论文:DBAIOps: A Reasoning LLM-Enhanced Database Operation and Maintenance System using Knowledge Graphs
repo:https://github.com/weAIDB/DBAIOps/
什么是DBAIOps
1.why DBAIOps:
- 人力运维非常耗时
- 人力运维难以扩展
- 人力运维常期困于重复的故障
- 文档+RAG模型不准确(没有DBA经验集成或有限制的局限性)
总之,人力运维和现有方案都一般般,所以推出了DBAIOps------结合大模型推理和知识图谱的运维系统,实现类DBA的诊断能力。
2.数据库故障分析方案对比:
- 预设规则方案:传统方案,比较死板
- 机器学习方案:本质上是基于规则的,有许多类似的限制;依赖训练数据,会造成较低的生成能力,一般适合特点问题常见的诊断。
- 基于LLM方案:使用一般文档和LLM(例如基于决策树),容易给出一般结果
- LLM+RAG方案:搜索基于分片的top-k临近知识,结果不准确
3.对比了以上方案后,可以看出结合了图知识、DBA经验、LLM的DBAIOps的优势:
- 结合DBA经验
- 保留原始关系
- 支持新的根因定位和解决方案
- 可扩展
overview
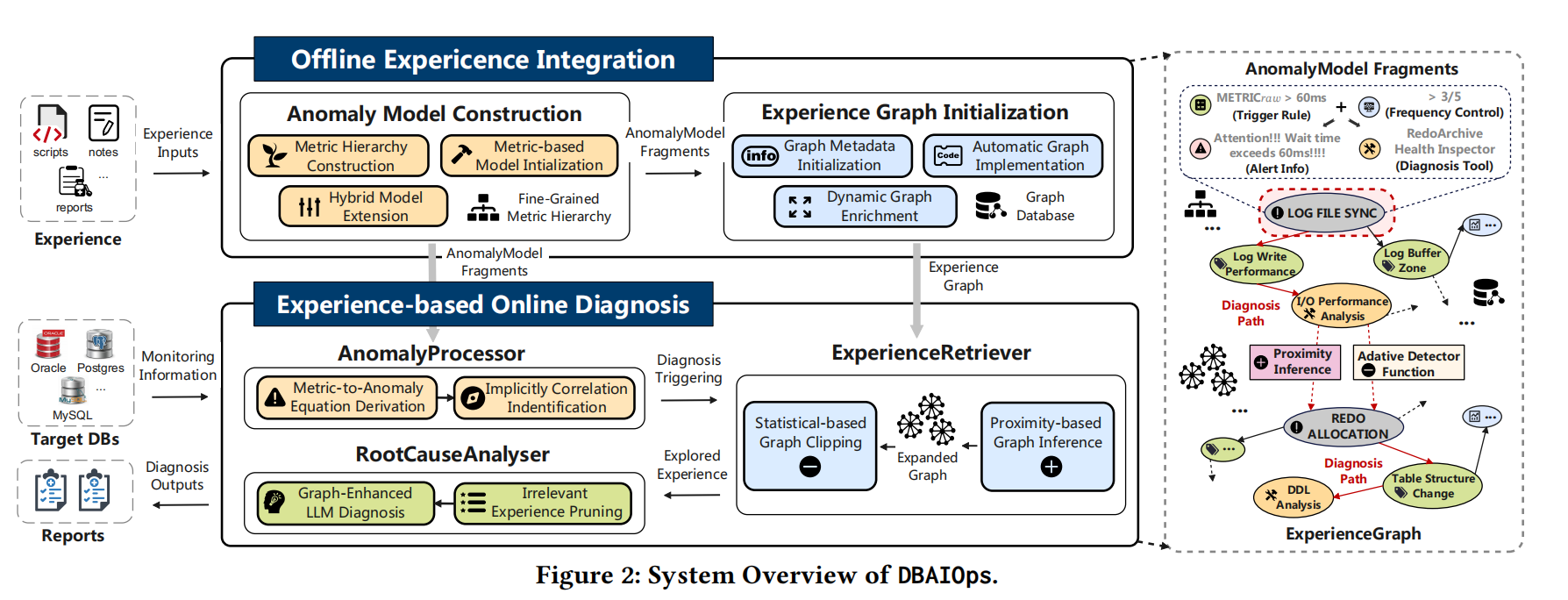
左侧是架构,右侧是示例。
offline做的是DBA经验嵌入neo4j,嵌入后的图模型叫ExperienceGraph,图的边代表异常现象或者metric的关系。嵌入后的异常模型称为AnomalyModel。
online做的是异常分析、检索、生成报告。其中AnomalyProcessor提取标准故障信息和AnomalyModel信息,然后通过ExperienceRetriever检索图;最后RootCauseAnlyser调用LLM生成分析报告。
从右侧的示例可以看到,通过图相关性找到LOG FILE SYNC关联的LOG WRITE性能、IO性能;通过REDO ALLOCATION可以找到表结构变更和DDL。
运维经验的图模型
不同于基于规则或者基于文档chunk的RAG,ExperienceGraph是编码了运维经验异构信息的图模型。图包含三个元素:(顶点、带方向的边,边上的关系)。
根据运维经验的特性,DBAIOps对其中顶点进行了分类:
- trigger vertex:用于检测数据库异常,是异常分析的入口。例如LOG FILE SYNC就是入口顶点
- metric vertex:数据库运行时的metric。如果是离线知识,指的应该是运维案例里的metric(如果有的话)
- experience vertex:编码了领域特定的运维经验,涵盖异常的含义及处置方法。比如LOG FILE SYNC超过60ms代表提交过于频繁或者其他参数需要调整。
- tool vertex:收集和分析异常指标的可执行脚本
- tag vertex:图顶点的语义类别。比如并发事务Concurrent Transactions涉及多种顶点,tag vertex可以加强跨案例的关联性
- auxiliary vertex:解释指标的含义
对边的分类:
- containment edge:Trigger Vertex-Experience Vertex
- relevance edge:Trigger Vertex-Metric Vertex
- diagnosis edge:Experience Vertex -Metric Vertex
- sysnonym edge:只出现在Tag Vertices-Tag Vertices之间,表示语义上同义,比如physical_read and disk_read; shared_pool and shared_buffer
以示例来分析运维经验图模型:
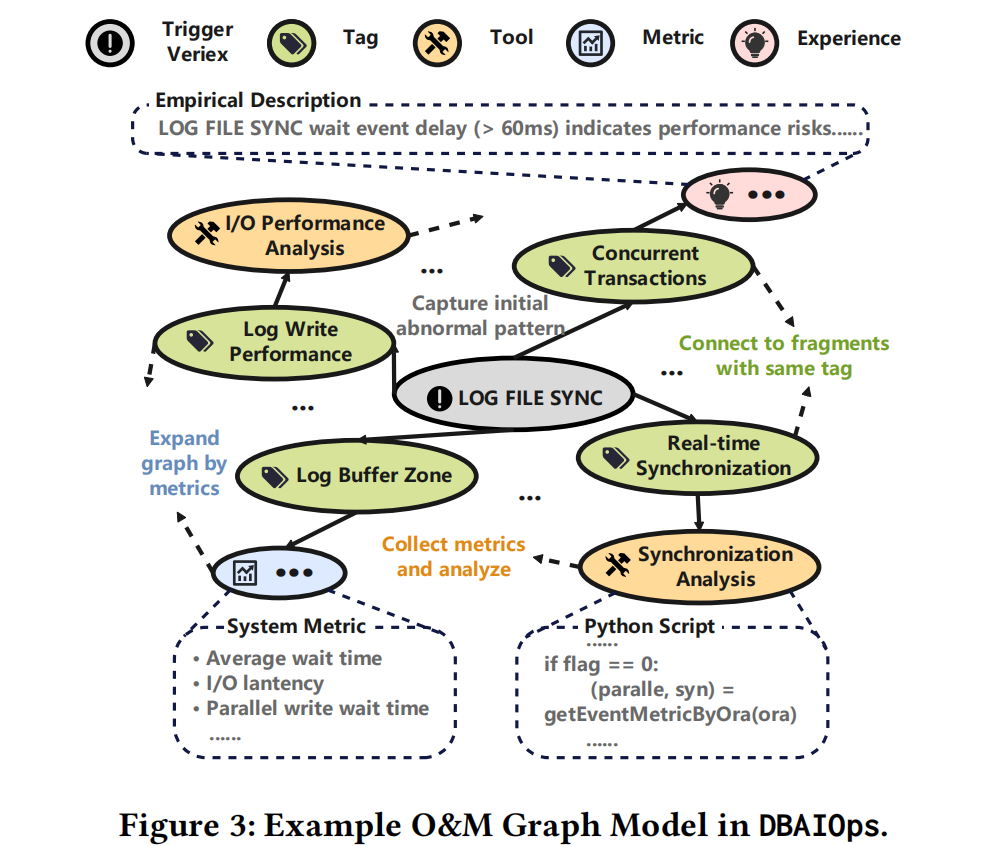
LOG FILE SYNC有多种TAG,TAG跟Experience、metric、tool关联。能看出来关联性非常强,它代表了人类DBA对LOG FILE SYNC的理解和运维经验。
图的构建
手搓图是不靠谱的,现有的ML生成图可能生成没关系的关系,所以提出了半自动的图生成方案。
- 图的初始化:这一部分是手动生成的,根据规则来定义trigger vertices。trigger vertices一旦生成,其关联的metric vertex、experience vertex等会自动生成。这部分有点像人类DBA指导创建知识草图,总的框架不能动,不能生成一些稀奇古怪的东西。
- 图的存放:就是放到Neo4J里;另外,不同的数据库类型通过tag来标记,这样很多知识是通用的,也避免了重复构建图。
- 图的增强:生成更多的边
- 图的更新:DBAIOps支持增量更新。这里的更新不仅指新增新的vertex,也包括去掉老的vertex
异常模型
metric
metric的来源有很多,包括运行信息(CPU %,吞吐等日常监控)、日志、trace等等,再加上相关性的差异,还需要从中取出关联性较强的metric。所以将metric分成了2类:
- 立即收集的metric:运行信息、日志、trace
- 后续收集的metric:周期、delta等metric,需要的时候再生成,比如AWR/ASH数据
在metric和异常相关性上,不同于基于基线的关联方式,DBAIOps采用每种异常都基于特定的metric组合。
最后通过一个公式来判断是否确实发生异常:

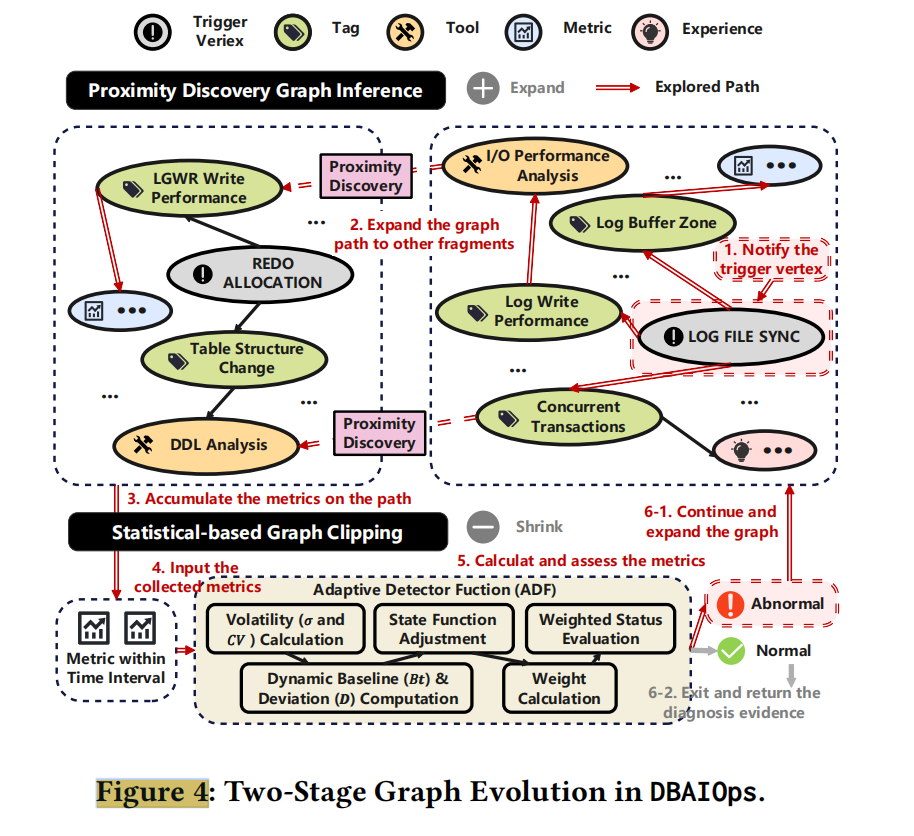
两阶段图演化
数据库异常很少孤立发生,一个性能问题可能同时触发或恶化其他问题。然而,预构建的知识图谱中不同异常模型 (如 LOG_FILE_SYNC 和 REDO_ALLOCATION) 之间的连接往往松散,共享的经验片段稀疏且碎片化。这导致传统方法难以发现跨模型的复合根因,如 I/O 瓶颈与内存压力的组合问题。
为解决这一挑战,DBAIOps 提出了自动 "图演化" 机制,动态发现并连接不同异常模型间的相关经验片段,使知识图谱从初始的稀疏结构逐步演化为密集互联的网络,从而支持更全面的根因分析。
-
第一阶段-Graph Inference and Proximity Discovery (图推理与邻近发现):通过图查询语言 (Cypher) 收集和聚合相关指标,基于可配置阈值遍历相关节点和边,构建关联网络。例如LOG_FILE_SYNC 延迟,从顶点出发,遍历最多 3 跳的关联节点。在 LOG_FILE_SYNC 和 REDO_ALLOCATION 模型间建立连接,因为它们都与 I/O 相关的并发问题有关。通过多次迭代,知识图谱逐渐演变为更密集的结构,使诊断能考虑更多潜在因素和复合原因。
-
第二阶段-Adaptive Abnormal Metric Detection (自适应异常指标检测):在图扩展路径上识别真正异常的指标。通过自适应检测函数(ADF),结合指标波动性、动态基线偏差等维度计算综合异常分数,依据异常评分结果,决定是否需要进一步扩展知识图谱结构,为后续 LLM 的根因推理筛选出精准的异常指标子集。
生成分析报告
图搞定后,就需要prompt喂给LLM来生成想要的报告,一个合理的prompt也可以提升报告的准确性。
异象有5种成分,这5种成分作为prompt给LLM:
- Anomaly:异常描述("CPU usage spiked to 95% at 16:00 on 2023-10-05")
- Condition:异常触发条件("exceeds 90% for >5 min")
- Metrics
- Experience:提供正常负载值,或者最近的维护任务
- Output:描述报告的组成的。有异常验证(需要继续分析的)、根因分析、恢复方案、汇总、SQL文本
自己的一点想法:
最近的维护任务很有用,维护任务一般来说关联性是比较大的,故障分析也不是能是简单的技术分析。不过谁去更新这个维护任务、哪些要更新哪些不更新应该是问题。
output中前几个都好理解,最后一个SQL文本可谓神来一笔。在生产环境中,抛开硬件故障,数据库的运行状态跟SQL是强相关的,我个人认为可以无脑抓SQL,抓出来再说因果关系的问题。从运维工作的角度来讲,故障都需要跟开发共同排查,那么SQL文本基本是必抓取的。
评估
不同工具、方式下,生成的分析报告的效果对比:
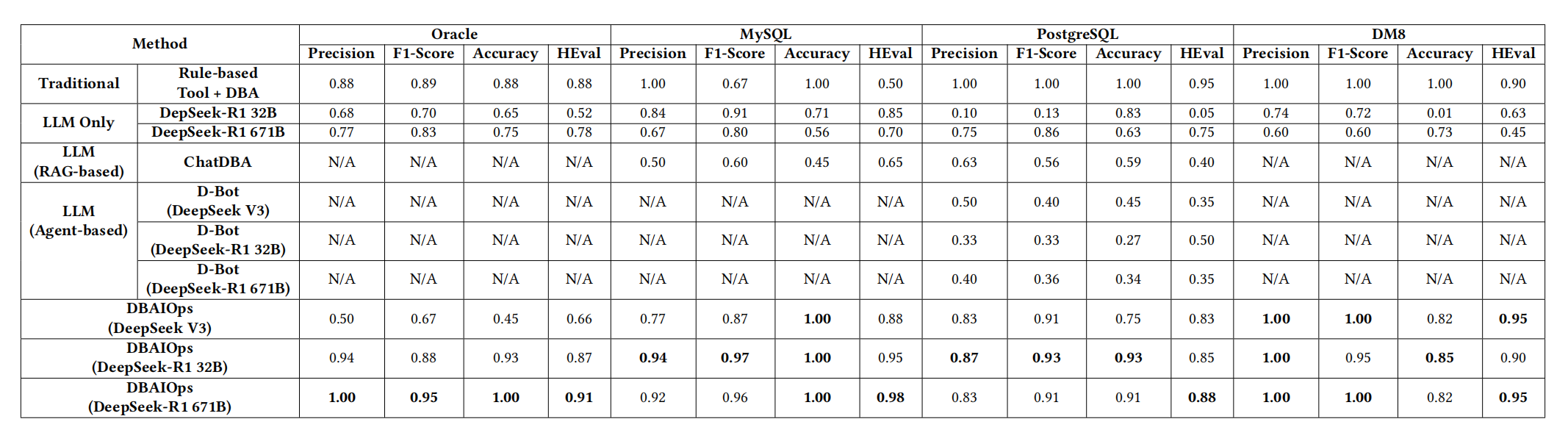
可以看出来很强了。特别要注意的是,DBAIOps特别强调了中型大模型的分析效果就已经很好了。这个还是比较重要的,DeepSeek-R1 671B裸跑就不差,但是成本不是一个级别的。
挑点刺
1.不能完全叫Ops,只是有故障分析功能。Ops内容是很多的,故障分析只是冰山一角。
2.图的分类和图的示例对不上号。定义的tag vertex和edge跟示例的差别比较大。
示例中的vertex作用很大,但是没有定义这些边的类型:tag vertex-tool vertex、tag vertex-experience vertex、tag vertex-metric vertex。而应该存在的边,看上去基本都没有,只有一个sysnonym edge。
应该列举出来示例中没有说明的部分,不然看的云里雾里的。
3.两阶段图演化的效果有点怪:
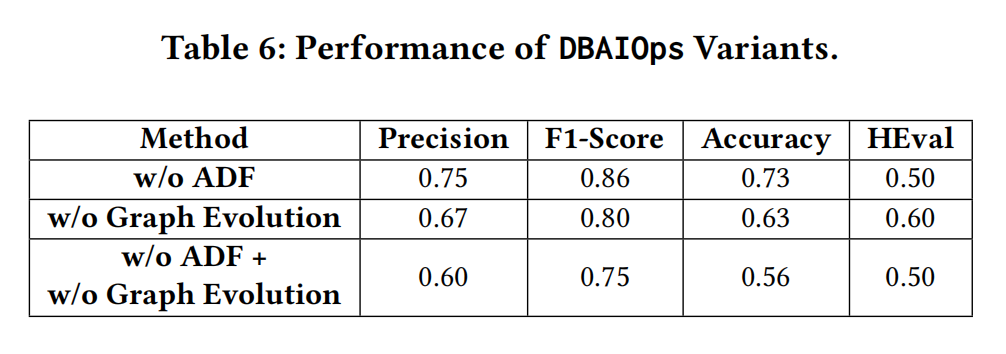
w/o ADF代表没有第二阶段图演化(自适应异常指标检测)
w/o ADF代表没有第一阶段图演化(图推理与邻近发现)
w/o ADF代表两个阶段都没有的图演化
这里少了两阶段都有的图演化,有的话就更能说明两阶段图演化的效果。
4.根因有些少:

上面几个圈起来的应该是比较常见的(我只看了oracle、postgres),但是暂时没有这些根因。
pg的根因有点少,刷脏一般不算太大的问题,刷脏根因本身,大概率排到众多根因的后面了。
总结
我个人非常喜欢的点:
1.GraphRAG在故障诊断方面,应该会比vector RAG好。
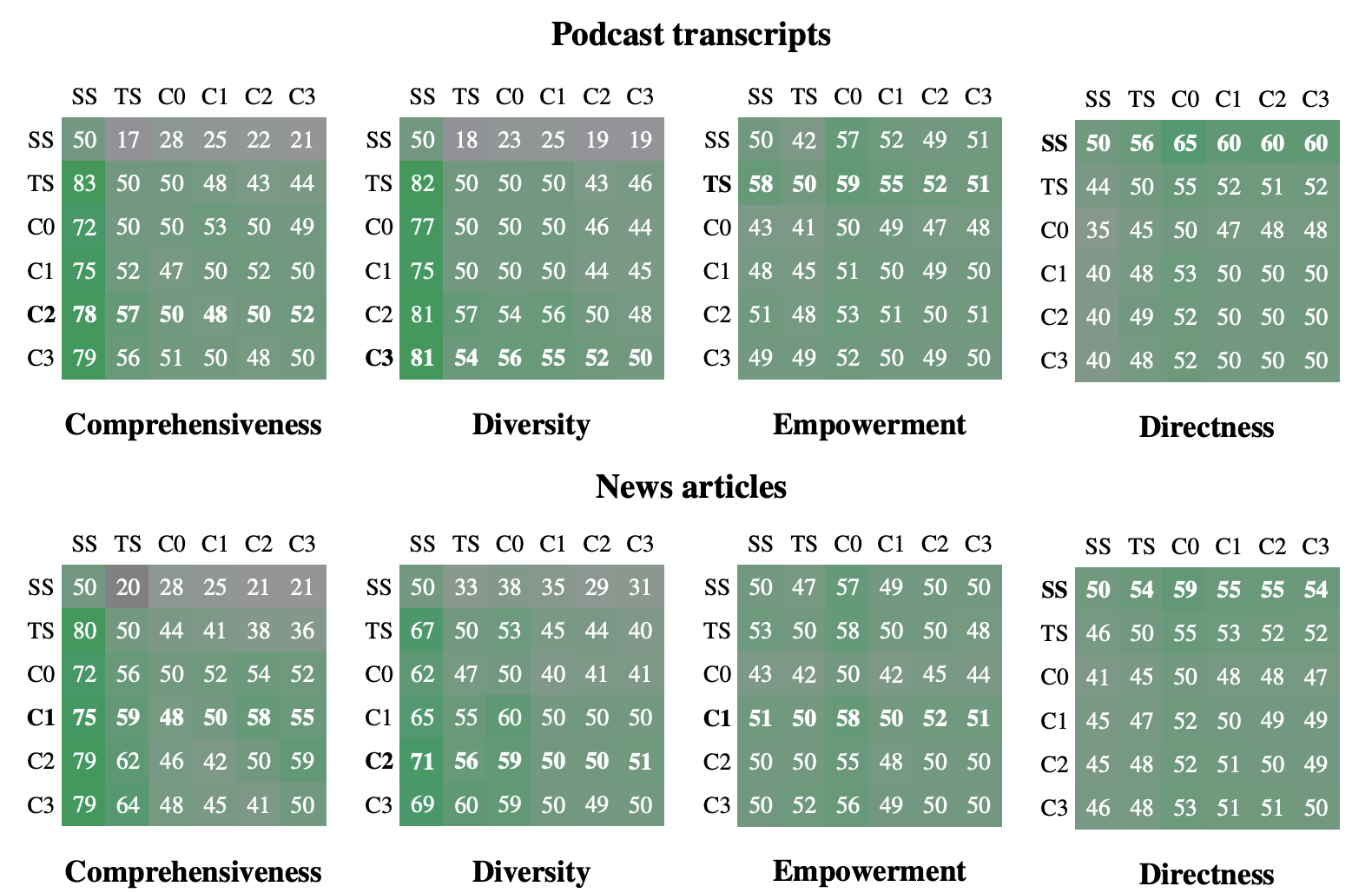
(GraphRAG原始论文:From Local to Global: A GraphRAG Approach to Query-Focused Summarization)
SS代表vector RAG,TS代表源文本摘要,C0/C1/C2/C3代表不同知识粒度的GraphRAG。从这个图可以简单得出结论:GraphRAG更适合多预料复杂场景,多角度分析,但在精准度上其实不一定比vectorRAG好
2.半自动的图生成方案
图生成是半自动的,trigger vertex手搓,其他可以自动生成。例如LOG FILE SYNC就是trigger vertex。故障的入口确实可以做出明显的异常点,这就是入口,PG也是一样的,任何故障应该也是一样的,符合人类对故障的理解逻辑。
3.自动图演化
加强某些vertex的关联性,是有意义的,Performance of DBAIOps Variants表格可见一斑
4.自动基线调整
在《可观测性工程》中对AIOps有这么一段话:
AI只有在存在清晰可辨的模式并且可以识别不断变化的基线来进行预测时才能提供帮助------目前还没有这种AIOps
DBAIOps在我的眼中
清晰可辨的模式= DBAIOps中的图,它包括了故障模型、异常关系、监控数据和日志
不断变化的基线= DBAIOps中的自适应异常指标检测
总之,比随意chunk故障知识、拍一个基线、vector近似搜索的RAG模型要进步很多了。