note
文章目录
- note
-
- 一、论文想解决什么问题?(Why)
- 二、论文的核心贡献(What)
-
- [1️⃣ 提出一个 **二维评测分类体系(Taxonomy)**](#1️⃣ 提出一个 二维评测分类体系(Taxonomy))
- [2️⃣ 系统梳理已有工作](#2️⃣ 系统梳理已有工作)
- [3️⃣ 明确指出 **企业级 Agent 评测的缺口**](#3️⃣ 明确指出 企业级 Agent 评测的缺口)
- 三、二维评测框架(核心)
- [第一维:Evaluation Objectives(评什么)](#第一维:Evaluation Objectives(评什么))
-
- [1️⃣ Agent Behavior(外在行为表现)](#1️⃣ Agent Behavior(外在行为表现))
- [2️⃣ Agent Capabilities(内部能力)](#2️⃣ Agent Capabilities(内部能力))
-
- [• Tool Use(工具调用)](#• Tool Use(工具调用))
- [• Planning & Reasoning(规划与推理)](#• Planning & Reasoning(规划与推理))
- [• Memory & Context(记忆与上下文)](#• Memory & Context(记忆与上下文))
- [• Multi-Agent Collaboration(多 Agent 协作)](#• Multi-Agent Collaboration(多 Agent 协作))
- [3️⃣ Reliability(可靠性)](#3️⃣ Reliability(可靠性))
- [4️⃣ Safety & Alignment(安全与对齐)](#4️⃣ Safety & Alignment(安全与对齐))
- [第二维:Evaluation Process(怎么评)](#第二维:Evaluation Process(怎么评))
-
- [1️⃣ Interaction Mode(交互模式)](#1️⃣ Interaction Mode(交互模式))
- [2️⃣ Evaluation Data(评测数据)](#2️⃣ Evaluation Data(评测数据))
- [3️⃣ Metrics Computation(怎么算分)](#3️⃣ Metrics Computation(怎么算分))
- [4️⃣ Tooling(工具)](#4️⃣ Tooling(工具))
- [5️⃣ Context(评测环境)](#5️⃣ Context(评测环境))
- Reference
一、论文想解决什么问题?(Why)
核心问题
-
现在 LLM Agent 越来越复杂 :
会规划、用工具、有记忆、能多轮互动、能协作
-
但 评测方法仍停留在 LLM 级别:
- 单轮 QA
- accuracy / BLEU / pass@k
-
👉 这些方法已经不足以评测 Agent
论文用一个很形象的比喻(在 Introduction):
评测 LLM ≈ 测发动机
评测 Agent ≈ 测整辆车在不同路况下的表现
二、论文的核心贡献(What)
论文做了三件非常重要的事:
1️⃣ 提出一个 二维评测分类体系(Taxonomy)
- 不是堆 benchmark
- 而是抽象出 评测的"空间坐标系"
2️⃣ 系统梳理已有工作
- 把零散的 benchmark、指标、工具
- 放进统一框架里对齐
3️⃣ 明确指出 企业级 Agent 评测的缺口
- 可靠性
- 合规
- 长时交互
- 权限与审计
三、二维评测框架(核心)
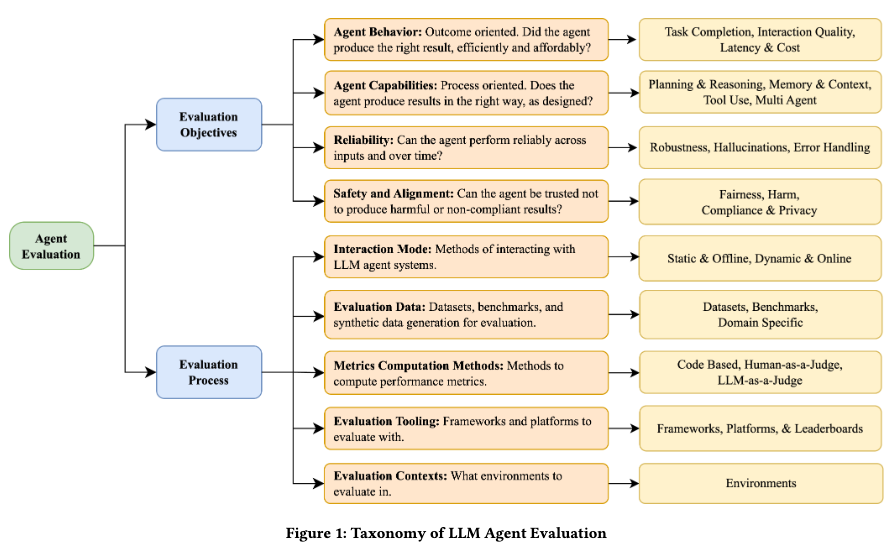
第一维:Evaluation Objectives(评什么)
👉 Agent 本身哪些"能力 / 属性"需要被评测
1️⃣ Agent Behavior(外在行为表现)
黑盒视角,像用户一样看 Agent
- ✅ 任务是否完成(Task Completion)
- ✅ 输出质量(质量、可读性、准确性)
- ✅ 延迟 & 成本(Latency & Cost)
📌 典型指标:
- Success Rate
- pass@k
- TTFT
- Token cost
2️⃣ Agent Capabilities(内部能力)
白盒 / 过程导向,Agent 是怎么做到的
• Tool Use(工具调用)
- 会不会调用
- 选没选对
- 参数对不对
- 是否能执行成功
• Planning & Reasoning(规划与推理)
- 工具序列是否合理
- 中间决策是否正确
- 是否能动态调整(ReAct)
• Memory & Context(记忆与上下文)
- 多轮对话是否记得关键信息
- 长时任务是否一致
• Multi-Agent Collaboration(多 Agent 协作)
- 是否能分工
- 是否有效沟通
- 是否同步目标
👉 这是 Agent 和普通 LLM 最大的分水岭
3️⃣ Reliability(可靠性)
企业和生产最关心的,但研究里最容易忽略的
- 一致性(同样输入是否稳定)
- 鲁棒性(输入扰动、工具失败)
📌 重点提出:
- pass@k 不够
- pass^k(每次都成功) 才是生产级要求
4️⃣ Safety & Alignment(安全与对齐)
不只是"有没有骂人",而是:
- 公平性
- 有害内容
- 合规 & 隐私
- 企业政策遵循
第二维:Evaluation Process(怎么评)
1️⃣ Interaction Mode(交互模式)
- Static / Offline(离线)
- Dynamic / Online(交互式)
👉 论文强调:
Agent 必须大量用动态评测
2️⃣ Evaluation Data(评测数据)
- 人工标注
- 合成数据
- 模拟环境
- 真实日志
3️⃣ Metrics Computation(怎么算分)
三大类:
- Code-based(规则/执行)
- LLM-as-a-Judge
- Human-in-the-loop
👉 强调 没有银弹,需要组合
4️⃣ Tooling(工具)
- LangSmith
- DeepEval
- OpenAI Evals
- AgentOps
提出一个概念:
Evaluation-driven Development(EDD)
评测不是收尾,而是开发过程的一部分
5️⃣ Context(评测环境)
- Mock API
- Sandbox
- Web Simulator
- 真实系统
Reference
1 Evaluation and Benchmarking of LLM Agents: A Survey