TL;DR
- 场景:ES 排序/聚合/脚本访问字段值时,倒排索引不擅长按"列"读数据
- 结论:Doc Values 是磁盘列式结构(除 text 外多数类型默认开启),用来高效读字段值
- 产出:给出可落地的字段选型、mapping 约束、常见报错定位与修复速查

版本矩阵
| 说明 | 验证状态 | 来源 |
|---|---|---|
| ES doc_values:磁盘列式结构,主要用于排序/聚合/脚本访问字段值 | 是 | 官方文档 |
| keyword 有 doc values;text 默认没有 doc values,聚合/排序需 fielddata 或改用 keyword | 是 | 社区一致结论 |
| 既有索引的 mapping 不能"替换/删除",需要新建索引 + reindex 才能彻底改字段类型/结构 | 部分 | 社区/实践共识 |
| "analyzed strings 不能用 doc values"在旧版本表述为 string/not_analyzed,ES 5+ 已拆分为 text/keyword,不要混用旧术语 | 是 | 历史/版本差异 |
| OpenSearch:doc values 默认对绝大多数字段开启,text 例外(与 ES 认知一致) | 是 | OpenSearch 参考 |
DocValues 机制
Doc Values 是一种以列式存储的索引机制,用于在检索时优化磁盘读取操作。与传统的行式存储不同,Doc Values 将每个字段的所有值按列组织存储,这种结构特别适合分析型查询场景。以下是其核心特点:
- 存储结构对比:
- 反向索引:基于倒排表的结构,主要用于全文检索场景,可以快速查找文档中包含某个词的情况
- Doc Values:采用紧凑的列式存储格式,每个字段的值被连续存储在磁盘上,支持高效的顺序读取
- 性能优势:
- 内存效率:仅需加载查询涉及的列,而非整个文档
- CPU缓存友好:连续存储的列数据能更好利用CPU缓存行
- 压缩率高:同列数据通常具有相似性,可采用更高效的压缩算法
- 典型应用场景:
排序场景:
- 示例:对商品按价格排序时,只需顺序读取price列的Doc Values
- 优势:相比加载完整文档,可减少90%以上的IO操作
聚合场景:
- 支持操作:terms、sum、average、percentiles等
- 实际案例:计算某时间段内订单金额的分布情况
- 性能对比:比使用脚本计算快5-10倍
过滤场景:
- 适用操作:范围过滤(price>100)、精确匹配(status="active")等
- 实现原理:通过bitmap快速筛选符合条件的文档ID
- 特殊优化:对数值类型支持位图索引加速
- 实现细节:
- 默认开启:在Elasticsearch等系统中通常默认启用
- 存储位置:既支持内存映射也支持磁盘持久化
- 更新机制:采用追加写方式,定期合并优化
- 使用建议:
- 适合字段:高基数字段、需要频繁聚合/排序的字段
- 不适合场景:大文本字段(超过几KB)、很少被查询的字段
- 配置参数:可通过"doc_values: false"显式关闭
通过合理使用Doc Values,可以显著提升分析型查询的性能,特别是在处理大数据集时效果更为明显。
为什么要有Doc Values
Elasticsearch之所以搜索这么迅速,归功于它的倒排索引设计,然后它也不是万能的,倒排索引的检索性能是非常快的,但是在字段排序时却不是理想的结构:
shell
Term Doc_1 Doc_2
-------------------------
quick | | X
the | X |
brown | X | X
dog | X |
dogs | | X
fox | X |
foxes | | X
in | | X
jumped | X |
lazy | X | X
leap | | X
over | X | X
summer | | X
the | X |
------------------------如上面的内容中可以看出,它只有词对应doc,但是并不知道每一个doc中的内容,那么如果想排序的话每一个doc都去获取一次文档内容岂不是非常耗时?DocValues的出现使得这个问题迎刃而解。 字段的 doc_values 属性有两个值,true、false,默认是true,即开启。 当 doc_values 为 false 时,无法基于该字段排序、聚合、在脚本中访问字段值。 当 doc_values 为 true 时,ES会增加一个相应的正排索引,这增加的磁盘占用,也会导致索引数据速度慢一些。
Doc Values 是列式存储的,这意味着每个字段值都以列的形式存储在磁盘中,而不是像原始文档那样存储在行中。这种方式有助于优化数据的读取,因为在执行排序或聚合时,Elasticsearch 只需访问与操作相关的字段,而不需要加载整个文档。
每个文档的字段值在索引时被预处理,并以压缩的形式存储为 Doc Values,这些值会以内存映射文件(memory-mapped file)的方式加载到内存中,以便进行快速读取。
Doc Values举例
创建一个索引:
json
PUT /person
{
"mappings" : {
"properties" : {
"name" : {
"type" : "keyword",
"doc_values": true
},
"age" : {
"type" : "integer",
"doc_values": false
}
}
}
}写入相对应的数据:
shell
POST _bulk
{ "index" : { "_index" : "person", "_id" : "1" } }
{ "name" : "明明", "age": 22 }
{ "index" : { "_index" : "person", "_id" : "2" } }
{ "name" : "丽丽", "age": 18 }
{ "index" : { "_index" : "person", "_id" : "3" } }
{ "name" : "媛媛", "age": 19 }执行结果如下图所示:  进行全量查询,确认一下数据的情况:
进行全量查询,确认一下数据的情况:
json
POST /person/_search
{
"query": {
"match_all": {}
},
"sort" : [
{
"name": {
"order": "desc"
}
}
]
}执行结果如下图所示: 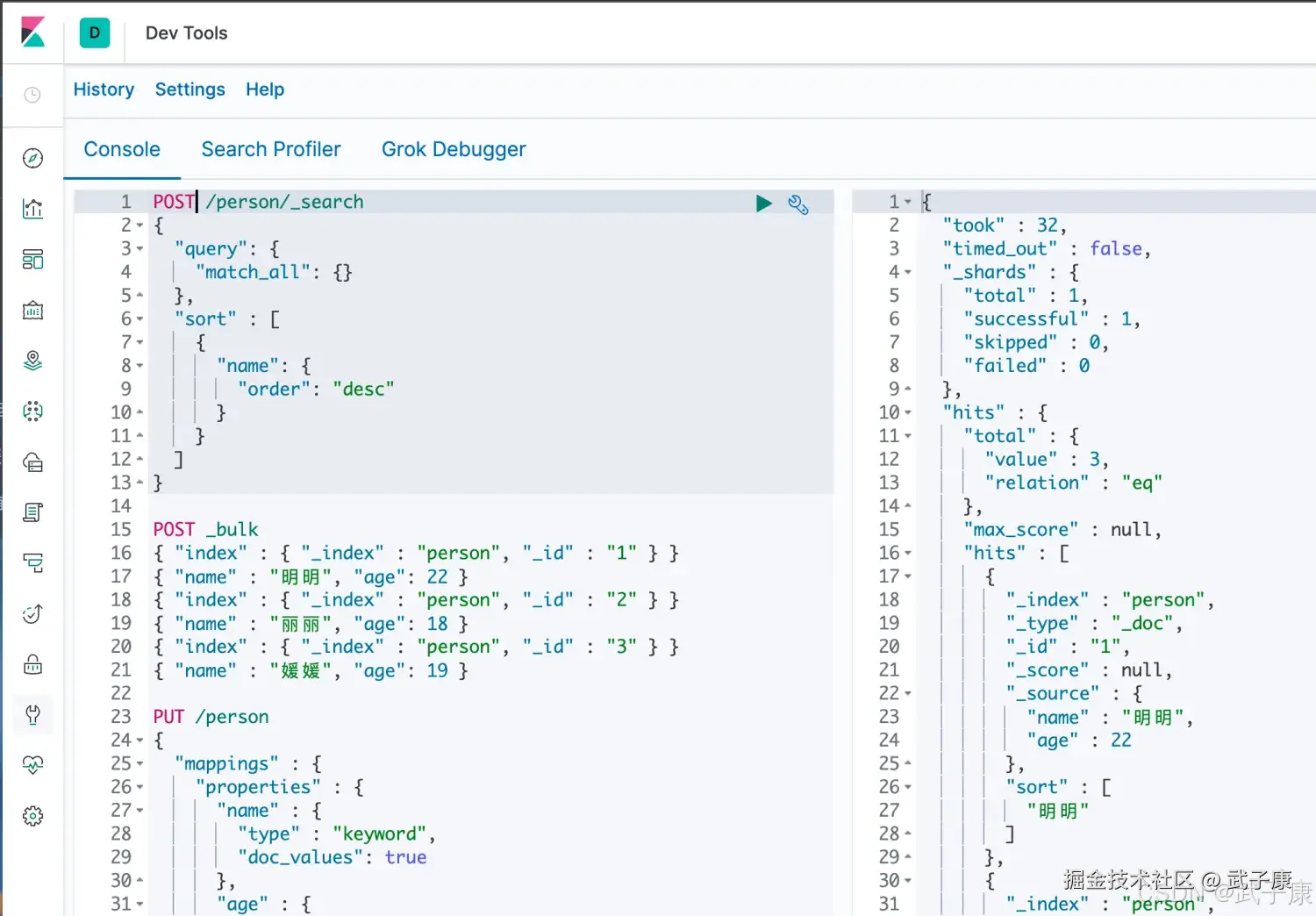
什么是Doc Values
Doc Values 通过转置倒排索引和正排索引两者间的关系来解决这个问题,倒排索引将词项映射到包含它的文档:
shell
Doc Terms
-----------------------------------------------------------------
Doc_1 | brown, dog, fox, jumped, lazy, over, quick, the
Doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer
Doc_3 | dog, dogs, fox, jumped, over, quick, the
-----------------------------------------------------------------当数据被转置后,想要收集到每个文档行,获取所有的词项就非常简单了。
深入理解ES Doc Values
DocValues是Lucene索引机制中的重要组成部分,它与倒排索引同时生成,具有以下特性:
- 生成机制:
- 在索引创建阶段,DocValues会与倒排索引并行构建
- 基于Segment级别生成,每个Segment都包含自己独立的DocValues数据
- 生成后是不可变的,与倒排索引保持一致性
- 存储特性:
- 采用高效的序列化方式将数据结构持久化到磁盘
- 存储格式经过优化,支持快速随机访问和顺序扫描
- 与倒排索引共享相同的Segment合并策略
- 内存管理优势:
- 利用操作系统文件缓存机制,而非JVM堆内存
- 当数据量小于系统可用内存时(workingset < RAM):
- 操作系统会自动将频繁访问的DocValues保留在内存中
- 实现接近内存数据库的访问速度
- 典型场景:过滤、排序、聚合等操作能获得极快响应
- 大容量处理能力:
- 当数据量超过内存容量时(workingset >> RAM):
- 操作系统会自动将不活跃数据换出到磁盘
- 虽然访问速度有所下降,但避免了OOM风险
- 典型场景:处理数十亿文档时仍能保持稳定性能
- 应用场景示例:
- 电商平台中百万级商品的价格排序
- 日志分析系统中的时间范围过滤
- 大数据分析中的分组聚合计算
这种设计使DocValues在保持高性能的同时,也能处理远超物理内存容量的数据集,为大规模数据应用提供了可靠的底层支持。
DocValues 压缩
从广义来说,DocValues本质上是一个序列化的列式存储,这个结构非常适用于聚合、排序、脚本等操作。而且,这种存储方式非常的便于压缩,特别是数字类型,这样可以减少磁盘空间并且提高访问速度。 下面我们看一组数字类型的DocValues:
shell
Doc Terms
-----------------------------------------------------------------
Doc_1 | 100
Doc_2 | 1000
Doc_3 | 1500
Doc_4 | 1200
Doc_5 | 300
Doc_6 | 1900
Doc_7 | 4200
-----------------------------------------------------------------你会注意到这里每个数字都是100的倍数,DocValues会检测一个段里面的所有数值,并使用一个最大公约数,方便做进一步的数据压缩,我们可以对每个数字都除以100,然后得到:1,10,15,12,3,19,42。现在这些数字变小了,只需要很少的位就可以存储下,也减少了磁盘存放的大小。
DocValues在压缩过程中使用如下技巧,它会依次检测以下压缩模式:
- 如果所有的数值各不相同(或缺失),设置一个标记并记录这些值
- 如果这些值小于256,将使用一个简单的编码表
- 如果这些值大于256,检测是否存在一个最大公约数
- 如果没有存在最大公约数,从最小的数值开始,统一计算偏移量进行编码 当然如果存储String类型,其一样可以通过顺序表对String类型进行数字编码,然后再把数字类型构建DocValues。
禁用 Doc Values
DocValues 默认对所有字段启动,除了 analyzed strings。也就是说所有的数字、地理坐标、日期、IP和不分析(not_analyzed)字符类型都会默认开启。 analyzed strings暂时还不能使用 DocValues,是因为经过分析以后得文本会生成大量的Token,这样非常影响性能。 虽然DocValues非常好用,但是如果你存储的数据确实不需要这个特性,就不如禁用它,这样不仅节省磁盘空间,也许会提升索引的速度。 要禁用DocValues,在字段的映射mapping设置doc_values:false即可。例如,这里我们创建了一个新的索引,字段 session_id禁用了DocValues:
json
DELETE /my_index
{
"mappings": {
"properties": {
"session_id": {
"type": "keyword",
"doc_values": false
}
}
}
}通过设置 doc_values:false,这个字段将不能被用于聚合、排序以及脚本操作
带来的优势
- 减少内存使用:由于 Doc Values 将字段值存储在磁盘上并在需要时读取,因此相比内存中保持字段值的方式(例如 fielddata),它极大地减少了内存的使用。
- 高效的磁盘读取:Doc Values 的列式存储意味着在执行排序或聚合操作时,Elasticsearch 可以只加载所需的字段值,而不必加载整个文档。
- 提高排序和聚合的性能:对于经常需要排序或聚合的字段,Doc Values 可以显著提高性能,因为它优化了读取路径。
使用场景
- 排序:例如,用户需要根据时间戳排序查询结果,Doc Values 会提供优化的列式存储,直接从磁盘读取时间戳的值进行排序,而不需要加载整个文档。
- 聚合:在执行例如统计某个字段的平均值、最大值或分布情况时,Doc Values 可以极大地提高查询的响应速度,因为只需读取相关字段即可。
- 范围查询:例如查找价格在一定范围内的文档时,Doc Values 允许快速扫描价格字段而不涉及文档的其他内容。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
sort/terms agg 报:Fielddata is disabled on text fields |
在 text 字段上做聚合/排序;text 默认无 doc values |
GET index/_mapping 看字段类型是否为 text,是否存在 xxx.keyword |
查询改用 xxx.keyword;或显式 fielddata=true(评估堆内存与热度);长期方案:建新索引用 text + keyword 多字段 |
按字段排序/聚合失败,提示该字段不支持 doc values |
字段类型不支持或被设置 doc_values:false |
mapping 中查 doc_values 与字段类型 |
对需要排序/聚合/脚本的字段保持 doc_values:true(可省略默认);对不需要分析能力的字符串用 keyword |
PUT mapping 后发现"没生效/改不掉/删不掉字段" |
ES mapping 不能替换或移除既有字段定义 |
看 PUT _mapping 返回与实际 mapping 对比;检查是否试图修改已有字段参数 |
走"新建索引 + 正确 mapping + reindex + 切别名"的迁移路径;不要期待在线覆盖式改 mapping |
照抄示例用 DELETE /index 携带 body 设置 mapping,执行报错 |
DELETE 用于删索引,不是建 mapping;示例请求方法不匹配 |
回看请求方法与 API:是否把建索引/建 mapping 写成 DELETE |
创建索引用 PUT /index {mappings...};更新 mapping 用 PUT /index/_mapping {properties...}(但不保证可改已有字段) |
doc_values 关闭后,磁盘省了但查询/脚本功能缺失 |
关闭 doc values 会直接丢失排序/聚合/脚本取值能力 |
mapping 检查 doc_values:false;复现:sort/agg/script 立刻失败 |
对"只写入不分析"的字段才关;若线上已关且必须恢复,通常需要新索引重建(依赖具体字段与版本限制) |
| 聚合/排序延迟抖动,CPU/IO 异常 | working set 大、冷热不均;把 text 开 fielddata 导致堆压力 |
看 JVM 堆、GC、热字段;确认是否启用 fielddata |
优先用 doc values(keyword/numeric/date);避免在 text 上启 fielddata;必要时做字段降维/分桶/预聚合 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-196 消息队列选型:RabbitMQ vs RocketMQ vs Kafka MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解