《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 什么是SAM3视频分割?
- 实战步骤:使用SAM3分割视频目标
-
- [1. 环境准备与库导入](#1. 环境准备与库导入)
- [2. 定义辅助函数](#2. 定义辅助函数)
- [3. 加载SAM3模型](#3. 加载SAM3模型)
- [4. 视频预处理:转为视频帧](#4. 视频预处理:转为视频帧)
- [5. 读取视频帧](#5. 读取视频帧)
- [6. 初始化视频处理会话](#6. 初始化视频处理会话)
- [7. 方法一:使用文本提示分割目标](#7. 方法一:使用文本提示分割目标)
- [8. 在整个视频中跟踪分割目标](#8. 在整个视频中跟踪分割目标)
- [9. 移除指定目标](#9. 移除指定目标)
- [10. 方法二:使用点提示添加指定目标](#10. 方法二:使用点提示添加指定目标)
- [11. 方法三:使用正负样本点精细分割](#11. 方法三:使用正负样本点精细分割)
- 总结
引言
在计算机视觉领域,视频目标分割一直是备受关注的任务。SAM3(Segment Anything Model 3)作为新一代分割模型,凭借其强大的提示交互能力,让视频目标分割变得前所未有的简单。之前的4篇文章已经介绍了许多关于SAM3分割图像与视频案例:
【SAM3教程-1】SAM3 使用文本提示进行图像分割详细步骤与示例【附源码】
【SAM3教程-2】使用正负样本提示框一键分割图片中的相似目标详细步骤与示例
【SAM3教程-3】使用提示点 + 提示框精准 "圈" 出指定目标,正负样本搭配更高效!【附源码】
【SAM3教程-4】使用文本精准分割视频里的目标,附完整代码教程
本文将详细介绍如何使用SAM3通过文本和点提示来实现视频中指定目标的精准分割与跟踪。包括以下内容:
使用文本提示分割并跟踪视频指定类别目标;
通过ID移除指定目标;
通过提示点添加指定目标;
通过正负样本提示点,精细分割出指定目标;
SAM3分割小男孩全身以及小女孩的衣服区域效果如下:
【注:示例中没有对小女孩进行完整分割,主要是用于演示SAM3的精细区域分割】

什么是SAM3视频分割?
SAM3是Meta推出的第三代"万物分割"模型,相比前代,它在视频处理方面进行了专门优化,支持多种提示方式(文本、点、框等)与视频目标的交互,能够:
- 通过文本描述直接分割视频中的目标
- 利用点提示精确指定需要分割的区域
- 对分割目标进行跨帧跟踪
- 支持目标的添加与移除操作
实战步骤:使用SAM3分割视频目标
1. 环境准备与库导入
首先需要导入必要的库,包括视频处理、深度学习框架和SAM3相关工具:
python
import cv2
import torch
import numpy as np
import supervision as sv
from pathlib import Path
from PIL import Image
from typing import Optional
from IPython.display import Video
from sam3.model_builder import build_sam3_video_predictor
import os
import glob
import matplotlib.pyplot as plt
from sam3.visualization_utils import (
load_frame,
prepare_masks_for_visualization,
visualize_formatted_frame_output,
)2. 定义辅助函数
为了方便后续处理,我们定义两个实用函数:
python
# 设置图片标题与坐标字体大小
plt.rcParams["axes.titlesize"] = 12
plt.rcParams["figure.titlesize"] = 12
# 从0到最后一帧传播需要分割的目标
def propagate_in_video(predictor, session_id):
# 从第0帧传播到视频结束
outputs_per_frame = {}
for response in predictor.handle_stream_request(
request=dict(
type="propagate_in_video",
session_id=session_id,
)
):
outputs_per_frame[response["frame_index"]] = response["outputs"]
return outputs_per_frame
# 将绝对坐标转换为相对坐标(0-1范围)
def abs_to_rel_coords(coords, IMG_WIDTH, IMG_HEIGHT, coord_type="point"):
if coord_type == "point":
return [[x / IMG_WIDTH, y / IMG_HEIGHT] for x, y in coords]
elif coord_type == "box":
return [
[x / IMG_WIDTH, y / IMG_HEIGHT, w / IMG_WIDTH, h / IMG_HEIGHT]
for x, y, w, h in coords
]
else:
raise ValueError(f"Unknown coord_type: {coord_type}")3. 加载SAM3模型
加载预训练的SAM3模型,需要指定模型权重文件和BPE(字节对编码)文件路径:
python
# 使用GPU加速
DEVICES = [torch.cuda.current_device()]
# 初始化模型并加载预训练权重
checkpoint_path = "models/sam3.pt" # 模型文件路径
bpe_path = "assets/bpe_simple_vocab_16e6.txt.gz" # BPE文件路径
predictor = build_sam3_video_predictor(
checkpoint_path=checkpoint_path,
bpe_path=str(bpe_path),
gpus_to_use=DEVICES
)4. 视频预处理:转为视频帧
原视频为:

使用ffmpeg工具将视频转换为一系列图片帧,方便按索引访问:
python
# 视频路径
SOURCE_VIDEO = "assets/videos/bedroom.mp4"
# 视频帧输出目录
output_dir = 'output2'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 使用ffmpeg分割视频为帧
!ffmpeg -i {SOURCE_VIDEO} -q:v 2 -start_number 0 output2/%05d.jpg
5. 读取视频帧
将分割好的视频帧读取到内存中,用于后续处理和可视化:
python
# 设置视频帧目录
video_path = f"output2"
# 加载视频帧用于可视化
if isinstance(video_path, str) and video_path.endswith(".mp4"):
cap = cv2.VideoCapture(video_path)
video_frames_for_vis = []
while True:
ret, frame = cap.read()
if not ret:
break
video_frames_for_vis.append(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
cap.release()
else:
video_frames_for_vis = glob.glob(os.path.join(video_path, "*.jpg"))
# 按帧索引排序
try:
video_frames_for_vis.sort(
key=lambda p: int(os.path.splitext(os.path.basename(p))[0])
)
except ValueError:
print("falling back to lexicographic sort.")
video_frames_for_vis.sort()6. 初始化视频处理会话
创建一个视频处理会话,让模型加载并准备处理视频:
python
response = predictor.handle_request(
request=dict(
type="start_session",
resource_path=SOURCE_VIDEO,
)
)
session_id = response["session_id"] # 会话ID用于后续操作会话ID是后续所有操作的标识,如果需要重新开始,可以使用下面reset_session重置会话:【否则可能会出现推理不准确】
python
_ = predictor.handle_request(
request=dict(
type="reset_session",
session_id=session_id,
)
)7. 方法一:使用文本提示分割目标
只需输入文本描述,SAM3就能自动识别并分割视频中对应的目标:
python
# 设置要分割的目标文本描述
prompt_text_str = "person" # 这里以"人"为例
frame_idx = 0 # 在第0帧添加文本提示
# 发送文本提示请求
response = predictor.handle_request(
request=dict(
type="add_prompt",
session_id=session_id,
frame_index=frame_idx,
text=prompt_text_str,
)
)
out = response["outputs"] # 获取分割结果可视化第一帧的分割结果:
python
plt.close("all")
visualize_formatted_frame_output(
frame_idx,
video_frames_for_vis,
outputs_list=[prepare_masks_for_visualization({frame_idx: out})],
titles=["SAM 3 Dense Tracking outputs"],
figsize=(6, 4),
)
8. 在整个视频中跟踪分割目标
基于第一帧的分割结果,让模型在整个视频中跟踪并分割目标:
python
# 从第0帧传播到视频结束并收集所有输出
outputs_per_frame = propagate_in_video(predictor, session_id)
# 格式化输出以实现可视化
outputs_per_frame = prepare_masks_for_visualization(outputs_per_frame)
# 每60帧可视化一次结果
vis_frame_stride = 60
plt.close("all")
for frame_idx in range(0, len(outputs_per_frame), vis_frame_stride):
visualize_formatted_frame_output(
frame_idx,
video_frames_for_vis,
outputs_list=[outputs_per_frame],
titles=["SAM 3 Dense Tracking outputs"],
figsize=(6, 4),
)
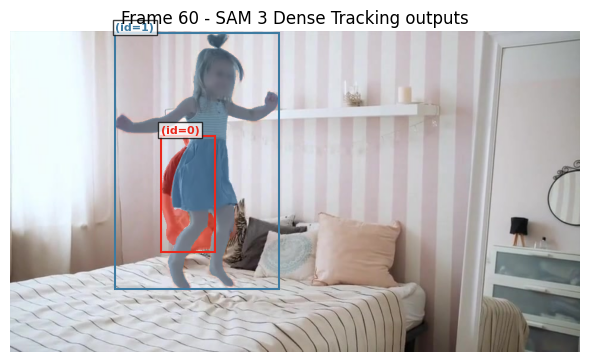


9. 移除指定目标
如果需要移除某个已分割的目标,可以通过目标ID进行操作,下面我们以移除上面画面中ID为1的小女孩为例:
python
obj_id = 1 # 指定需要移除的目标ID
response = predictor.handle_request(
request=dict(
type="remove_object",
session_id=session_id,
obj_id=obj_id,
)
)
# 重新传播并可视化结果(验证是否已移除)
outputs_per_frame = propagate_in_video(predictor, session_id)
outputs_per_frame = prepare_masks_for_visualization(outputs_per_frame)每隔60帧显示一次推理结果,我们可以发现,之前ID=1的小女孩已经没有被进行分割。




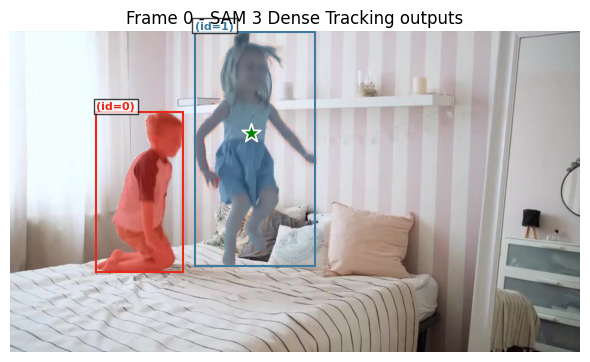
10. 方法二:使用点提示添加指定目标
除了文本,还可以通过点提示来指定需要分割的目标,适合更精确的控制:
下面我们再将上面移除的ID为1的目标,通过添加点提示的方式再重新添加回来。
python
# 获取图像尺寸
sample_img = Image.fromarray(load_frame(video_frames_for_vis[0]))
IMG_WIDTH, IMG_HEIGHT = sample_img.size
# 设置点提示参数
frame_idx = 0
obj_id = 1 # 要添加的目标ID
points_abs = np.array([[406, 170]]) # 正样本点(需要分割的区域)
labels = np.array([1]) # 1表示正样本点,0表示负样本点
# 转换为相对坐标并发送请求
points_tensor = torch.tensor(
abs_to_rel_coords(points_abs, IMG_WIDTH, IMG_HEIGHT, coord_type="point"),
dtype=torch.float32,
)
points_labels_tensor = torch.tensor(labels, dtype=torch.int32)
response = predictor.handle_request(
request=dict(
type="add_prompt",
session_id=session_id,
frame_index=frame_idx,
points=points_tensor,
point_labels=points_labels_tensor,
obj_id=obj_id,
)
)
11. 方法三:使用正负样本点精细分割
SAM3可以通过结合正负样本点,可以实现更精细的目标分割,下面我们重新修正一下上述ID=1的目标。我们不对整个人进行区域分割,只分割出衣服区域。
python
# 设置多个样本点(结合正负样本)
frame_idx = 0
obj_id = 1
points_abs = np.array([
[421, 155], # 正样本点(目标区域)
[420, 202], # 负样本点(非目标区域)
[400, 107], # 负样本点(非目标区域)
])
labels = np.array([1, 0, 0]) # 1:正样本,0:负样本
# 转换坐标并发送请求
points_tensor = torch.tensor(
abs_to_rel_coords(points_abs, IMG_WIDTH, IMG_HEIGHT, coord_type="point"),
dtype=torch.float32,
)
points_labels_tensor = torch.tensor(labels, dtype=torch.int32)
response = predictor.handle_request(
request=dict(
type="add_prompt",
session_id=session_id,
frame_index=frame_idx,
points=points_tensor,
point_labels=points_labels_tensor,
obj_id=obj_id,
)
)每隔60帧显示一次推理结果,我们可以发现,ID=1的目标已经被设置为仅分割衣服,没有对整个人进行区域分割。
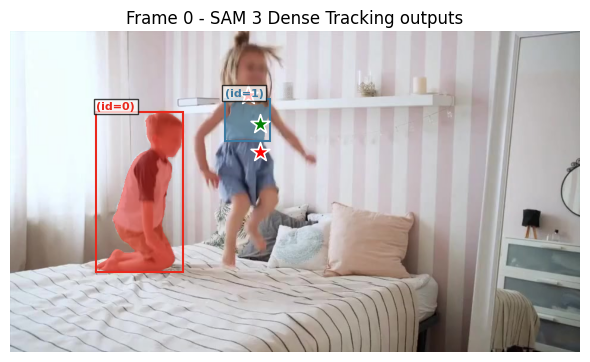





总结
SAM3通过灵活的提示机制,极大简化了视频目标分割的流程。无论是使用文本描述快速定位目标,还是通过点提示进行精细分割,都能获得出色的效果。这种交互方式使得即使是非专业用户也能轻松实现复杂的视频分割任务,为视频编辑、目标跟踪等应用场景提供了强大的技术支持。
通过本文介绍的方法,你可以快速上手SAM3的视频分割功能,根据实际需求选择合适的提示方式,实现精准的视频目标分割与跟踪。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!