目录
-
- 引言
- 一、一句话理解扩散模型
- 二、直观类比:从毛玻璃到高清照片
- [三、技术框架:加噪 + 去噪](#三、技术框架:加噪 + 去噪)
-
- [3.1 前向过程:系统性加噪("主动搞破坏")](#3.1 前向过程:系统性加噪(“主动搞破坏”))
-
- [关键设计:固定噪声调度(Noise Schedule)](#关键设计:固定噪声调度(Noise Schedule))
- 噪声调度示例
- [3.2 反向过程:智能去噪("学会修复")](#3.2 反向过程:智能去噪(“学会修复”))
- [四、核心组件:为什么是 U-Net?](#四、核心组件:为什么是 U-Net?)
-
- [4.1 U-Net 的三大组成部分](#4.1 U-Net 的三大组成部分)
-
- [(1)编码器(Encoder)--- "看懂整体"](#(1)编码器(Encoder)— “看懂整体”)
- [(2)瓶颈层(Bottleneck)--- "浓缩精华"](#(2)瓶颈层(Bottleneck)— “浓缩精华”)
- [(3)解码器(Decoder)--- "还原细节"](#(3)解码器(Decoder)— “还原细节”)
- [4.2 跳跃连接:U-Net 的灵魂](#4.2 跳跃连接:U-Net 的灵魂)
-
- 为什么需要?
- [举个例子(基于 U-Net 原始论文结构):](#举个例子(基于 U-Net 原始论文结构):)
- [4.3 U-Net 在扩散模型中的改造](#4.3 U-Net 在扩散模型中的改造)
- [五、扩散模型 vs GAN vs VAE](#五、扩散模型 vs GAN vs VAE)
- 六、总结:扩散模型的三大优势
- 七、结语
- [参考文献 & 延伸阅读](#参考文献 & 延伸阅读)
关键词:扩散模型、Diffusion Model、U-Net、图像生成、Stable Diffusion、去噪网络
引言
近年来,以 Stable Diffusion、DALL·E 2、MidJourney 为代表的 AI 绘图工具风靡全球,其背后的核心技术正是------扩散模型(Diffusion Model) 。相比 GAN 和 VAE,扩散模型凭借训练稳定、生成质量高、理论扎实等优势,迅速成为生成式 AI 的主流范式。
本文将系统性地讲解扩散模型的核心思想、数学原理、关键组件(尤其是 U-Net 结构)以及完整工作流程,从而助力理解"AI 是如何从一张噪声图一步步画出逼真图像的"。
一、一句话理解扩散模型
扩散模型是一种"先故意把图像弄脏,再一点点擦干净"的生成方法。
它的终极目标是:从纯噪声中,生成一张从未见过但高度逼真的新图像(如人脸、风景、动漫角色等)。
二、直观类比:从毛玻璃到高清照片
想象你面前有一块完全模糊的毛玻璃(全是雪花噪点),你的任务是:
在这块玻璃上"还原"出一张清晰的人脸照片。
但你不能直接画!你只能做一件事:
每一步,轻轻擦掉一点点"不该有的模糊",让它越来越像人脸。
- 第1步:隐约看出两个亮点(可能是眼睛);
- 第10步:鼻子、嘴巴轮廓浮现;
- 第50步:皮肤纹理、睫毛清晰可见;
- 第100步:一张高清自拍诞生!
✅ 这个"逐步去模糊"的过程,就是扩散模型的核心!
三、技术框架:加噪 + 去噪
扩散模型的工作分为两个阶段:
| 阶段 | 名称 | 是否可学习 | 目的 |
|---|---|---|---|
| 第一阶段 | 前向过程(Forward Process) | ❌ 否 | 将真实图像系统性加噪至纯噪声 |
| 第二阶段 | 反向过程(Reverse Process) | ✅ 是 | 训练神经网络从噪声中重建图像 |
3.1 前向过程:系统性加噪("主动搞破坏")
输入 :一张干净图像 x 0 x_0 x0(如猫的照片)
操作 :逐步添加高斯噪声,共 T T T 步(通常 T = 1000 T = 1000 T=1000)
输出 :纯噪声图像 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)
关键设计:固定噪声调度(Noise Schedule)
每一步的加噪强度由预设参数 α t ∈ ( 0 , 1 ) \alpha_t \in (0,1) αt∈(0,1) 控制。定义累积衰减系数:
α ˉ t = ∏ s = 1 t α s \bar{\alpha}t = \prod{s=1}^t \alpha_s αˉt=s=1∏tαs
则第 t t t 步的带噪图像可直接从原始图一步计算 :
x t = α ˉ t ⋅ x 0 + 1 − α ˉ t ⋅ ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\bar{\alpha}_t} \cdot x_0 + \sqrt{1 - \bar{\alpha}_t} \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I) xt=αˉt ⋅x0+1−αˉt ⋅ϵ,ϵ∼N(0,I)
💡 优势 :无需逐帧模拟加噪,训练时可随机采样任意 t t t,极大提升效率。
噪声调度示例
- 早期(t 小) : α ˉ t ≈ 1 \bar{\alpha}_t \approx 1 αˉt≈1 → 图像几乎不变;
- 后期(t 大) : α ˉ t → 0 \bar{\alpha}_t \to 0 αˉt→0 → 图像全为噪声;
- 常用策略:线性、余弦(cosine 更平滑,效果更好)。
✅ 前向过程总结 :固定算法,仅用于生成训练数据对 ( x t , ϵ ) (x_t, \epsilon) (xt,ϵ)。
3.2 反向过程:智能去噪("学会修复")
目标 :从纯噪声 x T x_T xT 出发,逐步还原出新图像 x 0 x_0 x0。
核心思想:让神经网络预测噪声
- 输入 :带噪图像 x t x_t xt + 时间步 t t t
- 输出 :对原始噪声 ϵ \epsilon ϵ 的预测 ϵ ^ θ ( x t , t ) \hat{\epsilon}_\theta(x_t, t) ϵ^θ(xt,t)
- 网络结构 :U-Net(带时间嵌入)
训练目标(极其简洁!)
最小化预测噪声与真实噪声的均方误差:
L = E x 0 , ϵ , t ∥ ϵ − ϵ \^ θ ( x t , t ) ∥ 2 \mathcal{L} = \mathbb{E}_{x_0, \epsilon, t} \left \\\| \\epsilon - \\hat{\\epsilon}_\\theta(x_t, t) \\\|\^2 \\right L=Ex0,ϵ,t∥ϵ−ϵ\^θ(xt,t)∥2
训练流程:
- 随机选一张真实图 x 0 x_0 x0;
- 随机选时间步 t ∈ 1 , T t \in 1, T t∈1,T;
- 用前向公式生成 x t x_t xt;
- 网络预测 ϵ ^ θ ( x t , t ) \hat{\epsilon}_\theta(x_t, t) ϵ^θ(xt,t);
- 计算 MSE 损失并反向传播。
✅ 妙处:无需对抗训练,损失稳定,收敛快。
生成过程(推理阶段)
从 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I) 开始,迭代执行:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ⋅ ϵ ^ θ ( x t , t ) ) + σ t z x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}t}} \cdot \hat{\epsilon}\theta(x_t, t) \right) + \sigma_t z xt−1=αt 1(xt−1−αˉt 1−αt⋅ϵ^θ(xt,t))+σtz
其中 z ∼ N ( 0 , I ) z \sim \mathcal{N}(0, I) z∼N(0,I)(最后一步设为 0 实现确定性生成)。
⏱️ 缺点:需 50~1000 步迭代,速度慢(但可通过 DDIM、蒸馏等加速至 1~4 步)。
四、核心组件:为什么是 U-Net?
在扩散模型中,U-Net 是去噪网络的标准骨架。它最初为医学图像分割设计,却完美契合"去噪"任务的需求。
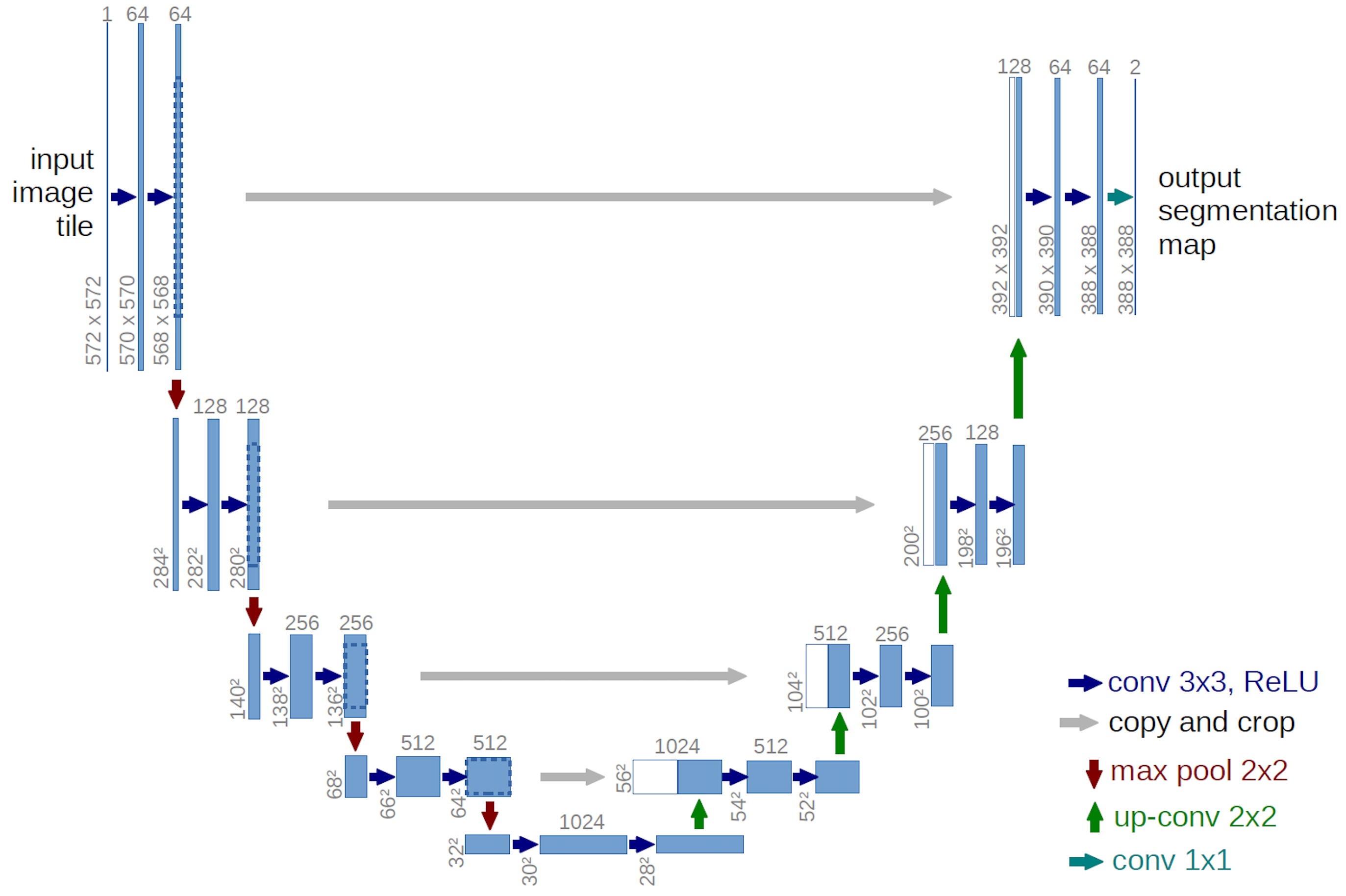
4.1 U-Net 的三大组成部分
(1)编码器(Encoder)--- "看懂整体"
- 通过卷积 + 下采样(如 MaxPooling)逐步缩小特征图;
- 宽高减半,通道数翻倍(64 → 128 → 256 → 512 → 1024);
- 提取高层语义:"这是人脸/猫/风景"。
(2)瓶颈层(Bottleneck)--- "浓缩精华"
- 最小空间尺寸(如 28×28),最大通道数(1024);
- 整合全局上下文信息。
(3)解码器(Decoder)--- "还原细节"
- 通过上采样(转置卷积)逐步恢复分辨率;
- 关键创新:跳跃连接(Skip Connection)
4.2 跳跃连接:U-Net 的灵魂
将编码器各层的特征图,裁剪后拼接到解码器对应层。
为什么需要?
- 编码器下采样会丢失精确位置信息(如边缘、纹理);
- 解码器仅靠高层语义无法精准重建细节;
- 跳跃连接提供"原始草稿",实现语义 + 定位的融合。
举个例子(基于 U-Net 原始论文结构):
- 上采样:将瓶颈层 28×28×1024 → 56×56×512(通过 2×2 转置卷积);
- 裁剪 :从编码器第四层取出 68×68×512 → 中心裁剪为 56×56×512;
- 拼接:与上采样结果 concat → 56×56×1024;
- 后续卷积:融合信息,输出 56×56×512。
📌 裁剪原因:因卷积无 padding,编码器特征图略大于解码器,需对齐尺寸。
4.3 U-Net 在扩散模型中的改造
| 原始 U-Net | 扩散模型中的 U-Net |
|---|---|
| 输入:干净图像 | 输入:带噪图像 x t x_t xt |
| 输出:分割掩码 | 输出:噪声残差 ϵ ^ \hat{\epsilon} ϵ^ |
| 无时间信息 | 加入时间嵌入(Time Embedding) |
| 任务:分割 | 任务:噪声回归(MSE loss) |
时间嵌入如何注入?
- 将时间步 t t t 通过 MLP 或正弦编码转为向量;
- 通过 Adaptive GroupNorm 或 FiLM 注入每个卷积块;
- 网络动态调整行为:
- 早期(t 大):关注大结构("是人脸");
- 晚期(t 小):关注细节("睫毛、皱纹")。
五、扩散模型 vs GAN vs VAE
| 模型 | 核心思路 | 优点 | 缺点 |
|---|---|---|---|
| GAN | 生成器 vs 判别器对抗 | 生成速度快 | 训练不稳定、模式崩溃 |
| VAE | 编码-解码 + 隐空间约束 | 训练稳定 | 生成图像模糊 |
| Diffusion | 逐步去噪 | 高质量、稳定、理论强 | 生成慢(可加速) |
🌟 正因如此,所有主流 AI 绘图工具(Stable Diffusion 等)均采用扩散模型!
六、总结:扩散模型的三大优势
- 生成质量极高:细节丰富,接近真实照片;
- 训练极其稳定:无需调参对抗,损失函数简单;
- 原理优雅统一:将生成问题转化为噪声回归,数学基础坚实。
⚠️ 唯一短板:推理速度慢,但已有多种加速方案(DDIM、LCM、蒸馏等)。
七、结语
扩散模型的本质,不是"凭空创造",而是"从混乱中恢复秩序"。它给 AI 一块"噪声画布",依靠 U-Net 这样的智能去噪器,一步步擦出我们想要的世界。
而 U-Net 的设计哲学------"先看大局,再补细节"------不仅解决了医学图像分割的难题,更成为生成式 AI 的基石。这正是深度学习的魅力:一个为特定任务设计的结构,最终照亮了整个领域。
参考文献 & 延伸阅读
U-Net: Convolutional Networks for Biomedical Image Segmentation