SAM 3通过引入可提示概念分割(PCS)任务,构建了统一的检测-分割-跟踪框架,包括:(1)存在头(Presence Head)机制 实现识别与定位解耦,通过全局存在标记判断概念是否出现,各个对象查询专注于条件定位问题,有效处理开放词汇场景下的多实例检测;(2)双编码器-解码器架构采用共享感知编码器(PE)的检测器和跟踪器设计,检测器基于DETR范式通过融合编码器将多模态提示(文本、图像样例的位置/标签/视觉特征)与图像特征进行交叉注意融合,跟踪器继承SAM 2架构使用 记忆库和Masklets(时空掩码)维护对象身份;(3)检测-传播-匹配流程 结合IoU匹配、掩码片段检测分数和定期重新提示的双重时序消歧策略,解决拥挤场景中的跟踪漂移和遮挡问题;(4)四阶段渐进式训练(PE预训练→检测器预训练→检测器微调→冻结骨干训练跟踪器)配合困难负样本 显著提升模型对相似概念的区分能力;(5)构建人机协作数据引擎,通过AI验证器(掩码验证MV和完整性验证EV)自动筛选高质量标注,并主动挖掘失败案例进行迭代改进,最终产生包含400万独特概念的SA-Co数据集,使模型在LVIS等基准上实现零样本mask AP 48.8,相比现有最佳系统提升超过2倍性能。
We present Segment Anything Model (SAM) 3, a unified model that detects, segments, and tracks objects in images and videos based on concept prompts, which we define as either short noun phrases (e.g., "yellow school bus"), image exemplars, or a combination of both. Promptable Concept Segmentation (PCS) takes such prompts and returns segmentation masks and unique identities for all matching object instances. To advance PCS, we build a scalable data engine that produces a high-quality dataset with 4M unique concept labels, including hard negatives, across images and videos. Our model consists of an image-level detector and a memory-based video tracker that share a single backbone. Recognition and localization are decoupled with a presence head, which boosts detection accuracy. SAM 3 doubles the accuracy of existing systems in both image and video PCS, and improves previous SAM capabilities on visual segmentation tasks. We open source SAM 3 along with our new Segment Anything with Concepts (SA-Co) benchmark for promptable concept segmentation.
【翻译】我们提出了Segment Anything Model (SAM) 3,这是一个统一的模型,能够基于概念提示在图像和视频中检测、分割和跟踪对象,我们将概念提示定义为简短的名词短语(例如"黄色校车")、图像样例或两者的组合。可提示概念分割(PCS)接受这些提示并返回所有匹配对象实例的分割掩码和唯一标识。为了推进PCS,我们构建了一个可扩展的数据引擎,该引擎在图像和视频中生成包含400万个独特概念标签的高质量数据集,包括困难负样本。我们的模型由图像级检测器和基于记忆的视频跟踪器组成,它们共享单一的骨干网络。识别和定位通过存在头进行解耦,这提高了检测精度。SAM 3在图像和视频PCS上的准确率是现有系统的两倍,并改进了之前SAM在视觉分割任务上的能力。我们开源了SAM 3以及我们新的Segment Anything with Concepts (SA-Co)可提示概念分割基准。
The ability to find and segment anything in a visual scene is foundational for multimodal AI, powering applications in robotics, content creation, augmented reality, data annotation, and broader sciences. The SAM series (Kirillov et al., 2023; Ravi et al., 2024) introduced the promptable segmentation task for images and videos, focusing on Promptable Visual Segmentation (PVS) with points, boxes or masks to segment a single object per prompt. While these methods achieved a breakthrough, they did not address the general task of finding and segmenting all instances of a concept appearing anywhere in the input (e.g., all "cats" in a video).
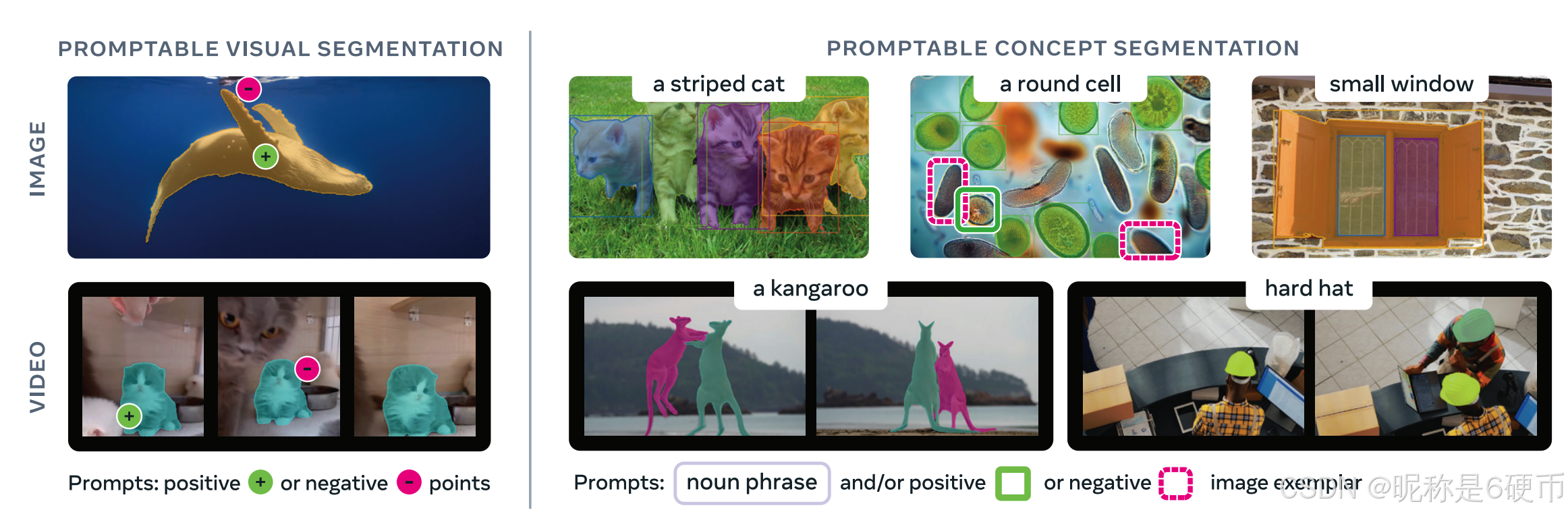
Figure 1 SAM 3 improves over SAM 2 on promptable visual segmentation with clicks (left) and introduces the new promptable concept segmentation capability (right). Users can segment all instances of a visual concept specified by a short noun phrase, image exemplars (positive or negative), or a combination of both.
【翻译】图1 SAM 3在基于点击的可提示视觉分割方面相比SAM 2有所改进(左),并引入了新的可提示概念分割能力(右)。用户可以通过简短的名词短语、图像样例(正样例或负样例)或两者的组合来指定视觉概念,从而分割该概念的所有实例。
Figure 2 Examples of SAM 3 improving segmentation of open-vocabulary concepts compared to OWLv2 (Minderer et al., 2024), on the SA-Co benchmark. See §F.6.1 for additional SAM 3 outputs.
【翻译】图2 SAM 3在SA-Co基准测试上相比OWLv2(Minderer等,2024)改进开放词汇概念分割的示例。更多SAM 3输出结果请参见§F.6.1。
To fill this gap, we present SAM 3, a model that achieves a step change in promptable segmentation in images and videos, improving PVS relative to SAM 2 and setting a new standard for Promptable Concept Segmentation (PCS). We formalize the PCS task (§2) as taking text and/or image exemplars as input, and predicting instance and semantic masks for every single object matching the concept, while preserving object identities across video frames (see Fig. 1). To focus on recognizing atomic visual concepts, we constrain text to simple noun phrases (NPs) such as "red apple" or "striped cat". While SAM 3 is not designed for long referring expressions or queries requiring reasoning, we show that it can be straightforwardly combined with a Multimodal Large Language Model (MLLM) to handle more complex language prompts. Consistent with previous SAM versions, SAM 3 is fully interactive, allowing users to resolve ambiguities by adding refinement prompts to guide the model towards their intended output.
Our model (§3) consists of a detector and a tracker that share a vision encoder (Bolya et al., 2025). The detector is a DETR-based (Carion et al., 2020) model conditioned on text, geometry, and image exemplars. To address the challenge of open-vocabulary concept detection, we introduce a separate presence head to decouple recognition and localization, which is especially effective when training with challenging negative phrases. The tracker inherits the SAM 2 transformer encoder-decoder architecture, supporting video segmentation and interactive refinement. The decoupled design for detection and tracking avoids task conflict, as the detector needs to be identity agnostic, while the tracker's main objective is to separate identities in the video.
To unlock major performance gains, we build a human- and model-in-the-loop data engine (§4) that annotates a large and diverse training dataset. We innovate upon prior data engines in three key ways: (i) media curation: we curate more diverse media domains than past approaches that rely on homogeneous web sources, (ii) label curation: we significantly increase label diversity and difficulty by leveraging an ontology and multimodal LLMs as "AI annotators" to generate noun phrases and hard negatives, (iii) label verification: we double annotation throughput by fine-tuning MLLMs to be effective "AI verifiers" that achieve near-human accuracy.
Starting from noisy media-phrase-mask pseudo-labels, our data engine checks mask quality and exhaustivity using both human and AI verifiers, filtering out correctly labeled examples and identifying challenging error cases. Human annotators then focus on fixing these errors by manually correcting masks. This enables us to annotate high-quality training data with 4M unique phrases and 52M masks, and a synthetic dataset with 38M phrases and 1.4B masks. We additionally create the Segment Anything with Concepts (SA-Co) benchmark for PCS (§5) containing 207K unique concepts with exhaustive masks in 120K images and 1.7K videos, > 50 × >50\times >50× more concepts than existing benchmarks.
【翻译】从噪声媒体-短语-掩码伪标签开始,我们的数据引擎使用人类和AI验证器检查掩码质量和完整性,过滤出正确标记的样例并识别具有挑战性的错误案例。然后人类标注员专注于通过手动纠正掩码来修复这些错误。这使我们能够标注包含400万个独特短语和5200万个掩码的高质量训练数据,以及包含3800万个短语和14亿个掩码的合成数据集。我们还为PCS创建了Segment Anything with Concepts (SA-Co)基准测试(§5),包含在12万张图像和1700个视频中的20.7万个独特概念的完整掩码,比现有基准测试多 > 50 × >50\times >50×个概念。
Our experiments (§6) show that SAM 3 sets a new state-of-the-art in promptable segmentation, e.g., reaching a zero-shot mask AP of 48.8 on LVIS vs. the current best of 38.5, surpassing baselines on our new SACo benchmark by at least 2 × \times × (see examples in Fig. 2), and improving upon SAM 2 on visual prompts. Ablations (§A) verify that the choice of backbone, novel presence head, and adding hard negatives all boost results, and establish scaling laws on the PCS task for both our high-quality and synthetic datasets. We open-source the SA-Co benchmark and release the SAM 3 checkpoints and inference code. On an H200 GPU, SAM 3 runs in 30 ms for a single image with 100+ detected objects. In video, the inference latency scales with the number of objects, sustaining near real-time performance for ∼ 5 \sim5 ∼5 concurrent objects. We review related work in §7; next, we dive into the task.
Figure 3 Illustration of supported initial and optional interactive refinement prompts in the PCS task.
【翻译】图3 PCS任务中支持的初始和可选交互式细化提示的说明。
2 Promptable Concept Segmentation (PCS) 可提示概念分割
We define the Promptable Concept Segmentation task as follows: given an image or short video ( ≤ \leq ≤ 30 secs), detect, segment and track all instances of a visual concept specified by a short text phrase, image exemplars, or a combination of both. We restrict concepts to those defined by simple noun phrases (NPs) consisting of a noun and optional modifiers. Noun-phrase prompts (when provided) are global to all frames of the image/video, while image exemplars can be provided on individual frames as positive or negative bounding boxes to iteratively refine the target masks (see Fig. 3).
All prompts must be consistent in their category definition, or the model's behavior is undefined; e.g., "fish" cannot be refined with subsequent exemplar prompts of just the tail; instead the text prompt should be updated. Exemplar prompts are particularly useful when the model initially misses some instances, or when the concept is rare.
Our vocabulary includes any simple noun phrase groundable in a visual scene, which makes the task intrinsically ambiguous. There can be multiple interpretations of phrases arising from polysemy ("mouse" device vs. animal), subjective descriptors ("cozy", "large"), vague or context-dependent phrases that may not even be groundable ("brand identity"), boundary ambiguity (whether 'mirror' includes the frame) and factors such as occlusion and blur that obscure the extent of the object. While similar issues appear in large closed-vocabulary corpora (e.g., LVIS (Gupta et al., 2019)), they are alleviated by carefully curating the vocabulary and setting a clear definition of all the classes of interest. We address the ambiguity problem by collecting test annotations from three experts, adapting the evaluation protocol to allow multiple valid interpretations (§E.3), designing the data pipeline/guidelines to minimize ambiguity in annotation, and an ambiguity module in the model (§C.2).
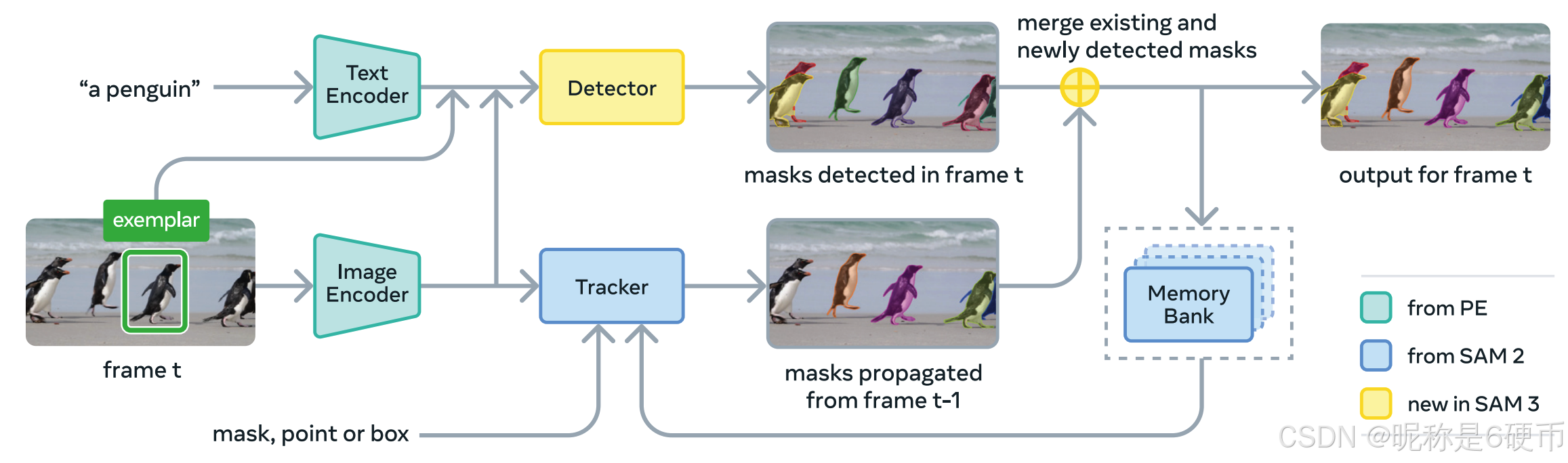
SAM 3 is a generalization of SAM 2, supporting the new PCS task (§2) as well as the PVS task. It takes concept prompts (simple noun phrases, image exemplars) or visual prompts (points, boxes, masks) to define the objects to be (individually) segmented spatio-temporally. Image exemplars and visual prompts can be iteratively added on individual frames to refine the target masks---false positive and false negative objects can be removed or added respectively using image exemplars and an individual mask(let) can be refined using PVS in the style of SAM 2. Our architecture is broadly based on the SAM and (M)DETR (Carion et al., 2020; Kamath et al., 2021) series. Fig. 4 shows the SAM 3 architecture, consisting of a dual encoder-decoder transformer---a detector for image-level capabilities---which is used in combination with a tracker and memory for video. The detector and tracker ingest vision-language inputs from an aligned Perception Encoder (PE) backbone (Bolya et al., 2025). We present an overview below, see §C for details.
Detector Architecture. The architecture of the detector follows the general DETR paradigm. The image and text prompt are first encoded by PE and image exemplars, if present, are encoded by an exemplar encoder. We refer to the image exemplar tokens and text tokens jointly as "prompt tokens". The fusion encoder then accepts the unconditioned embeddings from the image encoder and conditions them by cross-attending to the prompt tokens. The fusion is followed by a DETR-like decoder, where learned object queries cross-attend to the conditioned image embeddings from the fusion encoder.
Figure 4 SAM 3 architecture overview. See Fig. 10 for a more detailed diagram.
【翻译】图4 SAM 3架构概述。详细图表见图10。
Each decoder layer predicts a classification logit for each object query (in our case, a binary label of whether the object corresponds to the prompt), and a delta from the bounding box predicted by the previous level, following Zhu et al. (2020). We use box-region-positional bias (Lin et al., 2023) to help focalize the attention on each object, but unlike recent DETR models, we stick to vanilla attention. During training, we adopt dual supervision from DAC-DETR (Hu et al., 2023), and the Align loss (Cai et al., 2024). The mask head is adapted from MaskFormer (Cheng et al., 2021). In addition, we also have a semantic segmentation head, which predicts a binary label for every pixel in the image, indicating whether or not it corresponds to the prompt. See § C \S\mathrm{C} §C for details.
【翻译】每个解码器层为每个对象查询预测一个分类logit(在我们的情况下,是一个二进制标签,表示对象是否对应于提示),以及与前一层预测的边界框的增量,遵循Zhu等(2020)的方法。我们使用框-区域-位置偏置(Lin等,2023)来帮助将注意力聚焦在每个对象上,但与最近的DETR模型不同,我们坚持使用原始注意力。在训练期间,我们采用来自DAC-DETR(Hu等,2023)的双重监督和Align损失(Cai等,2024)。掩码头改编自MaskFormer(Cheng等,2021)。此外,我们还有一个语义分割头,它为图像中的每个像素预测一个二进制标签,指示它是否对应于提示。详细信息见 § C \S\mathrm{C} §C。
Presence Token. It can be difficult for each of the proposal queries to both recognize (what) and localize (where) an object in the image/frame. For the recognition component, contextual cues from the entire image are important. However, forcing proposal queries to understand the global context can be counterproductive, as it conflicts with the inherently local nature of the localization objective. We decouple the recognition and localization steps by introducing a learned global presence token. This token is solely responsible for predicting whether the target concept in the form of a noun phrase (NP) is present in the image/frame, i.e. p ( N P p(\mathrm{NP} p(NP is present in input). Each proposal query q i q_{i} qi only needs to solve the localization problem p ( q i p(q_{i} p(qi is a match | NP is present in input). The final score for each proposal query is the product of its own score and the presence score.
【翻译】存在标记。对于每个提议查询来说,同时识别(什么)和定位(在哪里)图像/帧中的对象可能是困难的。对于识别组件,来自整个图像的上下文线索很重要。然而,强制提议查询理解全局上下文可能适得其反,因为这与定位目标固有的局部性质相冲突。我们通过引入一个学习的全局存在标记来解耦识别和定位步骤。该标记仅负责预测名词短语(NP)形式的目标概念是否存在于图像/帧中,即 p ( N P p(\mathrm{NP} p(NP is present in input)。每个提议查询 q i q_{i} qi只需要解决定位问题 p ( q i p(q_{i} p(qi is a match | NP is present in input)。每个提议查询的最终得分是其自身得分与存在得分的乘积。
【解析】存在标记机制用于解决目标检测中的一个矛盾:识别任务需要全局上下文信息来理解对象的语义特征,而定位任务需要局部精确性来确定对象的空间位置。传统方法让每个对象查询同时承担这两个任务,导致优化目标的冲突。SAM 3通过任务解耦将这两个问题分离:全局存在标记专门负责概念级别的存在性判断,它需要综合整个图像的信息来确定目标概念是否出现;而各个提议查询则专注于条件定位问题,即在已知概念存在的前提下确定具体的空间位置。这种设计其实是条件概率的思想: p ( N P p(\mathrm{NP} p(NP is present in input)表示概念存在的先验概率, p ( q i p(q_{i} p(qi is a match | NP is present in input)表示在概念存在条件下的定位概率。最终得分的乘积形式确保只有当概念确实存在且定位准确时,查询才会获得高分。解耦不仅提高了模型的性能,还增强了可解释性,因为可以分别分析识别和定位的准确性。
Image Exemplars and Interactivity. SAM 3 supports image exemplars, given as a pair---a bounding box and an associated binary label (positive or negative)---which can be used in isolation or to supplement the text prompt. The model then detects all the instances that match the prompt. For example, given a positive bounding box on a dog, the model will detect all dogs in the image. This is different from the PVS task in SAM 1 and 2, where a visual prompt yields only a single object instance. Each image exemplar is encoded separately by the exemplar encoder using an embedding for the position, an embedding for the label, and ROI-pooled visual features, then concatenated and processed by a small transformer. The resulting prompt is concatenated to the text prompt to comprise the prompt tokens. Image exemplars can be interactively provided based on errors in current detections to refine the output.
Tracker and Video Architecture. Given a video and a prompt P P P , we use the detector and a tracker (see Fig. 4) to detect and track objects corresponding to the prompt throughout the video. On each frame, the detector finds new objects O t \mathcal{O}{t} Ot and the tracker propagates masklets M t − 1 \mathcal{M}{t-1} Mt−1 (spatial-temporal masks) from frames at the previous time t − 1 t-1 t−1 to their new locations M ^ t \hat{\mathcal{M}}{t} M^t on the current frame at time t t t . We use a matching function to associate propagated masklets M ^ t \hat{\mathcal{M}}{t} M^t with new object masks emerging in the current frame O t \mathcal{O}_{t} Ot ,
M ^ t = p r o p a g a t e ( M t − 1 ) , O t = detect ( I t , P ) , M t = match − a n d − u p d a t e ( M ^ t , O t ) . \hat{\boldsymbol{\mathcal{M}}}{t}=\mathrm{propagate}\left(\boldsymbol{\mathcal{M}}{t-1}\right),\quad\boldsymbol{\mathcal{O}}{t}=\operatorname*{detect}\left(\boldsymbol{I}{t},\boldsymbol{P}\right),\quad\boldsymbol{\mathcal{M}}{t}=\operatorname*{match}{-}\mathrm{and}{-}\mathrm{update}\left(\hat{\boldsymbol{\mathcal{M}}}{t},\boldsymbol{\mathcal{O}}_{t}\right). M^t=propagate(Mt−1),Ot=detect(It,P),Mt=−matchand−update(M^t,Ot).
【翻译】跟踪器和视频架构。给定视频和提示 P P P,我们使用检测器和跟踪器(见图4)来检测和跟踪整个视频中对应于提示的对象。在每一帧上,检测器找到新对象 O t \mathcal{O}{t} Ot,跟踪器将masklets M t − 1 \mathcal{M}{t-1} Mt−1(时空掩码)从前一时刻 t − 1 t-1 t−1的帧传播到当前时刻 t t t帧上的新位置 M ^ t \hat{\mathcal{M}}{t} M^t。我们使用匹配函数将传播的masklets M ^ t \hat{\mathcal{M}}{t} M^t与当前帧中出现的新对象掩码 O t \mathcal{O}_{t} Ot关联。
【解析】视频架构采用检测器-跟踪器双模块协同工作的设计,能有效处理视频序列中对象的时序连续性和空间变化性。检测器负责在每个独立帧上识别符合提示条件的新对象,而跟踪器则维护对象在时间维度上的一致性标识。Masklets概念是SAM 3在视频处理中的核心创新,它将传统的二维空间掩码扩展为三维时空掩码,能够同时编码对象的空间边界和时序演化信息。传播机制 M ^ t = p r o p a g a t e ( M t − 1 ) \hat{\boldsymbol{\mathcal{M}}}{t}=\mathrm{propagate}\left(\boldsymbol{\mathcal{M}}{t-1}\right) M^t=propagate(Mt−1)基于光流估计、特征匹配或运动预测等技术,将前一帧的对象掩码投影到当前帧的预期位置。检测过程 O t = detect ( I t , P ) \boldsymbol{\mathcal{O}}{t}=\operatorname*{detect}\left(\boldsymbol{I}{t},\boldsymbol{P}\right) Ot=detect(It,P)在当前帧上独立执行概念检测,不依赖历史信息,这样设计的优势是能够发现新出现的对象实例,避免跟踪漂移导致的目标丢失。匹配和更新函数 M t = match − a n d − u p d a t e ( M ^ t , O t ) \boldsymbol{\mathcal{M}}{t}=\operatorname*{match}{-}\mathrm{and}{-}\mathrm{update}\left(\hat{\boldsymbol{\mathcal{M}}}{t},\boldsymbol{\mathcal{O}}_{t}\right) Mt=match−and−update(M^t,Ot)是整个系统的关键组件,它需要解决数据关联问题:确定哪些传播的masklets与哪些新检测的对象对应,处理对象的出现、消失、遮挡和重新出现等复杂情况。这种双路径设计的优势在于结合了跟踪的时序连续性和检测的鲁棒性,既能保持对象身份的一致性,又能适应对象外观和场景的动态变化。
Tracking an Object with SAM 2 Style Propagation. A masklet is initialized for every object detected on the first frame. Then, on each subsequent frame, the tracker module predicts the new masklet locations M ^ t \hat{\mathcal{M}}{t} M^t of those already-tracked objects based on their previous locations M t − 1 \mathcal{M}{t-1} Mt−1 through a single-frame propagation step similar to the video object segmentation task in SAM 2. The tracker shares the same image/frame encoder (PE backbone) as the detector. After training the detector, we freeze PE and train the tracker as in SAM 2, including a prompt encoder, mask decoder, memory encoder, and a memory bank that encodes the object's appearance using features from the past frames and conditioning frames (frames where the object is first detected or user-prompted). The memory encoder is a transformer with self-attention across visual features on the current frame and cross-attention from the visual features to the spatial memory features in the memory bank. We describe details of our video approach in §C.3.
【翻译】使用SAM 2风格传播跟踪对象。为第一帧上检测到的每个对象初始化一个掩码片段。然后,在每个后续帧上,跟踪器模块基于那些已跟踪对象的先前位置 M t − 1 \mathcal{M}{t-1} Mt−1,通过类似于SAM 2中视频对象分割任务的单帧传播步骤来预测新的掩码片段位置 M ^ t \hat{\mathcal{M}}{t} M^t。跟踪器与检测器共享相同的图像/帧编码器(PE骨干网络)。在训练检测器之后,我们冻结PE并像SAM 2中一样训练跟踪器,包括提示编码器、掩码解码器、记忆编码器和记忆库,记忆库使用来自过去帧和条件帧(对象首次被检测到或用户提示的帧)的特征来编码对象的外观。记忆编码器是一个transformer,在当前帧的视觉特征上进行自注意力,并从视觉特征到记忆库中的空间记忆特征进行交叉注意力。我们在§C.3中描述视频方法的详细信息。
【解析】SAM 3的跟踪机制继承了SAM 2的核心设计思想,但在多对象跟踪场景下进行了扩展。掩码片段(masklet)的概念是时空分割的基本单元,它不仅包含空间位置信息,还携带时间连续性约束。初始化过程在第一帧建立所有目标对象的基准表示,这些表示将作为后续帧跟踪的参考模板。单帧传播机制的核心是预测函数 M ^ t = f ( M t − 1 ) \hat{\mathcal{M}}{t} = f(\mathcal{M}{t-1}) M^t=f(Mt−1),它基于前一帧的掩码位置来估计当前帧的掩码位置。这种逐帧传播的方式能够处理对象的渐进式运动和形变,避免全局优化的计算复杂性。共享编码器架构的设计确保检测和跟踪模块之间的特征一致性,维持跟踪的稳定性。冻结感知编码器的训练策略采用了迁移学习的思想,先训练检测器获得良好的视觉表示能力,然后固定这些表示来训练跟踪器,这样可以避免跟踪训练过程中破坏已经学好的视觉特征。记忆库机制是跟踪系统的核心,它维护了每个对象在历史帧中的外观特征,包括过去帧的一般外观信息和条件帧的关键外观信息。条件帧通常是对象首次出现或用户明确标注的帧,这些帧提供了最可靠的对象表示。记忆编码器的双重注意力机制:自注意力机制处理当前帧内的特征关系,帮助理解对象在当前帧中的完整表示;交叉注意力机制则建立当前帧特征与历史记忆特征之间的对应关系,实现时间维度上的特征匹配和传播。
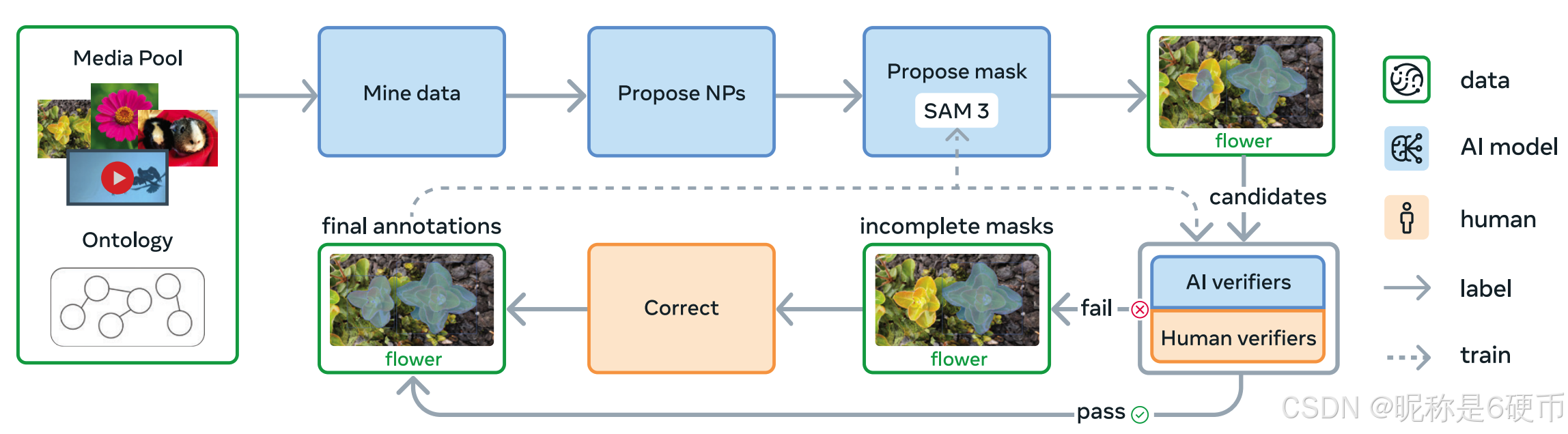
Figure 5 Overview of the final SAM 3 data engine. See § E . 1 \S\mathrm{E.1} §E.1 for details of collected data.
【翻译】图5 最终SAM 3数据引擎概述。收集数据的详细信息见 § E . 1 \S\mathrm{E.1} §E.1。
During inference, we only retain frames where the object is confidently present in the memory bank. The mask decoder is a two-way transformer between the encoder hidden states and the output tokens. To handle ambiguity, we predict three output masks for every tracked object on each frame along with their confidence, and select the most confident output as the predicted mask on the current frame.
Matching and Updating Based on Detections. After obtaining the tracked masks M ^ t \hat{\mathcal{M}}{t} M^t , we match them with the current frame detections O t \mathcal{O}{t} Ot through a simple IoU based matching function (§C.3) and add them to M t \mathcal{M}_{t} Mt on the current frame. We further spawn new masklets for all newly detected objects that are not matched. The merging might suffer from ambiguities, especially in crowded scenes. We address this with two temporal disambiguation strategies outlined next.
【翻译】基于检测的匹配和更新。在获得跟踪掩码 M ^ t \hat{\mathcal{M}}{t} M^t后,我们通过简单的基于IoU的匹配函数(§C.3)将它们与当前帧检测 O t \mathcal{O}{t} Ot进行匹配,并将它们添加到当前帧的 M t \mathcal{M}_{t} Mt中。我们进一步为所有未匹配的新检测对象生成新的掩码片段。合并可能会遇到歧义性问题,特别是在拥挤场景中。我们通过接下来概述的两种时序消歧策略来解决这个问题。
【解析】匹配和更新机制是视频对象跟踪系统的数据关联模块,负责建立时间维度上的对象一致性映射。通过计算两个区域的交集与并集的比值来评估它们的相似程度。在这个上下文中, M ^ t \hat{\mathcal{M}}{t} M^t代表从前一帧传播而来的预测掩码位置,而 O t \mathcal{O}{t} Ot代表当前帧上独立检测到的新对象。匹配过程实质上是解决一个二分图匹配问题:每个传播掩码需要找到最佳的检测对象进行关联,或者确定没有合适的匹配对象。成功匹配的掩码对会被合并到最终的 M t \mathcal{M}_{t} Mt中,这个过程不仅更新了对象的空间位置,还维持了其时序身份标识。新掩码片段的生成机制确保系统能够处理动态场景中新出现的对象,避免因为只依赖传播而错过新目标。拥挤场景中的歧义性问题主要源于多个对象在空间上的重叠和遮挡,这会导致IoU匹配出现多对一或一对多的冲突情况。时序消歧策略的引入是为了利用时间维度的连续性约束来解决这些空间匹配的不确定性,通过分析对象在多个时间步长上的行为模式来做出更可靠的关联决策。
First, we use temporal information in the form of a masklet detection score (§C.3) to measure how consistently a masklet is matched to a detection within a temporal window (based on the number of past frames where it was matched to a detection). If a masklet's detection score falls below a threshold, we suppress it. Second, we use the detector outputs to resolve specific failure modes of the tracker due to occlusions or distractors. We periodically re-prompt the tracker with high-confidence detection masks O t \mathcal{O}{t} Ot , replacing the tracker's own predictions M ^ t \hat{\mathcal{M}}{t} M^t . This ensures that the memory bank has recent and reliable references (other than the tracker's own predictions).
【翻译】首先,我们使用掩码片段检测分数(§C.3)形式的时序信息来测量掩码片段在时间窗口内与检测匹配的一致性(基于它与检测匹配的过去帧数)。如果掩码片段的检测分数低于阈值,我们就抑制它。其次,我们使用检测器输出来解决由于遮挡或干扰物导致的跟踪器特定失效模式。我们定期用高置信度检测掩码 O t \mathcal{O}{t} Ot重新提示跟踪器,替换跟踪器自己的预测 M ^ t \hat{\mathcal{M}}{t} M^t。这确保记忆库具有最新和可靠的参考(而不是跟踪器自己的预测)。
【解析】第一种时序消歧策略基于统计一致性原理,通过量化掩码片段在历史时间窗口内的匹配稳定性来评估其可靠性。掩码片段检测分数实际上是一个时序置信度度量,它统计了该掩码片段在过去若干帧中成功与检测结果匹配的频率。这种设计基于假设:真实的对象轨迹应该在时间上保持相对稳定的检测响应,而由噪声、误检或跟踪漂移产生的虚假轨迹往往表现出不一致的匹配模式。阈值抑制机制起到了轨迹质量控制的作用,自动清理那些可能由于跟踪错误而产生的低质量轨迹。第二种策略针对跟踪系统的固有局限性:纯粹基于传播的跟踪方法容易受到遮挡、快速运动、外观变化等因素的影响而产生累积误差。定期重新提示机制通过引入独立的检测信息来打破这种误差累积的循环,高置信度检测掩码 O t \mathcal{O}{t} Ot提供了当前帧上最可靠的对象位置估计。替换操作 M ^ t ← O t \hat{\mathcal{M}}{t} \leftarrow \mathcal{O}_{t} M^t←Ot实质上是一种自适应校正机制,当检测器的置信度足够高时,系统会选择相信检测结果而非跟踪预测。记忆库的更新策略确保长期跟踪的稳定性:通过定期注入高质量的检测结果,记忆库能够维持对象外观模型的准确性,避免因为持续依赖可能有偏差的跟踪预测而导致的特征漂移问题。
Instance Refinement with Visual Prompts. After obtaining the initial set of masks (or masklets), SAM 3 allows refining individual masks(lets) using positive and negative clicks. Specifically, given the user clicks, we apply the prompt encoder to encode them, and feed the encoded prompt into the mask decoder to predict an adjusted mask. In videos the mask is then propagated across the entire video to obtain a refined masklet.
Training Stages. We train SAM 3 in four stages that progressively add data and capabilities: 1) Perception Encoder (PE) pre-training, 2) detector pre-training, 3) detector fine-tuning, and 4) tracker training with a frozen backbone. See §C.4.1 for details.
Achieving a step change in PCS with SAM 3 requires training on a large, diverse set of concepts and visual domains, beyond existing datasets (see Fig. 12). We build an efficient data engine that iteratively generates annotated data via a feedback loop with SAM 3, human annotators, and AI annotators, actively mining media-phrase pairs on which the current version of SAM 3 fails to produce high-quality training data to further improve the model. By delegating certain tasks to AI annotators---models that match or surpass human accuracy---we more than double the throughput compared to a human-only annotation pipeline. We develop the data engine in four phases, with each phase increasing the use of AI models to steer human effort to the most challenging failure cases, alongside expanding visual domain coverage. Phases 1-3 focus only on images, with Phase 4 expanding to videos. We describe the key steps here; details and metrics are in §D.
Figure 6 Example video (top) and images (bottom) from SA-Co with annotated phrases and instance masks/IDs.
【翻译】图6 来自SA-Co的示例视频(上)和图像(下),带有标注的短语和实例掩码/ID。
Data Engine Components (Fig. 5). Media inputs (image or video) are mined from a large pool with the help of a curated ontology. An AI model proposes noun phrases (NPs) describing visual concepts, followed by another model (e.g., SAM 3) that generates candidate instance masks for each proposed NP. The proposed masks are verified by a two-step process: first, in Mask Verification (MV) annotators accept or reject masks based on their quality and relevance to the NP. Second, in Exhaustivity Verification ( E V ) (E V) (EV) annotators check if all instances of the NP have been masked in the input. Any media-NP pairs that did not pass the exhaustivity check are sent to a manual correction stage, where humans add, remove or edit masks (using SAM 1 in a browser based tool), or use "group" masks for small, hard to separate objects. Annotators may reject ungroundable or ambiguous phrases.
Phase 1: Human Verification. We first randomly sample images and NP proposal with a simple captioner and parser. The initial mask proposal model is SAM 2 prompted with the output of an off-the-shelf open-vocabulary detector, and initial verifiers are human. In this phase, we collected 4.3M image-NP pairs as the initial SA-Co/HQ dataset. We train SAM 3 on this data and use it as the mask proposal model for the next phase.
Phase 2: Human + \pmb{+} + AI Verification. In this next phase, we use human accept/reject labels from the MV and EV tasks collected in Phase 1 to fine-tune Llama 3.2 (Dubey et al., 2024) to create AI verifiers that automatically perform the MV and EV tasks. These models receive image-phrase-mask triplets and output multiple-choice ratings of mask quality or exhaustivity. This new auto-verification process allows our human effort to be focused on the most challenging cases. We continue to re-train SAM 3 on newly collected data and update it 6 times. As SAM 3 and AI verifiers improve, a higher proportion of labels are auto-generated, further accelerating data collection. The introduction of AI verifiers for MV and EV roughly doubles the data engine's throughput vs. human annotators. We refer to §A.4 for detailed analysis of how AI verifiers improve the data engine's throughput. We further upgrade the NP proposal step to a Llama-based pipeline that also proposes hard negative NPs adversarial to SAM 3. Phase 2 adds 122M image-NP pairs to SA-Co/HQ.
Phase 3: Scaling and Domain Expansion. In the third phase, we use AI models to mine increasingly challenging cases and broaden domain coverage in SA-Co/HQ to 15 datasets (Fig. 15). A domain is a unique distribution of text and visual data. In new domains, the MV AI verifier performs well zero-shot, but the EV AI verifier needs to be improved with modest domain-specific human supervision. We also expand concept coverage to long-tail, fine-grained concepts by extracting NPs from the image alt-text where available and by mining concepts from a 22.4M node SA-Co ontology (§D.2) based on Wikidata (17 top-level categories, 72 sub-categories). We iterate SAM 3 training 7 times and AI verifiers 3 times, and add 19.5M image-NP pairs to SA-Co/HQ.
Phase 4: Video Annotation. This phase extends the data engine to video. We use a mature image SAM 3 to collect targeted quality annotations that capture video-specific challenges. The data mining pipeline applies scene/motion filters, content balancing, ranking, and targeted searches. Video frames are sampled (randomly or by object density) and sent to the image annotation flow (from phase 3). Masklets (spatio-temporal masks) are produced with SAM 3 (now extended to video) and post-processed via deduplication and removal of trivial masks. Because video annotation is more difficult, we concentrate humans on likely failures by favoring clips with many crowded objects and tracking failures. The collected video data SA-Co/VIDEO consists of 52.5K videos and 467K masklets. See §D.6 for details.
Training Data. We collect three image datasets for the PCS task: (i) SA-Co/HQ, the high-quality image data collected from the data engine in phases 1-4, (ii) SA-Co/SYN, a synthetic dataset of images labeled by a mature data engine (phase 3) without human involvement, and (iii) SA-Co/EXT, 15 external datasets that have instance mask annotations, enriched with hard negatives using our ontology pipeline. Notably in the SA-Co/HQ dataset we annotate 5.2M images and 4M unique NPs, making it the largest high-quality open-vocab segmentation dataset. We also annotate a video dataset, SA-Co/VIDEO, containing 52.5K videos and 24.8K unique NPs, forming 134K video-NP pairs. The videos on average have 84.1 frames at 6 fps. See § E . 1 \S\mathrm{E.1} §E.1 for details including full statistics, comparison with existing datasets and the distribution of concepts.
SA-Co Benchmark. The SA-Co evaluation benchmark has 207K unique phrases, 121K images and videos, and over 3M media-phrase pairs with hard negative labels to test open-vocabulary recognition. It has 4 splits: SA-Co/Gold has seven domains and each image-NP pair is annotated by three different annotators (used to measure human performance); SA-Co/Silver has ten domains and only one human annotation per image-NP pair; SA-Co/Bronze and SA-Co/Bio are nine existing datasets either with existing mask annotations or masks generated by using boxes as prompts to SAM 2. The SA-Co/VEval benchmark has three domains and one annotator per video-NP pair. See Tab. 28 for dataset statistics and Fig. 6 for example annotations.
Metrics. We aim to measure the usefulness of the model in downstream applications. Detection metrics such as average precision (AP) do not account for calibration, which means that models can be difficult to use in practice. To remedy this, we only evaluate predictions with confidence above 0.5, effectively introducing a threshold that mimics downstream usages and enforces good calibration. The PCS task can be naturally split into two sub-tasks, localization and classification. We evaluate localization using positive micro F1 ( p m F 1 \mathrm{pmF_{1}} pmF1 ) on positive media-phrase pairs with at least one ground-truth mask. Classification is measured with image-level Matthews Correlation Coefficient (IL_MCC) which ranges in − 1 , 1 -1,1−1,1 and evaluates binary prediction at the image level ("is the object present?") without regard for mask quality. Our main metric, classification-gated F1 ( c g F 1 \mathrm{(cgF_{1}} (cgF1 ), combines these as follows: c g F 1 = 100 ∗ p m F 1 ∗ I L _ M C C \mathrm{cgF_{1}=100*p m F_{1}*I L\_M C C} cgF1=100∗pmF1∗IL_MCC . Full definitions are in §E.3.
【翻译】指标。我们旨在测量模型在下游应用中的有用性。检测指标如平均精度(AP)不考虑校准,这意味着模型在实践中可能难以使用。为了解决这个问题,我们只评估置信度高于0.5的预测,有效地引入了一个阈值,模拟下游使用并强制良好的校准。PCS任务可以自然地分为两个子任务:定位和分类。我们使用正样本微观F1( p m F 1 \mathrm{pmF_{1}} pmF1)在至少有一个真实掩码的正样本媒体-短语对上评估定位。分类使用图像级马修斯相关系数(IL_MCC)测量,范围在 − 1 , 1 -1,1−1,1,在图像级别评估二元预测("对象是否存在?"),不考虑掩码质量。我们的主要指标,分类门控F1( c g F 1 \mathrm{cgF_{1}} cgF1),将这些结合如下: c g F 1 = 100 ∗ p m F 1 ∗ I L _ M C C \mathrm{cgF_{1}=100*p m F_{1}*I L\_M C C} cgF1=100∗pmF1∗IL_MCC。完整定义见§E.3。
Handling Ambiguity. We collect 3 annotations per NP on SA-Co/Gold. We measure oracle accuracy comparing each prediction to all ground truths and selecting the best score. See §E.3.
We evaluate SAM 3 across image and video segmentation, few-shot adaptation to detection and counting benchmarks, and segmentation with complex language queries with SAM3+ MLLM. We also show a subset of ablations, with more in §A. References, more results and details are in §F.
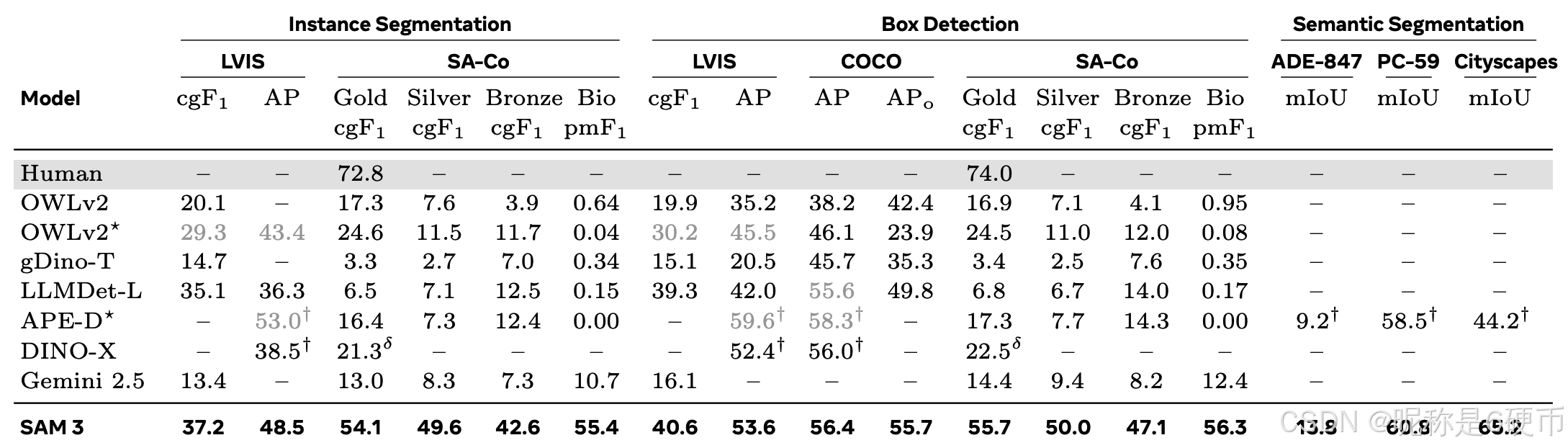
Image PCS with Text. We evaluate instance segmentation, box detection, and semantic segmentation on external and our benchmarks. SAM 3 is prompted with a single NP at a time, and predicts instance masks, bounding boxes, or semantic masks. As baselines, we evaluate OWLv2, GroundingDino (gDino), and LLMDet on box detection, and prompt SAM 1 with their boxes to evaluate segmentation. We also compare to APE, DINO-X, and Gemini 2.5 Flash, a generalist LLM. Tab. 1 shows that zero-shot, SAM 3 sets a new state-of-the-art on closed-vocabulary COCO, COCO-O and on LVIS boxes, and is significantly better on LVIS masks. On open-vocabulary SA-Co/Gold SAM 3 achieves more than double the c g F 1 \mathrm{cgF_{1}} cgF1 score of the strongest baseline OWLv2*, and 74 % 74\% 74% of the estimated human performance. The improvements are even higher on the other SA-Co splits. Open vocabulary semantic segmentation results on ADE-847, PascalConcept-59, and Cityscapes show that SAM 3 outperforms APE, a strong specialist baseline. See §F.1 for details.
【翻译】带文本的图像PCS。我们在外部基准和我们的基准上评估实例分割、框检测和语义分割。SAM 3每次使用单个NP进行提示,并预测实例掩码、边界框或语义掩码。作为基线,我们在框检测上评估OWLv2、GroundingDino(gDino)和LLMDet,并使用它们的框提示SAM 1来评估分割。我们还与APE、DINO-X和通用LLM Gemini 2.5 Flash进行比较。表1显示,在零样本情况下,SAM 3在封闭词汇COCO、COCO-O和LVIS框上创造了新的最先进水平,在LVIS掩码上显著更好。在开放词汇SA-Co/Gold上,SAM 3的 c g F 1 \mathrm{cgF_{1}} cgF1分数是最强基线OWLv2*的两倍多,达到估计人类性能的74%。在其他SA-Co分割上的改进甚至更高。在ADE-847、PascalConcept-59和Cityscapes上的开放词汇语义分割结果显示,SAM 3优于强大的专业基线APE。详细信息见§F.1。
Table 1 Evaluation on image concept segmentation with text. APo corresponds to COCO-O accuracy, ⋆ \star ⋆ : partially trained on LVIS, † \dagger † : from original papers, δ: from DINO-X API. Gray numbers indicate usage of respective closed set training data (LVIS/COCO). See §F.1 for more baselines and results and § E . 4 \S\mathrm{E.4} §E.4 for details of human performance.
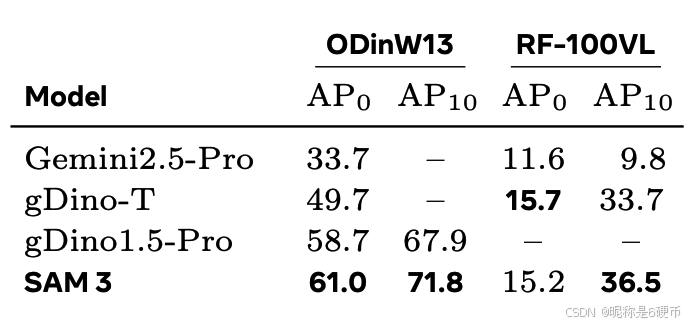
Table2 Zero-shot and 10-shot transfer on in-the-wild datasets.
【翻译】表2 在野外数据集上的零样本和10样本迁移。
Table 3 Prompting with 1 exemplar on COCO, LVIS and ODinW13. Evaluation per prompt type: T (text-only), I (image-only), and T+I (combined text and image). A P + {\mathrm{AP^{+}}} AP+ is evaluated only on positives examples.
【翻译】表3 在COCO、LVIS和ODinW13上使用1个示例进行提示。按提示类型评估:T(仅文本)、I(仅图像)和T+I(文本和图像组合)。 A P + {\mathrm{AP^{+}}} AP+仅在正样本上评估。
Few-Shot Adaptation. We evaluate zero- and few-shot transfer of SAM 3 on ODinW13 and RF100-VL, with their original labels as prompts. We do not perform any prompt tuning. We fine-tune SAM 3 without mask loss, and report average bbox mAP in Tab. 2. SAM 3 achieves state-of-the-art 10-shot performance, surpassing in-context prompting in Gemini and object detection experts (gDino); more details in §F.3. RF-100VL contains domains with specialized prompts that are out of SAM 3's current scope, but SAM 3 adapts through fine-tuning more efficiently than baselines.
PCS with 1 Exemplar. We first evaluate image exemplars using a single input box sampled at random from the ground truth. This can be done only on "positive" data, where each prompted object appears in the image. We report the corresponding A P + {\mathrm{A}}\mathrm{P^{+}} AP+ in Tab. 3 across three settings: text prompt (T), exemplar image (I), and both text and image (T+I); SAM 3 outperforms prior state-of-the-art T-Rex2 by a healthy margin on COCO ( + 18.3 ) (+18.3) (+18.3) , LVIS ( + 10.3 ) (+10.3) (+10.3) , and ODinW (+20.5). See § F . 2 \S\mathrm{F}.2 §F.2 for more details and results on SA-Co/Gold.
【翻译】使用1个示例的PCS。我们首先使用从真实标注中随机采样的单个输入框来评估图像示例。这只能在"正样本"数据上进行,其中每个提示的对象都出现在图像中。我们在表3中报告了三种设置下对应的 A P + {\mathrm{A}}\mathrm{P^{+}} AP+:文本提示(T)、示例图像(I)以及文本和图像(T+I);SAM 3在COCO(+18.3)、LVIS(+10.3)和ODinW(+20.5)上以显著优势超越了先前最先进的T-Rex2。更多详细信息和SA-Co/Gold上的结果见§F.2。
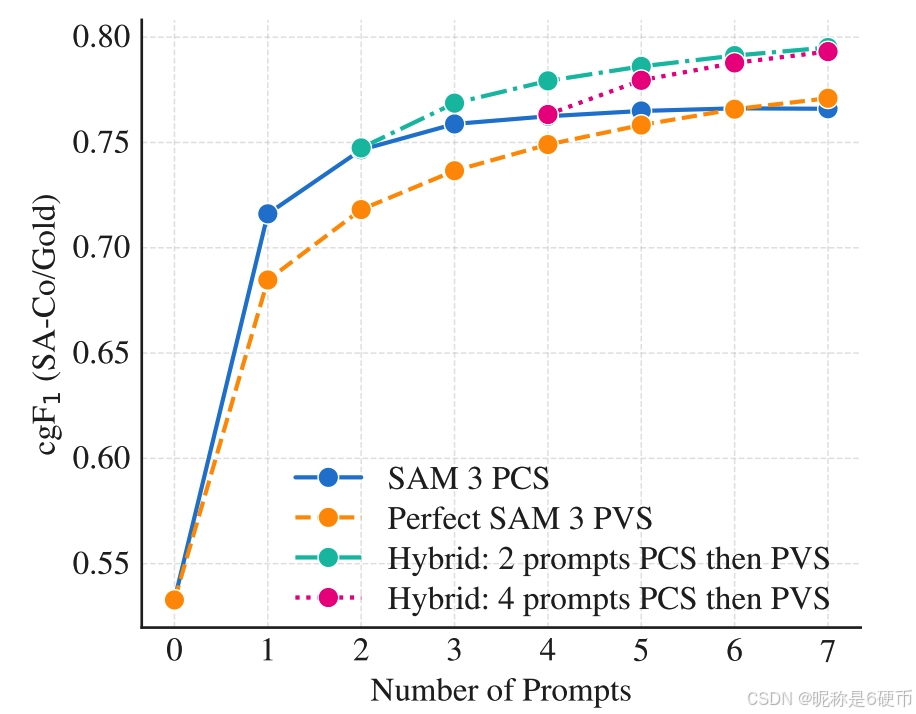
PCS with K Exemplars. Next, we evaluate SAM 3 in an interactive setting, simulating collaboration with a human annotator. Starting with a text prompt, we iteratively add one exemplar prompt at a time: missed ground truths are candidate positive prompts, false positive detections are candidate negative prompts. Results (Fig. 7) are compared to a perfect PVS baseline, where we simulate the user manually fixing errors using ideal box-to-mask corrections. SAM 3's PCS improves c g F 1 \mathrm{cgF_{1}} cgF1 more quickly, as it generalizes from exemplars (e.g., detecting or suppressing similar objects), while PVS only corrects individual instances. After 3 clicks, interactive PCS outperforms text-only by + 21.6 c g F 1 +21.6~\mathrm{cgF_{1}} +21.6 cgF1 points and PVS refinement by +2.0. Performance plateaus after 4 clicks, as exemplars cannot fix poor-quality masks. Simulating a hybrid switch to PVS at this point yields gains, showing complementary.
【翻译】使用K个示例的PCS。接下来,我们在交互式设置中评估SAM 3,模拟与人工标注员的协作。从文本提示开始,我们每次迭代添加一个示例提示:遗漏的真实标注是候选正样本提示,误检是候选负样本提示。结果(图7)与完美的PVS基线进行比较,我们模拟用户使用理想的框到掩码校正手动修复错误。SAM 3的PCS改进 c g F 1 \mathrm{cgF_{1}} cgF1更快,因为它从示例中泛化(例如,检测或抑制相似对象),而PVS只校正单个实例。3次点击后,交互式PCS比仅文本高出 + 21.6 c g F 1 +21.6~\mathrm{cgF_{1}} +21.6 cgF1点,比PVS细化高出+2.0。性能在4次点击后趋于平稳,因为示例无法修复质量差的掩码。此时模拟混合切换到PVS会产生收益,显示了互补性。
Figure 7 c g F 1 \mathrm{cgF_{1}} cgF1 vs. # of interactive box prompts for SAM 3 compared to the ideal PVS baseline, averaged over SA-Co/Gold phrases.
【翻译】图7 SAM 3与理想PVS基线相比的 c g F 1 \mathrm{cgF_{1}} cgF1与交互式框提示数量的关系,在SA-Co/Gold短语上平均。
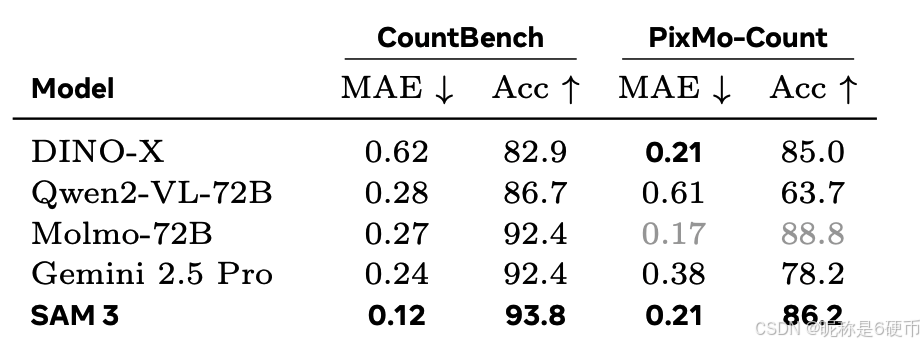
Object Counting. We evaluate on object counting benchmarks CountBench and PixMo-Count to compare with several MLLMs using Accuracy ( % \% % ) and Mean Absolute Error (MAE) from previous technical reports and our own evaluations. See Tab. 4 for results and §F.4 for more evaluation details. Compared to MLLMs, SAM 3 not only achieves good object counting accuracy, but also provides object segmentation that most MLLMs cannot provide.
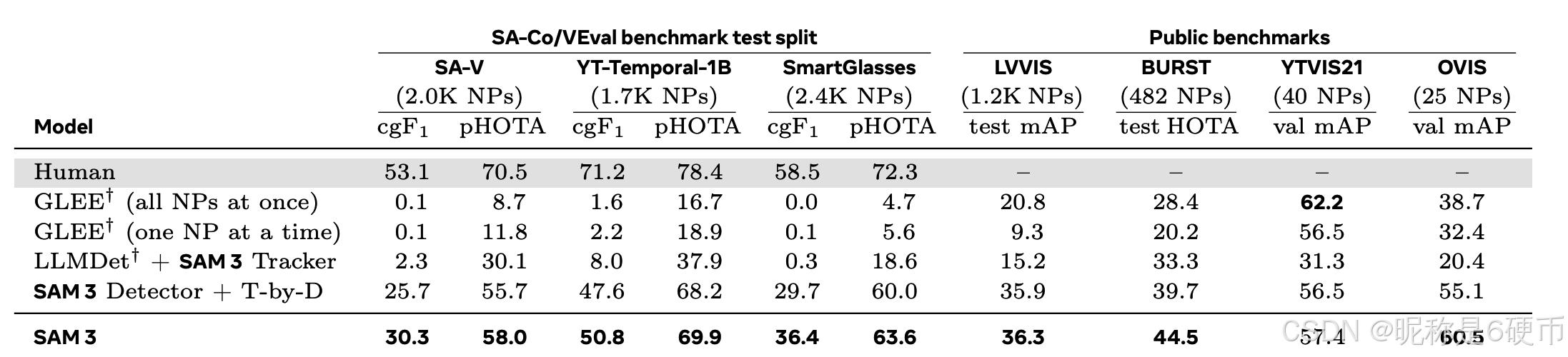
Video PCS with Text. We evaluate video segmentation with text prompts on both our SA-Co/VEval benchmark and existing public benchmarks. For SA-Co/VEval, we report c g F 1 \mathrm{cgF_{1}} cgF1 and pHOTA metrics (defined in §F.5) across its subsets (SA-V, YT-Temporal-1B, SmartGlasses). For public benchmarks, we use their official metrics. Baselines include GLEE, an open-vocabulary image and video segmentation model, "LLMDet + SAM 3 Tracker" (replacing our detector with LLMDet), and "SAM 3 Detector + T-by-D" (replacing our tracker with an association module based on the tracking-by-detection paradigm). In Tab. 5, SAM 3 largely outperforms these baselines, especially on benchmarks with a very large number of noun phrases. On SA-Co/VEval it reaches over 80 % 80\% 80% of human pHOTA. See §F.5 for more details.
【翻译】带文本的视频PCS。我们在我们的SA-Co/VEval基准和现有公共基准上评估带文本提示的视频分割。对于SA-Co/VEval,我们在其子集(SA-V、YT-Temporal-1B、SmartGlasses)上报告 c g F 1 \mathrm{cgF_{1}} cgF1和pHOTA指标(在§F.5中定义)。对于公共基准,我们使用它们的官方指标。基线包括GLEE(一个开放词汇图像和视频分割模型)、"LLMDet + SAM 3 Tracker"(用LLMDet替换我们的检测器)和"SAM 3 Detector + T-by-D"(用基于检测跟踪范式的关联模块替换我们的跟踪器)。在表5中,SAM 3在很大程度上优于这些基线,特别是在具有大量名词短语的基准上。在SA-Co/VEval上,它达到了人类pHOTA的80%以上。更多详细信息见§F.5。
Table4 Accuracy on counting benchmarks. Gray indicates usage of training sets.
【翻译】表4 计数基准上的准确率。灰色表示使用训练集。
Table 5 Video PCS from a text prompt (open-vocabulary video instance segmentation) on SA-Co/VEval and public benchmarks (see Tab. 39 for more results and analyses). SAM 3 shows strong performance, especially on benchmarks with a large number of NPs. †: GLEE and LLMDet do not perform well zero-shot on SA-Co/VEval.
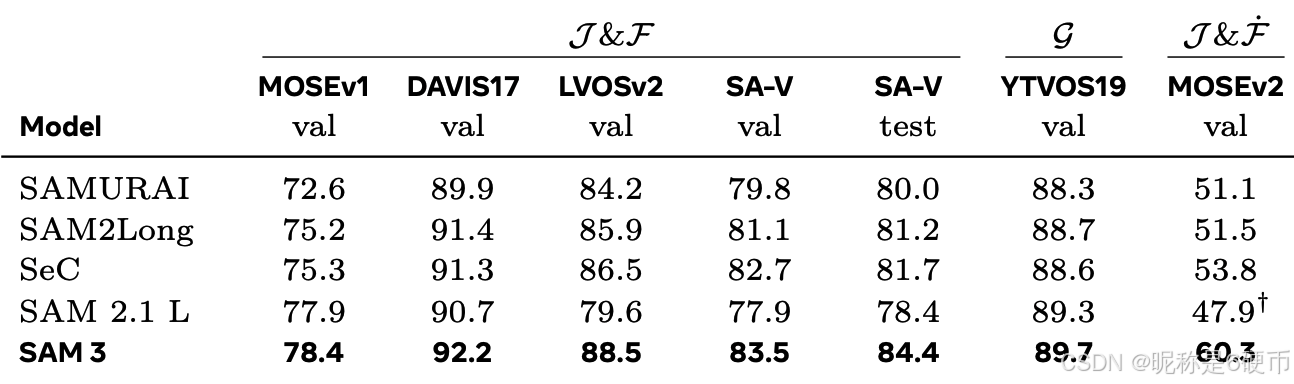
PVS. We evaluate SAM 3 on a range of visual prompting tasks, including Video Object Segmentation (VOS) and interactive image segmentation. Tab. 6 compares SAM 3 to recent state-of-the-art methods on the VOS task. SAM 3 achieves significant improvements over SAM 2 on most benchmarks, particularly on the challenging MOSEv2 dataset, where SAM 3 outperforms prior work by 6.5 points. For the interactive image segmentation task, we evaluate SAM 3 on the 37 datasets benchmark introduced in Ravi et al. (2024). As shown in Tab. 7, SAM 3 outperforms SAM 2 on average mIoU. See also § F . 6 \S\mathrm{F.6} §F.6 and Fig. 21 for interactive video segmentation.
Table 6 SAM 3 improves over SAM 2 in VOS. †: Zero-shot.
【翻译】表6 SAM 3在VOS上相比SAM 2有所改进。†:零样本。
Table 7 Interactive image segmentation on the SA-37 benchmark.
【翻译】表7 在SA-37基准上的交互式图像分割。
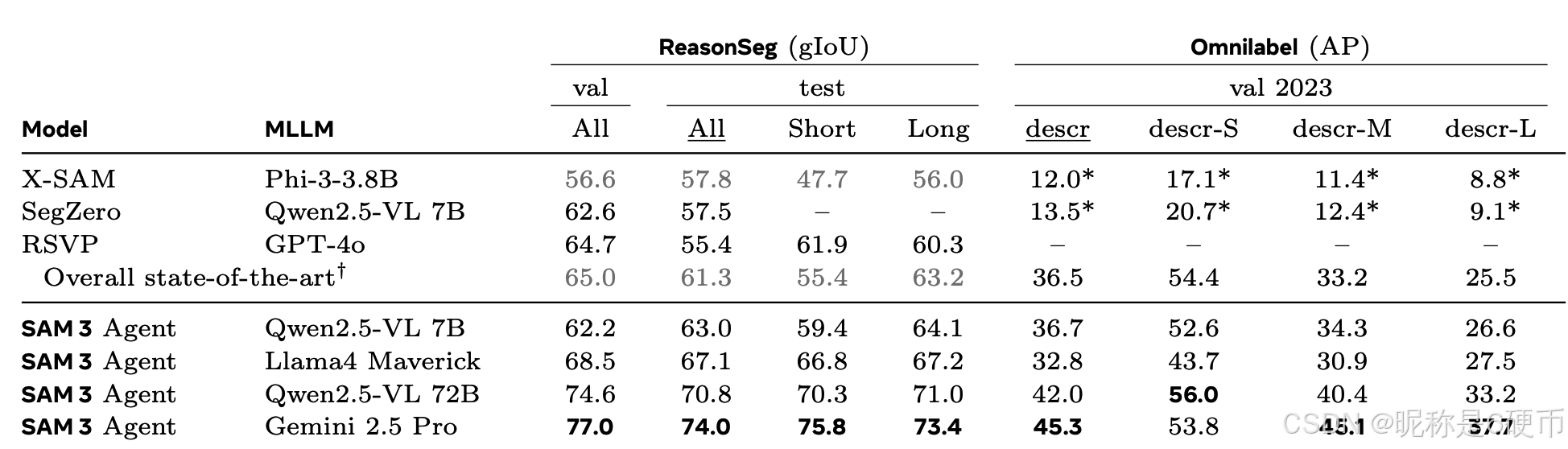
SAM 3 Agent. We experiment with an MLLM that uses SAM 3 as a tool to segment more complex text queries (see Fig. 25). The MLLM proposes noun phrase queries to prompt SAM 3 and analyzes the returned masks, iterating until the masks are satisfactory. Tab. 8 shows that this "SAM 3 Agent" evaluated zero-shot on ReasonSeg and OmniLabel surpasses prior work without training on any referring expression segmentation or reasoning segmentation data. SAM 3 Agent also outperforms previous zero-shot results on RefCOCO+ and RefCOCOg. SAM 3 can be combined with various MLLMs, with the same set of the system prompts for all those MLLMs, showing SAM 3's robustness. See §G for more details.
Table 8 SAM 3 Agent results. Gray indicates fine-tuned results on ReasonSeg (train), * indicates reproduced results, underline indicates the main metric. †: LISA-13B-LLaVA1.5 for ReasonSeg; REAL for OmniLabel.
【翻译】表8 SAM 3智能体结果。灰色表示在ReasonSeg(训练)上的微调结果,*表示复现结果,下划线表示主要指标。†:ReasonSeg使用LISA-13B-LLaVA1.5;OmniLabel使用REAL。
Table 9 Selected model and data ablations on SA-Co/Gold. Numbers across tables are not directly comparable.
【翻译】表9 在SA-Co/Gold上选定的模型和数据消融实验。不同表格间的数字不能直接比较。
Selected Ablations. In Tab. 9 we report a subset of the more extensive ablations from §A. Note that the ablated models are from different, shorter training runs than the model evaluated above. The presence head boosts c g F 1 \mathrm{cgF_{1}} cgF1 by + 1.5 +1.5 +1.5 (9a), improving image-level recognition measured by IL_MCC by + 0.05 +0.05 +0.05 . Tab. 9b shows that adding hard negatives significantly improves the model performance, most notably the image-level IL_MCC from 0.44 to 0.68. Tab. 9c shows that synthetic (SYN) training data improves over the external (EXT) by + 8.8 c g F 1 +8.8~\mathrm{cgF_{1}} +8.8 cgF1 and our high-quality (HQ) annotations add + 14.6 c g F 1 +14.6~\mathrm{cgF_{1}} +14.6 cgF1 on top of this baseline. We present detailed data scaling laws of both types of data in §A.2, showing their effectiveness on both in-domain and out-of-domain test sets. In Tab. 9d, we show how AI verifiers can improve pseudo-labels. Replacing the presence score from SAM 3 with that score from the exhaustivity verification (EV) AI verifier boosts c g F 1 \mathrm{cgF_{1}} cgF1 by + 7.2 +7.2 +7.2 . Using the mask verification (MV) AI verifier to remove bad masks adds another 1.1 points. Overall, AI verifiers close half of the gap between SAM 3's and human performance.
【翻译】选定的消融实验。在表9中,我们报告了§A中更广泛消融实验的一个子集。注意,消融模型来自与上述评估模型不同的、更短的训练运行。存在头将 c g F 1 \mathrm{cgF_{1}} cgF1提升了 + 1.5 +1.5 +1.5(9a),将由IL_MCC测量的图像级识别改进了 + 0.05 +0.05 +0.05。表9b显示,添加困难负样本显著改善了模型性能,最显著的是图像级IL_MCC从0.44提升到0.68。表9c显示,合成(SYN)训练数据比外部(EXT)数据改进了 + 8.8 c g F 1 +8.8~\mathrm{cgF_{1}} +8.8 cgF1,我们的高质量(HQ)标注在此基线上又增加了 + 14.6 c g F 1 +14.6~\mathrm{cgF_{1}} +14.6 cgF1。我们在§A.2中展示了两种数据类型的详细数据缩放定律,显示了它们在域内和域外测试集上的有效性。在表9d中,我们展示了AI验证器如何改进伪标签。用详尽性验证(EV)AI验证器的分数替换SAM 3的存在分数,将 c g F 1 \mathrm{cgF_{1}} cgF1提升了 + 7.2 +7.2 +7.2。使用掩码验证(MV)AI验证器去除坏掩码又增加了1.1个点。总体而言,AI验证器缩小了SAM 3与人类性能之间一半的差距。
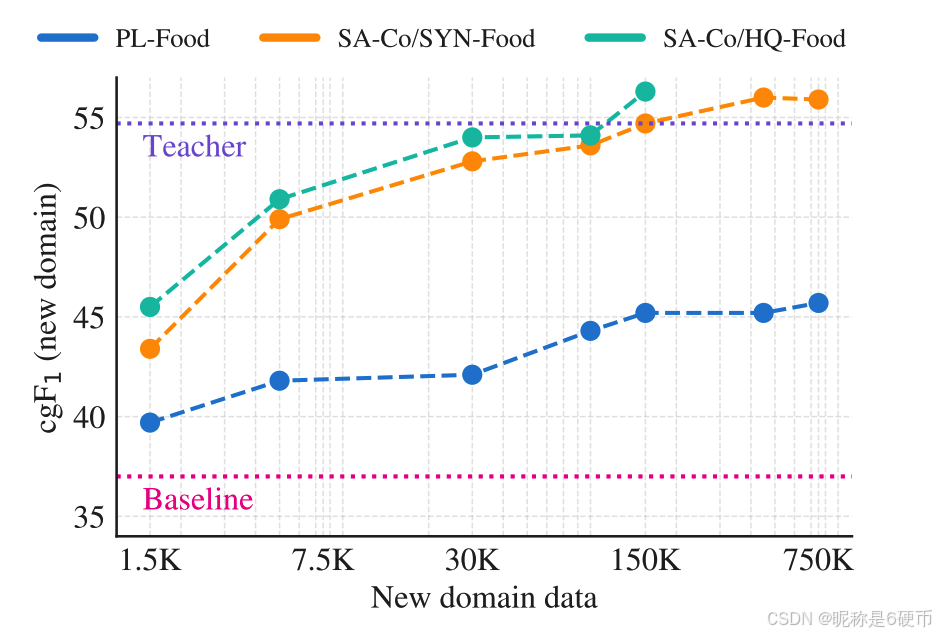
Domain adaptation ablation. With domain-specific synthetic data generated by SAM 3 + AI verifiers, we show that one can significantly improve performance on a new domain without any human annotation. We hold out one of the SA-Co domains, "Food&drink", from training SAM 3 and AI verifiers. We then use three variants of training data for the novel "Food&drink" domain: high-quality AI+human annotations as in SA-Co/HQ (referred to as SA-Co/HQ-Food), synthetic annotations as in SA-Co/SYN, using AI but no humans (SA-Co/SYN-Food), and pseudo-labels generated before the AI verification step, i.e. skipping both AI verifiers and humans (PL-Food). Fig. 8 plots performance on the "Food&drink" test set of the SA-Co/Gold benchmark as each type of training data is scaled up. We mix the domain specific data and high-quality general domain data at a 1:1 ratio. PL-Food provides some improvement compared to the baseline SAM 3 (zero-shot), but is far below the other variants due to its lower quality. HQ-Food and SYN-Food show similar scaling behavior, with SYN-Food slightly lower but eventually catching up, without incurring any human annotation cost. This points to a scalable way to improve performance on new data distributions. More details are in §A.3.
Figure 8 Domain adaptation via synthetic data. Synthetic (SYN) data generated by SAM 3 + AI verifiers (teacher system) achieves similar scaling behavior as human-annotated (HQ) data.
Promptable and Interactive Visual Segmentation. SAM (Kirillov et al., 2023) introduces "promptable" image segmentation with interactive refinement. While the original task definition included text prompts, they were not fully developed. SAM 2 (Ravi et al., 2024) extended the promptable visual segmentation task to video, allowing refinement points on any frame. SAM 3 inherits geometry-based segmentation while extending to include text and image exemplar prompts to segment all instances of a concept in images and videos.
Open-Vocabulary Detection and Segmentation in Images exhaustively labels every instance of an open-vocabulary object category with a coarse bounding box (detection) or a fine-grained pixel mask (segmentation). Recent open-vocabulary (OV) detection (Gu et al., 2021; Minderer et al., 2022) and segmentation (Ding et al., 2022; Liang et al., 2023) methods leverage large-scale vision-language encoders such as CLIP (Radford et al., 2021) to handle categories described by arbitrary text, even those never seen during training. While DETR (Carion et al., 2020) is limited to a closed set of categories seen during training, MDETR (Kamath et al., 2021) evolves the approach to condition on raw text queries. Image exemplars used as prompts to specify the desired object category (e.g., DINOv (Li et al., 2023a), T-Rex2 (Jiang et al., 2024)) present a practical alternative to text, but fall short in conveying the abstract concept of objects as effectively as text prompts. We introduce a new benchmark for OV segmentation with > 100 × >100\times >100× more unique concepts than prior work.
Visual Grounding localizes a language expression referring to a region of the image with a box or mask. (Plummer et al., 2020) introduces phrase detection as both deciding whether the phrase is relevant to an image and localizing it. GLIP (Li et al., 2022b) and GroundingDino (Liu et al., 2023) formulate object detection as phrase grounding, unifying both tasks during training. MQ-GLIP (Xu et al., 2023) adds image exemplars to text as queries. Building on this trend toward models supporting multiple tasks and modalities, GLEE (Wu et al., 2024a) allows text phrases, referring expressions, and visual prompts for category and instance grounding in both images and videos. Unlike SAM 3, GLEE does not support exemplars or interactive refinement. LISA (Lai et al., 2024) allows segmentation that requires reasoning, while OMG-LLaVa (Zhang et al., 2024a) and GLaMM (Rasheed et al., 2024) generate natural language responses interleaved with corresponding segmentation masks, with GLaMM accepting both textual and optional image prompts as input. Some general-purpose MLLMs can output boxes and masks (Gemini2.5 (Comanici et al., 2025)) or points (Molmo (Deitke et al., 2025)). SAM 3 can be used as a "vision tool" in combination with an MLLM (§6).
Multi-Object Tracking and Segmentation methods identify object instances in video and track them, associating each with a unique ID. In tracking-by-detection methods, detection is performed independently on each frame to produce boxes and confidence scores, followed by association of boxes using motion-based and appearance-based matching as in SORT (Bewley et al., 2016; Wojke et al., 2017), Tracktor (Bergmann et al., 2019), ByteTrack (Zhang et al., 2022c), SAM2MOT (Jiang et al., 2025), or OC-SORT (Cao et al., 2023). An alternative is an end-to-end trainable architecture that jointly detects and associates objects, e.g., TrackFormer (Meinhardt et al., 2022), TransTrack (Sun et al., 2020), or MOTR (Zeng et al., 2022). TrackFormer uses a DETR-like encoder-decoder that initializes new tracks from static object queries and auto-regressively follows existing tracks with identity-preserving track queries. A challenge with joint models is the conflict between detection and tracking (Feichtenhofer et al., 2017; Yu et al., 2023a), where one needs to focus on semantics while the other on disentangling identities, even if their spatial locations overlap over time. SAM 3 is a strong image detector tightly integrated into a tracker to segment concepts in videos.
We present Segment Anything with Concepts, enabling open-vocabulary text and image exemplars as prompts in interactive segmentation. Our principal contributions are: (i) introducing the PCS task and SA-Co benchmark, (ii) an architecture that decouples recognition, localization and tracking and extends SAM 2 to solve concept segmentation while retaining visual segmentation capabilities, (iii) a high-quality, efficient data engine that leverages the complimentary strengths of human and AI annotators. SAM 3 achieves state-of-the-art results, doubling performance over prior systems for PCS on SA-Co in images and videos. That said, our model has several limitations. For example, it struggles to generalize to out-of-domain terms, which could be mitigated by automatic domain expansion but requires extra training. We discuss this and other limitations of our model in §B. We believe SAM 3 and the SA-Co benchmark will be important milestones and pave the way for future research and applications in computer vision.
【翻译】我们提出了具有概念的分割一切(Segment Anything with Concepts),在交互式分割中启用开放词汇文本和图像示例作为提示。我们的主要贡献是:(i)引入PCS任务和SA-Co基准,(ii)一个解耦识别、定位和跟踪的架构,扩展SAM 2以解决概念分割,同时保留视觉分割能力,(iii)一个高质量、高效的数据引擎,利用人工和AI标注者的互补优势。SAM 3在SA-Co上的图像和视频PCS任务中实现了最先进的结果,性能比先前系统提升了一倍。尽管如此,我们的模型有几个局限性。例如,它难以泛化到域外术语,这可以通过自动域扩展来缓解,但需要额外的训练。我们在§B中讨论了模型的这些和其他局限性。我们相信SAM 3和SA-Co基准将成为重要的里程碑,为计算机视觉的未来研究和应用铺平道路。