Yolo 系列因为考虑到某些算子在NPU上的效率不高,故在 RKNN 上都有独特的处理方法,比如 Yolov5 中将3个检测头独立拆分出来,使用CPU完成这部分后处理;Yolov8中,则将DFL模块以及检测头拆分出来等;
相关拆分方法以及拆分后的后处理代码在 RK 官方的 Model zoo 里都有,本文主要是博主心血来潮,结合代码具体剖析一下拆分后的后处理实现。正所谓"知其然知其所以然",通过Yolov5系列的拆分以及剖析,其余系列当然手到擒来,而不是仅仅局限于会用官方demo。
以下内容为个人浅薄的理解,如果问题,欢迎各位大佬指正!
1. Yolov5 基础
Yolov5 基础这一块,网上有很多现成的讲解,本文不做赘述,只简单提及一下
1.1 原后处理流程(部分)
Yolov5 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图,将三个不同尺度的类别预测分支、bbox 预测分支和 obj 预测分支(对象置信度预测分支)进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支、bbox 预测分支和 obj 预测分支的 shape 分别为 (b, 3x80x80+3x40x40+3x20x20, 80)=(b,25200,80),(b,25200,4),(b,25200,1)
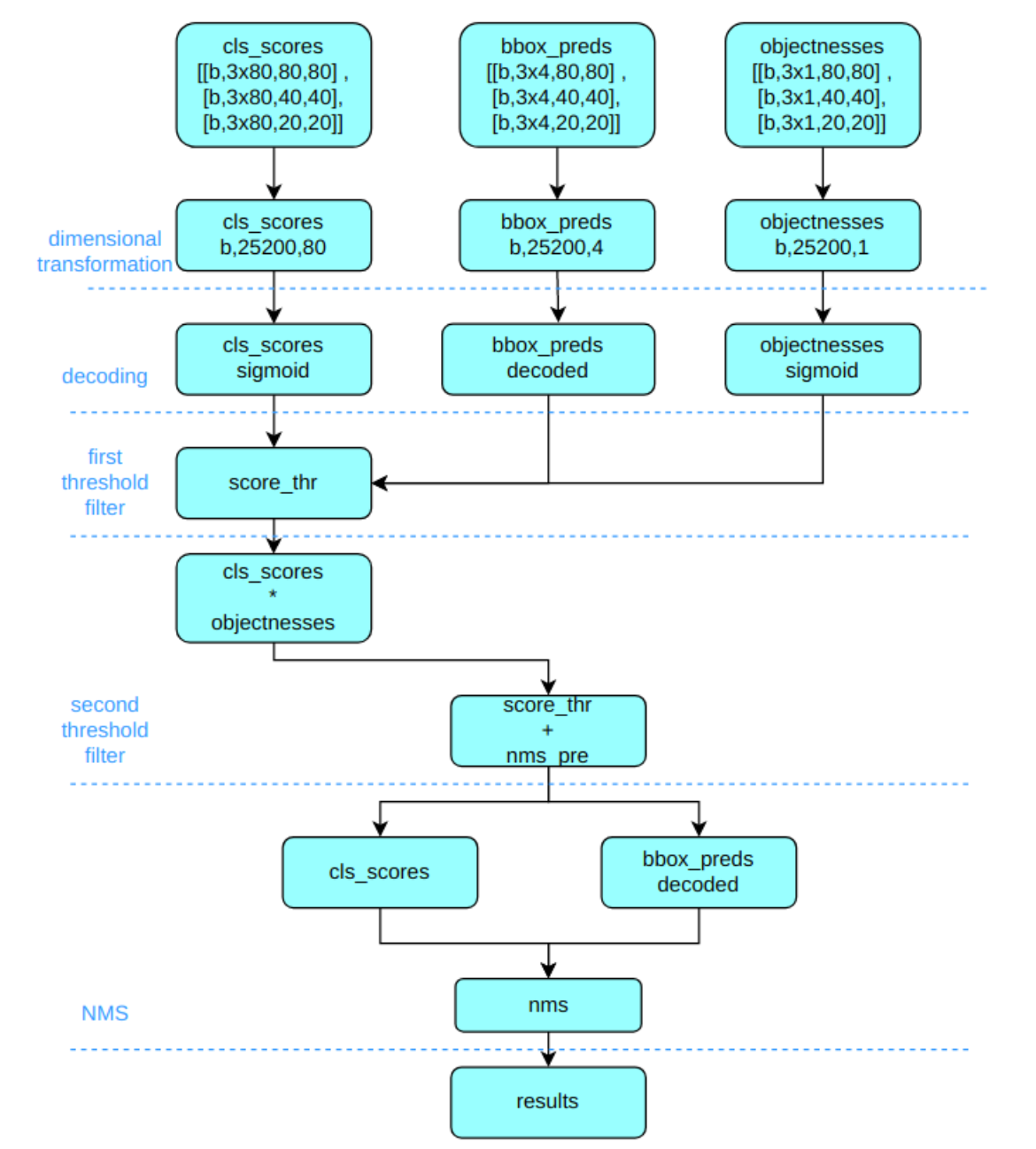
1.2 RKNN后处理流程
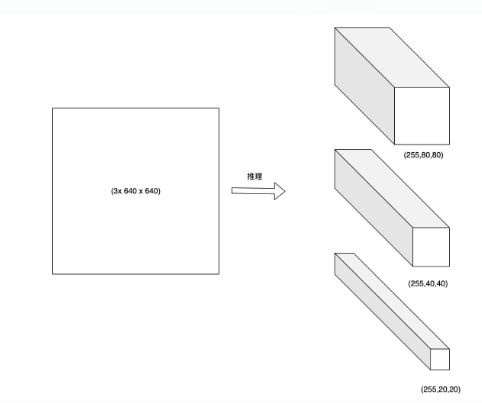
原流程中,将每个分支下的所有尺度的特征图进行了融合,而在RKNN流程中,我们不进行此操作,以 1x3x640x640 输入为例,模型推理后会得到三个检测头,分别是1x255x80x80, 1x255x40x40, 1x255x20x20 , 其中 255 = 3x80 + 3x4 + 3x1, 其中 3 代表 3个 anchor,80代表类别得分,1代表目标置信度。实际操作中,据目标置信度判断有无目标后,再根据别得分寻找当前grid得分最高的类。
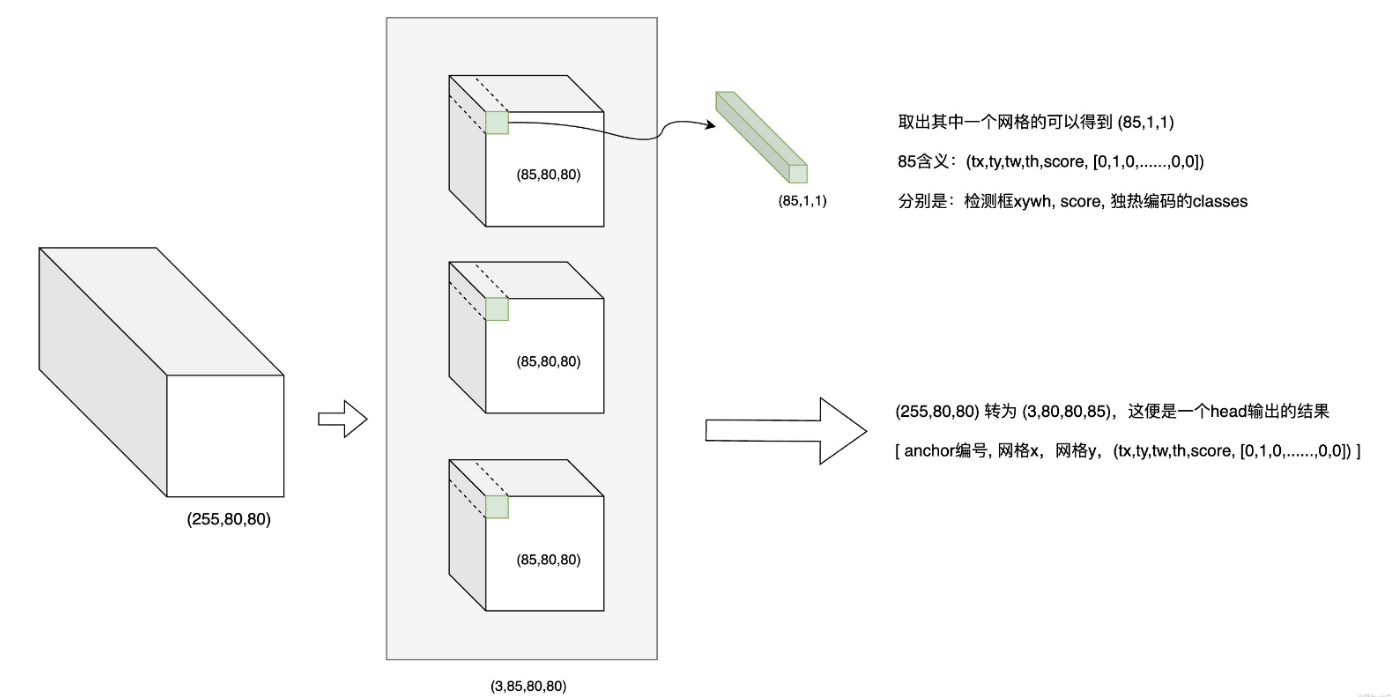
由于 Yolov5 中采用的是 anchoer based 的方式,每个网格上有 3 个 anchor。以检测头(255, 80, 80)为例,可以将其拆分为 3 个 tensor, 每个 tensor 的大小为 (85, 80, 80),即每个 anchor 在每个网格(grid)上有 85 个输出;
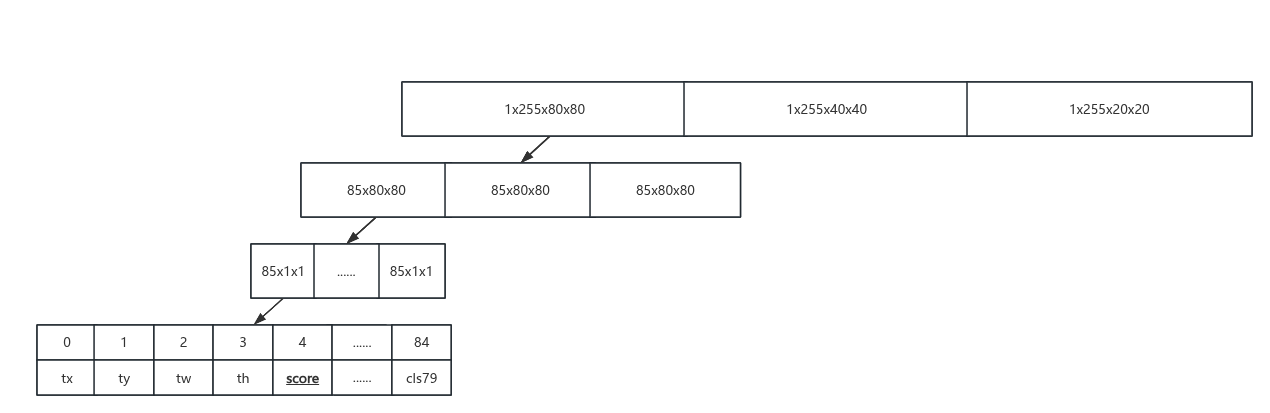
取出其中的一个网格,得到(85, 1, 1),其中85代表的是tx, ty, tw, th, score, \[0, 1, 0,......,0,0],分识别检测框的 x,y,w,h,obj_socre,classes_score。(255, 80, 80) 转为 (3, 80, 80, 85) 这便是一个 head 输出的结果:anchor编号, 网格x, 网格y, (tx, ty, tw, th, score, \[0, 1, 0,......,0,0)]
2. 后处理代码实现
前文已经提到"每个 anchor 在每个网格上有 85 个输出",在85x80x80这个立方体上,85是纵向深度,即如果以85进行再次切隔,可以得到85个面,第一个面是80个网格对应的tx信息,第二个面是80个网格对应的ty信息,第5个面是80个80个网格对应的预测结果信息,第6个面是80个网格对应的类别1的得分信息,第85个面是80个网格对应的类别80的预测信息。将其展开到一纬上,访问时就需要加上偏移量。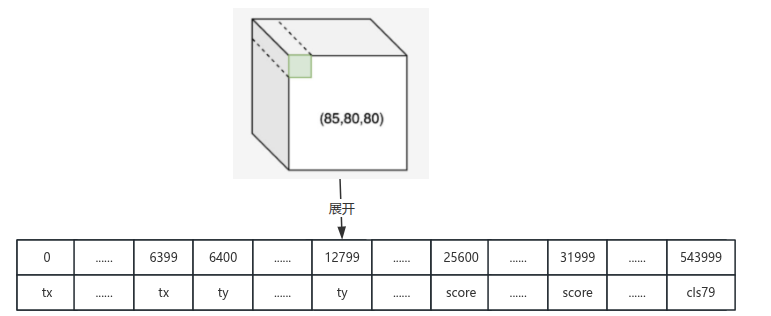
因此,我们可以写出如下后处理代码(无法直接使用,仅供参考):
cpp
// 80 个类
define CLASS_NUM = 80
// 5 代表 tx、 ty、 tw、 th、 cls_score
define PROP_BOX_SIZE = 5 + CLASS_NUM
// 以 80x80特征图为例,此处的 grid_h = grid_w = 80
int grid_len = grid_h * grid_w;
// 分别存储坐标,最终得分,类别id
std::vector<float> &boxes;
std::vector<float> &objProbs;
std::vector<int> &classId
// 3 个检测头
for (int head_num = 0; head_num < 3; head_num++) {
// 3 个 anchor
for (int anchor_num = 0; anchor_num < 3; anchor_num++) {
// grid h 坐标
for (int grid_h_id = 0; grid_h_id < grid_h; grid_h_id++) {
// grid w 坐标
for (int grid_w_id = 0; grid_w_id < grid_w; grid_w_id++) {
// 每个 grid 对应的 obj score, 此处加4是因为前4个是坐标,第5个才是得分
// 乘 grid_len 是前文提到,每一个面代表的是85中的同一类别的结果
float box_confidence = input[(PROP_BOX_SIZE * head_num + 4) * grid_len + grid_h_id * grid_w + grid_w_id];
if (box_confidence >= threshold) {
// 每个grid的偏移
int offset = (PROP_BOX_SIZE * head_num) * grid_len + grid_h_id * grid_w + grid_w_id;
// 此处假设 input 是 rknn 推理后的输出
float *in_ptr = input[head_num] + offset;
// 减0.5 为了将坐标从中心点还原到左上角(yolov5训练时坐标是以grid中心为基准的)
float box_x = *in_ptr * 2.0 - 0.5;
float box_y = in_ptr[grid_len] * 2.0 - 0.5;
float box_w = in_ptr[2 * grid_len] * 2.0;
float box_h = in_ptr[3 * grid_len] * 2.0;
// 坐标由特征图大小还原到原图大小
box_x = (box_x + grid_w_id) * (float)stride;
box_y = (box_y + grid_h_id) * (float)stride;
box_w = box_w * box_w * (float)anchor[a * 2];
box_h = box_h * box_h * (float)anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
// 在单个 anchor 单个 grid cell 内寻找最大类别
float maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k) {
// 5 + k 是因为前5个是基本信息,第6个才是类别得分
float prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs) {
maxClassId = k;
maxClassProbs = prob;
}
}
// maxClassProbs * box_confidence 是该类最终得分
if (maxClassProbs > threshold) {
objProbs.push_back(maxClassProbs * box_confidence);
classId.push_back(maxClassId);
validCount++;
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
}
}
}
}
}
}经过以上后处理步骤,已经得到了模型的推理输出结果,接下来只要对结果进行排序以及NMS去除重复框,还原到模型输入尺寸等操作,就可以得到最终输出,这一部分比较通俗易懂且 RK 官方的 Model zoo 也有成熟的代码,此处不做赘述。