这是一篇结合了 Prompt Engineering(提示工程) 实战技巧与 DeepSeek-R1 模型训练原理 的深度解析文章。这篇文章旨在理清"思维链(CoT)"是如何从一种用户侧的技巧,进化为模型侧的本能的。
从"咒语"到"本能":彻底读懂思维链(CoT)的前世今生
在当今的大模型(LLM)领域,"思维链"(Chain of Thought, CoT)是一个绝对绕不开的核心概念。它既是我们作为用户为了让 AI 变聪明而使用的"提示词技巧",也是像 DeepSeek-R1 这样前沿模型变强的"底层训练逻辑"。
本文将带你从这两个维度------用户视角的 Prompt 编写 与开发者视角的模型训练------全面拆解 CoT 是如何运作的。
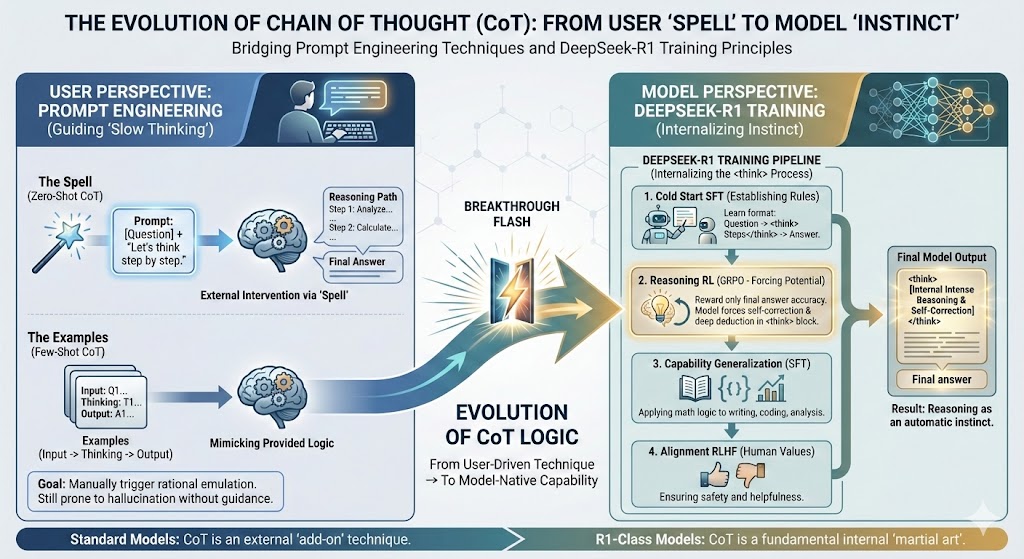
第一部分:用户视角的 CoT ------ 引导 AI "慢思考"的技巧
当我们说"融入 CoT 写 Prompt"时,我们是在通过提示词干预 AI 的推理路径。
1. 什么是 CoT Prompt?
简单来说,就是不只要求 AI 给出一个最终答案,而是要求 AI 把推导、思考、计算的中间过程也写出来。
这就像老师要求学生做数学题时:"写出解题步骤,不要直接填一个数字。"
经典对比:
-
❌ 普通 Prompt(快思考):
问: 罗杰有5个网球,又买了2罐(每罐3个),现在有几个?
AI: 11个。(对于弱模型,这很容易变成瞎猜的幻觉)
-
✅ CoT Prompt(慢思考):
问: 罗杰有5个网球,又买了2罐(每罐3个),现在有几个?请一步步思考。
AI: 罗杰原有 5 个 -> 买了两罐 2 * 3 = 6 个 -> 总共 5+6=11 个。 -> 答案:11个。
2. 实战中的两种玩法
在日常使用 ChatGPT、Claude 或文心一言时,你可以这样用:
-
玩法 A:零样本 CoT (Zero-Shot CoT)
-
核心: 不需要给例子,只需加一句"咒语"。
-
Prompt:
[你的问题]。请一步步思考 / Let's think step by step. -
适用场景: 逻辑分析、复杂决策。
-
-
玩法 B:少样本 CoT (Few-Shot CoT)
-
核心: 喂给 AI 一两个包含"完整推理过程"的示例,让它依样画葫芦。
-
Prompt:
问题:苹果是红色的吗?
思考过程:苹果有红富士(红)、青苹果(绿)等品种。
答案:不一定。
问题:你的新问题
思考过程:
-
适用场景: 需要特定输出格式或极高准确率的任务。
-
第二部分:模型视角的 CoT ------ DeepSeek-R1 如何将技巧内化为"本能"
如果说第一部分是用户在"推"着 AI 思考,那么 DeepSeek-R1 等新一代推理模型的突破在于:它们不再需要你推,思考已经变成了它们的本能。
DeepSeek-R1 通过特殊的训练流程,强行让模型在输出答案前,必须先在后台生成一段被 <think>...</think> 包裹的思考过程。这种能力不是靠背诵来的,而是通过 "冷启动 SFT" + "大规模强化学习(RL)" 练出来的。
以下是 CoT 被"种"进模型大脑的四个阶段:
第一阶段:立规矩(冷启动 SFT)
模型一开始不懂什么是"深度思考",它只懂模仿。
-
做法: 投喂少量高质量的、带有详细步骤的 CoT 数据(如:
问题 -> <think>步骤</think> -> 答案)。 -
目的: 像教小学生一样,先教会模型一种格式规范。此时模型学会了"先写步骤再写答案"的形式,但逻辑未必严密。
第二阶段:逼出潜能(面向推理的强化学习)
这是模型变聪明的关键点。
-
做法: 给模型海量的数学题和代码题,不给过程,只给题目。让模型自己试着写
<think>过程。 -
核心算法: GRPO (Group Relative Policy Optimization)。
-
奖励机制: 只要最后答案对,就给刚才生成的思考过程打高分。
-
顿悟时刻(Aha Moment): 为了拿高分(做对题),模型被迫学会了自我纠错 和反复推演 。它会自发地在
<think>里写出:"...不对,这个公式好像用错了,我重新算一遍..."。这种能力是被算法"逼"出来的。
第三阶段:能力泛化(拒绝采样 SFT)
为了防止模型变成只会做题的"书呆子"(说话生硬),这一步要扩充能力。
-
做法: 让刚才变聪明的模型自己生成几十万条 CoT 数据,并混入写作、翻译等普通任务。
-
目的: 把数学推理中习得的"深度思考能力",泛化到写代码、逻辑分析甚至写文章上。
第四阶段:对齐人类(全场景 RLHF)
- 做法: 最后的微调,确保模型不仅聪明,而且符合人类价值观(不输出有害内容,说话好听)。
第三部分:总结与启示
CoT 的进化论
-
过去(GPT-3 时代): CoT 是用户的外挂技巧。我们需要不断提示"请一步步思考",模型才能勉强跟上逻辑。
-
现在(DeepSeek-R1 时代): CoT 是模型的内功心法。模型如果不经过
<think>区域的高强度推演,它甚至会觉得"不舒服"(预测概率低)。
对我们写 Prompt 有什么影响?
-
对于普通模型: 依然建议你使用"请一步步思考"的技巧,这能显著提升准确率,减少幻觉。
-
对于 R1 类推理模型: 你不需要再刻意强调"请思考",它会自动吐出
<think>内容。你现在看到的那些长长的思考过程,正是模型在后台进行高强度逻辑博弈的具象化展示。
一句话总结:
融入 CoT 写 Prompt,是引导 AI 模仿人类的理性;而将 CoT 融入模型训练,则是让 AI 真正诞生出了类似于人类的推理本能。