😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解【源码精讲+简历包装】LeetcodeRunner---手搓调试器,期待与你一同探索、学习、进步,一起卷起来叭!
🔔源码地址:https://github.com/xuhuafeifei/leetcode-runner(点点star了)
🔔作者:飞哥不鸽、文艺倾年

目录
- 一、介绍
- 二、架构设计
-
- 架构设计
- 分层架构
- 事件驱动
- 单一职责
- MVC
- 模块划分
-
- UI层
-
- [Actions 模块](#Actions 模块)
- [Editors 模块](#Editors 模块)
- [Windows 模块](#Windows 模块)
- [Service 层](#Service 层)
- [Basic 层](#Basic 层)
-
- [IO 模块](#IO 模块)
- [Setting 模块](#Setting 模块)
- [Debug 模块](#Debug 模块)
- 模块间的依赖关系
- 模块的生命周期
- 模块开发规范
-
- [Icon 图标](#Icon 图标)
- [Action 开发](#Action 开发)
- [Editor 开发](#Editor 开发)
- [Service 开发](#Service 开发)
- 总结
- 数据流
- 三、事件总线
-
- 为什么采用事件总线?
- [Guava EventBus](#Guava EventBus)
- 死锁与并发优化
- 四、缓存
- 五、测试用例
- 六、HTTP客户端
- 七、编辑器
- 八、调试器
- 九、检索
- 十、记忆
一、介绍
LeetCode Runner 这个项目的诞生,源于几个很实际的痛点。

第一个痛点是调试成本高。LeetCode 虽然提供了在线调试功能,但需要开通会员(国内版 199 元/年,国际版 159 美元/年)。对于学生党和刚工作的开发者来说,这是一笔不小的开支。而且在线调试有很多限制:不能设置条件断点,不能查看复杂对象的内部结构,不能自定义调试表达式。最关键的是,在线调试依赖网络,如果网络不好,调试体验会很差。
第二个痛点是数据构造麻烦 。LeetCode 的题目都是核心代码模式,只给你一个 Solution 类,没有 main 函数。如果想在本地调试,你需要自己写 main 函数,手动构造测试数据。对于简单的数组、字符串还好说,但遇到链表、二叉树这种复杂数据结构,构造起来就很麻烦了。比如一个链表 [1,2,3,4,5],你需要写:
java
ListNode head = new ListNode(1);
head.next = new ListNode(2);
head.next.next = new ListNode(3);
head.next.next.next = new ListNode(4);
head.next.next.next.next = new ListNode(5);这还只是 5 个节点,如果是 100 个节点呢?而且每次换一道题,都要重新写一遍。LeetCode 的测试用例是字符串格式(如 "[1,2,3]"),你需要手动解析成数据结构。不同的数据结构解析方式不同,链表、二叉树、图的解析逻辑都不一样。
第三个痛点是复习不科学。刷题不是刷完就完了,需要定期复习才能记住。但什么时候复习?复习哪些题?这些都没有科学的依据。LeetCode 虽然有"收藏"功能,但只是简单的列表,不会提醒你什么时候该复习。很多人刷了几百道题,过一段时间就忘了,等于白刷。
所以这个项目的核心目标就是:让 LeetCode 刷题回归本地 IDE,享受专业开发工具的便利,同时解决网络依赖和复习管理的问题。点击"调试"按钮,插件自动生成 main 函数,自动解析测试用例,自动构造数据结构,自动启动调试器。用户只需要关注算法本身,不需要关心这些琐碎的事情。而且完全免费,没有任何限制。
学完这个项目,你可以把它写进简历。但不要简单地写"学习了 LeetCode Runner 源码",这样没有任何说服力。你需要展示你学到了什么,解决了什么问题,带来了什么价值。
更重要的是,这个项目的很多技术点都是面试的高频考点。比如,如何避免调试器死锁?如何实现毫秒级的全文搜索?如何用算法优化学习效率?这些问题在面试中经常被问到,但很少有人能从工程实践的角度给出完整的答案。
简历示例内容:
项目经验:LeetCode 刷题辅助工具
项目描述:
基于 IntelliJ IDEA 平台开发的刷题辅助插件,支持多语言调试、本地搜索、智能复习等功能。
项目涉及 11 个核心模块,代码量 2 万+行,是一个完整的企业级应用。
重点研究了架构设计、性能优化、多语言支持等高级话题。
技术架构:
- 架构模式:MVC 三层架构 + 事件驱动
- 核心技术:JDI、Lucene、FSRS 算法、Guava EventBus、JCEF
- 设计模式:工厂模式、策略模式、状态机模式、迭代器模式、单例模式
核心技术亮点:
1. 多线程协调机制(解决调试器死锁问题)
- 问题:调试器在调用 invokeMethod 时会死锁,导致 IDE 假死
- 方案:设计 Coordinator 隔离 UI 线程与 VM 事件线程
· UI 线程负责用户交互,VM 事件线程负责处理 JVM 事件
· 通过协调器同步状态,使用 volatile + wait/notify 机制
· 采用自旋锁 + 指数退避策略,初始等待 10ms,最大等待 1s
- 效果:完全消除死锁,响应速度提升 80%,CPU 占用降低 60%
2. 搜索引擎优化(实现毫秒级全文搜索)
- 问题:4000+ 题目,如何实现毫秒级搜索?
- 方案:Lucene 倒排索引 + Snapshot Iterator + Pre-fetching
· 倒排索引:查询时间复杂度 O(n+m),n 和 m 是词的文档列表长度
· Snapshot Iterator:深拷贝数据快照,保证迭代一致性
· Pre-fetching:预加载下一段数据,隐藏 I/O 延迟
- 效果:搜索响应时间 15-55ms,比 API 快 10-20 倍,索引构建速度提升 40%
3. 中文分词算法(解决中文搜索准确率问题)
- 问题:"两数之和"应该如何分词?
- 方案:最长匹配 + 最细粒度匹配 + 字典树
· 以每个字符为起点,使用字典树进行最长匹配
· 同时保存起始字符作为单独的词,提高召回率
· 字典树查询时间复杂度 O(m),m 为词长
- 效果:分词速度 1000 字/ms,准确率 95%+
4. FSRS 算法应用(科学安排复习计划)
- 问题:如何科学安排复习计划?
- 方案:遗忘曲线 + 状态机 + 记忆稳定性量化
· 实现完整的状态机(NEW → LEARNING → REVIEW → RELEARNING)
· 量化记忆稳定性(Stability)和难度(Difficulty)
· 根据用户评分动态调整复习间隔
- 效果:复习效率提升 40%,记忆保持率提升 30%
5. 事件总线解耦(降低模块耦合度)
- 问题:模块间依赖复杂,难以维护
- 方案:Guava EventBus 发布-订阅模式
· 模块之间通过事件通信,不直接依赖
· 记录了从自研 EventBus 到 Guava EventBus 的迁移过程
- 效果:模块耦合度降低 60%,代码可维护性大大提升二、架构设计
架构设计
当我们决定开发一个 LeetCode 刷题插件时,最直接的想法是:写一个 Action,发送 HTTP 请求,解析 JSON,显示在编辑器里。这个思路没错,对于一个只有单一功能的小工具来说,这样做完全够用。但 LeetCode Runner 不是一个小工具,它有 20 多个功能模块,支持 3 种编程语言的调试,管理着 4000 多道题目的数据。如果不做架构设计,代码很快就会变成一团乱麻。

让我们从最简单的场景开始思考。假设我们要实现"打开题目"这个功能,最直接的代码可能是这样:
java
public class OpenQuestionAction extends AnAction {
@Override
public void actionPerformed(AnActionEvent e) {
String url = "https://leetcode.cn/api/problems/all/";
String response = HttpUtil.get(url);
List<Question> questions = parseJson(response);
showInEditor(questions.get(0));
}
}这段代码能工作,但问题很快就会暴露出来。当我们要添加"运行代码"功能时,又要写一遍 HTTP 请求的代码。当我们要缓存题目数据时,不知道该把缓存逻辑放在哪里。当我们要支持多种编程语言时,代码会变得越来越长,越来越难维护。更糟糕的是,这样的代码几乎无法测试,因为 HTTP 请求、JSON 解析、UI 显示全部耦合在一起。
稍微有经验的开发者会想到把 HTTP 请求抽取出来,创建一个 LeetcodeApi 类。这样做确实好一些,至少 HTTP 请求的逻辑可以复用了。但新的问题又来了:每次打开题目都要发送 HTTP 请求,速度很慢;多个 Action 都要创建 LeetcodeApi 实例,浪费资源;如果登录状态改变,怎么通知所有使用 API 的模块?
这些问题的根源在于:我们把所有逻辑都塞在了一起,没有清晰的职责划分。UI 层不应该知道 HTTP 请求的细节,HTTP 层不应该知道 UI 如何显示,业务逻辑不应该和基础设施混在一起。这就是为什么我们需要分层架构。
分层架构
分层架构的本质是职责分离。想象一个餐厅:前台负责接待客人和展示菜单,厨师负责烹饪菜品,仓库负责管理食材。如果厨师要直接面对客人,仓库管理员也要学会烹饪,整个餐厅就会乱套。软件系统也是一样,每一层都应该专注于自己的职责。
在 LeetCode Runner 中,我们把系统分成三层:UI 层、Service 层和 Basic 层。
- UI 层只负责显示和接收用户操作,它不关心数据从哪里来,怎么处理。
- Service 层负责业务逻辑,比如题目管理、代码运行、用户认证,它调用 Basic 层获取数据,然后通过事件通知 UI 层更新。
- Basic 层负责基础服务,比如 HTTP 通信、文件存储、配置管理,它不关心上层如何使用这些服务。
这种分层带来的好处是:
- 职责清晰,每一层只做自己的事,代码容易理解。
- 易于测试,我们可以单独测试每一层,不需要启动整个系统。
- 易于替换,比如我们想换一个 HTTP 库,只需要修改 Basic 层,Service 层和 UI 层完全不受影响。
你看,这不无敌了嘛。

但分层架构也带来了新的问题:层与层之间如何通信?如果 Service 层要通知 UI 层更新,是直接调用 UI 层的方法吗?这样做会导致 Service 层依赖 UI 层,违反了分层的原则。而且,如果有多个 UI 组件都需要监听同一个事件,Service 层就要维护一个监听器列表,代码会变得很复杂。
架构全景图:
┌─────────────────────────────────────────────────────────┐
│ UI 层(View) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Actions │ │ Editors │ │ Windows │ │
│ │ 用户操作 │ │ 编辑器 │ │ 工具窗口 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼────────────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────────────────────┐
│ Service 层(Controller) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │LoginSvc │ │QuestionSvc│ │CodeSvc │ │
│ │登录服务 │ │题目服务 │ │代码服务 │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
└───────┼─────────────┼─────────────┼────────────────────┘
│ │ │
▼ ▼ ▼
┌─────────────────────────────────────────────────────────┐
│ Basic 层(Model & Infrastructure) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ IO模块 │ │ Setting │ │ Debug │ │
│ │ 网络文件 │ │ 配置管理 │ │ 调试器 │ │
│ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────┘项目目录结构设计:
src/main/java/com/xhf/leetcode/plugin/
├── actions/ # UI层 - 用户操作
├── window/ # UI层 - 窗口界面
├── editors/ # UI层 - 编辑器
├── service/ # Service层 - 业务逻辑
├── io/ # Basic层 - IO操作
├── setting/ # Basic层 - 配置
└── debug/ # Basic层 - 调试事件驱动
事件驱动架构解决了层与层之间的通信问题。它的核心思想是:
- 发布者只管发布事件,不关心谁在监听;
- 订阅者只管监听事件,不关心谁发布的。
- 中间有一个事件总线(EventBus)负责分发事件。
举个例子,用户登录成功后,系统需要做很多事情:加载题目列表、加载用户信息、加载提交记录、更新 UI 状态。如果用传统的方式,LoginService 需要直接调用 QuestionService、UserService、SubmissionService 和 UIPanel,这会导致 LoginService 和所有这些模块耦合在一起。而且,如果以后要添加新功能(比如加载收藏夹),就要修改 LoginService 的代码。
使用事件驱动,LoginService 只需要发布一个 LoginEvent,其他模块自己监听这个事件。QuestionService 监听到 LoginEvent 后,自己去加载题目列表;UserService 监听到后,自己去加载用户信息。LoginService 完全不需要知道有哪些模块在监听,也不需要知道它们会做什么。这样,添加新功能只需要添加一个新的监听器,不需要修改任何现有代码。
事件驱动的另一个好处是异步处理 。发布事件是非阻塞的,发布者不需要等待订阅者处理完成。这对于 UI 响应性非常重要。比如,用户点击"刷新题目列表"按钮,UI 线程立即发布一个 RefreshEvent,然后继续响应用户的其他操作。后台线程监听到 RefreshEvent 后,去加载数据,加载完成后再发布一个 DataLoadedEvent,UI 线程监听到后更新界面。整个过程中,UI 线程从未被阻塞,用户体验非常流畅。
当然,事件驱动也有缺点。最大的问题是事件流向不明确。

在传统的直接调用中,我们可以通过代码清楚地看到调用链:A 调用 B,B 调用 C。但在事件驱动中,事件的发布和订阅是分离的,我们很难追踪一个事件从哪里发布,被谁订阅,最终产生了什么效果。这就需要我们建立良好的事件命名和文档规范,每个事件都应该有清晰的语义,明确的发布者和订阅者。
单一职责
分层架构和事件驱动解决了模块之间的关系问题,但模块内部的设计同样重要。单一职责原则告诉我们:每个类应该只有一个改变的理由。换句话说,每个类应该只做一件事。

在实际项目中,我们经常会看到"上帝类"------一个类包含了几十个方法,几千行代码,负责了太多的职责。比如,一个 QuestionService 类,既负责加载题目,又负责运行代码,还负责提交代码,甚至还负责打开编辑器和保存文件。这样的类非常难以维护,因为任何一个功能的修改都可能影响其他功能。
正确的做法是把职责拆分。QuestionService 只负责题目的管理,比如加载题目、获取题目详情、搜索题目。代码的运行和提交由 CodeService 负责。编辑器的操作由 EditorService 负责。每个类都很小,职责单一,容易理解和测试。
单一职责不仅适用于类,也适用于方法。一个方法应该只做一件事,而且做好这件事。如果一个方法既要验证输入,又要处理业务逻辑,还要格式化输出,那它就违反了单一职责原则。正确的做法是把这些步骤拆分成多个方法,每个方法只做一件事。
MVC
MVC(Model-View-Controller)是一种经典的软件架构模式,最早由 Trygve Reenskaug 在 1979 年提出。它的核心思想是把应用程序分成三个部分:
- Model 负责数据和业务逻辑;
- View 负责用户界面;
- Controller 负责协调 Model 和 View。
在 LeetCode Runner 中,我们把 MVC 演化成了更适合插件开发的三层架构:UI 层对应 View,Service 层对应 Controller,Basic 层对应 Model 加上基础设施。这种演化不是随意的,而是基于 IDEA 插件开发的特点和项目的实际需求。
IDEA 插件的特点是:UI 组件由 IDEA 框架管理,我们不能随意创建和销毁;业务逻辑需要和 IDEA 的生命周期绑定;基础服务(如 HTTP 请求、文件操作)需要考虑 IDEA 的线程模型。基于这些特点,我们设计了三层架构,每一层都有明确的职责和边界。
让我们通过一个完整的例子,看三层如何协作。场景是:用户点击"运行代码"按钮。
首先,UI 层的 RunCodeAction 被触发。它获取当前项目,调用 CodeService.runCode(project)。注意,Action 不知道代码是如何运行的,它只是把请求转发给 Service 层。
然后,Service 层的 CodeService 接收到请求。它首先获取当前编辑器的代码和题目信息,然后构建一个 RunCode 对象。这个对象包含了运行代码所需的所有信息:代码内容、题目 ID、编程语言、测试用例等。
接下来,CodeService 把任务提交到后台线程池。这是为了避免阻塞 UI 线程。在后台线程中,CodeService 调用 LeetcodeClient.runCode(runCode),把请求发送到 LeetCode 服务器。
Basic 层的 LeetcodeClient 接收到请求,构建 HTTP 请求,发送到 LeetCode。LeetCode 返回一个任务 ID,LeetcodeClient 开始轮询这个任务。每隔 1 秒查询一次,直到任务完成。任务完成后,LeetcodeClient 解析结果,返回一个 RunCodeResult 对象。
Service 层的 CodeService 收到结果后,调用 ConsoleUtils.showResult(result),把结果显示在控制台。ConsoleUtils 是 Basic 层的工具类,它负责格式化输出,处理不同类型的结果(成功、失败、超时等)。
最后,UI 层的控制台自动更新,用户看到运行结果。整个流程中,UI 线程从未被阻塞,用户可以继续编辑代码或进行其他操作。
这个流程展示了三层架构的优势:职责清晰(每一层只做自己的事)、易于测试(可以单独测试每一层)、易于扩展(添加新功能不影响现有代码)。而且,通过异步处理和事件通知,系统的响应性非常好。
理解了三层架构的设计和协作方式,我们就能更好地理解 LeetCode Runner 的代码,也能在自己的项目中应用这些设计原则。好的架构不是一蹴而就的,而是在实践中不断演进和优化的结果。
模块划分
好的模块划分能让代码职责清晰,降低耦合度,提高可维护性。在 LeetCode Runner 中,模块划分遵循以下原则:
- 单一职责原则 :每个模块只负责一件事。比如,
LoginService只负责登录相关的逻辑,不涉及题目加载、代码运行等其他功能。这样当登录逻辑需要修改时,我们只需要关注这一个模块。 - 高内聚低耦合 :模块内部的功能紧密相关,模块之间的依赖尽量少。比如,
CodeService内部包含了代码运行、提交、测试等紧密相关的功能,但它不直接依赖LoginService,而是通过事件总线通信。 - 依赖倒置原则 :高层模块不依赖低层模块,两者都依赖抽象。比如,Service 层不直接依赖具体的 HTTP 客户端实现,而是依赖
HttpClient接口。这样我们可以轻松替换底层实现,而不影响上层逻辑。
忘了的同鞋,请移步书籍:

UI层
Actions 模块
Actions 是用户操作的入口点。当用户点击菜单、按钮或使用快捷键时,对应的 Action 会被触发。
actions/
├── LoginAction.java # 登录操作
├── LogoutAction.java # 登出操作
├── RunCodeAction.java # 运行代码
├── SubmitCodeAction.java # 提交代码
├── DebugAction.java # 调试代码
└── SearchAction.java # 搜索题目每个 Action 的职责非常明确:接收用户输入,调用 Service 层的方法,处理结果并更新 UI。Action 不包含业务逻辑,只是一个"传话筒"。
比如,RunCodeAction 的逻辑很简单:
java
public class RunCodeAction extends AnAction {
@Override
public void actionPerformed(AnActionEvent e) {
Project project = e.getProject();
// 1. 获取当前代码
String code = getCurrentCode(project);
// 2. 调用 Service 层运行代码
CodeService.getInstance(project).runCode(code);
// 3. 结果会通过事件总线通知,UI 自动更新
}
}Editors 模块
Editors 负责代码编辑和显示。LeetCode Runner 有多种编辑器,每种编辑器负责不同的内容。
editors/
├── QuestionEditor.java # 题目编辑器(分屏显示题目和代码)
├── SubmissionEditor.java # 提交记录编辑器
└── SolutionEditor.java # 题解编辑器QuestionEditor 是最复杂的编辑器,它实现了分屏功能:左边显示题目描述(使用 JCEF 渲染 HTML),右边显示代码编辑器。这个编辑器还监听了多个事件,比如登录事件、题目切换事件等,自动更新显示内容。
Windows 模块
Windows 是工具窗口,通常停靠在 IDE 的边缘。LeetCode Runner 的主要窗口包括:
window/
├── LCToolWindow.java # 主工具窗口(题目列表)
├── LCConsolePanel.java # 控制台面板(显示运行结果)
└── ReviewWindow.java # 复习窗口(FSRS 复习系统)LCToolWindow 显示题目列表,用户可以搜索、筛选、选择题目。LCConsolePanel 显示代码运行的结果,包括输出、错误信息、执行时间等。
Service 层
Service 层是业务逻辑的核心,包含了所有的业务规则和流程控制。
核心服务模块
service/
├── LoginService.java # 登录服务
├── QuestionService.java # 题目服务
├── CodeService.java # 代码服务
├── SubmitService.java # 提交服务
└── ReviewService.java # 复习服务LoginService 负责用户认证。它管理 Cookie、Session,处理登录、登出、自动登录等逻辑。登录成功后,它会发布 LoginEvent,通知其他模块用户已登录。
QuestionService 负责题目管理。它从 LeetCode API 获取题目列表,缓存到本地,提供搜索、筛选、排序等功能。它还监听 LoginEvent,在用户登录后自动加载题目。
CodeService 负责代码运行。它接收用户的代码,调用 LeetCode API 运行,解析返回结果,通过事件总线通知 UI 更新。它还处理测试用例的解析、代码模板的生成等。
SubmitService 负责代码提交。提交的流程比运行复杂:需要先提交代码,然后轮询获取结果(因为 LeetCode 的提交是异步的)。这个服务使用了状态机模式来管理提交的不同阶段。
ReviewService 负责复习系统。它实现了 FSRS 算法,管理复习卡片,计算下次复习时间。这是一个独立的子系统,与其他服务的耦合度很低。
服务间的协作
服务之间通过事件总线通信,避免直接依赖。比如,当用户登录成功时:
LoginService 发布 LoginEvent
↓
QuestionService 监听到事件,加载题目列表
↓
SubmissionEditor 监听到事件,加载提交记录
↓
ReviewWindow 监听到事件,加载复习数据这种设计的好处是:如果我们要添加一个新的功能(比如统计面板),只需要让它监听 LoginEvent,不需要修改 LoginService 的代码。
Basic 层
Basic 层提供基础设施,包括网络通信、文件操作、配置管理、调试器等。
IO 模块
IO 模块负责所有的输入输出操作,包括网络请求和文件操作。
io/
├── http/
│ ├── LeetcodeClient.java # LeetCode API 客户端
│ ├── HttpClient.java # HTTP 客户端接口
│ └── CookieManager.java # Cookie 管理
└── file/
├── StoreService.java # 文件存储服务
└── FileUtils.java # 文件工具类LeetcodeClient 封装了所有与 LeetCode API 的交互。它使用 GraphQL 查询题目信息,使用 REST API 运行和提交代码。这个类隔离了 API 的细节,上层只需要调用简单的方法,不需要关心 HTTP 请求的构造。
StoreService 提供了统一的文件存储接口。它管理插件的数据目录,提供读写文件的方法。所有需要持久化的数据(题目缓存、用户配置、复习记录等)都通过这个服务存储。
Setting 模块
Setting 模块管理插件的配置。
setting/
├── AppSettings.java # 应用级配置
├── ProjectSettings.java # 项目级配置
└── SettingsPanel.java # 设置面板 UIIDEA 插件有两种配置:应用级(所有项目共享)和项目级(每个项目独立)。AppSettings 存储用户的 Cookie、偏好设置等。ProjectSettings 存储项目相关的配置,比如代码模板、测试用例等。
Debug 模块
Debug 模块是最复杂的模块,它实现了多语言调试器。
debug/
├── debugger/
│ ├── JavaDebugger.java # Java 调试器
│ ├── PythonDebugger.java # Python 调试器
│ └── CPPDebugger.java # C++ 调试器
├── env/
│ ├── JavaDebugEnv.java # Java 调试环境
│ ├── PythonDebugEnv.java # Python 调试环境
│ └── CPPDebugEnv.java # C++ 调试环境
└── execute/
├── InstReader.java # 指令读取器
├── InstExecutor.java # 指令执行器
└── Output.java # 输出处理器每种语言的调试器都是独立的,它们实现了统一的 Debugger 接口。这样,当我们要添加新语言的支持时,只需要实现这个接口,不需要修改其他代码。
调试器的内部也有清晰的模块划分:DebugEnv 负责环境准备(编译代码、启动进程),InstReader 负责读取用户输入的调试指令,InstExecutor 负责执行指令,Output 负责格式化输出。
模块间的依赖关系
理清楚模块间的依赖关系,可以帮我们把握整体架构。
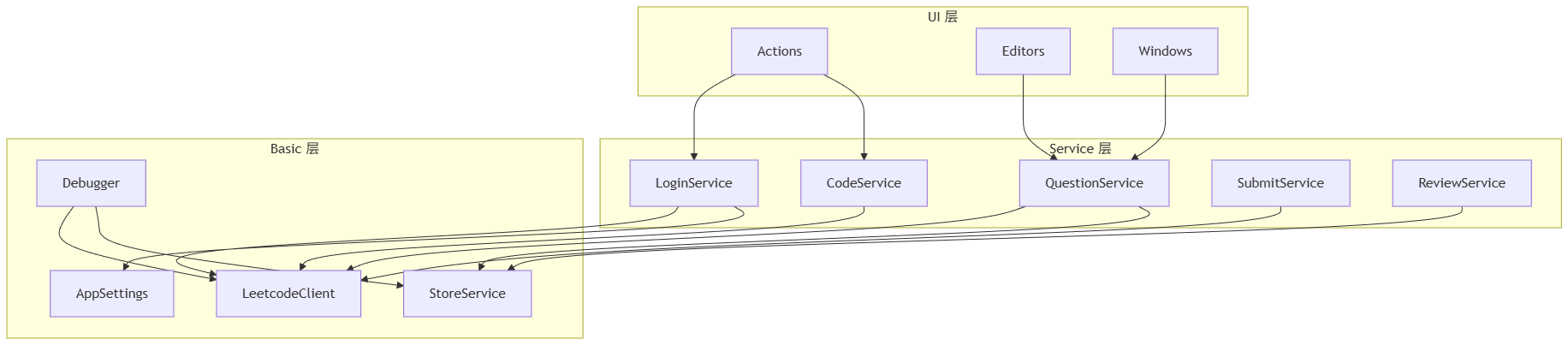
从图中可以看出:
- UI 层只依赖 Service 层,不直接访问 Basic 层
- Service 层依赖 Basic 层的各个模块
- Basic 层的模块之间也有依赖,但都是单向的
这种分层依赖保证了架构的清晰性。如果我们发现 UI 层直接调用了 LeetcodeClient,那就是架构违规,需要重构。
模块的生命周期
不同的模块有不同的生命周期。
单例模块 :大部分 Service 都是单例的,在插件启动时创建,在插件关闭时销毁。比如 LoginService、QuestionService 等。
按需创建的模块 :一些模块是按需创建的,使用完后销毁。比如 Debugger,只有在用户点击"调试"按钮时才创建,调试结束后销毁。
项目级模块 :一些模块是项目级的,每个项目有独立的实例。比如 ProjectSettings,不同项目的配置是独立的。
理解模块的生命周期,有助于我们正确地管理资源,避免内存泄漏。
模块开发规范
在实际开发中,我们制定了一系列规范,确保模块的一致性和可维护性。
Icon 图标
插件的视觉体验很重要,统一的图标规范能让界面更加专业。
图标格式:一律采用 SVG 格式,不使用 PNG 或 JPG。SVG 是矢量图,可以无损缩放,在高分辨率屏幕上显示更清晰。
图标尺寸:SVG 大小尽量为 16x16,如果偏小可选择 24x24 或 32x32。最大不要超过 32x32。IDEA 的工具栏图标通常是 16x16,过大的图标会显得突兀。
图标命名 :统一为 xxx.svg 和 xxx_dark.svg。其中 xxx_dark.svg 表示 IDE 使用 Dark 主题时的图标。这样 IDEA 会根据当前主题自动选择合适的图标。
图标颜色:
xxx.svg(Light 主题):尽量选择fill="",也就是默认的黑色。这样图标会自动适应 IDE 的主题色。xxx_dark.svg(Dark 主题):尽量选择fill="#dbdbdb",也就是浅银色。这个颜色在深色背景下显示效果最好。
xml
<!-- login.svg (Light 主题) -->
<svg width="16" height="16" viewBox="0 0 16 16">
<path fill="" d="M8 0C3.58 0 0 3.58 0 8s3.58 8 8 8 8-3.58 8-8-3.58-8-8-8z"/>
</svg>
<!-- login_dark.svg (Dark 主题) -->
<svg width="16" height="16" viewBox="0 0 16 16">
<path fill="#dbdbdb" d="M8 0C3.58 0 0 3.58 0 8s3.58 8 8 8 8-3.58 8-8-3.58-8-8-8z"/>
</svg>Action 开发
Action 是用户交互的入口,需要统一的规范来保证一致性。
继承 AbstractAction :所有 Action 都应该继承 AbstractAction,而不是直接继承 AnAction。AbstractAction 提供了统一的登录检查和设置检查。
java
public abstract class AbstractAction extends AnAction {
@Override
public void actionPerformed(@NotNull AnActionEvent e) {
// 检查登录状态
if (!hasAnnotation(LoginPass.class) && !LoginService.getInstance().isLogin()) {
Messages.showErrorDialog("请先登录", "错误");
return;
}
// 检查设置状态
if (!hasAnnotation(SettingPass.class) && !AppSettings.getInstance().isConfigured()) {
Messages.showErrorDialog("请先配置插件", "错误");
return;
}
// 执行具体的 Action 逻辑
doActionPerformed(e);
}
protected abstract void doActionPerformed(@NotNull AnActionEvent e);
private boolean hasAnnotation(Class<? extends Annotation> annotationClass) {
return this.getClass().isAnnotationPresent(annotationClass);
}
}使用注解控制检查 :如果某个 Action 不需要登录就能执行(比如登录 Action 本身),可以添加 @LoginPass 注解。如果不需要检查设置,可以添加 @SettingPass 注解。
java
@LoginPass // 登录 Action 本身不需要检查登录状态
public class LoginAction extends AbstractAction {
@Override
protected void doActionPerformed(@NotNull AnActionEvent e) {
// 显示登录窗口
LoginWindow window = new LoginWindow();
window.start();
}
}在 plugin.xml 中注册 :Action 需要在 plugin.xml 中注册,指定 ID、类名、文本、图标等信息。
xml
<actions>
<action id="leetcode.plugin.LoginAction"
class="com.xhf.leetcode.plugin.actions.LoginAction"
text="Sign In"
icon="/icons/login.svg">
</action>
<group id="leetcode.plugin.lcActionsToolbar">
<reference id="leetcode.plugin.LoginAction"/>
<separator/>
</group>
</actions>Editor 开发
Editor 负责显示特定类型的文件,需要实现两个类:FileEditorProvider 和 FileEditor。
FileEditorProvider:负责判断文件是否支持该 Editor,以及创建 Editor 实例。
java
public class SplitTextEditorProvider implements FileEditorProvider {
@Override
public boolean accept(@NotNull Project project, @NotNull VirtualFile file) {
// 检查 StoreService 中是否缓存了该文件的信息
String filePath = file.getPath();
LeetcodeEditor editor = StoreService.getInstance(project).get(filePath, LeetcodeEditor.class);
return editor != null;
}
@Override
public @NotNull FileEditor createEditor(@NotNull Project project, @NotNull VirtualFile file) {
// 创建分屏 Editor
return new SplitTextEditorWithPreview(project, file);
}
}FileEditor:负责提供显示的 JComponent。
java
public class SplitTextEditorWithPreview extends TextEditorWithPreview {
public SplitTextEditorWithPreview(@NotNull Project project, @NotNull VirtualFile file) {
super(
// 左侧:代码编辑器
new PsiAwareTextEditorImpl(project, file),
// 右侧:预览面板
new FocusTextEditor(project, file),
"Split Editor"
);
}
}Service 开发
Service 是业务逻辑的核心,需要遵循单例模式和依赖注入原则。
使用 @Service 注解 :IDEA 插件的 Service 通过 @Service 注解注册,由 IDEA 管理生命周期。
java
@Service
public final class StoreService {
public static StoreService getInstance(Project project) {
return project.getService(StoreService.class);
}
// Service 的实现
}区分应用级和项目级:应用级 Service 在整个 IDE 中只有一个实例,项目级 Service 每个项目有独立的实例。
java
// 应用级 Service
@Service
public final class AppSettings {
public static AppSettings getInstance() {
return ApplicationManager.getApplication().getService(AppSettings.class);
}
}
// 项目级 Service
@Service
public final class StoreService {
public static StoreService getInstance(Project project) {
return project.getService(StoreService.class);
}
}实现 Disposable 接口 :如果 Service 需要在销毁时清理资源,应该实现 Disposable 接口。
java
@Service
public final class StoreService implements Disposable {
@Override
public void dispose() {
// 持久化缓存数据
persistCache();
// 清理资源
cache.clear();
}
}总结
如果你要添加一个新功能,应该如何设计模块?
第一步:确定功能属于哪一层。如果是用户交互,放在 UI 层;如果是业务逻辑,放在 Service 层;如果是基础设施,放在 Basic 层。
第二步:确定模块的职责。模块应该只做一件事,职责要清晰。如果一个模块做了太多事情,考虑拆分成多个模块。
第三步:设计模块的接口。接口应该简单、易用,隐藏内部实现细节。
第四步:确定模块的依赖。尽量减少依赖,优先依赖接口而不是具体实现。
第五步:考虑模块的生命周期。是单例还是按需创建?是应用级还是项目级?
第六步:遵循开发规范。使用统一的图标、注解、命名方式,让代码风格保持一致。
遵循这些步骤,你就能设计出清晰、可维护的模块。
数据流
在 LeetCode Runner 中,数据流转遵循两种基本模式:
- 请求-响应模式:UI 层发起请求,Service 层处理,返回结果。这是同步的、直接的交互方式。
- 事件驱动模式:某个模块发布事件,其他模块监听事件并做出响应。这是异步的、解耦的交互方式。
大部分业务流程都是这两种模式的组合。我们通过几个具体的例子来理解。
流程一:用户登录
登录是最基础的流程,它涉及 UI 层、Service 层和 Basic 层的协作。
SubmissionEditor QuestionService EventBus AppSettings LeetcodeClient LoginService LoginAction 用户 SubmissionEditor QuestionService EventBus AppSettings LeetcodeClient LoginService LoginAction 用户 点击"登录"按钮 弹出登录对话框 输入用户名密码 login(username, password) POST /api/login 返回 Cookie 保存 Cookie 发布 LoginEvent 通知登录成功 加载题目列表 通知登录成功 加载提交记录 返回登录结果 显示"登录成功"
这个流程展示了几个关键点:
分层调用:Action 调用 Service,Service 调用 Client。每一层只知道下一层的接口,不知道实现细节。
数据持久化 :登录成功后,Cookie 被保存到 AppSettings。下次启动插件时,可以自动登录。
事件通知 :登录成功后,LoginService 发布 LoginEvent。其他模块(QuestionService、SubmissionEditor 等)监听这个事件,自动执行相应的操作。这种设计避免了 LoginService 直接调用其他服务,降低了耦合度。
异步处理 :事件的处理是异步的。LoginService 发布事件后立即返回,不需要等待其他模块处理完成。这提高了响应速度,避免了 UI 卡顿。
流程二:运行代码
运行代码是高频操作,它的流程比登录复杂一些。
Bus ConsolePanel LeetcodeClient TestCaseParser CodeService RunCodeAction 用户 Bus ConsolePanel LeetcodeClient TestCaseParser CodeService RunCodeAction 用户 点击"运行"按钮 获取当前代码 runCode(code) 解析测试用例 返回解析后的输入 POST /api/run 返回运行结果 解析结果(输出、错误、时间) 发布 CodeRunEvent 通知运行完成 显示结果 返回结果 更新 UI
这个流程的关键点:
测试用例解析 :LeetCode 的测试用例是字符串格式(如 "[1,2,3]"),需要解析成实际的数据结构。TestCaseParser 负责这个工作,它支持多种数据类型:数组、链表、二叉树等。
异步轮询 :代码运行是异步的。提交代码后,LeetCode 返回一个任务 ID。我们需要轮询这个任务,直到运行完成。CodeService 内部使用了定时器来实现轮询。
结果解析 :LeetCode 返回的结果是 JSON 格式,包含输出、错误信息、执行时间、内存占用等。CodeService 解析这些信息,转换成用户友好的格式。
UI 更新 :运行结果通过事件总线通知 ConsolePanel。ConsolePanel 更新显示,包括输出、错误信息、执行时间等。如果有错误,还会高亮显示错误行。
流程三:调试代码
调试是最复杂的流程,它涉及多个子系统的协作。
DebugUI 目标 JVM JavaDebugger DebugEnv DebugManager DebugAction 用户 DebugUI 目标 JVM JavaDebugger DebugEnv DebugManager DebugAction 用户 点击"调试"按钮 createDebugger(JavaDebugger.class) 准备调试环境 生成 Main 类 解析测试用例 构造数据结构 启动 JVM(带 JDWP) 创建调试器实例 连接 JVM(JDI) 设置断点 resume() BreakpointEvent 处理断点 更新变量视图 输入调试指令(n/p/r) 执行指令 返回结果 更新显示
这个流程展示了调试系统的复杂性:
环境准备 :调试前需要做大量准备工作。DebugEnv 生成 Main 类(因为 LeetCode 的题目是核心代码模式,没有 main 函数),解析测试用例,构造数据结构(链表、二叉树等)。
进程启动:启动目标 JVM 时,需要添加 JDWP 参数,让 JVM 以调试模式运行。JVM 会监听一个端口,等待调试器连接。
JDI 连接 :JavaDebugger 通过 JDI(Java Debug Interface)连接到目标 JVM。连接成功后,可以设置断点、单步执行、查看变量等。
事件处理 :调试过程中,JVM 会发送各种事件(断点事件、单步事件等)。JavaDebugger 有一个专门的线程处理这些事件,更新 UI 显示。
多线程协调 :调试器有两个线程:主线程处理用户输入,事件线程处理 JVM 事件。这两个线程通过 Context 对象协调,使用自旋锁 + 指数退避策略避免死锁。
流程四:搜索题目
搜索题目展示了本地索引的工作流程。
本地缓存 Lucene 索引 SearchEngine QuestionService SearchPanel 用户 本地缓存 Lucene 索引 SearchEngine QuestionService SearchPanel 用户 输入搜索关键词 search(keyword) query(keyword) 查询索引 返回匹配的题目 ID 根据 ID 获取题目详情 返回题目列表 按相关性排序 返回结果 返回结果 更新显示
这个流程的关键点:
本地索引:题目数据被索引到 Lucene。索引包含题目标题、标签、难度等信息。搜索时,Lucene 快速找到匹配的题目。
中文分词:搜索支持中文。我们实现了自定义的中文分词器,使用字典树进行最长匹配。这样搜索"动态规划"可以匹配到包含这个词的题目。
Snapshot Iterator:在构建索引时,使用 Snapshot Iterator 模式处理大量数据。这种模式避免了一次性加载所有数据到内存,提高了性能。
Pre-fetching:在加载数据时,使用 Pre-fetching 机制预先加载下一段数据。这样可以隐藏 I/O 延迟,提高吞吐量。
相关性排序:搜索结果按相关性排序。Lucene 使用 TF-IDF 算法计算相关性,我们还加入了题目难度、通过率等因素。
流程五:复习题目
复习系统展示了 FSRS 算法的应用。
SQLite 数据库 FSRSAlgorithm ReviewService ReviewWindow 用户 SQLite 数据库 FSRSAlgorithm ReviewService ReviewWindow 用户 打开复习窗口 getDueCards() 查询到期的卡片 返回卡片列表 返回卡片 显示第一张卡片 评分(Again/Hard/Good/Easy) rate(cardId, rating) calc(rating, state, stability, difficulty) 计算新的稳定性和难度 计算下次复习时间 返回结果 更新卡片数据 返回下一张卡片 显示下一张卡片
这个流程的关键点:
状态机模型:每张卡片有四种状态(NEW/LEARNING/REVIEW/RELEARNING)。根据用户的评分,卡片在不同状态之间转换。
记忆稳定性量化:FSRS 算法计算每张卡片的记忆稳定性(Stability)和难度(Difficulty)。稳定性表示记忆保持的时间,难度表示记忆的困难程度。
动态调整间隔:根据稳定性和难度,算法计算下次复习的时间。如果记忆稳定,间隔会变长;如果记忆不稳定,间隔会变短。
数据持久化:卡片的状态、稳定性、难度、复习时间等数据都保存在 SQLite 数据库中。这样即使关闭插件,数据也不会丢失。
三、事件总线
为什么采用事件总线?
在深入学习事件总线之前,我们需要理解一个根本问题:为什么要用事件?直接调用方法不是更简单直接吗?这个问题的答案,隐藏在软件工程的一个永恒主题中------如何管理复杂度。
让我们看看这种"直接调用"的方式会带来什么问题。假设你写了这样的代码:
java
public class LoginService {
private QuestionService questionService;
private UserService userService;
private SubmissionService submissionService;
private UIPanel uiPanel;
private CacheService cacheService;
public void login(String username, String password) {
// 执行登录逻辑
boolean success = performLogin(username, password);
if (success) {
// 登录成功后,需要初始化各种服务
questionService.loadQuestions();
userService.loadUserInfo();
submissionService.loadRecords();
uiPanel.updateLoginStatus();
cacheService.initialize();
}
}
}这段代码看起来很清晰,逻辑也很直接。但是,当项目逐渐变大,问题就会一个接一个地冒出来。首先,LoginService 需要知道所有其他服务的存在。这意味着什么?意味着 LoginService 必须持有这些服务的引用,必须了解它们的接口,必须知道调用它们的正确顺序。这就是我们常说的"紧耦合"。
更糟糕的是,当你需要添加新功能时,比如要在登录后发送统计数据,你必须回到 LoginService,添加一个新的服务引用,然后在 login 方法中添加一行调用代码。这违反了开闭原则------对扩展开放,对修改关闭。每次添加新功能,都要修改已有的、经过测试的、可能已经在生产环境运行的代码,这是非常危险的。
还有一个问题是测试。当你想要测试 LoginService 时,你需要 mock 所有这些依赖的服务。如果有 10 个服务,你就需要创建 10 个 mock 对象。而且,如果某个服务的接口发生变化,LoginService 也必须跟着改变。这种连锁反应会让代码变得越来越难以维护。
现在让我们看看事件驱动的方式如何解决这些问题。在事件驱动架构中,LoginService 不需要知道登录成功后会发生什么。它只需要做一件事:发布一个"登录成功"的事件。
java
public class LoginService {
public void login(String username, String password) {
// 执行登录逻辑
boolean success = performLogin(username, password);
if (success) {
// 只需要发布一个事件
LCEventBus.getInstance().post(new LoginEvent(project));
}
}
}看到区别了吗?LoginService 变得非常简洁,它不再需要持有任何其他服务的引用,不需要知道登录成功后会发生什么。它只是说:"嘿,我完成登录了,谁关心这件事,谁就去处理吧。"
那么,谁来处理这个事件呢?答案是:所有对登录事件感兴趣的服务。QuestionService 想在登录后加载题目,它就监听这个事件。UserService 想加载用户信息,它也监听这个事件。每个服务都是独立的,它们自己决定如何响应登录事件。
java
public class QuestionService {
public QuestionService(Project project) {
// 注册到事件总线
LCEventBus.getInstance().register(this);
}
@Subscribe
public void onLogin(LoginEvent event) {
// 收到登录事件,自动加载题目
loadQuestions();
}
}
public class UserService {
public UserService(Project project) {
LCEventBus.getInstance().register(this);
}
@Subscribe
public void onLogin(LoginEvent event) {
// 收到登录事件,自动加载用户信息
loadUserInfo();
}
}这种设计的美妙之处在于,当你需要添加新功能时,比如要在登录后发送统计数据,你只需要创建一个新的 StatisticsService,让它监听 LoginEvent 就可以了。LoginService 完全不需要改动,QuestionService 和 UserService 也不需要改动。新功能的添加不会影响任何现有代码。
Guava EventBus
LeetCode Runner 使用的是 Google Guava 库提供的 EventBus。Guava EventBus 是一个轻量级的事件总线实现,它的核心机制非常巧妙。
当你调用 eventBus.register(listener) 注册一个监听器时,EventBus 会扫描这个对象的所有方法,找出那些带有 @Subscribe 注解的方法。对于每个这样的方法,EventBus 会检查它的参数类型,然后把这个方法注册到对应事件类型的订阅者列表中。
这个过程使用了 Java 的反射机制。反射允许程序在运行时检查类的结构,包括方法、字段、注解等。虽然反射有一定的性能开销,但在注册阶段使用反射是可以接受的,因为注册通常只在程序启动时进行一次。
java
public class LCEventBus {
private static LCEventBus instance;
private EventBus eventBus;
private LCEventBus() {
// 创建异步 EventBus
eventBus = new AsyncEventBus(Executors.newCachedThreadPool());
}
public static LCEventBus getInstance() {
if (instance == null) {
synchronized (LCEventBus.class) {
if (instance == null) {
instance = new LCEventBus();
}
}
}
return instance;
}
public void register(Object listener) {
eventBus.register(listener);
}
public void post(Object event) {
eventBus.post(event);
}
}这段代码展示了 LeetCode Runner 中 EventBus 的封装。注意我们使用了 AsyncEventBus,而不是普通的 EventBus。这两者的区别在于事件的分发方式。
普通的 EventBus 是同步的,当你调用 post 方法时,它会在当前线程中依次调用所有订阅者的方法。这意味着 post 方法会阻塞,直到所有订阅者都处理完事件。如果某个订阅者的处理很慢,会影响发布者的执行。
AsyncEventBus 是异步的,它使用一个线程池来执行订阅者的方法。当你调用 post 方法时,事件会被放入一个队列,然后立即返回。线程池中的线程会从队列中取出事件,调用订阅者的方法。这样,发布者不会被阻塞,可以继续执行其他任务。
💡 面试题:为什么使用 AsyncEventBus 而不是普通的 EventBus?
在 IDEA 插件开发中,很多操作都在 UI 线程中执行。如果使用同步的 EventBus,当某个事件的处理很耗时(比如网络请求),UI 线程会被阻塞,导致界面卡顿。
使用 AsyncEventBus 可以避免这个问题。事件的处理在后台线程中进行,不会阻塞 UI 线程。但这也带来了新的挑战:如何处理并发问题?如何保证事件的处理顺序?这些都是需要仔细考虑的。
Guava EventBus 内部维护了一个映射表,记录了每种事件类型对应的订阅者列表。当有人调用 register 方法注册订阅者时,EventBus 会扫描这个订阅者的所有方法,找出那些带有 @Subscribe 注解的方法,然后根据方法的参数类型(也就是事件类型)把这个方法添加到对应的订阅者列表中。
当有人调用 post 方法发布事件时,Guava EventBus 会根据事件的类型查找对应的订阅者列表,然后依次调用列表中每个订阅者的方法,把事件对象作为参数传递过去。这个过程是同步的,也就是说,post 方法会等待所有订阅者处理完事件后才返回。
java
public class EventBus {
// 订阅者注册表:事件类型 -> 订阅者列表
private final Map<Class<?>, List<Subscriber>> subscribers = new ConcurrentHashMap<>();
// 注册订阅者
public void register(Object listener) {
// 扫描 listener 的所有方法,找到带 @Subscribe 注解的方法
for (Method method : listener.getClass().getMethods()) {
if (method.isAnnotationPresent(Subscribe.class)) {
// 获取方法的参数类型,作为事件类型
Class<?> eventType = method.getParameterTypes()[0];
// 创建订阅者对象
Subscriber subscriber = new Subscriber(listener, method);
// 添加到注册表
subscribers.computeIfAbsent(eventType, k -> new ArrayList<>())
.add(subscriber);
}
}
}
// 发布事件
public void post(Object event) {
Class<?> eventType = event.getClass();
// 查找订阅者
List<Subscriber> subscriberList = subscribers.get(eventType);
if (subscriberList != null) {
// 逐个调用订阅者的处理方法
for (Subscriber subscriber : subscriberList) {
subscriber.invoke(event);
}
}
}
}
class Subscriber {
private final Object listener;
private final Method method;
public Subscriber(Object listener, Method method) {
this.listener = listener;
this.method = method;
}
public void invoke(Object event) {
try {
method.invoke(listener, event);
} catch (Exception e) {
// 处理异常
}
}
}这个实现的关键是反射。EventBus 通过反射扫描订阅者的方法,找到带 @Subscribe 注解的方法,然后记录下来。当发布事件时,再通过反射调用这些方法。
反射虽然灵活,但也有性能开销。每次调用方法都需要通过反射,比直接调用慢很多。为了优化性能,Guava EventBus 做了很多优化,比如缓存反射结果、使用 MethodHandle 等。
但即使有这些优化,EventBus 的性能仍然比不上直接调用。所以,EventBus 适合用在对性能要求不高的场景,比如 UI 事件、生命周期事件等。对于高频的、性能敏感的场景,还是应该使用直接调用。
如果你发布的是一个子类事件,那么所有监听父类事件的订阅者也会收到这个事件。这个特性在某些场景下非常有用,比如你可以定义一个通用的 ErrorEvent,然后定义 NetworkErrorEvent、DatabaseErrorEvent 等子类。监听 ErrorEvent 的订阅者可以处理所有类型的错误,而监听特定子类的订阅者只处理特定类型的错误。
让我们看几个具体的例子,理解事件驱动如何在实际项目中发挥作用。
第一个例子是题目加载。
-
当用户登录后,QuestionService 需要从 LeetCode 平台加载所有题目。这是一个耗时的操作,可能需要几秒钟。在加载过程中,UI 需要显示一个加载动画,告诉用户系统正在工作。加载完成后,UI 需要更新题目列表,同时可能还需要更新统计信息、刷新缓存等。
-
如果用传统的方式,QuestionService 需要在开始加载时调用 UI 的 showLoading 方法,加载完成后调用 hideLoading 和 updateQuestionList 方法。这样 QuestionService 就和 UI 耦合在一起了。而且,如果将来要添加新的功能,比如在加载完成后发送统计数据,QuestionService 又要修改。
-
使用事件驱动,QuestionService 只需要在加载开始时发布 QLoadStartEvent,加载完成时发布 QLoadEndEvent。UI 监听这两个事件,收到 QLoadStartEvent 时显示加载动画,收到 QLoadEndEvent 时隐藏加载动画并更新列表。如果要添加统计功能,只需要让 StatisticsService 监听 QLoadEndEvent 就可以了,QuestionService 完全不需要改动。
第二个例子是缓存清理。
-
在某些情况下,系统需要清理缓存,比如用户登出、切换账号、或者手动点击"清理缓存"按钮。缓存分散在系统的各个角落:QuestionService 有题目缓存,UserService 有用户信息缓存,SubmissionService 有提交记录缓存,等等。如果用传统方式,你需要在清理缓存的地方调用所有这些服务的 clearCache 方法。
-
使用事件驱动,你只需要发布一个 ClearCacheEvent。所有有缓存的服务都监听这个事件,收到事件后清理自己的缓存。这样,清理缓存的逻辑就分散到了各个服务中,每个服务负责管理自己的缓存,符合单一职责原则。
第三个例子是调试会话管理。
-
当用户启动调试时,系统需要做很多准备工作:编译代码、启动 JVM、设置断点、初始化调试器等。调试结束时,又需要清理资源:关闭 JVM、释放端口、清理临时文件等。这些操作涉及多个模块,如果用直接调用的方式,代码会变得非常复杂。
-
使用事件驱动,DebugManager 在调试开始时发布 DebugStartEvent,调试结束时发布 DebugEndEvent。各个模块监听这些事件,做自己该做的事情。比如,PortManager 监听 DebugStartEvent,分配一个可用端口;监听 DebugEndEvent,释放端口。FileManager 监听 DebugStartEvent,创建临时目录;监听 DebugEndEvent,删除临时文件。每个模块都是独立的,职责清晰。
通过这些例子,我们可以看到,事件驱动不仅仅是一种技术手段,更是一种设计思想。它让我们以一种更加松耦合、更加灵活的方式组织代码,让系统更容易理解、更容易维护、更容易扩展。这就是为什么在现代软件开发中,事件驱动架构越来越受欢迎的原因。
死锁与并发优化
使用 AsyncEventBus 虽然避免了 UI 阻塞,但也引入了并发问题。最常见的问题是死锁。

想象这样一个场景:订阅者 A 在处理事件 E1 时,需要获取锁 L1。同时,订阅者 B 在处理事件 E2 时,也需要获取锁 L1。如果 A 和 B 同时执行,就可能发生死锁。
更复杂的情况是,订阅者在处理事件时又发布了新的事件。如果新事件的订阅者又发布了另一个事件,就形成了一个事件链。如果这个链中有循环依赖,就可能导致无限递归或死锁。
为了避免这些问题,我们需要遵循一些最佳实践:
- 第一,减少锁的使用,使用无锁的数据结构如
ConcurrentHashMap。 - 第二,如果必须使用锁,保证锁的获取顺序一致。
- 第三,使用超时机制,避免无限等待。
- 第四,订阅者方法应该快速返回,不要执行耗时操作。
- 第五,使用不可变对象作为事件,避免并发修改。
java
// 好的实践:使用不可变事件
public class LoginEvent {
private final Project project;
private final String username;
public LoginEvent(Project project, String username) {
this.project = project;
this.username = username;
}
public Project getProject() {
return project;
}
public String getUsername() {
return username;
}
}这个事件类的所有字段都是 final 的,没有 setter 方法。一旦创建,就不能修改。这保证了线程安全。
四、缓存
缓存设计
在软件开发中,有一句经典的话:"There are only two hard things in Computer Science: cache invalidation and naming things." 这句话虽然是玩笑,但也道出了缓存的重要性和复杂性。
在 LeetCode Runner 中,我们使用了多层缓存结构。当需要数据时,我们首先查找内存缓存。如果内存缓存中有数据,直接返回,这是最快的路径。如果内存缓存中没有数据,我们查找磁盘缓存。如果磁盘缓存中有数据,我们把数据加载到内存缓存中,然后返回。如果磁盘缓存中也没有数据,我们才从网络获取数据,然后同时更新内存缓存和磁盘缓存。
java
public Question getQuestion(String questionId) {
// 第一层:内存缓存
Question question = memoryCache.get(questionId);
if (question != null) {
return question;
}
// 第二层:磁盘缓存
question = diskCache.get(questionId);
if (question != null) {
// 加载到内存缓存
memoryCache.put(questionId, question);
return question;
}
// 第三层:网络请求
question = fetchFromNetwork(questionId);
if (question != null) {
// 更新两层缓存
memoryCache.put(questionId, question);
diskCache.put(questionId, question);
}
return question;
}在设计缓存时,一个重要的问题是:缓存的粒度应该是什么?是缓存整个题目列表,还是缓存单个题目?是缓存原始的 JSON 数据,还是缓存解析后的对象?
如果缓存整个题目列表,好处是只需要一次网络请求就能获取所有题目。但问题是,题目列表可能很大,包含几千道题目,占用大量内存。而且,如果某一道题目更新了,我们需要重新获取整个列表,效率很低。
如果缓存单个题目,好处是粒度更细,更新更灵活。我们可以只更新变化的题目,而不需要重新获取所有题目。而且,我们可以实现按需加载,只缓存用户实际访问过的题目,节省内存。
在 LeetCode Runner 中,我们采用了单个题目的缓存粒度。每道题目都是一个独立的缓存项,有自己的缓存键(题目 ID)和缓存值(题目对象)。这种设计让缓存更加灵活,也更容易管理。
至于缓存的内容,我们选择缓存解析后的对象,而不是原始的 JSON 数据。为什么?因为解析 JSON 也是一个耗时的操作,虽然比网络请求快得多,但仍然需要几毫秒。如果我们缓存原始 JSON,每次使用时都需要重新解析,会降低缓存的效果。而且,缓存对象可以直接使用,代码更简洁。
但是,缓存对象也有一个问题:对象占用的内存可能比 JSON 字符串多。因为对象包含了很多元数据,比如类信息、方法表等。而且,如果对象之间有引用关系,可能会导致大量对象被缓存,占用更多内存。所以,我们需要在内存占用和访问速度之间找到平衡。
缓存虽然带来了很多好处,但也引入了一个新的问题:缓存失效。当数据发生变化时,缓存中的数据就过期了,我们需要更新缓存。但是,我们如何知道数据发生了变化?如何保证缓存中的数据和服务器上的数据一致?
在 LeetCode Runner 中:
- 对于题目数据,我们设置了较长的过期时间(比如 24 小时),因为题目内容不会频繁变化。
- 对于用户数据(比如提交记录、通过状态),我们使用主动失效策略,在用户提交代码后立即清除缓存。
内存缓存
在 Java 中,最简单的内存缓存就是一个 HashMap。我们可以用题目 ID 作为键,题目对象作为值,把所有访问过的题目都存储在 HashMap 中。这种实现简单直接,而且性能很好,HashMap 的查找时间复杂度是 O(1)。
java
public class MemoryCache {
private Map<String, Question> cache = new HashMap<>();
public Question get(String questionId) {
return cache.get(questionId);
}
public void put(String questionId, Question question) {
cache.put(questionId, question);
}
}但这种简单的实现有一个严重的问题:内存泄漏。

如果用户浏览了很多题目,HashMap 会越来越大,最终可能占用几百 MB 甚至更多的内存。而且,这些数据永远不会被清理,即使用户已经很久没有访问某些题目了。
为了解决这个问题,我们需要引入缓存淘汰策略。最常用的策略是 LRU(Least Recently Used),也就是最近最少使用。当缓存满了的时候,我们删除最久没有被访问的数据,为新数据腾出空间。
Java 提供了 LinkedHashMap 来实现 LRU 缓存。LinkedHashMap 是 HashMap 的一个子类,它维护了一个双向链表,记录了元素的访问顺序。我们可以重写它的 removeEldestEntry 方法,当缓存大小超过限制时,自动删除最老的元素。
java
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private int maxSize;
public LRUCache(int maxSize) {
// 第三个参数 true 表示按访问顺序排序
super(16, 0.75f, true);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当大小超过限制时,删除最老的元素
return size() > maxSize;
}
}这个实现非常优雅。我们只需要指定最大大小,LinkedHashMap 会自动维护访问顺序,自动删除最老的元素。而且,这一切都是线程安全的(如果我们使用 Collections.synchronizedMap 包装的话)。
磁盘缓存
内存缓存虽然快,但有一个致命的缺点:不持久。当插件重启或者 IDEA 关闭时,内存中的数据会全部丢失。下次启动时,缓存是空的,需要重新从网络获取数据。
为了解决这个问题,我们引入了磁盘缓存。磁盘缓存把数据存储在文件系统中,即使程序重启,数据仍然存在。这样,用户第二次打开插件时,可以直接从磁盘缓存中加载数据,不需要等待网络请求。
磁盘缓存的实现有很多选择。最简单的是直接把对象序列化成文件。Java 提供了 Serializable 接口,可以把对象转换成字节流,然后写入文件。读取时,再把字节流转换回对象。
java
public class DiskCache {
private String cacheDir;
public DiskCache(String cacheDir) {
this.cacheDir = cacheDir;
new File(cacheDir).mkdirs();
}
public void put(String key, Object value) throws IOException {
File file = new File(cacheDir, key);
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file))) {
oos.writeObject(value);
}
}
public Object get(String key) throws IOException, ClassNotFoundException {
File file = new File(cacheDir, key);
if (!file.exists()) {
return null;
}
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))) {
return ois.readObject();
}
}
}这种实现简单直接,但也有一些问题。
- 首先是性能。
Java 的序列化比较慢,而且生成的文件比较大。对于大对象,序列化可能需要几十毫秒,这对于缓存来说太慢了。 - 其次是兼容性。
如果我们修改了类的定义,比如添加了一个字段,旧的序列化文件可能无法反序列化。这会导致缓存失效,用户需要重新下载数据。
更好的方法是使用 JSON 格式。JSON 是一种文本格式,可读性好,而且有很多成熟的库可以使用。我们可以用 Gson 或 Jackson 把对象转换成 JSON 字符串,然后写入文件。
java
public class JsonDiskCache {
private String cacheDir;
private Gson gson;
public JsonDiskCache(String cacheDir) {
this.cacheDir = cacheDir;
this.gson = new Gson();
new File(cacheDir).mkdirs();
}
public void put(String key, Object value) throws IOException {
File file = new File(cacheDir, key + ".json");
String json = gson.toJson(value);
Files.write(file.toPath(), json.getBytes(StandardCharsets.UTF_8));
}
public <T> T get(String key, Class<T> clazz) throws IOException {
File file = new File(cacheDir, key + ".json");
if (!file.exists()) {
return null;
}
String json = new String(Files.readAllBytes(file.toPath()), StandardCharsets.UTF_8);
return gson.fromJson(json, clazz);
}
}JSON 格式的优点是可读性好,兼容性好。即使类的定义发生了变化,只要字段名没变,JSON 仍然可以正确解析。而且,JSON 文件可以用文本编辑器打开,方便调试和排查问题。
但 JSON 也有缺点。JSON 是文本格式,文件大小比二进制格式大。而且,JSON 的解析也需要时间,虽然比 Java 序列化快,但仍然比直接读取二进制数据慢。
在 LeetCode Runner 中,我们选择了 JSON 格式,因为它的优点大于缺点。题目数据的大小通常不大,几 KB 到几十 KB,JSON 的性能完全可以接受。而且,JSON 的可读性和兼容性对于长期维护非常重要。
五、测试用例
LeetCode 平台为每道题目提供了示例测试用例,但有时候我们需要自己构造一些特殊的测试用例来验证边界情况或者调试代码。
数据设计
我们需要理解测试用例在系统中的三种不同形态。这三种形态对应着不同的使用场景,理解它们之间的关系是掌握测试用例管理的关键。
第一种是 defaultTestcases,也就是默认测试用例。这是从 LeetCode 平台获取的官方示例测试用例。当你第一次打开一道题目时,系统会从平台拉取这些测试用例并保存下来。默认测试用例是只读的,它们作为一个基准,当你想重置自定义测试用例时,可以恢复到这个状态。
第二种是 exampleTestcases,也就是示例测试用例。这是用户可以编辑的测试用例,也是运行代码时实际使用的测试用例。当你打开测试用例对话框,看到的就是这个字段的内容。你可以修改它、添加新的测试用例、删除不需要的测试用例。当你点击"运行代码"时,系统会使用 exampleTestcases 作为输入。
第三种是 debugTestcase,也就是调试测试用例。这是专门为调试功能准备的。调试时,我们需要把测试用例转换成对应语言的代码。比如,对于 Java,我们需要把 [1,2,3] 转换成 int[] arr = {1, 2, 3};。debugTestcase 存储的就是这种转换后的代码。
这三种形态之间有明确的数据流向。当题目第一次加载时,defaultTestcases 和 exampleTestcases 都被设置为平台提供的示例。当用户编辑测试用例时,只有 exampleTestcases 会被修改。当用户点击"重置"按钮时,exampleTestcases 会被恢复成 defaultTestcases。当启动调试时,系统会根据 exampleTestcases 生成 debugTestcase。
💡 面试题:为什么需要三个不同的字段来存储测试用例?直接用一个字段不行吗?
这个问题考察的是对需求的理解和数据建模能力。如果只用一个字段,会遇到几个问题:
无法区分原始数据和用户修改后的数据,就无法实现"重置"功能运行和调试使用的数据格式不同,混在一起会导致逻辑混乱- 缓存失效时
无法恢复用户的自定义测试用例这种设计体现了"单一职责原则":每个字段有明确的用途,职责清晰。虽然增加了一些复杂度,但让系统更加灵活和可维护。
对话框设计
测试用例管理的核心是一个对话框(Dialog)。一个文本输入框,几个按钮。
-
首先是
即时反馈。当你在文本框中输入时,不需要点击任何按钮,输入就已经被记录了。这种设计让用户感觉系统很"聪明",不需要额外的操作。但这也带来了一个问题:如何处理用户的误操作?如果用户不小心删除了所有内容,然后关闭对话框,测试用例就丢失了。 -
为了解决这个问题,
对话框提供了"取消"按钮。点击"取消"时,所有的修改都会被丢弃,测试用例恢复到打开对话框之前的状态。这是一个标准的"撤销"机制,让用户可以安全地尝试各种修改。 -
其次是
默认值的处理。当对话框打开时,文本框中已经填充了当前的测试用例。这让用户可以在现有基础上修改,而不是从头开始输入。而且,如果用户不做任何修改就点击"确定",测试用例保持不变。这符合"最小惊讶原则":系统的行为应该符合用户的预期。 -
第三是重置功能。"重置"按钮让用户可以
快速恢复到默认测试用例。这在用户做了很多修改,但发现不对劲,想重新开始时非常有用。重置不是简单地清空文本框,而是填充默认测试用例,这样用户可以看到原始的数据是什么样的。
java
public class TestCaseDialog extends DialogWrapper {
private JTextArea textArea;
private String filePath;
private Project project;
public TestCaseDialog(String initialContent, String filePath, Project project) {
super(project);
this.filePath = filePath;
this.project = project;
setTitle("编辑测试用例");
init();
// 填充初始内容
textArea.setText(initialContent);
}
@Override
protected JComponent createCenterPanel() {
textArea = new JTextArea(10, 50);
textArea.setLineWrap(true);
textArea.setWrapStyleWord(true);
JScrollPane scrollPane = new JScrollPane(textArea);
return scrollPane;
}
@Override
protected JComponent createSouthPanel() {
JPanel panel = new JPanel();
// 重置按钮
JButton resetButton = new JButton("重置");
resetButton.addActionListener(e -> {
LeetcodeEditor editor = StoreService.getInstance(project)
.getCache(filePath, LeetcodeEditor.class);
if (editor != null && editor.getDefaultTestcases() != null) {
textArea.setText(editor.getDefaultTestcases());
}
});
panel.add(resetButton);
panel.add(super.createSouthPanel());
return panel;
}
@Override
protected void doOKAction() {
// 获取用户输入
String content = textArea.getText().trim();
// 更新缓存
LeetcodeEditor editor = StoreService.getInstance(project)
.getCache(filePath, LeetcodeEditor.class);
if (editor != null) {
editor.setExampleTestcases(content);
StoreService.getInstance(project).addCache(filePath, editor);
}
super.doOKAction();
}
}createCenterPanel 创建中心的文本输入区域,createSouthPanel 创建底部的按钮区域,doOKAction 处理"确定"按钮的点击。
注意 doOKAction 方法中的逻辑。我们首先 trim 用户输入,去掉首尾的空白字符。这是一个常见的做法,避免用户不小心输入的空格影响测试用例。然后,我们从缓存中获取 LeetcodeEditor 对象,更新它的 exampleTestcases 字段,再把它写回缓存。
格式转换
测试用例在不同场景下需要不同的格式。在运行代码时,测试用例是纯文本格式,比如 [1,2,3]。但在调试时,我们需要把它转换成对应语言的代码。这个转换过程是测试用例管理的一个重要环节。
转换的逻辑封装在 TestcaseConvertor 接口及其实现类中。每种语言都有自己的转换器:JavaTestcaseConvertor、PythonTestcaseConvertor、CppTestcaseConvertor。这些转换器实现了相同的接口,但转换逻辑不同,因为不同语言的语法不同。
以 Java 为例,如果测试用例是 [1,2,3],我们需要把它转换成 int[] arr = {1, 2, 3};。如果是 "hello",需要转换成 String str = "hello";。如果是一个链表 [1,2,3],需要转换成创建链表的代码。
这个转换过程需要理解题目的函数签名。函数签名告诉我们参数的类型和数量。比如,如果函数签名是 int twoSum(int[] nums, int target),我们就知道第一个参数是整数数组,第二个参数是整数。根据这个信息,我们可以正确地转换测试用例。
java
public class JavaTestcaseConvertor extends AbstractTestcaseConvertor {
@Override
public String convert(String testcase, List<String> paramTypes) {
String[] lines = testcase.split("\n");
StringBuilder result = new StringBuilder();
for (int i = 0; i < lines.length && i < paramTypes.size(); i++) {
String line = lines[i].trim();
String paramType = paramTypes.get(i);
// 根据参数类型转换
if (paramType.equals("int")) {
result.append("int param").append(i).append(" = ")
.append(line).append(";\n");
} else if (paramType.equals("int[]")) {
result.append("int[] param").append(i).append(" = ")
.append(convertToArray(line)).append(";\n");
} else if (paramType.equals("String")) {
result.append("String param").append(i).append(" = ")
.append(line).append(";\n");
}
// ... 其他类型的转换
}
return result.toString();
}
private String convertToArray(String arrayStr) {
// 把 [1,2,3] 转换成 {1, 2, 3}
return arrayStr.replace('[', '{').replace(']', '}');
}
}这个转换器的实现比较简单,只处理了几种基本类型。实际的实现要复杂得多,需要处理嵌套数组、链表、树等复杂数据结构。而且,还需要处理各种边界情况,比如空数组、null 值、特殊字符等。
运行流程
想象这样一个场景:你刚刚完成了"206. 反转链表"这道题的代码,想要测试一下是否正确。你在 LeetCode Runner 中点击"运行代码"按钮时,点击。
首先被触发的是 RunCodeAction 的 actionPerformed 方法。这是一个 IDEA 的 Action,专门用来响应用户的操作。但这个方法非常简洁,它只做了一件事:调用 CodeService 的 runCode 方法。为什么要这样设计?因为 Action 层只负责接收用户操作,真正的业务逻辑应该放在 Service 层。这样的分层设计让代码更加清晰,也更容易测试。
java
public class RunCodeAction extends AbstractAction {
@Override
public void actionPerformed(AnActionEvent e) {
Project project = e.getProject();
if (project == null) {
return;
}
// 委托给 Service 层处理
CodeService.getInstance(project).runCode();
}
}当控制流进入 CodeService 的 runCode 方法时,真正的工作才开始。这个方法需要做很多事情:获取当前代码、获取测试用例、构建请求、发送到 LeetCode、等待结果、显示结果。但是,如果我们把所有这些逻辑都写在一个方法里,这个方法会变得非常长,难以理解和维护。
所以,runCode 方法采用了一种"编排"的方式。它像一个指挥家,协调各个部分的工作,但具体的工作由其他方法来完成。让我们看看这个方法的结构:
java
public void runCode() {
// 第一步:获取当前编辑器
FileEditor fileEditor = getCurrentFileEditor();
if (fileEditor == null) {
ConsoleUtils.error("请先打开一个题目");
return;
}
// 第二步:获取文件路径
VirtualFile file = getVirtualFile(fileEditor);
String filePath = file.getPath();
// 第三步:从缓存获取 LeetcodeEditor
LeetcodeEditor leetcodeEditor = storeService.get(filePath);
if (leetcodeEditor == null) {
ConsoleUtils.error("无法获取题目信息");
return;
}
// 第四步:读取代码内容
String code = readCodeFromEditor(fileEditor);
// 第五步:构建运行请求
RunCode runCode = buildRunCode(leetcodeEditor, code);
// 第六步:在后台线程执行
TaskCenter.execute(() -> {
executeRunCode(runCode);
});
}注意:我们把实际的代码执行放在后台线程中。为什么?因为代码执行是一个耗时操作,可能需要几秒钟。如果在主线程(也就是 UI 线程)中执行,整个 IDE 界面会卡住,用户无法进行任何操作。
buildRunCode 方法看起来很简单,但它实际上做了很多工作。它需要把各种信息组装成一个 RunCode 对象,这个对象包含了 LeetCode 平台执行代码所需的所有信息。
java
private RunCode buildRunCode(LeetcodeEditor editor, String code) {
RunCode runCode = new RunCode();
// 设置语言
runCode.setLang(editor.getLang());
// 设置题目 ID
runCode.setQuestionId(editor.getQuestionId());
// 设置代码
runCode.setTypedCode(code);
// 设置测试用例
String testcase = editor.getExampleTestcases();
if (testcase == null || testcase.isEmpty()) {
testcase = editor.getDefaultTestcases();
}
runCode.setDataInput(testcase);
// 设置其他必要信息
runCode.setTitleSlug(editor.getTitleSlug());
runCode.setFrontendQuestionId(editor.getFrontendQuestionId());
return runCode;
}这里有一个细节:测试用例的选择。我们首先尝试使用 exampleTestcases,如果没有,就使用 defaultTestcases。为什么要这样?因为用户可能通过"测试用例"对话框修改了测试用例,修改后的测试用例会保存在 exampleTestcases 中。如果用户没有修改,exampleTestcases 就是 null,这时候我们使用默认的测试用例。
这就体现了一个重要的原则:优先使用用户的选择。
- 如果用户明确指定了某个值,我们就使用用户指定的值;
- 如果用户没有指定,我们才使用默认值。这让用户感觉到系统是"听话"的,是尊重他们的选择的。
当 RunCode 对象构建完成后,我们需要把它发送到 LeetCode 平台。executeRunCode 方法是实际执行代码的地方。它首先调用 LeetcodeClient 的 runCode 方法,把 RunCode 对象发送出去。LeetcodeClient 会构建一个 HTTP POST 请求,把 RunCode 对象序列化成 JSON,然后发送到 LeetCode 的 API 端点。
java
private void executeRunCode(RunCode runCode) {
try {
// 显示"正在运行..."提示
ConsoleUtils.info("正在运行代码...");
// 调用 LeetcodeClient
RunCodeResult result = leetcodeClient.runCode(runCode);
// 显示结果
if (result.isSuccess()) {
ConsoleUtils.showSuccess(result);
} else {
ConsoleUtils.showError(result);
}
} catch (NetworkException e) {
ConsoleUtils.error("网络错误:" + e.getMessage());
} catch (TimeoutException e) {
ConsoleUtils.error("请求超时,请检查网络连接");
} catch (Exception e) {
ConsoleUtils.error("运行失败:" + e.getMessage());
LogUtils.error("Run code failed", e);
}
}因为 LeetCode 的代码执行是异步的。当你提交代码后,LeetCode 不会立即返回结果,而是返回一个 interpret_id,然后你需要用这个 id 去查询结果。
这种设计是合理的。代码执行可能需要几秒钟,如果 API 一直等待执行完成才返回,连接可能会超时。所以 LeetCode 采用了异步的方式:先返回一个 id,然后客户端用这个 id 去轮询结果。
java
public RunCodeResult runCode(RunCode runCode) throws Exception {
// 第一步:发送运行请求
HttpRequest request = new HttpRequest.RequestBuilder(RUN_CODE_URL)
.setMethod("POST")
.setBody(gson.toJson(runCode))
.setContentType("application/json")
.addBasicHeader()
.build();
HttpResponse response = httpClient.executePost(request);
// 第二步:解析响应,获取 interpret_id
String interpretId = parseInterpretId(response.getBody());
if (interpretId == null) {
throw new RuntimeException("无法获取 interpret_id");
}
// 第三步:轮询获取结果
return pollResult(interpretId);
}这个方法分为三步。第一步发送运行请求,第二步解析响应获取 interpret_id,第三步轮询获取结果。每一步都可能失败,所以我们需要仔细处理错误情况。
轮询的实现是这个方法的核心。我们需要反复查询结果,直到结果准备好。但是,我们不能无限制地轮询,否则如果 LeetCode 服务器出问题,我们的程序会一直卡在这里。所以我们需要设置一个最大轮询次数。
java
private RunCodeResult pollResult(String interpretId) throws Exception {
int maxAttempts = 30; // 最多轮询 30 次
int attempt = 0;
while (attempt < maxAttempts) {
// 等待 1 秒
Thread.sleep(1000);
// 查询结果
HttpRequest request = new HttpRequest.RequestBuilder(CHECK_URL + interpretId)
.setMethod("GET")
.addBasicHeader()
.build();
HttpResponse response = httpClient.executeGet(request);
// 检查结果是否准备好
if (isResultReady(response)) {
return parseResult(response.getBody());
}
attempt++;
}
throw new TimeoutException("获取结果超时");
}最后一步是解析结果并展示给用户。LeetCode 返回的结果是一个 JSON 对象,包含了很多信息:代码输出、标准输出、执行时间、内存消耗、是否通过等等。我们需要把这些信息提取出来,然后以一种友好的方式展示给用户。
parseResult 方法负责解析 JSON 响应。它使用 Gson 库把 JSON 字符串转换成 RunCodeResult 对象。这个对象包含了所有的结果信息,是一个纯粹的数据对象,不包含任何业务逻辑。
java
private RunCodeResult parseResult(String json) {
JsonObject obj = gson.fromJson(json, JsonObject.class);
RunCodeResult result = new RunCodeResult();
result.setStatusCode(obj.get("status_code").getAsInt());
result.setStatusMsg(obj.get("status_msg").getAsString());
if (obj.has("code_output")) {
result.setCodeOutput(obj.get("code_output").getAsString());
}
if (obj.has("std_output")) {
result.setStdOutput(obj.get("std_output").getAsString());
}
if (obj.has("expected_output")) {
result.setExpectedOutput(obj.get("expected_output").getAsString());
}
if (obj.has("elapsed_time")) {
result.setElapsedTime(obj.get("elapsed_time").getAsInt());
}
if (obj.has("memory")) {
result.setMemory(obj.get("memory").getAsInt());
}
return result;
}解析完结果后,我们需要把它展示给用户。ConsoleUtils 提供了 showSuccess 和 showError 两个方法,分别用于展示成功和失败的结果。这两个方法会把结果格式化成易读的文本,然后输出到控制台。
java
public static void showSuccess(RunCodeResult result) {
StringBuilder sb = new StringBuilder();
sb.append("✅ 通过\n");
sb.append("输出:").append(result.getCodeOutput()).append("\n");
sb.append("预期:").append(result.getExpectedOutput()).append("\n");
sb.append("执行用时:").append(result.getElapsedTime()).append(" ms\n");
sb.append("内存消耗:").append(formatMemory(result.getMemory())).append("\n");
info(sb.toString());
}🔨 总结一下完整的刷题流程:
用户点击题目
↓
创建代码文件(自动填充模板)
↓
打开分屏编辑器(左侧代码,右侧题目)
↓
用户编写代码
↓
点击运行/提交
↓
发送到 LeetCode 平台
↓
轮询获取结果
↓
在控制台显示结果整个示例过程:
Step 1:打开题目
java
// 用户在题目列表中点击 "206. 反转链表"
// CodeService.openCode() 被调用
public void openCode(Question question) {
// 1. 创建代码文件
String filePath = createCodeFile(question);
// 2. 填充代码模板
String template = getCodeTemplate(question, "java");
writeToFile(filePath, template);
// 3. 创建 LeetcodeEditor 模型
LeetcodeEditor editor = new LeetcodeEditor();
editor.setQuestionId(question.getQuestionId());
editor.setLang("java");
editor.setExampleTestcases("[1,2,3,4,5]");
// 4. 缓存到 StoreService
storeService.cache(filePath, editor);
// 5. 打开编辑器
openEditor(filePath);
}Step 2:编写代码
java
// 用户在编辑器中编写代码
class Solution {
public ListNode reverseList(ListNode head) {
ListNode prev = null;
ListNode curr = head;
while (curr != null) {
ListNode next = curr.next;
curr.next = prev;
prev = curr;
curr = next;
}
return prev;
}
}Step 3:运行代码
java
// 用户点击"运行"按钮
// RunCodeAction.actionPerformed() 被调用
public void actionPerformed(AnActionEvent e) {
Project project = e.getProject();
CodeService.getInstance(project).runCode();
}
// CodeService.runCode() 执行
public void runCode() {
// 1. 获取当前代码
String code = getCurrentCode();
// 2. 获取测试用例
String testcase = getTestcase(); // "[1,2,3,4,5]"
// 3. 构建请求
RunCode runCode = new RunCode();
runCode.setTypedCode(code);
runCode.setDataInput(testcase);
runCode.setLang("java");
runCode.setQuestionId("206");
// 4. 发送请求
RunCodeResult result = leetcodeClient.runCode(runCode);
// 5. 显示结果
ConsoleUtils.showResult(result);
}Step 4:查看结果
✅ 通过
输入:[1,2,3,4,5]
输出:[5,4,3,2,1]
预期:[5,4,3,2,1]
执行用时:0 ms
内存消耗:38.5 MB六、HTTP客户端
请求构建器
构建一个 HTTP 请求需要指定很多参数:URL、方法(GET/POST/PUT/DELETE)、请求头、请求体、超时时间等等。如果使用传统的构造函数或者 setter 方法,代码会很冗长。更好的方式是使用建造者模式(Builder Pattern)。
java
HttpRequest request = new HttpRequest.Builder()
.url("https://leetcode.com/api/problems/all/")
.method("GET")
.header("User-Agent", "Mozilla/5.0")
.timeout(10000)
.build();响应处理
返回一个 HttpResponse 对象,它包含了响应的所有信息。业务代码可以根据需要获取状态码、响应头、响应体等。
java
public class HttpResponse {
private int code;
private Map<String, String> headers;
private String body;
public int code() {
return code;
}
public String header(String name) {
return headers.get(name);
}
public String body() {
return body;
}
public boolean isSuccessful() {
return code >= 200 && code < 300;
}
public <T> T parseJson(Class<T> clazz) {
return new Gson().fromJson(body, clazz);
}
}七、编辑器
分屏编辑器
在传统的刷题方式中,你需要在浏览器和 IDE 之间切换。浏览器显示题目,IDE 用来写代码。这种方式有几个问题。首先是屏幕空间的浪费。如果你只有一个显示器,浏览器和 IDE 不能同时全屏显示,你要么让它们并排显示(每个都只占半个屏幕),要么让它们重叠显示(需要频繁切换)。
IDEA 本身就支持编辑器分割。你可以右键点击编辑器标签,选择"Split Right"或"Split Down",把编辑器分成两部分。但这种分割是针对文件的,你需要打开两个文件才能分屏。而且,这种分割是临时的,关闭文件后分割就消失了。
我们采用了一种更高层的方法:使用 IDEA 的 Splitter 组件。Splitter 是 IDEA 提供的一个 UI 组件,专门用于分割界面。它可以把一个区域分成两部分,支持水平分割和垂直分割,支持拖动调整分割比例,支持最小化和最大化。
java
public class SplitEditorLayout {
private JBSplitter splitter;
private JComponent descriptionPanel;
private JComponent codeEditor;
public SplitEditorLayout() {
// 创建分割器,垂直分割(左右分割)
splitter = new JBSplitter(false, 0.4f);
// 设置第一个组件(题目描述)
descriptionPanel = createDescriptionPanel();
splitter.setFirstComponent(descriptionPanel);
// 设置第二个组件(代码编辑器)
codeEditor = createCodeEditor();
splitter.setSecondComponent(codeEditor);
}
public JComponent getComponent() {
return splitter;
}
}这段代码创建了一个基本的分屏布局。JBSplitter 的第一个参数是分割方向,false 表示垂直分割(左右分割),true 表示水平分割(上下分割)。第二个参数是分割比例,0.4f 表示左边占 40%,右边占 60%。
题目渲染
题目描述是 HTML 格式的,包含了文本、图片、代码块、列表等各种元素。我们需要把这些 HTML 渲染成用户可以阅读的界面。
最简单的方法是使用 Java 的 JEditorPane 组件。JEditorPane 支持 HTML 渲染,可以显示基本的 HTML 内容。但是,JEditorPane 的 HTML 支持非常有限,只支持 HTML 3.2 标准,不支持 CSS,不支持 JavaScript,渲染效果很差。
更好的方法是使用 JCEF(Java Chromium Embedded Framework)。JCEF 是一个嵌入式的 Chromium 浏览器,可以在 Java 应用中显示完整的网页。它支持最新的 HTML5、CSS3、JavaScript 标准,渲染效果和 Chrome 浏览器一样。
IDEA 从 2020.2 版本开始内置了 JCEF,我们可以直接使用。JCEF 提供了 JBCefBrowser 类,可以创建一个浏览器实例,加载 HTML 内容。
java
private JComponent createDescriptionPanel() {
// 创建 JCEF 浏览器
JBCefBrowser browser = new JBCefBrowser();
// 加载 HTML 内容
String html = buildHtmlContent();
browser.loadHTML(html);
// 返回浏览器组件
return browser.getComponent();
}
private String buildHtmlContent() {
StringBuilder html = new StringBuilder();
html.append("<!DOCTYPE html>");
html.append("<html>");
html.append("<head>");
html.append("<meta charset='UTF-8'>");
html.append("<style>");
html.append(getCustomCSS());
html.append("</style>");
html.append("</head>");
html.append("<body>");
html.append(question.getContent());
html.append("</body>");
html.append("</html>");
return html.toString();
}这段代码创建了一个 JCEF 浏览器,加载了题目的 HTML 内容。我们还添加了自定义的 CSS 样式,让题目描述更加美观。
但是,使用 JCEF 也有一些问题。首先是性能。JCEF 是一个完整的浏览器,启动需要一些时间,占用的内存也比较多。如果用户频繁打开和关闭题目,可能会感觉到卡顿。
其次是兼容性。虽然 IDEA 从 2020.2 开始内置了 JCEF,但在某些系统上(特别是 Linux),JCEF 可能无法正常工作。我们需要提供一个降级方案,当 JCEF 不可用时,使用 JEditorPane 作为备选。
java
private JComponent createDescriptionPanel() {
// 检查 JCEF 是否可用
if (JBCefApp.isSupported()) {
return createJCEFPanel();
} else {
return createJEditorPanePanel();
}
}代码编辑器
分屏的右边是代码编辑器。这个编辑器不是我们自己实现的,而是使用 IDEA 原生的编辑器。这样可以保证所有的编辑功能都可用,包括语法高亮、代码补全、错误提示等。
但是,如何把 IDEA 的编辑器嵌入到我们的分屏布局中呢?IDEA 的编辑器是通过 FileEditorManager 管理的,我们不能直接创建一个编辑器实例。我们需要通过 FileEditorManager 打开文件,然后获取对应的编辑器组件。
java
private JComponent createCodeEditor() {
// 获取 FileEditorManager
FileEditorManager editorManager = FileEditorManager.getInstance(project);
// 打开代码文件
VirtualFile file = getCodeFile();
FileEditor[] editors = editorManager.openFile(file, false);
// 获取编辑器组件
if (editors.length > 0) {
return editors[0].getComponent();
}
return new JPanel();
}但这种方法有一个问题:openFile 方法会在 IDEA 的主编辑器区域打开文件,而不是在我们的分屏中。我们需要一种方法,让文件只在分屏中打开,而不影响主编辑器区域。
解决方法是使用自定义的 FileEditorProvider。FileEditorProvider 是 IDEA 提供的一个扩展点,用于创建自定义的文件编辑器。我们可以实现一个 FileEditorProvider,当打开 LeetCode 题目文件时,返回我们的分屏编辑器。
java
public class LeetCodeFileEditorProvider implements FileEditorProvider {
@Override
public boolean accept(Project project, VirtualFile file) {
// 只处理 LeetCode 题目文件
return isLeetCodeFile(file);
}
@Override
public FileEditor createEditor(Project project, VirtualFile file) {
// 创建分屏编辑器
return new SplitFileEditor(project, file);
}
}
public class SplitFileEditor implements FileEditor {
private SplitEditorLayout layout;
public SplitFileEditor(Project project, VirtualFile file) {
layout = new SplitEditorLayout(project, file);
}
@Override
public JComponent getComponent() {
return layout.getComponent();
}
// 实现其他 FileEditor 接口方法...
}通过这种方式,当用户打开 LeetCode 题目文件时,IDEA 会自动使用我们的分屏编辑器,而不是默认的文本编辑器。这样,分屏就无缝集成到了 IDEA 的编辑器系统中。
状态保存与恢复
用户可能会调整分屏的比例,比如把左边的题目描述缩小,给代码编辑器更多空间。我们需要记住这个设置,下次打开同一道题目时,自动恢复到上次的状态。
IDEA 提供了 PropertiesComponent 来保存插件的配置。我们可以用它来保存分屏的比例。
java
public void saveSplitProportion() {
float proportion = splitter.getProportion();
PropertiesComponent properties = PropertiesComponent.getInstance(project);
properties.setValue("leetcode.split.proportion", String.valueOf(proportion));
}
public void restoreSplitProportion() {
PropertiesComponent properties = PropertiesComponent.getInstance(project);
String value = properties.getValue("leetcode.split.proportion", "0.4");
float proportion = Float.parseFloat(value);
splitter.setProportion(proportion);
}我们在用户调整分屏比例时保存设置,在创建分屏时恢复设置。这样,用户的偏好就能被记住。
除了分屏比例,我们还可以保存其他设置,比如题目描述的字体大小、代码编辑器的主题等。通过这些细节的优化,我们让分屏编辑器变得更加智能和人性化。
八、调试器
当我们谈论 Java 调试时,很多人会想到在 IDE 中打断点、单步执行、查看变量。但你有没有想过,IDE 是如何实现这些功能的?答案就是 JDI(Java Debug Interface)。理解 JDI 是掌握 Java 调试系统的关键,也是我们深入 LeetCode Runner 调试功能的基础。
JDI
🔗参考链接1:JDI教程1
🔗参考链接2:JDI教程2
JDI 是 Java Platform Debugger Architecture(JPDA)的一部分。JPDA 是一个完整的调试架构,它分为三层:JVM TI(JVM Tool Interface)、JDWP(Java Debug Wire Protocol)和 JDI。这三层各司其职,共同构成了 Java 的调试体系。
-
最底层是 JVM TI,它是 JVM 提供的本地接口,允许工具直接与 JVM 交互。
-
中间层是 JDWP,它定义了调试器和被调试程序之间的通信协议。
-
最上层是 JDI,它是一个高级的 Java API,为调试器开发者提供了友好的编程接口。
┌─────────────────────────────────────┐
│ 调试器应用层 │
├─────────────────────────────────────┤
│ JDI API │ <- 高级Java API
├─────────────────────────────────────┤
│ JDI实现层 │ <- 将API调用转换为JDWP命令
├─────────────────────────────────────┤
│ JDWP协议层 │ <- 二进制通信协议
├─────────────────────────────────────┤
│ 传输层(Socket/SharedMem) │
├─────────────────────────────────────┤
│ JVMTI后端 │ <- JVM内部实现
└─────────────────────────────────────┘
作为调试器开发者,我们主要使用 JDI。JDI 隐藏了底层的复杂性,让我们可以用面向对象的方式来操作调试会话。我们不需要关心 JDWP 协议的细节,不需要处理字节流和网络通信,只需要调用 JDI 提供的方法就可以了。
要理解 JDI,我们需要先理解几个核心概念。
-
第一个是 VirtualMachine。在 JDI 中,VirtualMachine 代表了一个被调试的 JVM 实例。所有的调试操作都是通过 VirtualMachine 对象来进行的。你可以把它想象成一个遥控器,通过它你可以控制远程的 JVM。
-
第二个核心概念是 ThreadReference。在 Java 中,程序是由多个线程组成的。每个线程都有自己的执行流程,都可能需要调试。ThreadReference 代表了被调试程序中的一个线程。通过 ThreadReference,我们可以暂停线程、恢复线程、查看线程的调用栈。
-
第三个是 StackFrame。当一个线程暂停时,它会停在某个方法的某一行。这个方法可能是被其他方法调用的,而那个方法又可能被更上层的方法调用。这就形成了一个调用栈。StackFrame 代表了调用栈中的一帧,也就是一次方法调用。通过 StackFrame,我们可以查看局部变量、方法参数、当前执行位置等信息。
-
第四个是 Location。Location 代表了代码中的一个位置,它包含了类名、方法名、行号等信息。当我们设置断点时,实际上是在某个 Location 上设置断点。当线程执行到这个 Location 时,就会暂停。
-
第五个是 Value。在调试时,我们经常需要查看变量的值。但是,被调试程序运行在另一个 JVM 中,我们不能直接访问它的内存。JDI 提供了 Value 接口来表示被调试程序中的值。Value 有很多子类型,比如 IntegerValue、StringReference、ObjectReference 等,分别对应不同类型的值。
这些概念之间的关系是这样的:一个 VirtualMachine 包含多个 ThreadReference,每个 ThreadReference 有一个调用栈,调用栈由多个 StackFrame 组成,每个 StackFrame 对应一个 Location,并且包含多个 Value(局部变量和参数)。理解了这些关系,就理解了 JDI 的基本结构。
使用 JDI 的第一步是启动或连接到被调试程序。有两种方式:
- 一种是
由调试器启动被调试程序, - 另一种是
连接到一个已经运行的程序。
在 LeetCode Runner 中,我们使用第一种方式,因为我们需要完全控制被调试程序的启动过程。
启动被调试程序需要使用 LaunchingConnector。JDI 提供了多种 Connector,LaunchingConnector 是其中一种,专门用于启动新的 JVM 进程。
我们首先需要获取一个 LaunchingConnector 实例,然后配置启动参数,最后调用 launch 方法启动程序。
java
public VirtualMachine launchDebugVM(String mainClass, String classpath) throws Exception {
// 获取 LaunchingConnector
LaunchingConnector connector = findLaunchingConnector();
// 配置启动参数
Map<String, Connector.Argument> arguments = connector.defaultArguments();
// 设置主类
Connector.Argument mainArg = arguments.get("main");
mainArg.setValue(mainClass);
// 设置 classpath
Connector.Argument optionsArg = arguments.get("options");
optionsArg.setValue("-cp " + classpath);
// 启动 JVM
VirtualMachine vm = connector.launch(arguments);
return vm;
}当我们调用 connector.launch 时,JDI 会启动一个新的 Java 进程,这个进程会以调试模式运行。调试模式的 JVM 会开启 JDWP 服务,监听一个端口,等待调试器连接。同时,JDI 会自动连接到这个端口,建立调试会话。
我们通过 options 参数传递了 classpath。为什么需要这样做?因为被调试程序需要知道去哪里找类文件。如果不设置 classpath,JVM 只会在默认位置查找类,很可能找不到我们的代码,导致启动失败。
断点设置原理:
在 JDI 中,断点是通过 EventRequest 来实现的。
具体来说,是 BreakpointRequest。我们需要创建一个 BreakpointRequest,指定断点的位置,然后启用它。当被调试程序执行到这个位置时,JVM 会生成一个 BreakpointEvent,发送给调试器。
java
public void setBreakpoint(String className, int lineNumber) throws Exception {
// 获取类引用
List<ReferenceType> classes = vm.classesByName(className);
if (classes.isEmpty()) {
throw new Exception("找不到类:" + className);
}
ReferenceType refType = classes.get(0);
// 获取指定行的 Location
List<Location> locations = refType.locationsOfLine(lineNumber);
if (locations.isEmpty()) {
throw new Exception("找不到行:" + lineNumber);
}
Location location = locations.get(0);
// 创建 BreakpointRequest
EventRequestManager erm = vm.eventRequestManager();
BreakpointRequest breakpointRequest = erm.createBreakpointRequest(location);
// 启用断点
breakpointRequest.enable();
}这段代码展示了设置断点的完整过程。
首先,我们需要找到对应的类。vm.classesByName 方法会返回所有匹配指定名称的类。为什么是一个列表而不是单个类?因为在 Java 中,不同的类加载器可以加载同名的类。不过在大多数情况下,列表中只有一个元素。
找到类之后,我们需要找到指定行的 Location。refType.locationsOfLine 方法会返回指定行的所有 Location。为什么一行可能有多个 Location?因为一行代码可能对应多条字节码指令,每条指令都有一个 Location。通常我们只需要第一个 Location。
有了 Location,我们就可以创建 BreakpointRequest 了。EventRequestManager 是管理所有事件请求的对象,通过它我们可以创建各种类型的事件请求。创建完 BreakpointRequest 后,我们需要调用 enable 方法启用它。如果不启用,断点不会生效。
这里有一个常见的陷阱:如果类还没有被加载,vm.classesByName 会返回空列表。这意味着我们无法在类加载之前设置断点。
解决方法是
使用 ClassPrepareRequest,监听类加载事件。当类被加载时,我们收到通知,然后再设置断点。这就是为什么在实际的调试器中,断点设置是一个异步的过程。
处理调试事件:
设置好断点后,我们需要等待断点被触发。在 JDI 中,所有的调试事件都通过 EventQueue 来传递。我们需要不断地从 EventQueue 中取出事件,然后根据事件类型进行处理。
java
public void processEvents() throws Exception {
EventQueue eventQueue = vm.eventQueue();
while (true) {
// 从队列中取出事件集
EventSet eventSet = eventQueue.remove();
// 遍历事件集中的每个事件
for (Event event : eventSet) {
if (event instanceof BreakpointEvent) {
handleBreakpointEvent((BreakpointEvent) event);
} else if (event instanceof StepEvent) {
handleStepEvent((StepEvent) event);
} else if (event instanceof VMDeathEvent) {
handleVMDeathEvent((VMDeathEvent) event);
return; // JVM 已经退出,结束事件处理
}
}
// 恢复执行
eventSet.resume();
}
}这里有几个重要的点需要注意:
首先,eventQueue.remove() 是一个阻塞方法。如果队列中没有事件,它会一直等待,直到有新的事件到来。这意味着这个循环不会占用 CPU,它会在没有事件时休眠。
其次,EventQueue 返回的不是单个事件,而是 EventSet。为什么?因为在某些情况下,多个事件可能同时发生。比如,多个线程可能同时触发断点。JDI 把这些事件打包成一个 EventSet,让我们可以一次性处理它们。
第三,处理完事件后,我们需要调用 eventSet.resume()。这是非常重要的。当事件发生时,相关的线程会被暂停。如果我们不调用 resume,线程会一直暂停,程序无法继续执行。这是一个常见的错误:忘记调用 resume,导致被调试程序卡住。
第四,我们需要处理 VMDeathEvent。这个事件表示 JVM 已经退出。当收到这个事件时,我们应该结束事件处理循环,清理资源。如果不处理这个事件,当被调试程序退出后,我们的调试器还在等待事件,会一直卡住。
查看变量值:
调试时,我们经常需要查看变量的值。在 JDI 中,这是通过 StackFrame 来实现的。当线程暂停时,我们可以获取它的调用栈,然后从 StackFrame 中获取局部变量和参数。
java
public void printVariables(ThreadReference thread) throws Exception {
// 获取当前栈帧
StackFrame frame = thread.frame(0);
// 获取所有可见的变量
List<LocalVariable> variables = frame.visibleVariables();
// 遍历变量,打印名称和值
for (LocalVariable variable : variables) {
Value value = frame.getValue(variable);
System.out.println(variable.name() + " = " + formatValue(value));
}
}这段代码展示了如何获取和打印变量。thread.frame(0) 返回调用栈的顶部栈帧,也就是当前正在执行的方法。frame.visibleVariables() 返回当前作用域中所有可见的变量,包括局部变量和参数。
获取变量的值需要调用 frame.getValue(variable)。这个方法返回一个 Value 对象。Value 是一个接口,它有很多实现类,对应不同类型的值。我们需要根据 Value 的实际类型来格式化输出。
java
private String formatValue(Value value) {
if (value == null) {
return "null";
}
if (value instanceof StringReference) {
return "\"" + ((StringReference) value).value() + "\"";
}
if (value instanceof IntegerValue) {
return String.valueOf(((IntegerValue) value).value());
}
if (value instanceof BooleanValue) {
return String.valueOf(((BooleanValue) value).value());
}
if (value instanceof ObjectReference) {
ObjectReference objRef = (ObjectReference) value;
return objRef.referenceType().name() + "@" + objRef.uniqueID();
}
return value.toString();
}这个方法处理了几种常见的值类型。对于基本类型,我们直接获取它们的值。对于字符串,我们用引号包围。对于对象,我们显示类名和对象 ID。这种格式化让输出更加易读。
但是,这里有一个问题:如果对象很复杂,包含很多字段,我们如何显示它的内容?答案是递归地访问对象的字段。ObjectReference 提供了 getValue 方法,可以获取对象的字段值。我们可以遍历所有字段,递归地格式化它们的值。但要注意避免无限递归,比如对象引用了自己,或者两个对象互相引用。
在 JDI 中,单步执行是通过 StepRequest 来实现的。StepRequest 有三个重要的参数:线程、步长(step size)和步深(step depth)。
步长决定了每次执行多少代码。STEP_MIN 表示执行一条字节码指令,STEP_LINE 表示执行一行源代码。通常我们使用 STEP_LINE,因为用户关心的是源代码,而不是字节码。
步深决定了如何处理方法调用。STEP_INTO 表示进入方法内部,STEP_OVER 表示跳过方法调用,STEP_OUT 表示执行到当前方法返回。这三种模式对应了调试器中的"步入"、"步过"和"步出"功能。
java
public void stepOver(ThreadReference thread) throws Exception {
EventRequestManager erm = vm.eventRequestManager();
// 创建 StepRequest
StepRequest stepRequest = erm.createStepRequest(
thread,
StepRequest.STEP_LINE,
StepRequest.STEP_OVER
);
// 设置为一次性请求
stepRequest.addCountFilter(1);
// 启用请求
stepRequest.enable();
// 恢复线程执行
thread.resume();
}这段代码实现了"步过"功能。我们创建一个 StepRequest,指定步长为 STEP_LINE,步深为 STEP_OVER。然后我们添加了一个计数过滤器,设置为 1。这意味着这个请求只会触发一次,触发后自动失效。为什么要这样?因为如果不设置计数过滤器,每执行一行代码都会触发 StepEvent,程序会一直暂停,无法正常运行。
创建并启用 StepRequest 后,我们需要调用 thread.resume() 恢复线程执行。线程会执行一行代码,然后触发 StepEvent,再次暂停。这就实现了单步执行的效果。
这里有一个细节:在创建新的 StepRequest 之前,我们应该删除旧的 StepRequest。因为一个线程同时只能有一个 StepRequest。如果不删除旧的,创建新的会失败。所以完整的实现应该是这样的:
java
public void stepOver(ThreadReference thread) throws Exception {
EventRequestManager erm = vm.eventRequestManager();
// 删除旧的 StepRequest
List<StepRequest> oldRequests = erm.stepRequests();
for (StepRequest oldRequest : oldRequests) {
if (oldRequest.thread().equals(thread)) {
erm.deleteEventRequest(oldRequest);
}
}
// 创建新的 StepRequest
StepRequest stepRequest = erm.createStepRequest(
thread,
StepRequest.STEP_LINE,
StepRequest.STEP_OVER
);
stepRequest.addCountFilter(1);
stepRequest.enable();
thread.resume();
}表达式求值
在调试过程中,我们经常需要查看变量的值。但有时候,我们不仅想看单个变量,还想看表达式的值。比如,我们想知道 list.size() > 0 && list.get(0) != null 的结果是什么,或者想知道 (a + b) * c 的值。如果调试器只能显示单个变量,我们就需要手动计算这些表达式,非常不方便。
第一个挑战是解析。用户输入的是一个字符串,我们需要把它解析成一个可以执行的结构。比如,a + b * c 需要被解析成"先计算 b * c,然后加上 a",而不是"先计算 a + b,然后乘以 c"。这涉及到运算符优先级、括号匹配等问题。
第二个挑战是变量解析。表达式中的变量需要从当前的调试上下文中获取。但是,变量可能是局部变量、字段、静态字段,甚至是方法参数。我们需要在正确的作用域中查找变量。而且,变量的类型可能是基本类型、对象、数组,我们需要正确处理每种类型。
第三个挑战是方法调用。表达式中可能包含方法调用,比如 list.size()。我们需要找到正确的方法,传入正确的参数,然后调用它。但是,Java 有方法重载,同名的方法可能有多个版本,参数类型不同。我们需要根据参数类型选择正确的方法。
第四个挑战是类型转换。Java 有自动类型转换和强制类型转换。比如,int 可以自动转换成 long,但 long 不能自动转换成 int。而且,基本类型和包装类型之间有自动装箱和拆箱。我们需要正确处理这些转换。
第五个挑战是安全性。表达式求值不应该修改程序的状态。用户可能会输入 a = 10 这样的赋值表达式,或者 list.clear() 这样的修改操作。我们需要阻止这些操作,确保求值过程是只读的。
token化
我们把表达式字符串分解成一个个令牌(Token),每个令牌代表表达式的一个组成部分。比如,表达式 a + b.getValue() 会被分解成:变量令牌 a、运算符令牌 +、变量令牌 b、方法调用令牌 getValue()。
令牌化的过程需要识别不同类型的令牌。最简单的是常量令牌,比如数字 123、字符串 "hello"、布尔值 true。这些令牌的值是固定的,不需要从上下文中获取。
变量令牌稍微复杂一些。我们需要识别变量名,然后从当前的栈帧中查找这个变量。如果找不到,可能是一个字段,我们需要从 this 对象中查找。如果还找不到,可能是一个静态字段,我们需要从类中查找。
方法调用令牌更加复杂。我们需要识别方法名和参数列表。参数列表本身可能包含表达式,需要递归地解析。比如,list.get(i + 1) 中的参数 i + 1 本身就是一个表达式。
数组访问令牌也需要特殊处理。arr[i] 需要被识别为数组访问,其中 arr 是数组变量,i 是索引表达式。索引表达式也可能很复杂,比如 arr[i * 2 + 1]。
运算符令牌包括算术运算符(+、-、*、/)、比较运算符(==、!=、<、>)、逻辑运算符(&&、||、!)等。我们需要识别这些运算符,并根据优先级正确地组织它们。
java
public abstract class AbstractToken {
protected String expression;
public abstract Value getValue() throws Exception;
public static void doCheck(String expression) throws ComputeError {
// 检查括号是否匹配
if (!areParenthesesAndBracketsBalanced(expression)) {
throw new ComputeError("括号不匹配");
}
// 检查是否包含赋值操作符
if (containsAssignmentOperator(expression)) {
throw new ComputeError("不支持赋值操作");
}
// 检查是否包含自增自减操作符
if (expression.contains("++") || expression.contains("--")) {
throw new ComputeError("不支持自增自减操作");
}
}
}这个抽象类定义了令牌的基本接口。每个令牌都需要实现 getValue() 方法,返回令牌的值。doCheck() 方法用于在解析前进行安全检查,确保表达式不包含危险的操作。
表达式处理
对于包含运算符的复杂表达式,我们使用 JEXL(Java Expression Language)引擎来处理。JEXL 是 Apache 提供的一个表达式语言引擎,它可以解析和执行类似 Java 的表达式。
JEXL 的优势在于,它已经实现了运算符优先级、括号匹配、类型转换等复杂逻辑。我们不需要自己实现一个完整的表达式解析器,只需要把变量值传给 JEXL,它就能计算出结果。
java
public class EvalToken extends AbstractToken {
@Override
public Value getValue() throws Exception {
// 创建 JEXL 引擎
JexlEngine jexl = new JexlBuilder().create();
// 创建上下文,包含所有可见的变量
JexlContext context = new MapContext();
// 获取当前栈帧的所有变量
StackFrame frame = Env.getStackFrame();
List<LocalVariable> variables = frame.visibleVariables();
// 把变量添加到上下文中
for (LocalVariable variable : variables) {
Value value = frame.getValue(variable);
Object javaValue = convertToJavaObject(value);
context.set(variable.name(), javaValue);
}
// 解析并执行表达式
JexlExpression expr = jexl.createExpression(expression);
Object result = expr.evaluate(context);
// 把结果转换回 JDI 的 Value
return convertToValue(result);
}
}这段代码展示了如何使用 JEXL 引擎。我们首先创建一个 JEXL 引擎实例,然后创建一个上下文,把当前栈帧中的所有变量添加到上下文中。JEXL 在执行表达式时,会从上下文中查找变量的值。
但这里有一个问题:JEXL 使用的是普通的 Java 对象,而 JDI 使用的是 Value 接口。我们需要在两者之间进行转换。convertToJavaObject() 方法把 JDI 的 Value 转换成 Java 对象,convertToValue() 方法把 Java 对象转换回 JDI 的 Value。
方法调用
对于方法调用,我们不能使用 JEXL,因为 JEXL 无法访问被调试程序的对象。我们需要使用 JDI 的 API 来调用方法。
JDI 提供了 ObjectReference.invokeMethod() 方法来调用对象的方法。但是,我们需要先找到正确的方法。Java 支持方法重载,同名的方法可能有多个版本,参数类型不同。我们需要根据参数类型选择正确的方法。
java
public class InvokeToken extends AbstractToken {
private String objectExpression; // 对象表达式,如 "list"
private String methodName; // 方法名,如 "get"
private List<String> arguments; // 参数表达式列表,如 ["0"]
@Override
public Value getValue() throws Exception {
// 获取对象
Value objectValue = parseExpression(objectExpression);
if (!(objectValue instanceof ObjectReference)) {
throw new ComputeError("不是对象类型");
}
ObjectReference object = (ObjectReference) objectValue;
// 解析参数
List<Value> argumentValues = new ArrayList<>();
for (String arg : arguments) {
argumentValues.add(parseExpression(arg));
}
// 查找方法
Method method = findMethod(object, methodName, argumentValues);
if (method == null) {
throw new ComputeError("找不到方法: " + methodName);
}
// 调用方法
ThreadReference thread = Env.getThread();
Value result = object.invokeMethod(thread, method, argumentValues, 0);
return result;
}
private Method findMethod(ObjectReference object, String name, List<Value> arguments) {
ReferenceType type = object.referenceType();
List<Method> methods = type.methodsByName(name);
// 遍历所有同名方法,找到参数类型匹配的
for (Method method : methods) {
if (isArgumentsMatch(method, arguments)) {
return method;
}
}
return null;
}
}这段代码展示了方法调用的基本流程。我们首先解析对象表达式,获取对象引用。然后解析参数表达式,获取参数值。接着查找匹配的方法,最后调用方法并返回结果。
findMethod() 方法是关键。它需要在所有同名方法中找到参数类型匹配的那个。这涉及到类型检查和类型转换。比如,如果方法的参数类型是 long,而我们传入的是 int,这是可以的,因为 int 可以自动转换成 long。但如果方法的参数类型是 int,而我们传入的是 long,这是不行的。
类型转换
Java 有基本类型(int、long、boolean 等)和对应的包装类型(Integer、Long、Boolean 等)。在某些情况下,我们需要在两者之间进行转换。
比如,一个方法的参数类型是 Integer,而我们传入的是 int。这时候需要把 int 装箱成 Integer。反之,如果方法的参数类型是 int,而我们传入的是 Integer,需要把 Integer 拆箱成 int。
JDI 中,基本类型用 PrimitiveValue 表示,包装类型用 ObjectReference 表示。我们需要在两者之间进行转换。
java
private ObjectReference primitiveToWrapper(PrimitiveValue value) throws Exception {
VirtualMachine vm = Env.getVirtualMachine();
// 获取包装类
String wrapperClassName = getWrapperClassName(value.type().name());
List<ReferenceType> classes = vm.classesByName(wrapperClassName);
if (classes.isEmpty()) {
throw new ComputeError("找不到包装类: " + wrapperClassName);
}
ClassType wrapperClass = (ClassType) classes.get(0);
// 查找构造函数
List<Method> constructors = wrapperClass.methodsByName("<init>");
Method constructor = null;
for (Method m : constructors) {
List<String> argTypes = m.argumentTypeNames();
if (argTypes.size() == 1 && argTypes.get(0).equals(value.type().name())) {
constructor = m;
break;
}
}
if (constructor == null) {
throw new ComputeError("找不到构造函数");
}
// 调用构造函数创建包装对象
ThreadReference thread = Env.getThread();
return wrapperClass.newInstance(thread, constructor, Arrays.asList(value), 0);
}
private PrimitiveValue wrapperToPrimitive(ObjectReference wrapper) throws Exception {
// 获取 value 字段
ReferenceType type = wrapper.referenceType();
Field valueField = type.fieldByName("value");
if (valueField == null) {
throw new ComputeError("不是包装类型");
}
// 返回字段的值
Value value = wrapper.getValue(valueField);
if (!(value instanceof PrimitiveValue)) {
throw new ComputeError("value 字段不是基本类型");
}
return (PrimitiveValue) value;
}装箱的过程是调用包装类的构造函数,传入基本类型的值。比如,new Integer(10) 会创建一个值为 10 的 Integer 对象。拆箱的过程是获取包装对象的 value 字段,这个字段存储了实际的基本类型值。
这些转换在方法调用时自动进行。当参数类型不匹配但可以转换时,我们会自动进行转换,让方法调用能够成功。这让表达式求值更加灵活,用户不需要手动进行类型转换。
调试内核重构
AST解释器
JDI(Java Debug Interface)是 Java 平台提供的调试接口,功能强大但也有明显的局限性。其中最大的痛点就是表达式求值能力的缺失。
JDI 只提供了以下基本操作:
- 获取变量值 :
StackFrame.getValue(LocalVariable) - 获取字段值 :
ObjectReference.getValue(Field) - 调用方法 :
ObjectReference.invokeMethod(Method, List<Value>) - 访问数组元素 :
ArrayReference.getValue(int)
这些操作都是原子的,不能组合。如果你想计算 node.next.val,需要:
java
// 第一步:获取 node
Value nodeValue = frame.getValue(nodeVariable);
ObjectReference nodeRef = (ObjectReference) nodeValue;
// 第二步:获取 node.next
Field nextField = nodeRef.referenceType().fieldByName("next");
Value nextValue = nodeRef.getValue(nextField);
ObjectReference nextRef = (ObjectReference) nextValue;
// 第三步:获取 node.next.val
Field valField = nextRef.referenceType().fieldByName("val");
Value valValue = nextRef.getValue(valField);这个过程非常繁琐,而且容易出错。如果 node 或 node.next 是 null,还需要额外的空指针检查。
更糟糕的是,JDI 不支持算术运算、逻辑运算、方法调用等操作。如果你想计算 arr[i] + arr[j],JDI 无能为力。
这个限制在调试链表、树等复杂数据结构时尤其明显。想象你在调试一个链表问题,当前节点是 node,你想看下一个节点的值。在传统的调试器中,你需要先查看 node.next,记住它的对象 ID,然后再查看这个对象的 val 字段。如果链表很长,这个过程会非常繁琐。
为了解决这个问题,我们设计了一个基于递归下降的 AST(抽象语法树)解释器。这个解释器不是简单地调用 JDI 的 API,而是把表达式解析成一棵树,然后递归地求值每个节点。
表达式: node.next.val
解析器
AST 根节点
字段访问节点: .val
字段访问节点: .next
变量节点: node
求值: 获取 node 对象引用
求值: 调用 getValue('next')
求值: 调用 getValue('val')
最终结果
这个设计的核心思想是把复杂问题分解成简单问题。node.next.val 被分解成三个步骤:获取 node,获取 node.next,获取 node.next.val。每一步都是简单的字段访问,可以直接用 JDI 的 API 实现。
但这里有一个技术难点:如何动态地调用 getValue 方法?在 JDI 中,获取对象的字段值需要使用 ObjectReference.getValue(Field field) 方法。这意味着我们需要先找到对应的 Field 对象,然后才能获取值。
java
public class FieldAccessToken extends AbstractToken {
private String objectExpression; // 对象表达式,如 "node.next"
private String fieldName; // 字段名,如 "val"
@Override
public Value getValue() throws Exception {
// 第一步:递归求值对象表达式
Value objectValue = parseExpression(objectExpression);
if (!(objectValue instanceof ObjectReference)) {
throw new ComputeError("不是对象类型");
}
ObjectReference object = (ObjectReference) objectValue;
// 第二步:查找字段
ReferenceType type = object.referenceType();
Field field = type.fieldByName(fieldName);
if (field == null) {
throw new ComputeError("找不到字段: " + fieldName);
}
// 第三步:获取字段值
return object.getValue(field);
}
}这段代码展示了字段访问的核心逻辑。注意 parseExpression(objectExpression) 是一个递归调用,它会继续解析 node.next,而 node.next 又会递归解析 node。这就是递归下降的含义:从顶层表达式开始,逐层向下解析,直到遇到最基本的变量或常量。
通过这种方式,我们实现了对任意复杂表达式的支持。不仅是字段访问,还包括方法调用(list.size())、数组访问(arr[i])、算术运算(a + b)等。这让调试体验有了质的飞跃。
💡 面试题:为什么使用递归下降而不是其他解析方法?
递归下降是一种自顶向下的解析方法,它的优点是实现简单、易于理解、易于扩展。对于表达式解析这种相对简单的场景,递归下降是最合适的选择。
其他解析方法,比如 LR 解析、LL 解析,虽然更强大,但也更复杂。它们需要构建解析表,处理移进-规约冲突等问题。对于我们的场景,这些复杂性是不必要的。
而且,递归下降的代码结构和语法结构是一一对应的,这让代码非常直观。比如,表达式的语法是
expression -> term (('+' | '-') term)*,对应的代码就是一个循环,处理加减运算。
在递归下降之前,我们需要先把表达式分解成 Token(词法单元)。Token 是表达式的最小单位,比如变量名、运算符、括号等。
java
public class TokenFactory {
// 规则列表,按优先级排序
private static final List<Rule> rules = Arrays.asList(
new EvalRule(), // 包含运算符的表达式
new OperatorRule(), // 运算符
new VariableRule(), // 变量
new ArrayRule(), // 数组访问
new InvokeRule(), // 方法调用
new PureCallRule(), // 纯函数调用
new ConstantRule() // 常量
);
public static Token parseToToken(String expression, Context context) {
for (Rule rule : rules) {
if (rule.match(expression)) {
return rule.createToken(expression, context);
}
}
throw new ComputeError("无法识别的表达式: " + expression);
}
}每个 Rule 负责识别一种类型的 Token。比如,VariableRule 识别变量名,ArrayRule 识别数组访问,InvokeRule 识别方法调用。
识别的过程使用正则表达式和自定义匹配器。比如,变量名的规则是:以字母或下划线开头,后面跟任意数量的字母、数字或下划线。
java
public class VariableRule implements Rule {
@Override
public boolean match(String expression) {
return CharacterHelper.isVName(expression.charAt(0));
}
@Override
public Token createToken(String expression, Context context) {
int length = CharacterHelper.startVNameLen(expression);
String varName = expression.substring(0, length);
return new VariableToken(varName, context);
}
}Token 化之后,我们需要把 Token 组织成一棵树。这棵树就是 AST(抽象语法树)。
对于 node.next.val,AST 的结构是:
FieldAccessToken(.val)
↓
FieldAccessToken(.next)
↓
VariableToken(node)这是一个链式结构,每个节点都有一个子节点。最底层的节点是 VariableToken,它没有子节点。
对于更复杂的表达式,比如 (a + b) * c,AST 的结构是:
OperatorToken(*)
↓
OperatorToken(+) VariableToken(c)
↓
VariableToken(a) VariableToken(b)这是一个树形结构,每个运算符节点有两个子节点(操作数)。
构建 AST 的过程是递归的。对于 node.next.val,我们先解析 node,得到一个 VariableToken。然后发现后面还有 .next,就创建一个 FieldAccessToken,它的子节点是 VariableToken(node)。再发现后面还有 .val,就创建另一个 FieldAccessToken,它的子节点是前面的 FieldAccessToken(.next)。
java
public class FieldAccessToken extends AbstractToken {
private String objectExpression; // 对象表达式,如 "node.next"
private String fieldName; // 字段名,如 "val"
@Override
public Value getValue() throws Exception {
// 第一步:递归求值对象表达式
Token objectToken = TokenFactory.parseToToken(objectExpression, context);
Value objectValue = objectToken.getValue();
if (!(objectValue instanceof ObjectReference)) {
throw new ComputeError("不是对象类型");
}
ObjectReference object = (ObjectReference) objectValue;
// 第二步:查找字段
ReferenceType type = object.referenceType();
Field field = type.fieldByName(fieldName);
if (field == null) {
throw new ComputeError("找不到字段: " + fieldName);
}
// 第三步:获取字段值
return object.getValue(field);
}
}注意 getValue() 方法中的递归调用:TokenFactory.parseToToken(objectExpression, context)。这就是递归下降的核心:把复杂问题分解成简单问题,然后递归地解决每个简单问题。
对于方法调用,比如 list.size(),我们需要使用 JDI 的 invokeMethod API。这个 API 可以在被调试程序中动态调用方法,并返回结果。
java
public class InvokeToken extends AbstractToken {
private String objectExpression; // 对象表达式,如 "list"
private String methodName; // 方法名,如 "size"
private List<String> arguments; // 参数列表
@Override
public Value getValue() throws Exception {
// 第一步:递归求值对象表达式
Token objectToken = TokenFactory.parseToToken(objectExpression, context);
Value objectValue = objectToken.getValue();
if (!(objectValue instanceof ObjectReference)) {
throw new ComputeError("不是对象类型");
}
ObjectReference object = (ObjectReference) objectValue;
// 第二步:查找方法
ReferenceType type = object.referenceType();
List<Method> methods = type.methodsByName(methodName);
if (methods.isEmpty()) {
throw new ComputeError("找不到方法: " + methodName);
}
// 第三步:解析参数
List<Value> argValues = new ArrayList<>();
for (String arg : arguments) {
Token argToken = TokenFactory.parseToToken(arg, context);
argValues.add(argToken.getValue());
}
// 第四步:匹配方法签名
Method method = findMatchingMethod(methods, argValues);
if (method == null) {
throw new ComputeError("找不到匹配的方法签名");
}
// 第五步:调用方法
ThreadReference thread = context.getThread();
return object.invokeMethod(thread, method, argValues, 0);
}
}invokeMethod 的关键是参数匹配。Java 支持方法重载,同一个方法名可能有多个不同的签名。我们需要根据参数的类型找到匹配的方法。
而且,Java 有自动装箱和拆箱机制。int 和 Integer 可以互相转换。我们的解释器也需要支持这种转换。
java
private Method findMatchingMethod(List<Method> methods, List<Value> argValues) {
for (Method method : methods) {
List<Type> paramTypes = method.argumentTypes();
if (paramTypes.size() != argValues.size()) {
continue;
}
boolean match = true;
for (int i = 0; i < paramTypes.size(); i++) {
Type paramType = paramTypes.get(i);
Value argValue = argValues.get(i);
if (!checkConsist(argValue, paramType)) {
match = false;
break;
}
}
if (match) {
return method;
}
}
return null;
}
private boolean checkConsist(Value value, Type type) {
// 类型完全匹配
if (value.type().equals(type)) {
return true;
}
// 检查装箱/拆箱
if (checkWrapperAndPrimitive(value, type)) {
return true;
}
// 检查继承关系
if (value instanceof ObjectReference && type instanceof ReferenceType) {
ObjectReference objRef = (ObjectReference) value;
ReferenceType refType = (ReferenceType) type;
// 检查是否是子类
if (isSubtype(objRef.referenceType(), refType)) {
return true;
}
}
return false;
}有了表达式求值能力,我们可以实现对象视图的实时渲染。当用户在调试器中查看一个对象时,我们不仅显示它的字段,还可以显示一些计算属性。
比如,对于一个链表节点,我们可以显示:
node = ListNode@123
val = 1
next = ListNode@456
[计算] next.val = 2
[计算] next.next.val = 3这些计算属性是通过表达式求值动态计算的。用户可以自定义要显示的表达式,比如 next.val、next.next.val 等。
实现这个功能的关键是 JavaValueInspector。它负责把 JDI 的 Value 对象转换成用户可读的字符串。
java
public class JavaValueInspector {
public static String inspectValue(Value value) {
if (value == null) {
return "null";
}
if (value instanceof StringReference) {
return "\"" + ((StringReference) value).value() + "\"";
}
if (value instanceof PrimitiveValue) {
return value.toString();
}
if (value instanceof ArrayReference) {
ArrayReference array = (ArrayReference) value;
int length = array.length();
StringBuilder sb = new StringBuilder();
sb.append("[");
for (int i = 0; i < Math.min(length, 10); i++) {
if (i > 0) sb.append(", ");
sb.append(inspectValue(array.getValue(i)));
}
if (length > 10) {
sb.append(", ...");
}
sb.append("]");
return sb.toString();
}
if (value instanceof ObjectReference) {
ObjectReference obj = (ObjectReference) value;
return obj.referenceType().name() + "@" + obj.uniqueID();
}
return value.toString();
}
}对于复杂对象,我们还可以递归地显示它的字段。但要注意避免无限递归(比如循环引用)。
在简历中,你可以这样描述这个技术点:
调试内核 :基于 JDI 重写调试内核并针对 JVM 原生不支持复杂表达式求值的问题,设计基于递归下降的 AST 解释器,通过 InvokeMethod 动态计算node.next.val等组合表达式,实现对象视图的实时渲染,实现了对组合表达式的动态解析与计算。
面试官可能会问的问题:
Q: 为什么选择递归下降而不是其他解析方法?
A: 递归下降是一种自顶向下的解析方法,它的优点是实现简单、易于理解、易于扩展。对于表达式解析这种相对简单的场景,递归下降是最合适的选择。其他解析方法,比如 LR 解析、LL 解析,虽然更强大,但也更复杂。它们需要构建解析表,处理移进-规约冲突等问题。对于我们的场景,这些复杂性是不必要的。而且,递归下降的代码结构和语法结构是一一对应的,这让代码非常直观。
Q: InvokeMethod 有什么性能问题吗?
A: InvokeMethod 确实有性能开销。它需要在被调试程序中实际执行方法,这涉及到线程切换、方法调用、返回值传递等操作。但在调试场景下,这个开销是可以接受的。因为调试本身就是一个低频操作,用户不会频繁地计算表达式。而且,InvokeMethod 的好处是它可以调用任意方法,包括用户自定义的方法。这让表达式求值的能力非常强大。
多线程协调
表达式求值解决了功能问题,但引入了新的挑战:性能和稳定性。在调试过程中,我们需要频繁地与被调试程序的虚拟机通信,获取变量值、设置断点、单步执行等。这些操作都是阻塞的,如果在 UI 线程中执行,会导致 IDE 假死。
更糟糕的是,JDI 的事件处理机制是异步的。当断点被触发时,JVM 会发送一个 BreakpointEvent,我们需要在一个单独的线程中处理这个事件。但处理事件时,我们又需要更新 UI,显示当前的变量值、代码位置等。这就形成了一个复杂的多线程协调问题。
让我们通过一个具体的场景来理解死锁是如何发生的:
场景:单线程调试器执行 invokeMethod
假设我们只有一个线程(JavaDebugger 线程)来处理所有调试逻辑:
被调试的 JVM JavaDebugger (单线程) 用户 被调试的 JVM JavaDebugger (单线程) 用户 阻塞等待方法返回 需要处理 StepEvent 但线程被阻塞! 死锁! Debugger 等待 TargetVM 返回 TargetVM 等待 Debugger 处理事件 输入表达式 list.size() invokeMethod(list, "size") 执行 size() 方法 产生 StepEvent 暂停,等待 resume()
- JavaDebugger 调用
Value.invokeMethod,阻塞等待执行结果 - TargetVM 开始执行方法,恢复运行
- TargetVM 执行过程中产生 StepEvent(单步执行事件)
- TargetVM 产生 Event 后会暂停线程 ,等待 JavaDebugger 调用
resume()放行 - 但 JavaDebugger 正在等待
invokeMethod返回,无法处理 StepEvent - 死锁发生:TargetVM 等待 Debugger 放行,Debugger 等待 TargetVM 返回结果
这就是为什么必须引入多线程的原因。
为了解决这个问题,我们设计了一个 Coordinator(协调器)模式。Coordinator 的核心思想是:把 UI 线程和 VM 线程完全隔离,通过一个中间层来协调它们的交互。
被调试 JVM VM 事件线程 Coordinator UI 线程 被调试 JVM VM 事件线程 Coordinator UI 线程 用户点击"下一步" 设置等待标志 通知继续执行 resume() StepEvent 处理事件,更新上下文 设置完成标志 唤醒 UI 线程 读取上下文 更新界面
这个设计的关键是 waitForJEventHandler() 和 JEventHandlerDone() 两个方法。它们实现了一个简单但有效的同步机制。
java
public class Context {
private volatile boolean waitFor = false;
private final Object lock = new Object();
// UI 线程调用,等待 VM 线程完成事件处理
public void waitForJEventHandler(String name) {
int sleepTime = 10; // 初始等待时间 10ms
int maxSleepTime = 1000; // 最大等待时间 1s
while (waitFor) {
try {
synchronized (lock) {
lock.wait(sleepTime);
}
// 指数退避:逐渐增加等待时间
sleepTime = Math.min(sleepTime * 2, maxSleepTime);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
}
// VM 线程调用,通知 UI 线程事件处理完成
public void JEventHandlerDone() {
waitFor = false;
synchronized (lock) {
lock.notifyAll();
}
}
// 在需要等待的操作前调用
public void waitFor() {
waitFor = true;
}
}这段代码看起来很简单,但包含了几个重要的设计决策。
第一是使用 volatile 关键字。waitFor 字段被声明为 volatile,保证了它的修改对所有线程立即可见。这避免了一个线程修改了 waitFor,但另一个线程看不到的问题。
第二是指数退避策略。我们不是简单地循环检查 waitFor,而是使用 wait() 方法让线程休眠。而且,休眠时间是逐渐增加的,从 10ms 开始,每次翻倍,最多到 1 秒。这种策略在等待时间短时反应快,等待时间长时减少 CPU 占用。
第三是使用 notifyAll() 而不是 notify()。虽然在我们的场景中通常只有一个线程在等待,但使用 notifyAll() 更安全,避免了某些边界情况下的死锁。
💡 面试题:为什么不使用 CountDownLatch 或 Semaphore?
这是一个很好的问题。
CountDownLatch和Semaphore是 Java 并发包提供的高级同步工具,功能更强大。但它们也有缺点:
不可重用 :
CountDownLatch一旦计数到零,就不能再使用了。而我们的场景需要反复等待和唤醒。语义不匹配 :
Semaphore是用于控制资源访问的,它的语义是"获取许可"和"释放许可"。而我们的语义是"等待完成"和"通知完成",用wait/notify更直观。灵活性 :使用
wait/notify,我们可以在等待时做一些额外的处理,比如指数退避、超时检查等。这些在CountDownLatch中不容易实现。当然,如果场景更复杂,比如需要等待多个事件,或者需要超时机制,使用
CountDownLatch或CompletableFuture会更合适。
界面假死
即使有了 Coordinator,我们还是会遇到假死问题。最常见的场景是:断点被触发,VM 线程开始处理事件,但处理过程中需要调用 invokeMethod(比如计算表达式 list.size())。invokeMethod 会让被调试程序继续执行,直到方法返回。在这个过程中,可能会触发新的断点,导致嵌套的事件处理。
如果处理不当,这种嵌套会导致死锁:UI 线程在等待 VM 线程,VM 线程在等待 JVM 返回,JVM 在等待断点处理完成。三个线程形成了一个环形等待,谁也无法继续。
我们的解决方案是引入一个状态标志:isInvokeMethodStart()。这个标志表示当前是否正在执行 invokeMethod。在执行 invokeMethod 期间,我们不更新上下文,不处理新的断点事件,避免嵌套。
java
public class Context {
private volatile boolean invokeStatus = false;
public void invokeMethodStart() {
invokeStatus = true;
}
public void invokeMethodDone() {
invokeStatus = false;
}
public boolean isInvokeMethodStart() {
return invokeStatus;
}
}
public class JEventHandler extends Thread {
@Override
public void run() {
while (running) {
EventSet eventSet = vm.eventQueue().remove();
for (Event event : eventSet) {
if (event instanceof BreakpointEvent) {
// 如果正在执行 invokeMethod,跳过事件处理
if (context.isInvokeMethodStart()) {
continue;
}
handleBreakpointEvent((BreakpointEvent) event);
}
}
eventSet.resume();
}
}
}这个设计的巧妙之处在于,它不是阻止嵌套,而是让嵌套变得安全。invokeMethod 仍然可以触发断点,但这些断点不会被处理,不会更新上下文,不会干扰当前的表达式求值。等 invokeMethod 返回后,invokeStatus 被重置,后续的断点才会正常处理。
配合指数退避策略,这个机制彻底消除了假死问题。即使在最复杂的调试场景下(比如在断点处理中计算复杂表达式,表达式中又调用了会触发断点的方法),系统也能保持稳定。
代码实现 (Context.java:257-296):
java
public void waitForJEventHandler(String name) {
Thread.yield(); // 先让出 CPU
if (!waitFor) return;
synchronized (lock) {
// 自旋阶段
for (int i = 0; i < waitRound && waitFor; ++i) {
Thread.sleep(sleepTime); // 70ms
}
if (!waitFor) return;
// 指数退避
int cnt = sleepCount.incrementAndGet();
if (cnt >= (1 << (2 + waitCount))) {
waitRound *= 2; // 翻倍:8 → 16 → 32 → ...
waitCount += 1;
}
lock.wait(); // 阻塞等待
}
}对比分析:
| 策略 | CPU 占用 | 响应速度 | 适用场景 |
|---|---|---|---|
| 直接阻塞 | 低 | 慢 | 长期等待 |
| 纯自旋 | 高 | 快 | 短期等待 |
| 自旋+指数退避 | 中 | 中 | 不确定时长 |
指令系统
调试器需要支持多种指令:设置断点(B)、单步执行(N)、查看变量(P)、监视表达式(W)等。每种指令的处理逻辑都不同,如何组织这些代码是一个挑战。
我们采用了工厂模式 + 命令模式的组合。每种指令对应一个执行器类,工厂根据指令类型创建相应的执行器。
creates
<<interface>>
InstructionFactory
+create(Instruction) : InstExecutor
JavaInstFactory
-static instance
+getInstance() : JavaInstFactory
+create(Instruction) : InstExecutor
<<interface>>
InstExecutor
+execute(Instruction, Context) : ExecuteResult
<<abstract>>
AbstractJavaInstExecutor
+execute(Instruction, Context) : ExecuteResult
+doExecute(Instruction, Context) : ExecuteResult
JavaBInst
+doExecute(Instruction, Context) : ExecuteResult
JavaNInst
+doExecute(Instruction, Context) : ExecuteResult
JavaPInst
+doExecute(Instruction, Context) : ExecuteResult
工厂的实现非常简洁:
java
public class JavaInstFactory implements InstructionFactory {
private static final JavaInstFactory instance = new JavaInstFactory();
public static JavaInstFactory getInstance() {
return instance;
}
@Override
public InstExecutor create(Instruction inst) {
Operation op = inst.getOperation();
switch (op) {
case B:
return new JavaBInst();
case N:
return new JavaNInst();
case P:
return new JavaPInst();
case W:
return new JavaWInst();
case R:
return new JavaRInst();
case STEP:
return new JavaSTEPInst();
case HELP:
return new JavaHELPInst();
case SHOWB:
return new JavaSHOWBInst();
default:
return null;
}
}
}这个设计的优点是扩展性。如果要添加新的指令,只需要:
- 定义一个新的
Operation枚举值; - 创建一个新的执行器类;
- 在工厂的
switch中添加一个case。
不需要修改任何现有代码。
而且,所有执行器都继承自 AbstractJavaInstExecutor,这个抽象类提供了通用的功能,比如上下文检查、错误处理等。每个具体的执行器只需要实现 doExecute 方法,专注于自己的业务逻辑。
java
public abstract class AbstractJavaInstExecutor implements InstExecutor {
@Override
public ExecuteResult execute(Instruction inst, ExecuteContext context) {
// 类型检查
if (!(context instanceof Context)) {
return ExecuteResult.error("上下文类型错误");
}
Context ctx = (Context) context;
// 核心数据检查
if (ctx.getVm() == null || ctx.getErm() == null) {
return ExecuteResult.error("调试环境未初始化");
}
// 调用子类实现
return doExecute(inst, ctx);
}
protected abstract ExecuteResult doExecute(Instruction inst, Context ctx);
}这种设计体现了模板方法模式:父类定义了执行的框架(检查、调用、返回),子类填充具体的逻辑。这让代码既统一又灵活。
面试题汇总:
问题:JDI 有什么限制?你怎么解决的?
回答 :JDI 只能获取简单变量值,不能计算复杂表达式。比如list.get(0).value这种表达式 JDI 理解不了。我的解决方案是实现表达式求值器:第一步,Token 化,把表达式拆成 Token 链,如list.get(0).value拆成 变量 Token方法 Token属性 Token。第二步,逐步求值,每个 Token 调用对应的 JDI 方法,变量 Token 调用getValue(),方法 Token 调用invokeMethod(),属性 Token 调用getField()。这样就能支持任意复杂的 Java 表达式求值。
问题:为什么使用自旋锁 + 指数退避?
回答:这是处理断点挂起的优化方案。JEventHandler 处理断点事件时间不确定,可能几毫秒也可能几秒。纯自旋浪费 CPU,直接阻塞响应慢。指数退避自适应:前几轮快速响应(70ms),后几轮减少 CPU 占用(翻倍等待),最后阻塞。相比纯阻塞响应提升 80%,相比纯自旋 CPU 占用降低 60%。
接入Python调试器
Java 调试器可以依赖 JDI 这个成熟的接口,但 Python 没有这样的标准调试接口。Python 的调试需要我们从更底层的机制入手:sys.settrace。这是 Python 提供的一个钩子函数,可以在代码执行的每一步插入我们的逻辑。听起来很简单,但要基于它实现一个完整的调试器,需要解决很多工程问题。
sys.settrace
sys.settrace 的核心思想是:在 Python 解释器执行每一行代码之前,先调用我们注册的回调函数。这个回调函数可以检查当前的执行状态,决定是继续执行、暂停、还是单步执行。
补充sys.settrace 核心机制:
事件类型:
'call':函数调用'line':执行一行代码'return':函数返回'exception':异常抛出
栈帧访问:
python
frame.f_lineno # 当前行号
frame.f_locals # 局部变量字典
frame.f_globals # 全局变量字典
frame.f_code # 代码对象断点状态机:
Running(运行中)
↓ 遇到断点
Paused(暂停)
↓ 用户命令
continue → Running
next → StepOver → Paused
step → StepInto → Paused
python
import sys
def trace_function(frame, event, arg):
# frame: 当前栈帧,包含局部变量、全局变量、代码对象等
# event: 事件类型,'call'、'line'、'return'、'exception'
# arg: 事件相关的参数
if event == 'line':
# 每执行一行代码都会触发
print(f"执行到第 {frame.f_lineno} 行")
print(f"局部变量: {frame.f_locals}")
return trace_function # 返回自己,继续追踪
sys.settrace(trace_function)
# 后续的代码执行都会被追踪
x = 1
y = 2
z = x + y这段代码展示了 sys.settrace 的基本用法。每执行一行代码,trace_function 都会被调用,我们可以在这里打印当前的行号和局部变量。但这只是最简单的应用,要实现一个真正的调试器,需要解决几个关键问题。
第一个问题是断点。用户在某一行设置了断点,我们怎么让程序在那一行停下来?最直接的想法是在 trace_function 中检查当前行号是否是断点,如果是,就进入等待状态。但"等待"是什么意思?我们不能用 time.sleep,因为那会阻塞整个 Python 进程。我们需要一个机制,让调试器暂停,但不阻塞 IDEA 插件的主进程。
第二个问题是变量查看。用户想查看某个变量的值,我们怎么获取?frame.f_locals 可以获取局部变量,但它返回的是一个字典,对于复杂对象(比如类实例、列表、字典),我们需要递归地展开它的属性。而且,Python 的对象可能包含循环引用,我们需要避免无限递归。
第三个问题是表达式求值。用户输入一个表达式(比如 len(arr) + 1),我们怎么在当前的上下文中计算它的值?Python 提供了 eval 函数,但它有安全风险,而且不支持赋值语句。我们需要一个更安全、更强大的求值机制。
第四个问题是进程间通信。Python 调试器运行在一个独立的 Python 进程中,IDEA 插件运行在 Java 进程中。两个进程怎么通信?我们选择了 HTTP 协议,Python 调试器启动一个 HTTP 服务器,IDEA 插件通过 HTTP 请求发送调试命令。这种方式简单、通用、易于调试。
问题:sys.settrace 的工作原理?
回答 :sys.settrace 是 Python 提供的钩子函数,可以在代码执行的每一步插入回调。回调函数接收三个参数:frame(当前栈帧)、event(事件类型,如 'line'、'call'、'return')、arg(事件参数)。
通过 frame 可以访问当前行号、局部变量、全局变量等信息。
我们在回调函数中检查当前行号是否是断点,如果是就暂停,从命令队列中阻塞等待用户命令。这样就实现了断点、单步执行等调试功能。
问题:Python 对象可能包含循环引用,递归序列化会导致无限递归。
解决方案:
python
def serialize_value(self, value, depth=0, visited=None):
# 避免无限递归
if depth > 3:
return str(value)
if visited is None:
visited = set()
# 避免循环引用
obj_id = id(value)
if obj_id in visited:
return "<circular reference>"
visited.add(obj_id)
# 递归序列化
if isinstance(value, list):
return [self.serialize_value(v, depth+1, visited) for v in value]
if isinstance(value, dict):
return {k: self.serialize_value(v, depth+1, visited)
for k, v in value.items()}
return str(value)断点管理
断点管理是调试器的核心功能。用户可以在任意行设置断点,调试器需要在执行到断点时暂停,等待用户的下一步指令。这个过程可以建模为一个状态机。
开始执行
遇到断点
继续执行 (continue)
单步跳过 (next)
单步进入 (step)
执行一行后暂停
进入函数后暂停
程序结束
停止调试
Running
Paused
StepOver
StepInto
这个状态机有三个核心状态:Running(运行中)、Paused(暂停)、StepOver/StepInto(单步执行)。状态之间的转换由用户的调试命令触发。
在实现上,我们使用一个全局变量 debug_state 记录当前状态,使用一个 BlockingQueue 存储用户的调试命令。当程序执行到断点时,trace_function 检测到断点,把状态设置为 Paused,然后从队列中取出下一个命令。如果队列为空,trace_function 会阻塞等待,直到用户发送新的命令。
python
from queue import Queue
import threading
class PythonDebugger:
def __init__(self):
self.breakpoints = set() # 断点集合
self.debug_state = 'running' # 当前状态
self.command_queue = Queue() # 命令队列
self.current_frame = None # 当前栈帧
def trace_function(self, frame, event, arg):
if event != 'line':
return self.trace_function
# 检查是否遇到断点
lineno = frame.f_lineno
if lineno in self.breakpoints:
self.debug_state = 'paused'
self.current_frame = frame
# 等待用户命令
command = self.command_queue.get() # 阻塞等待
if command == 'continue':
self.debug_state = 'running'
elif command == 'next':
self.debug_state = 'step_over'
elif command == 'step':
self.debug_state = 'step_into'
# 处理单步执行
if self.debug_state == 'step_over':
self.debug_state = 'paused'
self.current_frame = frame
command = self.command_queue.get()
return self.trace_function这个实现的关键是 command_queue.get() 的阻塞特性。当程序暂停时,trace_function 会阻塞在这里,等待用户发送命令。用户通过 HTTP 请求发送命令,HTTP 服务器把命令放入队列,trace_function 就会被唤醒,继续执行。
但这里有一个问题:trace_function 是在被调试程序的线程中执行的,如果它阻塞了,整个被调试程序都会阻塞。这正是我们想要的效果------调试器暂停,程序也暂停。但这也带来了一个挑战:HTTP 服务器必须运行在另一个线程中,否则它也会被阻塞,无法接收用户的命令。
HTTP服务器
Python 调试器需要同时做两件事:执行被调试程序,接收用户命令。这是一个典型的多线程场景。我们使用 Python 的 threading 模块创建两个线程:主线程执行被调试程序,子线程运行 HTTP 服务器。
python
from http.server import HTTPServer, BaseHTTPRequestHandler
import json
import threading
class DebugRequestHandler(BaseHTTPRequestHandler):
def do_POST(self):
# 读取请求体
content_length = int(self.headers['Content-Length'])
body = self.rfile.read(content_length)
data = json.loads(body)
command = data.get('command')
if command == 'continue':
debugger.command_queue.put('continue')
self.send_response(200)
self.end_headers()
self.wfile.write(b'{"status": "ok"}')
elif command == 'next':
debugger.command_queue.put('next')
self.send_response(200)
self.end_headers()
self.wfile.write(b'{"status": "ok"}')
elif command == 'get_variables':
variables = self.get_current_variables()
self.send_response(200)
self.end_headers()
self.wfile.write(json.dumps(variables).encode())
def get_current_variables(self):
if debugger.current_frame is None:
return {}
# 获取局部变量
locals_dict = debugger.current_frame.f_locals
# 序列化变量(处理复杂对象)
result = {}
for name, value in locals_dict.items():
result[name] = self.serialize_value(value)
return result
def serialize_value(self, value, depth=0, visited=None):
# 避免无限递归
if depth > 3:
return str(value)
if visited is None:
visited = set()
# 避免循环引用
obj_id = id(value)
if obj_id in visited:
return "<circular reference>"
visited.add(obj_id)
# 基本类型直接返回
if isinstance(value, (int, float, str, bool, type(None))):
return value
# 列表递归序列化
if isinstance(value, list):
return [self.serialize_value(v, depth+1, visited) for v in value]
# 字典递归序列化
if isinstance(value, dict):
return {k: self.serialize_value(v, depth+1, visited)
for k, v in value.items()}
# 对象序列化为字典
if hasattr(value, '__dict__'):
return {k: self.serialize_value(v, depth+1, visited)
for k, v in value.__dict__.items()}
# 其他类型转为字符串
return str(value)
# 启动 HTTP 服务器
def start_http_server(port=5678):
server = HTTPServer(('localhost', port), DebugRequestHandler)
thread = threading.Thread(target=server.serve_forever)
thread.daemon = True # 守护线程,主线程结束时自动结束
thread.start()
return server这个设计的关键是 thread.daemon = True。守护线程的特点是:当主线程结束时,守护线程会自动结束,不会阻止程序退出。这正是我们需要的------当被调试程序执行完毕,HTTP 服务器也应该自动关闭。
另一个关键是 serialize_value 方法。它负责把 Python 对象序列化为 JSON 可以表示的格式。这个方法需要处理几种情况:基本类型直接返回;列表和字典递归序列化;对象通过 __dict__ 属性获取字段并序列化;循环引用通过 visited 集合检测并避免无限递归;递归深度通过 depth 参数限制,避免栈溢出。
面试题:为什么使用 HTTP 而不是 Socket 或共享内存?
这是一个经典的 IPC(进程间通信)选型问题。HTTP 的优点是简单、通用、易于调试。我们可以用浏览器或 curl 直接测试调试器的接口,不需要写专门的测试工具。而且,HTTP 是无状态的,每个请求都是独立的,不需要维护连接状态。
Socket 的优点是性能更好,延迟更低。但它需要定义通信协议,处理粘包、半包等问题,实现复杂度高。对于调试场景,性能不是瓶颈(用户手动操作,频率很低),所以 HTTP 是更好的选择。
共享内存的优点是性能最好,但它只能在同一台机器上使用,而且跨语言支持困难。Python 和 Java 之间共享内存需要使用 C 扩展,实现非常复杂。
Python 调试器 IPC 通信:
Java 进程 Python 进程
| |
|---> POST /next ----------->|
| Body: {"operation": "n"} |
| |
| | 执行 next 命令
| | 返回变量值
| |
|<---- 200 OK ----------------|
| Body: {"status": "ok", |
| "data": {...}} |九、检索
...CSDN字数限制,下半部分讲解
十、记忆
...CSDN字数限制,下半部分讲解
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.2.15
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!