机器学习是人工智能的核心,机器学习的强大之处在于它能够从数据中学习,并在无需直接编程的情况下进行预测,给定一组输入,模型将根据从现有数据中学习到的模式,预测接下来会发生什么。
文章目录
- 一、模型和训练
-
- [1.1 过度拟合](#1.1 过度拟合)
- 二、机器学习的三种模式
-
- [2.1 监督学习](#2.1 监督学习)
- [2.2 无监督学习](#2.2 无监督学习)
- [2.3 强化学习](#2.3 强化学习)
- 三、对比总结
一、模型和训练
模型是一种数学表示,向模型输入数据(训练集),模型学习和理解数据模式的过程称为训练,在训练过程中,我们通常还会预留一部分数据作为测试集,用于在模型训练后评估其能力。
以房价预测模型为例,模型会学习许多房屋示例及其实际价格价值,模型会分析房屋特征(解释变量)与其价格(目标变量)之间的关系,找到映射函数: f f f(房屋大小, 位置, 房龄) → 价格。一旦学会了这种关系,就可以使用模型预测新房的价格 ,训练的目标是找到最佳模型,即最准确地捕捉解释变量和目标变量之间关系的模型。
1.1 过度拟合
在机器学习中,过度拟合(Overfitting)是指模型在训练数据上表现得过于完美,但在未见过的数据上表现却很差的现象。简而言之,过度拟合指模型 "死记硬背" 了训练数据,却不会 "举一反三"。
过度拟合的核心矛盾是「训练集性能」与「测试集性能」的巨大差距,具体表现为:
- 训练误差极低,测试误差极高。
- 模型在新数据上表现不稳定,对微小的输入变化敏感,预测结果波动大。
- 训练曲线随着训练样本增加,训练误差持续下降,但测试曲线训练初期下降,达到某个临界点后开始上升,两条曲线最终差距悬殊。
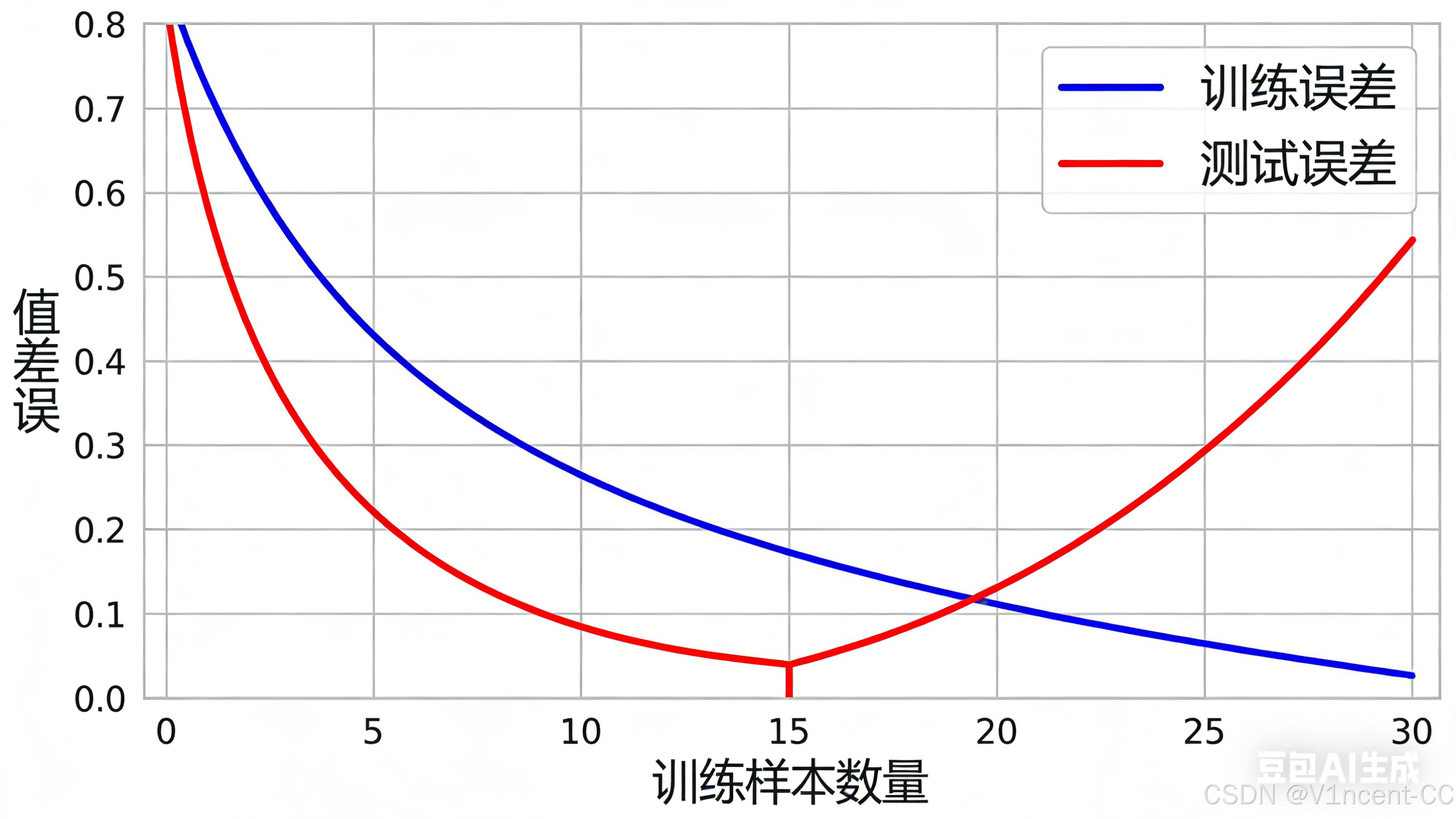
导致过度拟合的场常见原因:
- 模型复杂度过高: 模型拥有过多的参数,导致模型有能力"记住"训练数据的每一个细节,包括那些无关紧要的随机波动。
- 训练数据量太少: 如果训练样本太少,模型会过度依赖这有限的数据,将其中的特定特征误认为是普遍模式。
- 特征选择不当: 训练数据引入了过多不相关或冗余的特征。
因此,机器学习的目标是找到一种平衡,既能很好地拟合训练数据,捕捉真实的模式和关系,又不会在数据中复制其精确的模式或引入噪声。在模型从数据中学习的能力与避免过度拟合或过度学习之间取得平衡,是机器学习面临的最大挑战之一,需要谨慎的模型设计决策、数据处理和评估方法。
二、机器学习的三种模式
机器学习的三大核心模式(监督学习、无监督学习、强化学习)是整个AI领域的基础框架,其核心区别在于数据标签的有无、学习目标的差异以及与环境的交互方式。
2.1 监督学习
监督学习(Supervised Learning)指利用带标签的训练数据(即每个输入样本都对应一个明确的 "标准答案"),让模型学习 "输入特征→输出标签" 的映射关系,找到那个最佳的映射函数f,最终能对新的无标签数据准确预测标签的学习模式。
通俗理解为:模型像学生,训练数据的 "标签" 像老师给出的标准答案,模型通过学习大量 "题目(输入)- 答案(标签)" 对,掌握规律后独立解题。
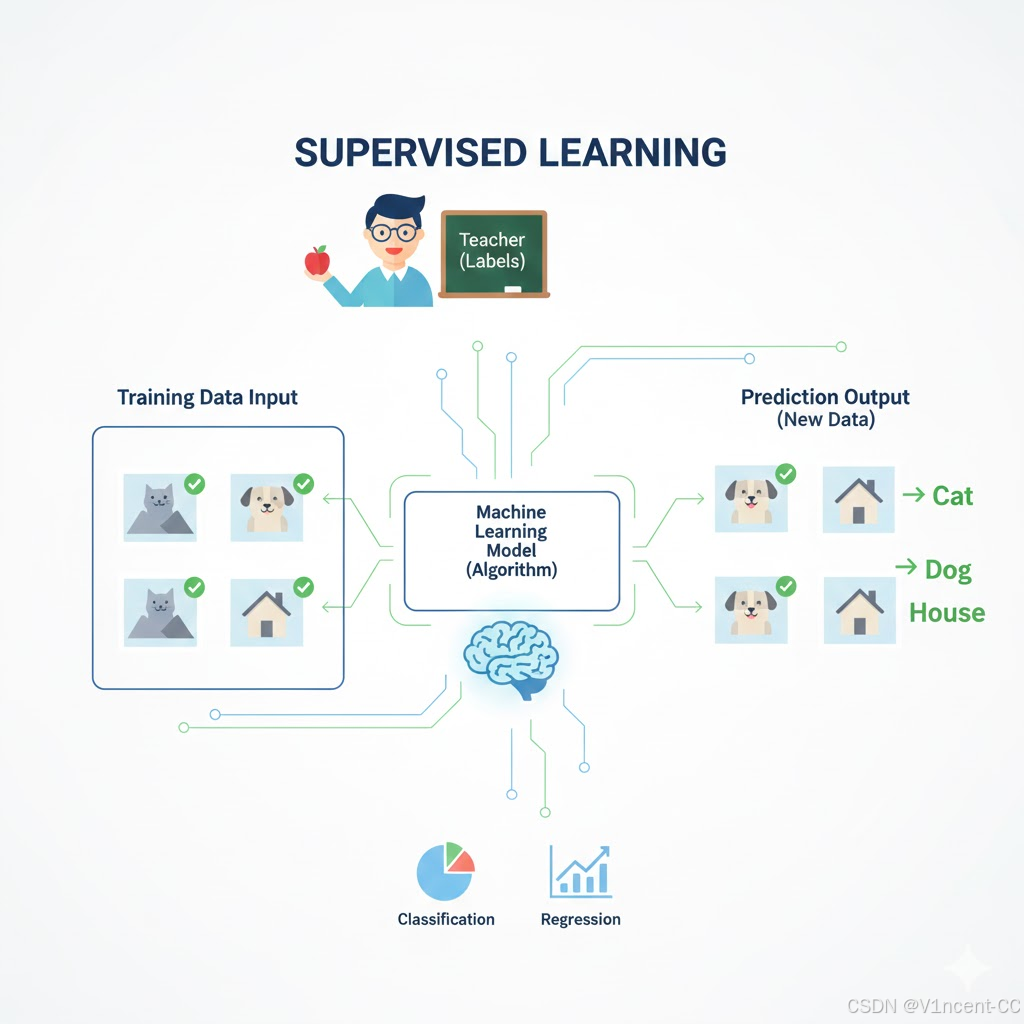
工作原理:
输入: 给定一组输入 X 和对应的已知输出 Y。
目标: 模型学习一个映射函数 f(X) → Y,以至于在给定新的、未见过 X 时,能够准确预测其 Y。
评估: 通过比较模型的预测输出和真实的标签之间的差异(损失),来不断调整模型的参数。
常见应用场景:
- 邮件分类: 将邮件分类为"垃圾邮件"或"非垃圾邮件"。
- 医疗诊断: 将 X 光片或 MRI 图像分类为"癌变"或"正常"。
- 信用评分: 将贷款申请人分类为"高风险"或""低风险"。
2.2 无监督学习
无监督学习是利用无标签的训练数据(没有"标准答案"),让模型自主探索数据本身的内在规律、结构或隐藏特征的学习模式。
通俗理解为:模型像科学家,没有预设答案,通过观察大量数据,自主发现数据中的聚类、关联或异常等规律。
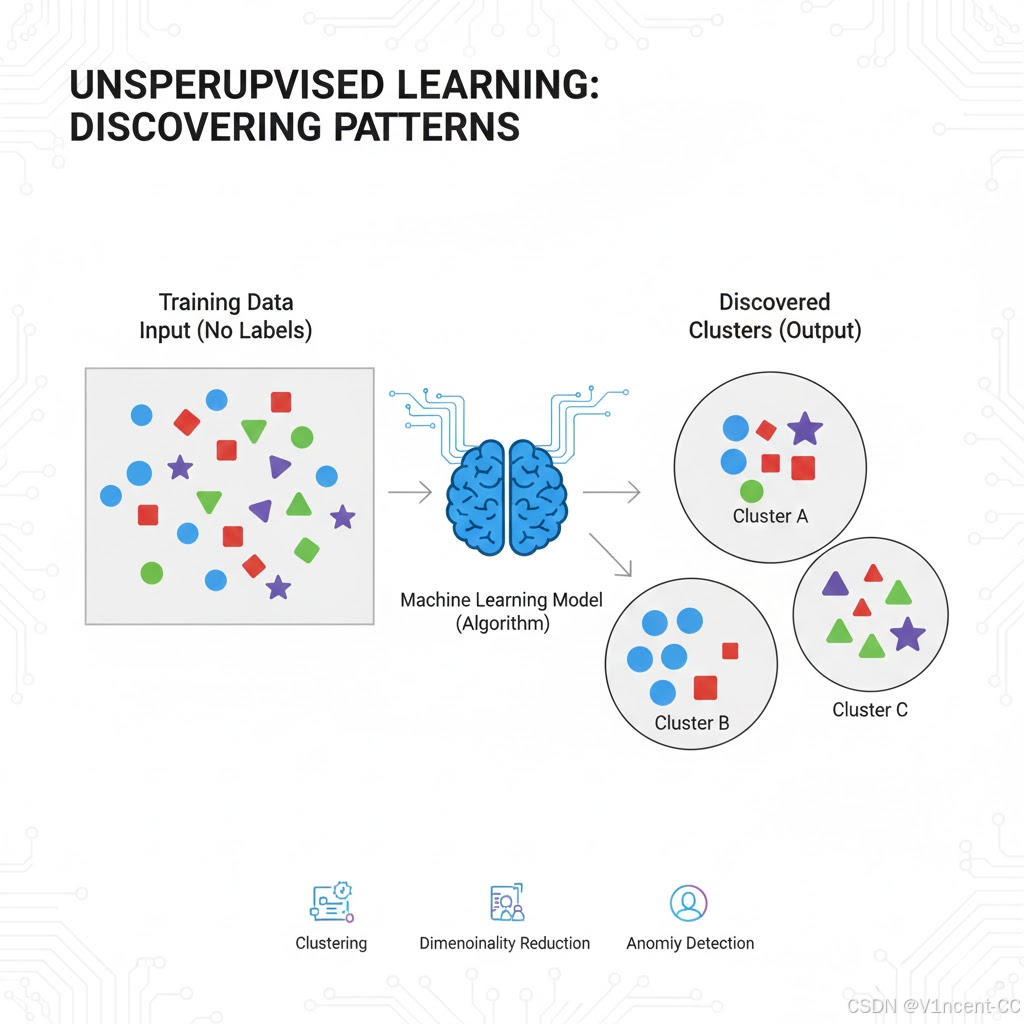
一般来说,无监督学习的目标是发现数据中的规律,例如将相似的变量分组,这种发现未标记关系的能力意味着,无监督学习算法可以在监督学习之前使用,为预测建模准备数据,以这种方式使用时,无监督算法有助于清理和标记数据。
工作原理:
输入: 只有一组输入数据 X,没有对应的输出 Y。
目标: 发现数据的内在联系,例如将相似的数据点分组,或减少数据的维度。
评估: 评估往往更依赖于人工检查或特定的指标,因为它没有标准答案。
常见应用场景:
- 客户细分: 将用户根据购买行为、兴趣爱好等特征自动分成不同的目标群体,便于精准营销。
- 社交网络分析: 识别社交媒体中的兴趣社区或同质群体。
- 购物篮分析:发现哪些商品经常一起被购买,例如"买尿布的人通常也会买啤酒",从而优化货架摆放和促销策略。
2.3 强化学习
强化学习(Reinforcement Learning)是模型通过与环境交互,在"试错"中学习最优决策策略的模式,模型执行动作后,环境会反馈 "奖励"(正向反馈)或 "惩罚"(负向反馈),模型的目标是通过不断调整动作,最大化长期累积奖励。
通俗理解为:模型像游戏玩家,环境是游戏场景,动作是玩家操作,奖励是游戏得分,模型通过反复玩游戏,找到能拿到最高总分的 "最优玩法"。
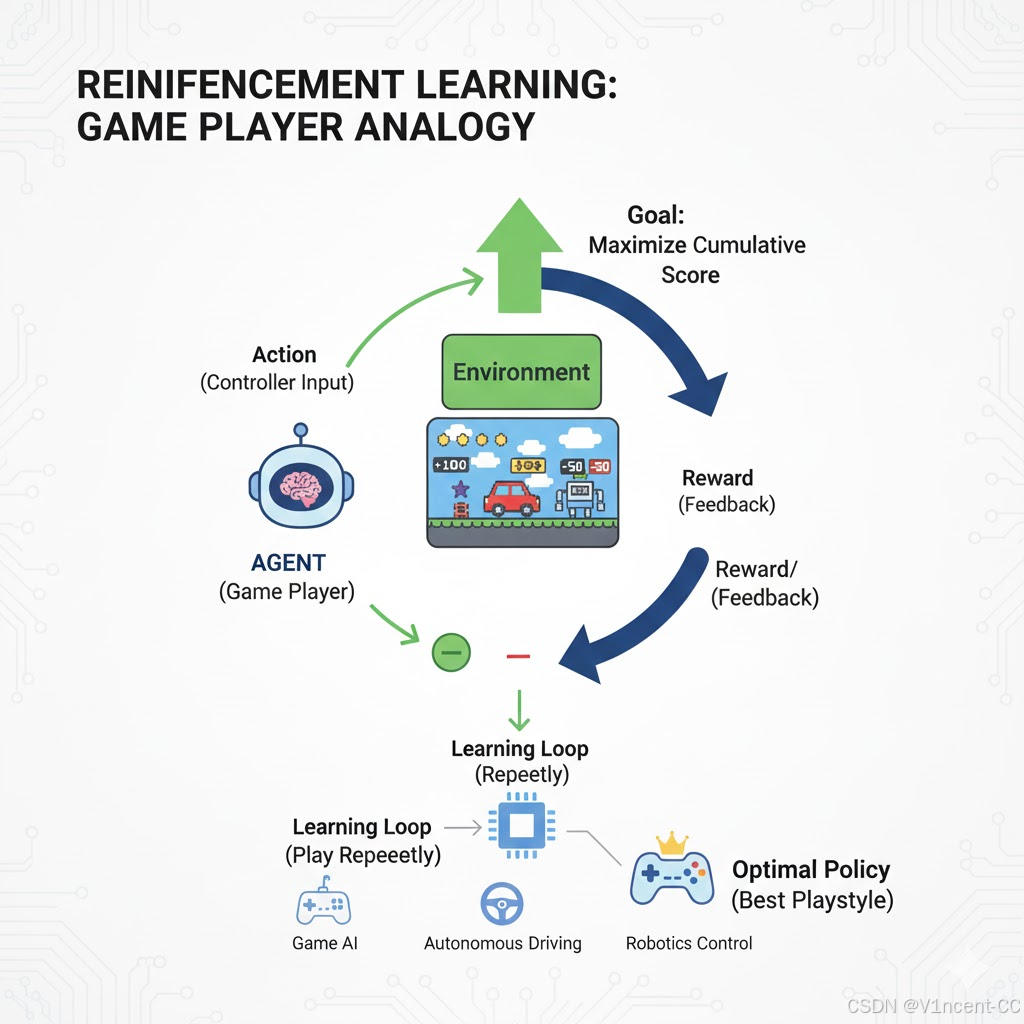
工作原理
模型和环境: 模型在环境中观察当前状态 (S)。
行动和奖励: 模型选择一个行动 (A),环境会给出新的状态 ( S ′ ) (S') (S′) 和一个奖励 ( R ) (R) (R)。
目标: 模型通过反复试验,学习一个最优策略,即在任何给定状态下,都能选择一个能获得最高长期累积奖励的行动。
常见应用场景
- 自动驾驶: 模型决定何时加速、减速、变道或刹车,以最大化安全和效率。
- 游戏AI:AlphaGo 围棋、斗地主机器人。
三、对比总结
下面是机器学习三种主要模式(监督学习、无监督学习、强化学习)的对比总结:
| 学习模式 | 输入 | 目标 | 常见任务 | 典型应用 |
|---|---|---|---|---|
| 监督学习 | 已知 (特征数据) | 已知 (标签) | 分类、回归、 目标检测、语音识别 | 邮件分类、房价预测、人脸识别 |
| 无监督学习 | 已知 (特征数据) | 未知 (无特定标签) | 聚类、降维、 异常检测、关联分析 | 客户分群、购物篮分析 |
| 强化学习 | 未知 (随机行为) | 已知 (最大化奖励) | 策略优化、路径规划、 对抗学习 | AlphaGo、自动驾驶、斗地主机器人 |