CLIP surgery
动机
CLIP存在相反激活问题,意味着它关注图像的背景,而不是前景。
验证实验
反向可视化
Q-K自注意力本来应该在前景位置激活,但是却发现主要在背景位置激活,这说明Q-K学偏了。
噪声激活
即使使用空字符串作为类别嵌入,发现也能激活一些无关的地方,这说明CLIP的局部特征中分享着一些共同类别的特征 。
CLIP 为了适应海量类别,会学到大量在当前类别下"未激活"的特征,这些就是冗余特征 。

先直接按照你给的提纲来梳理这篇 CLIP Surgery for Better Explainability with Enhancement in Open-Vocabulary Tasks。
0. 摘要翻译(意译)
对比语言--图像预训练模型 CLIP 是一个强大的多模态视觉模型,在零样本和文本引导视觉任务中表现出色。但我们发现它在可解释性上有严重问题:
1)CLIP 预测出的相似度热力图更偏向背景而不是前景,这与人类直觉相反;
2)可视化结果中在无关位置有大量噪声激活。
为了解决这两个问题,作者做了深入分析,给出新的发现和证据,并据此提出 CLIP Surgery:在推理阶段像做"手术"一样修改结构和特征,从而提高可解释性,并提升多个开放词汇任务的性能。
CLIP Surgery 对卷积网络和 ViT 都显著提升了解释质量,远超现有方法;同时在开放词汇分割和多标签识别上也有明显收益。例如,在 NUS-Wide 多标签识别上 mAP 提升 4.41%(无任何额外训练),在 Cityscapes 开放词汇语义分割上比 SOTA 提高 8.74% mIoU。该方法还可以帮助多模态可视化和与 SAM 类似的交互式分割。代码开源在 GitHub。
1. 方法动机
1.a 为什么要提这个方法?
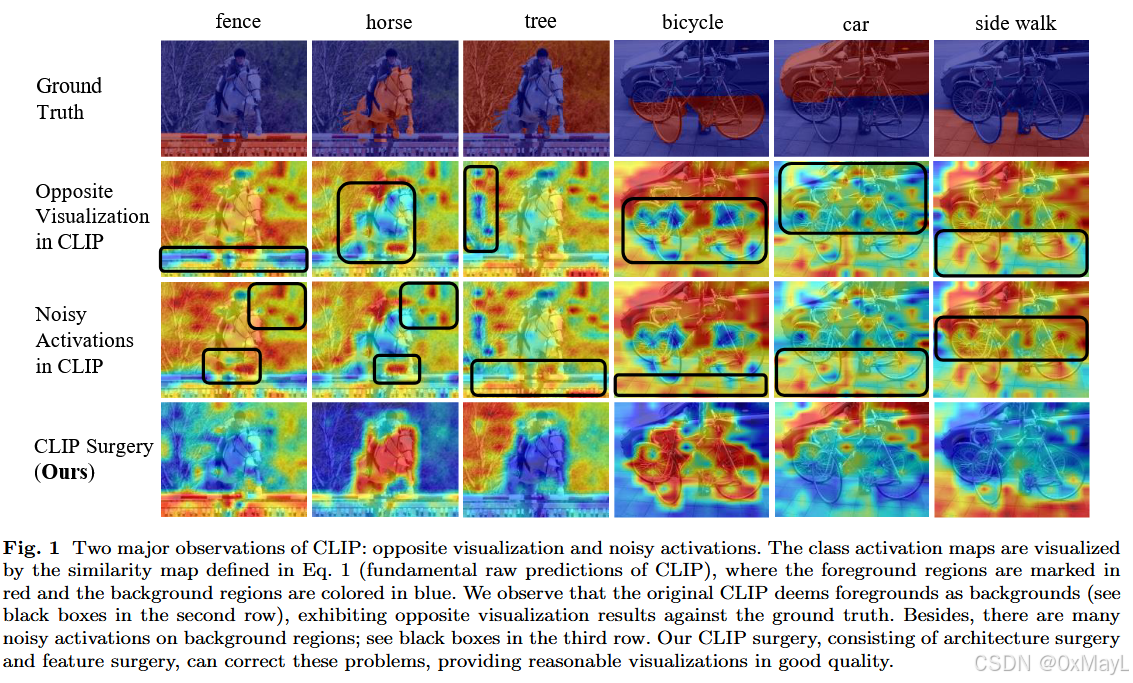
作者在直接用 CLIP 的 图文相似度图(similarity map) 来做可视化时发现两个很"离谱"的现象(Fig.1, Fig.3):
-
Opposite Visualization(反向可视化)
- 目标类本该高亮前景区域,结果 CLIP 的热力图却把前景当成"低分",背景当"高分"。
- 这种现象在 ResNet 和 ViT 的 CLIP 版本上都出现,是系统性问题,而不是个例或某个 backbone 的 bug。
-
Noisy Activations(噪声激活)
- 热力图上在无关背景位置出现大量散点状的高亮区域。
- 无论是 CLIP 自己的 similarity map,还是套用 Grad-CAM、Bi-Modal 等方法,这些噪声都有。
同时,现有可解释性方法多是为 单模态、全监督 网络设计的,直接移植到 CLIP 上效果很差(定量表 4 也证明了这一点)。
驱动力:
- 提供一个仅修改推理结构、无需训练的简单方法,既提升 CLIP 的可解释性,又能直接让开放词汇分割、多标签识别等下游任务受益。
1.b 现有方法的痛点/不足
-
传统可解释性方法(Grad-CAM, pLRP 等)
- 面向 CNN 或单模态 ViT 设计。
- 在 CLIP 上:mIoU & mSC 都很低,而且仍然存在"前景变背景"的现象。
-
多模态解释方法(Bi-Modal, gScoreCAM 等)
- 需要对每个 label 做反向传播,多次前向,效率低。
- 对密集预测(大分辨率热力图)退化更严重,对高输出分辨率非常敏感(Tab.5)。
-
RCLIP / ECLIP
- RCLIP:通过将 CLIP 的 similarity map 反向来"纠正"反向可视化,但本质上仍基于有问题的内部表征。
- ECLIP:需要额外训练新的池化层,复杂度增加,不够"即插即用"。
-
开放词汇分割现有方法
- 大多需要:额外模型(proposal net, saliency 模型)、复杂训练(聚类、自监督预训练)、或额外标注。
- 真正"完全不训练,仅改推理"的方法只有 MaskCLIP,但它只为分割设计,并未系统解决 explainability 问题。
1.c 论文核心假设 / 直觉(简化)
-
反向可视化的根源:
- 自注意力里 query / key 参数学偏了,把语义相反的区域关联在一起,导致关系图混乱。
- 如果只用 value--value 相似度(v-v self-attention),可以获得更"语义局部"的注意力。
-
噪声激活的根源:
- CLIP 为了适应海量类别,会学到大量在当前类别下"未激活"的特征,这些就是 冗余特征。
- 这些冗余特征在 similarity map 中会以"统一的噪声模式"出现(比如用空文本 prompt 也能看到类似的噪声激活)。
-
如果能:
- 用 v-v attention 替换原始 q-k attention;
- 跳过那些在语义上偏向"负类"的 FFN 特征;
- 显式估计并扣掉冗余特征;
就能同时修复 反向可视化 和 噪声激活,并提升开放词汇任务表现。
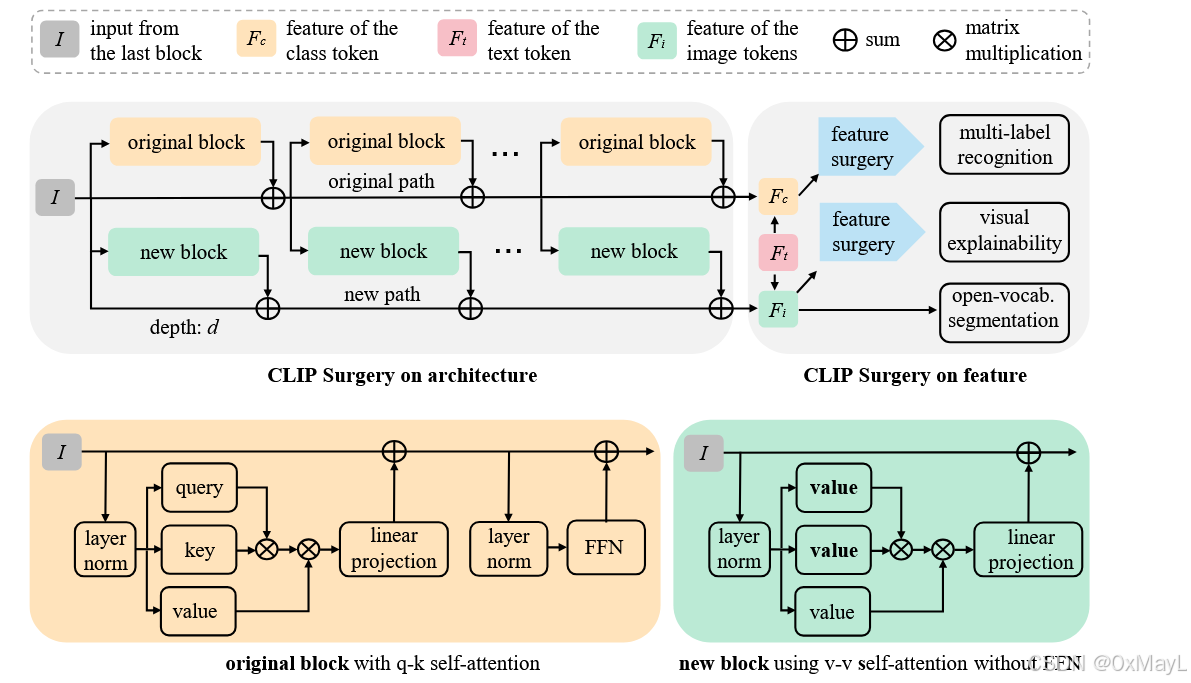
2. 方法设计
整体结构见 Fig.2(第 5 页):上半部分是 Architecture Surgery(结构手术) ,右上是 Feature Surgery(特征手术)。
2.a Pipeline 总览:输入 → 处理 → 输出
以 ViT-CLIP 为例:
-
标准 CLIP 前向
-
输入:图像 III 和若干文本标签 Tjj=1Nt{T_j}_{j=1}^{N_t}Tjj=1Nt。
-
图像编码器输出:
- class token 特征 Fc∈R1×CF_c \in \mathbb{R}^{1\times C}Fc∈R1×C
- patch tokens 特征 Fi∈RNi×CF_i \in \mathbb{R}^{N_i \times C}Fi∈RNi×C
-
文本编码器输出:
- 文本特征 Ft∈RNt×CF_t \in \mathbb{R}^{N_t \times C}Ft∈RNt×C
-
-
Architecture Surgery(结构手术)
-
从某个深度 ddd 开始,对后续 Transformer Block 复制一条"新路径":
- 在新路径中,把原来的 q-kq\text{-}kq-k 自注意力替换为 v-v 自注意力;
- 去掉 FFN,只保留注意力 + 线性投影;
- 用"二路残差"把新路径输出与原路径输出合并(dual paths)。
-
新路径专门给 解释 / 分割 用,原路径保留给 分类 / 多标签识别。
-
-
Feature Surgery(特征手术)
-
目标:从图文特征中估计"冗余部分"并减掉。
-
步骤(解释任务):
- 将 FiF_iFi 在文本维度复制为 F^i∈RNi×Nt×C\hat F_i \in \mathbb{R}^{N_i \times N_t \times C}F^i∈RNi×Nt×C,
将 FtF_tFt 在空间维度复制为 F^t∈RNi×Nt×C\hat F_t \in \mathbb{R}^{N_i \times N_t \times C}F^t∈RNi×Nt×C。 - 归一化后做逐元素乘法:
Fm=F^i∣F^i∣2⊙F^t∣F^t∣2∈RNi×Nt×C F^m = \frac{\hat F_i}{|\hat F_i|_2} \odot \frac{\hat F_t}{|\hat F_t|_2} \in \mathbb{R}^{N_i \times N_t \times C} Fm=∣F^i∣2F^i⊙∣F^t∣2F^t∈RNi×Nt×C - 用 class token 与文本的相似度算出每个类的权重 w∈R1×Ntw \in \mathbb{R}^{1 \times N_t}w∈R1×Nt,强调"显著类":
s=softmax(Fc∣Fc∣2⋅(Ft∣Ft∣2)⊤⋅τ),w=smean(s) s = \text{softmax}\Big( \frac{F_c}{|F_c|_2} \cdot (\frac{F_t}{|F_t|_2})^\top \cdot \tau \Big),\quad w = \frac{s}{\text{mean}(s)} s=softmax(∣Fc∣2Fc⋅(∣Ft∣2Ft)⊤⋅τ),w=mean(s)s - 按类别加权平均,得到"冗余特征":
Fr=mean(Fm⊙expand(w))∈RNi×1×C F_r = \text{mean}\big(F^m \odot \text{expand}(w)\big) \in \mathbb{R}^{N_i \times 1 \times C} Fr=mean(Fm⊙expand(w))∈RNi×1×C - 最终相似度:
S=sum(Fm−expand(Fr))∈RNi×Nt S = \text{sum}\big(F^m - \text{expand}(F_r)\big) \in \mathbb{R}^{N_i \times N_t} S=sum(Fm−expand(Fr))∈RNi×Nt
- 将 FiF_iFi 在文本维度复制为 F^i∈RNi×Nt×C\hat F_i \in \mathbb{R}^{N_i \times N_t \times C}F^i∈RNi×Nt×C,
-
将 SSS reshape → resize → normalize 得到最终 similarity map M^\hat MM^。
-
-
输出
- Explainability :对每个类 jjj,用对应的 S:,jS:, jS:,j 得到热力图,可视化 / 生成伪 mask。
- 开放词汇分割:Argmax over 类维度,得到每个像素的类标签。
- 多标签识别 :用 FcF_cFc 代替 F^i\hat F_iF^i 做同样的 Feature Surgery,得到 per-class score S^∈R1×Nt\hat S \in \mathbb{R}^{1\times N_t}S^∈R1×Nt 作为分类 logit。
2.b 模型结构细节:各模块功能 & 协同
-
原始 q-k 自注意力模块
公式:
Attnqk=softmax(QK⊤⋅scale)V \text{Attn}_{qk} = \text{softmax}(QK^\top \cdot \text{scale})V Attnqk=softmax(QK⊤⋅scale)V其中:
- Q=Xϕq, K=Xϕk, V=XϕvQ = X\phi_q,\ K = X\phi_k,\ V = X\phi_vQ=Xϕq, K=Xϕk, V=Xϕv
- XXX 为层输入,维度 RN×C\mathbb{R}^{N\times C}RN×C。
问题:作者可视化发现 Q,KQ,KQ,K 产生的注意图,会把 token 与"语义相反"的区域强绑定,导致"反向可视化"(Fig.4)。
-
v-v 自注意力模块
公式:
Attnvv=softmax(VV⊤⋅scale)V \text{Attn}_{vv} = \text{softmax}(VV^\top \cdot \text{scale})V Attnvv=softmax(VV⊤⋅scale)V- 不再使用 ϕq,ϕk\phi_q, \phi_kϕq,ϕk,只用 ϕv\phi_vϕv。
- 好处:自相似度最高,其次是语义相近的邻域 token,注意力更局部、更符合直觉。
-
Dual Paths(双路径残差)
见 Fig.2 下半部分和 Eq.(5):
新路径输出:
x^i+1={None,i<d3ptAttn∗vv(xi;ϕv)+xi,i=d3ptAttn∗vv(xi;ϕv)+x^i,i>d \hat x_{i+1} = \begin{cases} \text{None}, & i < d3pt \text{Attn}*{vv}(x_i;\phi_v) + x_i, & i=d3pt \text{Attn}*{vv}(x_i;\phi_v) + \hat x_i, & i>d \end{cases} x^i+1={None,i<d3ptAttn∗vv(xi;ϕv)+xi,i=d3ptAttn∗vv(xi;ϕv)+x^i,i>d原路径输出:
xi+1={FFN(xi′)+xi′,xi′=Attnqk(xi;ϕq,ϕk,ϕv)+xi,ViT3ptResBlock(xi)+xi,ResNet x_{i+1} = \begin{cases} \text{FFN}(x_i')+x_i',\quad x_i' = \text{Attn}_{qk}(x_i;\phi_q,\phi_k,\phi_v)+x_i, & \text{ViT} 3pt \text{ResBlock}(x_i) + x_i, & \text{ResNet} \end{cases} xi+1={FFN(xi′)+xi′,xi′=Attnqk(xi;ϕq,ϕk,ϕv)+xi,ViT3ptResBlock(xi)+xi,ResNet直观理解:
-
原路径保持"原汁原味"的 CLIP 结构和权重,用于分类。
-
新路径从深层开始逐层叠加 v-v 注意力的残差,聚合多个层的"好注意力",但不反向影响原路径输入,避免模型崩溃。
-
Tab.2 表明:
- 仅在最后一层替换 attention 有提升,但有限;
- 多层替换但不加 dual path 会彻底崩掉(mSC 变负);
- 加了 dual path 且去掉 FFN 表现最好。
-
-
去掉 FFN 的原因
作者计算了 每一层 self-attention / FFN 输出与最终 class 特征之间的余弦相似度(Fig.5):
a⟨Ft,F^c⟩=Ft⋅F^c∣Ft∣2∣F^c∣2 a\langle F_t, \hat F_c\rangle = \frac{F_t \cdot \hat F_c}{|F_t|_2|\hat F_c|_2} a⟨Ft,F^c⟩=∣Ft∣2∣F^c∣2Ft⋅F^c
发现:
- self-attention 输出与最终特征更接近;
- 部分 FFN 输出甚至更接近"负类特征",尤其最后一个 FFN 余弦只 0.1231,甚至比负类还"负"。
所以在新路径中 完全跳过 FFN,只用 self-attention 输出来做解释/分割。
2.c 关键公式与含义(通俗讲一下)
-
原始 similarity map:
M=norm(resize(reshape(Fi∣Fi∣2⋅(Ft∣Ft∣2)⊤))) M = \text{norm}(\text{resize}(\text{reshape}( \frac{F_i}{|F_i|_2} \cdot (\frac{F_t}{|F_t|_2})^\top))) M=norm(resize(reshape(∣Fi∣2Fi⋅(∣Ft∣2Ft)⊤)))- Fi∈RNi×CF_i \in \mathbb{R}^{N_i\times C}Fi∈RNi×C:图像各 patch 特征
- Ft∈RNt×CF_t \in \mathbb{R}^{N_t\times C}Ft∈RNt×C:文本各类别特征
- 内积 + L2 归一化 = 余弦相似度
- reshape & resize:把 token 网格插值成输入图像大小的热力图。
-
Feature Surgery 的核心:
- FmF^mFm:对每个"像素--类别--通道"位置,把图像特征和对应类别文本特征相乘,相当于保留"对这个类别有贡献的通道"。
- www:哪些类别对当前图像"显而易见",就给它更大的权重,让它们在估计冗余特征时更有话语权。
- FrF_rFr:对所有类别的 FmF^mFm 加权平均,得到在"所有类别里都常见"的部分,也就是冗余特征。
- S=sum(Fm−expand(Fr))S = \text{sum}(F^m - \text{expand}(F_r))S=sum(Fm−expand(Fr)):从每个位置、每个类别的"原贡献"里减去冗余部分,再对通道求和,即 去冗余后的类别得分。
对多标签分类,只是把 FiF_iFi 换成 FcF_cFc,得到 per-class logit,用于 mAP。
3. 与其他方法的对比
3.a 与主流方法的本质差异
-
不训练,只改推理架构和算子
- 相比 ViL-Seg, ReCo, GroupViT, SegCLIP 等需要训练或微调的开放词汇分割方法,CLIP Surgery 完全基于预训练 CLIP 的权重。
-
解释性与性能同时优化
- 其他解释方法多只改善可视化,不直接改善下游任务。
- CLIP Surgery 显式把解释性设计(v-v attention + 去冗余)转化为 segmentation / multi-label recognition 性能提升。
-
不依赖反向传播
- Grad-CAM, pLRP, Bi-Modal, gScoreCAM 都需要 per-label backward。
- CLIP Surgery 只做一次前向,通过结构/特征改造得到所有类别的 dense map,更适合大类数和密集预测。
-
对输出分辨率不敏感
- Tab.5:其他方法从 ViT-B/32(7×7)到 ViT-B/16(14×14)普遍性能下降;
- CLIP Surgery 反而进一步提升,这为下游"高分辨率分割"提供条件。
3.b 创新点 / 贡献
论文列了四点贡献,归纳一下:
-
发现问题 + 溯源
- 系统性分析并证明:反向可视化来自自注意力中的 q,k 参数,噪声激活来自冗余特征。
-
架构手术(Architecture Surgery)
- 提出 v-v self-attention + dual paths + 去 FFN 的组合,在纯推理阶段修正 CLIP 内部表征。
-
特征手术(Feature Surgery)
- 提出显式的冗余特征估计和消除方法,统一应用于 explainability 和 multi-label recognition。
-
Explainability + 多任务提升
- 在解释性、开放词汇分割、多标签识别、交互式分割、多模态可视化上都取得大幅度提升,展示了方法通用性。
3.c 适用场景
更适合:
- 使用 CLIP 作为 backbone 的任务(分割、多标签、交互式分割、视觉定位等)。
- 需要 像素级 / token 级可解释性 的应用(例如医疗影像、自动驾驶)。
- 不方便大规模微调,只能在预训练 CLIP 上"做文章"的场景。
不太适合:
- 单标签分类中只关心排名而不关心 mAP 的场景(作者也指出 Feature Surgery 对 rank-based 指标影响有限)。
3.d 方法对比表(简化)
| 方法 | 是否训练 | 是否额外模型/标注 | 主要操作 | 优点 | 缺点 |
|---|---|---|---|---|---|
| Grad-CAM / pLRP | 否 | 否 | 反向传播梯度/相关性 | 通用、易用 | CLIP 上效果差,慢,输出粗 |
| Bi-Modal | 否 | 否 | 多模态 transformer 梯度/attention | 支持图文 | CLIP 上噪声多,分辨率敏感 |
| gScoreCAM | 否 | 否 | ScoreCAM 变种 | 专为 CLIP 设计 | 高分辨率效果差,需多次 backward |
| RCLIP | 否 | 否 | 翻转 similarity map | 简单有效 | 仍基于"有问题"的内部特征 |
| ECLIP | 是 | 否 | 训练新的 pooling 层 | 解释性强 | 需要微调,复杂 |
| MaskCLIP | 否 | 否 | 修改 attention pooling 做分割 | 无需训练,分割性能不错 | 不针对 explainability,改动局部 |
| CLIP Surgery | 否 | 否 | v-v attention + dual paths + 去冗余 | 大幅提升解释性 + 分割 + 多标签 | 需改模型代码,推理稍复杂 |
4. 实验表现与优势
4.a 验证方法 & 设计
-
Explainability 评估
-
数据集:VOC 2012, COCO 2017, PASCAL Context, ImageNet-S50。
-
指标:
- mIoU\text{mIoU}mIoU:前景 mask 与 GT 的平均 IoU;
- mSC\text{mSC}mSC(mean Score Contrast):前景分数与背景分数的平均差异,范围 -100%, 100%。
mSC=meancmeans(Sˉf−Sˉb) \text{mSC} = \text{mean}_c\text{mean}_s\big(\bar S_f - \bar S_b\big) mSC=meancmeans(Sˉf−Sˉb)
值 < 0 表示"反向可视化"。
-
-
开放词汇语义分割
- 数据集:PASCAL Context, COCO Stuff, Cityscapes。
- backbone 统一 ViT-B/16,输入 512×512,argmax over 类维。
-
开放词汇多标签识别
- 数据集:PASCAL Context, NUS-Wide。
- 指标:mAP。
- 对比不同激活(None, Sigmoid, Softmax, Ours)。
-
交互式分割(与 SAM)
- 用 CLIP Surgery similarity map 选取高分前景点 + 低分背景点作为 SAM 的点提示;评估点精度 & mIoU。
4.b 关键结果(挑几个有代表性的)
-
Explainability:CLIP vs CLIP Surgery(Tab.3)
-
以 ViT-B/16 在 PASCAL Context 为例:
- mIoU: 15.76% → 46.28%(+30.52)
- mSC: -16.73% → 34.32%(从"背景偏好"到"强前景")
-
各 backbone 上平均提升:
- mIoU:+22.11% ~ +35.95%
- mSC:+47.72% ~ +65.21%。
-
-
与其他解释方法对比(Tab.4 + Fig.9)
- 在所有数据集和指标上,CLIP Surgery 均为第一;
- 对比第二名的 ECLIP(需训练):在 PASCAL Context 上 mIoU / mSC 仍高出约 15.9 / 19.9。
-
开放词汇语义分割(Tab.6)
-
mIoU(PASCAL Context / COCO Stuff / Cityscapes, ViT-B/16):
- ViL-Seg:16.3 / 16.4 / --
- ReCo:22.3 / 14.8 / 21.1
- MaskCLIP:22.4 / 15.3 / 22.7
- CLIP Surgery :29.3 / 21.9 / 31.4
-
在 Cityscapes 上比最强基线 MaskCLIP 高 8.7 mIoU。
-
-
开放词汇多标签识别(Tab.7, 8)
-
ViT-B/16 + Ours 在 NUS-Wide:
- Softmax:42.85 mAP
- Ours:47.19 mAP(+4.34)
-
与零样本多标签方法对比(都在 NUS-Wide):
- DualCoOp: 43.6
- TaI-DPT: 44.99
- TaI-DPT + Ours: 48.28(新的 SOTA)。
-
-
交互式分割(Fig.11, 12 & Tab.9)
- 用文本→点提示喂给 SAM,在 ImageNet-S50 等数据集上 mIoU 接近 70%,点精度接近 90%。
- 输入分辨率从 224 升到 512 时,mIoU 明显进一步提升。
4.c 优势最明显的场景/数据集
- 解释任务:所有数据集上 mSC 都从负变正,视觉效果从"完全错误"变为"直观可信",尤其是 VOC / Pascal Context(图中红色前景非常清晰)。
- 开放词汇分割:Cityscapes(道路场景)提升最大,说明方法对于结构化、多类背景场景尤其有用。
- 多标签识别:NUS-Wide 这类 web 场景复杂、多标签数据集,Feature Surgery 的去冗余特别有效。
4.d 局限性 & 隐含不足
- 方法依赖于 CLIP 的特征空间结构,对于非 CLIP 的 VL 模型需要重新验证。
- Feature Surgery 对 单标签 / 排序类指标 的影响有限(因为等价于加了个公共 bias),主要提升 mAP 这类跨样本度量。
- Architecture Surgery 需要改动模型实现,不是"零工程成本"的黑盒后处理。
5. 学习与应用建议
5.a 是否开源?复现关键步骤
-
论文明确给出了 GitHub 链接(xmed-lab/CLIP Surgery)
-
复现关键步骤:
-
基于官方 CLIP 实现,拿到中间层输出(各 Block 的输入/输出)。
-
从设定的深度 ddd 开始,复制 Block 结构构造"新路径":
- 将 attention 部分替换为 v-v self-attention;
- 去掉 FFN,只保留线性投影;
- 使用 dual paths 逻辑合并残差。
-
对新路径输出的 patch 特征 FiF_iFi 和文本特征 FtF_tFt,实现 Feature Surgery(Eq.6--9)。
-
分割任务:将 SSS reshape + resize + argmax 得到像素级预测。
-
多标签任务:对 class token FcF_cFc 做 Feature Surgery,用 S^\hat SS^ 作为 logit 计算 mAP。
-
5.b 实现注意点(超参数 / 预处理 / 训练细节)
-
超参数
- 深度 d=7d=7d=7,logit scale τ=2\tau=2τ=2;作者说明性能对它们不敏感,一个合理区间即可(例如 d∈1,10d\in1,10d∈1,10 只导致 mSC 变化约 0.4%)。
-
输入大小
- Explainability:通常 224×224 足够。
- 开放词汇分割 / SAM:使用 512×512 明显更好。
-
文本 prompt
- 使用 CLIP 原始 85 个 ImageNet prompt 模板,所有方法统一使用"prompt ensemble + 平均"。
-
实现坑点
-
Dual paths 里一定要保证原路径输入不被新路径覆盖,否则会导致深层 feature 失配。
-
Feature Surgery 中 expand 的维度要严格对齐:
- Fm:(Ni,Nt,C)F^m: (N_i, N_t, C)Fm:(Ni,Nt,C)
- expand(w):(Ni,Nt,C)\text{expand}(w): (N_i, N_t, C)expand(w):(Ni,Nt,C)
- Fr:(Ni,1,C)F_r: (N_i, 1, C)Fr:(Ni,1,C) 再 expand 成 (Ni,Nt,C)(N_i, N_t, C)(Ni,Nt,C)。
-
5.c 迁移到其他任务的可能性
可以迁移,且思路清晰:
-
开放词汇目标检测 / 实例分割
- 在 detector backbone 中插入 Architecture Surgery(v-v attention + dual paths),获取更干净的 spatial 特征;
- 用 Feature Surgery 生成更可靠的 attention map 作为 proposal / mask 的初始化。
-
视觉定位 / grounding
- 使用文本短句/词语作为 prompt,直接用 CLIP Surgery 的 similarity map 做 grounding,替代传统 CAM。
-
视频任务
- 对时序 ViT 或时空 transformer,在空间维上用相同结构手术,甚至可以考虑在时间维也做 v-v attention 手术。
-
你自己的 CLIP-based 分割/识别论文
-
如果 backbone 是 CLIP,可以:
- 直接用 CLIP Surgery 的 similarity map 作为监督(pseudo mask);
- 或用 Architecture Surgery 改 backbone,把它当"更好的特征提取器"。
-
6. 总结
6.a 一句话概括核心思想(≤20 字)
改造 CLIP 注意力与特征,修正可视化并提升开放词汇性能。
6.b 速记版 pipeline(3--5 步,避免术语)
- 用预训练 CLIP 提取图像和文字特征。
- 在后几层里用新的自注意力替代原注意力,并跳过中间全连接层。
- 统计所有类别中共同出现的特征,把它们当作"噪声成分"减掉。
- 用处理后的图文相似度图来画热力图,或直接当作每个像素的类别分数。
- 对整张图的类别分数做同样处理,用来做多标签识别和其他开放词汇任务。
如果你想,我可以下一步专门帮你画一张"矩阵维度总览表",把 Fi,Ft,Fc,Fm,Fr,SF_i, F_t, F_c, F^m, F_r, SFi,Ft,Fc,Fm,Fr,S 全部列出来,对照方便你在代码里实现。