无人机系统面临着复杂多变的环境挑战,如动态障碍物、风扰、系统故障等,传统的基于精确模型的控制方法往往难以适应这些不确定性。为此,学习与控制相结合的智能方法成为研究热点。
刚刚过去的IROS 2025上,涌现了多篇聚焦单体无人机和多智能体的结合学习与控制的论文,体现了其在提升系统自主性与适应性方面的探索。NOKOV度量动作捕捉系统为研究提供高精度位姿"真值",助力 现实实验 验证。同时在多智能体研究中支持控制算法的闭环执行。
· 单体无人机
一、 基于学习的动态模型 ------ 在状态空间层面进行学习,获得系统的动力学模型
论文:PI-WAN: A Physics-Informed Wind-Adaptive Network for Quadrotor Dynamics Prediction in Unknown Environments (IROS 2025)
作者:Mengyun Wang, Bo Wang, Yifeng Niu and Chang Wang
国防科技大学 牛轶峰老师团队 针对四旋翼在未知风扰环境中建模不准、数据驱动方法泛化差的问题,提出物理信息风自适应网络,将物理约束嵌入训练过程,结合TCN捕获时序特征,提升模型在未见条件下的泛化与鲁棒性。仿真和现实实验表明,该网络集成至MPC控制器后,显著提高了轨迹跟踪精度。NOKOV度量动作捕捉系统在现实实验中为研究提供四旋翼无人机的状态数据,用于计算跟踪误差并验证控制器性能。
 在风扇产生未知外部风场干扰的环境中,采用所提方法控制的四旋翼无人机成功实现了对圆形轨迹的追踪。
在风扇产生未知外部风场干扰的环境中,采用所提方法控制的四旋翼无人机成功实现了对圆形轨迹的追踪。
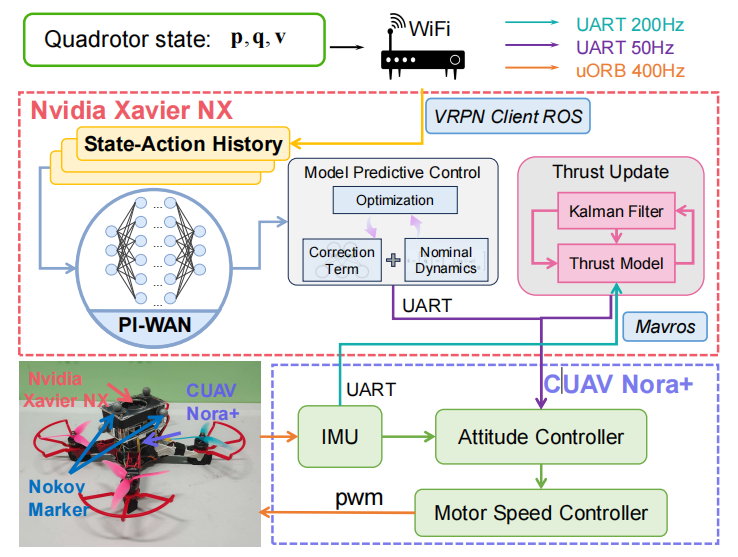 真实环境实验系统。该四旋翼无人机平台由四旋翼机架、CUAV Nora+ 飞行控制器及Xavier NX机载计算机组成。
真实环境实验系统。该四旋翼无人机平台由四旋翼机架、CUAV Nora+ 飞行控制器及Xavier NX机载计算机组成。
二、基于学习的运动规划------ 在轨迹空间层面进行学习,生成全局的运动轨迹
论文:Automatic Generation of Aerobatic Flight in Complex Environments via Diffusion Models(IROS 2025)
作者:Yuhang Zhong, Anke Zhao, Tianyue Wu, Tingrui Zhang and Fei Gao
浙江大学 高飞老师团队 提出基于扩散模型的特技飞行自动化生成框架。该方法将特技分解为可组合基元,结合历史轨迹先验与条件引导确保连续性,并通过分类器引导避障与分层优化保证动态可行性。仿真与真实实验结果表明,该方法在工厂、车间等复杂环境中实现了超过99%的避障成功率,生成了多样且物理可行的长轨迹,并成功部署于真实无人机。NOKOV 度量动作捕捉系统在现实实验中 为执行生成轨迹的无人机提供高精度的 位姿 追踪 ,以支持其在真实世界狭小、杂乱空间中的飞行实验验证。
 我们的方法实现了连续长时域特技飞行动作的自动生成,使无人机能够以动态可行的运动穿越复杂工业厂房。
我们的方法实现了连续长时域特技飞行动作的自动生成,使无人机能够以动态可行的运动穿越复杂工业厂房。
 一架四旋翼无人机在真实世界中执行特技飞行轨迹的快照,所展示的五个不同飞行动作均由所提方法实时生成。
一架四旋翼无人机在真实世界中执行特技飞行轨迹的快照,所展示的五个不同飞行动作均由所提方法实时生成。
三、基于学习的控制器------ 在控制器层面进行学习,优化策略或控制器参数
1.基于安全强化学习的策略优化
论文:A Safety-Adjusted Policy Optimization Algorithm and Application for Obstacle Avoidance in the Quadcopter(IROS 2025)
作者:Gang Xia, Xinsong Yang, Qihan Qi, Yaping Sun, Xiwang Dong
四川大学杨鑫松老师和北京航空航天大学董希旺老师团队 提出安全调整策略优化(SAPO),采用双策略框架,通过成本策略动态调整奖励策略,结合KL散度与高斯核提升性能。在四旋翼避障任务中,SAPO在满足零成本约束的同时取得高回报,性能优于基线方法,并通过仿真与实物实验验证。NOKOV 度量动作捕捉 系统为 本文 算法 反馈 无人机的实时高精度状态数据,实现算法在真实环境中闭环控制与有效验证。
2.基于学习的被动容错控制
论文:Learning-Based Passive Fault-Tolerant Control of a Quadrotor with Rotor Failure(IROS 2025)
作者:Jichao Chen, Kaidong Zhao, Zihan Liu, YanJie Li, Yunjiang Lou
哈工深 楼云江老师团队 针对四旋翼在任意单旋翼故障下的安全问题,提出一种基于学习的被动容错控制方法。本文设计了一个新颖的选择器-控制器网络结构,无需故障信息或控制器切换。仿真与实物实验表明,该方法在故障响应速度与位置跟踪性能上优于现有PFTC和AFTC方法,并在完全旋翼失效情况下实现了实物飞行验证。NOKOV度量动作捕捉系统为飞控的状态估计器提供无人机高精度位姿真值,验证本文算法在真实世界中的有效性。
3.基于贝叶斯优化的参数自整定
论文:Heteroscedastic Bayesian Optimization-Based Dynamic PID Tuning for Accurate and Robust UAV Trajectory Tracking(IROS 2025)
作者:Fuqiang Gu, Jiangshan Ai, Xu Lu, Xianlei Long, Yan Li, Tao Jiang, Chao Chen, Huidong Liu
重庆大学和澳大利亚悉尼麦考瑞大学研究团队 针对无人机轨迹跟踪中因系统非线性、强耦合特性及环境干扰导致的控制精度与鲁棒性不足问题,提出基于异方差贝叶斯优化的动态PID整定方法。该方法通过显式建模噪声方差与输入间的依赖关系,并采用两阶段优化策略,实现对控制器参数的自适应调整。仿真和真实实验表明,本文方法显著优于现有方法,位置与角度跟踪精度分别提升24.7%-42.9%和40.9%-78.4%,显著提升了轨迹跟踪的准确性和环境适应能力。NOKOV度量动作捕捉系统 为无人机在真实实验中的轨迹跟踪提供 高精度位姿数据 ,以支持控制器性能的准确评估与验证 。
· 多智能体系统
一、多智能体强化学习 ------学习协同策略,通过交互优化团队行为
1.知识增强的团队奖励驱动协同追捕
论文:Emergent Cooperative Strategies for Pursuit-Evasion in Cluttered Environments: A Knowledge-Enhanced Multi-Agent Deep Reinforcement Learning Approach (IROS 2025)
作者:Yihao Sun, Chao Yan, Han Zhou, Xiaojia Xiang and Jie Jiang
国防科技大学 周晗老师团队 针对复杂环境中多智能体合作追逃任务,提出一种知识增强的多智能体深度强化学习方法(KE-MATD3),通过集成改进人工势场(IAPF)的启发式知识来引导团队奖励学习,突破个体奖励现实,促进协作行为。实验表明,KE-MATD3在仿真和实物测试中均表现出优越的学习效率和性能,并涌现出有效的合作策略。NOKOV度量动作捕捉 为研究提供无人机集群实时位姿数据以支持闭环控制,并助力验证本文提出的协同策略性能。
2.分层强化学习实现异构集群安全协同
论文: Multi-UAV-UGV Collision-Free Tracking Control via Control Barrier Function-Based Reinforcement Learning (IROS 2025)
作者:Haojie Xia, Qihan Qi, Xinsong Yang , Xingxing Ju , and Housheng Su
四川大学杨鑫松 老师 与华中科大苏厚胜 老师 团队 提出一种基于强化学习与控制屏障函数的分层控制方法,以解决多无人机-无人地面车协同跟踪中特征匹配、实时跟踪和无人机间避碰问题。本文核心贡献包括设 计最优特征匹配以最小化无人机飞行距离、开发无模型强化学习跟踪器,以及构建基于CBF的安全调节器确保碰撞规避。仿真与实物实验结果表明,本文方法能实现高效、实时且安全的跟踪。NOKOV度量动作捕捉系统 为研究 提供无人机与地面机器人的实时位置及速度数据,以支撑闭环控制,并验证 本文提出的 协同跟踪策略的性能。
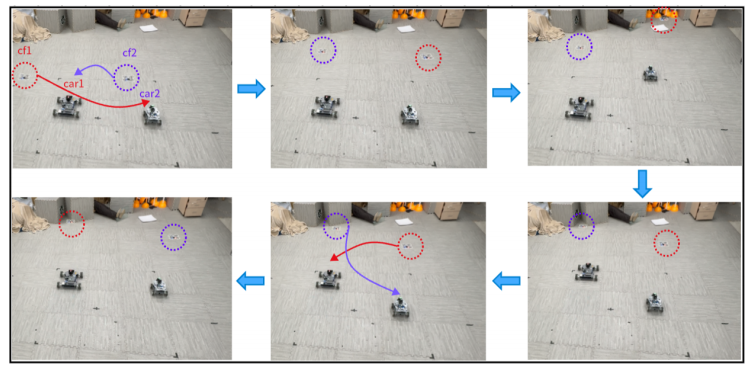 我们使用Crazyflie 2.1无人机与麦卡纳姆轮机器人进行实测,所呈现的实时追踪结果验证了本方法的有效性。
我们使用Crazyflie 2.1无人机与麦卡纳姆轮机器人进行实测,所呈现的实时追踪结果验证了本方法的有效性。
二、多智能体模仿学习------ 从专家演示中学习团队行为规则
论文:Symmetry-Guided Multi-Agent Inverse Reinforcement Learning (IROS 2025)
作者:Yongkai Tian, Yirong Qi, Xin Yu, Wenjun Wu, Jie Luo
北京航空航天大学吴文峻老师团队 为解决多智能体逆向强化学习(MIRL)中样本效率低的问题,首次证明利用多智能体系统固有的对称性可以恢复更准确的奖励函数,并提出一个包含对称性引导演示增强器(SGDA)和对称感知鉴别器(SAD)的通用框架。仿真和现实实验结果表明,该框架能显著提高算法性能,在真实多机器人系统中得到有效验证。NOKOV度量动作捕捉系统 为研究提供无人车集群环境状态数据,以支持 协同控制闭环 在真实环境中 运行 , 同时验证了本文方法在提升样本效率与策略性能方面的有效性。
三、语言模型任务规划 ------ 通过语义理解生成可执行的任务规划
引用格式
Lou, R. Shi, Y. Lin, Q. Wang and W. Wu, "TALKER: A Task-Activated Language Model Based Knowledge-Extension Reasoning System," in IEEE Robotics and Automation Letters, vol. 10, no. 2, pp. 1026-1033, Feb. 2025, doi: 10.1109/LRA.2024.3511434.
北京航空航天大学吴文峻老师团队 在IEEE RA-L期刊发表成果,并于IROS 2025作大会报告。论文提出的TALKER系统,旨在解决使用多智能体强化学习训练无人机执行复杂集体任务时面临的数据成本高、可扩展性差等挑战。本文提出了一种结合任务激活和知识扩展机制的分层交互框架,利用大语言模型进行集群级任务规划,并通过内外双重反馈循环实现系统持续演进。实验结果表明,TALKER系统在多达90架无人机的集群任务中,相比基于多智能体强化学习的方法显著提高了任务成功率。NOKOV动作捕捉系统为本文"虚实结合部署"提供室内定位支持,具体来说提供了无人机高精度的位置信息,以实现TALKER系统在真实世界中对无人机集群的控制与验证。
NOKOV度量动作捕捉系统 为以上研究提供高精度位姿"真值",助力现实实验验证。在多智能体研究中,NOKOV度量动作捕捉系统支持控制算法的闭环执行。
NOKOV Motion Capture
10 Years, 1200+ Robotic Labs