网络是GPU和TPU差异最大的领域之一。正如我们所见,TPU之间以二维或三维环面连接,每个TPU仅与其相邻的TPU相连。这意味着在两个TPU之间发送消息必须经过中间所有TPU,这迫使我们只能在网状网络中使用统一的通信模式。虽然这在某些方面不太方便,但也意味着每个TPU的链路数量是恒定的,我们可以扩展到任意规模的TPU"pod"而不会损失带宽。
另一方面,GPU 使用更传统的基于树状结构的层级交换网络。8 个 GPU 组成一组,称为节点(GB200 最多可达 72 个)。这些节点之间通过称为 NVLink 的高带宽互连线以 1 跳的距离连接,然后通过连接到每个 GPU 的网卡,使用低带宽的 InfiniBand (IB) 或以太网连接成更大的单元(称为SU或可扩展单元)。这些 SU 又可以通过更高级别的交换机连接成任意大小的单元。
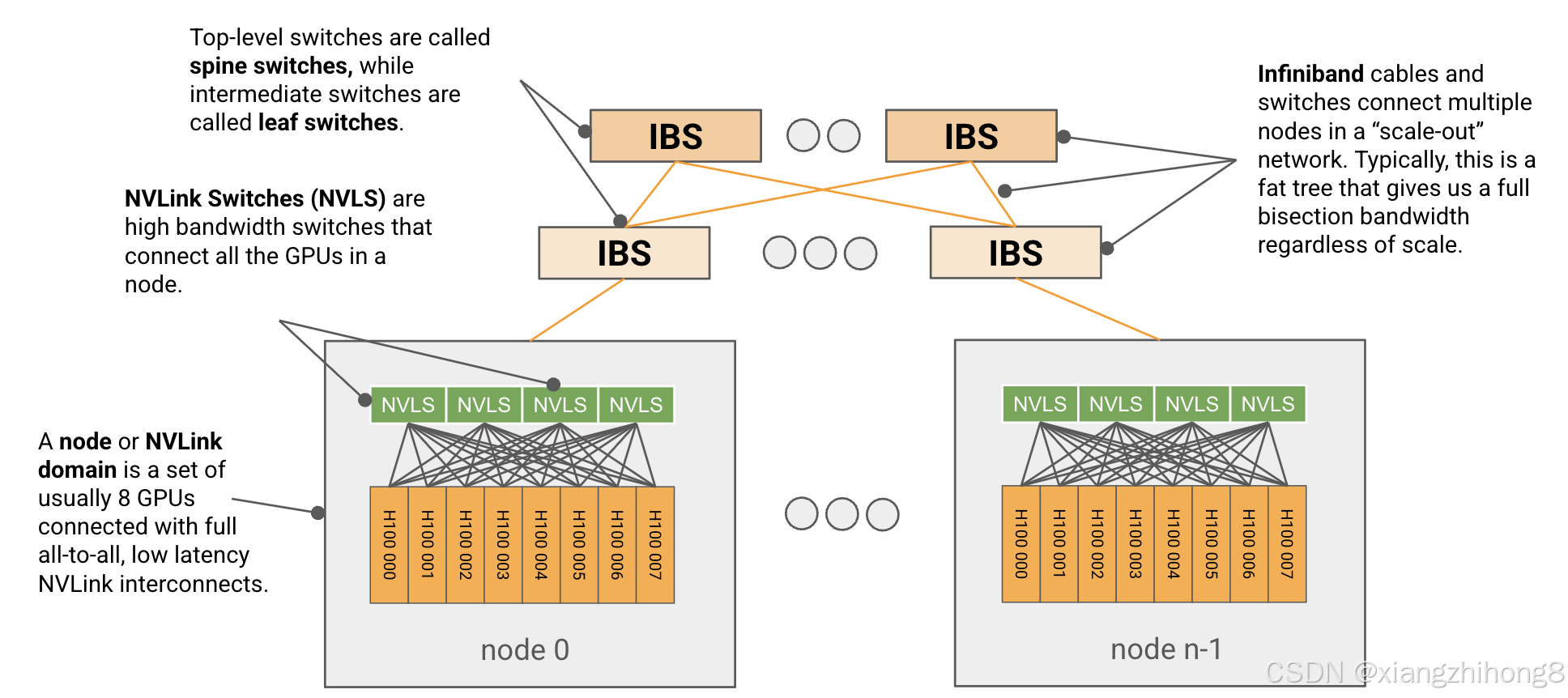 **图:**典型的 H100 网络示意图。一组 8 个 GPU 通过 NVSwitch(也称为 NVLink 交换机)连接到一个节点或 NVLink 域,这些节点之间通过交换式 InfiniBand 架构相互连接。每个 H100 在 NVLink 域中具有约 450GB/s 的出口带宽,每个节点在 IB 网络中具有 400GB/s 的出口带宽。
**图:**典型的 H100 网络示意图。一组 8 个 GPU 通过 NVSwitch(也称为 NVLink 交换机)连接到一个节点或 NVLink 域,这些节点之间通过交换式 InfiniBand 架构相互连接。每个 H100 在 NVLink 域中具有约 450GB/s 的出口带宽,每个节点在 IB 网络中具有 400GB/s 的出口带宽。
在节点层面
GPU 节点是一个小型单元,通常由 8 个 GPU 组成(GB200 最多可达 72 个),通过全带宽、低延迟的 NVLink 互连连接。每个节点包含多个高带宽 NVSwitch,用于在所有本地 GPU 之间交换数据包。实际的节点级拓扑结构随着时间的推移发生了相当大的变化,包括每个节点的交换机数量,但对于 H100,每个节点有 4 个 NVSwitch,GPU 以5 + 4 + 4 + 5链路模式连接到这些交换机,如下图所示:
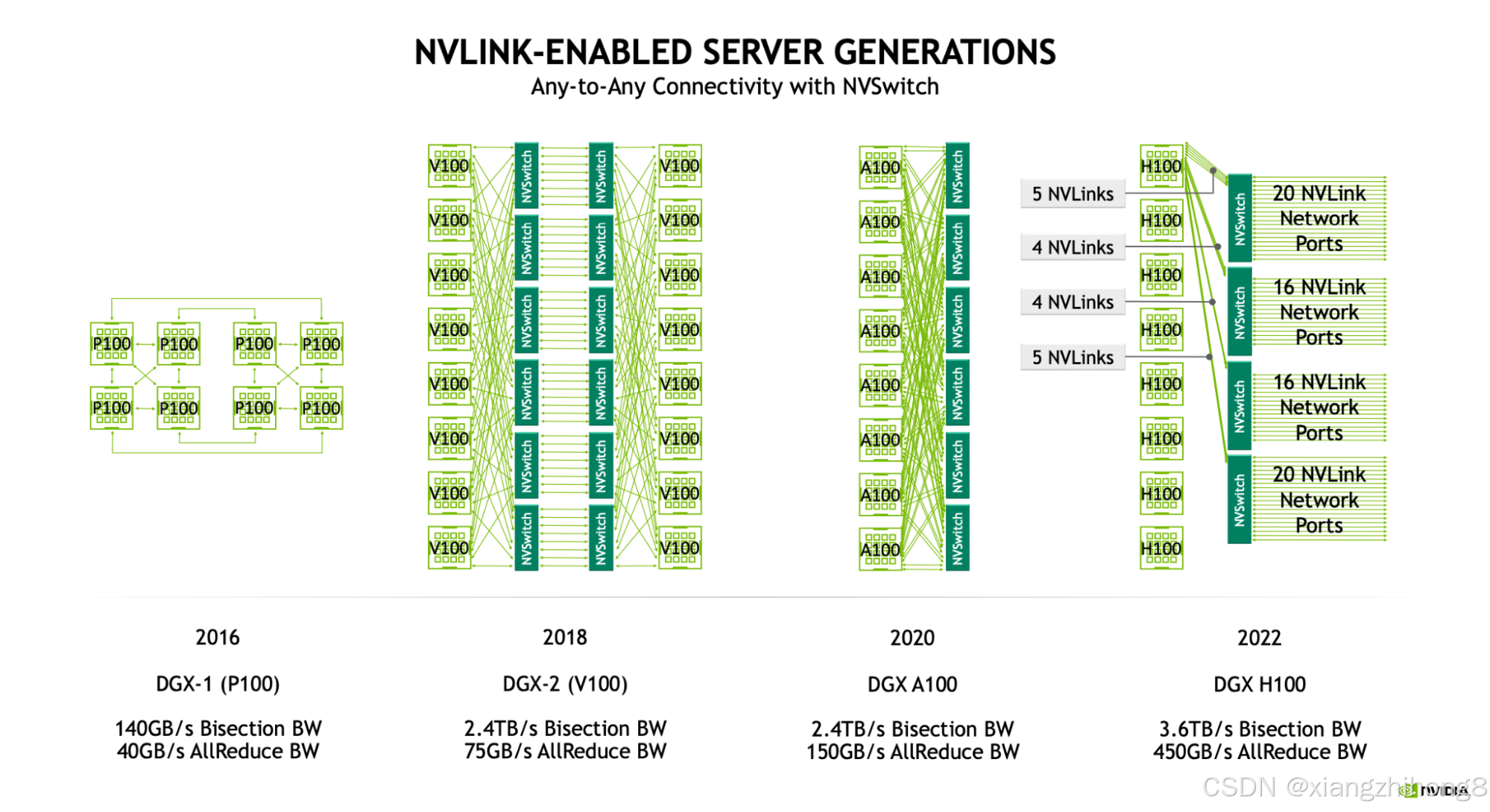 **图:**从 Pascall (P100) 开始的节点(又称 NVLink)域图。自 Volta (V100) 起,我们使用一组交换机实现了节点内所有设备的互联。H100 节点有 4 个 NVSwitch 连接到所有 8 个 GPU,链路速率为 25GB/s。
**图:**从 Pascall (P100) 开始的节点(又称 NVLink)域图。自 Volta (V100) 起,我们使用一组交换机实现了节点内所有设备的互联。H100 节点有 4 个 NVSwitch 连接到所有 8 个 GPU,链路速率为 25GB/s。
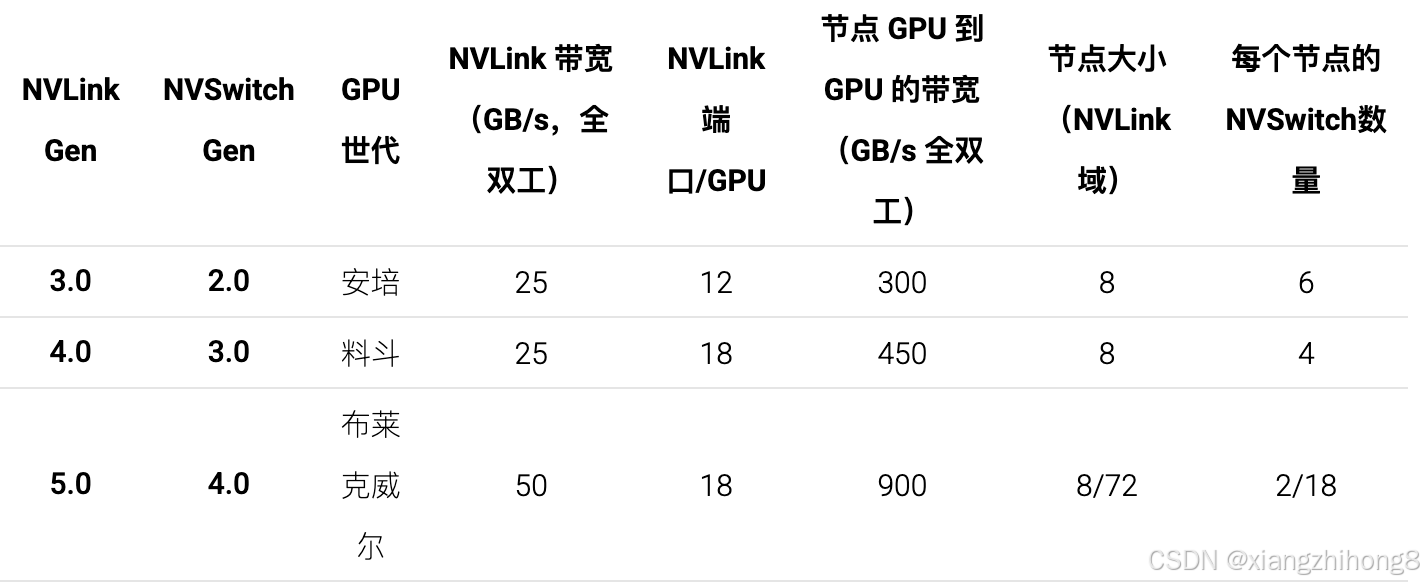
对于 Hopper 一代(NVLink 4.0),每个 NVLink 链路都具有 25GB/s 的全双工传输速率。16带宽(B200 为 50GB/s),使18 * 25=450GB/s每个 GPU 都能以全双工带宽连接到网络。大型 NVSwitch 最多可配备 64 个 NVLink 端口,这意味着一个配备 4 个交换机的 8xH100 节点可以处理高达 50GB/s64 * 25e9 * 4=6.4TB/s的带宽。以下概述了这些数字如何随 GPU 代际变化:
 Blackwell (B200) 拥有 8 个 GPU 的节点。GB200NVL72 支持更大的 NVLink 域,最多可容纳 72 个 GPU。我们将详细介绍 8 个 GPU 和 72 个 GPU 的系统。
Blackwell (B200) 拥有 8 个 GPU 的节点。GB200NVL72 支持更大的 NVLink 域,最多可容纳 72 个 GPU。我们将详细介绍 8 个 GPU 和 72 个 GPU 的系统。
测验 2:GPU 节点
这里还有一些关于网络通信的问答题。我觉得这些题特别适合课后练习,因为它们能让你深入了解实际的通信模式。
问题 1 H100 节点的总带宽
在一个包含 8 个 H100 节点和 4 个交换机的节点系统中,每个节点的总带宽是多少?*提示:*同时考虑 NVLink 和 NVSwitch 的带宽。
答 :我们有 4 台 Gen4 NVSwitch,每台交换机都具有64 * 25e9=1.6TB/s一定的单向带宽。这可以提供4 * 1.6e12=6.4e12交换机级别的带宽。但是,请注意,每台 GPU 只能处理 450GB/s 的单向带宽,这意味着我们最多只能获得 450GB/s 的450e9 * 8 = 3.6TB/s带宽。由于这个值较小,峰值带宽为 3.6TB/s。
问题 2 二分带宽
二分带宽定义为网络中任意两个相等分区之间可用的最小带宽。换句话说,如果将网络分成两个相等的部分,这两个部分之间有多少带宽?你能计算一个 8x H100 节点的二分带宽吗?*提示:*二分带宽通常包含双向流量。
答 :任何偶数分区,每一半都将包含 4 个 GPU,每个 GPU 都可以访问4 * 450GB/s另一半。考虑双向流量,这可以提供8 * 450GB/s跨越分区的字节数,或 3.6TB/s 的二分带宽。这是 NVIDIA 报告的数据,例如此处所示。
问题 3 AllGather 开销
给定一个 B 字节的数组,在 8xH100 节点上执行一次(吞吐量受限的)AllGather 操作需要多长时间?计算 bf16D X , F的值D=4096,其中F=65,536。建议在回答此问题之前阅读 TPU 集体操作 部分。在这里先思考一下,我们接下来会更详细地讨论集体操作。
答:每块GPU可以输出450GB/s的数据,并且每块GPU有B / N 字节(其中 是N=8节点大小)。我们可以想象每个节点将其字节发送给其他所有节点。N− 1节点一个接一个地连接,总共需要 (N - 1) 圈,每一圈都......T 通讯= ( B / ( N ∗ W 单向) ),或者T 通讯= ( N − 1 ) ∗ B / ( N ∗ W 单向)这大约是B / ( N ∗ W 大学)或者B / 3.6e12二分带宽。
对于给定的数组,我们有B=4096 * 65536 * 2=512MB,因此总时间为536e6 * (8 - 1) / 3.6e12 = 1.04ms。这可能受限于延迟,因此在实践中可能需要更长时间(在实践中大约需要 1.5 毫秒)。
超越节点级别
在节点级别之外,GPU 网络的拓扑结构标准化程度较低。NVIDIA 发布了参考架构 DGX SuperPod,该架构使用 InfiniBand 连接比单个节点更多的 GPU,但客户和数据中心提供商可以根据自身需求进行定制。
以下是一个参考 1024 GPU H100 系统的示意图,其中底行的每个盒子都是一个 8xH100 节点,包含 8 个 GPU、8 个 400Gbps CX7 网卡(每个 GPU 一个)和 4 个 NVSwitch。
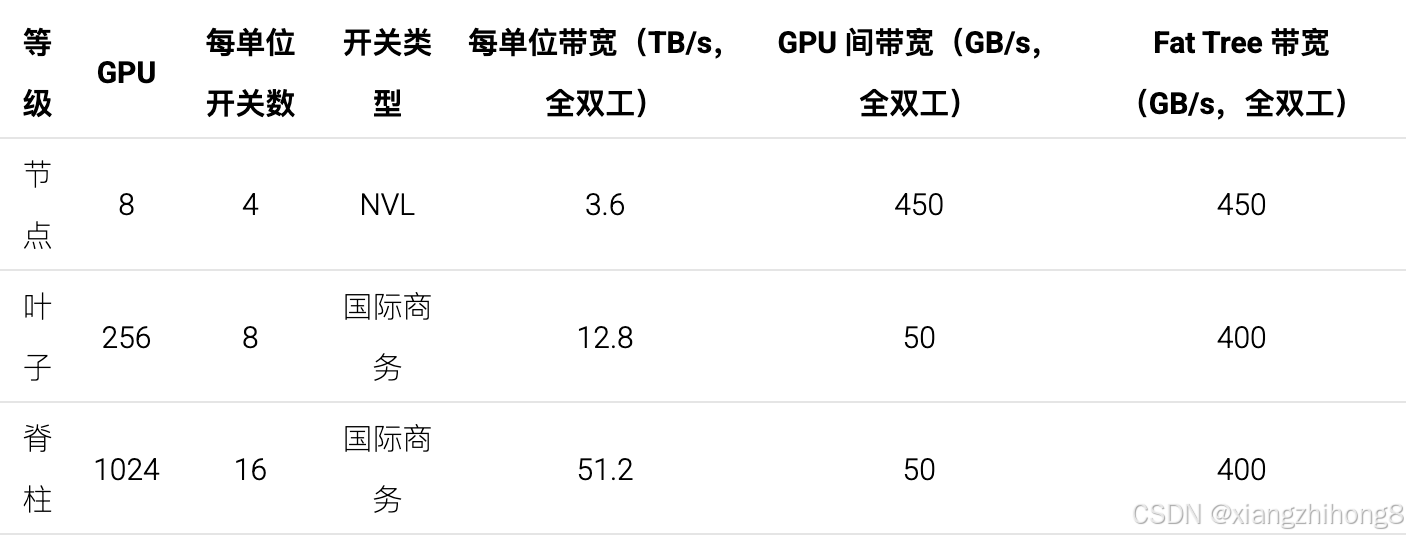
**图:**参考级 1024 H100 DGX SuperPod 的示意图,包含 128 个节点(有时为 127 个),每个节点配备 8 个 H100 GPU,并连接到 InfiniBand 横向扩展网络。32 个节点(256 个 GPU)组成的一组称为"可扩展单元"(SU)。叶脊式 InfiniBand 交换机提供足够的带宽,以实现节点间的全二分带宽。
可扩展单元:每组 32 个节点称为一个"可扩展单元"(或 SU),它们隶属于一组 8 台叶级 InfiniBand 交换机。该 SU 包含 256 个 GPU,每个节点配备 4 台 NVSwitch,并由 8 台 InfiniBand 叶级交换机组成。图中所示的所有线缆均为 InfiniBand NDR(50Gb/s 全双工),并配备 64 端口 NDR IB 交换机(每个端口也支持 50Gb/s)。请注意,IB 交换机的带宽是 NVSwitch 的两倍(64 个端口,链路带宽为 400 Gbps)。
SuperPod:整个 SuperPod 将 4 个 SU 与 16 个顶层"脊"IB 交换机连接起来,从而形成 1024 个 GPU,其中包含 512 个节点级 NVSwitch、32 个叶 IB 交换机和 16 个脊 IB 交换机,总计 512 + 32 + 16 = 560 个交换机。叶交换机以 32 个节点为一组连接到节点,因此每组 256 个 GPU 有 8 个叶交换机。所有叶交换机都连接到所有脊交换机。
我们有多少带宽? InfiniBand 网络(称为"横向扩展网络")的整体拓扑结构是一个胖树,其电缆和交换机保证了节点级以上的完全二分带宽(此处为 400GB/s)。这意味着如果我们把节点分成两半,每个节点都可以同时以 400GB/s 的速率向另一分区中的一个节点输出数据。更重要的是,这意味着在横向扩展网络中,AllReduce 的带宽应该大致恒定!虽然实际实现可能并非如此,但您可以想象在横向扩展网络中对任意数量的节点进行环形归约,因为您可以构建一个包含所有节点的环。
 相比之下,TPU v5p 的单链路出口带宽约为 90GB/s,或沿 3D 环面所有轴向的出口带宽约为 540GB/s。虽然这不是点对点通信,因此只能用于受限的、统一的通信模式,但它仍然提供了更高的 TPU 间带宽,可以扩展到任意规模的拓扑结构(至少最多可达 8960 个 TPU)。
相比之下,TPU v5p 的单链路出口带宽约为 90GB/s,或沿 3D 环面所有轴向的出口带宽约为 540GB/s。虽然这不是点对点通信,因此只能用于受限的、统一的通信模式,但它仍然提供了更高的 TPU 间带宽,可以扩展到任意规模的拓扑结构(至少最多可达 8960 个 TPU)。
理论上,通过添加额外的交换机或间接层,可以将 GPU 交换结构扩展到任意大小,但代价是会增加延迟和昂贵的网络交换机。
GB200 NVL72: NVIDIA 近期开始生产新型 GB200 NVL72 GPU 集群,该集群将 72 个 GPU 集成在一个 NVLink 域中,GPU 间带宽高达 900GB/s。这些域可以链接成更大的 SuperPod,从而获得更高(9 倍)的 IB 胖树带宽。下图展示了该拓扑结构:
**图:**示意图展示了一个包含 576 个 GPU 的 GB200 DGX SuperPod。底层每个机架包含 72 个 GB200 GPU。
计算单个节点的出口带宽(上图中的橙色线),我们得到的4 * 18 * 400 / 8 = 3.6TB/s到叶节点的带宽是 H100 的 9 倍(正如该节点包含的 GPU 数量是 H100 的 9 倍一样)。这意味着关键节点的出口带宽要高得多,因此 跨节点的总带宽实际上可能低于节点内部的带宽。

测验 3:超越节点层级
问题 1 胖树拓扑
使用上图所示的 DGX H100 图,计算节点级 1024 个 GPU pod 的二分带宽。证明每条链路的带宽选择都确保了二分带宽的完整性。提示:务必同时计算链路带宽和交换机带宽。
答:我们逐个组件进行分析:
-
首先,每个节点都通过 8 条 400Gbps NDR IB 线缆连接到叶交换机,从而为每个节点提供
8 * 400 / 8 = 400 GB/s到叶交换机的带宽。我们有 8 台叶交换机,每台的带宽为 3.2TB/s(64 条 400Gbps 链路),但我们只能使用 64 个端口中的 32 个端口从 SU 接入数据,因此这32 * 400 / 8 = 12.8TB/s32 个节点的带宽正好是 400GB/s。 -
然后,在脊交换机层,我们使用
8 * 16 * 2400Gbps NDR IB 线缆将每个 SU 连接到脊交换机,从而为每个 SU 提供8 * 16 * 2 * 400 / 8 = 12.8 TB/s到叶交换机的带宽。同样,每个节点的带宽为 400GB/s。我们有 16 台脊交换机,每台交换机的带宽为 3.2TB/s,因此16 * 3.2 = 51.2 TB/s,在 128 个节点上,总带宽同样为 400GB/s。
因此,如果我们以任何方式对节点进行二分,每个GPU将获得400GB/s的带宽。每个组件都拥有足够的带宽来确保树的完整性。
问题 2 扩展到更大的 DGX pod
假设我们想用 2048 个 GPU 而不是 1024 个进行训练。修改上述 DGX 拓扑结构以处理这种情况的最简单/最佳方法是什么?如果是 4096 个 GPU 呢?提示:没有唯一正确答案,但尽量降低成本,同时考虑链路容量。
答:一种方案是保持SU架构不变(8台交换机下32个节点),然后增加SU的数量和顶层交换机的数量。这样我们需要两倍数量的脊交换机,也就是8个SU,每条SU配备32台脊交换机,就能满足带宽需求。
这样做的一个问题是,每个叶交换机只有 64 个端口,而上图中我们已经用完了所有端口。但我们可以简单地在每个脊交换机上使用一根 400 Gbps NDR 线缆,而不是两根,这样既能保持总带宽不变,又能节省一些端口。
对于 4096 个 GPU 来说,端口数量实际上已经不够用了,所以我们需要增加一层间接层,也就是增加一个层级结构。NVIDIA 将这些称为"核心交换机",并使用 128 个脊交换机和 64 个核心交换机构建了一个 4096 GPU 集群。你可以自己计算一下,这足以提供足够的带宽。