现代机器学习GPU(例如H100、B200)基本上是由多个专门用于矩阵乘法的计算核心(称为流式多处理器或SM)连接到一块高速内存条(称为HBM)组成。下图所示:
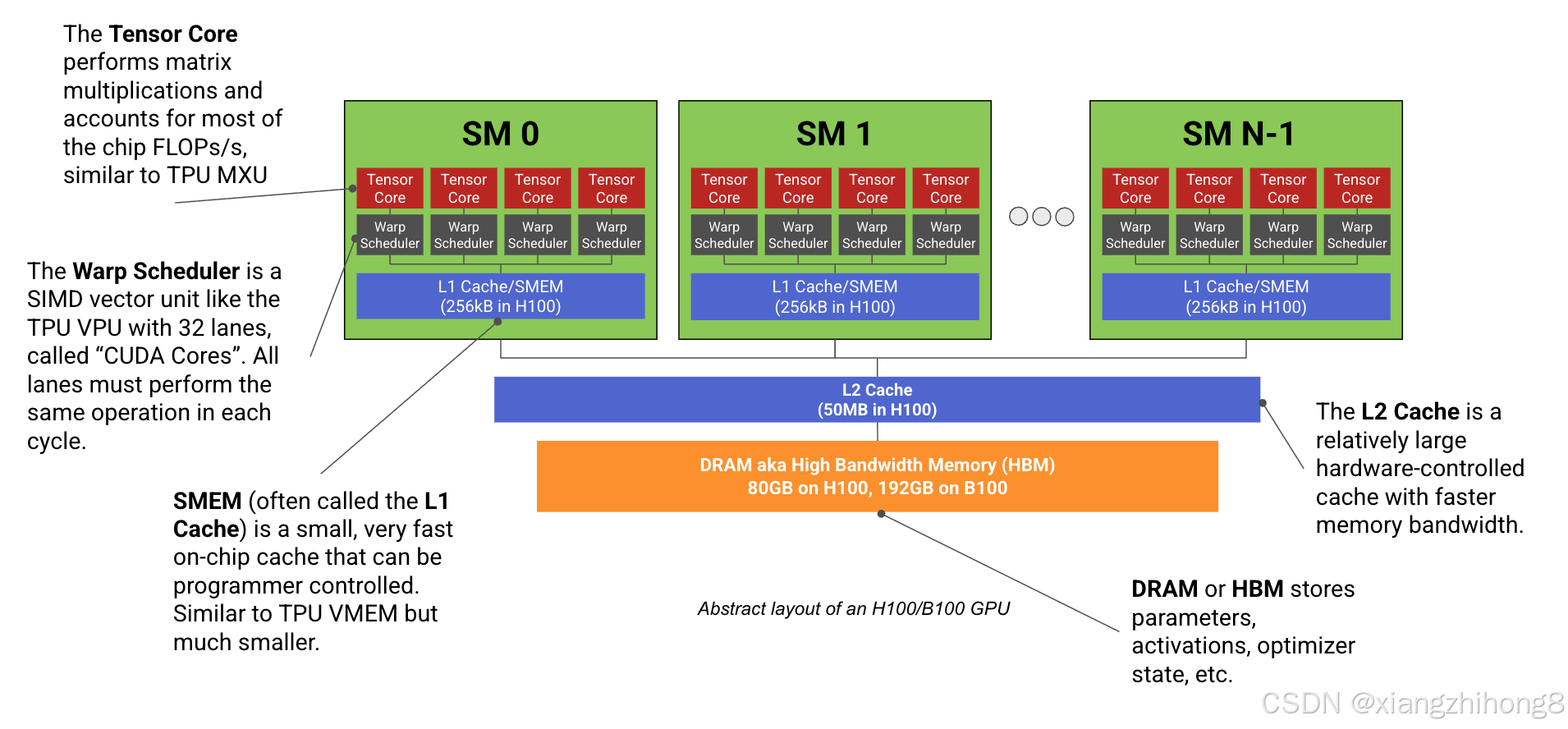 图: H100 或 B200 GPU 的抽象布局示意图。H100 有 132 个 SM(流式多处理器),而 B200 有 148 个。我们用"Warp Scheduler"(线程束调度器)一词来泛指一组 32 个 CUDA SIMD 核心以及将工作分配给它们的调度器。请注意,它看起来很像 TPU!
图: H100 或 B200 GPU 的抽象布局示意图。H100 有 132 个 SM(流式多处理器),而 B200 有 148 个。我们用"Warp Scheduler"(线程束调度器)一词来泛指一组 32 个 CUDA SIMD 核心以及将工作分配给它们的调度器。请注意,它看起来很像 TPU!
每个SM(就像TPU的张量核心一样)都有一个专用的矩阵乘法核心(不幸的是,它也被称为张量核心)。),一个向量算术单元(称为Warp 调度器) 。)以及高速片上缓存(称为SMEM)。与最多只有2个独立"张量核心"的TPU不同,现代GPU拥有超过100个SM(H100上为132个)。虽然每个SM的性能远低于TPU的张量核心,但整个系统更加灵活。每个SM几乎完全独立,因此GPU可以同时执行数百个不同的任务。
让我们更详细地了解一下H100 SM:
图: H100 SM 的示意图(来源),图中显示了 4个子分区,每个子分区包含一个张量核心、一个线程束调度器、一个寄存器文件以及不同精度的 CUDA 核心组。底部附近的"L1 数据缓存"是 256kB 的 SMEM 单元。B200 的结构与之类似,但增加了大量的张量内存 (TMEM),用于为体积庞大的张量核心提供数据。
每个SM被划分为4个相同的象限,NVIDIA称之为SM子分区,每个子分区包含一个Tensor Core、16k个32位寄存器以及一个名为Warp Scheduler的SIMD/SIMT向量运算单元,其通道(ALU)NVIDIA称之为CUDA Core。每个分区的核心组件可以说是Tensor Core,它执行矩阵乘法运算,贡献了其绝大部分的FLOPs/s(浮点运算/秒),但它并非唯一值得注意的组件。
-
CUDA 核心:每个子分区包含一组称为 CUDA 核心的 ALU,用于执行 SIMD/SIMT 向量运算。每个 ALU 通常每个周期可以执行 1 个算术运算,例如 f32.add。每个子分区包含 32 个 fp32 核心(以及少量 int32 和 fp64 核心),每个核心在每个周期执行相同的指令。与 TPU 的 VPU 类似,CUDA 核心负责 ReLU 激活函数、逐点向量运算和归约(求和)操作。
-
张量核心 (TC):每个子分区都有自己的张量核心,它是一个专用的矩阵乘法单元,类似于 TPU MXU。张量核心贡献了 GPU 的绝大多数 FLOPs/s(例如,在 H100 上,我们有 990 bf16 TC TFLOP/s,而 CUDA 核心只有 66 TFLOPs/s)。
-
990 bf16 TFLOPs/s, 132 个 SM 以 1.76GHz 的频率运行,意味着每个 H100 TC 可以执行
7.5e12 / 1.76e9 / 4 ~ 1024bf16 FLOPs/周期,大约相当于 8x8x8 矩阵乘法。 -
与 TPU 类似,GPU 可以以更高的吞吐量执行低精度矩阵乘法运算(例如,H100 的 fp8 FLOPs/s 是 fp16 的两倍)。低精度训练或服务速度可以显著提升。
-
自 Volta 架构以来,每一代 GPU 的 TC(时间转换器)容量都比上一代有所增加(相关内容可参阅相关文章)。到了 B200 架构,TC 的容量已经大到无法再将其输入存储在 SMEM(单帧内存)中,因此 B200 引入了一种名为 TMEM(时间存储器)的新内存空间。
-
CUDA 核心比 TPU 的 VPU 更灵活: GPU CUDA 核心(自 V100 版本起)采用 SIMT(单指令多线程 )编程模型,而 TPU 则采用 SIMD(单指令多数据 )模型。与 TPU VPU 中的 ALU 类似,子分区内的 CUDA 核心必须在每个周期执行相同的操作(例如,如果一个核心正在计算两个浮点数的和,那么子分区中的其他所有 CUDA 核心也必须执行相同的操作)。然而,与 VPU 不同的是,每个 CUDA 核心(或 CUDA 编程模型中的"线程")都有自己的指令指针,可以独立编程 。当同一个 warp 中的两个线程被指示执行不同的操作时,实际上会执行这两个操作,从而屏蔽掉不需要执行不同操作的核心。
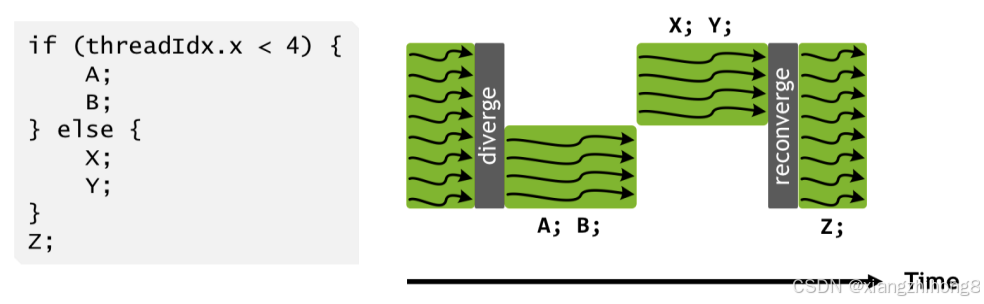 **图:**一组线程中线程束发散的示例(来源)。白色区域表示至少一部分物理 CUDA 核心发生停滞。
**图:**一组线程中线程束发散的示例(来源)。白色区域表示至少一部分物理 CUDA 核心发生停滞。
这使得线程级别的编程更加灵活,但代价是如果线程束发散过于频繁,性能会悄然下降。线程在访问内存方面也更加灵活;VPU 只能操作连续的内存块,而 CUDA 核心可以访问共享寄存器中的单个浮点数,并维护每个线程的状态。
CUDA 核心调度也更加灵活: SM 的运行方式有点像多线程 CPU,因为它们可以同时"调度"许多程序(线程束)(每个 SM 最多 64 个),但每个线程束调度器在每个时钟周期中只执行一个程序。Warp调度器会自动在活动线程束之间切换,以隐藏内存加载等I/O操作。相比之下,TPU通常是单线程的。
记忆
除了计算单元之外,GPU 还具有内存层次结构,其中最大的是 HBM(GPU 主内存),然后是一系列较小的缓存(L2、L1/SMEM、TMEM、寄存器内存)。
-
寄存器:每个子分区都有自己的寄存器文件,其中包含 H100/B200(每个 SM)上的 16,384 个 32 位字,
4 * 16384 * 4 = 256kiBCUDA 内核可以访问该文件。- 每个 CUDA 核心一次最多只能访问 256 个寄存器,因此尽管我们可以为每个 SM 调度多达 64 个"驻留线程束",但
256 * 1024 / (4 * 32 * 256)如果每个线程使用 256 个寄存器,则一次只能容纳 8 个线程束。
- 每个 CUDA 核心一次最多只能访问 256 个寄存器,因此尽管我们可以为每个 SM 调度多达 64 个"驻留线程束",但
-
SMEM(L1缓存):每个SM都有其自身的256kB片上缓存,称为SMEM。SMEM既可以由程序员控制作为"共享内存",也可以由硬件用作片上缓存。SMEM用于存储TC矩阵乘法器的激活值和输入值。
-
L2缓存:所有SM共享9使用相对较大的约 50MB L2 缓存来减少主内存访问。
-
它的大小与TPU的VMEM类似,但速度慢得多,而且不受程序员控制。这就导致了一种"远程控制"的现象:程序员需要修改内存访问模式,以确保L2缓存得到充分利用。10
-
NVIDIA并未公布其芯片的L2带宽,但经测量约为5.5TB/s。这大约是HBM带宽的1.6倍,但由于它是全双工的,因此实际双向带宽接近3倍。相比之下,TPU的VMEM容量是其两倍*,*带宽也更高(约为40TB/s)。
-
-
HBM: GPU 主内存,用于存储模型权重、梯度、激活值等。
-
HBM 容量从 Volta 的 32GB 大幅增加到 Blackwell (B200) 的 192GB。
-
从 HBM 到 CUDA Tensor Core 的带宽称为 HBM 带宽或内存带宽,在 H100 上约为 3.35TB/s,在 B200 上约为 9TB/s。
-
GPU规格概要
以下是近期几款GPU的规格概要。同一GPU的不同版本在SM单元数量、时钟频率和浮点运算能力方面略有差异。以下是显存容量数据:
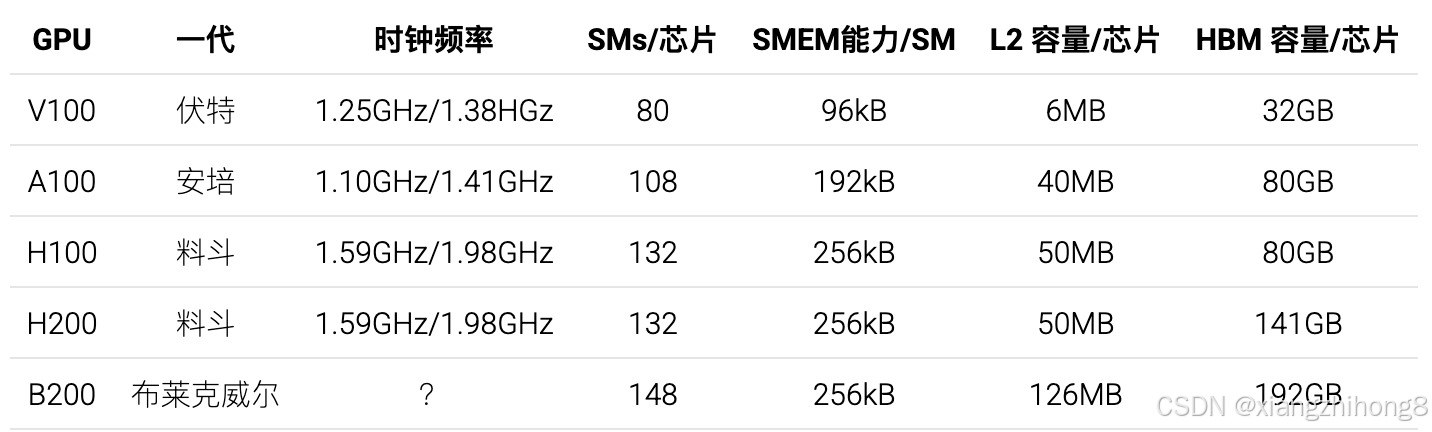 所有世代的SM单元都配备256kB的寄存器内存。Blackwell架构的SM单元还额外配备了256kB的TMEM内存。以下是各芯片的浮点运算性能和带宽数据:
所有世代的SM单元都配备256kB的寄存器内存。Blackwell架构的SM单元还额外配备了256kB的TMEM内存。以下是各芯片的浮点运算性能和带宽数据:
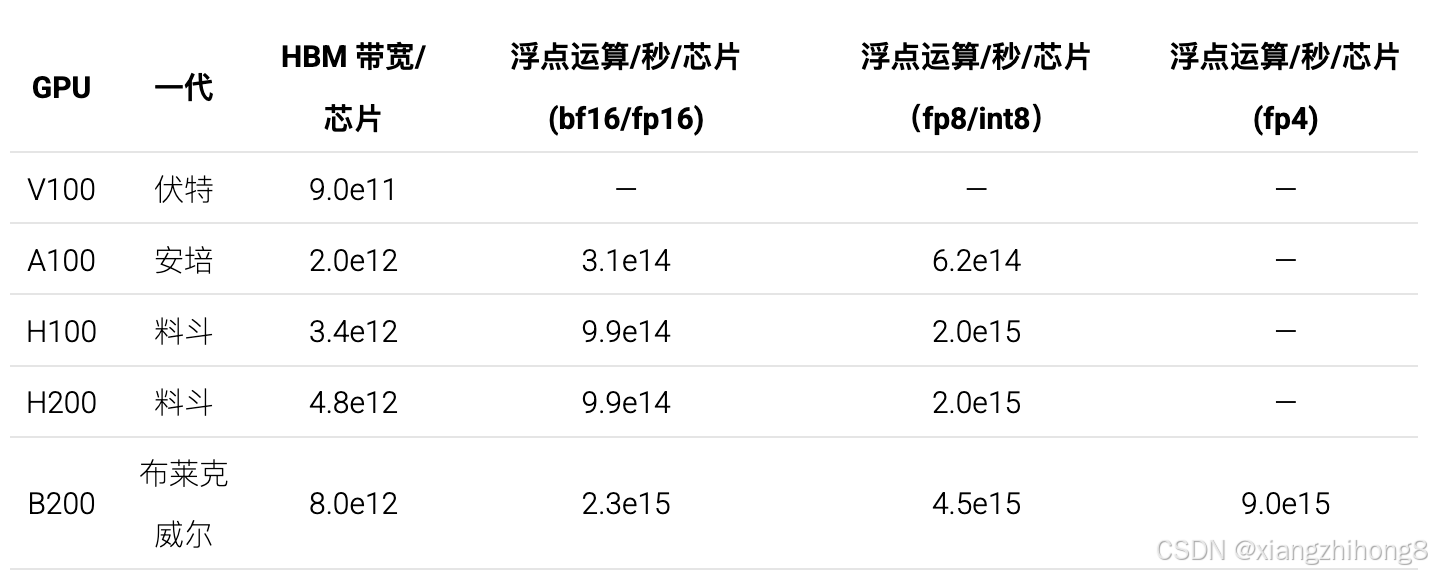 由于 B100 不是批量生产的,所以我们将其排除在外。11某些规格会略微取决于 GPU 的具体版本,因为 NVIDIA GPU 不像 TPU 那样标准化。
由于 B100 不是批量生产的,所以我们将其排除在外。11某些规格会略微取决于 GPU 的具体版本,因为 NVIDIA GPU 不像 TPU 那样标准化。
以下是一份便于理解的GPU和TPU组件对比表:
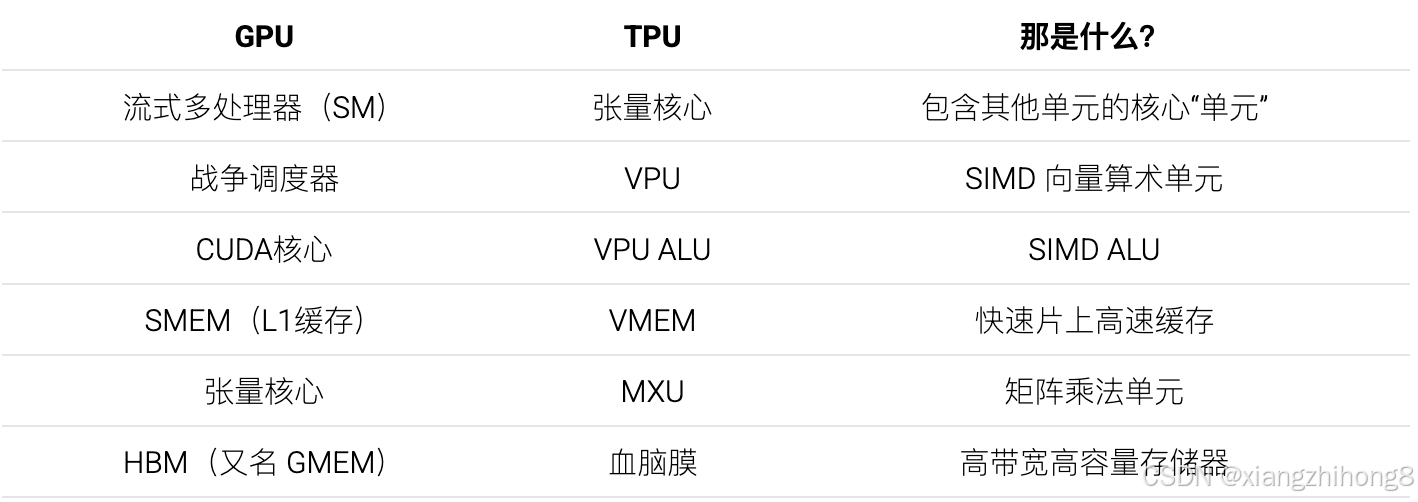
芯片级GPU与TPU的比较
GPU 最初是用来渲染视频游戏的,但自从 2010 年代深度学习兴起以来,它们的作用越来越像专用矩阵乘法机------换句话说,越来越像 TPU。12从某种程度上说,这段历史解释了现代GPU的外观。它们的设计初衷并非纯粹为了LLM或机器学习模型,而是作为通用加速器,其硬件追求的"通用性"既是优势也是劣势。GPU在应用于新任务时通常"开箱即用",对优秀编译器的依赖程度远低于TPU。但这同时也使得GPU的性能分析和极限性能挖掘变得更加困难,因为许多编译器特性都可能造成瓶颈。
GPU 的模块化程度更高。TPU拥有 1-2 个大型 Tensor Core,而 GPU 则拥有数百个小型 SM。同样,每个 Tensor Core 包含 4 个大型 VPU,每个 VPU 拥有 1024 个 ALU,而 GPU 的 H100 芯片则拥有 132 * 4 = 528 个独立的 SIMD 单元。以下是 GPU 与 TPU 的 1:1 对比,突显了这一点:
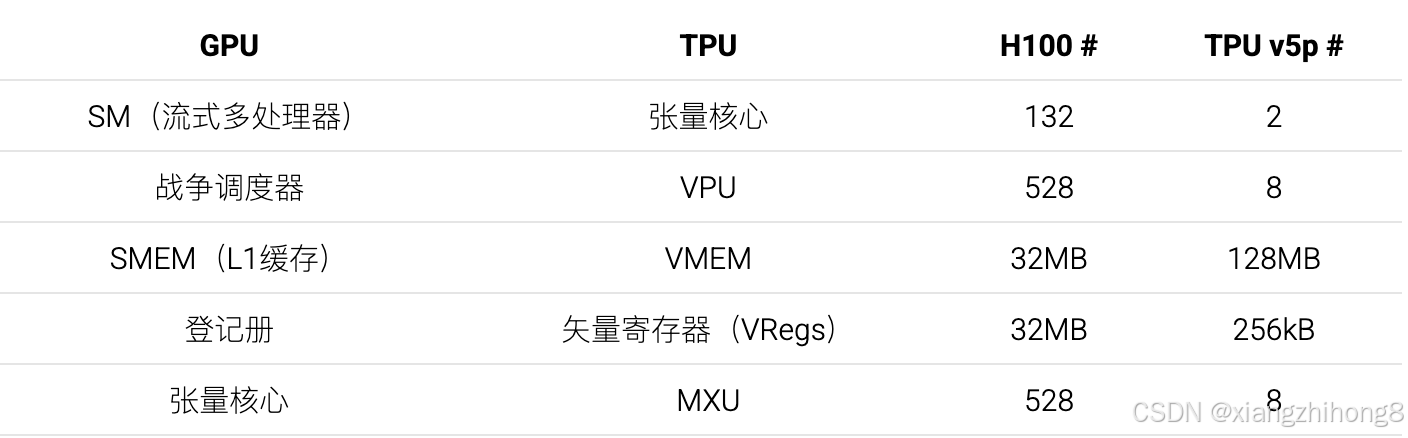 一方面,模块化程度的差异使得TPU的构建成本更低、更易于理解,但另一方面,这也给编译器带来了更大的负担,需要编译器做出正确的处理。由于TPU只有一个控制线程,并且只支持向量化的VPU级指令,编译器需要手动流水线化所有内存加载和MXU/VPU操作,以避免停顿。而GPU程序员可以启动数十个不同的内核,每个内核运行在一个完全独立的SM上。另一方面,这些内核可能会因为频繁访问L2缓存或内存加载无法合并而导致性能极差;由于硬件控制了运行时的大部分过程,因此很难了解其背后的运行机制。因此,TPU通常能够以更少的工作量接近其性能峰值。
一方面,模块化程度的差异使得TPU的构建成本更低、更易于理解,但另一方面,这也给编译器带来了更大的负担,需要编译器做出正确的处理。由于TPU只有一个控制线程,并且只支持向量化的VPU级指令,编译器需要手动流水线化所有内存加载和MXU/VPU操作,以避免停顿。而GPU程序员可以启动数十个不同的内核,每个内核运行在一个完全独立的SM上。另一方面,这些内核可能会因为频繁访问L2缓存或内存加载无法合并而导致性能极差;由于硬件控制了运行时的大部分过程,因此很难了解其背后的运行机制。因此,TPU通常能够以更少的工作量接近其性能峰值。
从历史数据来看,单个GPU的性能(以及价格)都比同等配置的TPU更强大:单个H200的浮点运算速度(FLOPs/s)几乎是TPU v5p的两倍,HBM显存则是其1.5倍。同时,在谷歌云平台上,H200的标价约为每小时10美元,而TPU v5p的标价仅为每小时4美元。与GPU相比,TPU通常更依赖于多个芯片的联网。
TPU 拥有更大的高速缓存。此外,TPU 的 VMEM 容量也远大于 GPU 的 SMEM(加上 TMEM),这些内存可用于存储权重和激活值,从而实现极快的加载和使用。如果能够持续地将模型权重存储或预取到 VMEM 中,则可以显著提升 LLM 推理的速度。
测验 1:GPU 硬件
这里有一些练习题,可以帮助你检验对以上内容的掌握程度。答案已提供,但最好在查看答案之前,先尝试用笔和纸自己作答。
问题 1 CUDA 核心
H100 有多少个 fp32 CUDA 核心(ALU)?B200 又有多少个?这与 TPU v5p 中独立 ALU 的数量相比如何?
答 : H100 有 132 个 SM,每个 SM 分为 4 个子分区,每个子分区包含 32 个 fp32 CUDA 核心,因此我们有132 * 4 * 32 = 16896CUDA 核心。B200 有148SM,因此总共有CUDA 核心18944。TPU v5p 有 2 个 TensorCore(通常通过 Megacore 连接),每个 TensorCore 包含一个 VPU,该 VPU 具有 (8, 128) 条通道,每条通道有 4 个独立的 ALU,因此2 * 4 * 8 * 128 = 8192有 ALU。这大约是 H100 向量通道数的一半,运行频率大致相同。
问题 2 向量浮点运算次数计算
单个 H100 有 132 个 SM 单元,运行频率为 1.59GHz(最高可达 1.98GHz)。假设每个 ALU 每个时钟周期可以执行一次向量运算。每秒可以执行多少次向量 fp32 浮点运算?使用睿频加速后呢?这与矩阵乘法浮点运算次数相比如何?
答 :使用 Boost 后,其浮点运算速度为 33.5 TFLOPs/s。这只有 规格表132 * 4 * 32 * 1.59e9 = 26.9TFLOPs/s上数据的一半,因为理论上我们可以在一个周期内执行一次 FMA(融合乘加)运算,这算作两次浮点运算,但在大多数情况下这没什么用。我们可以执行 990 TFLOPs/s 的 bfloat16 矩阵乘法运算,因此忽略 FMA 运算,Tensor Core 的浮点运算速度大约是其 30 倍。
问题 3 GPU 矩阵乘法强度
H100、B200 和 fp8 的峰值 fp16 矩阵乘法强度分别是多少?强度指的是矩阵乘法浮点运算速度(FLOPs/s)与内存带宽的比值。
答 :对于 H100,峰值浮点运算能力为 990e12 fp16 FLOPs,带宽为 3.35e12 字节/秒。因此990e12 / 3.35e12 = 295,其临界强度与 TPU 的 240 非常接近。对于 B200 2250e12 / 8e12 = 281,其临界强度也非常接近。这意味着,与 TPU 类似,在矩阵乘法运算中,我们需要大约 280 的批处理大小才能达到计算瓶颈。
对于 H100 和 B200,我们恰好有 2 倍的 fp8 FLOPs,因此峰值强度也分别翻倍至 590 和 562,尽管从某种意义上说,如果我们考虑到权重也可能以 fp8 格式加载,它就保持不变。
问题 4 MATMU 运行时间
根据问题 3 的答案,您预计fp16[64, 4096] * fp16[4096, 8192]在单个 B200 上执行 MATMU 操作需要多长时间?如果是呢fp16[512, 4096] * fp16[4096, 8192]?
答:从以上内容可知,当批处理大小小于 281 个令牌时,通信将受到限制。因此,第一个问题纯粹受带宽限制。我们进行读取或写入操作。
2 B D + 2 D F + 2 B F 字节(2*64*4096 + 2*4096*8192 + 2*64*8192=69e6)8e12的带宽为字节/秒,因此大约需要69e6 / 8e12 = 8.6us。实际上,我们可能只能利用总带宽的一小部分,因此可能需要接近 10-12 微秒。当我们增加批处理大小时,计算量将完全受限,因此我们预计T=2*512*4096*8192/2.3e15=15us。同样,我们预计只能利用总 FLOPs 的一小部分,因此我们可能会看到接近 20 微秒。
问题 5 L1 缓存容量
H100 的总 L1/SMEM 容量是多少?寄存器内存容量是多少?这与 TPU VMEM 容量相比如何?
答 :每个SM单元有256kB的SMEM和256kB的寄存器内存,各约33MB 132 * 256kB。加起来总共约66MB。这大约是现代TPU的VMEM(120MB)的一半,尽管TPU的总寄存器内存只有256kB!TPU的VMEM延迟低于SMEM延迟,这也是TPU上的寄存器内存并非至关重要的原因之一(VMEM的溢出和填充开销很小)。
问题 6 计算 B200 时钟频率
NVIDIA 报告称,B200 可以执行 80TFLOPS/s 的向量 fp32 计算。已知每个 CUDA 核心在 FMA(融合乘加)操作中每个周期可以执行 2 FLOPs,请估算峰值时钟周期。
答 :我们知道有 148 * 4 * 32 = 18944 个 CUDA 核心,所以我们可以做到18944 * 2 = 37888 FLOPs / cycle。因此80e12 / 37888 = 2.1GHz,可以实现一个较高但合理的峰值时钟频率。B200 系列处理器通常采用液冷散热,因此更高的时钟频率更为合理。
问题 7 估算 H100 加法运算运行时间
fp32[N]使用上图,计算在单个 H100 上将两个向量相加所需的时间。计算两个向量的加法运算时间。T数学和T通信这个操作的算术强度是多少?如果可以访问,请尝试在 PyTorch 或 JAX 中分别运行此操作,并N = 1024比较N=1024 * 1024 * 1024结果。
答 :首先,将两个fp32[N]向量相加需要执行 N 次 FLOP 运算,需要4 * N * 2加载字节数,并写回 4 * N 个字节,总共需要3 * 4 * N = 12N。计算它们的比率,我们得到total FLOPs / total bytes = N / 12N = 1 / 12,这非常糟糕。
正如我们上面计算的,忽略 FMA,我们可以获得大约 33.5 TFLOPs/s 的性能提升。这仅在所有 CUDA 核心都被使用的情况下才成立。对于,我们最多 N = 1024只能使用1024 个 CUDA 核心或 8 个 SM,这将耗时更长(假设我们受限于计算能力,则大约需要 16 倍的时间)。此外,我们的内存带宽为 3.35e12 字节/秒。因此,我们的峰值硬件强度为。33.5e12 / 3.35e12 = 1013所以我们将严重受限于通信。因此,我们的运行时环境将非常有限。
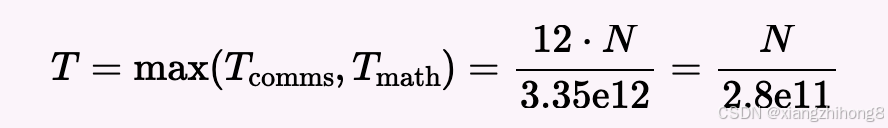 对于
对于N = 65,536,这大约是 0.23 微秒。实际上,我们在 JAX 中看到的运行时间约为 1.5 微秒,这没问题,因为我们预计这里会受到极高的延迟限制。对于N = 1024 * 1024 * 1024,我们设定的最高延迟约为 3.84 毫秒,而实际运行时间为 4.1 毫秒,这很好!