
代码题会是什么东西好慌 先把章末习题总结一波看看实力
实验一 Flink集群安装和初步使用
是的期末了我连环境都还没配 懒得配Linux了 用Maven速成一下子 以下为模拟环境配置速成教程
安装JDK1.8 安装Jetbrain IDEA 新建项目这样点
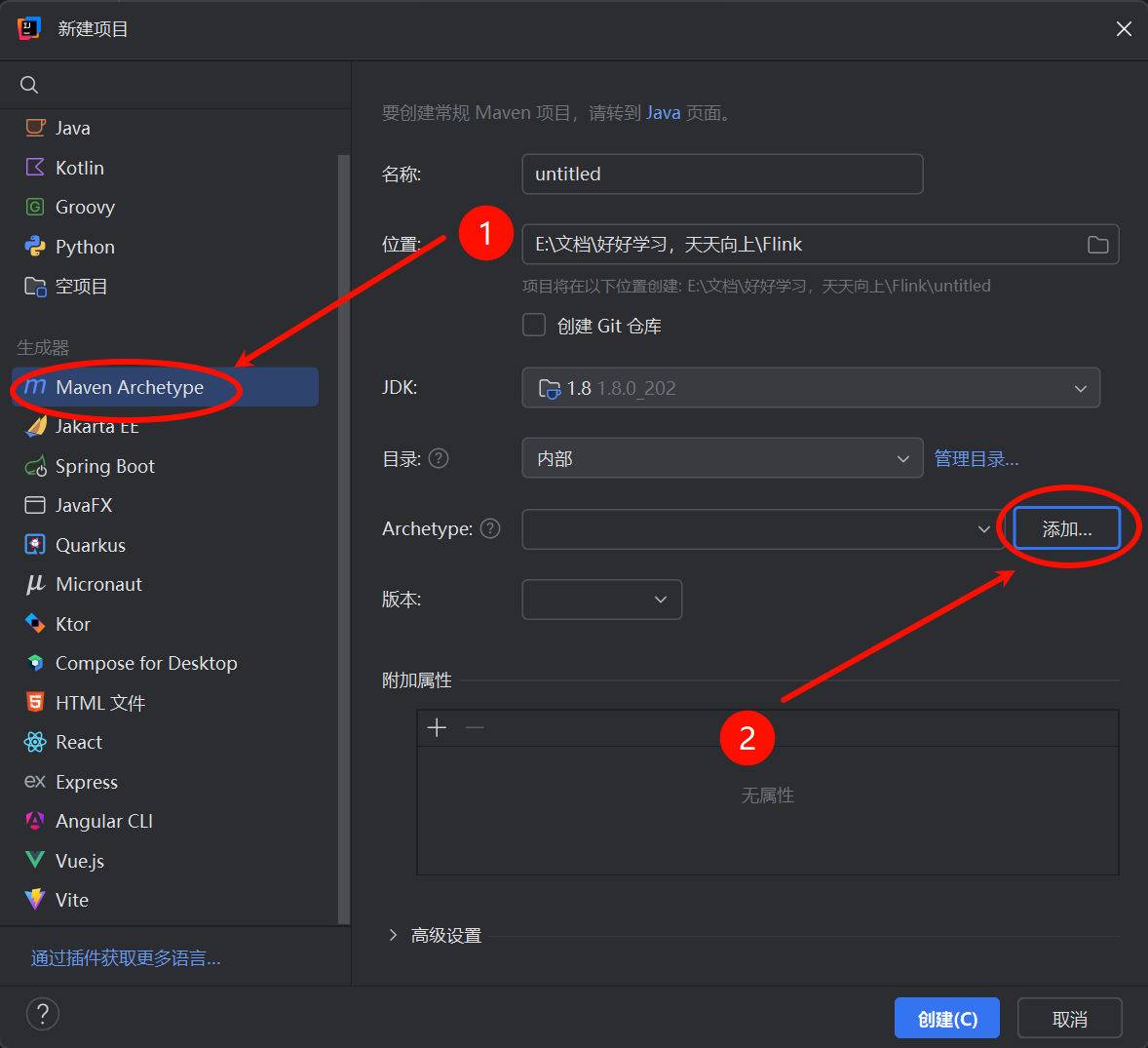
然后里面这样填再然后点创建
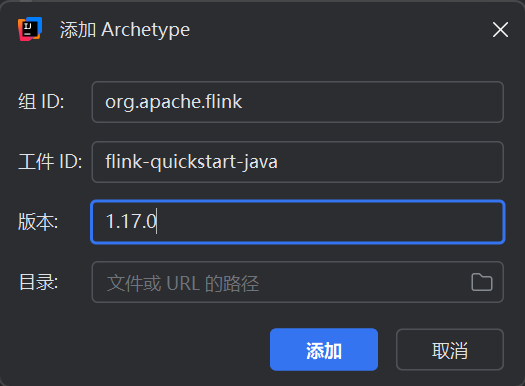
再然后pom.xml文件改成下面这样 改完右上角有个小按钮点一下自动下载一下依赖就行了
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 项目基本信息 -->
<groupId>com.example</groupId>
<artifactId>flink-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 核心配置:JDK版本、Flink版本、Scala版本(确保依赖匹配) -->
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.14.5</flink.version> <!-- 已验证依赖存在的稳定版本 -->
<scala.binary.version>2.12</scala.binary.version> <!-- 与Flink 1.14.5匹配的Scala版本 -->
<slf4j.version>1.7.36</slf4j.version> <!-- 日志依赖版本(兼容Flink) -->
</properties>
<dependencies>
<!-- 1. Flink流处理核心依赖(必须) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 2. Flink WebUI依赖(免安装可视化核心,已验证存在) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 3. 日志依赖(避免运行时报日志相关错误) -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
</dependencies>
<!-- 打包插件(可选,后续需要打包运行时可用) -->
<build>
<plugins>
<!-- Maven编译插件(确保用JDK 1.8编译) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>${maven.compiler.source}</source>
<target>${maven.compiler.target}</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<!-- Shade插件(打包时包含所有依赖,避免运行时缺包) -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
</excludes>
</artifactSet>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.example.FlinkHelloWorld</mainClass> <!-- 你的主类全路径 -->
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>实验二 使用多种算子完成Flink文本处理实验
因为我们没虚拟机所以要先配nc模拟流数据输入 下载这个然后配环境变量 之后流输入的内容我们就开个cmd然后输入nc -lk 7777之后需要传入什么数据直接继续往cmd后面输入就行了
然后直接写 运行 胜利结算
java
package org.example;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.util.Collector;
public class WordCountJob {
public static void main(String[] args) throws Exception {
// 设置Flink执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建一个socket数据源
DataStream<String> text = env.socketTextStream("localhost", 7777);
// 将文本转换为小写
DataStream<String> words = text.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toLowerCase();
}
});
// 分割单词并为每个单词附加一个计数器为1的Tuple
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);
out.collect(wordsAndOne);
}
}
});
// 过滤包含字母"a"的单词
wordAndOne = wordAndOne.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0.contains("a");
}
});
// 按单词进行分组,创建一个KeyedStream
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOne.keyBy(
new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
}
);
// 对每个单词的计数进行累加
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.reduce(
new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
String word = value1.f0;
int count = value1.f1 + value2.f1;
return Tuple2.of(word, count);
}
}
);
// 打印结果
sumDS.print();
// 执行任务
env.execute("WordCountFlinkJob");
}
}固定搭配
java
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();这一句所有代码块都会用,是用于设置Flink执行环境的
java
DataStream<String> text = env.socketTextStream("localhost", 7777);这句就是获取流数据源,在这里就是收本地socket的输入的,端口号要和我们上面nc启动时输入的一致,<String>说明读入的是字符串
sumDS.print()用于打印结果,env.execute("WordCountFlinkJob")用于执行Flink程序
一些算子
java
DataStream<String> words = text.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toLowerCase();
}
});这个是全部转小写,MapFunction<输入类型, 输出类型>(泛型必须和输入输出一致),public 输出类型 map(输入类型 value) throws Exception。
java
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOne = words.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" "); // 按空格拆单词
for (String word : words) {
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1); // 每个单词配1
out.collect(wordsAndOne); // 收集结果,输出到下一流
}
}
});用于以空格为界分割字符串,并返回<字符串,1>的元组
java
wordAndOne = wordAndOne.filter(new FilterFunction<Tuple2<String, Integer>>() {
@Override
public boolean filter(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return stringIntegerTuple2.f0.contains("a"); // f0是二元组第1个元素(单词)
}
});相当于x=x*2这种运算,对所有word进行一个filter过滤运算,只返回有a的
实验三 使用窗口计算函数ReduceFunction统计传感器温度最大值
比上面那个还简单,只需要输入的字符串直接转成元组,然后把之前的加法操作变成取最值操作即可
java
package org.example;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class TemperatureMaxAndMin {
public static void main(String[] args) throws Exception {
// 获取 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); // 设置任务并行度为1
// 创建一个 Socket 数据流,监听指定主机和端口
DataStream<String> socketDataStream = env.socketTextStream("localhost", 7777);
// 将输入字符串解析为温度数据(例如,每行格式为 "sensorId temperature")
DataStream<TemperatureReading> temperatureStream = socketDataStream
.map(line -> {
String[] parts = line.split(" ");
String sensorId = parts[0];
double temperature = Double.parseDouble(parts[1]);
return new TemperatureReading(sensorId, temperature);
});
// 使用滚动窗口进行温度统计
SingleOutputStreamOperator<TemperatureReading> resultStream = temperatureStream.keyBy(reading -> reading.sensorId)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.reduce(new ReduceFunction<TemperatureReading>() {
@Override
public TemperatureReading reduce(TemperatureReading t1, TemperatureReading t2) throws Exception {
String maxSensorId;
double maxTemperature = Math.max(t1.getTemperature(), t2.getTemperature());
if (maxTemperature == t1.getTemperature()) {
maxSensorId = t1.getSensorId();
} else {
maxSensorId = t2.getSensorId();
}
return new TemperatureReading(maxSensorId, maxTemperature);
}
});
// 打印结果
resultStream.map(reading -> reading.getSensorId() + ": " + reading.getTemperature())
.print();
// 执行 Flink 程序
env.execute("TemperatureStatistics");
}
// 温度读数类
public static class TemperatureReading {
private String sensorId;
private double temperature;
public TemperatureReading(String sensorId, double temperature) {
this.sensorId = sensorId;
this.temperature = temperature;
}
public String getSensorId() {
return sensorId;
}
public double getTemperature() {
return temperature;
}
}
}实验四 使用窗口计算函数AggregateFunction计算给定窗口时间内的订单销售额
java
package org.example;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class OrderAggregate {
public static void main(String[] args) throws Exception {
// 设置执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 创建Socket数据源
// 假设订单数据格式为:订单ID,产品名称,销售数量
DataStream<String> socketDataStream = env.socketTextStream("localhost", 9999);
// 使用AggregateFunction进行窗口化的订单统计
DataStream<Tuple3<String, String, Integer>> result = socketDataStream
.map(new OrderParser())
.keyBy(order -> order.f1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.aggregate(new OrderAggregator());
// 打印结果
result.print();
// 执行Flink程序
env.execute("Online Order Statistics Experiment");
}
// 自定义订单解析函数
public static final class OrderParser implements MapFunction<String, Tuple3<String, String, Integer>> {
@Override
public Tuple3<String, String, Integer> map(String value) throws Exception {
// 假设订单数据格式为:订单ID,产品名称,销售数量
String[] parts = value.split(",");
return new Tuple3<>(parts[0], parts[1], Integer.parseInt(parts[2]));
}
}
// 自定义AggregateFunction来统计每个产品的销售量
public static final class OrderAggregator implements AggregateFunction<Tuple3<String, String, Integer>, Tuple3<String, String, Integer>, Tuple3<String, String, Integer>> {
@Override
public Tuple3<String, String, Integer> createAccumulator() {
return new Tuple3<>("", "", 0);
}
@Override
public Tuple3<String, String, Integer> add(Tuple3<String, String, Integer> accumulator, Tuple3<String, String, Integer> value) {
Tuple3<String, String, Integer> newAccumulator = new Tuple3<>(accumulator.f0, accumulator.f1, accumulator.f2);
newAccumulator.f2 += value.f2;
return newAccumulator;
}
@Override
public Tuple3<String, String, Integer> getResult(Tuple3<String, String, Integer> accumulator) {
return accumulator;
}
@Override
public Tuple3<String, String, Integer> merge(Tuple3<String, String, Integer> a, Tuple3<String, String, Integer> b) {
return new Tuple3<>(a.f0, a.f1, a.f2 + b.f2);
}
}
}