目录
[二、训练 - 测试数据混用:NLP 模型评估的 "头号陷阱"](#二、训练 - 测试数据混用:NLP 模型评估的 “头号陷阱”)
[(一)随机法:保证分布一致性的 "保守策略"](#(一)随机法:保证分布一致性的 “保守策略”)
[(二)数据块法:模拟分布偏移的 "现实策略"](#(二)数据块法:模拟分布偏移的 “现实策略”)
[(三)策略匹配:扣留估计的 "协同原则"](#(三)策略匹配:扣留估计的 “协同原则”)
[六、从 "单一数值" 到 "统计稳健性":更科学的性能评估](#六、从 “单一数值” 到 “统计稳健性”:更科学的性能评估)
[七、工业界与学术界的实践:数据集划分的 "最佳实践"](#七、工业界与学术界的实践:数据集划分的 “最佳实践”)
[八、结语:数据集是 NLP 模型的 "试金石"](#八、结语:数据集是 NLP 模型的 “试金石”)
一、引言
在自然语言处理(NLP)技术从统计模型(如 n-gram)迭代至大语言模型(LLM)的数十年进程中,"模型性能的公正评估" 始终是贯穿研究与工程实践的核心命题。无论模型架构如何复杂、训练算力如何提升,数据集的合理划分与测试策略的科学设计,都是判断一个模型 "真的有效" 还是 "仅拟合了训练数据" 的关键标尺。遗憾的是,许多初学者甚至部分从业者,仍会陷入 "在训练数据上测试模型" 的经典误区 ------ 这看似节省了数据,却让所有后续的 "性能优化" 都沦为自欺欺人的数字游戏。本文将从数据集划分的底层逻辑出发,系统拆解 NLP 中开发与测试数据集的设计原则、策略选择与评估方法,揭示如何通过合理的数据集管理,让模型评估更接近真实应用场景。
二、训练 - 测试数据混用:NLP 模型评估的 "头号陷阱"
统计自然语言处理中,"在训练数据上测试模型" 是最普遍也最致命的错误之一。其本质是混淆了 "模型对训练数据的拟合能力" 与 "模型对未知数据的泛化能力"------ 而后者,才是我们开发模型的最终目标。
以经典的 n-gram 语言模型为例:当我们用最大似然估计(MLE)训练一个 trigram 模型时,MLE 会最大化训练数据中 trigram 序列的出现概率。若直接用训练数据中的句子测试,模型对这些句子的困惑度(Perplexity)会极低 ------ 因为它 "见过" 这些句子的每一个词序列,甚至能完美预测下一个词。但一旦输入训练集之外的新句子,模型的困惑度会急剧上升:比如训练集全是 "新闻语料",测试一个 "小说句子" 时,模型对 "小说特有的句式、意象词" 毫无认知,性能会断崖式下跌。
这种 "训练集测试的出色表现",本质是模型 "记住了数据" 而非 "学会了语言规律"。因此,当我们拿到任何一批 NLP 数据时,第一步必须是将其划分为 "训练集" 与 "测试集":训练集用于模型的参数学习,测试集则是 "未见过的全新数据",仅用于最终评估模型的泛化能力。
通常,测试集的比例会控制在总数据的 5%~10% 之间:比例过小,测试结果会受 "数据随机性" 影响(比如测试集恰好包含大量简单样本,性能虚高);比例过大,则会压缩训练集的规模,导致模型因数据不足而无法充分学习语言规律 ------ 这一比例平衡,是无数 NLP 实践沉淀出的经验准则。
三、基础划分的延伸:扣留估计与留存数据的作用
早期的数据集划分仅止步于 "训练 - 测试" 二元结构,但随着模型调参、算法迭代的需求增加,这种简单划分逐渐暴露了缺陷:若直接用测试集来改进模型(比如调整 n-gram 的平滑参数、优化分词算法),测试集会逐渐失去 "全新数据" 的属性 ------ 模型会慢慢拟合测试集的分布,最终的测试结果同样无法反映泛化能力。
为此,"扣留估计(Holdout Estimation)" 策略应运而生:将训练集再划分为 "训练子集" 与 "留存子集(Holdout Set)"。其中,训练子集用于模型的初始训练,留存子集则承担 "临时测试集" 的角色 ------ 我们可以在留存子集上测试模型、调整参数、改进算法,而测试集仍保持 "完全未接触" 的状态。
比如,当我们训练一个基于 Kneser-Ney 平滑的 4-gram 模型时:
- 先将总数据划分为训练集(90%)与测试集(10%);
- 再从训练集中划分出训练子集(80%)与留存子集(20%);
- 用训练子集训练模型,在留存子集上测试困惑度,调整平滑的折扣值(比如从 0.7 调整到 0.75);
- 当模型在留存子集上的性能稳定后,再用完整的训练集重新训练模型,最后在测试集上进行最终评估。
留存数据的核心价值,是在 "不污染测试集" 的前提下,为模型优化提供反馈 ------ 它是训练集与测试集之间的 "缓冲带",让我们既能迭代改进模型,又能保证测试集的公正性。
四、避免过拟合:开发测试集与最终测试集的双轨体系
当我们进入 "设计算法→训练→测试→改进→重复" 的迭代流程时,新的问题会出现:若留存子集被反复用于测试(比如迭代了 10 次算法,每次都用留存子集评估),模型会逐渐拟合留存子集的分布 ------ 这就是 "训练过度(Overtrained)",本质是一种针对留存子集的过拟合。
为解决这一问题,NLP 领域逐渐形成了 "双测试集" 体系:开发测试集(Development Test Set,简称 Dev 集) 与 最终测试集(Final Test Set)。
- 开发测试集(Dev 集):是 "公开的测试集",用于模型的调参、算法改进、错误分析 ------ 它会被反复使用,是模型迭代的核心反馈源。比如在机器翻译任务中,我们可以在 Dev 集上统计 "未登录词翻译错误" 的比例,进而优化分词词典;
- 最终测试集:是 "盲测集",仅在模型迭代完成后使用一次,用于公布最终性能。它的分布与训练集、Dev 集完全独立,甚至在很多比赛(如 GLUE、MMLU)中,最终测试集的真实标签是不公开的 ------ 目的就是防止选手 "针对 Dev 集过度优化"。
正因为 Dev 集被用于多次调参,模型会不可避免地拟合 Dev 集的语言分布,而最终测试集是 "完全陌生" 的,因此最终测试集的性能通常会比 Dev 集略差------ 这并非模型退化,而是更接近真实应用场景的 "泛化性能"。
比如在 NLP 顶会的论文中,研究者通常会报告模型在 Dev 集上的中间结果(用于展示改进过程),而在最终测试集上的结果才是判断模型优劣的核心依据 ------ 这一规则,正是为了保证学术研究的公正性。
五、测试数据的选择策略:随机法与数据块法的博弈
确定了 "训练 - Dev - 最终测试" 的划分框架后,另一个关键问题是:如何从总数据中选择测试数据? 这一问题的答案,取决于我们对 "真实应用场景" 的模拟需求,目前学界与工业界主要分为两派策略:
(一)随机法:保证分布一致性的 "保守策略"
"随机法" 的核心逻辑是:测试数据应与训练数据的分布尽可能一致------ 因此从总数据中随机选择一定比例的样本(句子、n-gram 或文档)作为测试集,剩余部分作为训练集。
这种策略的优势在于,它能最大限度保证测试集与训练集在 "流派、术语、作者风格、词表分布" 等维度的一致性。比如,当我们训练一个 "新闻标题分类模型" 时,若总数据是 2023 年全年的人民日报新闻标题,随机选择 10% 作为测试集,能保证测试集的话题(如 "经济""科技")、术语(如 "GDP""高质量发展")与训练集高度重合 ------ 此时模型的测试性能,能真实反映它对 "人民日报风格新闻标题" 的分类能力。
但随机法的局限性也很明显:它假设 "未来的应用数据与训练数据分布一致",而现实中,NLP 模型的应用场景往往会面临 "分布偏移(Distribution Shift)"------ 比如训练集是 2023 年的新闻,而实际应用中需要处理 2024 年的新闻,后者的话题、术语可能发生显著变化。
(二)数据块法:模拟分布偏移的 "现实策略"
与随机法相反,"数据块法" 主张保留一个 "大块连续内容" 作为测试集,而非随机抽样。其理论基础是:现实中,模型处理的 "未来数据" 与训练数据的分布必然存在差异(比如语言风格随时间演变、话题随场景变化),因此测试数据应尽可能模拟这种 "分布偏移"。
比如,若我们的数据集是 2023 年 1 月至 12 月的微博语料:
- 随机法会从 12 个月中随机选 10% 的微博作为测试集;
- 数据块法则会保留 12 月整月的微博作为测试集。
后者的优势在于,它能模拟 "模型训练完成后,处理未来一个月新微博" 的实际场景 ------ 而 12 月的微博可能包含 "年终总结""新年祝福" 等训练集(1-11 月)中较少出现的内容,更能反映模型的真实泛化能力。
数据块法的适用场景通常是 "时序数据" 或 "跨领域数据":比如社交媒体语料、学术论文语料(不同年份的研究热点不同)、客服对话语料(不同季度的用户咨询话题不同)等。
(三)策略匹配:扣留估计的 "协同原则"
无论选择随机法还是数据块法,有一个关键原则必须遵守:留存数据的选择策略,必须与测试数据的策略一致。
比如,若我们用 "数据块法" 选择了 12 月的微博作为测试集,那么留存数据也应从训练集(1-11 月)中选择 "11 月整月" 的内容 ------ 这样留存数据的分布,能更接近测试集的 "时序偏移" 特征,用它调参得到的模型,在最终测试集上的性能会更稳定。
反之,若测试集用数据块法,留存数据用随机法,留存数据的分布与测试集差异过大,调参的结果会失去参考价值 ------ 这是很多从业者容易忽略的细节。
六、从 "单一数值" 到 "统计稳健性":更科学的性能评估
早期的 NLP 研究中,研究者通常仅报告模型在测试集上的 "单一性能数值"(比如困惑度、准确率)------ 但这种评估方式存在严重的局限性:测试集的 "随机性" 会极大影响结果。
比如,一个 n-gram 模型在包含 100 个句子的测试集上,若恰好遇到 10 个 "句式简单、词频高" 的句子,困惑度可能低至 50;但如果测试集包含 10 个 "生僻词、复杂句式" 的句子,困惑度可能飙升至 150。单一数值无法反映模型性能的 "波动范围",也无法判断 "模型 A 比模型 B 好" 是真实优势还是偶然结果。
(一)划分样本集:用方差量化性能波动
为解决这一问题,更稳健的方法是:将测试集划分为多个相似的样本集(比如 20 个),在每个样本集上分别测试模型,再计算性能的均值与方差。
方差的计算公式为:
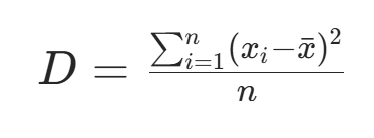
其中,n是样本集的个数,是模型在第i个样本集上的性能,
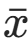 是所有样本集上的平均性能。
是所有样本集上的平均性能。
比如,我们将测试集的 100 个句子划分为 20 个样本集(每个 5 个句子),模型在每个样本集上的困惑度分别为 60、58、62、...、65,计算得到均值为 61,方差为 2.5------ 这意味着模型的性能波动较小,结果更可靠;若方差为 10,则说明模型的性能受测试样本的影响较大,结果的可信度更低。
(二)统计显著性检验:判断性能差异的真实性
仅看均值与方差还不够 ------ 我们还需要通过 "统计显著性检验",判断两个模型的性能差异是否是 "偶然结果"。
最常用的方法是 t 检验:假设模型 A 和模型 B 在 20 个样本集上的性能均值分别为 61 和 58,方差分别为 2.5 和 3.0,通过 t 检验可以计算 "两者均值差≥3" 的概率:若概率小于 0.05(即 "显著性水平"),则认为模型 B 的性能确实优于模型 A;若概率大于 0.05,则说明差异是偶然的,不能认为 B 比 A 好。
(三)结合训练数据块:检测模型的过拟合倾向
若将 "划分样本集" 的方法与 "训练数据块" 结合,还能进一步检测模型是否过拟合了训练集的某一部分。
具体做法是:将训练集划分为多个连续的数据块(比如按时间顺序划分为 5 个块),用每个块训练一个模型,再用对应的小测试集(从训练集的后续部分选择)测试性能。若某个模型的性能远高于其他模型,说明它过拟合了对应训练块的特定分布 ------ 这提示我们需要优化模型的泛化能力(比如增加数据量、调整平滑策略)。
七、工业界与学术界的实践:数据集划分的 "最佳实践"
在实际的 NLP 研究与工程中,数据集的划分策略会根据任务、数据规模、应用场景灵活调整,但核心原则始终不变:保证测试数据的 "未知性",用统计方法提升评估的稳健性。
(一)学术界:公开数据集的标准化划分
在学术研究中,公开数据集通常会预先划分为 "训练集 - Dev 集 - 最终测试集":
- 比如 GLUE 基准数据集,包含训练集(70%)、Dev 集(15%)、测试集(15%),测试集的标签不公开,研究者需提交模型预测结果到官方平台,才能获得最终性能;
- 对于小数据集(比如某方言的语料库),会采用 "k 折交叉验证":将数据划分为 k 份,每份轮流作为 Dev 集,剩余作为训练集,最终取 k 次评估的均值 ------ 这能最大化利用有限的数据,同时避免 Dev 集过小的问题。
(二)工业界:大规模数据的多维度测试
在工业界,大规模预训练模型的数据集划分更为复杂:
- 训练集通常是几十 TB 的跨领域语料(新闻、小说、科技论文等);
- Dev 集会覆盖多个领域,用于调整预训练的超参数(如学习率、batch size);
- 最终测试集则会细分 "同领域测试集"(与训练集领域一致)、"跨领域测试集"(训练集未包含的领域)、"时序测试集"(未来时间段的语料)------ 通过多维度的测试,全面评估模型的泛化能力。
八、结语:数据集是 NLP 模型的 "试金石"
从 n-gram 到大语言模型,NLP 技术的核心目标始终是 "让机器理解并生成人类语言"------ 而数据集的开发与测试,是判断这一目标是否达成的 "试金石"。
合理的数据集划分(训练 - Dev - 最终测试),能避免过拟合与数据污染;科学的测试策略(随机法 / 数据块法),能让评估更接近真实应用场景;稳健的性能评估(样本集划分、统计检验),能让结果更可信。这些看似 "基础" 的工作,是 NLP 研究从 "实验室玩具" 走向 "工业级应用" 的必经之路 ------ 只有重视数据集的每一个细节,才能让模型的性能 "既好看,又好用"。
九、总结
本文系统阐述了NLP模型评估中数据集划分的核心原则与方法。首先指出在训练数据上测试模型的严重误区,强调必须划分独立测试集以评估泛化能力。接着介绍开发测试集(Dev集)与最终测试集的"双轨体系",以及随机法和数据块法两种测试数据选择策略。文章还详细说明了通过样本集划分、方差计算和统计检验来提升评估稳健性的方法,并对比了学术界与工业界在数据集划分上的实践差异。最后强调科学的数据集管理是确保模型评估公正可靠的关键,只有合理的划分策略才能使性能指标真实反映模型在实际应用中的表现。