一、引言
1.1 研究背景与意义
随着 3D 数据集的快速扩充和 3D 场景理解需求的日益增长,3D 计算机视觉领域的各类任务(如目标检测、语义分割、实例分割等)受到了学术界和工业界的广泛关注。其中,3D 实例分割作为一项基础性且具有挑战性的任务,要求同时识别点云中每个物体的类别并勾勒出其独立的掩码,在自动驾驶、机器人导航、室内场景重建等实际应用中发挥着关键作用。
当前主流的 3D 实例分割方法大多依赖数据驱动的深度学习模型,这类方法虽然取得了令人瞩目的性能,但往往需要海量的训练数据和密集的点级人工标注。然而,点级全监督实例标注的成本极高 ------ 在 ScanNet 数据集中,标注一个场景的点级实例标签平均需要 22.3 分钟,而标注一个 3D 边界框仅需 1.93 分钟。因此,边界框标注凭借其能提供丰富的实例级信息且标注成本合理的优势,成为弱监督 3D 实例分割中一种极具吸引力的标注方式。
原文链接:Sketchy Bounding-box Supervision for 3D Instance Segmentation
代码链接:dengq7/Sketchy-3DIS
沐小含持续分享前沿算法论文,欢迎关注...
1.2 现有问题
尽管基于边界框监督的弱监督 3D 实例分割方法已取得一定进展,但这些方法普遍依赖准确且紧凑的边界框标注。在实际应用场景中,由于人工标注的主观性、场景复杂度等因素,获得完全准确的边界框往往十分困难。标注的边界框通常会存在缩放、平移、旋转等偏差,这类不准确的边界框被称为 "草图边界框(sketchy bounding box)"。如图 1 (a) 所示,草图边界框与准确边界框存在明显差异,而图 1 (b) 的实验结果表明,现有方法(如 GaPro)在草图边界框监督下性能会显著下降,这一问题严重限制了弱监督 3D 实例分割方法在实际场景中的应用。
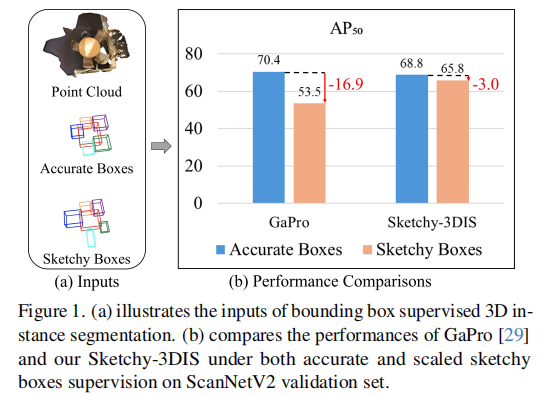
图 1. (a) 展示了边界框监督的 3D 实例分割的输入;(b) 对比了 GaPro 29 和本文提出的 Sketchy-3DIS 在 ScanNetV2 验证集上,分别在准确边界框和缩放草图边界框监督下的性能。
1.3 本文贡献
为解决草图边界框监督下的弱监督 3D 实例分割问题,本文提出了一种新颖的框架 Sketchy-3DIS,主要贡献如下:
- 首次探索将草图边界框标注用于 3D 实例分割任务,允许使用具有噪声容忍性、与实例大小无关的 3D 边界框进行训练,突破了现有方法对准确边界框的依赖。
- 提出了一种弱监督 3D 实例分割框架,该框架包含自适应框到点伪标签生成器(adaptive box-to-point pseudo labeler)和粗到精实例分割器(coarse-to-fine instance segmentator),通过两者的联合训练实现高性能分割。
- 在 ScanNetV2 和 S3DIS 两个主流数据集上,Sketchy-3DIS 在草图边界框监督下取得了领先的性能,甚至超过了部分全监督方法,验证了其有效性和泛化能力。
二、相关工作
2.1 全监督 3D 实例分割
现有全监督 3D 实例分割方法主要可分为三类:
- 基于分组的方法(grouping-based):这类方法通常根据预测的逐点语义类别和实例中心偏移量对三维点进行分组,但分组规则多由研究人员手动定义,缺乏灵活性。
- 基于检测的方法(detection-based):先预测每个物体的边界框,再在框内生成前景掩码,将任务拆分为目标检测和分割两个步骤,存在误差累积的问题。
- 基于查询的方法(query-based):受 DETR 52 和 Mask2Former 3 的启发,这类方法利用一组可学习的查询向量,同时预测物体的语义类别和实例掩码,综合建模物体的几何和语义属性。相比前两类方法,基于查询的方法性能更优,避免了误差累积和耗时的细化过程。
然而,所有全监督方法都依赖密集的点级标注,当缺乏这类标注时,其性能会急剧下降。
2.2 弱监督 3D 实例分割
弱监督方法旨在通过部分或间接标注完成任务,以降低标注成本。现有弱监督 3D 实例分割方法主要采用以下几种标注形式:
- 稀疏点标注:利用稀疏的点标签,通过标签传播策略完成实例分割,但稀疏点难以完全捕捉物体的空间范围。
- 2D 图像辅助标注:如 MIT 47、CIP-WPIS 49 等方法,利用 2D 图像标注作为辅助输入,但引入了多模态依赖,增加了系统复杂度。
- 实例级单点标注:为每个实例标注一个单点,通过随机游走、聚类等技术进行实例预测,但单点信息有限,难以保证分割准确性。
- 3D 边界框标注:这是当前主流的弱监督标注方式,相比其他弱监督标注,边界框能更好地捕捉物体的空间范围,且标注成本远低于点级标注。
基于边界框监督的方法中,Box2Mask 4 是首个将边界框监督用于 3D 实例分割的工作。后续方法如 WISGP 8、GaPro 29、BSNet 27 等通过引入空间相关性、高斯过程、教师 - 学生模型等技术提升性能,但这些方法均依赖轴对齐的准确边界框,性能受边界框准确性影响极大。CIP-WPIS 49 尝试使用略微宽松的边界框,但依赖 2D 模态且仅能适应轻微扩大的边界框,灵活性有限。本文提出的 Sketchy-3DIS 不仅能解决多框内点的正确分配问题,还能有效修正草图边界框带来的误差,进一步降低了对标注准确性的要求。
三、方法
3.1 整体框架
Sketchy-3DIS 的整体框架如图 3 所示,主要包含三个核心部分:3D U-Net 骨干网络、自适应框到点伪标签生成器和粗到精实例分割器。其工作流程如下:
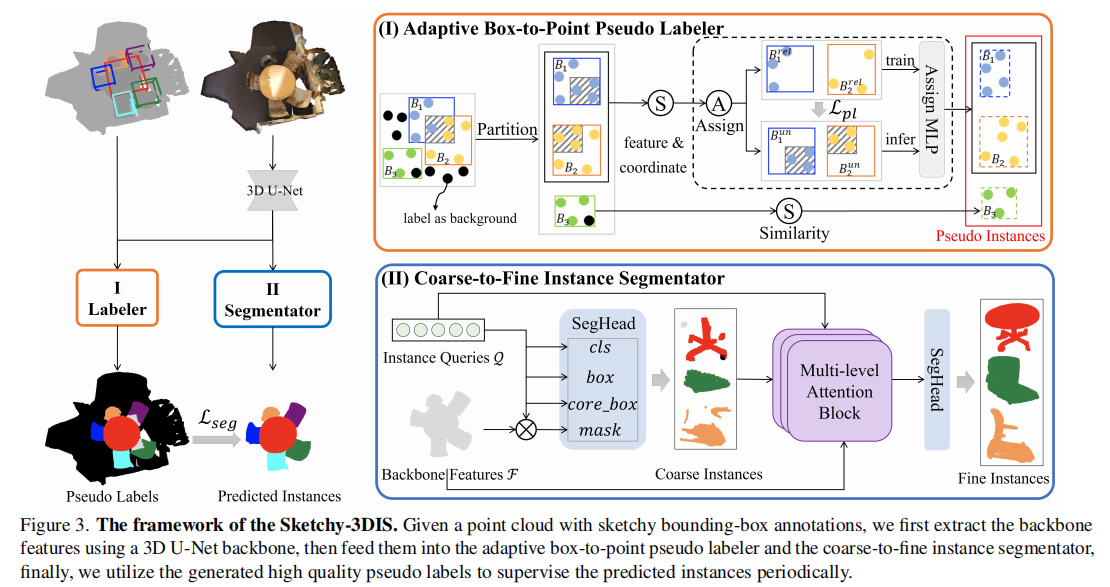
图 3. Sketchy-3DIS 的框架。给定带有草图边界框标注的点云,首先通过 3D U-Net 骨干网络提取特征,然后将特征分别输入自适应框到点伪标签生成器和粗到精实例分割器,最后利用生成的高质量伪标签定期监督预测的实例,实现模型的联合训练。
- 输入:3D 点云
(其中 N 为点的数量,C 为特征通道数,包括 3D 坐标、RGB 颜色和表面法向量)和草图边界框标注。
- 特征提取:将点云和草图边界框输入 3D U-Net 骨干网络,提取点特征,并通过对超点(superpoint)内的点特征进行平均,生成超点级特征。
- 伪标签生成:将超点级特征和草图边界框输入自适应框到点伪标签生成器,将粗糙的框级标注转换为精细的逐点实例标注(伪标签)。
- 实例分割:将超点级特征输入粗到精实例分割器,通过 Transformer 架构预测实例的类别、掩码和边界框。
- 联合训练:通过双边匹配(bilateral matching)建立伪标签与预测实例之间的对应关系,利用伪标签监督实例分割器的训练,同时优化伪标签生成器和实例分割器。
在推理阶段,仅需将新的点云输入骨干网络和粗到精实例分割器,即可完成实例分割。
3.2 草图边界框设置
为模拟实际场景中的不准确边界框,本文通过对真实边界框施加缩放、平移和旋转扰动来生成草图边界框。
3.2.1 真实边界框定义
真实边界框由两个角点的位置定义:
其中 和
分别表示边界框在三维空间中最小和最大坐标点。
3.2.2 基本扰动操作
对真实边界框分别进行缩放、平移和旋转操作,生成基本的不准确边界框:
- 缩放操作:
- 平移操作:
- 旋转操作:
考虑到实际人工标注的边界框与真实边界框不会存在过大差异,本文经验性地设置参数:,
,
。
3.2.3 草图边界框组合生成
通过组合上述基本扰动操作,生成多种类型的草图边界框。如图 2 所示,展示了四种草图边界框(到
),其中红色矩形表示准确边界框,蓝色矩形表示草图边界框。从
到
,"草图程度" 逐渐增加,实例分割的难度也随之增大。
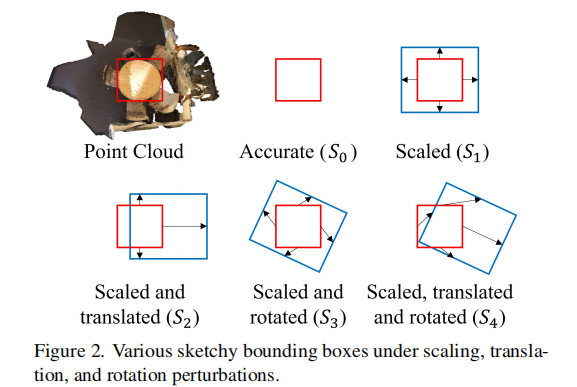
图 2. 在缩放、平移和旋转扰动下生成的各种草图边界框。
3.3 自适应框到点伪标签生成器
草图边界框是一种不准确的弱标注,为了将其转换为精细的逐点实例标注,本文设计了自适应框到点伪标签生成器,该生成器能根据点与边界框的相关性,将框内的点自适应分配到对应的实例中。
3.3.1 基于框的点分类
根据点与 3D 边界框的空间关系,可将点分为三类:
- 边界框外的点:即背景点,直接标注为背景(图 3 中黑色圆点)。
- 单个边界框内的点:可能是目标点(图 3 中绿色 / 黄色 / 蓝色圆点)或背景点,需要进一步筛选。
- 多个边界框重叠区域内的点:这类点的归属存在不确定性,需要通过学习相关性来分配实例标签。
3.3.2 自适应点到实例分配
-
单个边界框内的点分配:对于单个边界框内的点,通过计算点与边界框在坐标空间和特征空间的相似度,筛选出背景点。边界框的坐标和特征通过平均框内所有点的坐标和特征得到,点与边界框的相似度计算公式如下:

其中
-
多个边界框重叠区域内的点分配:对于重叠区域内的点,由于其标签存在不确定性,直接通过边界框难以获得高置信度的标签。因此,首先移除每个框内的重叠点,利用剩余的可靠点(仅属于一个框,标签与框标签一致)进行相似度学习。给定重叠区域内点的特征
为了监督相似度学习,采用交叉熵损失作为伪标签损失 :
,其中
是可靠点的标签(即其所属的边界框)。
通过训练好的 MLP 模型,预测重叠区域内不可靠点的标签,从而将这些点分配到对应的实例中,最终生成高质量的伪实例标签。
3.4 粗到精实例分割器
为了从点云中准确预测实例,本文设计了粗到精实例分割器,该分割器首先从整个点云预测粗实例,然后基于粗实例的区域进一步细化,得到精细实例。
3.4.1 粗实例分割
假设一个场景包含 q 个物体,每个查询向量(instance query)代表一个物体,建模实例相关的特征(语义类别和掩码)。查询向量首先与整个点云的骨干特征进行交互,得到粗实例。由于粗实例的逐点掩码无法整体且精确地描述物体,因此进一步预测两个边界框:粗粒度边界框和细粒度边界框,结合场景级特征,通过多级注意力块(Multi-level Attention Block)对初始粗实例进行细化。
3.4.2 分层实例细化
为了充分利用点云和粗实例的多粒度特征,分割器的解码器采用了堆叠的六个块,每个块包含一个多级注意力块和一个实例分割头(图 3)。多级注意力块的细节如图 4 所示,实例查询通过与全局、局部不同粒度的特征进行交互,逐步提升分割精度。
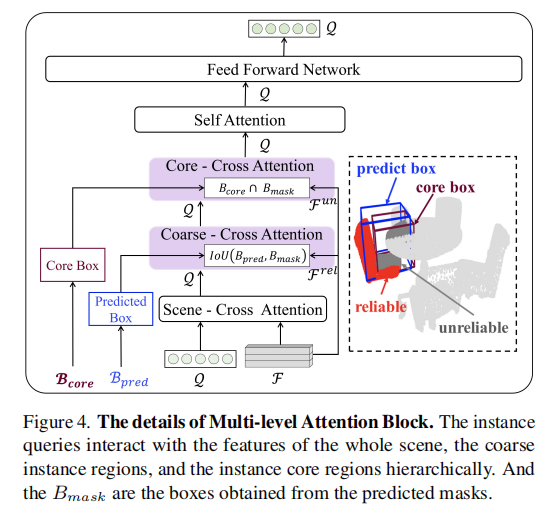
图 4. 多级注意力块的细节。实例查询首先与整个场景的特征进行全局交互,然后与粗实例描述的区域进行局部交互。粗实例描述的区域分为可靠区域和不可靠区域,分别由预测框和核心框表示。
多级注意力块的工作流程如下:
- 全局交互:实例查询首先与逐点骨干特征进行全局交互,获取场景级信息。
- 可靠区域交互:将粗实例抽象为一个边界框
- 不可靠区域交互:为了处理复杂场景,实例查询还需要与不可靠区域进行交互。不可靠区域由预测核心框
- 信息聚合:实例查询经过全局 - 局部的多层交互后,具备了强判别能力,再通过自注意力模块和前馈网络聚合学习到的信息,进一步提升分割性能。
3.5 双边匹配与训练损失
3.5.1 双边匹配
为了建立伪实例与预测实例之间的对应关系,本文采用匈牙利算法(Hungarian method)进行双边匹配,计算第 个预测实例和第
个伪实例的匹配成本
:
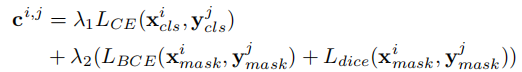
其中 和
分别表示预测实例和伪实例的分类概率,
和
分别表示预测实例和伪实例的二进制掩码,
为交叉熵损失,
为二元交叉熵损失,
为 Dice 损失,
和
为损失权重。
3.5.2 训练损失
整体训练损失由伪标签生成损失 和实例分割损失
组成:
其中实例分割损失不仅监督预测的语义类别和二进制掩码,还监督预测的边界框和核心框,具体定义如下:
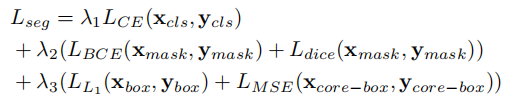
其中 和
分别表示预测边界框和真实边界框(由伪实例标签得到),
和
分别表示预测核心框和真实核心框(基于预测掩码与伪实例掩码的 IoU 确定),
为 L1 损失,
为均方误差损失,
为损失权重。
四、实验
4.1 实验设置
4.1.1 数据集
- ScanNetV2 6:包含 1201 个训练场景、312 个验证场景和 100 个测试场景,标注了 18 个语义类别和实例标签,是 3D 实例分割的主流数据集。
- S3DIS 1:室内场景数据集,包含 6 个区域的 272 个场景,标注了 13 个物体类别。按照现有方法的设置,使用 Area 5 的场景进行验证,其余区域的场景用于训练。
4.1.2 评估指标
采用平均精度(mean average precision, AP)作为主要评估指标,AP 是 IoU 阈值从 95% 到 50%(步长为 5%)的精度平均值。同时,还使用 IoU 阈值为 50% 和 25% 的平均精度(分别记为 AP50 和 AP25)作为补充评估指标。
4.1.3 实现细节
模型在单个 RTX 3090 GPU 上进行训练,以 SPFormer 36 作为 ScanNetV2 数据集的代码库,以 ISBNet 30 作为 S3DIS 数据集的代码库。优化器采用 AdamW,学习率为 0.0002,权重衰减为 0.05。损失权重设置为 。所有模型均从头开始训练,未使用预训练权重,其他超参数和训练细节与基准代码库保持一致。
4.2 主要实验结果
4.2.1 ScanNetV2 数据集结果
表 1 展示了 Sketchy-3DIS 与现有主流方法在 ScanNetV2 数据集上的性能对比。其中 "Mask" 表示使用密集点级标注的全监督方法,"S0" 表示使用准确边界框标注的弱监督方法,"S1" 表示使用草图边界框标注的弱监督方法。
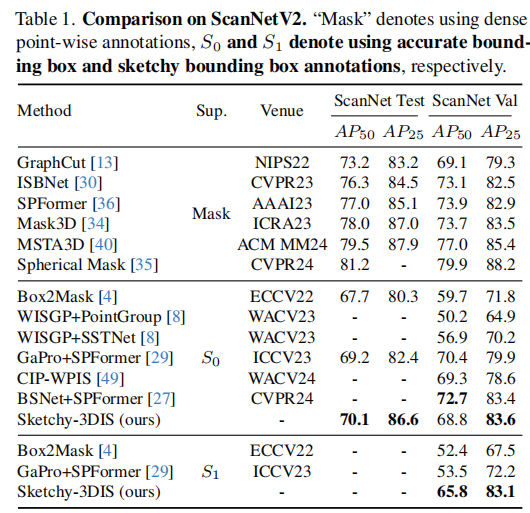
从表 1 可以看出:
- 在准确边界框监督(S0)下,Sketchy-3DIS 的 AP25 达到 83.6,超过了 BSNet+SPFormer(83.4)等现有弱监督方法,甚至接近部分全监督方法的性能。
- 在草图边界框监督(S1)下,Sketchy-3DIS 的 AP50 为 65.8,AP25 为 83.1,远高于现有方法(GaPro+SPFormer 的 AP50 为 53.5,AP25 为 72.2),充分证明了其在不准确边界框监督下的优越性。
- 即使不使用多模态先验 49 或合成场景 27 等辅助手段,Sketchy-3DIS 依然取得了优异的性能,验证了其核心设计的有效性。
4.2.2 S3DIS 数据集结果
表 2 展示了 Sketchy-3DIS 与现有方法在 S3DIS Area 5 上的性能对比。
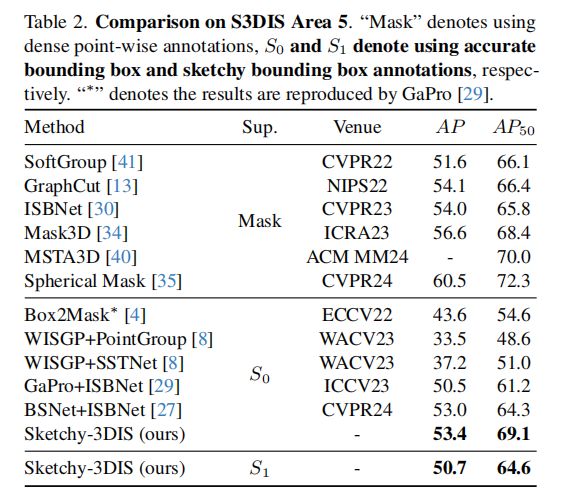
从表 2 可以看出,在准确边界框监督(S0)下,Sketchy-3DIS 的 AP 为 53.4,AP50 为 69.1,超过了所有现有弱监督方法,甚至比全监督基线方法 ISBNet(AP50=66.4)高出 2.7 个百分点;在草图边界框监督(S1)下,Sketchy-3DIS 的 AP 为 50.7,AP50 为 64.6,依然保持了领先的性能,验证了其泛化能力。
4.2.3 伪标签质量对比
图 5 展示了 Sketchy-3DIS 与 GaPro 在 S1 草图边界框监督下生成的伪标签质量对比。可以看出,Sketchy-3DIS 生成的伪标签在细节上(绿色圆圈标注区域)比 GaPro 更准确,并且能更好地区分同类别的不同物体(红色圆圈标注区域)。与真实标签相比,Sketchy-3DIS 生成的伪标签质量也具有很强的竞争力。
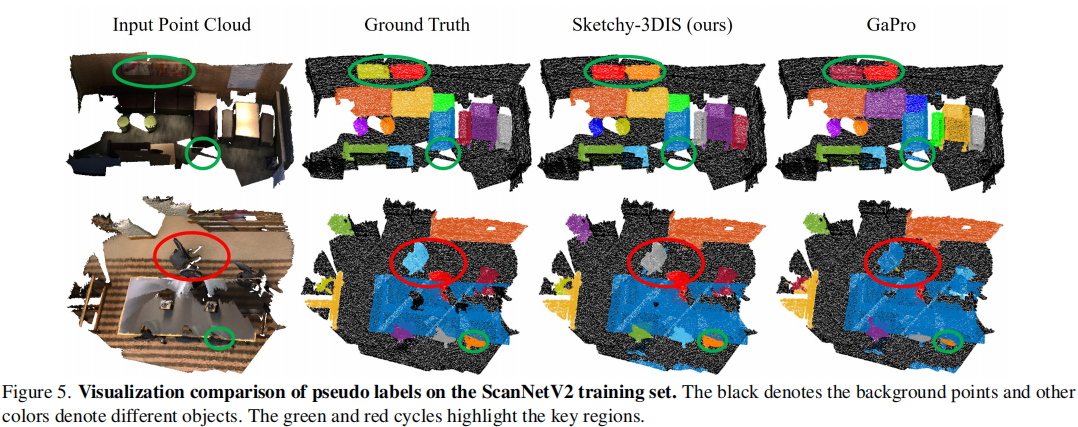
图 5. ScanNetV2 训练集上伪标签的可视化对比。黑色表示背景点,其他颜色表示不同的物体。绿色和红色圆圈标注了关键区域。
4.3 消融实验与分析
4.3.1 不同草图边界框下的鲁棒性
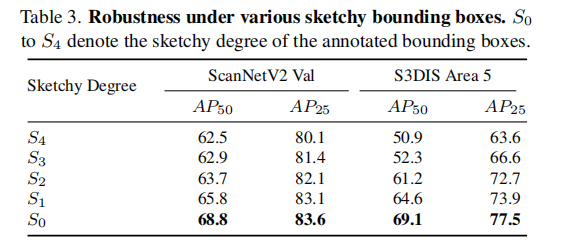
表 3 展示了 Sketchy-3DIS 在四种不同草图程度的边界框(S1 到 S4)监督下的性能,其中 S0 为准确边界框。可以看出,随着草图程度的增加(从 S1 到 S4),模型的性能仅轻微下降。在 ScanNetV2 验证集上,S4 的 AP50 为 62.5,相比 S0 的 68.8 仅下降 6.3 个百分点;在 S3DIS Area 5 上,S4 的 AP50 为 50.9,相比 S0 的 69.1 下降 18.2 个百分点,但依然保持了较高的性能。这表明 Sketchy-3DIS 对边界框的不准确具有较强的鲁棒性。
4.3.2 伪标签生成器和实例分割器的有效性
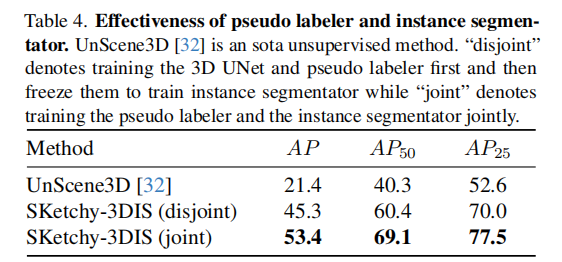
表 4 验证了伪标签生成器和实例分割器的有效性,以当前最先进的无监督方法 UnScene3D 32 作为基线。"disjoint" 表示先训练 3D U-Net 和伪标签生成器,然后冻结它们再训练实例分割器;"joint" 表示伪标签生成器和实例分割器联合训练。
从表 4 可以看出:
- 即使采用分离训练的方式,Sketchy-3DIS 的性能也远高于无监督基线方法,证明了伪标签生成器能生成高质量的伪标签,为实例分割提供了有效的监督信息。
- 联合训练方式下,模型的 AP、AP50 和 AP25 分别达到 53.4、69.1 和 77.5,相比分离训练有显著提升,验证了伪标签生成器和实例分割器联合训练的有效性,两者能相互促进,提升整体性能。
4.3.3 伪标签生成器各组件的有效性
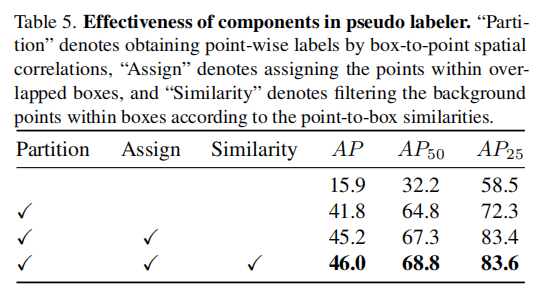
表 5 验证了伪标签生成器中各组件的作用,其中 "Partition" 表示通过框到点的空间相关性获取逐点标签,"Assign" 表示对重叠框内的点进行分配,"Similarity" 表示根据点到框的相似度过滤框内的背景点。
从表 5 可以看出:
- 仅使用 "Partition" 组件时,模型性能已有显著提升,说明基于空间相关性的点分类是有效的。
- 增加 "Assign" 组件后,模型性能进一步提升,证明了对重叠区域内点的自适应分配能解决点归属不确定性问题。
- 加入 "Similarity" 组件后,模型性能达到最优,表明通过相似度过滤框内背景点能进一步提升伪标签质量。
4.3.4 多级注意力块中各注意力的有效性
表 6 验证了多级注意力块中各注意力模块的作用,其中 "Scene" 表示与整个场景的特征交互,"Coarse" 表示与粗实例区域的特征交互,"Core" 表示与实例核心区域的特征交互,"Self" 表示通过自注意力模块增强实例查询。
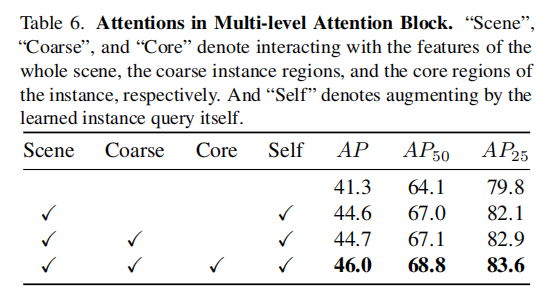
从表 6 可以看出,随着注意力模块的逐步增加,模型性能不断提升。当同时使用 "Scene""Coarse""Core" 和 "Self" 四种注意力模块时,模型性能达到最优,证明了多级注意力块能自适应地挖掘不同粒度的上下文信息,有效提升分割性能。
4.3.5 实例分割损失各部分的有效性
表 7 验证了实例分割损失中各部分的作用,其中表示对预测实例框的监督损失,
表示对实例核心框的监督损失,
表示对实例掩码的监督损失。
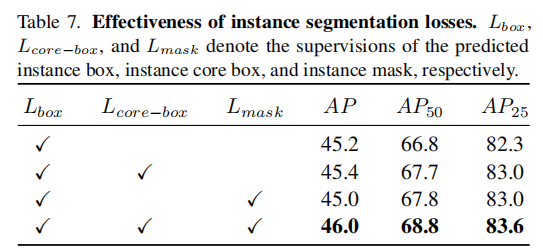
从表 7 可以看出,同时使用三种损失时,模型性能达到最优,证明了对实例框、核心框和掩码的联合监督能全面提升实例分割的准确性。
4.3.6 定性分割结果
图 6 展示了 Sketchy-3DIS 在 ScanNetV2 验证集上的定性分割结果,与 GaPro 和真实标签进行对比。可以看出,Sketchy-3DIS 在简单场景和复杂场景中都能实现有效的实例分割。对于同类别的多个近距离物体,Sketchy-3DIS 能准确区分;此外,该方法还能自适应地分割出真实标签中遗漏的物体(如红色圆圈标注的橱柜),展示了其强大的识别能力。
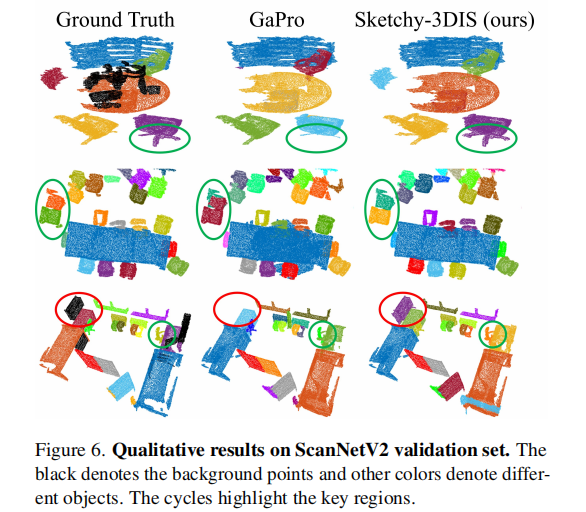
图 6. ScanNetV2 验证集上的定性结果。黑色表示背景点,其他颜色表示不同的物体。圆圈标注了关键区域。
五、结论与未来工作
5.1 结论
本文针对实际场景中准确边界框难以获取的问题,提出了一种基于草图边界框监督的弱监督 3D 实例分割框架 Sketchy-3DIS。该框架通过自适应框到点伪标签生成器将不准确的草图边界框转换为高质量的逐点伪标签,再结合粗到精实例分割器实现精准的实例分割,两者的联合训练进一步提升了模型性能。在 ScanNetV2 和 S3DIS 两个数据集上的大量实验表明,Sketchy-3DIS 在草图边界框监督下取得了领先的性能,甚至超过了部分全监督方法,验证了其有效性、鲁棒性和泛化能力。
5.2 未来工作
本文的实验结果表明,当草图边界框的不准确程度极大时,模型性能会显著下降。因此,未来的研究方向将聚焦于进一步提升模型对极端不准确边界框的适应能力,探索更有效的伪标签生成策略和实例分割方法,以实现更高的噪声容忍性。此外,还可以将 Sketchy-3DIS 扩展到更复杂的场景(如室外自动驾驶场景),进一步验证其实际应用价值。