学会与大型语言模型一同放松:通过双向协同进化求解约束优化问题
信息:
- 作者:Beidan Liu, Zhengqiu Zhu, Chen Gao, Tianle Pu, Yong Zhao, Wei Qi, Quanjun Yin
- 单位:国防科技大学,清华大学
- 日期:2026.04
1. 概述
1.1. 介绍
约束优化问题,即 Constraint Optimization Problems, COPs,广泛存在于物流调度、工业规划、设施布局、金融决策等场景中。其难点不只是目标函数复杂,更关键的是硬约束会把可行域切割成大量碎片化区域,使搜索过程很容易陷入"找不到可行解"或"只能在局部区域反复微调"的状态。传统方法如分支定界、启发式算法、元启发式算法等往往依赖专家经验;而近年来的 LLM-based optimization 方法虽然能自动生成算法或代码,但多数仍把 LLM 当成代码生成器或可行性检查器,而不是让 LLM 主动进行问题分析和约束处理策略设计。
而在人类运筹优化实践中,面对复杂硬约束时,专家往往不会一开始就严格求解原问题,而是先求解一个被"放松"的问题。例如时间窗可以暂时允许轻微违反,容量约束可以设置一定宽容度,安全区域约束可以先扩大或简化,然后再逐步收紧回原约束。这样做的本质是扩大初期可行域,使搜索过程先获得有价值反馈,再逐步逼近严格可行解。论文指出现有 LLM 优化方法缺少这种"约束松弛"的系统机制,所以在硬约束增多时容易退化。
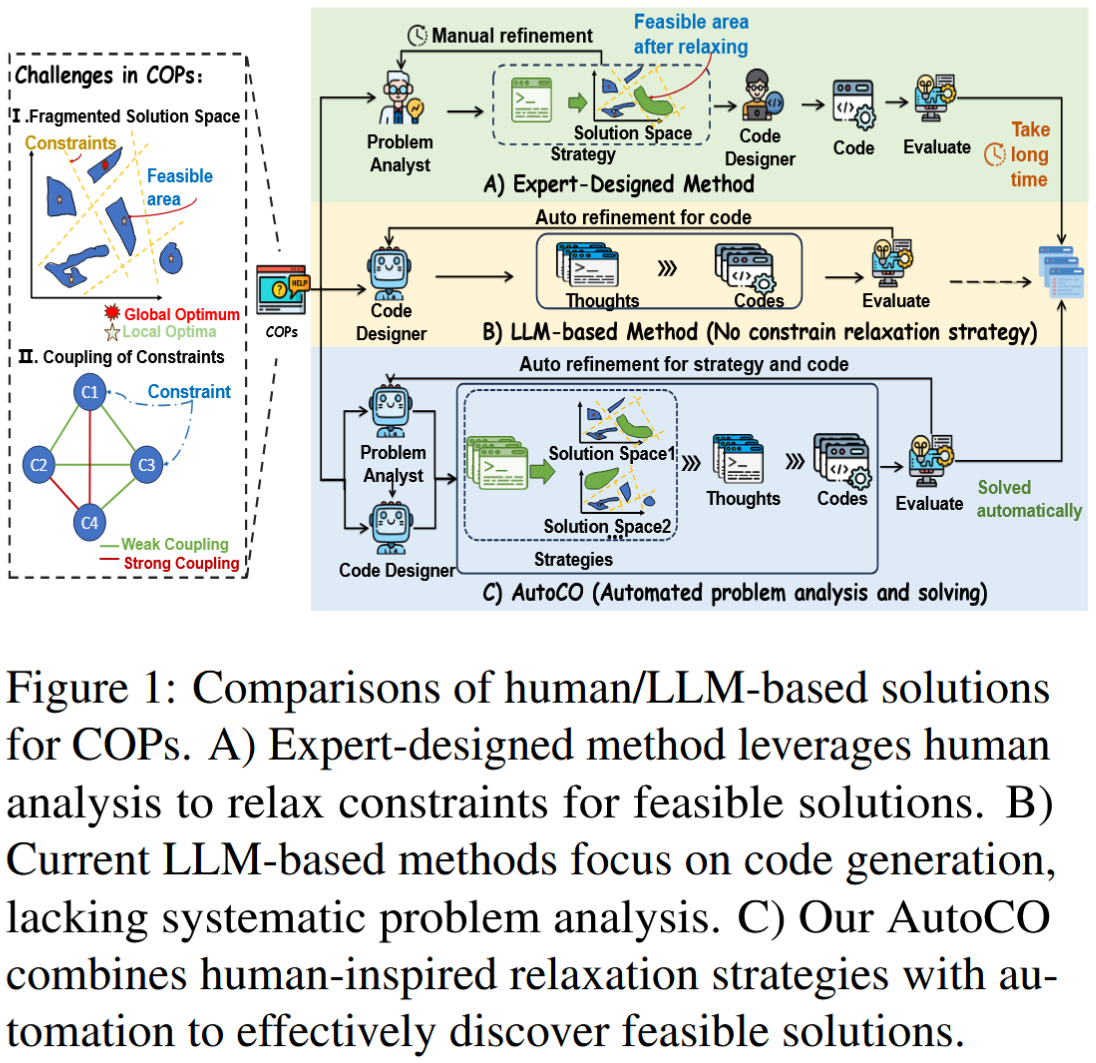
图1对比了三种求解范式:A 是专家设计方法,依靠人工分析约束并设计松弛策略;B 是当前常见 LLM 方法,主要做代码生成,缺少系统的问题分析;C 是 AutoCO,它试图把人类专家的"先分析约束、再设计松弛、最后生成求解代码"的过程自动化。这个图也是理解本文贡献的入口。
1.2. 贡献
- 提出一个端到端的 AutoCO 框架,把 COP 求解拆成问题分析、策略搜索、代码执行三个阶段,而不是直接让 LLM 写一个求解器。
- 提出"三元表示"机制,将一个候选个体表示为约束松弛策略、算法思想和可执行代码三者的组合,即: I j = ⟨ σ j , A j , C j ⟩ I_j=\langle\sigma_j,A_j,C_j\rangle Ij=⟨σj,Aj,Cj⟩,其中 σ j \sigma_j σj 是第 j 个约束松弛策略, A j A_j Aj 是对应算法思想, C j C_j Cj是可执行代码,这种方式避免了"策略说一套,代码写一套"的脱节问题。
- 提出双向协同演化机制:局部层用 Evolutionary Algorithm, EA 优化具体策略-思想-代码个体;全局层用 Monte Carlo Tree Search, MCTS 探索更大的松弛策略空间,并通过双向信息交换避免早熟收敛。论文声称,相比现有 SOTA LLM-based 方法,AutoCO 在三个 COP benchmark 上平均降低了 24.7% 的 optimality gap。
2. 研究方法
2.1. 初步研究
一般约束优化问题 COP 可定义为:
( P ) : min x f ( x ) (P):\quad \min_x f(x) (P):xminf(x)
s.t. g k ( x ) ≤ 0 , k = 1 , ... , m \text{s.t.}\quad g_k(x)\leq 0,\quad k=1,\ldots,m s.t.gk(x)≤0,k=1,...,m
h j ( x ) = 0 , j = 1 , ... , p h_j(x)=0,\quad j=1,\ldots,p hj(x)=0,j=1,...,p
x ∈ X x\in X x∈X
f ( x ) f(x) f(x) 是目标函数, x x x 是决策变量向量, g k ( x ) g_k(x) gk(x) 表示第 k k k 个不等式约束, h j ( x ) h_j(x) hj(x) 表示第 j j j 个等式约束, X X X 是变量的基本定义域,可以包含连续变量、离散变量或混合变量。
在这个定义下,传统 LLM 方法的问题在于:它们通常直接面对原始约束 g k ( x ) ≤ 0 g_k(x)\leq 0 gk(x)≤0,一旦生成解违反约束,就被判为 infeasible,无法提供有效优化反馈。而 AutoCO 则把每个约束都绑定一个松弛因子 ,把约束处理从"二元可行/不可行"变成"有控制地放宽或收紧"。论文将一个松弛策略定义为:
σ = ( g 1 , δ 1 ) , ... , ( g m , δ m ) \sigma={(g_1,\delta_1),\ldots,(g_m,\delta_m)} σ=(g1,δ1),...,(gm,δm)
g k g_k gk 是第 k k k 个约束, δ k ∈ α k , β k \delta_k\in\alpha_k,\beta_k δk∈αk,βk 是该约束的松弛因子, α k , β k \alpha_k,\beta_k αk,βk分别是允许的下界和上界。所有可能的松弛策略构成策略空间: T = σ 1 , σ 2 , ... , σ N T={\sigma_1,\sigma_2,\ldots,\sigma_N} T=σ1,σ2,...,σN
当某个策略 σ \sigma σ 作用于原问题时,得到松弛后的问题:
( P σ ) : min x f ( x ) (P_\sigma):\quad \min_x f(x) (Pσ):xminf(x)
s.t. g k ( x ) ≤ δ k , k = 1 , ... , m \text{s.t.}\quad g_k(x)\leq \delta_k,\quad k=1,\ldots,m s.t.gk(x)≤δk,k=1,...,m
h j ( x ) = 0 , j = 1 , ... , p h_j(x)=0,\quad j=1,\ldots,p hj(x)=0,j=1,...,p
x ∈ X x\in X x∈X
如果 δ k ≥ 0 \delta_k\geq 0 δk≥0,那么原本要求 g k ( x ) ≤ 0 g_k(x)\leq 0 gk(x)≤0 的约束被放松为 g k ( x ) ≤ δ k g_k(x)\leq \delta_k gk(x)≤δk,可行域会扩大,即: F P σ ⊇ F P F_{P_\sigma}\supseteq F_P FPσ⊇FP
这就是本文方法的核心逻辑:通过暂时扩大可行域,使算法更容易找到初始可行或近可行解,然后再利用反馈继续优化,最终回到严格约束下的高质量解。
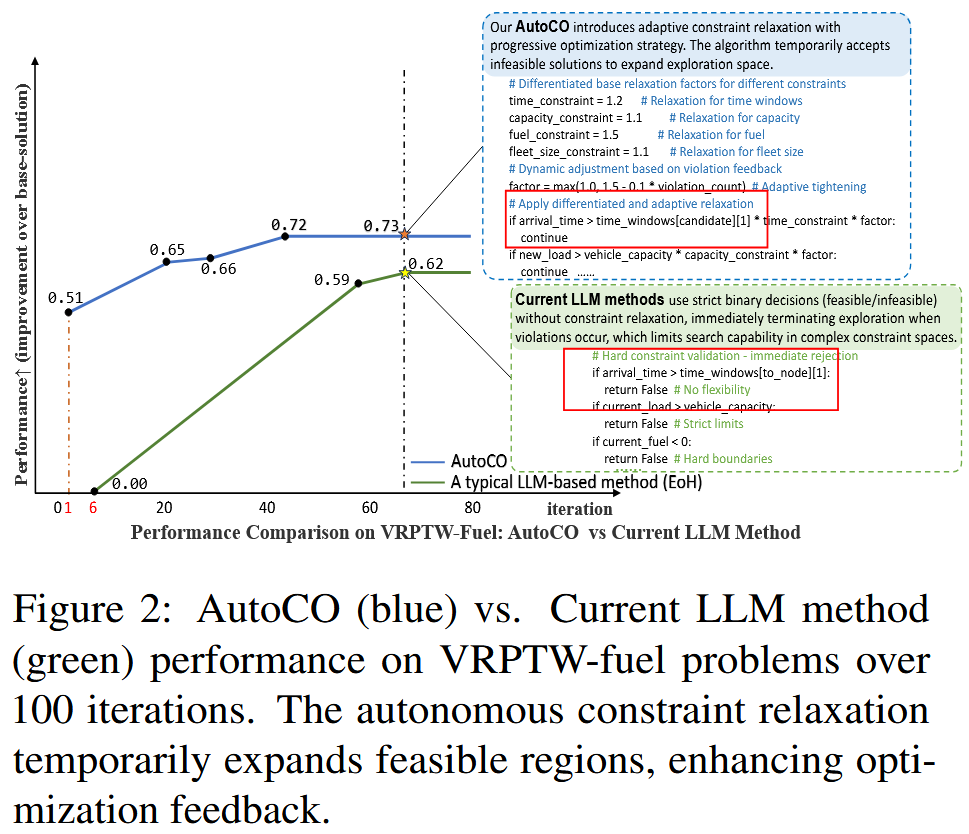
图2直观地说明了 AutoCO 和当前 LLM-based 方法的差异:普通 LLM 方法倾向于硬性判断,例如到达时间超过时间窗就直接拒绝,载重超过容量就直接拒绝,燃料小于零就直接判失败;AutoCO 则会为不同约束设计不同的松弛系数,例如时间窗约束可以乘以 1.2,容量约束可以乘以 1.1,燃料约束可以乘以 1.5,并且根据 violation feedback 动态收紧。这使得搜索不会因为早期轻微违反而立刻终止。
2.2. 总流程
论文的方可以理解为:先把原始 COP 形式化,再把"约束松弛"变成 LLM 可搜索的策略空间,随后用三元个体表示策略、算法和代码,最后用进化算法(EA)与 蒙特卡洛树搜索(MCTS)双层机制共同搜索。
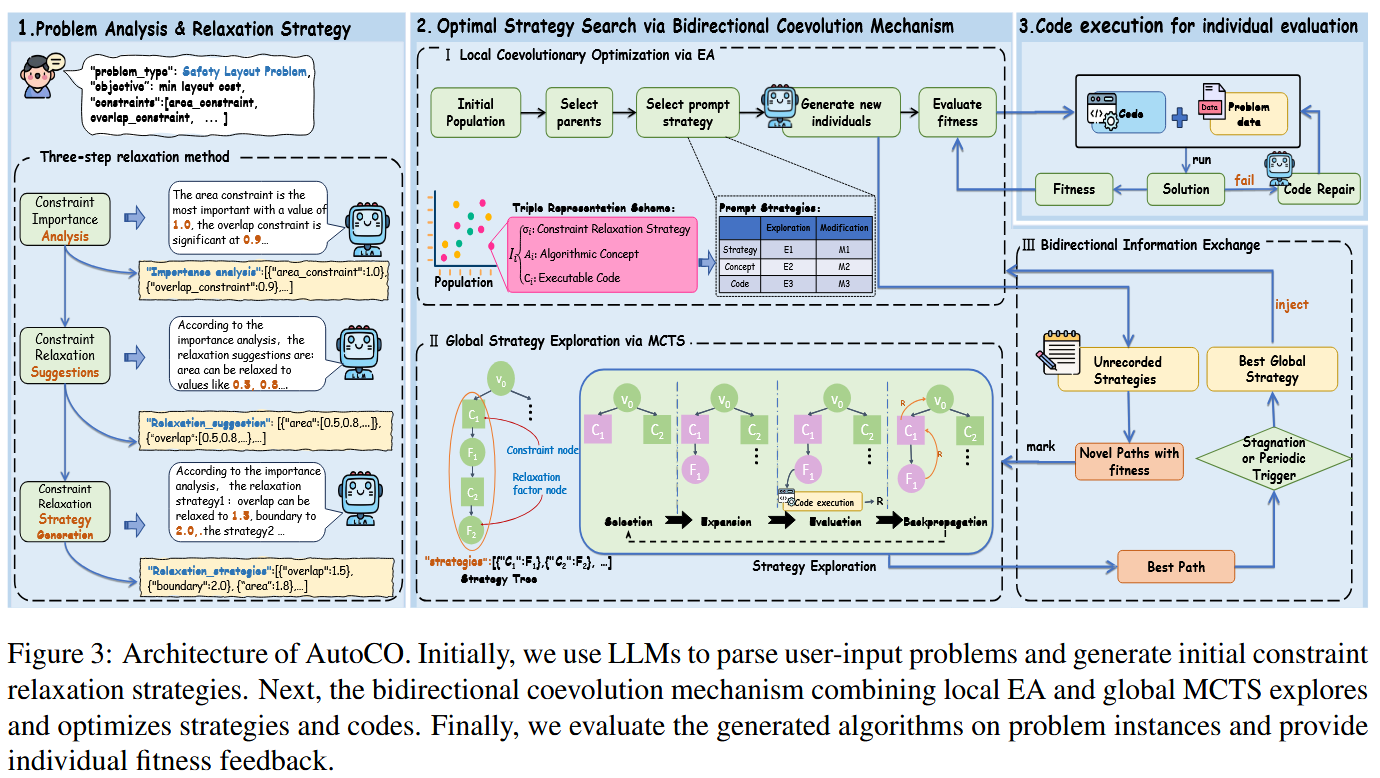
图3展示了三阶段结构:第一阶段是 Problem Analysis & Relaxation Strategy ,即 LLM 解析问题文本,识别目标函数和约束,并生成初始松弛策略;第二阶段是 Optimal Strategy Search via Bidirectional Coevolution Mechanism ,即通过 EA 和 MCTS 共同搜索策略-算法-代码三元组;第三阶段是 Code execution for individual evaluation,即运行生成代码,得到解和 fitness,再把结果反馈给搜索过程。
2.2.1. 阶段一:问题分析&约束策略
第一阶段的 LLM-driven constraint relaxation strategy generation 又分成三步:
2.2.1.1. 约束重要性分析
LLM 从问题描述中抽取约束集合: G = g 1 , g 2 , ... , g m G={g_1,g_2,\ldots,g_m} G=g1,g2,...,gm, 并为每个约束分配重要性权重: w i ∈ 0 , 1 w_i\in0,1 wi∈0,1
如果 w i = 1 w_i=1 wi=1,说明该约束非常关键,不宜过度放松;如果 w i = 0 w_i=0 wi=0,说明该约束影响较小,可以更大胆地调整。这个设计的意义在于,松弛策略空间会随约束数量指数增长,因此不能穷举所有组合,必须先判断哪些约束值得重点处理。
2.2.1.2. 约束松弛范围建议
对每个约束 g i g_i gi,LLM 给出一个松弛范围: α i , β i , α i ≤ 1 ≤ β i \\alpha_i,\\beta_i,\quad \alpha_i\leq 1\leq \beta_i αi,βi,αi≤1≤βi
其中 1 表示原始约束边界, α i < 1 \alpha_i<1 αi<1 表示收紧约束, β i > 1 \beta_i>1 βi>1 表示允许一定程度的违反。这里并不是单纯鼓励"越放松越好",而是把松弛看成一种可搜索的策略:有些约束适合放宽,有些约束反而需要保持严格,甚至阶段性收紧。
2.2.1.3. 约束松弛策略生成
LLM 根据权重集合: W = w 1 , ... , w m W={w_1,\ldots,w_m} W=w1,...,wm 和范围集合: R = { α 1 , β 1 , ... , α m , β m } R=\{\\alpha_1,\\beta_1,\ldots,\\alpha_m,\\beta_m\} R={α1,β1,...,αm,βm},生成初始策略集合: Σ = σ 1 , ... , σ k \Sigma={\sigma_1,\ldots,\sigma_k} Σ=σ1,...,σk, 每个策略可以看作一个 m m m 维向量: σ j = ( δ j 1 , ... , δ j m ) \sigma_j=(\delta_{j1},\ldots,\delta_{jm}) σj=(δj1,...,δjm)
其中 δ j i \delta_{ji} δji 表示第 j j j 个策略中第 i i i 个约束的松弛系数。这样,LLM 不只是随机生成策略,而是基于约束重要性和松弛范围进行有结构的策略采样。
2.2.2. 阶段二:通过 EA 和 MCTS 共同搜索策略-算法-代码三元组
一个候选个体不是单独一段代码,而是: I j = ⟨ σ j , A j , C j ⟩ I_j=\langle \sigma_j,A_j,C_j\rangle Ij=⟨σj,Aj,Cj⟩。其中 σ j \sigma_j σj 是约束松弛策略, A j A_j Aj 是算法思想, C j C_j Cj 是可执行代码。
这个设计有两个作用:
- 让 LLM 生成的代码必须服务于某个明确的松弛策略,而不是泛泛地写一个启发式求解器。
- 让演化操作可以同时修改策略、思想和代码。例如,在 VRPTW-Fuel 中,一个个体可能包含"燃料约束比容量约束更难满足,因此初期允许燃料约束更大松弛,同时对时间窗采用动态收紧"的策略;对应算法思想可能是"先构造宽松可行路线,再进行局部修复";代码中则具体体现为不同约束判断条件中的 relaxation factor。
2.2.3. 阶段三:双向协同演化机制
M exchange = Bidirec_Update ( T MCTS , P EA ) M_{\text{exchange}}=\text{Bidirec\Update}(T{\text{MCTS}},P_{\text{EA}}) Mexchange=Bidirec_Update(TMCTS,PEA)
其中 T MCTS T_{\text{MCTS}} TMCTS 表示蒙特卡洛树搜索 (MCTS) 搜索树, P EA P_{\text{EA}} PEA 表示 EA 种群, M exchange M_{\text{exchange}} Mexchange 表示二者之间的信息交换机制。局部层采用 EA。其基本演化过程为:
P EA t + 1 = Evolution ( P EA t ) P_{\text{EA}}^{t+1}=\text{Evolution}(P_{\text{EA}}^t) PEAt+1=Evolution(PEAt),其中 P EA t P_{\text{EA}}^t PEAt 是第 t t t 代种群, P EA t + 1 P_{\text{EA}}^{t+1} PEAt+1 是下一代种群。EA 层负责在当前较有希望的区域内进行细粒度优化,包括选择父代、选择 prompt strategy、生成新个体、执行代码、评价 fitness。
这里的"演化"不是传统固定交叉变异,而是由 LLM 根据专门 prompt 对 σ j , A j , C j \sigma_j,A_j,C_j σj,Aj,Cj 进行协同修改。也就是说,它要保证策略变化、算法思想变化和代码变化彼此一致。
全局层采用 MCTS。MCTS 用于探索更大的松弛策略空间 T T T。论文对 MCTS 树结构做了专门设计:树节点在"约束节点"和"松弛因子节点"之间交替。一个完整路径对应一个完整松弛策略。例如路径可能依次选择"时间窗约束 → 松弛因子 1.2 → 容量约束 → 松弛因子 1.1 → 燃料约束 → 松弛因子 1.5",从而形成一个策略 σ \sigma σ。
为了在搜索中平衡 exploration 和 exploitation,论文使用改造后的 UCT 公式:
U C T ( n ) = { Q ( n ) N ( n ) + k ln N ( F ) N ( n ) , n = D i Q ( n ) N ( n ) + k ln N ( D i ) N ( n ) w i , n = R i j UCT(n)= \begin{cases} \dfrac{Q(n)}{N(n)}+k\sqrt{\dfrac{\ln N(F)}{N(n)}}, & n=D_i\\8pt \dfrac{Q(n)}{N(n)}+k\sqrt{\dfrac{\ln N(D_i)}{N(n)}}w_i, & n=R_{ij} \end{cases} UCT(n)=⎩ ⎨ ⎧N(n)Q(n)+kN(n)lnN(F) ,N(n)Q(n)+kN(n)lnN(Di) wi,n=Din=Rij
Q ( n ) Q(n) Q(n) 表示节点 n n n 的累计奖励, N ( n ) N(n) N(n) 表示节点访问次数,F 是父节点,k 是探索系数, D i D_i Di 是第 i 个约束节点, R i j R_{ij} Rij 是第 i 个约束的第 j 个松弛因子节点, w i w_i wi 是约束重要性权重。
这个公式的关键差异是:对约束节点 D i D_i Di,它采用常规 UCT;对松弛因子节点 R i j R_{ij} Rij,它额外乘以约束重要性 w i w_i wi,使重要约束的松弛选择在搜索中受到更强关注。
MCTS 的流程仍然包括 selection、expansion、evaluation、backpropagation。选择阶段根据 UCT 选择路径;扩展阶段加入新的约束-松弛因子组合;评价阶段让 LLM 基于该策略生成可执行代码并运行;反向传播阶段把执行得到的 fitness 作为 reward 回传更新节点统计量。最终,MCTS 输出最优或较优策略: σ ∗ \sigma^* σ∗
再将其注入 EA 种群,指导局部搜索。
双向信息交换是本文方法区别于简单"EA + MCTS 串联"的关键。交换机制写作:
I exchange = { S MCTS → P EA I EA → T MCTS I_{\text{exchange}}= \begin{cases} S_{\text{MCTS}}\rightarrow P_{\text{EA}}\\ I_{\text{EA}}\rightarrow T_{\text{MCTS}} \end{cases} Iexchange={SMCTS→PEAIEA→TMCTS
其中, S MCTS S_{\text{MCTS}} SMCTS 表示 MCTS 发现的有希望策略, I EA I_{\text{EA}} IEA 表示 EA 中已经评估过的个体或可行解:
- 第一条方向是 MCTS 到 EA:当 EA 出现停滞,或者达到周期性触发条件时,MCTS 将全局发现的策略注入 EA,帮助种群跳出局部最优。
- 第二条方向是 EA 到 MCTS:EA 中已经运行并评价过的策略会回传给 MCTS,用于更新搜索树,避免 MCTS 重复探索已知区域。
从方法本质看,AutoCO 并不是单纯"LLM 写代码 + 运行反馈"的框架,而是把约束松弛策略显式建模为可搜索对象。它的创新不在于某个具体 VRP 启发式,而在于把"约束处理策略"提升为 LLM 自动优化的第一类对象。这一点与 EoH、FunSearch、ReEvo 等方法有明显区别:这些主要优化算法程序本身,而 AutoCO 试图同时优化"为什么这样放松约束""采用什么算法思想""代码如何实现"。
3. 实验
3.1. 实验设置
为验证 AutoCO 在不同类型约束优化问题上的有效性和泛化能力,论文选取了三个具有代表性的约束优化问题作为测试对象:
- 带时间窗车辆路径问题(VRPTW):要求车辆从仓库出发服务多个客户,并满足每个客户的服务时间窗约束。难点在于,前面访问顺序一旦选错,后面客户可能因为到达时间过早或过晚而不可行。因此它主要考察算法处理"路径顺序---时间可行性"耦合约束的能力。
- 带燃料约束的时间窗车辆路径问题(VRPTW-Fuel):在 VRPTW 的基础上进一步加入燃料消耗限制,燃料消耗又与行驶距离、车辆载重等因素相关。因此它比普通 VRPTW 更难,因为算法不仅要满足时间窗和容量,还要保证路线中的累计燃料消耗不超过上限。作为更复杂硬约束场景,用来验证 AutoCO 的约束松弛策略是否能帮助找到可行解。
- 安全设施布局问题(SFL):要求在给定区域内布置若干设施,同时满足非重叠约束、安全区域包含约束等几何约束。难点在于,它不是单纯的路径组合问题,而是连续空间中的布局优化,并且包含非线性几何关系。例如设施之间不能重叠,设施还要位于指定安全区域内。论文用 SFL 检验 AutoCO 是否也能处理空间布局类约束优化问题,而不只适用于车辆路径问题。

这三个问题分别覆盖了时间约束、资源累积约束与几何布局约束等不同约束结构,因此能够较全面地检验 AutoCO 对复杂硬约束的处理能力。
论文采用 optimality gap 作为主要性能指标,其定义为: γ = ∣ f best − f opt ∣ ∣ f opt ∣ \gamma=\frac{|f_{\text{best}}-f_{\text{opt}}|}{|f_{\text{opt}}|} γ=∣fopt∣∣fbest−fopt∣
除解质量外,论文还使用端到端运行时间 T e 2 e T_{e2e} Te2e、首次可行解时间 T t f f T_{tff} Ttff 和性能停滞时间 T s t a g T_{stag} Tstag 评价算法效率。
实现方面,论文使用 DeepSeek-R1 作为基础 LLM,种群规模设置为 45,每次运行时间限制为 2 小时,并在 Intel i5-13400F 和 RTX 4060 Ti 环境下进行实验。
3.2. Baseline
- 精确求解器 Gurobi,用于提供强参考基线,并检验传统数学规划求解器在复杂硬约束问题上的表现。
- 传统优化与学习方法,包括强化学习方法 DeepACO,以及典型元启发式算法 SA、GA、PSO、MA 和 DE。这些方法代表了组合优化中常见的人工设计搜索策略。
- LLM-based optimization 方法,包括 FunSearch、EoH 和 ReEvo。它们同样利用 LLM 进行程序搜索或算法生成。
3.3. 主要结果
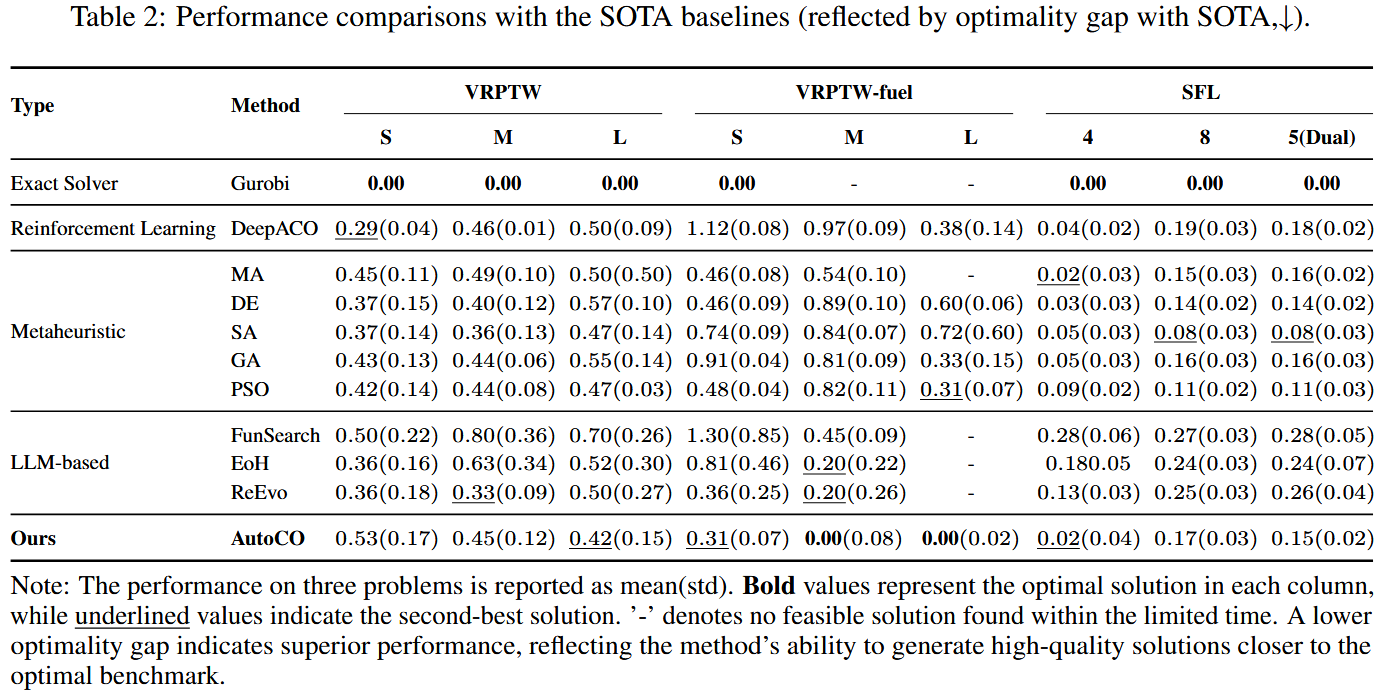
主要结果见表2。整体来看,AutoCO 并不是在所有问题和所有规模上都绝对最优,但它在硬约束更复杂、可行解更难获得的场景下表现更突出。对于 VRPTW,AutoCO 在 S、M、L 三种规模上的 optimality gap 分别为 0.53、0.45 和 0.42。虽然在小规模和中规模上不一定优于传统强基线,但在大规模实例上具有较好的竞争力,说明其自动策略设计在问题规模增加时仍能保持一定有效性。
更关键的结果出现在 VRPTW-Fuel 上。由于该问题在时间窗约束之外进一步引入燃料约束,可行域更加碎片化,许多方法难以稳定获得高质量解。AutoCO 在 S、M、L 三种规模上的 gap 分别为 0.31、0.00 和 0.00,明显优于多数 LLM-based baseline。相比之下,FunSearch 在小规模 VRPTW-Fuel 上 gap 达到 1.30,DeepACO 在 S 和 M 上分别为 1.12 和 0.97,说明这些方法在复杂资源约束下退化明显。Gurobi 在较大 VRPTW-Fuel 实例中未能在限定时间内找到可行解,也进一步说明该问题对传统精确求解器具有较高挑战。
在 SFL 问题上,AutoCO 同样保持了较稳定表现。该问题的难点不在于路径顺序,而在于连续布局空间中的非重叠、安全区域和几何包含关系。AutoCO 在 SFL-4、SFL-8 和 SFL-5(Dual) 上分别取得 0.02、0.17 和 0.15 的 gap,说明其约束松弛机制不仅适用于车辆路径类问题,也能迁移到几何布局类约束优化问题。
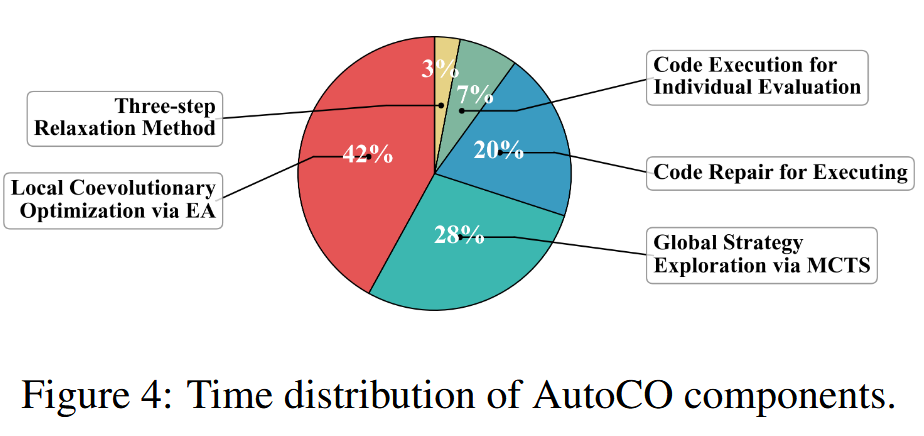
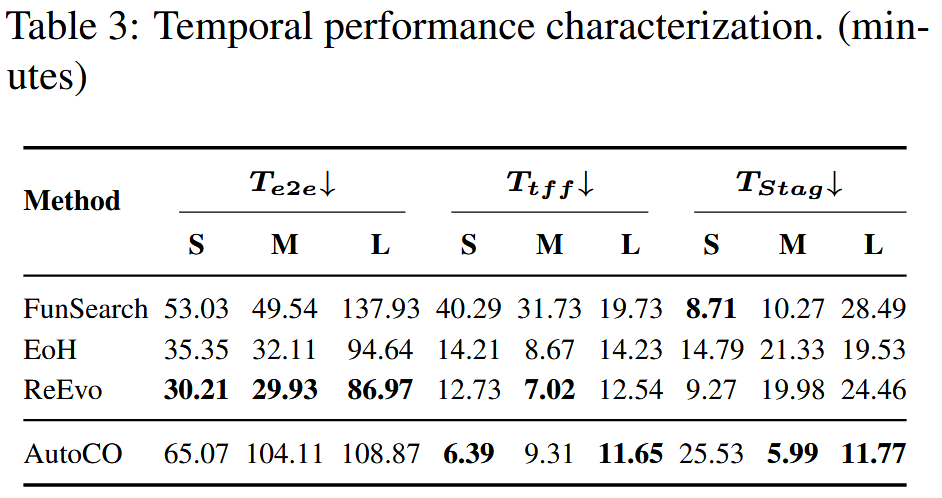
时间效率结果见表3和图4。AutoCO 的端到端运行时间并不总是最短,部分情况下甚至高于 FunSearch、EoH 和 ReEvo。这说明 AutoCO 的复杂框架确实带来了额外计算开销。但它在首次可行解时间上表现较好,例如在 VRPTW 的 S、M、L 三种规模上分别为 6.39、9.31 和 11.65 分钟,通常快于其他 LLM-based 方法。也就是说,AutoCO 的优势不在于最短总运行时间,而在于能够较快找到可行解,并利用后续搜索继续改进解质量。
从整体实验结果看,AutoCO 的主要价值体现在复杂硬约束场景中。其约束松弛策略使搜索过程不再被严格可行性判断过早中断,而是可以先进入扩大的近可行区域,再通过演化和反馈逐步收紧约束、优化解质量。因此,论文的实验结论并不是"AutoCO 全面替代传统求解器",而是说明"在可行解稀缺、约束耦合强、传统 LLM 方法容易停滞的问题上,显式搜索约束松弛策略是有效的"。
3.4. 消融实验与补充分析
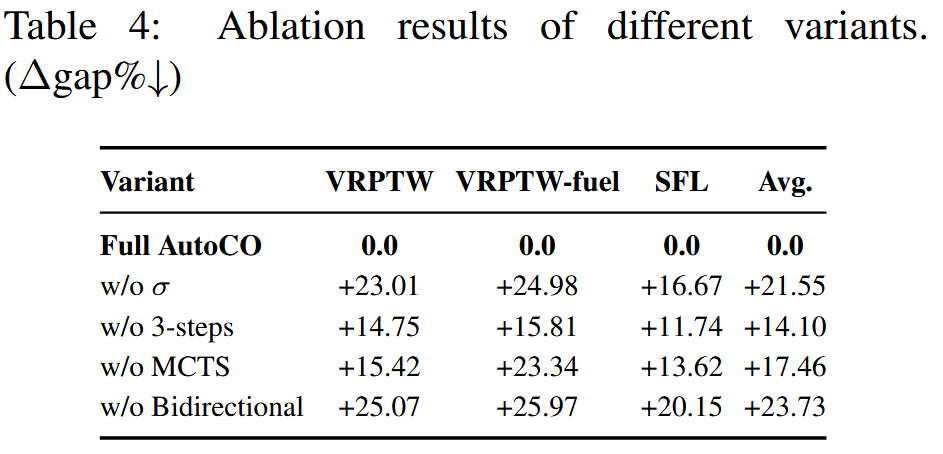
论文进一步通过消融实验验证各模块的贡献。表4比较了完整 AutoCO 与四个变体:
- 去掉约束松弛模块 w / o σ w/o\ \sigma w/o σ
- 去掉三步策略生成 w / o 3 - s t e p s w/o\ 3\text{-}steps w/o 3-steps
- 去掉 MCTS 全局搜索 w / o M C T S w/o\ MCTS w/o MCTS
- 去掉双向信息交换 w / o B i d i r e c t i o n a l w/o\ Bidirectional w/o Bidirectional
结果显示,去掉约束松弛模块会造成平均 +21.55% 的 gap 增量,说明显式建模约束松弛策略是 AutoCO 的核心。去掉三步策略生成带来 +14.10% 的性能下降,说明先分析约束重要性、再建议松弛范围、最后生成策略的结构化流程优于直接随机生成策略。
MCTS 和双向信息交换同样重要。去掉 MCTS 后,平均 gap 增加 +17.46%,说明单纯依靠 EA 的局部演化容易陷入局部搜索区域,缺少全局策略探索能力。去掉双向信息交换后,性能下降最明显,平均 gap 增加 +23.73%。这表明 AutoCO 的优势并不只是简单地把 EA 和 MCTS 放在一起,而是来自二者之间的信息流动:EA 将已评估策略反馈给 MCTS,减少重复搜索;MCTS 在 EA 停滞时向种群注入新的全局策略,帮助跳出局部最优。
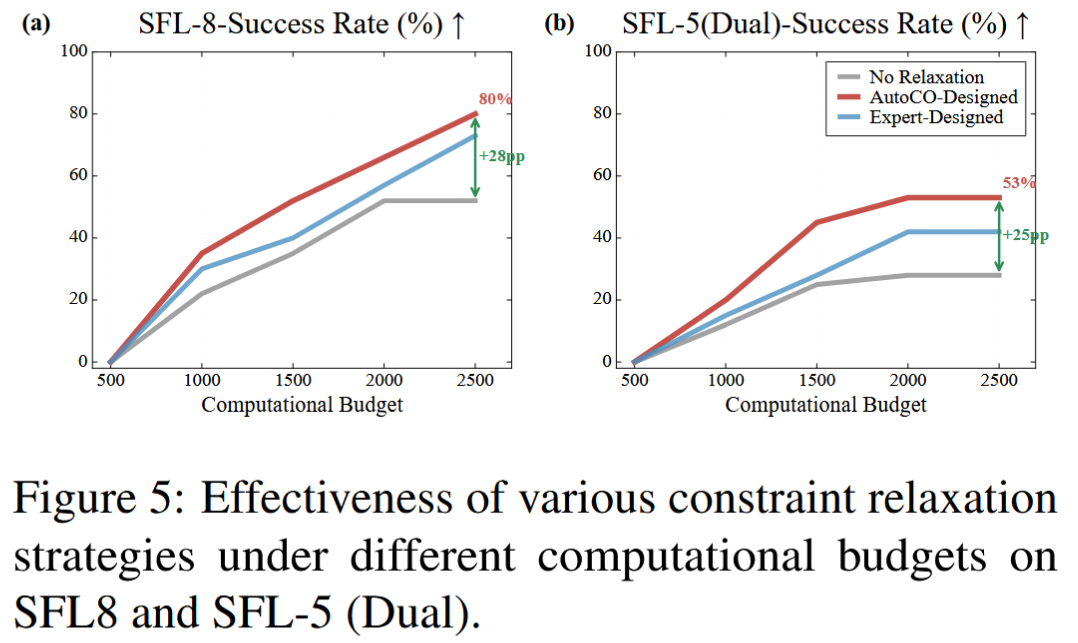
论文还通过图5验证了 AutoCO 生成的约束松弛策略本身是否有效。在 SFL-8 和 SFL-5(Dual) 上比较了不松弛原始约束、专家设计松弛策略和 AutoCO 自动生成策略。结果显示,AutoCO 策略在不同计算预算下取得更高成功率。例如在 SFL-8 上,不松弛策略的成功率停留在 52%,而 AutoCO 策略可达到 80%。这说明 AutoCO 的性能提升不只是来自代码生成,而是因为其自动设计的松弛策略确实改变了搜索空间,使可行解更容易被发现。
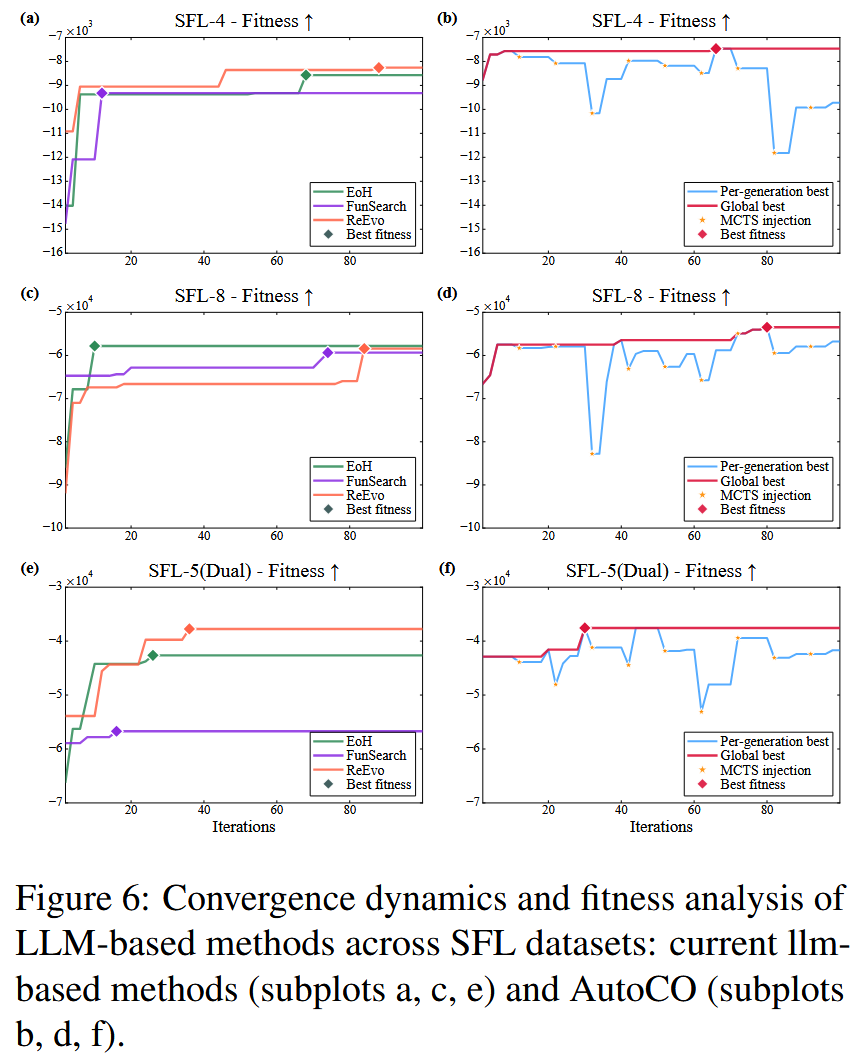
最后,图6展示了不同 LLM-based 方法的优化动态。FunSearch、EoH 和 ReEvo 在获得初始解后较快进入局部停滞,而 AutoCO 即使短期 fitness 停滞,也能通过 MCTS injection 注入全局策略,在后续迭代中继续产生改进。这一结果进一步支持论文关于"双向协同演化能够缓解早熟收敛"的论点。
4. 总结
4.1. 结论
AutoCO 是一个有启发性的自动化约束优化框架,而不是一个已经可以替代成熟求解器的通用 COP solver。论文提出了一个更高层次的思想:LLM-based optimization 不应只优化代码,还应优化约束处理策略本身。 将 LLM 从被动的约束检查器或代码生成器,提升为主动的约束松弛策略设计者。其核心思想是通过三步约束分析生成初始松弛策略,通过三元表示同步维护策略、算法思想和代码,通过 EA 与 MCTS 的双向协同搜索实现局部精修和全局探索。实验表明,该框架在 VRPTW、VRPTW-Fuel 和 SFL 三类问题上具有一定泛化性,尤其在硬约束复杂、传统方法或当前 LLM 方法容易停滞的情况下更有优势。
4.2. 限制
- 当前实验主要集中于静态、确定性约束优化问题,尚未覆盖随机优化和动态优化场景。例如现实物流中的订单动态到达、交通时间随机变化、设施布局中的不确定需求等,都没有被充分处理。
- 随着约束数量和问题规模增加,松弛策略空间会指数增长,即使有 MCTS 和 LLM 指导,策略搜索仍可能面临可扩展性问题。
- AutoCO 需要同时维护 LLM reasoning、EA、MCTS、代码执行和约束验证,计算开销较大,不一定适合实时决策。
- 方法效果受 LLM 推理能力和代码能力影响,如果 LLM 在早期约束分析时判断错误,后续搜索可能会在错误策略空间中演化。
- 虽然实验支持 bidirectional coevolution 的有效性,但理论收敛性质尚未被严格证明。
4.3. 未来方向
- 扩展到多目标优化,并处理更复杂的约束耦合;
- 发展分布式协同演化框架,以提高大规模问题上的可扩展性。