好的,这是对您提供的博客文章《A Gentle Introduction to LoRA》的全文翻译。
原文链接: https://thinkingmachines.ai/blog/lora/
原文标题: A Gentle Introduction to LoRA
译文标题: LoRA 简明入门
正文翻译
当我第一次进入大型语言模型(LLM)的世界时,我感到有些不知所措。有太多的模型、技术和论文需要跟上。但最让我困扰的是微调(fine-tuning)这些庞然大物的成本。我只是一个爱好者,没有成千上万的美元可以花在 GPU 上。我如何才能让这些模型适应我自己的用例呢?
正是在那时,我发现了 LoRA,这是一种彻底改变了我们微调 LLM 方式的技术。LoRA 使得在消费级硬件上微调 LLM 成为可能,从而为爱好者和研究人员打开了一个充满可能性的新世界。它帮助实现了对 AI 的大众化访问。
在这篇文章中,我们将深入探讨 LoRA 是什么,它是如何工作的,以及为什么它如此强大。
LoRA(Low-Rank Adaptation of Large Language Models)------大型语言模型的低秩自适应。
问题所在:全量微调的挑战 (The Problem: The Challenge of Full Fine-Tuning)
在 LoRA 出现之前,微调 LLM 的标准方法是"全量微调"。这意味着要更新模型的所有权重。对于像 GPT-3 这样拥有 1750 亿参数的模型来说,这是一个巨大的计算挑战。
想象一下,你有一个巨大的、已经硬化成形的粘土雕塑。这个雕塑代表了你的预训练 LLM。现在,你想要对它做一些小小的改动------也许是给它加上一顶帽子。通过全量微调,你必须重塑整个雕塑,这是一个既缓慢又昂贵的过程。
除了计算成本,全量微调还有其他一些缺点:
- 灾难性遗忘 (Catastrophic Forgetting): 当你微调整个模型时,你可能会丢失一些在预训练期间学到的宝贵知识。
- 存储成本: 每个微调后的模型都是一个全新的、巨大的文件副本。如果你想为不同的任务微调多个模型,存储成本会迅速增加。
解决方案:参数高效微调 (The Solution: Parameter-Efficient Fine-Tuning - PEFT)
为了解决全量微调的这些问题,研究人员开始探索"参数高效微调"(PEFT)方法。PEFT 的核心思想是:我们不需要更新所有的模型权重。相反,我们可以冻结预训练模型的绝大部分参数,只微调一小部分新增的或特定的参数。
LoRA 的登场:大型语言模型的低秩自适应 (Enter LoRA: Low-Rank Adaptation of Large Language Models)
LoRA 是 PEFT 家族中最受欢迎和最有效的技术之一。它由微软的研究人员在论文 LoRA: Low-Rank Adaptation of Large Language Models 中提出。
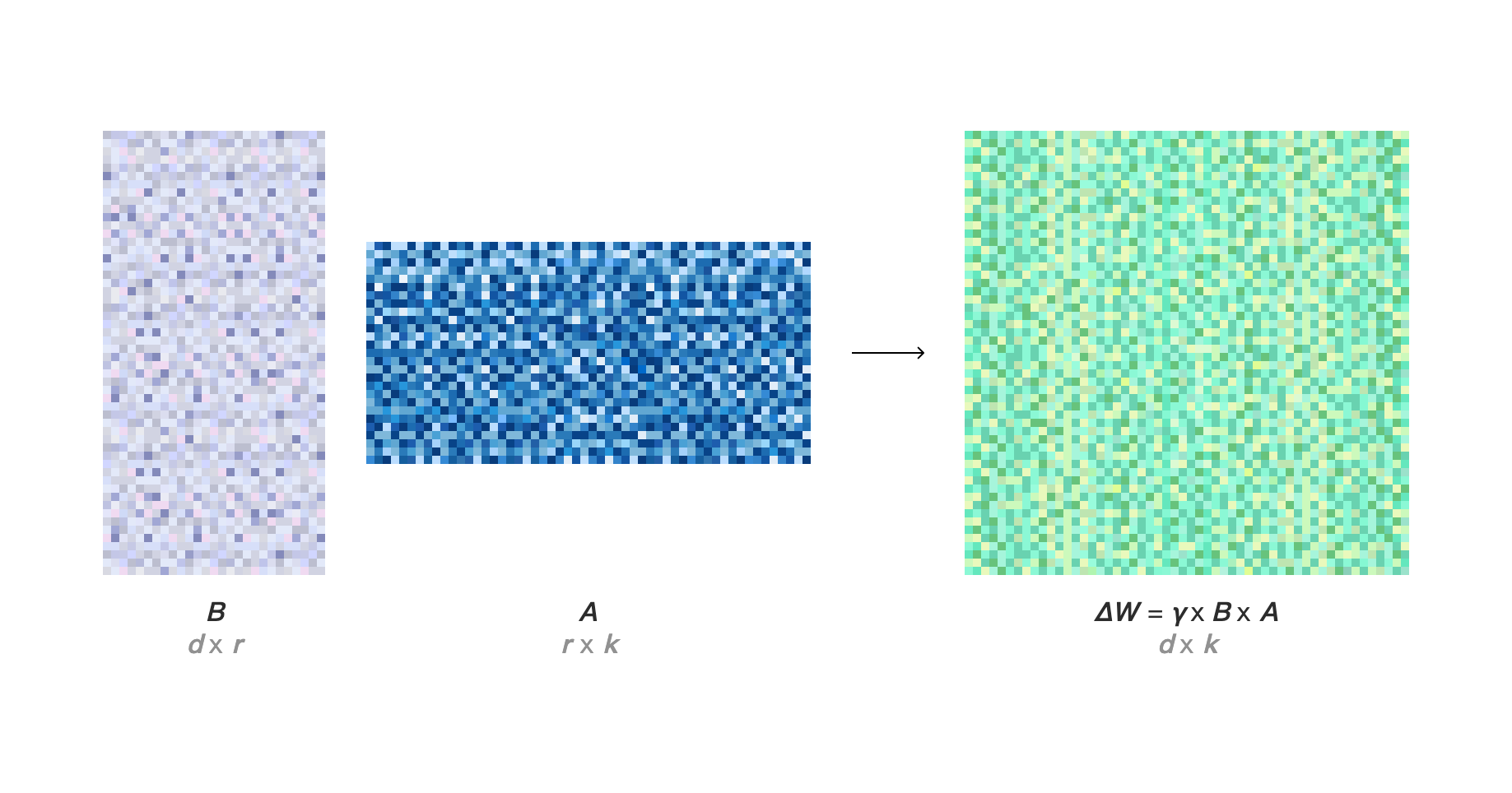
LoRA 的关键思想非常巧妙:它并没有直接修改原始模型的权重,而是在模型的特定层旁边注入两个更小的、可训练的"低秩"矩阵(我们称之为 A 和 B)。在微调过程中,只有这些新增的矩阵会被更新,而原始的、庞大的权重矩阵保持不变。
回到我们的雕塑比喻:LoRA 就像是在你那座巨大的、已硬化的雕塑上添加一小层可塑造的粘土。你可以在这层新粘土上雕刻你的帽子,而无需改动下面的原始雕塑。这不仅更快、更容易,而且如果你不喜欢这顶帽子,你随时可以把它拿掉,恢复到原始的雕塑状态。
从技术上讲,LoRA 的工作原理基于一个叫做"秩分解"(rank decomposition)的线性代数概念。其思想是,任何大的矩阵都可以被近似为两个或多个更小的矩阵的乘积。在 LoRA 中,我们将权重更新 ΔW 分解为两个低秩矩阵 A 和 B 的乘积。
因此,如果原始权重矩阵是 W,那么更新后的权重 W' 就是:
W' = W + ΔW = W + B * A
这里,A 和 B 的"秩"(rank)r 是一个远小于原始矩阵维度的超参数。这个 r 越小,我们训练的参数就越少,计算效率就越高。

LoRA 的工作原理:原始的、冻结的权重矩阵 W₀ 与低秩矩阵 A 和 B 的乘积相加。只有 A 和 B 在训练期间被更新。
为什么这能行得通?(Why does this work?)
LoRA 的有效性背后有一个迷人的假设,即大型语言模型具有一个很低的"内在维度"(low intrinsic dimension)。这意味着,即使模型生活在一个拥有数十亿参数的高维空间中,但使它适应新任务所需的权重变化实际上可以被一个更小的、低维度的子空间所描述。
LoRA 正是利用了这一点。通过只在这些低维子空间中进行优化,我们可以在不牺牲太多性能的情况下,大幅降低微调的计算成本。
在实践中如何使用 LoRA? (How do you use LoRA in practice?)
多亏了像 Hugging Face 的 PEFT 库这样的工具,在实践中使用 LoRA 变得异常简单。下面是一个如何将 LoRA 应用于 mistralai/Mistral-7B-v0.1 模型的例子:
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import get_peft_model, LoraConfig
# 加载基础模型
base_model = AutoModelForCausalLM.from_pretrained(
"mistralai/Mistral-7B-v0.1",
device_map="auto",
torch_dtype=torch.bfloat16,
)
# 定义 LoRA 配置
config = LoraConfig(
r=32, # LoRA 秩
lora_alpha=64, # LoRA 缩放因子
target_modules=["q_proj", "v_proj"], # 将 LoRA 应用于哪些模块
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
# 应用 LoRA
peft_model = get_peft_model(base_model, config)
# 打印可训练参数的数量
peft_model.print_trainable_parameters()
# trainable params: 16,777,216 || all params: 7,258,402,048 || trainable%: 0.2311正如你所看到的,我们只训练了总参数的 0.23%!这是一个巨大的缩减,它使得在单个 GPU 上微调大型模型成为可能。
对于 LoRA,什么最重要? (What matters for LoRA?)
LoRA 论文介绍了一系列我们可以调整的超参数(hyperparameters)。作为参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)库的一部分,Hugging Face 的 LoraConfig 类公开了这些参数,例如 r、lora_alpha 和 target_modules。在本文中,我们决定研究哪些参数对模型的性能影响最大。
学习率 (Learning Rate)
在所有超参数中,学习率无疑是最重要的一个。一个好的学习率可以带来平滑的损失曲线,而一个差的学习率则可能导致模型性能停滞不前甚至发散(即损失值变得非常大)。
上图:我们 LoRA 实验的训练损失。绿色曲线代表一个合适的学习率,它使损失能够平滑地下降。红色曲线则代表一个糟糕的学习率,它导致了不稳定的训练和最终的损失发散。
一个好的经验法则是,在全量微调(full fine-tuning)时,学习率通常设置在 1e-5 到 5e-5 的范围内。对于 LoRA 微调,学习率可以设置得更高一些,通常在 1e-4 到 5e-4 之间。
r 参数 (The r parameter)
r 参数决定了用于微调的低秩矩阵的秩(rank)。简单来说,r 控制着可训练参数的数量。
r 的值越高,意味着可训练的参数越多,这可能带来更好的性能,但代价是训练时间更长,并且生成的模型检查点(checkpoint)文件也更大。相反,r 的值越低,可训练参数越少,训练速度更快,模型文件也更小,但可能会牺牲一些性能。
上图:不同 r 值对应的验证损失。正如预期的那样,随着 r 值的增加,验证损失(validation loss)趋于下降。然而,当 r 超过 64 后,性能提升的幅度开始减小,这表明在某个点之后,继续增加 r 带来的收益会递减。
目标模块 (Target Modules)
target_modules 参数决定了我们将 LoRA 应用于基础模型的哪些模块(或层)。通常的做法是将 LoRA 应用于注意力机制(attention mechanism)的层 ,例如 query 和 value 投影。
选择更多的目标模块通常会带来更好的性能,但同样会增加可训练参数的数量。一些实验表明,将 LoRA 应用于尽可能多的模块可以获得最佳结果。
上图:不同目标模块对应的验证损失。可以看出,当我们将 LoRA 应用于更多的模块时,验证损失往往会降低。例如,同时将 query、key、value 和 output 层作为目标,通常会比仅将 query 和 value 层作为目标取得更好的结果。
Alpha 参数
alpha 参数是 LoRA 的缩放因子。权重更新的最终效果由 lora_alpha / r 决定。通常的做法是将其设置为与 r 相等或 r 的两倍(例如 alpha = 2 * r)。
你可以将 alpha 视为一个类似于学习率的参数,它专门用于调整 LoRA 层的权重。因此,如果你发现通过调整学习率无法使模型收敛(如上文第一张图所示),你也可以尝试调整 alpha 的值。
正如你所看到的,有多个超参数可以调整。在这些参数中,找到一个好的学习率是最重要的。其次,你应该决定将 LoRA 应用于哪些模块(target_modules),这通常取决于你的性能需求和计算预算之间的权衡。r 的值也遵循同样的权衡逻辑。最后,alpha 参数可以作为调整 LoRA 层权重的额外工具。
结论 (Conclusion)
LoRA 是一项强大的技术,它改变了我们与大型语言模型互动的方式。通过显著降低微调的计算成本,LoRA 使得更广泛的受众能够使用和定制这些模型。
总结一下 LoRA 的主要优势:
- 减少 VRAM 需求: 由于我们只训练一小部分参数,所需的 GPU 显存大幅减少。
- 更小的检查点: 微调后的 LoRA 权重通常只有几百兆字节,而不是数十吉字节。
- 更快的训练: 训练更少的参数意味着训练过程更快。
- 无灾难性遗忘: 由于原始模型权重被冻结,模型不会忘记它在预训练中学到的知识。
在我们 Thinking Machines Data Science,我们已经广泛使用 LoRA 来为我们的客户构建定制的 LLM 解决方案。如果你有兴趣了解更多关于我们如何利用 AI 来解决现实世界问题的信息,请随时与我们联系!