在大模型时代,让模型读懂你的私有数据,是几乎所有 AI 应用绕不开的问题。
LlamaIndex,正是为了解决这个问题而生。
一、为什么需要 LlamaIndex?
我们先从一个现实问题说起。
1.1 大模型的"记忆缺陷"
无论是 GPT、Claude 还是 LLaMA,本质上都有几个限制:
- 无法直接访问你的本地文档 / 数据库
- 上下文长度有限
- 模型知识有时间截断
- 直接微调成本极高
这就导致一个常见场景:
👉 "我有一堆 PDF / 飞书文档 / 数据库数据,能不能像 ChatGPT 一样直接问?"
答案是:可以,但不能直接喂给模型。
二、LlamaIndex 是什么?它解决了什么问题?
2.1 一句话定义
LlamaIndex 是一个"连接私有数据与大语言模型的中间层框架"
它的核心目标只有一个:
让 LLM 能高效、可控、可扩展地使用你的数据
2.2 LlamaIndex 在 RAG 中的位置
下面这张图,非常经典地描述了 LlamaIndex 的整体定位(RAG 架构):
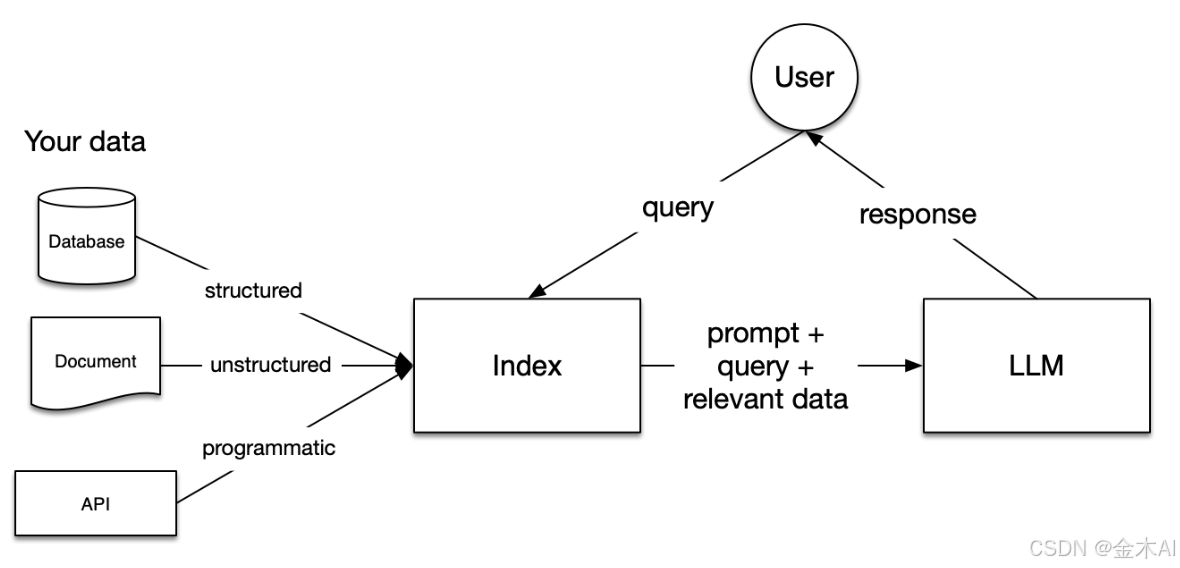
流程拆解:
1.用户输入 Query
2.从 Index(索引)中检索相关数据
3.将「Query + 相关数据」一起送给 LLM
4.LLM 生成最终回答
在 RAG 架构中,Index 表示连接私有数据与大语言模型的检索层,用于对结构化、非结构化以及程序化数据进行索引和查询。
LlamaIndex 正是对这一 Index 层的工程化实现框架,它封装了数据加载、文本切分、向量化、索引构建以及查询等完整流程,使得 RAG 系统可以快速落地。
📌 关键点:
LlamaIndex 有 Python 和 TypeScript 两个版本,Python 版的文档相对更完善。
-
Python 文档地址:https://docs.llamaindex.ai/en/stable/
-
Python API 接口文档:https://docs.llamaindex.ai/en/stable/api_reference/
-
TS 文档地址:https://ts.llamaindex.ai/
-
TS API 接口文档:https://ts.llamaindex.ai/api/
LlamaIndex 是一个开源框架,GitHub 链接:https://github.com/run-llama
三、LlamaIndex 的核心架构全解析 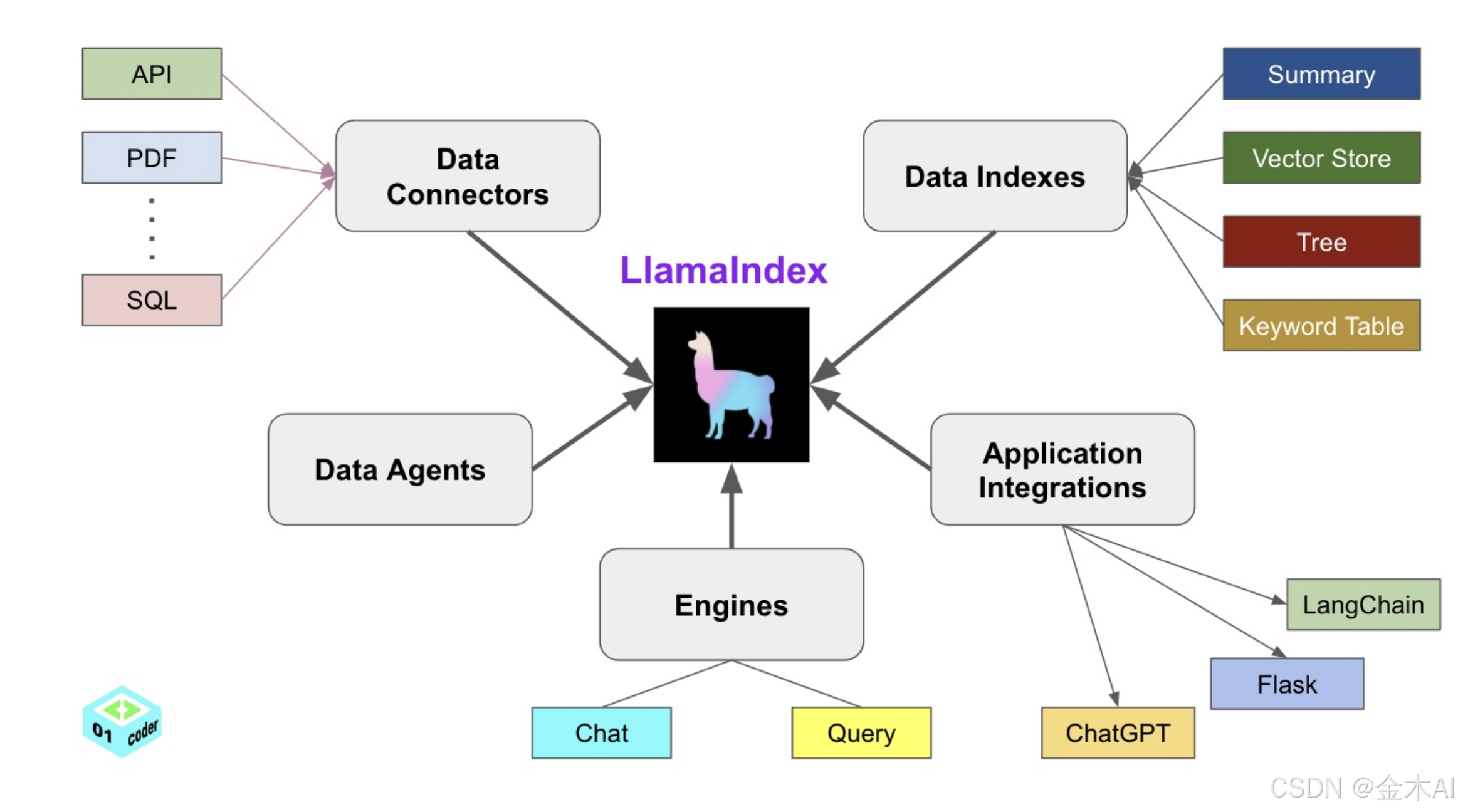
从整体上看,LlamaIndex 是一个围绕"数据 → 索引 → 查询/对话 → 应用集成"构建的 RAG 框架,其核心由以下几部分组成:
3.1 Data Connectors(数据连接层)
LlamaIndex 首先通过 Data Connectors 对接各种数据源,包括:
- API 接口
- PDF 等文档
- SQL 数据库
- 其他结构化或非结构化数据
这一层的作用是统一数据入口,将不同来源的数据加载并标准化,为后续索引构建做好准备。
3.2 Data Indexes(索引层)
数据加载后,会被构建为不同类型的 Index(索引),例如:
- Vector Store:向量索引,用于语义检索(RAG 的核心)
- Keyword Table:关键词索引
- Tree:层级结构索引
- Summary:摘要索引
不同索引结构适用于不同查询场景,LlamaIndex 提供了高度灵活的索引组合能力。
3.3 Engines(查询与对话引擎)
Engines 是连接索引和大模型的核心执行层,主要包括:
- Query Engine:一次性问答查询
- Chat Engine:支持上下文的多轮对话
它负责将用户问题与索引结果整合,并组织成适合 LLM 理解的 Prompt。
3.4 Data Agents(数据代理)
Data Agents 赋予系统一定的"自主决策能力",可以根据问题自动选择:
- 使用哪类索引
- 调用哪些数据源
- 采用何种查询策略
这是 LlamaIndex 向 Agent 化、智能化演进的重要组件。
3.5 Application Integrations(应用集成层)
在最外层,LlamaIndex 可以与多种应用或框架进行集成,例如:
- ChatGPT
- LangChain
- Flask 等 Web 框架
这使得 LlamaIndex 能够方便地嵌入到实际业务系统中,快速构建智能问答或知识检索应用。
四、LlamaIndex 安装与环境准备
4.1 基础安装
pip install llama-index
如果你想做完整 RAG:
pip install llama-index
llama-index-vector-stores-chroma
llama-index-embeddings-openai
llama-index-llms-openai
五、从 0 到 1:一个完整 RAG 实战示例
5.1 应用目标
构建一个:"能读取本地文档并支持自然语言问答的 AI 助手"
python
from dotenv import load_dotenv
import os
import requests
# Load environment variables from .env file
load_dotenv()
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
EMBEDDING_DIM = 384 # all-MiniLM-L6-v2 模型的维度
COLLECTION_NAME = "full_demo"
PATH = "./qdrant_db"
client = QdrantClient(path=PATH)
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.vector_stores.qdrant import QdrantVectorStore
from llama_index.core.node_parser import SentenceSplitter
from llama_index.readers.file import PyMuPDFReader
from llama_index.core import Settings
from llama_index.core import StorageContext
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
import time
# 设置 Tarvos API key 和 URL(从环境变量读取)
TARVOS_API_KEY = os.getenv("TARVOS_API_KEY")
TARVOS_API_URL = os.getenv("TARVOS_API_URL")
TARVOS_MODEL = os.getenv("TARVOS_MODEL", "meta-llama/Meta-Llama-3.1-70B-Instruct")
# 1. 设置本地 embedding 模型(关键!避免调用 OpenAI API)
print("正在加载本地 embedding 模型...")
Settings.embed_model = HuggingFaceEmbedding(
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
# 2. 指定全局文档处理的 Ingestion Pipeline
Settings.transformations = [SentenceSplitter(chunk_size=300, chunk_overlap=100)]
# 3. 加载本地文档
print("正在加载文档...")
documents = SimpleDirectoryReader("./data", file_extractor={".pdf": PyMuPDFReader()}).load_data()
if client.collection_exists(collection_name=COLLECTION_NAME):
client.delete_collection(collection_name=COLLECTION_NAME)
# 4. 创建 collection
print("正在创建向量数据库...")
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(size=EMBEDDING_DIM, distance=Distance.COSINE)
)
# 5. 创建 Vector Store
vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME)
# 6. 指定 Vector Store 的 Storage 用于 index
storage_context = StorageContext.from_defaults(vector_store=vector_store)
print("正在创建索引...")
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
# 7. Tarvos API 问答函数
def ask_tarvos(question, context):
headers = {
"Content-Type": "application/json",
"Authorization": TARVOS_API_KEY,
}
body = {
"model": TARVOS_MODEL,
"messages": [
{"role": "system", "content": "你是一个专业的AI助手,请根据提供的检索内容回答用户问题。如果检索内容与问题无关,请说明无法回答。"},
{"role": "user", "content": f"参考内容:\n{context}\n\n问题:{question}"}
]
}
try:
resp = requests.post(TARVOS_API_URL, json=body, headers=headers)
return resp.json()["choices"][0]["message"]["content"]
except Exception as e:
return f"调用 Tarvos API 失败: {str(e)}"
# 8. 主对话循环
print("\n✅ 系统就绪!开始对话(输入空行退出)\n")
while True:
question = input("User: ")
if question.strip() == "":
break
# 检索 top-k 文档
retriever = index.as_retriever(similarity_top_k=3)
nodes = retriever.retrieve(question)
context = "\n\n".join([n.get_content() for n in nodes])
# 调用 Tarvos API 生成答案
answer = ask_tarvos(question, context)
print(f"AI: {answer}\n")5.2运行结果