MCP server分析
- 1.Introduction
- [2.Evaluation Framework](#2.Evaluation Framework)
- 3.实验结果
- 参考文献
1.Introduction
作者首先构建了一个全面的MCP Server代码仓库数据集:1.从Anthropic的GitHub仓库中收集官方列出的 MCP Server(343个,包括官方和社区的server);2.通过挖掘GitHub,识别出使用官方MCP SDK的其它仓库,并将这些挖掘结果补充到Anthropic的官方列表中(1556个)。这一步收集到1899个MCP server仓库。研究问题包括:
| 研究问题 | 动机 | 发现 | 结论 |
|---|---|---|---|
| RQ - 0:MCP Server的健康度与可持续性如何? | MCP正成为AI应用生态的关键基础设施,因此必须评估其生态是否健康、能否长期持续发展。已有研究表明,开发活跃度(如提交频率、CI/CD 使用)和社区参与度(如贡献者数量、问题响应速度等)是衡量开源项目健康与可持续性的重要指标。 | MCP Server表现出较强的开发活跃度,平均每周5.5次代码提交(传统软件为2.5 次);CI使用率为42.2%(传统为40.3%);中位数贡献者数量为2.0(与传统软件持平);贡献者的社交影响力更高:中位数关注者达129.6 人(传统为37.3);但问题解决速度略慢:中位数需5.6天(传统为4.0 天)。 | 总体来看,MCP 生态在活跃度和社区影响力方面表现良好,具备一定可持续性基础,但响应效率仍有提升空间。 |
| RQ-1:MCP服务器存在哪些安全漏洞? | 已有研究指出,约46%的Python包存在安全漏洞,而一次数据泄露事件平均成本高达450万美元。MCP服务器作为连接大模型与真实系统(如数据库、文件系统、API)的桥梁,一旦被滥用,风险极高------例如"工具投毒"(tool poisoning)可能导致凭证泄露或远程代码执行。 | 1.使用通用漏洞检测工具SonarQube分析发现:7.2%的MCP server存在8类传统安全漏洞,其中最常见的是凭证暴露(3.6%);2.这些漏洞中仅有3类与已知生态系统漏洞重叠;3.但使用专门针对MCP的扫描工具mcp-scan后,又额外发现5.5%的服务器存在"工具投毒"类漏洞; | MCP特有漏洞(如工具投毒)虽比例不高,但危害极大,且现有工具难以发现,需专项研究应对。 |
| RQ-2:MCP服务器是否存在可维护性问题? | code smells和潜在缺陷会显著增加维护成本------成熟项目中高达39%的维护工作用于修复此类问题。作为新兴技术,MCP代码的可维护性尚属未知。 | 1.MCP服务器中的code smell和bug pattern与传统软件高度相似;2. 66%的MCP server包含严重或阻塞性code smell,其中最常见的是高认知复杂度(high cognitive complexity);14.4%的server存在严重或阻塞性 bug;3.研究还构建了一个分类体系:包含10种code smell和9类bug。 | 尽管是新领域,MCP 代码质量并未优于传统软件,长期可能引发高昂维护成本。 |
2.Evaluation Framework
evaluation framework如下
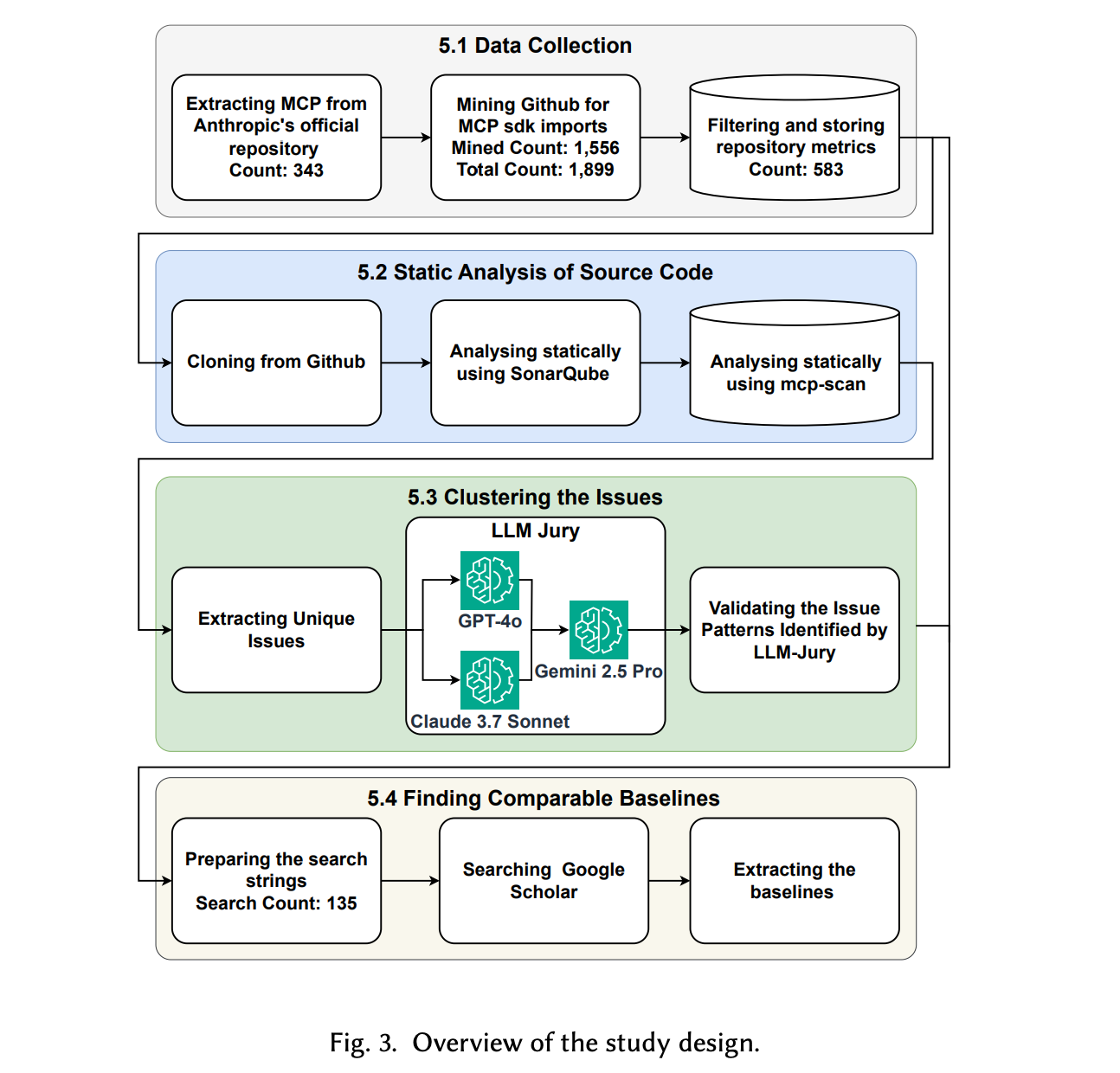
1.Data Collection:
-
(1-1).Anthropic官方Model Context Protocol仓库中维护一份 MCP Server列表,分为两类:官方集成(如 AWS Labs 维护的AWS MCP)和社区服务器(如为DeepSeek R1构建的MCP)。截至 2025年3月19日,共收录88个官方和255个社区项目。作者将每个仓库的名称与GitHub URL存入 Elasticsearch。
-
(1-2).基于SDK导入模式挖掘GitHub MCP server库:为补充官方MCP Server列表,作者通过GitHub Code Search API搜索公开代码中对MCP SDK的引用。对JavaScript/TypeScript仓库使用
@modelcontextprotocol/sdk,Python 使用from mcp.server。共发现 1,715 个相关仓库,剔除已收录的159个后,新增1,556个MCP Server(截至2025年3月20日)。 -
(1-3).过滤toy project:参照previous study 2 ^{2} 2,作者排除star数少于10的仓库,保留583个高质量项目。部分仓库因多语言混用被GitHub标记为主语言非Python/JS/TS,归类为"其它"。
-
(1-4).采集健康与可持续性指标:基于CHAOSS项目及文献,作则选取14项指标评估生态健康度,并通过GitHub REST API自动采集。所有原始与处理后的数据按仓库粒度存入Elasticsearch,确保可追溯与复用。
2.Static Analysis:
-
(2-1).传统工具分析:为检测MCP Server中的安全漏洞、code smell和bug,作者采用广泛使用的开源静态分析工具SonarQube。相比FindBugs和PMD,SonarQube支持 30 多种语言,无需编译字节码,并内置符合MITRE CWE Top 25、OWASP Top 10和PCI DSS等行业安全标准的检测规则,同时擅长识别可维护性问题(如code smell和bug)。针对583个仓库,作者 (i) 从GitHub克隆仓库;(ii) 通过 Docker部署的SonarQube CLI进行扫描;(iii) 利用SonarQube Web API提取问题级元数据;(iv) 将结果存入 Elasticsearch以支持高效查询。单个仓库扫描耗时30秒至5分钟不等,全部分析在一台M3 MacBook Air上于四天内完成。
-
(2-2).MCP专用工具分析:除通用漏洞外,MCP特有风险(如"工具投毒")日益受到关注 3 ^{3} 3。为此,Invariant Labs等机构已推出专用扫描器(如mcp-scan)。然而,该工具需复杂配置:包括部署MCP服务器、设置Docker 环境、配置API密钥等凭证,并安装依赖,过程繁琐耗时。因此,作者采用统计抽样方法,在95%置信水平、10%误差范围内,从583个仓库中随机选取83个代表性样本,并手动使用mcp-scan扫描,以识别潜在的工具投毒实例。
3.Clustering the issues:
-
(3-1).对SonarQube在所有MCP Server中检测出的结果进行分析,聚焦于安全漏洞、code smell和bug三类问题。SonarQube将每条规则违反称为一个issue,并标注其类型(vulnerability / code_smell / bug)和严重性等级。其严重性分为下面5级。作者提取每个问题的元数据(包括类型 、严重性 、规则ID 及描述),并通过去重将违规归纳为三组独立集合------分别对应漏洞、代码坏味道和缺陷。
-
(3-2).随后应用LLM-Jury进行聚类,具体来说通过多个"工作"大模型(worker LLMs)------ Claude-3.7-Sonnet和GPT-4o来独立为每个issue分配聚类标签,依据包括规则名称、描述、影响及编程语言;以及一个"裁判"大模型(judge LLM)Gemini-2.5-Pro来综合各worker的输出及原始信息,最终确定最合适的主题模式。通过此流程,提炼出能表征MCP生态中最常见漏洞、code smell和bug的高层主题模式。
-
(3-3).验证LLM-Jury识别的问题模式。具体来说,从三类问题中各随机抽取 25 个样本(共 75 个);由论文前两位作者作为人工评审员,独立为每个问题打标签;两人通过讨论解决命名或粒度上的分歧;最后,结合两位人工评审与LLM-Jury的结果,计算Fleiss' Kappa一致性系数。结果显示 :三者在漏洞类别上完全一致( κ = 1.0 \kappa = 1.0 κ=1.0),在代码坏味道和缺陷上高度一致( κ = 0.9 \kappa = 0.9 κ=0.9),表明 LLM-Jury 生成的问题模式具有高可信度。
| 等级 | 后果 |
|---|---|
| Blocker | 可能导致崩溃或安全泄露等严重后果,需立即修复; |
| Critical | 对应用有重大影响,应尽快修复; |
| Major | 显著影响应用功能; |
| Minor | 轻微影响; |
| Info | 仅作提示,无实际影响。 |
4.Finding Comparable baseline:针对RQ-0,作者从相关研究中提取健康与可持续性指标的典型值(如中位提交频率);针对RQ-1,作者梳理了PyPI、NPM和IaC等主流生态中漏洞的分类体系与流行程度;针对RQ-2,作者汇总了传统软件领域中code smell与bug的分类及量化prevalence,并借此评估MCP中发现的特定缺陷类型在其他领域的普遍性。
3.实验结果
3.1.RQ-0
作者选择提交频率、贡献者数、Star数、Fork数、项目规模、Issue生命周期、构建活动等指标评估MCP server健康程度,通过GitHub REST API自动采集这些指标。同时从已有研究中收集通用OSS和机器学习(ML)领域的同类指标作为比较基准;若某指标在ML领域无数据,则仅与通用 OSS 对比。进一步将 MCP Server按集成类型(官方 / 社区 / 挖掘所得)分组,分析不同类别在各项指标上的差异:使用 Kruskal-Wallis H检验 判断三组是否存在显著差异;若存在差异,则进行Bonferroni校正后的Mann-Whitney U两两比较;并用Cliff's delta计算效应量,评估差异的实际意义。
发现:在14项关键开发与社区指标中,MCP Server在9项上达到或超过通用开源软件(OSS),表明其生态具有积极的可持续发展趋势。
- 1.开发活跃度更高
| 指标 | 分析 |
|---|---|
| 提交频率 | MCP服务器中位数为5.5次/周,远高于OSS的2.5次/周。 |
| CI采用率 | 42.2%的MCP项目已使用持续集成(CI),略高于OSS(40.3%)和ML(37.2%)更重要的是,MCP项目往往在发布后六个月内就采用CI,而一般OSS通常需一年以上。 |
| 构建表现 | MCP 项目的构建成功率更高、构建时间更短、修复失败构建更快,预示其具备更频繁发布能力,有利于早期项目成长。 |
-
2.社区增长迅猛(经年龄归一化后):尽管 MCP 项目绝对Star和Fork数较低(因协议仅推出 6 个月,而对比项目平均年龄达1.9--6.8年),但按年均增长率计算:MCP项目年均获79 Stars/18 Forks,远超OSS基线的34.7 Stars/7.5 Forks。贡献者的社交影响力(关注者数量)也显著更高,显示更强的社区吸引力。
-
3.不同类型MCP Server的差异,Github挖掘所得的MCP项目比官方列出的社区项目相比 (1).提交数比社区项目高101.4%(中位数44.3 vs 22.0);(2).代码量(LoC)多56%(中位数1445 vs 929),比社区项目多近2.6倍。
MCP生态虽处于早期阶段,但已展现出高强度的开发投入、快速的社区增长和先进的工程实践(如早期采用CI)。特别是由社区自发挖掘出的MCP项目,表现出比官方和传统社区项目更强的活跃度和规模,进一步印证了该生态的活力与可持续发展潜力。
3.2.RQ-1
motivation如下
| 方面 | 关键内容 |
|---|---|
| 背景风险 | (1).46%的Python包和40%的JavaScript包存在已知漏洞;(2).MCP 服务器主要用这两种语言开发,且下载量巨大(每周数百万次) |
| 新兴威胁案例 | (1).攻击者通过恶意NPM包攻击FM驱动的编辑器Cursor(集成MCP客户端);(2).窃取超4,200名用户的凭证,凸显AI工具链安全风险 |
| MCP的高风险角色 | (1).直接访问文件系统、数据库、API等敏感资源; (2).处理API 密钥、用户凭证等机密数据 (3).与关键基础设施紧密耦合,成为高价值攻击目标 |
| 研究空白 | (1).MCP Server实际漏洞分布、类型和严重程度尚无系统研究 (2).现有安全工具是否能有效检测MCP特有漏洞(如"工具投毒")未知 |
| 本研究目标 | (1).量化MCP服务器中漏洞的普遍性与模式 (2).与传统生态(PyPI/NPM)漏洞对比 (3).评估现有检测工具对 MCP 特有风险的覆盖能力 |
研究方法如下
| 步骤 | 方法与目的 |
|---|---|
| 漏洞提取 | 使用SonarQube对MCP Server代码库进行静态分析,聚焦Blocker、Critical、Major、Minor四类严重性漏洞(排除Info级别)。 |
| 模式归纳 | 应用LLM-Jury方法,对检测到的漏洞进行聚类,提炼出高层级的漏洞模式。 |
| 标准化映射 | 将每种漏洞模式映射到最匹配的CWE(Common Weakness Enumeration),依据SonarQube规则定义及官方文档。例如:源码中硬编码 OPENAI_API_KEY → CWE-798(硬编码凭证)。 |
| 风险上下文分析 | 查询CVE数据库,检查每个映射CWE是否关联已知真实攻击事件,以评估漏洞在现实中的潜在危害。 |
| MCP特有漏洞检测 | 使用专用工具mcp-scan对83个代表性样本进行扫描,识别如"工具投毒"等传统工具无法发现的MCP特有漏洞。 |
| 组间差异分析 | 针对三类MCP Server(官方 / 社区 / 挖掘),采用Kruskal-Wallis H检验 + Bonferroni校正的Mann-Whitney U 两两检验,统计比较其漏洞数量分布是否存在显著差异。 |
发现如下
| 类别 | 核心发现 |
|---|---|
| 1. 漏洞类型分布 | (1).凭证暴露 (Credential Exposure)是最常见的漏洞,这点与PyPI的XSS或NPM的恶意包不同。(2).在通过SonarQube识别出的8类漏洞模式中仅2类(认证问题、输入验证不当)在PyPI中常见,与NPM中无重合。3.MCP特有高发漏洞还包括:缺乏访问控制、资源管理不当、传输安全缺陷,这些在其他生态中未被列为top漏洞。 |
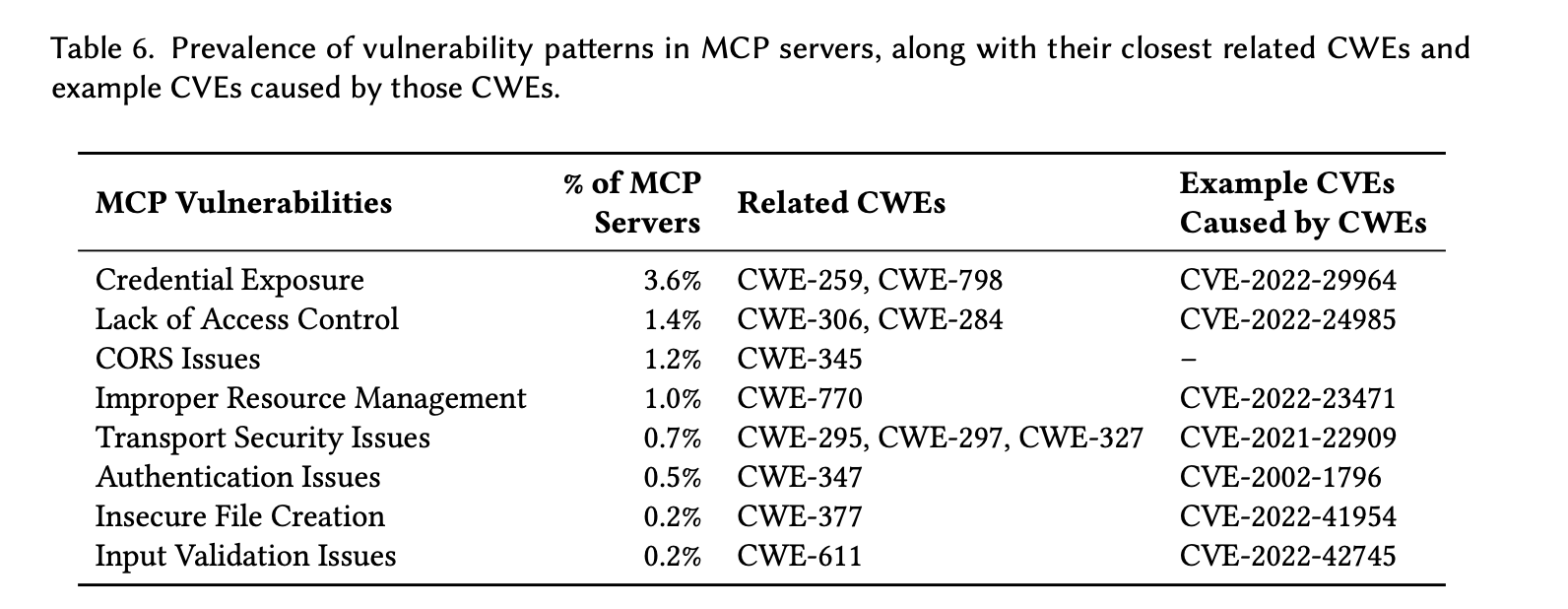
| 2. 漏洞普遍性 | (1).7.2%的MCP仓库 (42/583)含至少一个安全漏洞;其中一半 (≈3.6%)为凭证暴露。(2).共检测到277个漏洞 ,关联13个CWE,多个CWE对应已知CVE(如CVE-2022-29964),说明风险真实且严重。 |
| 3.与传统生态对比 | (1).相比PyPI(46%有漏洞)和NPM(40%依赖含漏洞代码),MCP 漏洞检出率更低 ,但漏洞类型更独特。(2).PyPI已发现119 种 CWE,远多于MCP的13种,反映MCP生态尚处早期,但风险特征不同。 |
| 4. MCP特有漏洞:工具投毒 | 使用专用工具mcp-scan 在73个样本中发现5.5%存在"工具投毒" ,比例高于凭证暴露 。尽管工具尚不成熟(初期仅60/83扫描成功,后经修复增至73),仍能检出高危问题,暗示更多隐藏漏洞未被现有工具覆盖。 |
| 5. 现有工具局限性 | mcp-scan 无法检测深层问题 ,如 apple-notes-mcp 要求 macOS 全盘访问权限 (过度授权); godot-mcp 默认自动批准敏感操作 (如停用项目)。 原因:工具仅依赖运行时反射获取工具描述,不分析源码,难以发现上下文相关安全缺陷。 |
| 6. "纯MCP" vs "衍生MCP" | (1).纯MCP项目 (无遗留代码):漏洞集中于凭证暴露 和传输安全 (如SSL验证绕过)。(2).衍生MCP项目 (MCP作为附加功能):85%漏洞位于 .yaml 等部署文件中,且多出现在多功能系统(如SciPhi-AI/R2R、alibaba/higress等)。表明两类项目需差异化安全治理策略。 |
| 7. 不同集成类型对比 | (1).官方MCP服务器中SonarQube 未检出任何漏洞(中位数=0);(2).社区 & 挖掘类:中位数均为2个漏洞/仓库。与Docker生态类似:官方维护项目安全性显著更高。 |
| 8. 实际泄露案例 | 在社区/挖掘项目中发现泄露的:(1).OpenAI / Gemini API 密钥 (2). Google Cloud 服务账号证书 (3).GitHub Personal Access Tokens 可导致:高额账单、私有仓库泄露、CI/CD 被控 。均属CWE-798(硬编码凭证),已有历史高危CVE关联。 |
找到的一些漏洞案例如下
3.3.RQ2
| 方面 | 内容摘要 |
|---|---|
| 研究动机 | (1).可维护性是AI系统的关键挑战 :2025年报告显示,73%的AI/大数据系统低于行业可维护性基准。(2).高昂成本 :成熟企业每年为单个系统修复可维护性问题平均花费约33.25万美元 。(3). 主要根源 :code smell (如高认知复杂度)与软件缺陷 (bugs),前者显著增加调试时间与错误率,后者占GitHub顶级项目39% 的开发精力 。(4).MCP尤其脆弱:作为新兴范式,其代码多在初期编写阶段引入坏味道,亟需早期评估。 |
| 研究目标 | (1).系统刻画MCP服务器中code smell与bug的类型和普遍程度 ;(2).分析其在不同编程语言 (Python/JS/TS)中的分布差异;(3).为早期生态提供可操作的改进建议,指导未来开发与工具建设。 |
| 对比视角 | 将MCP中发现的坏味道与缺陷模式与PyPI、NPM等传统软件生态进行对比,判断其是否具有领域特殊性。 |
发现
| 维度 | 关键发现 |
|---|---|
| 总体情况 | (1).66% 的MCP服务器 包含至少一个 Critical/Blocker 级别代码坏味道 ;(2).14.4% 的MCP服务器 存在 严重或阻塞性缺陷 (bugs);(3).code smell与缺陷类型在传统软件(Python/JS/Java)中已有先例,表明现有重构与调试技术可迁移应用。 |
| 最常见code smell | 高认知复杂度 (High Cognitive Complexity)最为普遍,出现在59.7% 的 MCP 项目 中,是第二常见坏味道(代码重复)的 近 3 倍;超过阈值(通常为 15)会显著增加理解难度、调试时间和错误率。 |
| code smell分布:按集成类型 | - "github挖掘"类 (mined)MCP Server code smell数量比官方和社区类多 66% (中位数:5 vs 3);可能原因:挖掘类项目规模更大,而代码量与code smell正相关。 |
| code smell分布:按编程语言 | JavaScript MCP 项目code smell最少 (中位数=2),比Python和TypeScript(中位数=4)少约 50%;Python与TypeScript之间无显著差异。 |
| 缺陷(Bugs) | - 共识别 9 类缺陷 ,影响 84 个仓库 (14.4%); - Top 3 缺陷 (数组操作错误、参数不匹配、类型/结构问题)未在Java生态中报告 ,但在 Python/JS 社区已知; - 其余 6 类中有 3 类(异常处理不当、集合误用、对象方法设计问题)与Java缺陷重合。 |
| 缺陷分布:按语言 | 不同语言间缺陷数量无显著差异 (Kruskal-Wallis: 𝑝 = 0.178 𝑝 = 0.178 p=0.178);尽管TypeScript 似更易出现Critical缺陷、Python更多Blocker缺陷,但统计上不显著。 |
| 缺陷分布:按集成类型 | "挖掘"类项目缺陷比社区类多 67%;官方 vs 社区、官方 vs 挖掘均无显著差异;可能原因:挖掘类项目提交更频繁,而高频提交若不规范易引入缺陷。 |
| 实践启示 | 1.MCP可复用现有软件工程中的重构策略 (如提取方法、解耦对象)和调试实践 ;2.需重点关注高认知复杂度 和权限/配置类坏味道;3.对"挖掘"类项目应加强代码审查与自动化质量门禁。 |
参考文献
1.Hasan M M, Li H, Fallahzadeh E, et al. Model context protocol (mcp) at first glance: Studying the security and maintainability of mcp serversJ. arXiv preprint arXiv:2506.13538, 2025.
2.Sampling Projects in GitHub for MSR Studies
3.Vineeth Sai Narajala and Idan Habler. 2025. Enterprise-Grade Security for the Model Context Protocol (MCP): Frameworks and Mitigation Strategies. arXiv preprint arXiv:2504.08623 (2025).