3.1 引言
《碧海黑帆》是一款采用育碧内部引擎 Anvil 开发的开放世界海战多人在线游戏。该游戏最多支持 20 名玩家同时在线,每位玩家均可拥有一艘高度可自定义的巨大战舰。由于资源高度可定制,且在玩家人数达到上限时,游戏在极端情况下难免会超出流送预算。如何在有限的内存预算内保持最佳视觉质量,对技术团队而言是一项巨大挑战。
随着资源纹理分辨率随着输出分辨率的提升而不断增加,纹理流送已成为现代电子游戏高效利用内存的关键技术之一。为实现最佳视觉质量,可扩展性至关重要。传统的纹理流送技术使用一个参考位置(通常是摄像机或玩家位置)来计算每个纹理的优先级,从而由 CPU 决定加载或卸载哪些 Mipmap 层级。但这只是一个粗略的估算,是对 GPU 在执行绘制调用时实际读取纹理数据的一种经验性猜测。
3.2 实现
3.2.1 概述
利用 GPU 反馈进行纹理流送有多种方案。某些平台提供硬件特性以协助计算 GPU 所需的 Mipmap 层级,例如 DirectX 12 的采样器反馈流送功能。由于不同平台图形 API 差异巨大,我们在《碧海黑帆》中选择了软件方案,以确保跨平台行为一致、实现统一。
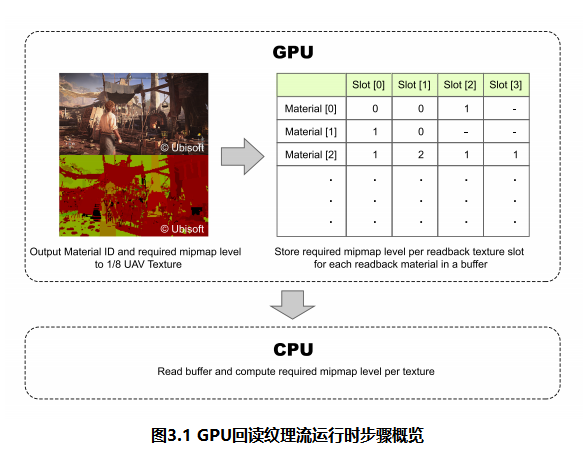
图 3.1 展示了我们系统的概览。在 G-Buffer 渲染阶段,我们从像素着色器将所需 Mipmap 层级的信息写入一个 UAV(无序访问视图)纹理中。该 UAV 纹理具有两个 16 位无符号整数通道。R 通道存储材质 ID;G 通道则存储最多四个 UV 变量计算出的 Mipmap 层级。这意味着单个材质最多可支持四个独特的 UV 变量用于回读式纹理流送。我们称这四个位置为回读纹理槽位。这些信息经过处理后回读至 CPU,通知纹理流送器上一帧使用了哪些纹理及 Mipmap 层级。以下章节将详细阐述每个步骤。
3.2.2 离线准备
由于需要材质像素着色器显式地向 UAV 纹理写入数据,首要挑战是如何将相关着色器代码注入到材质着色器中。Anvil 引擎中的材质通过节点图编辑器创建。我们修改了从节点图生成着色器代码的着色器构建器。它会解析节点图,检测用于采样纹理的 UV 变量,并为每个独特的变量分配回读纹理槽位。同时,用于计算每个回读纹理槽位所需 Mipmap 层级的着色器代码块也会被注入到像素着色器中。回读纹理槽位信息(即回读纹理槽位索引与纹理寄存器索引的配对)存储在着色器元数据中,并在运行时作为查找表使用。请注意,多个纹理寄存器索引可关联到同一个回读纹理槽位,这取决于它们的采样方式:例如,基于物理渲染中使用的反照率、法线、粗糙度和金属度贴图通常使用相同的 UV 变量进行采样,因此仅需一个回读纹理槽位。
3.2.3 运行时 UAV 输出
在运行时,于 G-Buffer 渲染阶段,所有不透明材质着色器都会向回读 UAV 纹理填充它们采样纹理的反馈信息。由于我们希望新的流送技术不会对性能产生负面影响,因此需要其尽可能快。为每个像素都写入回读信息被认为过于昂贵且冗余,因为相邻像素通常需要纹理的同一 Mipmap 层级。因此,我们决定让 UAV 纹理的宽高为 G-Buffer 的 1/8,并且仅让每 64 个像素中的一个写入采样信息。这意味着 UAV 纹理中的一个像素代表了 G-Buffer 中一个 8×8 的图块。为避免遗漏一个图块内其余 63 个像素(它们在单帧中不写入 UAV)的信息,我们应用了抖动策略,确保图块中的每个像素最终都会在多帧中写入采样信息。
【注释】
抖动策略(jittering guaranteeing) 在这里指的是 Jittering / 抖动采样 技术,用于解决 稀疏反馈 带来的信息缺失问题。
抖动策略如何工作
基本机制
帧0: 采样位置 = (0,0) # 写入图块左上角像素
帧1: 采样位置 = (2,2) # 向右下偏移
帧2: 采样位置 = (4,4) # 继续偏移
帧3: 采样位置 = (6,6) # 图块右下角
... 循环模式
数学表达
对于8×8图块中的像素位置
(x,y)(其中x,y ∈ [0,7]):采样帧号 = (当前帧号 + 哈希(x,y)) % 64
采样位置 = (x, y) 仅当 采样帧号 == 0
实际上通过更简洁的公式实现:
采样像素 = (screenCoord + frameOffset) % 8 == 0
为什么需要抖动策略
1. 避免系统性遗漏
没有抖动:图块中某些区域(如边缘、角落)可能永远不被采样
抖动后:所有像素最终都会被采样到
2. 时间性分摊
单个像素的采样信息不够准确(可能异常)
通过多帧积累,获得统计上可靠的反馈
64帧后,每个8×8图块的所有像素都被采样过一次
3. 减少视觉伪影
无抖动的问题:
某些纹理部分可能长期不被检测到
导致这些区域的Mipmap层级错误
产生"纹理闪烁"或"分辨率不一致"
抖动后的效果:
采样覆盖均匀分布在时间和空间上
反馈更加稳定和准确
技术实现细节
GPU端实现
glsl
// 简化示例
uint2 tileCoord = screenCoord / 8; // 8×8图块坐标
uint2 subPixel = screenCoord % 8; // 图块内像素位置
// 计算抖动偏移(每帧变化)
uint frameMod = frameIndex % 64;
uint2 jitterOffset = uint2(
(frameMod / 8) % 8, // X偏移
frameMod % 8 // Y偏移
);
// 仅当像素与抖动位置匹配时写入
if (all(subPixel == jitterOffset)) {
WriteFeedbackToUAV(tileCoord, mipLevel);
}
CPU端处理
收集多帧数据 → 统计分析 → 确定最终Mipmap需求
例如:
纹理A在64帧中被采样了50次
其中45次请求Mipmap层级2
5次异常值(层级0或层级4)
系统采用多数投票或加权平均
【注释】
在像素着色器中写入 UAV 纹理的一个缺点是,UAV 写入不受延迟深度测试的影响(如果早期深度测试被禁用,延迟深度测试在光栅操作阶段进行)。像素着色器中的 UAV 操作会自动禁用早期深度测试,但对于普通的不透明着色器,可通过着色器属性强制启用早期深度测试。然而,需要丢弃像素(例如 Alpha 测试)或修改深度的着色器必须使用延迟深度测试。因此,可能会导致并未最终进入 G-Buffer 的材质意外地覆写 UAV。这可以通过深度预渲染所有物体来避免,但《碧海黑帆》并未采用此方案。不过,由于 CPU 端对回读信息应用了高频滤波器以吸收噪声,这并未对我们造成实际影响。
【注释】
在HLSL中提前强制深度测试开启 (在UAV特殊处理情况)
cpp// 强制早期深度测试 + 模板测试 [earlydepthstencil] // 强制早期深度/模板测试 float4 OceanPS(PixelInput input) : SV_Target0 { return texture(albedoMap, texCoord); }GLSL
// 强制早期片段测试(OpenGL的叫法)
cpplayout(early_fragment_tests) in; // ⭐ GLSL的强制语法 in vec2 texCoord; out vec4 fragColor; uniform sampler2D albedoMap; void main() { // 在这个着色器中,深度测试会在片段着色器执行前进行 // 即使没有这个声明,驱动也可能优化,但这是明确要求 return texture(albedoMap, texCoord); }解释下UAV渲染流程为啥会有问题
正常的渲染流程(无UAV写入)
顶点着色 → 光栅化 → 早期深度测试 → 像素着色 → 深度写入 → ROP输出
↑ ↓
确定哪些像素被遮挡 最终颜色和深度值
有UAV写入时的异常流程
顶点着色 → 光栅化 → 禁用早期深度测试 → 像素着色 → UAV写入 → 延迟深度测试 → ...
↑ ↓
像素着色器执行了, 但后来可能被深度测试淘汰!
写入UAV了
伪代码
// 物体顺序:墙(近)→ 海盗旗(远)
// 墙深度:0.1,旗深度:0.9
渲染墙:
像素着色器执行 → 计算墙的纹理需求
写入UAV:"墙需要Mip=2"
深度测试:0.1通过
输出到帧缓冲区 ✅
渲染海盗旗:
像素着色器执行 → 计算旗的纹理需求
写入UAV:"旗需要Mip=3" ❌ 问题在这里!
// 工作报告已经提交了!
- 深度测试:0.9 vs 0.1 → 失败!
// 旗被墙挡住了
- 不输出到帧缓冲区 ✅
// 但UAV记录已经存在了!
结果:
帧缓冲区:只显示墙(正确✅)
UAV记录:记录了墙和旗(错误❌)
【注释】
三线性过滤所需的 Mipmap 层级可按清单 3.1 计算;see Segal and Akeley 12.
cpp
float2 xy = uv ∗ textureSize ;
float2 dx_xy = ddx fine (xy);
float2 dy_xy = ddy fine (xy);
float mipLevel = 0.5 ∗ log2(max(dot( dx_xy , dx_xy ), dot( dy_xy , dy_xy )));
// 清单 3.1 用于三线性过滤的Mipmap层级计算
cpp
float2 dx uv = ddx_fine (uv);
dx uv .y ∗= aspectRatio ;
float2 dy uv = ddy_fine (uv);
dy uv .y ∗= aspectRatio ;
float normalizedMipLevel = 0.5 ∗ log2(max(dot( dx_uv , dy_uv ),
dot( dy_uv , dy_uv )));
// Calculation is independent of texture size until here:
float mipLevel = normalizedMipLevel + log2( textureWidth );
// 清单3.2 基于纹理尺寸无关的三线性过滤的Mipmap层级计算该公式需要纹理尺寸。然而,我们的资源管线允许美术使用一组纹理(如反照率、法线、高光贴图等),且它们通常都使用相同的 UV 变量进行采样。这些纹理可能尺寸各异,因此即使使用相同的 UV 变量采样,每个纹理的 Mipmap 层级也可能不同。这意味着,如果我们直接在 UAV 中存储 Mipmap 层级,则每个纹理都需要一个回读槽位。为避免此限制,可以重新调整计算方式,使其独立于纹理尺寸,转而计算"归一化"的 Mipmap 层级。
清单3.2与清单3.1等效。请注意,系数0.5无需应用于textureWidth,因为它会被抵消掉:
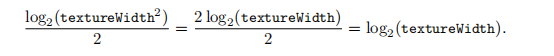
清单 3.2 中的计算使得 GPU 端的计算独立于纹理尺寸,并为每个 UV 变量(即每个回读槽位)存储一个单一的"归一化"Mipmap 层级。计算实际 Mipmap 层级的最后一行可以移至 CPU 端,在那里为关联到同一回读槽位的所有纹理进行计算。
对于各向异性过滤,公式略有不同,但遵循相同的方法;see Segal and Akeley 22.。
为降低 UAV 纹理的带宽占用,归一化 Mipmap 值被转换为无符号整数并以 4 位存储(值域 0-15),从而允许将四个归一化 Mipmap 值打包存储在 UAV 纹理的 16 位 G 通道中。此值域足以支持尺寸高达 32768 像素的纹理。
【注释】
在这里为啥使用Log2
设:
纹理宽度:W
UV在屏幕X方向的导数:du/dx
1个屏幕像素覆盖的纹理像素数 = |du/dx| × W
我们希望:
Mip层级k的像素尺寸 ≈ 屏幕像素覆盖的纹理区域
即:W/(2^k) ≈ |du/dx| × W
两边除以W:1/(2^k) ≈ |du/dx|
⇒ 2^k ≈ 1/|du/dx|
⇒ k ≈ log₂(1/|du/dx|) = -log₂(|du/dx|
为什么这样分解合理?
cpp
// 物理意义:
// normalizedMip = "需求强度"(只与视角和距离有关)
// texturePart = "供应能力"(纹理本身的分辨率)
// 例子:
相同距离看不同物体:
看砖墙:normalizedMip = -3.0
看海盗旗:normalizedMip = -3.0 (如果距离相同)
但:
砖墙纹理:4096×4096 → texturePart = log₂(4096) = 12
海盗旗纹理:1024×1024 → texturePart = log₂(1024) = 10
最终Mip:
砖墙:-3.0 + 12 = 9.0 → Mip层级9
海盗旗:-3.0 + 10 = 7.0 → Mip层级7
【注释】
3.2.4 运行后处理
一旦我们获得了存储当前帧所有图块回读材质信息的图像,就需要汇总这些信息,以得到每个材质所需的最高归一化 Mipmap 层级。为了减少回读至 CPU 及后续评估的带宽,我们分两个步骤处理,生成一个紧密打包的缓冲区,大小为 128 KiB(每个回读材质 16 位),以材质 ID 为索引。它包含了每个材质四个回读纹理槽位所需的最精细归一化 Mipmap 层级值。
第一个计算着色器本质上使用全局原子操作计算每个回读槽位的每帧最大值。该步骤的伪代码如清单 3.3 所示。可以使用组共享内存进行优化,但为了简洁起见,此处略过。由于原子操作不能处理打包数据,因此运行第二个计算着色器,将每帧最大归一化 Mipmap 值紧密打包为每个材质 16 位的回读数据。整个后处理过程可以在异步计算队列上运行,几乎不产生性能开销。
cpp
Texture2D<uint2> materialFeedback ;
RWByteAddressBuffer readback;
// Execute for each pixel of the feedback texture.
void collectMaximum (uint2 pixelPos )
{
uint2 rawFeedback = materialFeedback [pixelPos ];
uint materialId = rawFeedback .x;
uint rbSlots = rawFeedback .y;
for (uint i = 0; i < 4; ++i)
{
// Unpack feedback value from readback slot.
// Each slot covers 4 bit.
uint normalizedMip = (rbSlots >> (4 ∗ i)) & 0xF;
uint oldValue ;
// Atomics work on 4 bytes , so we need 4 bytes per slot.
uint byteAddress = materialId ∗ 4 ∗ 4 + i;
readback. InterlockedMax (byteAddress , normalizedMip , oldValue);
}
}
//清单 3.3. 生成回读缓冲区的伪代码3.2.5 CPU Readback
cpp
// For each material with readback information ,
// calculate the desired mipmap level for each readback slot:
for (uint slot = 0; slot < 4; ++ slot)
{
char rawSlotData = readbackMaterial . rawSlotData [slot ];
int normalizedMipLevel = unpack( rawSlotData );
for (Texture& t : readbackMaterial . texturesPerSlot [slot ])
{
int idealMipLevel = normalizedMipLevel + log2(t.width);
if ( idealMipLevel != t. currentMipLevel )
{
addPendingRequest (t, idealMipLevel );
}
}
}
// 清单3.4. CPU读取数据的处理过程将 3.2.4节中生成的缓冲区回读至 CPU(或至少回读一部分,具体取决于系统中注册的材质数量)。对于每个材质,为关联到每个回读纹理槽位的所有纹理计算所需的 Mipmap 层级,如清单 3.4 所示。请注意,纹理高度在此无关紧要,因为归一化 Mipmap 层级已经考虑了纹理的宽高比。
这里会使用第 3.2.2 节提到的查找表,以确定给定材质的每个回读纹理槽位关联了哪些纹理。
在 CPU 端计算出每个纹理所需的最精细 Mipmap 层级后,系统将 GPU 反馈与当前已加载的 Mipmap 层级进行比较。如果存在差异,则安排反馈请求并开始跟踪。如果该差异持续数帧,则认为反馈有效,并发出流送请求以加载或卸载 Mipmap 数据。目前,我们在卸载一个 Mipmap 层级前会等待 30 帧。之所以需要这种高频滤波器,是因为稀疏反馈(每个 8×8 图块仅有一个像素写入回读 UAV 纹理)以及 UAV 写入顺序伪影导致回读数据噪声较大。这有助于避免频繁加载和卸载同一 Mipmap 层级,从而防止产生明显的视觉"弹跳"问题。
3.3 成果

我们测量了实际游戏场景中可流送纹理的数量。在一个资源密度相当高的海盗巢穴中,约有 2400 个纹理在 GPU 回读式纹理流送系统中注册。
当流送内存预算充足时(通常在较低屏幕分辨率下),启用 GPU 回读流送系统可以释放 50 到 240 MiB 未使用的纹理 Mipmap 数据,具体数值取决于场景。摄像机前方遮挡背景物体的对象越多,被释放的流送纹理数据就越多。视觉质量得以保持,如图 3.2 所示。

当屏幕分辨率为 4K 时,在某些情况下使用默认的纹理 Mipmap 加载距离会观察到质量不足。GPU 回读式纹理流送有助于检测这些情况并加载缺失的纹理 Mipmap。在图 3.3 中,绿色区域表示像素着色器采样了当前已加载的最精细 Mipmap 层级。这是理想情况,因为我们没有为未使用的纹理数据浪费内存。红色和洋红色区域表示像素着色器试图采样一个未加载的 Mipmap 层级。这意味着质量损失,表现为纹理模糊,因为纹理流送导致所需的 Mipmap 层级不可用。

我们还比较了在流送内存严重不足条件下的视觉质量。图 3.4 展示了与图 3.2 相同的场景,但流送内存预算小得多。启用 GPU 回读流送时,视觉质量得以保持。然而,当摄像机移动时,如果内存不足的程度非常极端,可能会观察到一些纹理流送延迟,表现为纹理"弹跳"。通常可以通过在低端平台上计算所需 Mipmap 层级时应用 Mipmap 偏移来避免此情况。
3.3.1 性能

表 3.1 展示了在 PlayStation 5 的"画质模式"和 4K 分辨率下,启用 GPU 回读式纹理流送所增加的额外成本。考虑到该技术在提高内存使用效率方面的显著优势,它提供了一个成本相当低的解决方案。
3.3.2 局限性
如第 实现部分 所述,系统存在一些局限性,例如仅支持 G-Buffer 材质中用于采样纹理的四个独特 UV 变量。根据着色器复杂程度,这可能不足以满足所有用例。该系统目前还不支持自定义着色器运算符(该功能允许美术在着色器图的节点中编写自己的着色器代码)。在《碧海黑帆》中,大约 87% 用于不透明材质的纹理受到 GPU 回读式纹理流送的跟踪。
使用 GPU 回读流送意味着加载的纹理取决于视图,即使玩家停留在同一位置,仅旋转摄像机也可能触发加载。《碧海黑帆》仅计划在当前世代主机和 PC 上发布,这使我们能够利用所有平台上快速的 SSD。因此,HDD 加载延迟不是问题。
3.4 结论与未来工作
GPU 回读式纹理流送技术通过更高效地利用纹理内存预算,帮助减轻了《碧海黑帆》中流送内存使用的压力。与旧系统相比,该系统还提高了可扩展性,旧系统需要技术美术为每个平台、每种游戏模式、每个资源类别手动设置流送预算。
随着着色器日益复杂,需要更多独特的 UV 变量,每个材质仅支持四个回读纹理槽位的限制必须得到解决。可以通过使用超过一个 16 位纹理通道、动态槽位数和改进打包方案来解决此问题,同时密切关注性能影响。
另一个值得探索的方向是将 GPU 回读式纹理流送与需要 UV 导数计算的渲染管线相结合。近期,有许多关于可见性缓冲区渲染的示例,用于处理微小三角形或对四边形不友好的资源。这些技术在着色器中计算 UV 导数,我们或许可以以较低的成本轻松地为其提供 GPU 回读式纹理流送支持。
参考文献
Burns and Hunt 13 Christopher A. Burns and Warren A. Hunt. "The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading." Journal of Computer Graphics Techniques 2:2 (2013), 55--69. http://jcgt.org/published/0002/02/04/.
Karis et al. 21 Brian Karis, Rune Stubbe, and Graham Wihlidal. "A Deep Dive into Nanite Virtualized Geometry." Presented at SIGGRAPH, 2021. https://advances.realtimerendering.com/s2021/Karis_Nanite_SIGGRAPH_Advances_2021_final.pdf
McLaren 22 James McLaren. "Adventures with Deferred Texturing in Horizon Forbidden West." Guerrilla, 2022. https://www.guerrilla-games.com/read/adventures-with-deferred-texturing-in-horizon-forbidden-west
Microsoft 19 Microsoft. "earlydepthstencil." Windows App Development, Direct3D Reference for HLSL, 2019. https://learn.microsoft.com/en-us/windows/win32/direct3dhlsl/sm5-attributes-earlydepthstencil.
Microsoft 21 Microsoft. "Sampler Feedback." DirectX-Specs, 2021. https://microsoft.github.io/DirectX-Specs/d3d/SamplerFeedback.html.
Segal and Akeley 12 Mark Segal and Kurt Akeley. "The OpenGL Graphics System: A Specification, Version 4.2." Khronos, 2012. https://registry.khronos.org/OpenGL/specs/gl/glspec42.core.pdf.
Segal and Akeley 22 Mark Segal and Kurt Akeley. "The OpenGL Graphics System: A Specification, Version 4.6." Khronos, 2022. https://registry.khronos.org/OpenGL/specs/gl/glspec46.core.pdf.
注释
Burns and Hunt 13 - 奠基:可见性缓冲
解决的问题 :传统延迟渲染(Deferred Shading)的带宽和内存瓶颈。传统方式需要在G-Buffer中存储大量材质属性(如法线、高光、粗糙度等),导致高带宽消耗和固定的材质复杂度。
提出的方案 :可见性缓冲(Visibility Buffer, V-Buffer)。
极简的几何通道 :在第一阶段,仅将每个像素的材质ID 和深度(或原始三角形ID)写入一个很小的缓冲区,替代庞大的G-Buffer。
延迟材质解析:在后续的着色阶段,根据材质ID从全局材质表中动态获取真正的材质属性和着色程序,再进行着色计算。
核心思想 :"延迟材质(Deferred Material)"。将几何与材质的耦合彻底打破,极大地节省了带宽和内存,并为复杂的材质系统提供了灵活性。
McLaren 22 - 工业实践:延迟贴图
解决的问题 :在开放世界游戏中,应用Nanite式虚拟几何体时,如何高效处理与之匹配的海量、超高分辨率纹理。直接流送所有纹理的Mipmap链内存消耗巨大。
提出的方案 :延迟贴图(Deferred Texturing) ,可视作 Burns and Hunt 13 思想的延伸与工业化实现。
结合虚拟几何体 (如PlayStation的"Geometry Engine")和虚拟纹理。
在几何通道中,只输出几何缓冲区(包含原始三角形ID、顶点偏移、材质ID等)。
在着色通道中,使用几何缓冲区中的信息,动态地从虚拟纹理页中获取所需的纹理像素(Texel)。
核心思想 :"不流送看不见的纹理"。将纹理数据的需求也延迟到像素着色阶段,通过虚拟纹理技术按需流送,解决了超高质量资产的内存问题。
Karis et al. 21 - 革命:几何虚拟化
解决的问题 :实时渲染中几何细节的终极瓶颈。传统网格LOD(细节层次)系统制作成本高、内存占用大,且存在POP(突变)问题,难以渲染电影级细节的资产。
提出的方案 :Nanite虚拟化几何管线。
预处理 :将影视级模型自动转换为支持粒度细至三角形的CLOD(连续细节层次) 的集群网格数据。
硬件光栅化 :完全基于硬件光栅化管线 ,通过包围盒层级剔除、三角形集群裁剪、自适应细节选择,每帧仅流送和光栅化必要的三角形。
可见性缓冲 :使用改进版的可见性缓冲作为输出,仅存储实例/集群ID、三角形ID、重心坐标,完美契合延迟贴图。
核心思想 :"几何即流媒体"。将几何体视为可实时、自适应流式传输的数据,实现了从"手工LOD"到"自动无限细节"的范式转移。
Microsoft 19 & Segal and Akeley 12/22 - 图形API特性
这几篇是支撑上述高级技术的底层API特性规范。
Microsoft 19 earlydepthstencil:
解决问题 :解决深度测试与像素着色器执行顺序导致的性能浪费(过度绘制)。
方案 :HLSL属性,允许像素着色器在运行前就进行深度/模板测试并更新深度缓冲。这能让后续被遮挡的像素提前被剔除,大幅提升性能,是高效延迟管线的关键优化。
Segal and Akeley 12/22 OpenGL 规范:
- 内容 :定义图形系统的标准,包含了实现上述各种算法所需的基础功能,如变换反馈、计算着色器、纹理数组、稀疏纹理等。4.2到4.6版本的演进体现了对GPU通用计算和复杂资源管理能力的支持升级。
Microsoft 21 - 关键使能技术:采样器反馈
解决的问题 :虚拟纹理/延迟贴图中"哪些纹理数据是下一帧真正需要的"难以高效预测,可能导致卡顿或质量下降。
提出的方案 :采样器反馈(Sampler Feedback) 硬件特性。
运行时跟踪 :GPU在着色过程中,自动记录实际被采样到的纹理区域及其Mip层级。
生成反馈图:这些信息被写入一张"反馈"纹理。
精准流送 :驱动程序或游戏引擎分析反馈图,精准预加载下一帧所需的确切纹理块 ,实现零过载(只流需要的)和零遗漏(需要的都有) 的理想状态。
核心思想 :"让GPU告诉CPU它需要什么"。将纹理流送的决策从基于猜测的启发式方法,转变为基于实际渲染需求的精确数据驱动方法,是虚拟纹理和延迟贴图能够高效、稳定运行的核心。
OpenGL 4.2 升级到 4.6
1. 计算着色器(OpenGL 4.3+,在4.6中成熟)
它是什么:一种不受图形管线(顶点、像素等)约束的通用并行计算程序,直接在GPU上运行。
对高级渲染的作用:
Karis et al. 21 Nanite :用于实现GPU驱动的剔除(Culling) 。Nanite的核心------层次深度剔除(Hi-Z Culling)、集群包围盒剔除,都是在计算着色器中并行完成的,然后通过间接绘制(Indirect Draw) 指令让硬件光栅化仅处理可见的集群。这是实现"仅流送可见几何"的关键。
Microsoft 21 采样器反馈分析:生成反馈图后,分析哪些纹理块需要被加载或提升Mip层级,这个分析过程非常适合用计算着色器并行处理。
任何后期处理:如屏幕空间反射、环境光遮蔽等,现在都大量使用计算着色器。
2. 着色器存储缓冲对象与原子操作
它是什么:允许着色器(特别是计算着色器)读写一个结构化的、巨大的全局内存缓冲区,并能进行原子操作(如增加、比较交换)。
对高级渲染的作用:
Karis et al. 21 Nanite :用于实现实例化与间接参数生成。计算着色器将剔除结果(如每个集群的可见性)写入SSBO,另一个计算着色器或间接绘制命令读取这个缓冲区,来知道要绘制多少个实例、每个实例使用什么参数。这是GPU驱动管线的基石。
Burns and Hunt 13 V-Buffer :可用于实现复杂的材质全局表,供所有像素着色器随机访问。
3. 纹理数组与数组纹理
它是什么:将多个相同尺寸和格式的2D纹理组合成一个单一的纹理对象,在着色器中可以通过一个索引来访问不同的"层"。
对高级渲染的作用:
- Burns and Hunt 13 V-Buffer / McLaren 22 延迟贴图 :这是实现材质系统 的核心数据结构。所有材质的漫反射贴图、法线贴图等,可以分别打包到几个巨大的纹理数组中。像素着色器根据
材质ID,就能索引到对应的纹理层进行采样,替代了传统方式下为每个物体绑定独立纹理的低效操作。4. 稀疏纹理(OpenGL 4.6/ARB_sparse_texture)
它是什么:一种"虚拟"纹理,其存储空间(显存)可以部分提交、按需分配。你可以先声明一个巨大的纹理,但只为其一部分区域(称为"Tile"或"Page")实际分配内存。
对高级渲染的作用:
McLaren 22 延迟贴图 / 虚拟纹理 :这是虚拟纹理得以实现的最底层硬件/API支持。《地平线》等游戏使用的虚拟纹理技术,其本质就是稀疏纹理的应用。游戏世界中的海量纹理被平铺成小块,只有当前视角附近需要的那些块才会被提交到显存中。
与 Microsoft 21 采样器反馈的关系 :采样器反馈正是为了智能化地管理稀疏纹理的页表而设计的。反馈信息告诉驱动,下一帧哪些"稀疏块"需要被提交或释放。
5. 间接绘制与多重间接绘制
它是什么:允许CPU不直接指定绘制调用的参数(如顶点数量、实例数量),而是将这些参数存储在一个GPU缓冲区中,由GPU来读取并执行绘制。
对高级渲染的作用:
- Karis et al. 21 Nanite :这是GPU驱动渲染的"最后一公里" 。计算着色器完成剔除后,将每个要绘制的集群的绘制参数写入一个缓冲区。然后,一个极简的CPU调用(
glMultiDrawIndirect)即可启动成百上千个独立的绘制命令,每个命令的参数都来自GPU的计算结果。这彻底解放了CPU,避免了CPU与GPU之间频繁的同步和通信。6. 变换反馈(及其高级形式)
它是什么:允许将顶点着色器(或几何着色器)的输出捕获回GPU缓冲区,而不是直接光栅化。
对高级渲染的作用:
高级剔除与LOD选择:在一些方案中(如早期的GPU驱动渲染实验),可用于处理视锥剔除或LOD选择的结果流。
粒子系统模拟:经典用途之一。
从 4.2 (2012) 到 4.6 (2022) 的演进意义
OpenGL 4.2 (2012) :代表了早期可编程管线的成熟。它具备了现代着色器模型的基础,但高级GPU计算和资源管理能力还较弱。
OpenGL 4.6 (2022) :集大成者,标志着GPU作为通用并行计算设备的地位被完全确立。它强制要求支持之前许多需要扩展(如ARB_gl_spirv, ARB_sparse_texture)才能使用的功能,并加强了对Vulkan等现代API理念的兼容(如SPIR-V着色器字节码支持)。
传统延迟渲染 (带宽/内存瓶颈)
↓
可见性缓冲 (延迟材质,打破几何-材质耦合) Burns and Hunt 13
↓
|--- 演进为 ---> 工业级延迟贴图管线 (解决海量纹理) McLaren 22
|
↓
|--- 结合革命性思想 ---> 虚拟几何体 (解决海量几何) Karis et al. 21
|
↓
共同依赖的底层API优化 Microsoft 19, Segal and Akeley
&
关键的使能硬件特性 Microsoft 21
注释