三行代码简单粗暴,clc 是清空命令行窗口,这样我们后续运行代码输出的结果就不会被之前的内容干扰,看着清爽;clear 是清除工作区中的所有变量,防止之前定义的变量名冲突或者对当前项目产生不必要的影响;close all 则关闭所有打开的图形窗口,避免图形窗口过多占用资源,也让后续绘图更加有序。
再看下面这几行初始化变量的代码。opt.Delays = [1 2 3 4 5 6 7 8 9 10 12 16 20]; 这里定义了一个延迟向量,在时间序列预测中,延迟的选择很关键,它决定了模型能参考到过去哪些时刻的数据,就像刚才说的回顾走过的路,这个向量就规定了能看多远。
opt.dataPreprocessMode = 'Data Standardization'; 这里选择了数据预处理的方式为"数据标准化",还有其他可选模式注释在后面,数据预处理能让数据更符合模型的"口味",提升模型的表现,就像做菜前要把食材处理好一样。
opt.learningMethod = 'LSTM'; 明确了使用 LSTM 作为学习方法,当然也可以选择 MLP(多层感知机),不同的学习方法有各自的特点和适用场景,这里基于项目对 BiLSTM 的需求选择了 LSTM。
opt.trPercentage = 0.8; 设定了将数据划分为训练集和测试集的比例,80%的数据用于训练模型,20%用于测试,合理的划分能让模型既学到足够的知识,又能在新数据上检验学习成果。
通过这些初始化设置,我们就为基于 BiLSTM 的时间序列预测在 MATLAB 环境中搭建好了初步的舞台,后续就可以在这个基础上大展身手,进行模型构建、训练和预测等一系列操作啦。