目录
[二.实用 Helper 工具](#二.实用 Helper 工具)
[2.1.sqlite 基础操作类](#2.1.sqlite 基础操作类)
[2.3.UUID 生成器类](#2.3.UUID 生成器类)
Linux机器上创建mq项目, 并且规划开发目录, 使用Makefile组织项目。
mkdir -p mymq/{demo,mqclient,mqcommon,mqserver,mqtest,third}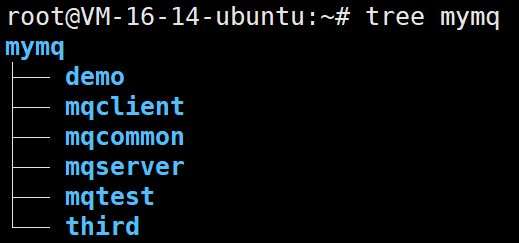
- demo:编写一些功能用例时所在的目录
- mqcommon: 公共模块代码(线程池,数据库访问,文件访问,日志打印,pb相关,以及其他的一些琐碎功能模块代码)
- mqclient: 客户端模块代码
- mqserver: 服务器模块代码
- mqtest: 单元测试
- third: 用到的第三方库存放目录
我们先来处理一下这个third目录
首先这个third里面其实就是存放了Muduo库相关的
还记得我们前面在讲解Moduo库的时候使用的这个Muduo源码的目录吗:【消息队列项目】Muduo库的介绍-CSDN博客
我们直接把这个目录拷贝过来当我们的third目录。
cp -r /root/test/muduo/* /root/mymq/third/
现在就完美了。
接下来我们在本篇文章就是实现:
mqcommon: 公共模块代码(线程池,数据库访问,文件访问,日志打印,pb相关,以及其他的一些琐碎功能模块代码)
这个目录的代码
一.日志输出工具宏的实现
首先我们进入/mymq/demo目录

为了便于编写项目中能够快速定位程序的错误位置,因此编写一个日志打印类,进行 简单的日志打印。
封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
例如: 17.22.58 log.cpp:12打开文件失败
那么具体怎么实现呢?
那么还记得
您可以把__FILE__和__LINE__理解为两个"魔法标记",它们的作用是在编译时,由编译器自动填入当前代码所在的位置信息。
它们的具体含义如下:
- FILE
- 它是什么:它是一个字符串常量。
- 它代表什么:它代表了**当前源代码文件的完整路径名或文件名。**编译器在处理这行代码时,会将它替换成当前源文件的名字。例如,如果你的文件叫做 main.c,那么 FILE 就会被替换为 "main.c"。在某些编译环境中,它可能会包含完整的文件路径,如 "D:/project/src/main.c"。
- LINE
- 它是什么:它是一个整数常量。
- 它代表什么:它代表了**当前代码在源文件中的行号。**编译器会将它替换成一个数字,这个数字就是这行代码(即 LINE 这行本身)在文件中的具体行数。如果你把这段代码移动到文件的第50行,那么 LINE 的值在下次编译时就会变成50。
cpp
#include<iostream>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
printf("[%s:%d] Hello World!\n",__FILE__,__LINE__);
}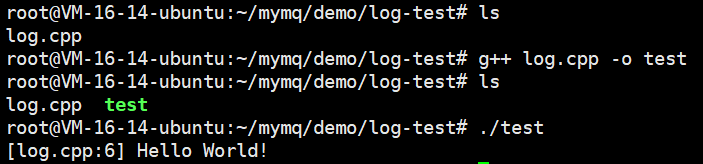
可以看到。还是很不错的
但是还有一个系统事件呢!这个怎么搞?
我们需要学习一些新的东西
1. time() 函数 - 获取时间戳
cpp
time_t t = time(nullptr);作用:
- time() 函数返回从 1970年1月1日00:00:00 UTC(Unix纪元)到当前时间的秒数
- 这个秒数被称为 "时间戳" 或 "Unix时间戳"
- time_t 是一个整数类型(通常是 long int),用于存储这个秒数
参数:
- nullptr(或 NULL)表示我们不需要将时间戳存储到额外的地方
- 如果传入一个 time_t 类型变量的地址,函数也会把时间戳写入那个地址
类比:
想象一个从1970年1月1日开始计时的巨大秒表,time() 就是按下秒表查看当前累积秒数的按钮。
2. localtime() 函数 - 转换成本地时间结构
cpp
struct tm* ptm = localtime(&t);作用:
- 将 time() 得到的秒数(时间戳)转换成本地时间的各个组成部分
- 返回一个指向 tm 结构体的指针,这个结构体包含了年、月、日、时、分、秒等各个字段
tm 结构体包含的字段:
- tm_sec - 秒 (0-59)
- tm_min - 分 (0-59)
- tm_hour - 时 (0-23)
- tm_mday - 一个月中的第几天 (1-31)
- tm_mon - 月 (0-11,0代表1月)
- tm_year - 年(从1900年开始的年数,2023年就是123)
- tm_wday - 一周中的第几天 (0-6,0代表周日)
- tm_yday - 一年中的第几天 (0-365)
- tm_isdst - 夏令时标志
重要注意事项:
- localtime() 返回的是指向静态内存区域的指针,这意味着:
- 每次调用 localtime() 都会覆盖上次的结果
- 不需要手动释放这个指针指向的内存
如果需要保存结果,应该复制结构体的内容,而不是直接保存指针
3. strftime() 函数 - 格式化时间字符串
cpp
strftime(time_str, 31, "%H:%M:%S", ptm);作用:
将 tm 结构体中的时间信息按照指定的格式字符串格式化成可读的字符串
参数详解:
- time_str:目标字符数组,用于存放格式化后的字符串
- 31:最多写入的字符数(包括结尾的空字符\0)
- "%H:%M:%S":格式控制字符串
ptm:指向 tm 结构体的指针
常用格式说明符:
- %H:24小时制的小时 (00-23)
- %I:12小时制的小时 (01-12)
- %M:分钟 (00-59)
- %S:秒 (00-59)
- %p:AM/PM 指示符
- %Y:4位数的年份
- %y:2位数的年份
- %m:月份 (01-12)
- %d:日 (01-31)
- %A:完整的星期几名称
- %a:缩写的星期几名称
- %B:完整的月份名称
- %b或%h:缩写的月份名称
示例格式:
- "%Y-%m-%d %H:%M:%S" → "2023-12-25 14:30:45"
- "%a %b %d %H:%M:%S %Y" → "Mon Dec 25 14:30:45 2023"
我们就能写出下面这个
cpp
#include<iostream>
#include<ctime>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
int main()
{
time_t t=time(nullptr);
struct tm* ptm=localtime(&t);
char time_str[32];
strftime(time_str,31,"%H:%M:%S",ptm);
printf("[%s][%s:%d] Hello World!\n",time_str,__FILE__,__LINE__);
}
但是我们不能每次调用的时候都写这么多代码吧
那么我们就需要将它封装成宏函数
宏函数相关知识
在 C/C++ 中,宏函数必须定义在一行内,或者通过反斜杠(\)进行换行连接。
cpp
// ✅ 正确的多行写法(使用反斜杠续行)
#define COMPLEX_MACRO(a, b, c) do { \
int result = (a) + (b); \
if (result > (c)) { \
printf("Too big: %d\n", result); \
} else { \
printf("OK: %d\n", result); \
} \
} while(0)
// 这样子写也行,但是可读性极其差劲
#define COMPLEX_MACRO_ONE_LINE(a, b, c) do { int result = (a) + (b); if (result > (c)) { printf("Too big: %d\n", result); } else { printf("OK: %d\n", result); } } while(0)C99标准引入了不定参数宏,允许宏接受可变数量的参数。语法类似于可变参数函数,使用 ... 表示可变参数部分,并在替换部分使用 VA_ARGS 来引用这些参数。
cpp
#define PRINT(...) printf(__VA_ARGS__)
int main() {
PRINT("Hello, %s!\n", "world");
PRINT("Number: %d\n", 42);
return 0;
}注意:在C语言中,字符串常量相邻会自动连接成一个字符串
因为format是一个字符串参数,在预处理时,它会被替换成用户传入的字符串,然后与周围的字符串连接,形成一个完整的格式字符串。
cpp
#define LOG(format, ...) printf("[%s:%d] " format "\n", __FILE__, __LINE__, __VA_ARGS__)
// 使用示例
int x = 42;
LOG("Value: %d", x);
cpp
// 宏展开后的代码:
printf("[%s:%d] " "Value: %d" "\n", __FILE__, __LINE__, x);
// 编译器会处理为:
printf("[%s:%d] Value: %d\n", __FILE__, __LINE__, x);好了我们现在就去写我们的日志输出工具宏
cpp
#include<iostream>
#include<ctime>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
#define DEBUG_LEVEL 0
#define INFO_LEVEL 1
#define ERROR_LEVEL 2
#define DEFAULT_LEVEL DEBUG_LEVEL
#define LOG(level,format,...)\
{\
if(level>=DEFAULT_LEVEL)\
{\
time_t t=time(nullptr);\
struct tm* ptm=localtime(&t);\
char time_str[32];\
strftime(time_str,31,"%H:%M:%S",ptm);\
printf("[%s][%s:%d]\t" format "\n",time_str,__FILE__,__LINE__,__VA_ARGS__);\
}\
}
int main()
{
LOG(DEBUG_LEVEL,"hello %s--%d","World",22);
}
但是现在还有一个问题。如果说我传递的是
cpp
LOG(DEBUG_LEVEL,"hello World");那么宏函数的不定参数就会报错啊。

上面的LOG宏定义中,format 和 ... 是分开的,这样调用时就需要至少两个参数(level和format),然后可变参数至少一个(因为__VA_ARGS__至少需要一个参数)。
如果你希望允许可变参数为空,则需要使用**##VA_ARGS**。
cpp
#include<iostream>
#include<ctime>
//封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [17.22.58 log.cpp:12]打开文件失败
#define DEBUG_LEVEL 0
#define INFO_LEVEL 1
#define ERROR_LEVEL 2
#define DEFAULT_LEVEL DEBUG_LEVEL
#define LOG(level,format,...)\
{\
if(level>=DEFAULT_LEVEL)\
{\
time_t t=time(nullptr);\
struct tm* ptm=localtime(&t);\
char time_str[32];\
strftime(time_str,31,"%H:%M:%S",ptm);\
printf("[%s][%s:%d]\t" format "\n",time_str,__FILE__,__LINE__,##__VA_ARGS__);\
}\
}
int main()
{
LOG(DEBUG_LEVEL,"hello World");
}这样子编译就不会报错了

现在我们就对这个进行封装啊
cpp
#include<iostream>
#include<ctime>
// 封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [DBG][17.22.58][log.cpp:12]打开文件失败
// 定义日志级别常量
// DEBUG_LEVEL: 调试级别,最低级别,用于开发调试
// INFO_LEVEL: 信息级别,用于普通信息输出
// ERROR_LEVEL: 错误级别,用于错误信息输出
#define DEBUG_LEVEL 0 // 调试级别,数值最小,级别最低
#define INFO_LEVEL 1 // 信息级别
#define ERROR_LEVEL 2 // 错误级别,数值最大,级别最高
// 设置默认日志级别
// 只有大于等于此级别的日志才会被打印
// 可以修改为 DEBUG_LEVEL、INFO_LEVEL 或 ERROR_LEVEL
#define DEFAULT_LEVEL INFO_LEVEL
// 主日志宏定义
// lev_str: 日志级别字符串,如"DBG"、"INF"、"ERR",会显示在日志开头
// level: 日志级别数值,必须为 DEBUG_LEVEL、INFO_LEVEL 或 ERROR_LEVEL,用于判断是否打印
// format: 格式化字符串,与printf的格式相同
// ...: 可变参数,对应format中的占位符
#define LOG(lev_str, level, format, ...) \
{ \
/* 判断当前日志级别是否达到默认级别,如果达到则打印 */ \
if(level >= DEFAULT_LEVEL) \
{ \
/* 获取当前系统时间 */ \
time_t t = time(nullptr); \
/* 将时间转换为本地时间结构体 */ \
struct tm* ptm = localtime(&t); \
/* 定义时间字符串缓冲区 */ \
char time_str[32]; \
/* 格式化时间为"小时:分钟:秒"格式 */ \
strftime(time_str, 31, "%H:%M:%S", ptm); \
/* 打印日志:格式为[级别][时间][文件名:行号] 用户自定义内容 */ \
printf("[%s][%s][%s:%d]\t" format "\n", lev_str, time_str, __FILE__, __LINE__, ##__VA_ARGS__); \
} \
}
// 快捷宏:调试日志
// 自动使用"DBG"字符串和DEBUG_LEVEL级别
// format: 格式化字符串
// ...: 可变参数
#define DLOG(format, ...) LOG("DBG", DEBUG_LEVEL, format, ##__VA_ARGS__)
// 快捷宏:信息日志
// 自动使用"INF"字符串和INFO_LEVEL级别
#define ILOG(format, ...) LOG("INF", INFO_LEVEL, format, ##__VA_ARGS__)
// 快捷宏:错误日志
// 自动使用"ERR"字符串和ERROR_LEVEL级别
#define ELOG(format, ...) LOG("ERR", ERROR_LEVEL, format, ##__VA_ARGS__)
int main()
{
// 测试调试日志
// 由于DEFAULT_LEVEL设置为INFO_LEVEL(1),DEBUG_LEVEL(0)小于1,所以这行不会打印
DLOG("hello World");
// 测试信息日志
// INFO_LEVEL(1)等于DEFAULT_LEVEL(1),所以会打印:[INF][当前时间][文件名:行号] hello World
ILOG("hello World");
// 测试错误日志
// ERROR_LEVEL(2)大于DEFAULT_LEVEL(1),所以会打印:[ERR][当前时间][文件名:行号] hello World
ELOG("hello World");
return 0;
}
怎么样,还是很不错的吧。
那么到这里我们的这个日志宏函数就算是写完了,现在我们把下面这段拷贝到到下面的logger.hpp
还是很简单吧
cpp
#ifndef __M_LOG_H__
#define __M_LOG_H__
#include <iostream>
#include <ctime>
namespace mymq
{
// 封装一个日志宏,通过日志宏进行日志的打印,将打印的信息前带有系统事件,文件名,行号
// 例如: [DBG][17.22.58][log.cpp:12]打开文件失败
// 定义日志级别常量
// DEBUG_LEVEL: 调试级别,最低级别,用于开发调试
// INFO_LEVEL: 信息级别,用于普通信息输出
// ERROR_LEVEL: 错误级别,用于错误信息输出
#define DEBUG_LEVEL 0 // 调试级别,数值最小,级别最低
#define INFO_LEVEL 1 // 信息级别
#define ERROR_LEVEL 2 // 错误级别,数值最大,级别最高
// 设置默认日志级别
// 只有大于等于此级别的日志才会被打印
// 可以修改为 DEBUG_LEVEL、INFO_LEVEL 或 ERROR_LEVEL
#define DEFAULT_LEVEL INFO_LEVEL
// 主日志宏定义
// lev_str: 日志级别字符串,如"DBG"、"INF"、"ERR",会显示在日志开头
// level: 日志级别数值,必须为 DEBUG_LEVEL、INFO_LEVEL 或 ERROR_LEVEL,用于判断是否打印
// format: 格式化字符串,与printf的格式相同
// ...: 可变参数,对应format中的占位符
#define LOG(lev_str, level, format, ...) \
{ \
/* 判断当前日志级别是否达到默认级别,如果达到则打印 */ \
if (level >= DEFAULT_LEVEL) \
{ \
/* 获取当前系统时间 */ \
time_t t = time(nullptr); \
/* 将时间转换为本地时间结构体 */ \
struct tm *ptm = localtime(&t); \
/* 定义时间字符串缓冲区 */ \
char time_str[32]; \
/* 格式化时间为"小时:分钟:秒"格式 */ \
strftime(time_str, 31, "%H:%M:%S", ptm); \
/* 打印日志:格式为[级别][时间][文件名:行号] 用户自定义内容 */ \
printf("[%s][%s][%s:%d]\t" format "\n", lev_str, time_str, __FILE__, __LINE__, ##__VA_ARGS__); \
} \
}
// 快捷宏:调试日志
// 自动使用"DBG"字符串和DEBUG_LEVEL级别
// format: 格式化字符串
// ...: 可变参数
#define DLOG(format, ...) LOG("DBG", DEBUG_LEVEL, format, ##__VA_ARGS__)
// 快捷宏:信息日志
// 自动使用"INF"字符串和INFO_LEVEL级别
#define ILOG(format, ...) LOG("INF", INFO_LEVEL, format, ##__VA_ARGS__)
// 快捷宏:错误日志
// 自动使用"ERR"字符串和ERROR_LEVEL级别
#define ELOG(format, ...) LOG("ERR", ERROR_LEVEL, format, ##__VA_ARGS__)
}
#endif注意我们这里加了命名空间mymq,以及防止头文件重复包含的语句
二.实用 Helper 工具
首先我们先在mymq/mqcommon/目录里面创建一个helper.hpp
2.1.sqlite 基础操作类
我们之前实现过:【消息队列项目】SQLite简单介绍-CSDN博客
在那篇文章里面,我们封装的接口是下面这样子的
cpp
#include <sqlite3.h>
#include<iostream>
#include<string>
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper {
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void*,int,char**,char**);
SqliteHelper(const std::string&filename):_db_handler(nullptr),_dbfile(filename){}
~SqliteHelper(){ close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX) {
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret=sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK) {
// 输出错误信息
std::cout << "打开数据库文件 " << _dbfile << " 失败!\n";
std::cout << sqlite3_errmsg(_db_handler) << std::endl;
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close() {
if (_db_handler) sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr) {
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK) {
std::cout << "执行 sql: " << sql << " 失败!\n";
std::cout << "原因: " << sqlite3_errmsg(_db_handler) << std::endl;
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};我们仔细发现这里面的接口还是使用std::cout来进行日志打印的,我们就需要把这个std::cout换成我们上面写好的日志输出工具宏
cpp
#ifndef ___M_HELPER_H__
#define ___M_HELPER_H__
#include <sqlite3.h>
#include <iostream>
#include <string>
#include"logger.hpp"
namespace mymq
{
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper
{
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void *, int, char **, char **);
SqliteHelper(const std::string &filename) : _db_handler(nullptr), _dbfile(filename) {}
~SqliteHelper() { close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX)
{
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret = sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK)
{
// 输出错误信息
ELOG("打开数据库文件%s失败: %s",_dbfile.c_str(),sqlite3_errmsg(_db_handler));
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close()
{
if (_db_handler)
sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr)
{
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK)
{
ELOG("sql语句: %s 执行失败: %s",sql.c_str(),sqlite3_errmsg(_db_handler));
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};
}
#endif我们直接在mymq/mqcommon/helper.hpp里面添加上面这些内容
2.2.字符串分割类
这里我们就是需要实现一个类,他能对字符串进行分割的功能。
话不多说,我们先写测试代码
cpp
#include<iostream>
#include<string>
#include<vector>
size_t split(const std::string &str, //待分割的原始字符串
const std::string &sep, //分隔符(可以是多个字符)
std::vector<std::string> &res, //存储分割结果的字符串向量(输出型参数)
bool is_push_empty_string = false) { //是否将空子串加入结果,默认为false
// 边界情况:如果原字符串或分隔符为空,直接返回0
if (str.empty() || sep.empty()) return 0;
size_t pos; // 分隔符出现的位置
size_t idx = 0; // 当前查找起始位置
// 循环查找分隔符直到字符串末尾
while(idx < str.size()) {
// 从当前位置开始查找分隔符
pos = str.find(sep, idx);//pos就是分隔符第一次出现的下标,再次调用find,就是第二次出现的......
// 情况1:找不到更多分隔符
if (pos == std::string::npos) {
// 将剩余部分作为最后一个子串加入结果
res.push_back(str.substr(idx));//str.substr(idx)代表从idx往后一直截取到字符串末尾
break;
}
// 情况2:分隔符紧挨着(产生空子串)
if (pos == idx && is_push_empty_string == false) {
// 跳过分隔符继续查找(不添加空字符串)
idx += sep.size();
continue;
}
// 一般情况:提取从当前位置到分隔符之前的子串
res.push_back(str.substr(idx, pos - idx));
// 移动查找位置到分隔符之后
idx = pos + sep.size();
}
// 返回分割出的子串数量
return res.size();
}
int main()
{
std::string str="news.....music.#.app";
std::vector<std::string> arry;
int n=split(str,".",arry);
for(auto s:arry)
{
std::cout<<s<<std::endl;
}
}
很完美,我们换一个
cpp
int main()
{
std::string str="n.es.ws..shu.w.d...music.#.app";
std::vector<std::string> arry;
int n=split(str,".",arry);
for(auto s:arry)
{
std::cout<<s<<std::endl;
}
}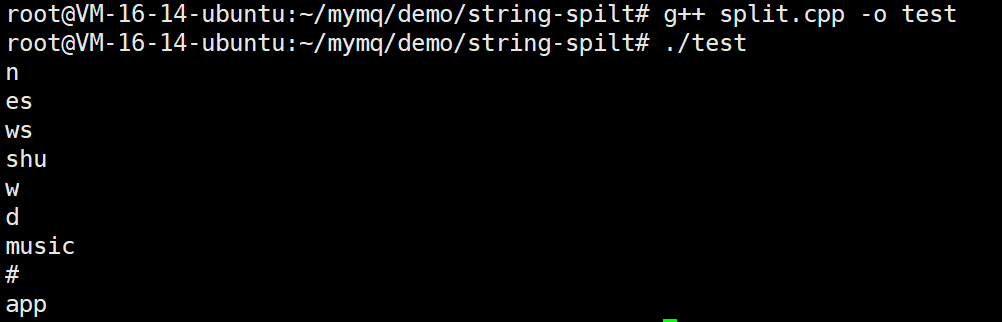
非常完美!!
现在我们就把这个函数封装成一个类的静态函数
cpp
class StringHelper {
public:
//函数功能是将字符串按指定分隔符分割成若干子串
//返回值是分割得到的子串数量
static size_t split(const std::string &str, //待分割的原始字符串
const std::string &sep, //分隔符(可以是多个字符)
std::vector<std::string> &res, //存储分割结果的字符串向量(输出型参数)
bool is_push_empty_string = false) { //是否将空子串加入结果,默认为false
// 边界情况:如果原字符串或分隔符为空,直接返回0
if (str.empty() || sep.empty()) return 0;
size_t pos; // 分隔符出现的位置
size_t idx = 0; // 当前查找起始位置
// 循环查找分隔符直到字符串末尾
while(idx < str.size()) {
// 从当前位置开始查找分隔符
pos = str.find(sep, idx);//pos就是分隔符第一次出现的下标,再次调用find,就是第二次出现的......
// 情况1:找不到更多分隔符
if (pos == std::string::npos) {
// 将剩余部分作为最后一个子串加入结果
res.push_back(str.substr(idx));//str.substr(idx)代表从idx往后一直截取到字符串末尾
break;
}
// 情况2:分隔符紧挨着(产生空子串)
if (pos == idx && is_push_empty_string == false) {
// 跳过分隔符继续查找(不添加空字符串)
idx += sep.size();
continue;
}
// 一般情况:提取从当前位置到分隔符之前的子串
res.push_back(str.substr(idx, pos - idx));
// 移动查找位置到分隔符之后
idx = pos + sep.size();
}
// 返回分割出的子串数量
return res.size();
}
};然后我们就把这个放入到logger.hpp里面去
现在logger.hpp就变成了下面这样子
cpp
#ifndef ___M_HELPER_H__
#define ___M_HELPER_H__
#include <sqlite3.h>
#include <iostream>
#include <string>
#include "logger.hpp"
#include<vector>
namespace mymq
{
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper
{
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void *, int, char **, char **);
SqliteHelper(const std::string &filename) : _db_handler(nullptr), _dbfile(filename) {}
~SqliteHelper() { close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX)
{
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret = sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK)
{
// 输出错误信息
ELOG("打开数据库文件%s失败: %s", _dbfile.c_str(), sqlite3_errmsg(_db_handler));
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close()
{
if (_db_handler)
sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr)
{
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK)
{
ELOG("sql语句: %s 执行失败: %s", sql.c_str(), sqlite3_errmsg(_db_handler));
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};
class StringHelper
{
public:
// 函数功能是将字符串按指定分隔符分割成若干子串
// 返回值是分割得到的子串数量
static size_t split(const std::string &str, // 待分割的原始字符串
const std::string &sep, // 分隔符(可以是多个字符)
std::vector<std::string> &res, // 存储分割结果的字符串向量(输出型参数)
bool is_push_empty_string = false)
{ // 是否将空子串加入结果,默认为false
// 边界情况:如果原字符串或分隔符为空,直接返回0
if (str.empty() || sep.empty())
return 0;
size_t pos; // 分隔符出现的位置
size_t idx = 0; // 当前查找起始位置
// 循环查找分隔符直到字符串末尾
while (idx < str.size())
{
// 从当前位置开始查找分隔符
pos = str.find(sep, idx); // pos就是分隔符第一次出现的下标,再次调用find,就是第二次出现的......
// 情况1:找不到更多分隔符
if (pos == std::string::npos)
{
// 将剩余部分作为最后一个子串加入结果
res.push_back(str.substr(idx)); // str.substr(idx)代表从idx往后一直截取到字符串末尾
break;
}
// 情况2:分隔符紧挨着(产生空子串)
if (pos == idx && is_push_empty_string == false)
{
// 跳过分隔符继续查找(不添加空字符串)
idx += sep.size();
continue;
}
// 一般情况:提取从当前位置到分隔符之前的子串
res.push_back(str.substr(idx, pos - idx));
// 移动查找位置到分隔符之后
idx = pos + sep.size();
}
// 返回分割出的子串数量
return res.size();
}
};
}
#endif2.3.UUID 生成器类
UUID(通用唯一识别码,Universally Unique Identifier)是一种用于确保全局唯一性的标识符标准。
我们将根据下面这3个步骤来生成我们的UUID
一、基本结构设计
生成器采用16字节(32位十六进制字符) 的复合结构,分为两个部分:
- 前8字节:完全随机数,确保全局唯一性
- 后8字节:顺序递增的序号,增强可读性和可追溯性
二、生成过程详解
第一步:生成随机部分(前8字节)
- 使用高质量的随机数生成器(std::random_device和std::mt19937_64)生成真正的随机数
- 生成8个0-255之间的随机整数,每个整数对应一个字节,八个整数对应八个字节
- 将每个字节转换为2位十六进制字符串,不足两位时前面补零
- 在特定的位置(第4、6、8个字节后)插入连字符"-",初步形成8-4-4的格式
第二步:生成序号部分(后8字节)
- 使用原子计数器seq确保线程安全,序号从1开始递增
- 每次调用uuid()函数时,原子性地获取并递增序号
- 将64位序号的8个字节从高位到低位依次提取
- 每个字节同样转换为2位十六进制字符串,前面补零
- 在倒数第2个字节后(即16个十六进制字符的第6个字节后)插入连字符"-"
第三步:格式拼接
- 前8字节随机部分已形成:XXXXXXXX-XXXX-XXXX-(注意最后的连字符)
- 后8字节序号部分形成:XXXXXXXX-XXXX格式
- 两部分直接拼接,最终形成:XXXXXXXX-XXXX-XXXX-XXXXXXXX-XXXX的格式
话不多说,我们先看看随机数是怎么生成的
cpp
#include <iostream>
#include <random>
int main() {
// 创建random_device对象
std::random_device rd;
// 生成一个随机数
int random_number = rd();
std::cout << "随机数: " << random_number << std::endl;
// 再生成一个
int another_random = rd();
std::cout << "另一个随机数: " << another_random << std::endl;
return 0;
}
但是这个随机数是机器随机数,根据硬件生成的,每次生成都需要访问硬件,生成效率低下
这个时候我们就需要学习一个新的随机数生成算法
std::mt19937_64:
-
这是一个伪随机数生成器,使用梅森旋转算法,周期非常长(2^19937-1),速度很快。
-
它需要种子来初始化,一旦初始化,就可以快速生成高质量的伪随机数序列。
cpp
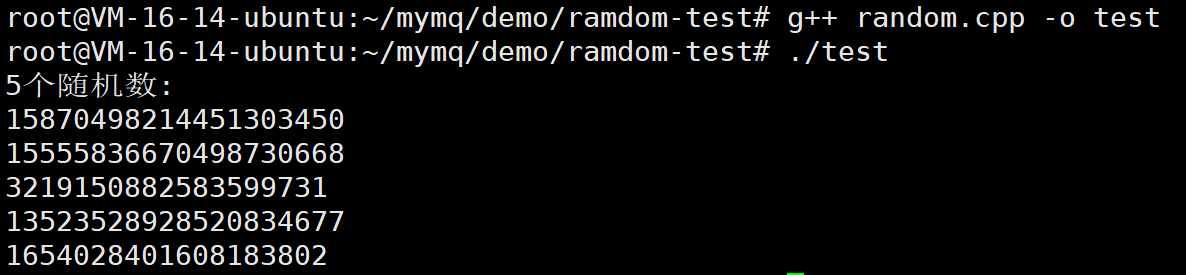
#include <iostream>
#include <random>
int main() {
// 第一步:创建random_device获取高质量随机种子
std::random_device rd;
// 第二步:用random_device的输出来初始化mt19937_64
std::mt19937_64 generator(rd());
// 第三步:使用generator生成随机数
std::cout << "5个随机数:" << std::endl;
for (int i = 0; i < 5; i++) {
// 注意:这里调用的是generator(),不是rd()
std::cout << generator() << std::endl;
}
return 0;
}
还是很不错的吧
但是我们需要生成8个0-255之间的随机整数,我们怎么生成指定范围的随机数呢?
例子:生成指定范围的随机数
cpp
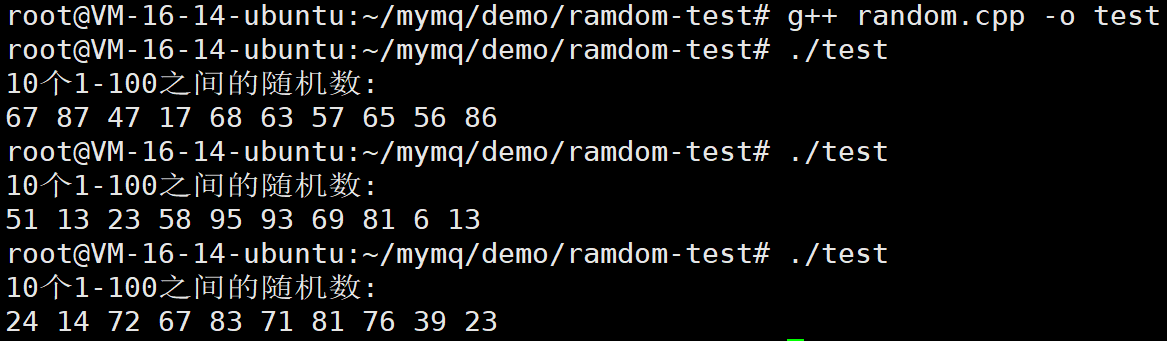
#include <iostream>
#include <random>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::cout << "10个1-100之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::cout << dist(generator) << " ";
}
std::cout << std::endl;
return 0;
}
还是很简单的。
那么问题又来了,我们怎么把一个十进制的数字转换成一个十六进制的数呢?
我们使用std::stringstream和std::hex来将十进制整数转换为十六进制字符串。
根据这个思路,我们就能写成下面这个
cpp
#include <iostream>
#include <random>
#include <sstream>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::cout << "10个1-100之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::stringstream ss;
ss<<std::hex<<dist(generator);
std::cout << ss.str() << " ";
}
std::cout << std::endl;
return 0;
}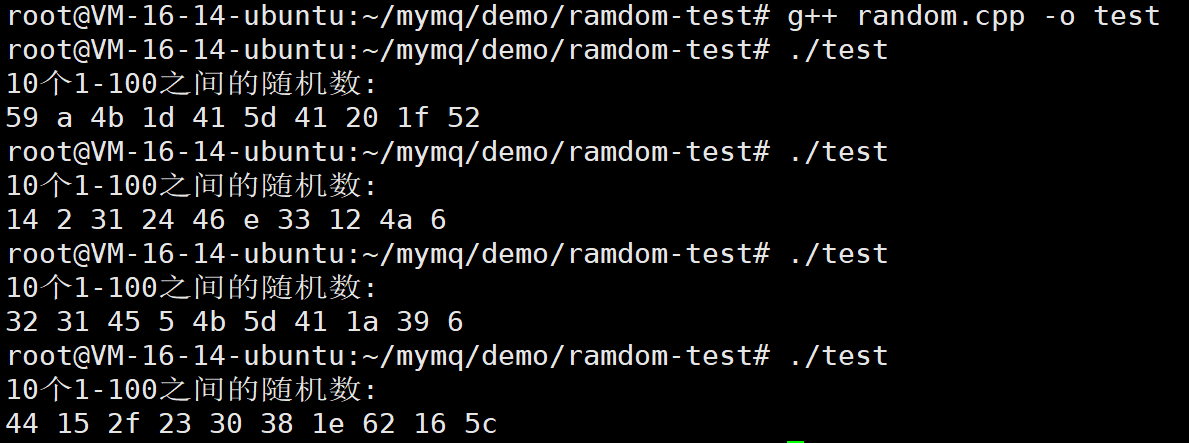
但是我们仔细观察一下:有的随机数只有1位,有的随机数却有2位,我们必须得确保生成的随机数都是2位的
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::cout << "10个1-100之间的随机数:" << std::endl;
for (int i = 0; i < 10; i++) {
std::stringstream ss;
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<dist(generator);
std::cout << ss.str() << " ";
}
std::cout << std::endl;
return 0;
}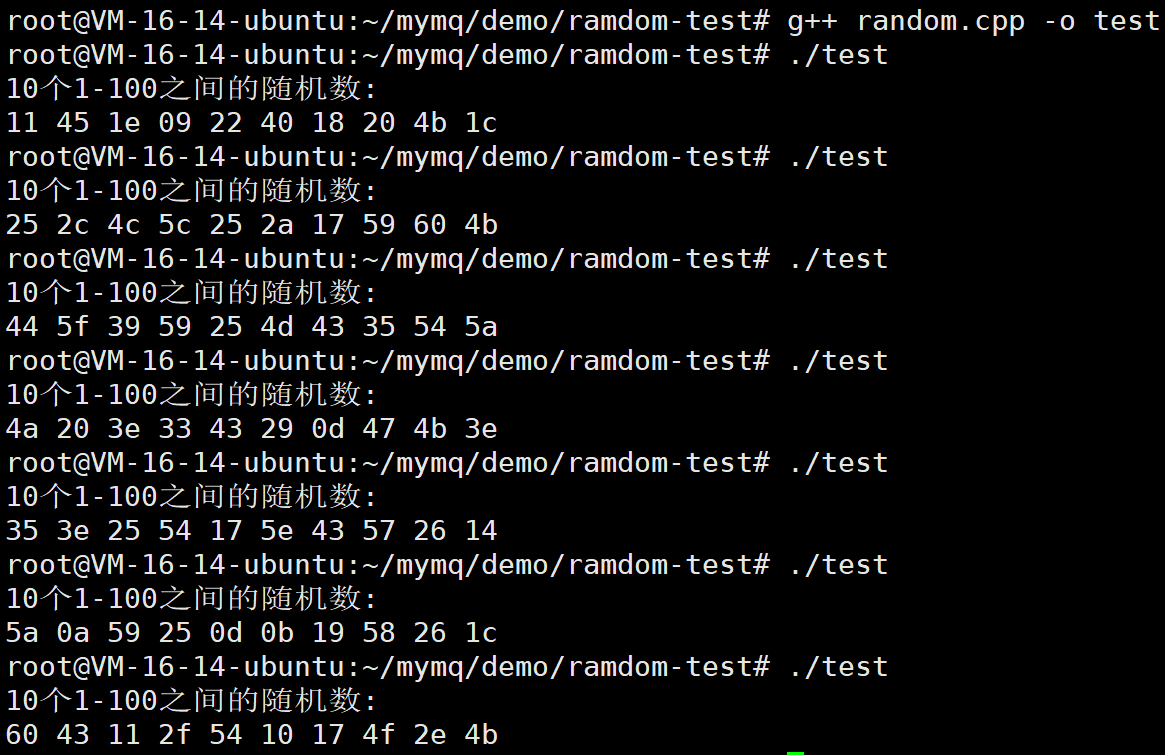
现在我们生成的随机都是2位的。保持格式统一了。
我们前面的目标可是生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来。
我们现在就能实现了
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss;//注意这个在外面了
//生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++) {
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<dist(generator);
if(i==3 || i==5 || i==7)
{
ss<<"-";
}
}
std::cout << ss.str() <<std::endl;
return 0;
}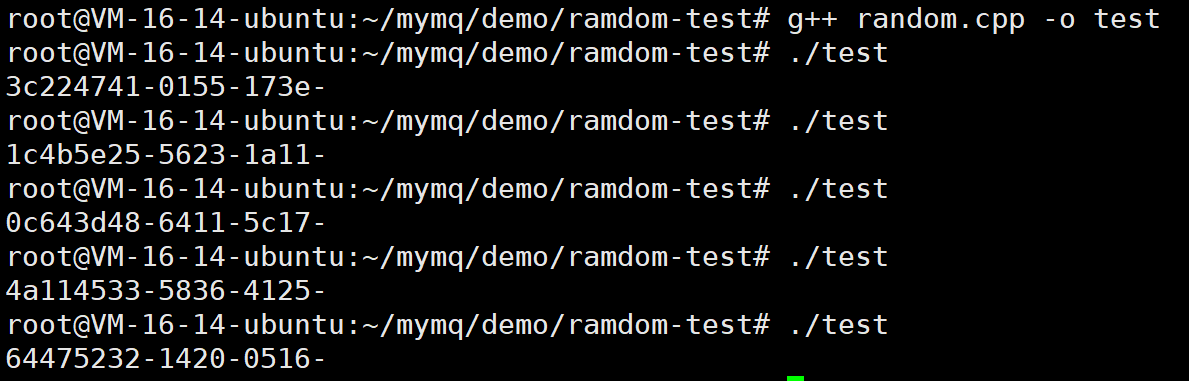
还是很不错的。
但是还是不够的我们还需要实现下面这个
第二步:生成序号部分(后8字节)
- 使用原子计数器seq确保线程安全,序号从1开始递增
- 每次调用uuid()函数时,原子性地获取并递增序号
- 将64位序号的8个字节从高位到低位依次提取
- 每个字节同样转换为2位十六进制字符串,前面补零
- 在倒数第2个字节后(即16个十六进制字符的第6个字节后)插入连字符"-"
这里其实涉及到两个关键操作
- 右移操作(>>)将数字的二进制表示向右移动指定的位数。
- & 0xFF 操作保留最低的8位(1个字节),清空其他位。
我们马上就能实现
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include<atomic>
int main() {
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss;//注意这个在外面了
//生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++) {
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<dist(generator);
if(i==3 || i==5 || i==7)
{
ss<<"-";
}
}
static std::atomic<size_t> seq(1);//定义一个原子类型的整数,初始化为1
size_t num=seq.fetch_add(1);//size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
//每次提取最低的8位,一共64位,需要提取8次
for (int i = 7; i >= 0; i--) {
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
//带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') <<byte;
if(i==6)
{
ss<<"-";
}
}
std::cout << ss.str() <<std::endl;
return 0;
}
到这里我们就算是写完了
我们把它封装成一个类
cpp
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include <atomic>
class UUIDHelper
{
public:
static std::string uuid()
{
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss; // 注意这个在外面了
// 生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++)
{
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << dist(generator);
if (i == 3 || i == 5 || i == 7)
{
ss << "-";
}
}
static std::atomic<size_t> seq(1); // 定义一个原子类型的整数,初始化为1
size_t num = seq.fetch_add(1); // size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
// 每次提取最低的8位,一共64位,需要提取8次
for (int i = 7; i >= 0; i--)
{
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << byte;
if (i == 6)
{
ss << "-";
}
}
return ss.str();
}
};
int main()
{
for(int i=0;i<20;i++)
{
std::cout << UUIDHelper::uuid() << std::endl;
}
return 0;
}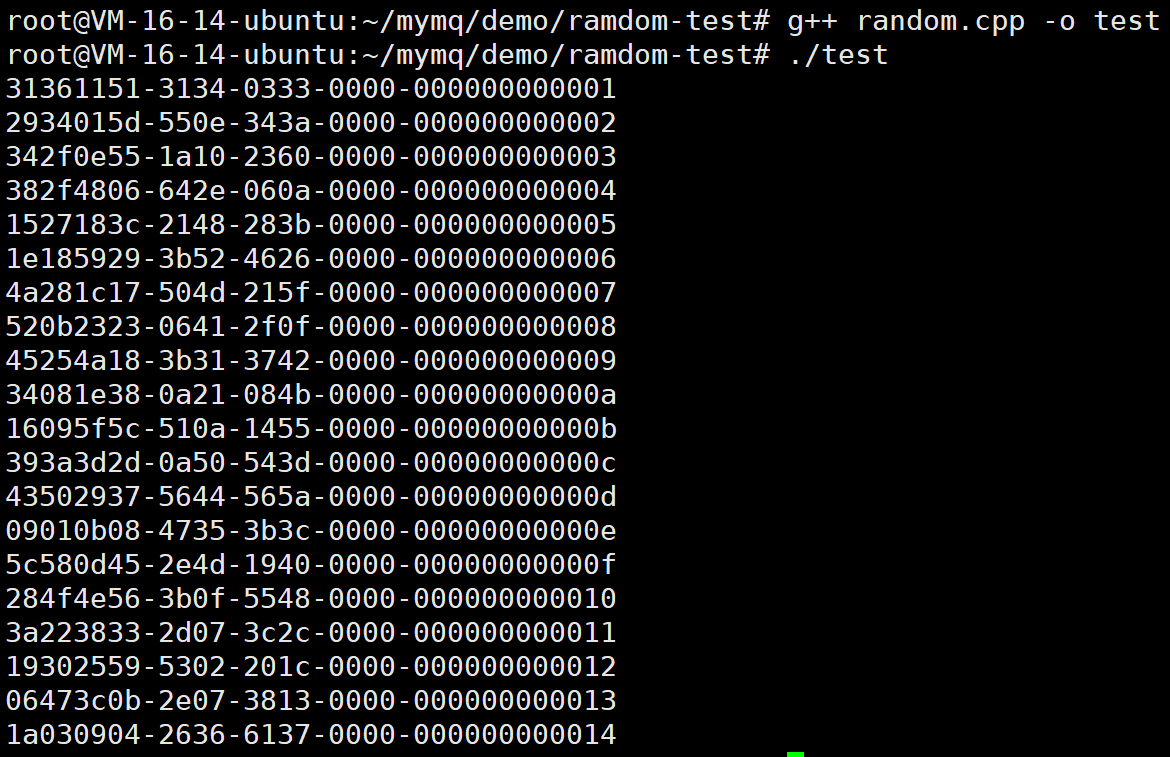
还是很不错的
现在我们就把这个封装好的类放入mymq/mqcommon/目录里面的helper.hpp
现在helper.hpp就变成了下面这样子
cpp
#ifndef ___M_HELPER_H__
#define ___M_HELPER_H__
#include <sqlite3.h>
#include <iostream>
#include <string>
#include "logger.hpp"
#include <vector>
#include <random>
#include <sstream>
#include <iomanip>
#include<atomic>
namespace mymq
{
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper
{
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void *, int, char **, char **);
SqliteHelper(const std::string &filename) : _db_handler(nullptr), _dbfile(filename) {}
~SqliteHelper() { close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX)
{
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret = sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK)
{
// 输出错误信息
ELOG("打开数据库文件%s失败: %s", _dbfile.c_str(), sqlite3_errmsg(_db_handler));
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close()
{
if (_db_handler)
sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr)
{
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK)
{
ELOG("sql语句: %s 执行失败: %s", sql.c_str(), sqlite3_errmsg(_db_handler));
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};
class StringHelper
{
public:
// 函数功能是将字符串按指定分隔符分割成若干子串
// 返回值是分割得到的子串数量
static size_t split(const std::string &str, // 待分割的原始字符串
const std::string &sep, // 分隔符(可以是多个字符)
std::vector<std::string> &res, // 存储分割结果的字符串向量(输出型参数)
bool is_push_empty_string = false)
{ // 是否将空子串加入结果,默认为false
// 边界情况:如果原字符串或分隔符为空,直接返回0
if (str.empty() || sep.empty())
return 0;
size_t pos; // 分隔符出现的位置
size_t idx = 0; // 当前查找起始位置
// 循环查找分隔符直到字符串末尾
while (idx < str.size())
{
// 从当前位置开始查找分隔符
pos = str.find(sep, idx); // pos就是分隔符第一次出现的下标,再次调用find,就是第二次出现的......
// 情况1:找不到更多分隔符
if (pos == std::string::npos)
{
// 将剩余部分作为最后一个子串加入结果
res.push_back(str.substr(idx)); // str.substr(idx)代表从idx往后一直截取到字符串末尾
break;
}
// 情况2:分隔符紧挨着(产生空子串)
if (pos == idx && is_push_empty_string == false)
{
// 跳过分隔符继续查找(不添加空字符串)
idx += sep.size();
continue;
}
// 一般情况:提取从当前位置到分隔符之前的子串
res.push_back(str.substr(idx, pos - idx));
// 移动查找位置到分隔符之后
idx = pos + sep.size();
}
// 返回分割出的子串数量
return res.size();
}
};
class UUIDHelper
{
public:
static std::string uuid()
{
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss; // 注意这个在外面了
// 生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++)
{
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << dist(generator);
if (i == 3 || i == 5 || i == 7)
{
ss << "-";
}
}
static std::atomic<size_t> seq(1); // 定义一个原子类型的整数,初始化为1
size_t num = seq.fetch_add(1); // size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
// 每次提取最低的8位,一共64位,需要提取8次
for (int i = 7; i >= 0; i--)
{
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << byte;
if (i == 6)
{
ss << "-";
}
}
return ss.str();
}
};
}
#endif2.4.文件操作类
这个类里面我们需要完成8个操作
- 文件是否存在判断
- 文件大小获取
- 文件读取
- 文件写入
- 文件创建
- 文件删除
- 目录创建
- 目录删除
我们先把整个的框架搭建出来,然后我们后续再进行详细补充
cpp
class FileHelper
{
public:
// 构造函数:使用给定的文件名初始化对象
FileHelper(const std::string &filename) : _filename(filename) {}
// 检查文件是否存在
bool exists() {}
// 获取文件大小(字节数)
size_t size() {}
// 读取整个文件内容到字符串,注意body是输出型参数
bool read(std::string &body) {}
// 从文件指定偏移量读取指定长度的数据到缓冲区,注意body是输出型参数
bool read(std::string &body, size_t offset, size_t len) {}
// 将整个字符串内容写入文件(覆盖模式)
bool write(const std::string &body) {}
// 在文件指定偏移量处写入数据
bool write(const std::string &body, size_t offset, size_t len) {}
// 重命名文件
bool rename(const std::string &nname) {}
// 静态方法:创建空文件
static bool createFile(const std::string &filename) {}
// 静态方法:删除文件
static bool removeFile(const std::string &filename) {}
// 静态方法:创建目录(支持创建多级目录)
static bool createDirectory(const std::string &path) {}
// 静态方法:递归删除目录及其所有内容
static bool removeDirectory(const std::string &path) {}
// 静态方法:获取文件的父目录路径
static std::string parentDirectory(const std::string &filename) {}
private:
std::string _filename; // 内部存储的文件名
};2.4.1.判断文件是否存在
我们需要学习一个函数------stat
cpp
int stat(const char *restrict pathname, struct stat *restrict statbuf);stat() 是 Unix/Linux 系统中一个获取文件详细信息的函数。你可以把它想象成一个文件信息探测器 - 它不打开文件,也不修改文件,只是"看一眼"然后告诉你关于这个文件的所有信息。
核心用途
想要知道文件的这些信息吗?
- 文件大小是多少?
- 文件是什么时候创建的?
- 文件最近什么时候被修改?
- 文件是什么类型的(普通文件?目录?链接?)?
- 文件的权限是什么?
- 文件属于哪个用户/组?
所有这些都可以通过一次 stat() 调用获取!
返回值
- 成功:返回 0
- 失败:返回 -1,并设置 errno
我们看一下函数参数
- const char *pathname;:要查询的文件路径,可以是文件的完整路径或相对路径
- struct stat *statbuf; // 指向stat结构体的指针,这是最关键的部分!stat() 会把文件的所有信息填充到这个结构体中。
struct stat 结构体详解
这是 stat() 函数的核心,让我们详细看看它包含哪些信息:
cpp
struct stat {
dev_t st_dev; /* 文件所在设备的ID */
ino_t st_ino; /* Inode编号(文件的唯一标识)*/
mode_t st_mode; /* 文件类型和权限 */
nlink_t st_nlink; /* 硬链接数量 */
uid_t st_uid; /* 文件所有者的用户ID */
gid_t st_gid; /* 文件所有者的组ID */
dev_t st_rdev; /* 如果是设备文件,设备的ID */
off_t st_size; /* 文件大小(字节)*/
blksize_t st_blksize; /* 文件系统I/O的块大小 */
blkcnt_t st_blocks; /* 文件占用的块数(512字节/块)*/
/* 时间信息 */
struct timespec st_atim; /* 最后访问时间 */
struct timespec st_mtim; /* 最后修改时间 */
struct timespec st_ctim; /* 最后状态改变时间 */
/* 旧版本的时间字段(为了兼容性)*/
#define st_atime st_atim.tv_sec /* 向后兼容 */
#define st_mtime st_mtim.tv_sec
#define st_ctime st_ctim.tv_sec
};这些我们不必了解太多,我们只需要知道,文件不存在,那么这个stat函数就会返回-1,并且设置errno
cpp
// 检查文件是否存在
bool exists()
{
struct stat st;
int res=stat(_filename.c_str(),&st);
if(res==0)
{
return true;
}
return false;
}2.4.2.获取文件大小
这个也是使用那个stat函数的
cpp
// 获取文件大小(字节数)
size_t size()
{
struct stat st;
int res=stat(_filename.c_str(),&st);
if(res<0)
{
return 0;
}
return st.st_size;//返回文件大小
}2.4.3.读取文件
读取文件的的部分内容
话不多说,我们直接就写出下面这个来了
cpp
// 从文件指定偏移量读取指定长度的数据到缓冲区
bool read(char *body, size_t offset, size_t len) {
// 1. 以二进制只读模式打开文件
std::ifstream ifs(_filename, std::ios::binary | std::ios::in);
if (ifs.is_open() == false) {
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
ifs.seekg(offset, std::ios::beg);
// 3. 读取len长度的数据到body缓冲区
ifs.read(body, len);
if (ifs.good() == false) { // 检查读取是否成功
ELOG("%s 文件读取数据失败!!", _filename.c_str());
ifs.close();
return false;
}
// 4. 关闭文件
ifs.close();
return true;
}在C++中,处理文件输入输出的流类主要有三种:
-
std::ifstream:用于读取文件(输入)
-
std::ofstream:用于写入文件(输出)
-
std::fstream:用于同时读取和写入文件(输入输出)
我们这里是使用了std::ifstream,理所应当。
这里使用到了std::ifstream的两个成员函数,我需要提一嘴
- ifs.seekg(从哪里开始偏移, 偏移方向);
- ifs.read(存到哪里, 读取多少);
注意事项一:std::ifstream::seekg函数的使用方法
两个参数的版本(常用)
cpp
basic_istream& seekg(pos_type offset, ios_base::seekdir dir);offset:偏移量(字节数)
dir:基准位置(从哪里开始偏移)
- std::ios::beg 或 std::ios_base::beg - 从文件开头开始
- std::ios::cur 或 std::ios_base::cur - 从当前位置开始
- std::ios::end 或 std::ios_base::end - 从文件末尾开始
一个参数的版本
cpp
basic_istream& seekg(pos_type pos);- pos:绝对位置(从文件开头算起的字节偏移量)
- 等价于 seekg(pos, std::ios::beg)
注意事项二:第一个参数要求是 char*,不能传递string对象或者string的c_str成员函数
std::ifstream::read() 函数的原型是:
cpp
istream& read(char* s, streamsize n);第一个参数要求是 char*(字符指针),而 std::string 是一个对象,不是指针。
所以不能这样写:
cpp
std::string body;
ifs.read(body, len); // 错误!类型不匹配当然,我们更不能像下面这样子写
cpp
std::string body;
ifs.read(body.c_str(), len); // 错误!类型不匹配它的第一个参数是 char*,即指向字符数组的指针,这个数组应该是可写的,因为 read 函数会将读取的数据存入这个数组。
而 std::string::c_str() 返回的类型是 const char*,这是一个指向常量字符数组的指针,即该数组是只读的。
因此,将 const char* 传递给需要 char* 的参数,在C++中是不允许的(因为如果允许,那么就可以通过这个指针修改只读的内存,这是不安全的)。
读取文件的所有内容
接下来我们看看另外一个接口
读取整个文件的内容
cpp
// 读取整个文件内容到字符串,注意body是输出型参数
bool read(std::string &body)
{
// 获取文件大小,调整字符串大小以容纳文件内容
size_t fsize = this->size();//注意这个size就是我们上面写好的
body.resize(fsize);
// 调用read函数读取整个文件
return read(&body[0], 0, fsize);//从文件的第0个字节开始往后读取fsize个字节
}注意了,这里面调用的read的原型如下:
cpp
bool read(char* buffer, size_t offset, size_t size)它将从文件的 offset 位置读取 size 字节到 buffer 中,并返回操作是否成功。
这里需要回答一个问题
为什么是 &body0 而不是 body或者body.c_str()?
1. body 是对象本身
body是一个std::string类型的对象,而read函数需要的是char*指针。所以直接使用body会导致类型不匹配,编译错误。
2. body.c_str() 返回的是const char*
c_str()函数返回一个指向以空字符结尾的字符数组的指针,即C风格的字符串。这个指针是const char*,意味着我们不能通过这个指针修改字符串的内容。而read函数需要向这个缓冲区写入数据,所以不能使用const char*。
3. &body0 返回的是char*
在C++11及以后的标准中,std::string的内部存储是连续的,并且允许通过&body0获取一个指向第一个字符的指针,而且这个指针是可写的(非const)。这样我们就可以通过这个指针修改字符串的内容。
2.4.4.文件写入
我们必须需要明白:文件的写入都是覆盖式的写入!!!
我们必须明白其中的利害
在文件指定偏移量处写入数据
cpp
// 在文件指定偏移量处写入数据
bool write(const char *body, size_t offset, size_t len) {
// 1. 以二进制读写模式打开文件(允许读取和写入)
std::fstream fs(_filename, std::ios::binary | std::ios::in | std::ios::out);
if (fs.is_open() == false) {
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
fs.seekp(offset, std::ios::beg);
// 3. 写入len长度的数据
fs.write(body, len);
if (fs.good() == false) { // 检查写入是否成功
ELOG("%s 文件写入数据失败!!", _filename.c_str());
fs.close();
return false;
}
// 4. 关闭文件
fs.close();
return true;
}首先我们需要明白
在C++中,处理文件输入输出的流类主要有三种:
-
std::ifstream:用于读取文件(输入)
-
std::ofstream:用于写入文件(输出)
-
std::fstream:用于同时读取和写入文件(输入输出)
在这个函数中,我们需要打开文件并写入数据。按道理来说,我们直接使用std::ofstream即可,但是在实现过程中,我们使用std::fstream,为什么呢?
实际上是在这个函数中,我们需要将数据写入到文件的指定偏移量处,但是我们在跳转至文件的指定偏移量那里,这个过程是需要读权限的!!!
也就是下面这一步
cpp
// 2. 跳转到指定偏移量(相对于文件开头)
fs.seekp(offset, std::ios::beg);所以,我们必须使用std::fstream,使用 std::fstream 可以同时支持读写操作。
将整个字符串内容写入文件(覆盖模式)
cpp
// 将整个字符串内容写入文件(覆盖模式)
bool write(const std::string &body) {
return write(body.c_str(), 0, body.size());
}这个可是覆盖式的写啊!!
2.4.5.获取文件的父目录路径
假设给了我们一个文件:/root/test/main.cpp,那么她的父目录路径就是/root/test
cpp
// 静态方法:获取文件的父目录路径
static std::string parentDirectory(const std::string &filename) {
// 查找最后一个目录分隔符的位置
size_t pos = filename.find_last_of("/");
if (pos == std::string::npos) {
// 如果没有找到分隔符,说明文件在当前目录
return "./"; // 返回当前目录
}
// 提取分隔符前的部分作为目录路径
std::string path = filename.substr(0, pos);
return path;
}这里用到了string的一个成员函数------find_last_of
cpp
size_t find_last_of(const string& str, size_t pos = npos) const;功能:在字符串中从后向前搜索,查找任意一个指定字符集合中的字符
返回:找到的字符的位置(从0开始计数),如果没找到则返回 string::npos
参数解释
- 第一个参数 str
- 包含要查找的字符集合的字符串
- 不是查找整个字符串,而是查找其中任意一个字符
- 第二个参数 pos(可选)
- 从哪个位置开始向前搜索(默认为 npos,即从末尾开始)
- 搜索范围是:从 pos 位置(包括该位置)开始,向前到字符串开头
我们看个简单的例子
cpp
#include <iostream>
#include <string>
using namespace std;
int main() {
string text = "/example.com/path/to/file.txt";
string delimiters = "/";
// 示例1:查找最后一个斜杠
size_t pos = text.find_last_of(delimiters);
cout << "位置: " << pos << endl;
cout << "字符: " << text[pos] << endl;
// 示例2:从指定位置向前查找
size_t pos2 = text.find_last_of(delimiters, 15); // 只搜索前15个字符
cout << "位置: " << pos2 << endl;
cout << "字符: " << text[pos] << endl;
return 0;
}
还是很简单的
2.4.6.文件重命名
这个很简单就能写出来
cpp
// 重命名文件
bool rename(const std::string &nname) {
if (::rename(_filename.c_str(), nname.c_str()) == 0) {
return true;
}
return false;
}这里使用了C标准库中的rename函数(通过::表明是全局命名空间中的rename,避免与成员函数命名冲突)。
rename函数的原型(在C标准库中)是:
cpp
int rename(const char *oldpath, const char *newpath);它会将文件从oldpath重命名为newpath。
- 如果成功,返回0;
- 失败则返回-1,并设置errno。
2.4.6.创建文件
cpp
// 静态方法:创建空文件
static bool createFile(const std::string &filename)
{
// 以二进制写入模式创建文件
std::fstream ofs(filename, std::ios::binary | std::ios::out);
if (ofs.is_open() == false)
{
ELOG("%s 文件打开失败!", filename.c_str());
return false;
}
ofs.close();
return true;
}2.4.7.删除文件
cpp
// 静态方法:删除文件
static bool removeFile(const std::string &filename)
{
// 使用系统调用remove()删除文件
return (::remove(filename.c_str()) == 0);
}2.4.8.创建目录(支持创建多级目录)
这个函数的功能是创建目录。目录路径可以是多级的,比如"aaa/bbb/ccc",它需要创建所有不存在的父级目录。
函数的工作思想是:
-
函数接收一个目录路径作为参数,比如"aaa/bbb/ccc"。
-
它沿着路径从左到右逐个处理每个目录层级。
-
它查找路径中的斜杠("/")分隔符,每次找到斜杠就截取到该位置的部分路径。
-
对于每个截取的部分路径(比如"aaa",然后"aaa/bbb",最后"aaa/bbb/ccc"):
a. 尝试创建这个目录。
b. 如果创建成功,继续处理下一个层级。
c. 如果目录已经存在(这是正常情况,不算错误),继续处理下一个层级。
d. 如果因为其他原因失败(比如权限不足),就报错并停止。
-
重复这个过程,直到处理完整个路径。
-
最终,整个路径中的所有目录都会被创建。
简单来说:函数按顺序创建路径中的每一级目录,从最外层开始,逐层向内创建,确保父目录存在后再创建子目录。如果某个目录已经存在,就跳过它继续创建下一级目录。
cpp
// 静态方法:创建目录(支持创建多级目录)
static bool createDirectory(const std::string &path)
{
// 从第一个父级目录开始逐级创建
size_t pos, idx = 0;
while (idx < path.size())
{
// 查找下一个目录分隔符
pos = path.find("/", idx);
if (pos == std::string::npos)
{
// 没有更多分隔符,创建最终目录,权限设置为0775(rwxrwxr-x)
return (mkdir(path.c_str(), 0775) == 0);
}
// 提取当前层级的子路径
std::string subpath = path.substr(0, pos);
// 创建目录,权限设置为0775(rwxrwxr-x)
int ret = mkdir(subpath.c_str(), 0775);
// 如果创建失败且不是因为目录已存在,返回错误
if (ret != 0 && errno != EEXIST)
{
ELOG("创建目录 %s 失败: %s", subpath.c_str(), strerror(errno));
return false;
}
// 移动到下一个部分
idx = pos + 1;
}
return true;
}举个例子来说明
我来用文字和变量详细描述这个函数的思想,以路径 "aaa/bbb/ccc" 为例:
-
初始化:
-
函数接收路径
path = "aaa/bbb/ccc" -
设置变量
idx = 0,表示从字符串的位置0开始查找
-
-
第一次循环 (
idx = 0):-
从
idx=0的位置查找斜杠"/" -
找到斜杠在位置
pos = 3(因为"aaa"后面跟着"/") -
因为找到了斜杠(
pos != npos):-
提取子路径
subpath = path.substr(0, 3)= "aaa" -
尝试创建目录"aaa"
-
如果创建失败且不是因为目录已存在,则返回失败
-
-
更新
idx = pos + 1 = 4,移动到"bbb"的开始位置
-
-
第二次循环 (
idx = 4):-
从
idx=4的位置查找斜杠"/" -
找到斜杠在位置
pos = 7("bbb"后面跟着"/") -
提取子路径
subpath = path.substr(0, 7)= "aaa/bbb"- 注意:这个子路径包含了之前创建的"aaa"
-
尝试创建目录"aaa/bbb"
-
更新
idx = 7 + 1 = 8,移动到"ccc"的开始位置
-
-
第三次循环 (
idx = 8):-
从
idx=8的位置查找斜杠"/" -
这次找不到斜杠(
pos = npos) -
进入if分支:创建最终目录
-
子路径
subpath = path.substr(0, npos)= 整个路径 "aaa/bbb/ccc" -
尝试创建目录"aaa/bbb/ccc"
-
-
结束:所有目录创建完成,返回成功
关键点:
-
idx:记录当前查找的起始位置 -
pos:记录找到的斜杠位置 -
每次循环处理路径的一个层级
-
先创建父目录("aaa"),再创建子目录("aaa/bbb"),最后创建孙子目录("aaa/bbb/ccc")
-
如果目录已存在,忽略错误继续处理下一个层级
这样,即使路径很深如"a/b/c/d/e/f",函数也能逐级创建所有必需的目录。
但是这个函数还是有问题的,上面那个函数只能传入相对目录,如果说传入绝对目录,那是一点办法都没有啊
变量追踪
- path = /home/user/documents/reports/2024 (长度28)
- idx = 0 (初始位置)
第一轮循环 (idx = 0)
- 查找第一个斜杠:pos = path.find("/", 0) = 0
- 找到斜杠,位置为0(路径的第一个字符)
- 提取子路径:subpath = path.substr(0, 0) = 空字符串""
- 尝试创建目录:mkdir("", 0775)
- 问题:这会失败,因为空字符串不是有效路径
- errno 不是 EEXIST(目录已存在错误)
- 函数返回 false,创建失败
解决方案其实也很简单,但是我们没有必要去修改了,我们这个项目用不到。
2.4.9.递归删除目录及其所有内容
cpp
// 静态方法:递归删除目录及其所有内容
static bool removeDirectory(const std::string &path)
{
// 使用系统命令"rm -rf"强制递归删除目录
std::string cmd = "rm -rf " + path;
// system()返回值-1表示命令执行失败
return (system(cmd.c_str()) != -1);
}这里我们使用了系统命令接口来执行了rm -rf 指令!!这样子就能递归删除目录及其所有内容了。
2.4.10.整合测试
我们将上述代码整合到一个类里面
cpp
#include <fstream>
#include <string>
#include <sys/stat.h> // for stat
#include <sys/types.h> // for mkdir
#include <cerrno> // for errno
#include <cstring> // for strerror
class FileHelper {
public:
// 构造函数:使用给定的文件名初始化对象
FileHelper(const std::string &filename) : _filename(filename) {}
// 检查文件是否存在
bool exists() {
struct stat st;
// stat()函数返回0表示成功,即文件存在
return (stat(_filename.c_str(), &st) == 0);
}
// 获取文件大小(字节数)
size_t size() {
struct stat st;
int ret = stat(_filename.c_str(), &st);
if (ret < 0) { // 获取文件信息失败
return 0; // 返回0表示文件不存在或无法访问
}
return st.st_size; // 返回文件大小
}
// 从文件指定偏移量读取指定长度的数据到缓冲区
bool read(char *body, size_t offset, size_t len) {
// 1. 以二进制只读模式打开文件
std::ifstream ifs(_filename, std::ios::binary | std::ios::in);
if (ifs.is_open() == false) {
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
ifs.seekg(offset, std::ios::beg);
// 3. 读取len长度的数据到body缓冲区
ifs.read(body, len);
if (ifs.good() == false) { // 检查读取是否成功
ELOG("%s 文件读取数据失败!!", _filename.c_str());
ifs.close();
return false;
}
// 4. 关闭文件
ifs.close();
return true;
}
// 读取整个文件内容到字符串
bool read(std::string &body) {
// 获取文件大小,调整字符串大小以容纳文件内容
size_t fsize = this->size();
body.resize(fsize);
// 调用read函数读取整个文件
return read(&body[0], 0, fsize);
}
// 在文件指定偏移量处写入数据
bool write(const char *body, size_t offset, size_t len) {
// 1. 以二进制读写模式打开文件(允许读取和写入)
std::fstream fs(_filename, std::ios::binary | std::ios::in | std::ios::out);
if (fs.is_open() == false) {
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
fs.seekp(offset, std::ios::beg);
// 3. 写入len长度的数据
fs.write(body, len);
if (fs.good() == false) { // 检查写入是否成功
ELOG("%s 文件写入数据失败!!", _filename.c_str());
fs.close();
return false;
}
// 4. 关闭文件
fs.close();
return true;
}
// 将整个字符串内容写入文件(覆盖模式)
bool write(const std::string &body) {
return write(body.c_str(), 0, body.size());
}
// 重命名文件
bool rename(const std::string &nname) {
// 使用系统调用rename()重命名文件
return (::rename(_filename.c_str(), nname.c_str()) == 0);
}
// 静态方法:获取文件的父目录路径
static std::string parentDirectory(const std::string &filename) {
// 查找最后一个目录分隔符的位置
size_t pos = filename.find_last_of("/");
if (pos == std::string::npos) {
// 如果没有找到分隔符,说明文件在当前目录
return "./"; // 返回当前目录
}
// 提取分隔符前的部分作为目录路径
std::string path = filename.substr(0, pos);
return path;
}
// 静态方法:创建空文件
static bool createFile(const std::string &filename) {
// 以二进制写入模式创建文件
std::fstream ofs(filename, std::ios::binary | std::ios::out);
if (ofs.is_open() == false) {
ELOG("%s 文件打开失败!", filename.c_str());
return false;
}
ofs.close();
return true;
}
// 静态方法:删除文件
static bool removeFile(const std::string &filename) {
// 使用系统调用remove()删除文件
return (::remove(filename.c_str()) == 0);
}
// 静态方法:创建目录(支持创建多级目录)
static bool createDirectory(const std::string &path) {
// 从第一个父级目录开始逐级创建
size_t pos, idx = 0;
while (idx < path.size()) {
// 查找下一个目录分隔符
pos = path.find("/", idx);
if (pos == std::string::npos) {
// 没有更多分隔符,创建最终目录
return (mkdir(path.c_str(), 0775) == 0);
}
// 提取当前层级的子路径
std::string subpath = path.substr(0, pos);
// 创建目录,权限设置为0775(rwxrwxr-x)
int ret = mkdir(subpath.c_str(), 0775);
// 如果创建失败且不是因为目录已存在,返回错误
if (ret != 0 && errno != EEXIST) {
ELOG("创建目录 %s 失败: %s", subpath.c_str(), strerror(errno));
return false;
}
// 移动到下一个部分
idx = pos + 1;
}
return true;
}
// 静态方法:递归删除目录及其所有内容
static bool removeDirectory(const std::string &path) {
// 使用系统命令"rm -rf"强制递归删除目录
std::string cmd = "rm -rf " + path;
// system()返回值-1表示命令执行失败
return (system(cmd.c_str()) != -1);
}
private:
std::string _filename; // 内部存储的文件名
};现在我们就把这个封装好的类放入mymq/mqcommon/目录里面的helper.hpp
现在我们就写代码进行测试
测试文件是否存在,文件是否存在
cpp
#include"../../mqcommon/helper.hpp"
int main()
{
mymq::FileHelper helper ("../../mqcommon/helper.hpp");
DLOG("是否存在: %d",helper.exists());
DLOG("文件大小: %ld",helper.size());
}
我们可以去对比一下

这个文件大小倒是对上了
测试 创建目录(支持创建多级目录),创建文件,获取文件父目录
cpp
#include"../../mqcommon/helper.hpp"
int main()
{
mymq::FileHelper tmp_helper ("./aaa/bbb/ccc/tmp.hpp");
if(tmp_helper.exists()==false)//如果说文件不存在
{
std::string path=mymq::FileHelper::parentDirectory("./aaa/bbb/ccc/tmp.hpp");//获取该文件的父目录
if(mymq::FileHelper(path).exists()==false)//目录不存在
{
mymq::FileHelper::createDirectory(path);//创建父目录
}
mymq::FileHelper::createFile("./aaa/bbb/ccc/tmp.hpp");//创建文件
}
}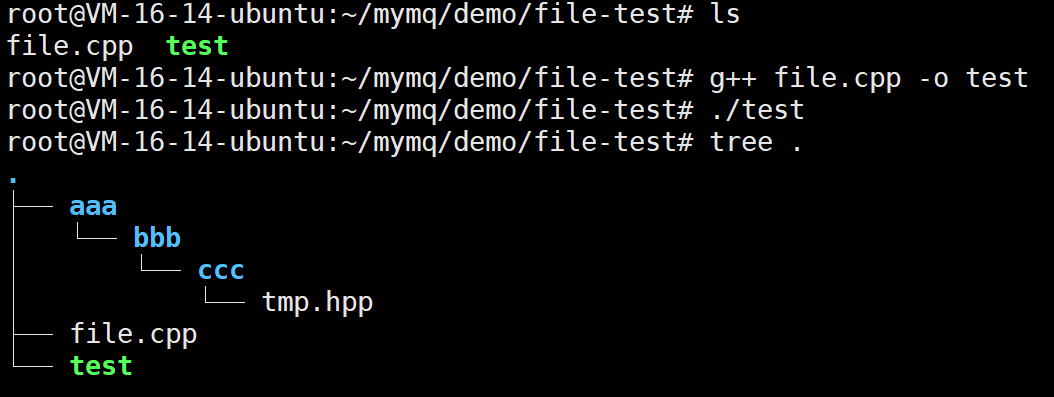
一点问题都没有。
这里需要注意:我们这里使用了下面这个成员函数来检测目录是否存在
cpp
// 检查文件是否存在,千万不要忘了目录也是文件
bool exists()
{
struct stat st;
// stat()函数返回0表示成功,即文件存在
return (stat(_filename.c_str(), &st) == 0);
}大家千万不要忘了:目录也是文件
测试文件读取/写入
cpp
#include"../../mqcommon/helper.hpp"
int main()
{
const std::string testFile = "test_basic.txt";
const std::string testContent = "Hello, FileHelper! 这是一个测试文件。\n第二行内容。\n第三行内容。";
// 创建FileHelper对象
mymq::FileHelper fh(testFile);
if(fh.exists()==false)
{
mymq::FileHelper::createFile(testFile);
}
// 测试写入整个文件
bool writeResult = fh.write(testContent);
// 测试读取整个文件
std::string readContent;
bool readResult = fh.read(readContent);
std::cout<<readContent<<std::endl;
}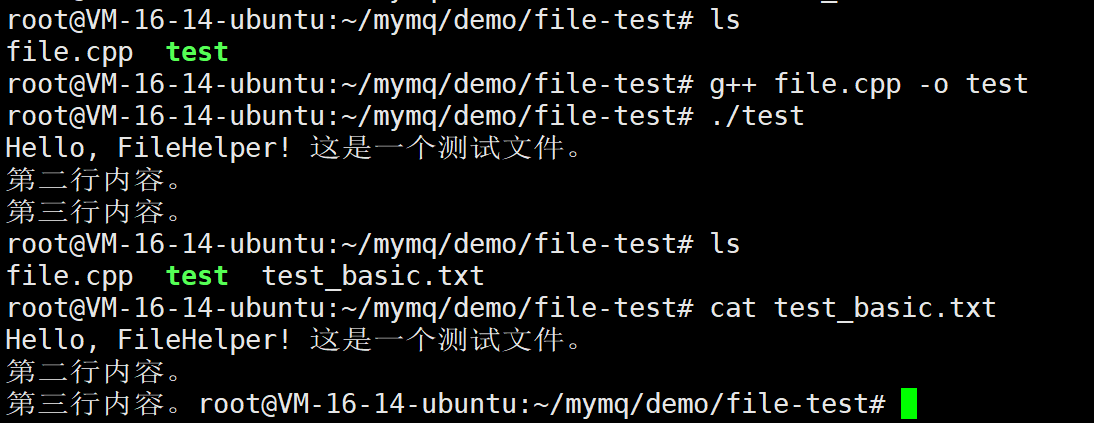
可以看到,文件读取和写入都是没有问题的。
测试 偏移读写
cpp
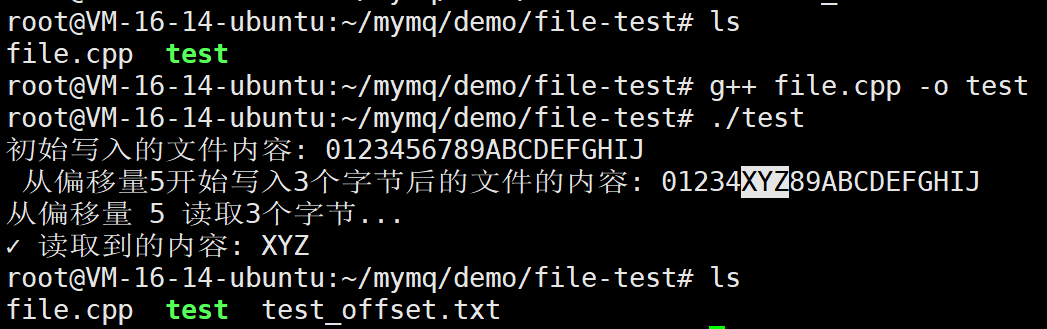
#include"../../mqcommon/helper.hpp"
int main()
{
const std::string testFile = "test_offset.txt";
// 创建FileHelper对象
mymq::FileHelper fh(testFile);
if(fh.exists()==false)
{
mymq::FileHelper::createFile(testFile);
}
// 初始写入一些内容
std::string initialContent = "0123456789ABCDEFGHIJ";
fh.write(initialContent);
// 读取整个文件验证
std::string updatedContent1;
fh.read(updatedContent1);
std::cout << "初始写入的文件内容: " << updatedContent1 << std::endl;
// 测试在偏移位置写入
const char* newData = "XYZ";
bool writeResult = fh.write(newData, 5, 3);// 从偏移量5开始写入3个字节
// 读取整个文件验证
std::string updatedContent2;
fh.read(updatedContent2);
std::cout << " 从偏移量5开始写入3个字节后的文件的内容: " << updatedContent2 << std::endl;
// 测试从偏移位置读取
std::cout << "从偏移量 5 读取3个字节..." << std::endl;
char buffer[4] = {0}; // 多一个字节用于null终止
bool readResult = fh.read(buffer, 5, 3);
std::cout << "✓ 读取到的内容: " << buffer << std::endl;
}
2.5.完整代码
现在我们就能写出这个helper.hpp的完整代码了
cpp
#ifndef ___M_HELPER_H__
#define ___M_HELPER_H__
#include <sqlite3.h>
#include <iostream>
#include <string>
#include "logger.hpp"
#include <vector>
#include <random>
#include <sstream>
#include <iomanip>
#include <atomic>
#include <fstream>
#include <sys/stat.h> // for stat
#include <sys/types.h> // for mkdir
#include <cerrno> // for errno
#include <cstring> // for strerror
namespace mymq
{
/**
* SQLite 数据库帮助类
* 封装了常用的 SQLite 操作,简化数据库使用
*/
class SqliteHelper
{
public:
// 定义回调函数类型别名,与 sqlite3_exec 的回调函数签名一致
typedef int (*sqlite_callback)(void *, int, char **, char **);
SqliteHelper(const std::string &filename) : _db_handler(nullptr), _dbfile(filename) {}
~SqliteHelper() { close(); }
bool open(int thread_safe_level = SQLITE_OPEN_FULLMUTEX)
{
// 设置打开标志------读写模式、不存在时创建、线程安全级别
int flag = SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE | thread_safe_level;
// 使用带标志的open函数打开数据库
int ret = sqlite3_open_v2(_dbfile.c_str(), &_db_handler, flag, nullptr);
// 检查数据库打开是否成功
if (ret != SQLITE_OK)
{
// 输出错误信息
ELOG("打开数据库文件%s失败: %s", _dbfile.c_str(), sqlite3_errmsg(_db_handler));
// 关闭失败的连接
sqlite3_close(_db_handler);
return false;
}
return true;
}
void close()
{
if (_db_handler)
sqlite3_close(_db_handler);
_db_handler = nullptr;
}
bool exec(const std::string &sql, sqlite_callback cb = nullptr, void *arg = nullptr)
{
// 执行SQL语句
int ret = sqlite3_exec(_db_handler, sql.c_str(), cb, arg, nullptr);
// 检查执行结果
if (ret != SQLITE_OK)
{
ELOG("sql语句: %s 执行失败: %s", sql.c_str(), sqlite3_errmsg(_db_handler));
return false;
}
return true;
}
private:
sqlite3 *_db_handler; // SQLite 数据库句柄,管理数据库连接
std::string _dbfile; // 数据库文件路径
};
class StringHelper
{
public:
// 函数功能是将字符串按指定分隔符分割成若干子串
// 返回值是分割得到的子串数量
static size_t split(const std::string &str, // 待分割的原始字符串
const std::string &sep, // 分隔符(可以是多个字符)
std::vector<std::string> &res, // 存储分割结果的字符串向量(输出型参数)
bool is_push_empty_string = false)
{ // 是否将空子串加入结果,默认为false
// 边界情况:如果原字符串或分隔符为空,直接返回0
if (str.empty() || sep.empty())
return 0;
size_t pos; // 分隔符出现的位置
size_t idx = 0; // 当前查找起始位置
// 循环查找分隔符直到字符串末尾
while (idx < str.size())
{
// 从当前位置开始查找分隔符
pos = str.find(sep, idx); // pos就是分隔符第一次出现的下标,再次调用find,就是第二次出现的......
// 情况1:找不到更多分隔符
if (pos == std::string::npos)
{
// 将剩余部分作为最后一个子串加入结果
res.push_back(str.substr(idx)); // str.substr(idx)代表从idx往后一直截取到字符串末尾
break;
}
// 情况2:分隔符紧挨着(产生空子串)
if (pos == idx && is_push_empty_string == false)
{
// 跳过分隔符继续查找(不添加空字符串)
idx += sep.size();
continue;
}
// 一般情况:提取从当前位置到分隔符之前的子串
res.push_back(str.substr(idx, pos - idx));
// 移动查找位置到分隔符之后
idx = pos + sep.size();
}
// 返回分割出的子串数量
return res.size();
}
};
class UUIDHelper
{
public:
static std::string uuid()
{
// 初始化随机数生成器
std::random_device rd;
std::mt19937_64 generator(rd());
// 生成1-100之间的随机数
std::uniform_int_distribution<int> dist(1, 100);
std::stringstream ss; // 注意这个在外面了
// 生成8个1-100之间的随机数,并按照XXXXXXXX-XXXX-XXXX-(注意最后的连字符)连接起来
for (int i = 0; i < 8; i++)
{
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << dist(generator);
if (i == 3 || i == 5 || i == 7)
{
ss << "-";
}
}
static std::atomic<size_t> seq(1); // 定义一个原子类型的整数,初始化为1
size_t num = seq.fetch_add(1); // size_t是一个八个字节的无符号整型,也就是64位,刚好是我们第二部的的长度
// 每次提取最低的8位,一共64位,需要提取8次
for (int i = 7; i >= 0; i--)
{
// 步骤1:右移 (i * 8) 位,将目标字节移到最低8位
uint64_t shifted = num >> (i * 8);
// 步骤2:使用 & 0xFF 提取最低8位
uint64_t byte = shifted & 0xFF;
// 带格式的转换(16进制输出,固定宽度为2位,不足2位前面补0)
ss << std::hex << std::setw(2) << std::setfill('0') << byte;
if (i == 6)
{
ss << "-";
}
}
return ss.str();
}
};
class FileHelper
{
public:
// 构造函数:使用给定的文件名初始化对象
FileHelper(const std::string &filename) : _filename(filename) {}
// 检查文件是否存在,千万不要忘了目录也是文件
bool exists()
{
struct stat st;
// stat()函数返回0表示成功,即文件存在
return (stat(_filename.c_str(), &st) == 0);
}
// 获取文件大小(字节数)
size_t size()
{
struct stat st;
int ret = stat(_filename.c_str(), &st);
if (ret < 0)
{ // 获取文件信息失败
return 0; // 返回0表示文件不存在或无法访问
}
return st.st_size; // 返回文件大小
}
// 从文件指定偏移量读取指定长度的数据到缓冲区
bool read(char *body, size_t offset, size_t len)
{
// 1. 以二进制只读模式打开文件
std::ifstream ifs(_filename, std::ios::binary | std::ios::in);
if (ifs.is_open() == false)
{
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
ifs.seekg(offset, std::ios::beg);
// 3. 读取len长度的数据到body缓冲区
ifs.read(body, len);
if (ifs.good() == false)
{ // 检查读取是否成功
ELOG("%s 文件读取数据失败!!", _filename.c_str());
ifs.close();
return false;
}
// 4. 关闭文件
ifs.close();
return true;
}
// 读取整个文件内容到字符串
bool read(std::string &body)
{
// 获取文件大小,调整字符串大小以容纳文件内容
size_t fsize = this->size();
body.resize(fsize);
// 调用read函数读取整个文件
return read(&body[0], 0, fsize);
}
// 在文件指定偏移量处写入数据
bool write(const char *body, size_t offset, size_t len)
{
// 1. 以二进制读写模式打开文件(允许读取和写入)
std::fstream fs(_filename, std::ios::binary | std::ios::in | std::ios::out);
if (fs.is_open() == false)
{
ELOG("%s 文件打开失败!", _filename.c_str());
return false;
}
// 2. 跳转到指定偏移量(相对于文件开头)
fs.seekp(offset, std::ios::beg);
// 3. 写入len长度的数据
fs.write(body, len);
if (fs.good() == false)
{ // 检查写入是否成功
ELOG("%s 文件写入数据失败!!", _filename.c_str());
fs.close();
return false;
}
// 4. 关闭文件
fs.close();
return true;
}
// 将整个字符串内容写入文件(覆盖模式)
bool write(const std::string &body)
{
return write(body.c_str(), 0, body.size());
}
// 重命名文件
bool rename(const std::string &nname)
{
// 使用系统调用rename()重命名文件
return (::rename(_filename.c_str(), nname.c_str()) == 0);
}
// 静态方法:获取文件的父目录路径
static std::string parentDirectory(const std::string &filename)
{
// 查找最后一个目录分隔符的位置
size_t pos = filename.find_last_of("/");
if (pos == std::string::npos)
{
// 如果没有找到分隔符,说明文件在当前目录
return "./"; // 返回当前目录
}
// 提取分隔符前的部分作为目录路径
std::string path = filename.substr(0, pos);
return path;
}
// 静态方法:创建空文件
static bool createFile(const std::string &filename)
{
// 以二进制写入模式创建文件
std::fstream ofs(filename, std::ios::binary | std::ios::out);
if (ofs.is_open() == false)
{
ELOG("%s 文件打开失败!", filename.c_str());
return false;
}
ofs.close();
return true;
}
// 静态方法:删除文件
static bool removeFile(const std::string &filename)
{
// 使用系统调用remove()删除文件
return (::remove(filename.c_str()) == 0);
}
// 静态方法:创建目录(支持创建多级目录)
static bool createDirectory(const std::string &path)
{
// 从第一个父级目录开始逐级创建
size_t pos, idx = 0;
while (idx < path.size())
{
// 查找下一个目录分隔符
pos = path.find("/", idx);
if (pos == std::string::npos)
{
// 没有更多分隔符,创建最终目录
return (mkdir(path.c_str(), 0775) == 0);
}
// 提取当前层级的子路径
std::string subpath = path.substr(0, pos);
// 创建目录,权限设置为0775(rwxrwxr-x)
int ret = mkdir(subpath.c_str(), 0775);
// 如果创建失败且不是因为目录已存在,返回错误
if (ret != 0 && errno != EEXIST)
{
ELOG("创建目录 %s 失败: %s", subpath.c_str(), strerror(errno));
return false;
}
// 移动到下一个部分
idx = pos + 1;
}
return true;
}
// 静态方法:递归删除目录及其所有内容
static bool removeDirectory(const std::string &path)
{
// 使用系统命令"rm -rf"强制递归删除目录
std::string cmd = "rm -rf " + path;
// system()返回值-1表示命令执行失败
return (system(cmd.c_str()) != -1);
}
private:
std::string _filename; // 内部存储的文件名
};
};
#endif三.消息类型定义
在开始正式编写项目功能模块代码之前,我们需要先完成一项基础工作:定义消息的类型。由于消息最终需要进行持久化存储,并涉及序列化与反序列化过程,因此我们选择使用 Protocol Buffers(protobuf) 来定义消息结构,并通过它生成对应的代码。
定义消息类型即意味着需要编写一个描述消息结构的 .proto 文件,并利用 protobuf 工具生成相应语言的数据访问类。
设计消息类型
一、消息的组成要素
消息定义主要包含以下两部分内容:
a. 消息本身的基本要素
i. 消息属性
- 消息ID:唯一标识一条消息。
- 消息投递模式:分为非持久化模式与持久化模式。
- 消息的 routing_key:用于消息路由。
ii. 消息有效载荷:即消息实际携带的数据内容。
b. 消息持久化所需的附加信息
- i. 消息的存储位置
- ii. 消息的长度
- iii. 消息是否有效
此处不采用 bool 类型,而使用字符 '0' 或 '1' 表示。原因是 bool 类型在不同平台或序列化方式中可能占用不同字节长度,若后续修改文件中该标记位的值,可能导致整个消息长度发生变化,不利于持久化文件的稳定维护。
二、公共枚举定义
由于客户端和服务端都需要使用到交换机类型和消息投递模式的相关信息,我们将这两个枚举也一并定义在同一个 proto 文件中,以保证两端代码的一致性。
- 交换机类型(ExchangeType)
- a. DIRECT -- 直连交换机
- b. FANOUT -- 广播交换机
- c. TOPIC -- 主题交换机
- 消息投递模式(DeliveryMode)
- a. NON_DURABLE -- 非持久化模式(值为 1,与 RabbitMQ 约定一致)
- b. DURABLE -- 持久化模式(值为 2)
通过以上定义,我们可以在项目中统一消息的结构与行为,为后续的消息传递、持久化及路由机制打下基础。接下来即可根据该 proto 文件生成对应编程语言的数据结构代码,并在项目中直接使用。
实现
我们把下面这个填写进这个msg.proto
cpp
syntax = "proto3"; // 指定使用 protobuf 第3版语法
package mymq; // 包名,用于防止命名冲突
// 消息投递模式枚举
enum DeliveryMode {
UNKNOWMODE = 0; // 未知模式(protobuf要求枚举从0开始)
UNDURABLE = 1; // 非持久化模式,内存存储,服务重启后消息丢失
DURABLE = 2; // 持久化模式,磁盘存储,服务重启后消息仍存在
};
// 交换机类型枚举
enum ExchangeType {
UNKNOWTYPE = 0; // 未知类型(protobuf要求枚举从0开始)
DIRECT = 1; // 直接交换:完全匹配 routing_key 进行路由
FANOUT = 2; // 广播交换:忽略 routing_key,发送到所有绑定队列
TOPIC = 3; // 主题交换:通过模式匹配 routing_key 进行路由
};
// 消息基础属性
message BasicProperties {
string id = 1; // 消息唯一标识符(UUID格式)
string routing_key = 2; // 路由键,用于交换机匹配队列
// 投递模式:1-非持久化;2-持久化(与RabbitMQ保持一致)
DeliveryMode delivery_mode = 3;
};
// 完整的消息结构
message MQMessage {
// 消息有效载荷部分(包含实际数据和属性)
message Payload {
BasicProperties properties = 1; // 消息基础属性
string body = 2; // 消息体,实际传输的数据内容
};
// 真正需要持久化存储的部分(除以下字段外,其他字段均为运行时辅助信息)
Payload payload = 1;
// 消息有效性标记:使用字符'0'或'1'表示,避免bool类型序列化长度不统一的问题
// '1'-有效,'0'-无效(已消费或被标记删除)
string valid = 2;
// 消息在持久化文件中的偏移量(以字节为单位)
uint64 offset = 3;
// 消息在持久化文件中的长度(以字节为单位)
// offset和length组合使用,可在文件中快速定位和读取消息
uint64 length = 4;
};那么写好文件了,我们就进行生成吧

现在就OK了