前言
最近翻阅了50篇vla+RL的工作,很多我博客内已经解读过,很多 我暂时还无意解读,除了本文要介绍的PLD 除外
本文,特地解读下该PLD工作
第一部分 自我改进的VLA:通过残差强化学习进行数据生成的模型
1.1 引言与相关工作
1.1.1 引言
如原论文所述,采集高质量的机器人示范既昂贵又耗费人力,使得大规模数据集更加难以获取
即便能够获得这类数据,它们也往往是通过与最终部署的 VLA 策略解耦的远程操作流水线采集的,从而在覆盖范围上留下关键空白:人工操作员必须手动预判并纠正故障模式,但他们给出的示范很少真正反映策略在部署时会遇到的真实状态分布
因此,尽管 SFT 能够可靠地提升其训练任务上的性能,业界对于这些收益能否、以及在多大程度上能够迁移到新的任务和环境上仍缺乏充分理解
- 这些挑战引出了以下问题:VLA 模型能否在仅需极少人力投入的情况下,利用由 RL 甄选的数据来自我提升?
具体来说,这种自策划的数据训练,能否在分布内和分布外场景中,都达到或超越基于人类专家(oracle)遥操作数据进行SFT微调的效果? - 作者的核心观察是,数据收集不应与基础策略相互独立:负责收集数据的策略与通才模型必须相互交互,这样一来,探索过程才能利用通才模型的先验知识,且所收集的数据能够与其轨迹分布保持一致
- 一种自然而然的方式是在实现这一想法的一种方式是使用强化学习(RL)来获取面向特定任务的专家,以指导数据收集。然而,在这一设定下应用RL会受到两个关键挑战的阻碍
其一,语言条件操控任务中的稀疏奖励信号会导致RL不稳定且样本效率低下
说白了,泛化性会有限
对此,来自的研究者提出了 PLD,这是一条包含三个阶段的后训练流水线
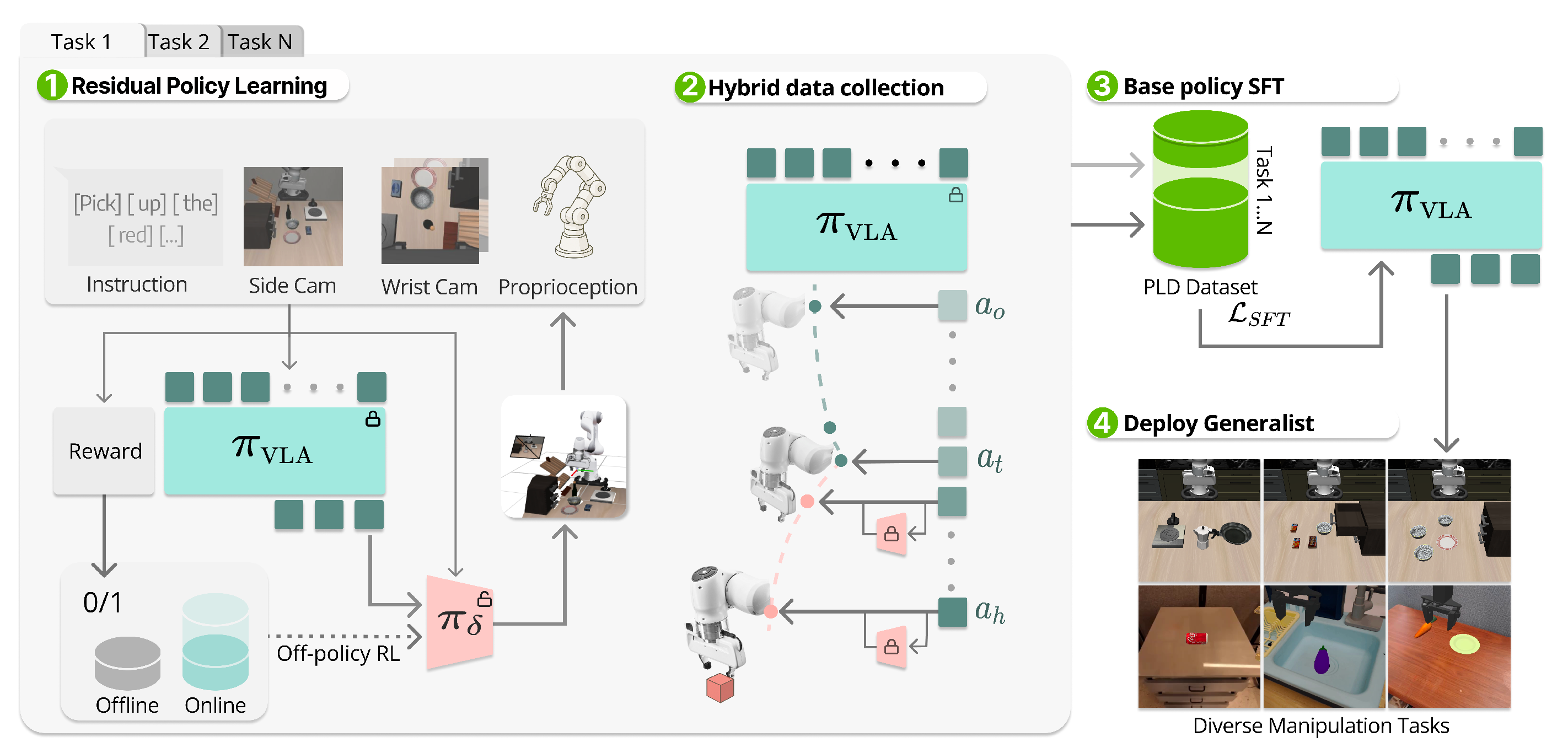
- 阶段1:在线专家获取
作者冻结 VLA 主干网络,并通过样本效率高的离线策略 RL(off-policy RL)为多个任务训练若干轻量级残差 actor,使它们能够在任意状态"接管"基础策略,并在任务上取得超过 99% 的成功率 - 阶段 2:自动数据收集
作者提出一种混合 rollout 方案,使残差接管更偏向于基础模型经常访问的状态,从而在捕获恢复行为的同时缓解分布偏移 - 阶段 3:监督微调
通过 SFT 将为多个任务收集的数据蒸馏回基础模型中,该过程与 VLA 架构无关,同时支持 flow-matching 和 auto regressiveaction head(Black et al., 2024; Kim et al., 2024)
借助 PLD,可以通过 VLA 引导的探索,高效获取面向特定任务的 RL 专家。随后,VLA 利用 PLD 数据得到进一步提升,在 LIBERO 基准上实现了超过 99% 的性能
1.1.2 相关工作
// 待更
1.1.3 预备知识:任务形式化、有监督微调、基于目标的强化学习(Goal-Conditioned RL)
首先,对于任务形式化而言
作者研究在稀疏二元奖励条件下、使用视觉-语言-动作(VLA)模型作为基础策略类别的语言条件操纵任务
-
假设一个具有时间跨度
令策略以
其中 -
与近期VLA 模型一致,
i) 用于连续控制的扩散头
ii) 流式动作头(Ghosh et al., 2024; Black et al., 2024)
(iii) 用于自回归解码的离散动作分词器(Kim et al.,2024; Pertsch et al.,2025)最后,通过调节
其次,对于有监督微调而言
-
给定一个VLA 策略和一个演示数据集
-
令
在当代VLA 系统中,损失的具体形式依赖于动作头的架构
自回归/token 动作头(Kim et al., 2024; Pertsch et al., 2025)通过对动作token
-
随着近期工作通过动作分块与并行解码提升效率,以及通过由
在推理时实现迭代采样(Ghosh et al., 2024; Chi et al., 2024)。Flow-matching 头部学习一个连续的速度场,将先验运输到动作分布中,使用
在这些头部中,SFT 仍然是使用适量标注机器人数据将通用策略专门化到新的具身形式和任务上的标准机制(Kim et al., 2024; 2025)
最后,对于基于目标的强化学习(Goal-Conditioned RL)
作者将连续控制建模为一个MDP
- 其中状态空间为S ,动作空间为A ,转移动态为
- 在目标条件设定中,每个任务由从
此时奖励变为依赖目标的
策略为 - 将GCRL 视为在
在无限时域设定下,RL 的目标是
在本文中,作者考虑稀疏二元奖励设置,即,是通过关于目标相关表征
、度量
以及容差
的成功谓词来定义的
1.2 PLD的完整方法论
尽管近期工作探索对大型 VLA 进行直接的 RL 微调(Mark et al., 2024; Dong et al., 2025b),此类范式即便只用于单任务微调也可能极其耗费资源:例如,在 batch size 为 8 的设置下,OpenVLA-OFT 在进行 LIBERO 训练时每块 GPU 需要约 62.5 GB 显存(Kim et al., 2025)
与此同时,这些方法在异构设置下能否平滑扩展到多任务微调仍不明确
因此,作者选择采用一个解耦式流水线
- 冻结基础策略
- 然后,通过在预设的"基础策略探测"步数之后让该残差策略"接管"控制来收集专家数据
- 最后,通过 SFT 将这些技能蒸馏回基础模型,并将该通用模型部署到多样化的操作任务上。PLD 的整体概览如图 3 所示
1.2.1 通过策略先验热启动实现数据高效强化学习
在先前利用先验数据实现样本高效RL 的成功工作基础上(Ball et al., 2023)
RLPD的介绍,详见此文《RLPD------利用离线数据实现高效的在线RL:不进行离线RL预训练,直接应用离策略方法SAC,在线学习时对称采样离线数据》
RLPD『Ball等,2023,即********Efficient online reinforcement learning with offline data******,相当于 利用离线数据实现高效的在线RL,即Online RL with Offline Data 』,之所以选择它,是因为其样本效率高,且能够融合先验数据
- 该工作关注的是,是否可以在在线学习时,直接应用现有的离策略方法以充分利用离线数据,作者++从头开始在线强化学习,同时将离线数据包含++在 ++回放缓冲区++中,从而展示了online off-policy RL algorithms利用离线数据进行学习时表现出极高的效率
- 且在每一步训练中,RLPD 在先验(离线)数据和on-policy数据 之间等概率采样,以形成一个训练批次「Song等,2023------Hybrid RL: Using both offline and online data can make RL efficient」
即"对称采样",即每个批次有50%的数据来自(在线)回放缓冲区,另外50%来自离线数据缓冲区「We call this 'symmetric sampling', whereby for each batch we sample 50% of the data from our replay buffer, and the remaining 50% fromthe offline data buffer」
作者考虑一个off-policy actor-critic 框架,并为离线和在线经验回放分别维护两个独立的缓冲区
-
首先用来自基础策略
在训练过程中,离线和在线经验将被对称地回放;例如,小批量数据由两个缓冲区中数量相等的样本组成,从而确保价值函数持续在高价值的状态-动作对上进行训练
-
在实践中,作者++训练一个针对特定任务的残差动作模块
为调节探索并避免在初始阶段与
这样设计有两点原因:
相较之下,残差高斯策略可以通过任意现成的 off-policy 强化学习算法轻松训练与
-
为了稳定离策略学习并减轻遗忘,作者引入一个预热阶段,在该阶段仅使用
同时,Q 函数通过诸如 Cal-QL(Nakamotoet al., 2024)之类的保守目标进行初始化
重要的是,作者不会在策略损失中显式施加行为约束,从而使得到的专家策略
// 待更