TL;DR
- 场景:Java 服务接入 Memcached,需要搞清 Spymemcached 的线程模型、分片路由和序列化细节,避免线上踩坑。
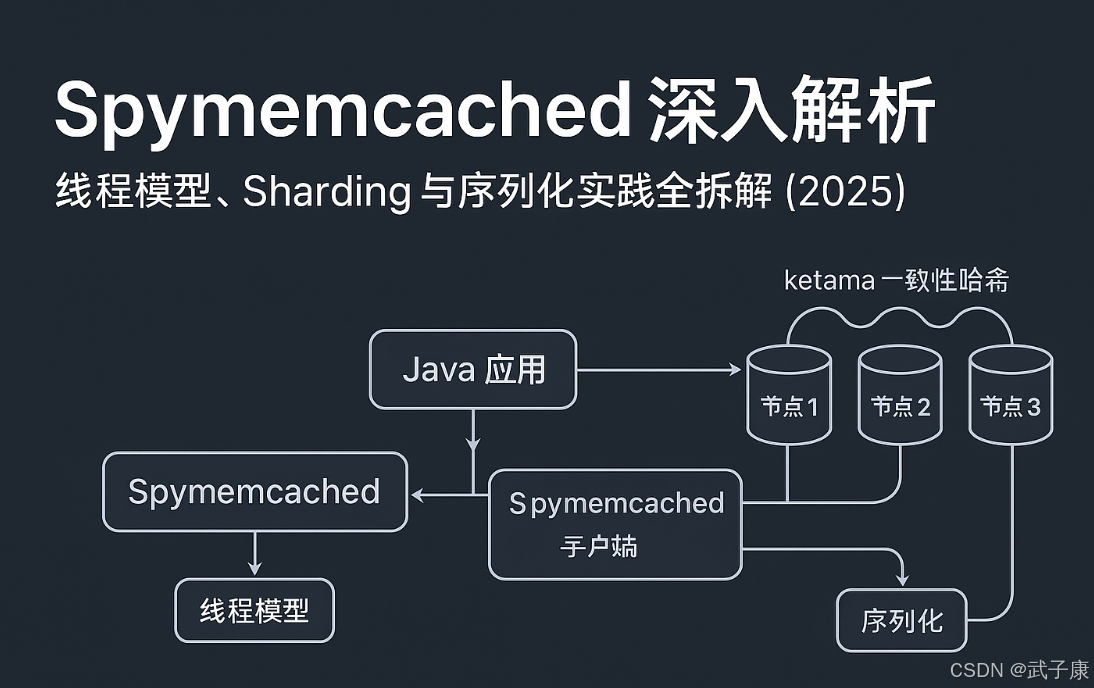
- 结论:Spymemcached 基于 NIO+回调实现异步 IO,通过 ketama 一致性哈希做 Sharding,并在客户端层面承担部分容错与序列化职责。
- 产出:给出整体架构拆解、线程与 Sharding 机制说明,以及围绕超时、热点、序列化等问题的错误速查卡,可直接用于设计和排查参考。
Spymemcached
基本介绍
Spymemcached 是一个 memcached 的客户端,使用NIO实现。
它主要有如下的特性:
-
协议支持
Memcached 协议支持两种格式:
- Text 协议:基于纯文本的协议,易于调试和阅读,适合简单场景
- Binary 协议:二进制协议,传输效率更高,支持更复杂的操作,适合生产环境
-
异步通信机制
采用 NIO(Non-blocking I/O) 实现高效网络通信,通过 callback(回调) 机制处理响应,避免线程阻塞。例如:
java
client.get("key", new GetOperationCallback() {
@Override
public void complete(String key, Object value) {
// 处理获取到的值
}
});-
集群与分片
支持 Sharding(分片)机制,数据自动分布到多个节点,例如:
- 采用一致性哈希算法分配 key
- 支持动态增减节点,数据自动重新平衡
-
断网恢复能力
具备 自动重连 功能:
- 网络中断后自动尝试重新连接
- 可配置重试间隔和最大重试次数
-
容错与故障转移(Failover)
提供可扩展的容错机制:
- 节点故障时自动切换到备用节点
- 支持配置多级备份策略
-
批量操作与序列化
- 批量 get:支持一次获取多个 key,减少网络开销
- JDK 序列化:默认支持 Java 对象的序列化/反序列化,也可扩展其他序列化方案(如 JSON、Protobuf)
整体设计
-
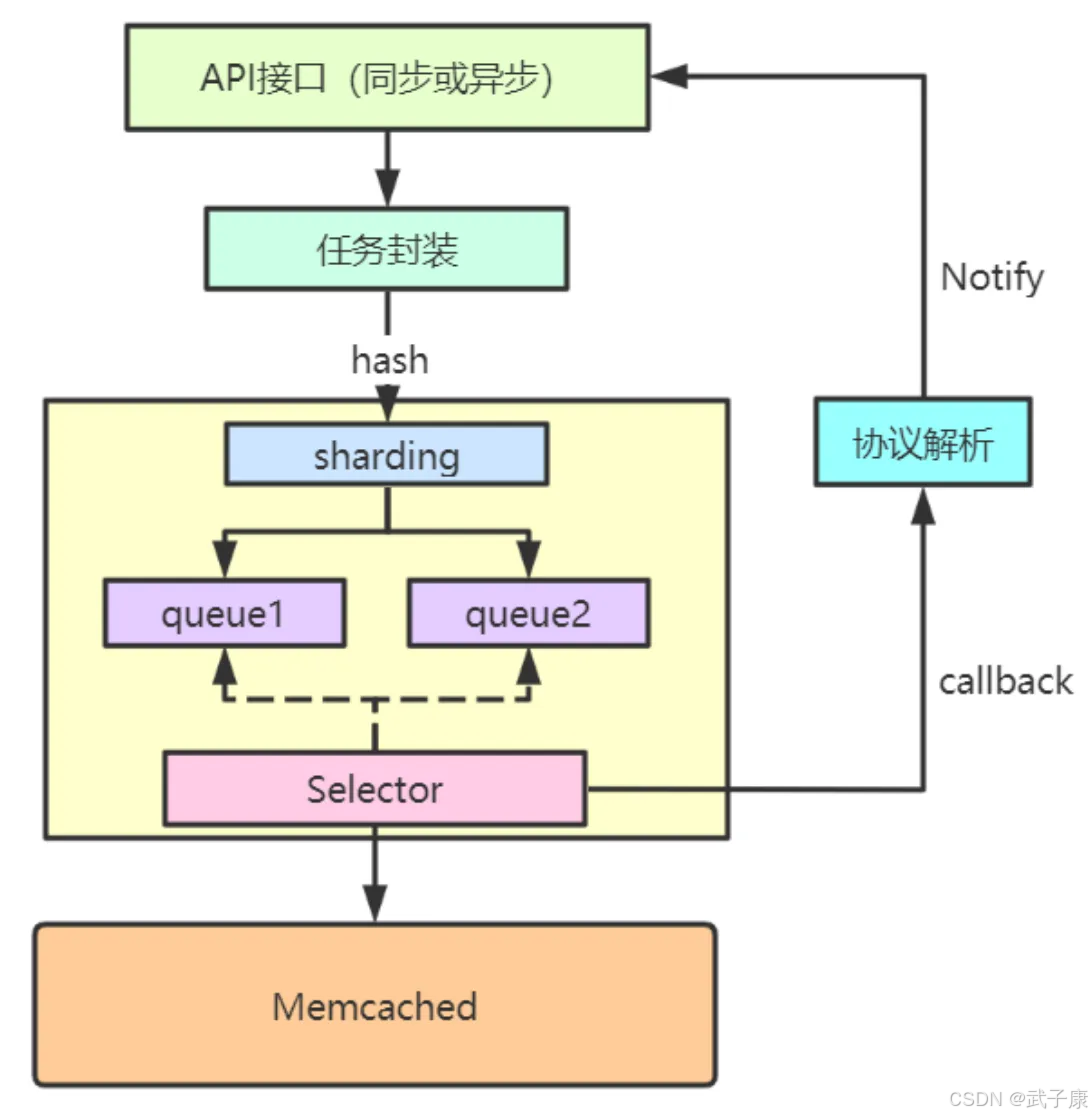
API接口设计:
- 提供同步和异步两种调用方式:
- 同步接口直接返回操作结果(阻塞调用线程)
- 异步接口返回Future对象,支持后续通过get()方法获取结果
- 示例:
Future<Value> asyncGet(String key)和Value syncGet(String key)
- 提供同步和异步两种调用方式:
-
任务封装机制:
- 将每个访问请求(如get/set操作)及其回调逻辑封装为独立Task对象
- Task包含:
- 操作类型(GET/SET/DELETE等)
- 键值数据
- 回调处理器
- 超时计时器
- 示例:Set操作Task会包含key、value、expire时间等字段
-
路由分区策略:
- 采用一致性哈希等Sharding算法
- 根据key的哈希值确定目标节点
- 维护key到物理连接的映射表
- 支持动态扩容时的数据迁移
-
任务队列管理:
- 每个connection维护独立的任务队列
- 采用线程安全的阻塞队列实现
- 支持优先级队列(如紧急任务优先)
- 队列容量可配置,防止内存溢出
-
异步IO处理流程:
- Selector监控所有连接的IO事件
- 当连接可写时,从队列头部取出Task
- 按照Memcached协议格式封装请求:
- 文本协议:
"get <key>\r\n" - 二进制协议:构造对应command报文
- 通过channel发送请求
-
响应处理机制:
-
收到响应包后:
- 根据报文中的opaque字段匹配原始Task
- 解析响应数据(如VALUE/END等)
- 执行注册的callback
- 对于Future调用:
- 设置结果值
- 唤醒等待的线程
-
异常处理:
- 超时处理
- 连接异常重试
- 协议错误记录
-
-
性能优化点:
- 连接池管理复用connection
- 批量操作合并(如multi-get)
- 零拷贝优化网络传输
- 异步回调避免线程阻塞
接口设计
对外API接口有两种,同步和异步。
同步接口:比如set、get等
异步接口:asyncGet、asyncIncr等
java
package icu.wzk;
import net.spy.memcached.AddrUtil;
import net.spy.memcached.MemcachedClient;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
public class CacheDemo02 {
public static void main(String[] args) throws Exception {
String server = "172.16.1.130:11211";
MemcachedClient memcachedClient = new MemcachedClient(AddrUtil.getAddresses(server));
Object obj = null;
Future<Object> f = memcachedClient.asyncGet("key");
try {
obj = f.get(5, TimeUnit.SECONDS);
} catch (Exception e) {
f.cancel(false);
}
}
}线程设计
SpyMemcached 有两类线程:业务线程和Selector线程。
业务线程
业务线程主要负责处理客户端请求的封装、序列化以及任务分发,具体工作流程如下:
- 请求封装 :接收客户端请求,将其封装为统一的Task对象。每个Task包含:
- 操作类型(GET/SET/DELETE等)
- 键值对数据
- 过期时间等元数据
- 对象序列化 :将Task对象序列化为二进制数据。支持多种序列化协议:
- Protocol Buffers(高效二进制协议)
- JSON(调试场景使用)
- 协议封装 :添加Memcached协议头信息,包括:
- 魔术字节(标识协议类型)
- 操作码
- 数据长度
- 其他控制字段
- 任务分发 :根据一致性哈希算法确定目标节点,将Task放入对应连接的发送队列。队列采用:
- 无锁环形缓冲区(高并发场景)
- 带优先级的双队列(区分读写操作)
对于接收到的响应数据,业务线程还负责:
- 反序列化Memcached返回的二进制数据
- 将结果转换为业务层可用的对象模型
- 处理特殊响应(如NOT_FOUND, SERVER_ERROR等)
Selector线程
Selector线程作为I/O核心处理单元,采用多路复用技术管理所有连接,主要职责包括:
发送处理
- 队列轮询:通过epoll/kqueue监控所有连接的可写事件
- 数据发送 :
- 从连接发送队列批量取出Task(每次最多32个)
- 合并小包(Nagle算法优化)
- 通过零拷贝技术直接发送序列化数据
- 流量控制 :
- 监控节点背压(backpressure)
- 动态调整发送窗口大小
接收处理
- 响应读取 :
- 非阻塞读取socket数据
- 协议解析(处理TCP粘包/拆包)
- 校验数据完整性(CRC校验)
- 结果通知 :
- 通过条件变量唤醒等待的业务线程
- 将反序列化结果写入响应缓存
- 支持回调机制(异步编程模型)
连接管理
- 故障检测 :
- 心跳检测(每5秒发送PING命令)
- 响应超时监控(默认3秒阈值)
- 自动恢复 :
- 指数退避重连(1s,2s,4s...上限30s)
- 连接重建后自动重发队列中的Task
- 负载均衡 :
- 实时统计节点响应延迟
- 动态调整节点权重
- 热点数据自动迁移
典型应用场景:
- 电商秒杀:业务线程快速封装库存扣减请求,Selector线程保证高并发写入
- 社交feed流:批量获取用户动态时,Selector线程合并多个GET请求提升吞吐量
Sharding机制
路由机制
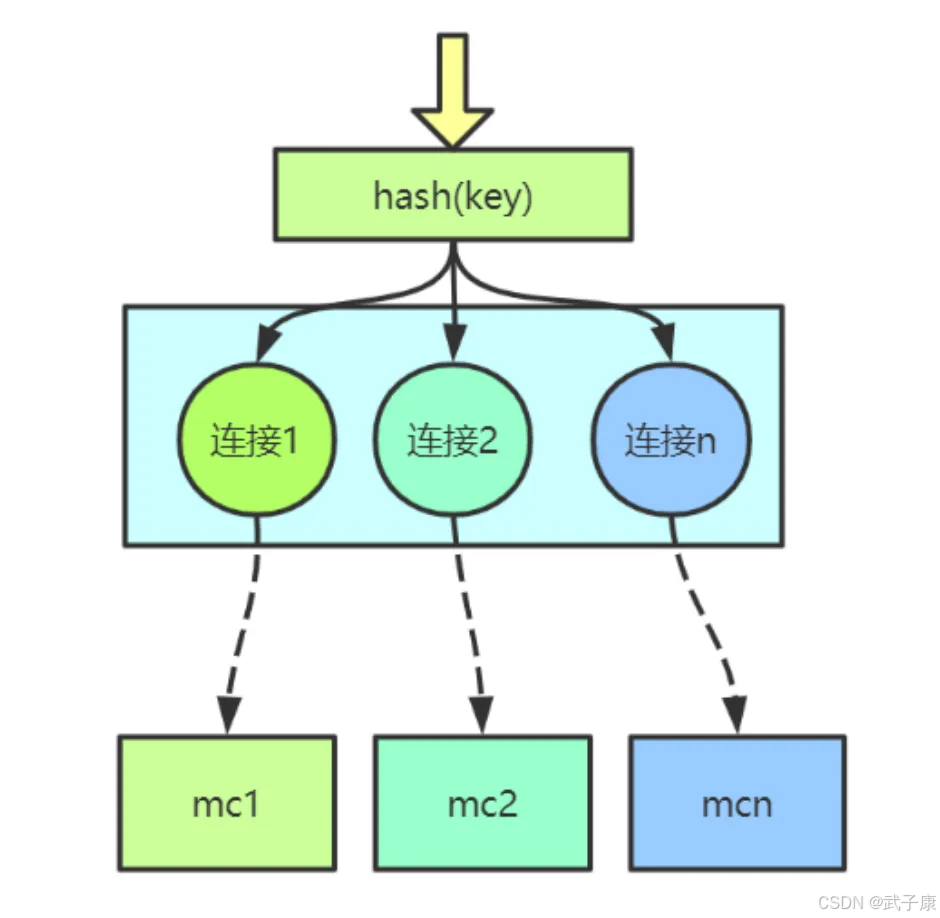
Spymemcached 默认支持两种哈希算法用于数据分片:
-
arrayMod(数组取模哈希)
- 传统哈希算法实现
- 计算方式:hash(key) % 节点数量 = 目标节点索引
- 特点:
- 简单直接,计算开销小
- 节点增减时会导致大规模数据迁移(几乎全部key需要重新映射)
- 适合节点数量固定不变的场景
- 示例:当有3个节点时,key为"user:1001"可能映射到:
hash("user:1001")=123456 → 123456%3=0 → 选择节点0
-
ketama(一致性哈希)
- 基于一致性哈希算法实现
- 核心机制:
- 为每个物理节点生成大量虚拟节点(默认160个)
- 构建哈希环,将虚拟节点均匀分布在环上
- 查找时:hash(key)在环上顺时针找到最近的虚拟节点
- 优势:
- 节点增减时平均只需迁移1/N的数据(N为节点数)
- 支持权重配置(通过调整虚拟节点数量)
- 天然解决热点问题
- 应用场景:
- 需要弹性扩容的场景
- 对数据分布均匀性要求高的场景
- 例如:一个10节点的集群扩容到12节点时,仅影响约16.7%的数据
两种算法对比:
- arrayMod在节点变化时会导致近乎100%的数据重分布
- ketama在增加1个节点时平均只影响1/(N+1)的数据量
- 生产环境推荐使用ketama,除非有特殊性能考量
容错
key路由到服务器节点,服务节点宕机,有两种处理方式。
自动重连机制详细说明:
-
节点故障检测:
- 通过心跳检测或请求超时判断节点状态
- 当连续3次检测失败(可配置)即判定为故障节点
-
重连队列管理:
- 摘除流程:
- 从正常节点池中移除故障节点
- 记录摘除时间戳和失败原因
- 重连策略:
- 初始重连间隔:5秒
- 采用指数退避算法,最大间隔不超过1分钟
- 重连成功后会重新加入正常节点池
- 摘除流程:
-
Selector线程工作流程:
- 每10秒扫描一次重连队列
- 对每个节点执行TCP连接测试
- 成功后进行业务请求测试验证
failover处理策略详解:
-
Redistribute策略(推荐):
- 实现方式:轮询/随机选择下一个可用节点
- 应用场景:读操作、幂等操作
- 示例:数据库查询请求,当主节点故障时自动切换到从节点
-
Retry策略:
- 实现要点:
- 最大重试次数:3次(可配置)
- 重试间隔:线性增长(1s,2s,3s)
- 适用场景:写操作、非幂等操作但业务允许重试
- 风险提示:需注意请求重复问题
- 实现要点:
-
Cancel策略:
- 异常处理流程:
- 记录详细错误日志
- 抛出ConnectionException
- 包含原始错误信息和故障节点信息
- 使用场景:
- 关键业务不允许自动切换
- 所有节点均不可用
- 需要人工干预的特殊情况
- 异常处理流程:
补充说明:
-
策略选择建议:
策略类型 适用场景 注意事项 Redistribute 多节点冗余环境 需确保节点数据一致性 Retry 短暂性故障 需考虑业务幂等性 Cancel 关键业务操作 需要完善异常处理 -
监控指标:
- 重连成功率
- 平均重连耗时
- failover触发次数
- 各策略使用占比
序列化
我们在日常的使用过程中大部分是对象,那么在 Memcached中会以二进制的形式方式存储。所以在存储数据的时候要进行序列化。
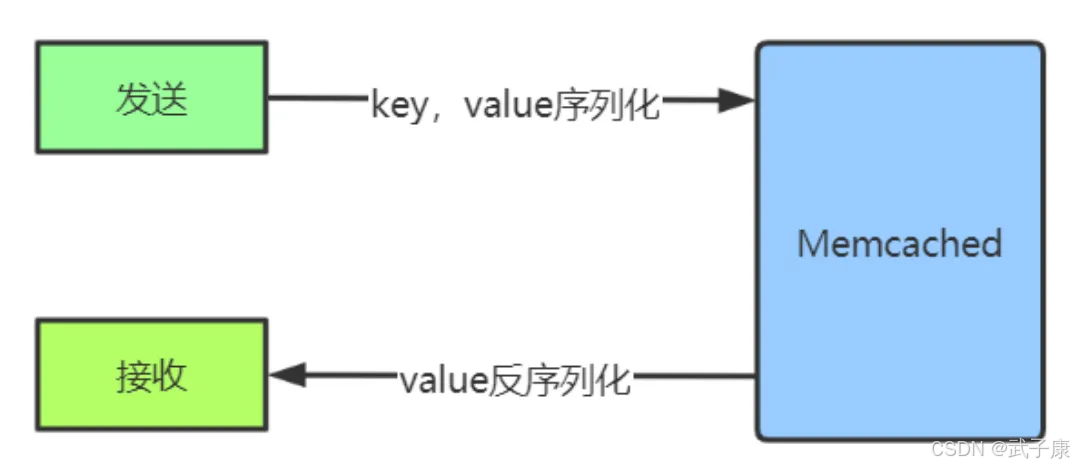
序列化后会判断长度是否大于阈值的 16384byte,如果是大于就进行GZip压缩。
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 高并发下大量 get 超时,Future get() 经常触发 Timeout | 单节点压力过大,Selector 线程处理不过来或网络抖动,队列积压严重 | 监控 Memcached QPS、RT 与客户端线程堆栈,查看 Selector 线程是否长时间忙于写或读;降低单节点压力(加节点并配合 ketama)、调大超时配置、优化批量 get 逻辑 |
| 节点增减后,缓存命中率瞬间跌到接近 0 | 使用 arrayMod 分片,扩容/缩容导致 key 映射几乎全变 | 对比扩容前后 key→节点映射,观察某些热点 key 是否都换了节点;生产场景改用 ketama 一致性哈希;已有集群扩容前预热新节点,或使用双写/渐进迁移方案 |
| 某个节点故障后,业务层大量报「连接异常」或长时间阻塞 | Failover 策略配置不当:重试+重连叠加,导致请求堆积或阻塞 | 打开客户端日志,统计失败节点的重试次数、重连间隔,查看是否出现「雪崩式重试」;限制最大重试次数,减小阻塞式调用比例,必要时短路到 Cancel 策略并快速失败 |
| QPS 上去后 Client 进程内存持续增长,GC 压力异常 | 任务队列、Future 或回调里持有大对象引用,批量操作结果未及时释放 | 使用 heap dump 查看是否有大量未完成的 Future/Task 对象,确认是否队列无界;给队列设置合理上限;回调中避免持有大对象;对大 Value 及时清理引用,必要时分批读取 |
| 某些 key 偶发「NOT_FOUND」,但后端业务明确写入成功 | 分片路由不一致:不同 Client 实例 Ketama 配置不一致或顺序不同 | 检查所有 Client 配置中节点列表顺序、权重配置和哈希算法是否完全一致;固定节点列表顺序和权重;对 client 配置做集中管理,禁止单机随意改动 |
| 大对象写入时 CPU 飙高,RT 明显上升 | 序列化+GZip 压缩消耗较大,特别是超过 16384 byte 阈值的大对象 | 火焰图分析 CPU 消耗,关注序列化和压缩方法调用栈;统计大 Value 比例与平均大小;尽量避免超大对象进缓存;调整压缩阈值;必要时用更轻量的自定义序列化和有损拆分方案 |
| 客户端日志频繁出现重连、Failover 日志 | 后端节点不稳定或网络抖动,触发自动重连与 failover 逻辑 | 结合服务端监控看连接数、拒绝数和网络丢包情况;梳理 Failover 触发的时间点与比例;先解决服务端与网络稳定性;再收紧重连与 Failover 策略,避免「抖动放大」 |
| 某一批请求返回值类型或内容解不出来,反序列化抛异常 | 不同应用/版本之间序列化协议不兼容(JDK 原生、JSON、Protobuf 混用) | 统计异常 key 的来源应用和部署批次,确认是否有多种序列化方式写入同一缓存空间;为不同序列化协议划分独立 namespace 或 key 前缀;上线前做灰度和版本兼容设计 |
| 单机 CPU 高但网络带宽利用率不高 | 大量小包请求,未做批量 get 或合并写,Selector 线程频繁系统调用 | 抓包查看包大小与频率,分析是否存在大量单 key get 导致的系统调用开销;尽可能使用批量 get;在调用侧做聚合;减少无意义的重复读写 |
| 偶发业务线程「卡死」在 Future.get() | 调用过多同步接口依赖,未设置超时或超时过大,底层超时/异常未及时上抛 | 线程 dump 查看是否集中阻塞在少数 Future.get 调用上;同时对照客户端超时配置;所有同步调用统一加超时;鼓励使用异步+回调模式;对底层异常做统一封装和快速失败策略 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南!
AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-180 Java 接入 FastDFS:自编译客户端与 Maven/Spring Boot 实战
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS正在更新... 深入浅出助你打牢基础!
🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
🔗 大数据模块直达链接