从debate函数开始看
python
async def debate(idea: str, investment: float = 3.0, n_round: int = 5):
"""Run a team of presidents and watch they quarrel. :)"""
Biden = Debator(name="Biden", profile="Democrat", opponent_name="Trump")
Trump = Debator(name="Trump", profile="Republican", opponent_name="Biden")
team = Team()
team.hire([Biden, Trump])
team.invest(investment)
team.run_project(idea, send_to="Biden") # send debate topic to Biden and let him speak first
await team.run(n_round=n_round)
def main(idea: str, investment: float = 3.0, n_round: int = 10):
"""
:param idea: Debate topic, such as "Topic: The U.S. should commit more in climate change fighting"
or "Trump: Climate change is a hoax"
:param investment: contribute a certain dollar amount to watch the debate
:param n_round: maximum rounds of the debate
:return:
"""
if platform.system() == "Windows":
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
asyncio.run(debate(idea, investment, n_round))
if __name__ == "__main__":
fire.Fire(main) 组件1:team
python
class Team(BaseModel):
"""
Team: Possesses one or more roles (agents), SOP (Standard Operating Procedures), and a env for instant messaging,
dedicated to env any multi-agent activity, such as collaboratively writing executable code.
"""
model_config = ConfigDict(arbitrary_types_allowed=True)
env: Optional[Environment] = None
investment: float = Field(default=10.0)
idea: str = Field(default="")
use_mgx: bool = Field(default=True)
def __init__(self, context: Context = None, **data: Any):
super(Team, self).__init__(**data)
ctx = context or Context()
if not self.env and not self.use_mgx:
self.env = Environment(context=ctx)
elif not self.env and self.use_mgx:
self.env = MGXEnv(context=ctx)
else:
self.env.context = ctx # The `env` object is allocated by deserialization
if "roles" in data:
self.hire(data["roles"])
if "env_desc" in data:
self.env.desc = data["env_desc"]组件2:Environment
这里Environment和Context都是布置背景的内容,Context和Memory都是Envrionment初始化配置的内容。
这里区分MGXEnv和Env:
MGXEnv是一个团队协作环境中的消息发布系统 ,核心逻辑是TeamLeader(团队领导)作为消息中枢,管理不同角色之间的通信。我来详细解读:
核心逻辑架构
用户/角色 → TeamLeader(Mike) → 目标角色
↑ ↓
直接聊天 常规工作流四种消息处理模式
1. 用户直接与特定角色聊天 (user_defined_recipient=True)
python
if user_defined_recipient:
# 用户直接私聊某个角色
self.direct_chat_roles.add(role_name) # 标记为直接聊天状态
self._publish_message(message) # 直接发送,不经过TL场景:用户想和某个角色单独聊天(如:"@设计师,帮我设计个logo")
-
TL不参与,避免干扰
-
其他角色也不会收到
2. 角色回复用户的直接聊天 (sent_from in direct_chat_roles)
python
elif message.sent_from in self.direct_chat_roles:
# 角色回复用户的私聊
self.direct_chat_roles.remove(message.sent_from) # 结束私聊状态
if self.is_public_chat:
self._publish_message(message) # 只有在公开聊天时才广播场景:设计师回复用户的私聊请求
-
如果是在私聊环境,只有用户能看到回复
-
如果切换到公开聊天,TL和其他角色才能看到
3. TeamLeader处理后的消息 (publicer == tl.profile)
python
elif publicer == tl.profile:
if message.send_to == {"no one"}:
return True # 跳过TL的虚拟消息
# TL已处理,可以正式发布
self._publish_message(message)场景:TL完成消息分配/处理后发布
-
TL可能过滤、修改或分配消息
-
这是常规工作流的最后一步
4. 常规工作流消息(默认情况)
python
else:
# 所有常规消息都先经过TL
message.send_to.add(tl.name) # 添加TL为收件人
self._publish_message(message) # 发送给TL处理场景:角色A想和角色B沟通工作
角色A → TL → 分配/处理 → 角色B环境的作用和函数:
-
observe 提供环境观察
-
step action+obsevation
-
publish_message 给参与的人分配信息
-
run 运转所有任务
-
加入role 读取role
回到team
python
class Team(BaseModel):
def hire(self, roles: list[Role]):
"""Hire roles to cooperate"""
self.env.add_roles(roles)
...
def run_project(self, idea, send_to: str = ""):
"""Run a project from publishing user requirement."""
self.idea = idea
# Human requirement.
self.env.publish_message(Message(content=idea))
def start_project(self, idea, send_to: str = ""):
"""
Deprecated: This method will be removed in the future.
Please use the `run_project` method instead.
"""
warnings.warn(
"The 'start_project' method is deprecated and will be removed in the future. "
"Please use the 'run_project' method instead.",
DeprecationWarning,
stacklevel=2,
)
return self.run_project(idea=idea, send_to=send_to)
@serialize_decorator
async def run(self, n_round=3, idea="", send_to="", auto_archive=True):
"""Run company until target round or no money"""
if idea:
self.run_project(idea=idea, send_to=send_to)
while n_round > 0:
if self.env.is_idle:
logger.debug("All roles are idle.")
break
n_round -= 1
self._check_balance()
await self.env.run()
logger.debug(f"max {n_round=} left.")
self.env.archive(auto_archive)
return self.env.history那么 可以看到team主要也是队伍的成员、运行项目这些功能
debate.py 的debate函数 team.run_project
--> env.publish_message()
python
def publish_message(self, message: Message, peekable: bool = True) -> bool:
"""
Distribute the message to the recipients.
In accordance with the Message routing structure design in Chapter 2.2.1 of RFC 116, as already planned
in RFC 113 for the entire system, the routing information in the Message is only responsible for
specifying the message recipient, without concern for where the message recipient is located. How to
route the message to the message recipient is a problem addressed by the transport framework designed
in RFC 113.
"""
logger.debug(f"publish_message: {message.dump()}")
found = False
# According to the routing feature plan in Chapter 2.2.3.2 of RFC 113
for role, addrs in self.member_addrs.items():
if is_send_to(message, addrs):
role.put_message(message)
found = True
if not found:
logger.warning(f"Message no recipients: {message.dump()}")
self.history.add(message) # For debug
return True
def is_send_to(message: "Message", addresses: set): #Message default是配置MESSAGE_ROUTE_TO_ALL
"""Return whether it's consumer"""
if MESSAGE_ROUTE_TO_ALL in message.send_to:
return True
for i in addresses:
if i in message.send_to:
return True
return FalseMESSAGE_ROUTE_TO_ALL :Message default是配置MESSAGE_ROUTE_TO_ALL
所以普通 环境里 消息传给所有人
这里member_addrs 是加入成员的时候就会设置 这是以防名字在不同环境下重复,要区分
组件3:role
然后就到role了
python
class Role(BaseRole, SerializationMixin, ContextMixin, BaseModel):
"""Role/Agent"""
model_config = ConfigDict(arbitrary_types_allowed=True, extra="allow")
name: str = ""
profile: str = ""
goal: str = ""
constraints: str = ""
desc: str = ""
is_human: bool = False
enable_memory: bool = (
True # Stateless, atomic roles, or roles that use external storage can disable this to save memory.
)
role_id: str = ""
states: list[str] = []
# scenarios to set action system_prompt:
# 1. `__init__` while using Role(actions=[...])
# 2. add action to role while using `role.set_action(action)`
# 3. set_todo while using `role.set_todo(action)`
# 4. when role.system_prompt is being updated (e.g. by `role.system_prompt = "..."`)
# Additional, if llm is not set, we will use role's llm
actions: list[SerializeAsAny[Action]] = Field(default=[], validate_default=True)
rc: RoleContext = Field(default_factory=RoleContext)
addresses: set[str] = set()
planner: Planner = Field(default_factory=Planner)
# builtin variables
recovered: bool = False # to tag if a recovered role
latest_observed_msg: Optional[Message] = None # record the latest observed message when interrupted
observe_all_msg_from_buffer: bool = False # whether to save all msgs from buffer to memory for role's awareness
__hash__ = object.__hash__ # support Role as hashable type in `Environment.members`
def put_message(self, message):
"""Place the message into the Role object's private message buffer."""
if not message:
return
self.rc.msg_buffer.push(message)存message到每个role的memory里
整个过程怎么运转的呢?
来看examples/debate.py
python
async def debate(idea: str, investment: float = 3.0, n_round: int = 5):
"""Run a team of presidents and watch they quarrel. :)"""
Biden = Debator(name="Biden", profile="Democrat", opponent_name="Trump")
Trump = Debator(name="Trump", profile="Republican", opponent_name="Biden")
team = Team()
team.hire([Biden, Trump])
team.invest(investment)
team.run_project(idea, send_to="Biden") # send debate topic to Biden and let him speak first
await team.run(n_round=n_round)就是team.run(n_round=n_round)这句维持运转
然后跳转到metagpt\team.py
python
@serialize_decorator
async def run(self, n_round=3, idea="", send_to="", auto_archive=True):
"""Run company until target round or no money"""
if idea:
self.run_project(idea=idea, send_to=send_to)
while n_round > 0:
if self.env.is_idle:
logger.debug("All roles are idle.")
break
n_round -= 1
self._check_balance()
await self.env.run()
logger.debug(f"max {n_round=} left.")
self.env.archive(auto_archive)
return self.env.history然后就是self.env.run ()
跳转到metagpt\environment\base_env.py
python
async def run(self, k=1):
"""处理一次所有信息的运行
Process all Role runs at once
"""
for _ in range(k):
futures = []
for role in self.roles.values():
if role.is_idle:
continue
future = role.run()
futures.append(future)
if futures:
await asyncio.gather(*futures)
logger.debug(f"is idle: {self.is_idle}")role.run() 跳转到metagpt\roles\role.py
python
@role_raise_decorator
async def run(self, with_message=None) -> Message | None:
"""Observe, and think and act based on the results of the observation"""
if with_message:
msg = None
if isinstance(with_message, str):
msg = Message(content=with_message)
elif isinstance(with_message, Message):
msg = with_message
elif isinstance(with_message, list):
msg = Message(content="\n".join(with_message))
if not msg.cause_by:
msg.cause_by = UserRequirement
self.put_message(msg)
if not await self._observe():
# If there is no new information, suspend and wait
logger.debug(f"{self._setting}: no news. waiting.")
return
rsp = await self.react()
# Reset the next action to be taken.
self.set_todo(None)
# Send the response message to the Environment object to have it relay the message to the subscribers.
self.publish_message(rsp)
return rsp每次就是读消息 存消息 然后观察_observe()整理信息 react
observe
python
async def _observe(self) -> int:
"""Prepare new messages for processing from the message buffer and other sources."""
# Read unprocessed messages from the msg buffer.
news = []
if self.recovered and self.latest_observed_msg:
news = self.rc.memory.find_news(observed=[self.latest_observed_msg], k=10)
# 从消息缓冲区读取未处理的消息消息来源可能是其他角色发送的,或者是系统产生的。使用pop_all()确保每条消息只被一个角色处理一次
if not news:
news = self.rc.msg_buffer.pop_all()
# Store the read messages in your own memory to prevent duplicate processing.
old_messages = [] if not self.enable_memory else self.rc.memory.get()
# Filter in messages of interest.
self.rc.news = [
n for n in news if (n.cause_by in self.rc.watch or self.name in n.send_to) and n not in old_messages ## 关注特定来源 消息是发给我的
]
if self.observe_all_msg_from_buffer:
# save all new messages from the buffer into memory, the role may not react to them but can be aware of them
self.rc.memory.add_batch(news)
else:
# only save messages of interest into memory
self.rc.memory.add_batch(self.rc.news)
self.latest_observed_msg = self.rc.news[-1] if self.rc.news else None # record the latest observed msg
# Design Rules:
# If you need to further categorize Message objects, you can do so using the Message.set_meta function.
# msg_buffer is a receiving buffer, avoid adding message data and operations to msg_buffer.
news_text = [f"{i.role}: {i.content[:20]}..." for i in self.rc.news]
if news_text:
logger.debug(f"{self._setting} observed: {news_text}")
return len(self.rc.news)消息缓冲区
↓
[收件箱] ← 新消息流入
↓
🔍 观察者筛选:
├── 消息是发给我的吗? → 是 → 加入rc.news
├── 是我关注的事件吗? → 是 → 加入rc.news
└── 都不是 → 忽略
↓
💾 记忆存储 (仅存储筛选后的消息)
↓
📝 记录最后观察的消息 (latest_observed_msg)关键技术细节
1. 恢复机制
python
if self.recovered and self.latest_observed_msg:
news = self.rc.memory.find_news(observed=[self.latest_observed_msg], k=10)-
当角色从崩溃/中断中恢复时,避免消息丢失
-
基于最后观察的消息,从记忆中找到后续的10条新消息
2. 两种观察模式
python
if self.observe_all_msg_from_buffer:
self.rc.memory.add_batch(news) # 模式A:知道所有消息
else:
self.rc.memory.add_batch(self.rc.news) # 模式B:只记相关消息-
全知模式:了解所有消息内容(用于团队领导等需要全局视野的角色)
-
专注模式:只关注与自己直接相关的内容(用于专业角色)
3. 去重机制
python
[n for n in news if ... and n not in old_messages]-
避免重复处理同一消息
-
提升系统效率
然后react
python
async def _react(self) -> Message:
"""Think first, then act, until the Role _think it is time to stop and requires no more todo.
This is the standard think-act loop in the ReAct paper, which alternates thinking and acting in task solving, i.e. _think -> _act -> _think -> _act -> ...
Use llm to select actions in _think dynamically
"""
actions_taken = 0
rsp = AIMessage(content="No actions taken yet", cause_by=Action) # will be overwritten after Role _act
while actions_taken < self.rc.max_react_loop:
# think
has_todo = await self._think()
if not has_todo:
break
# act
logger.debug(f"{self._setting}: {self.rc.state=}, will do {self.rc.todo}")
rsp = await self._act()
actions_taken += 1
return rsp # return output from the last action_think
python
async def _think(self) -> bool:
"""Consider what to do and decide on the next course of action. Return false if nothing can be done."""
if len(self.actions) == 1:
# If there is only one action, then only this one can be performed
self._set_state(0)
return True
if self.recovered and self.rc.state >= 0:
self._set_state(self.rc.state) # action to run from recovered state
self.recovered = False # avoid max_react_loop out of work
return True
if self.rc.react_mode == RoleReactMode.BY_ORDER:
if self.rc.max_react_loop != len(self.actions):
self.rc.max_react_loop = len(self.actions)
self._set_state(self.rc.state + 1)
return self.rc.state >= 0 and self.rc.state < len(self.actions)
prompt = self._get_prefix()
prompt += STATE_TEMPLATE.format(
history=self.rc.history,
states="\n".join(self.states),
n_states=len(self.states) - 1,
previous_state=self.rc.state,
)
next_state = await self.llm.aask(prompt)
next_state = extract_state_value_from_output(next_state)
logger.debug(f"{prompt=}")
if (not next_state.isdigit() and next_state != "-1") or int(next_state) not in range(-1, len(self.states)):
logger.warning(f"Invalid answer of state, {next_state=}, will be set to -1")
next_state = -1
else:
next_state = int(next_state)
if next_state == -1:
logger.info(f"End actions with {next_state=}")
self._set_state(next_state)
return True
def extract_state_value_from_output(content: str) -> str:
"""
For openai models, they will always return state number. But for open llm models, the instruction result maybe a
long text contain target number, so here add a extraction to improve success rate.
Args:
content (str): llm's output from `Role._think`
"""
content = content.strip() # deal the output cases like " 0", "0\n" and so on.
pattern = (
r"(?<!-)[0-9]" # TODO find the number using a more proper method not just extract from content using pattern
)
matches = re.findall(pattern, content, re.DOTALL)
matches = list(set(matches))
state = matches[0] if len(matches) > 0 else "-1"
return state 对于think
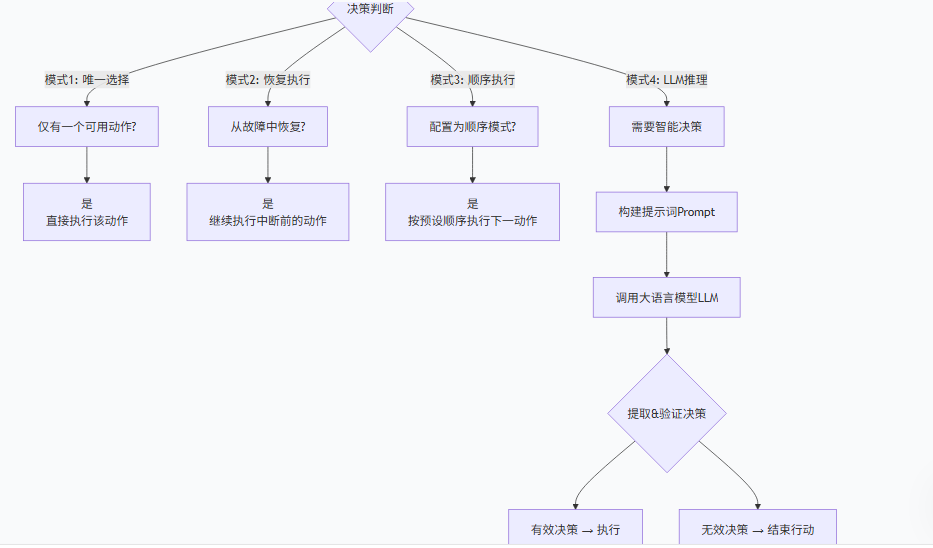
模式1:唯一选择(默认路径)
python
if len(self.actions) == 1:
self._set_state(0) # 只有一个动作,没得选
return True场景:角色只有一个能力时(如"翻译员"只能做翻译)。
模式2:恢复执行
python
if self.recovered and self.rc.state >= 0:
self._set_state(self.rc.state) # 从上次中断的状态继续
return True场景:系统崩溃后重启,角色从上次中断的地方继续工作。
模式3:顺序执行
python
if self.rc.react_mode == RoleReactMode.BY_ORDER:
self._set_state(self.rc.state + 1) # 简单地执行下一个动作场景:需要严格按步骤执行的流程(如"需求分析→设计→开发→测试")。
模式4:LLM智能决策(最复杂)
当需要灵活决策时,让大语言模型来决定。
🤖 模式4详解:LLM如何"思考"
这是最核心的部分,展示了如何让AI像人一样思考下一步行动:
第1步:构建思考提示词
python
prompt = STATE_TEMPLATE.format(
history=self.rc.history, # 过往对话历史
states="\n".join(self.states), # 所有可能动作的描述
n_states=len(self.states) - 1, # 可选动作编号范围
previous_state=self.rc.state, # 上一个动作
)生成的Prompt示例:
text
你是一个设计师,刚刚完成了UI草图。
历史对话:PM说"需要更简洁的设计",你回复"好的,我调整一下"。
可选动作:
0. 细化当前设计方案
1. 与PM确认需求细节
2. 开始设计下一个页面
3. 任务完成,结束工作
请基于历史对话,选择下一步最合适的动作编号(0-3),如果应该结束则选-1。第2步:LLM推理与回答
python
next_state = await self.llm.aask(prompt) # LLM返回如"1"或"我认为应该选1"第3步:解析LLM的回答(关键!)
python
def extract_state_value_from_output(content: str) -> str:
# LLM可能返回"我建议选择动作1"或"答案是:1"等非标准格式
pattern = r"(?<!-)[0-9]" # 匹配数字但不匹配负号
matches = re.findall(pattern, content)
state = matches[0] if matches else "-1" # 提取不到则默认结束
return state解析示例:
| LLM原始回答 | 提取结果 | 说明 |
|---|---|---|
"1" |
"1" |
标准回答,直接使用 |
"选择动作1" |
"1" |
从文本中提取数字 |
"我觉得应该结束" |
"-1" |
无数字,默认结束 |
"选项2不错" |
"2" |
提取到数字2 |
第4步:验证与执行
python
if int(next_state) not in range(-1, len(self.states)):
next_state = -1 # 无效选择则结束
self._set_state(next_state) # 设置下一步动作然后到act think+act=react
python
async def _act(self) -> Message:
logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")
response = await self.rc.todo.run(self.rc.history)
if isinstance(response, (ActionOutput, ActionNode)):
msg = AIMessage(
content=response.content,
instruct_content=response.instruct_content,
cause_by=self.rc.todo,
sent_from=self,
)
elif isinstance(response, Message):
msg = response
else:
msg = AIMessage(content=response or "", cause_by=self.rc.todo, sent_from=self)
self.rc.memory.add(msg)
return msg就这样走完轮回就跑完过程
同时角色在初始化的时候 会初始化action和state 不详写
组件4:Action
metagpt\roles\role.py的_act 函数--> self.rc.todo.run
metagpt\actions\action.py
python
async def _run_action_node(self, *args, **kwargs):
"""Run action node"""
msgs = args[0]
context = "## History Messages\n"
context += "\n".join([f"{idx}: {i}" for idx, i in enumerate(reversed(msgs))])
return await self.node.fill(req=context, llm=self.llm)
async def run(self, *args, **kwargs):
"""Run action"""
if self.node:
return await self._run_action_node(*args, **kwargs)
raise NotImplementedError("The run method should be implemented in a subclass.")然后就到actionnode
python
@exp_cache(serializer=ActionNodeSerializer())
async def fill(
self,
*,
req,
llm,
schema="json",
mode="auto",
strgy="simple",
images: Optional[Union[str, list[str]]] = None,
timeout=USE_CONFIG_TIMEOUT,
exclude=[],
function_name: str = None,
):
"""Fill the node(s) with mode.
:param req: Everything we should know when filling node.
:param llm: Large Language Model with pre-defined system message.
:param schema: json/markdown, determine example and output format.
- raw: free form text
- json: it's easy to open source LLM with json format
- markdown: when generating code, markdown is always better
:param mode: auto/children/root
- auto: automated fill children's nodes and gather outputs, if no children, fill itself
- children: fill children's nodes and gather outputs
- root: fill root's node and gather output
:param strgy: simple/complex
- simple: run only once
- complex: run each node
:param images: the list of image url or base64 for gpt4-v
:param timeout: Timeout for llm invocation.
:param exclude: The keys of ActionNode to exclude.
:return: self
"""
self.set_llm(llm)
self.set_context(req)
if self.schema:
schema = self.schema
if mode == FillMode.CODE_FILL.value:
result = await self.code_fill(context, function_name, timeout)
self.instruct_content = self.create_class()(**result)
return self
elif mode == FillMode.XML_FILL.value:
context = self.xml_compile(context=self.context)
result = await self.xml_fill(context, images=images)
self.instruct_content = self.create_class()(**result)
return self
elif mode == FillMode.SINGLE_FILL.value:
result = await self.single_fill(context, images=images)
self.instruct_content = self.create_class()(**result)
return self
if strgy == "simple":
return await self.simple_fill(schema=schema, mode=mode, images=images, timeout=timeout, exclude=exclude)
elif strgy == "complex":
# 这里隐式假设了拥有children
tmp = {}
for _, i in self.children.items():
if exclude and i.key in exclude:
continue
child = await i.simple_fill(schema=schema, mode=mode, images=images, timeout=timeout, exclude=exclude)
tmp.update(child.instruct_content.model_dump())
cls = self._create_children_class()
self.instruct_content = cls(**tmp)
return self核心概念:ActionNode 是一棵树
想象一下项目管理中的工作分解结构(WBS),ActionNode 就是它的动态、智能化版本:
text
🌲 根节点(Root ActionNode)
├── 📝 子任务 A(Child ActionNode)
├── 🔧 子任务 B(Child ActionNode)
│ ├── ⚙️ 子子任务 B.1
│ └── ⚙️ 子子任务 B.2
└── 📊 子任务 C(Child ActionNode)每个节点都负责完成一个定义清晰的小任务,所有节点组合起来完成一个大目标。
🎯 fill方法:节点的"执行引擎"
fill 方法是让这棵"任务树"动起来的关键。它根据不同的 mode(模式)和 strgy(策略),智能地决定如何填充(完成)节点内容。
三种核心填充模式
| 模式 | 触发条件 | 工作原理 | 典型场景 |
|---|---|---|---|
auto(自动) |
默认模式 | 检查是否有子节点: • 有 → 填充所有子节点 • 无 → 填充当前节点 | 通用任务处理 |
children(仅子节点) |
明确指定时 | 只填充子节点,忽略当前节点内容 | 协调者角色(如项目经理) |
root(仅根节点) |
明确指定时 | 只填充当前根节点,不处理子节点 | 简单、原子性任务 |
两种执行策略
| 策略 | 工作原理 | 适用场景 |
|---|---|---|
simple(简单) |
将整个节点树一次性交给LLM处理,让LLM自己理解结构并输出所有结果 | 任务结构简单、子任务间关联性强 |
complex(复杂) |
分别处理每个子节点,逐个调用LLM,最后合并结果 | 任务复杂、子任务相对独立、需要精确控制 |
python
# simple策略:一次性处理整个树
result = await root_node.simple_fill("设计一个电商网站")
# complex策略:逐个处理子节点
for child in root_node.children:
await child.simple_fill(f"设计电商网站的{child.key}部分")⚙️ 高级填充模式详解
除了基本模式,还有三种针对特定场景的优化模式:
1. CODE_FILL(代码填充)
python
# 专门用于生成代码
await node.fill(mode="code_fill", function_name="calculate_price")
# LLM会专注于生成特定函数的代码实现2. XML_FILL(XML填充)
python
# 使用XML格式进行结构化填充
context = node.xml_compile("用户需求描述")
result = await node.xml_fill(context)
# 适合需要严格结构化的输出3. SINGLE_FILL(单节点填充)
python
# 只填充当前单个节点,不涉及子节点
result = await node.single_fill("翻译这句话")
# 最简单的原子操作这里配置会配置到actionnode的content和instruct_content然后
返回到role.py来看 metagpt\roles\role.py
python
async def _act(self) -> Message:
logger.info(f"{self._setting}: to do {self.rc.todo}({self.rc.todo.name})")
response = await self.rc.todo.run(self.rc.history)
if isinstance(response, (ActionOutput, ActionNode)):
msg = AIMessage(
content=response.content,
instruct_content=response.instruct_content,
cause_by=self.rc.todo,
sent_from=self,
)
elif isinstance(response, Message):
msg = response
else:
msg = AIMessage(content=response or "", cause_by=self.rc.todo, sent_from=self)
self.rc.memory.add(msg)
return msg有content和instruct_content就能出aimessage 到此就完成action