(文献+程序)多智能体分布式模型预测控制 编队 队形变换 论文复现带文档 MATLAB MPC 无人车 无人机编队 无人船无人艇控制 编队控制强化学习 嵌入式应用 simulink仿真验证 PID 智能体数量变化
在智能控制的广袤世界里,多智能体分布式模型预测控制(MPC)在编队领域那可是相当耀眼的存在。无论是无人车、无人机编队,还是无人船无人艇控制,都离不开它的"保驾护航"。今天咱就来唠唠这个超有趣的玩意儿。
一、从论文到复现
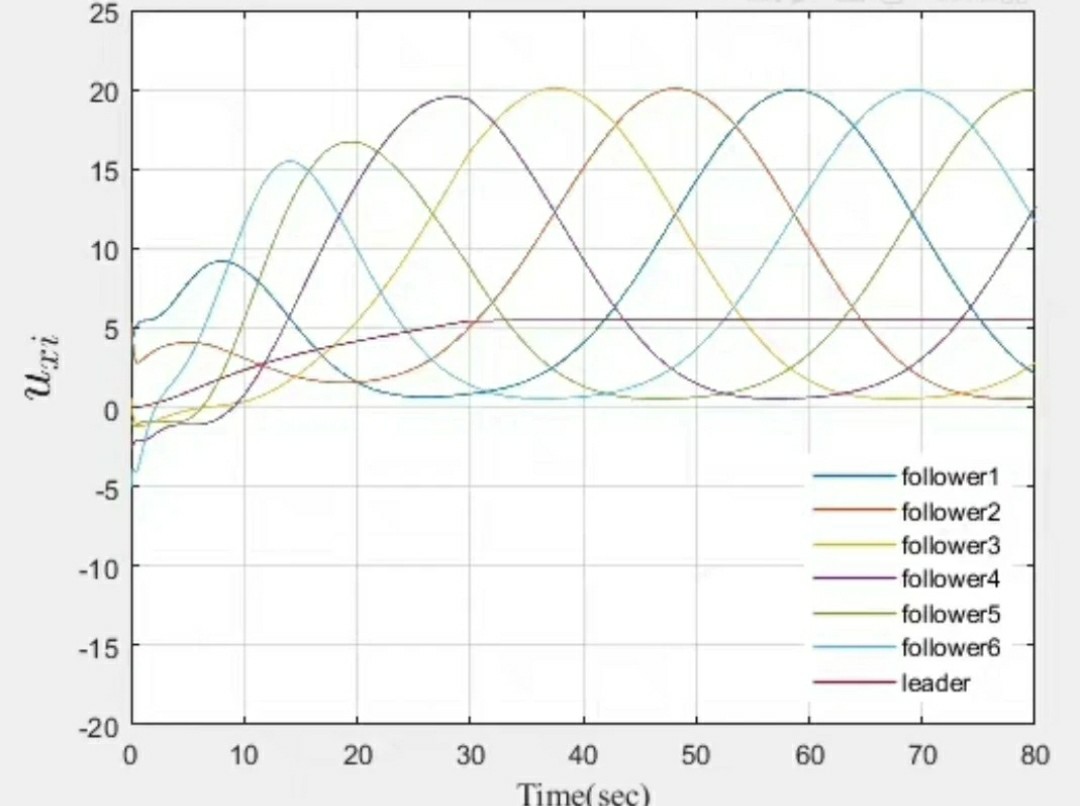
最近在研究一些关于多智能体编队的论文,发现不少都聚焦在模型预测控制这块。很多作者提出了精妙的算法来实现无人车、无人机、无人船艇的编队以及队形变换。而要真正将论文中的理论落地,MATLAB 就是一个超好用的工具啦。
比如说,论文里可能会给出复杂的数学模型来描述智能体之间如何协同保持编队和变换队形。咱要在 MATLAB 里复现,首先得把这些数学关系转化为代码。下面是一段简单的用于多智能体位置更新的 MATLAB 代码示例(这里简化处理,仅为示意):
matlab
% 定义智能体数量
numAgents = 5;
% 初始化智能体位置
agentPositions = zeros(numAgents, 2);
% 简单的位置更新规则
for i = 1:numAgents
agentPositions(i, 1) = agentPositions(i, 1) + randn; % x 方向随机更新
agentPositions(i, 2) = agentPositions(i, 2) + randn; % y 方向随机更新
end在这段代码里,我们先定义了智能体的数量,然后初始化它们的位置。接着通过一个循环,利用 randn 函数给每个智能体在 x 和 y 方向上随机地更新位置。这就像是给每个智能体赋予了一点点随机的"小步伐",让它们能在一定范围内移动。
二、编队控制的多样方法
- 强化学习
强化学习在编队控制中也发挥着巨大作用。它通过让智能体在环境中不断尝试、学习,以获得最优的控制策略。想象一下,每个无人车、无人机或无人船艇就像一个聪明的小探险家,在不断摸索中找到如何与小伙伴们紧密配合,保持编队和变换队形的最佳方法。
在实际实现中,我们可以利用 Q - learning 算法来实现强化学习控制。下面是一个简化的 Q - learning 伪代码示例:
python
# 初始化 Q 表
Q = np.zeros((num_states, num_actions))
# 定义学习率和折扣因子
alpha = 0.1
gamma = 0.9
for episode in range(num_episodes):
state = get_initial_state()
while not is_terminal(state):
action = choose_action(state, Q)
next_state, reward = take_action(action)
Q[state, action] = Q[state, action] + alpha * (reward + gamma * np.max(Q[next_state, :]) - Q[state, action])
state = next_state在这段伪代码里,我们首先初始化了 Q 表,它记录了在每个状态下采取不同行动的预期奖励。然后在每个 episode 中,智能体从初始状态开始,选择行动,根据采取行动后的奖励和下一个状态来更新 Q 表,逐步学习到最优策略。
- PID 控制
PID 控制那可是经典中的经典。在多智能体编队里,它可以用来稳定智能体的位置和速度,确保编队的稳定性。比如在无人车编队中,PID 控制器可以根据当前车辆与目标位置的偏差,实时调整车辆的速度和转向,让它紧紧跟随编队。
matlab
% 定义 PID 参数
Kp = 1;
Ki = 0.1;
Kd = 0.01;
% 初始化误差和积分项
prevError = 0;
integral = 0;
% 当前位置和目标位置
currentPosition = [1, 1];
targetPosition = [5, 5];
% 计算误差
error = targetPosition - currentPosition;
% 积分项更新
integral = integral + error;
% 微分项计算
derivative = error - prevError;
% 控制输出
controlOutput = Kp * error + Ki * integral + Kd * derivative;
prevError = error;这里我们定义了 PID 的三个参数 Kp、Ki、Kd,然后根据当前位置和目标位置计算误差,通过积分和微分计算出控制输出,用来调整智能体的状态。
三、Simulink 仿真验证
Simulink 对于验证多智能体编队控制算法简直是神器。我们可以搭建各种模型,模拟不同的场景。比如说,设置智能体数量变化的场景,看看我们的控制算法是否依然稳定。
在 Simulink 里,我们可以把每个智能体抽象为一个模块,连接它们之间的信号流,模拟信息交互。通过设置不同的参数,就可以轻松验证算法在不同条件下的性能。比如设置不同的干扰,观察编队是否能保持稳定,队形变换是否能顺利完成。
四、嵌入式应用的展望
当我们在 MATLAB 和 Simulink 里把算法玩得溜熟之后,就可以考虑将这些成果应用到嵌入式系统中啦。想象一下,让无人车、无人机、无人船艇真正在现实世界里按照我们设计的编队方式行动。这时候就需要把算法移植到嵌入式芯片上,结合硬件电路,实现真正的智能体控制。
总之,多智能体分布式模型预测控制在编队领域有着无限的可能,从理论研究到实际应用,每一步都充满了挑战与惊喜。希望大家都能在这个奇妙的领域里探索出属于自己的精彩。