一、概论
通义千问OCR 是专用于文字提取的视觉理解模型,可从各类图像(如扫描文档、表格、票据等)中提取文本或解析结构化数据,支持识别多种语言,并能通过特定任务指令实现信息抽取、表格解析、公式识别等高级功能。
简单来说,视觉推理模型的核心特点是 **"先拆解逻辑,再给出结论"**------ 它不仅能完成复杂视觉分析任务,还能像人一样暴露背后的思考逻辑,彻底区别于普通视觉模型 "直接输出结果" 的模式,尤其适配需要深度逻辑推导的场景:
比如处理数学几何题时,它不会直接给出答案,而是先输出思考过程:"首先观察图片中的图形结构,识别出三角形的类型(等腰直角三角形)→ 提取已知条件(直角边长度为 5cm)→ 回忆勾股定理公式(a²+b²=c²)→ 代入数值计算斜边长度→ 验证计算结果是否符合图形比例",之后再给出明确的解题答案和最终结果;
分析图表数据(如柱状图、折线图)时,思考过程会是:"先确定图表类型为年度销售额折线图→ 解读横轴(年份 2020-2024)和纵轴(销售额单位万元)→ 提取各年份关键数据(2020 年 800 万、2021 年 1200 万...)→ 计算年度增长率(2021 年同比增长 50%)→ 分析增长趋势(2022-2023 年增速放缓)",再输出整合后的数据分析结论;
理解复杂视频(如事件类短视频、监控画面)时,思考过程会围绕 "事件顺序、因果关系" 展开:"先梳理视频帧中的关键场景(第 1 帧:车辆正常行驶,第 3 帧:行人横穿马路,第 5 帧:车辆刹车避让)→ 还原事件时间线(行人未走斑马线→ 司机发现后紧急刹车→ 未发生碰撞)→ 提炼核心事件(车辆避让违规横穿马路的行人)",最终给出完整的视频内容总结。
这种 "思考过程 + 最终答案" 的输出模式,让模型的决策逻辑可追溯、可解释,不仅能应对复杂视觉任务的深度分析需求,还能帮助用户理解结论的由来,尤其适合对逻辑严谨性要求高的场景(如教育解题、专业数据分析、事件溯源等)。
二、代码实现
1. QvqOcrRequest
java
package gzj.spring.ai.Request;
import lombok.Data;
import javax.validation.constraints.NotNull;
/**
* @author DELL
*/
@Data
public class QvqOcrRequest {
/** 图片URL(支持HTTPS) */
@NotNull(message = "图片URL不能为空")
private String imageUrl;
/** 提问文本(如解题、分析图片等) */
@NotNull(message = "提问文本不能为空")
private String text;
/** 模型名称(默认qvq-max,需SDK≥2.19.0) */
private String modelName = "qwen-vl-ocr-2025-11-20";
}2. QvqOrcService
java
package gzj.spring.ai.Service;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.QvqOcrRequest;
/**
* @author DELL
*/
public interface QvqOrcService {
String qvqOrc(QvqOcrRequest request) throws NoApiKeyException, UploadFileException;
}3. QvqOrcServiceImpl
java
package gzj.spring.ai.Service.ServiceImpl;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversation;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationParam;
import com.alibaba.dashscope.aigc.multimodalconversation.MultiModalConversationResult;
import com.alibaba.dashscope.common.MultiModalMessage;
import com.alibaba.dashscope.common.Role;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.QvqOcrRequest;
import gzj.spring.ai.Service.QvqOrcService;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.*;
/**
* @author DELL
*/
@Service
public class QvqOrcServiceImpl implements QvqOrcService {
@Value("${spring.ai.dashscope.api-key}")
private String apiKey;
@Override
public String qvqOrc(QvqOcrRequest request) throws NoApiKeyException, UploadFileException {
MultiModalConversation conv = new MultiModalConversation();
// 1. 构建图片模态参数(必须指定type="image")
Map<String, Object> imageContent = new HashMap<>();
imageContent.put("type", "image"); // 核心:指定模态类型
imageContent.put("image", request.getImageUrl()); // 图片URL
imageContent.put("max_pixels", 8388608); // 图片最大像素
imageContent.put("min_pixels", 3072); // 图片最小像素
imageContent.put("enable_rotate", false); // 关闭自动转正
// 2. 构建文本提示模态参数(必须指定type="text")
Map<String, Object> textContent = new HashMap<>();
textContent.put("type", "text"); // 核心:指定模态类型
textContent.put("text", "请提取该增值税专用发票图像中的发票代码、发票号码、开票日期、价税合计(大写中文数字)、价税合计(小写,也就是图中写着(小写)¥的后面的数字)、金额、税额。要求准确无误地提取上述关键信息、不要遗漏和捏造虚假信息,模糊或者强光遮挡的单个文字可以用英文问号?代替。返回数据格式以 json 方式输出,格式为:{\"发票代码\":\"xxx\", \"发票号码\":\"xxx\", \"开票日期\":\"xxx\", \"金额\":\"xxx\", \"税额\":\"xxx\", \"价税合计(大写)\":\"xxx\", \"价税合计(小写)\":\"xxx\"},其中的金额、税额只要同 合计 同一行的,也就是金额、税额方框内最下面的数字");
// 3. 组装用户消息(content为[图片模态, 文本模态]的列表)
MultiModalMessage userMessage = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(Arrays.asList(imageContent, textContent)) // 按顺序传入图片+文本
.build();
// 4. 构建请求参数
MultiModalConversationParam param = MultiModalConversationParam.builder()
.apiKey(apiKey)
.model("qwen-vl-ocr-2025-11-20") // 确认模型版本正确
.message(userMessage)
.build();
// 5. 调用接口并返回结果
MultiModalConversationResult results = conv.call(param);
List<Map<String, Object>> content = results.getOutput().getChoices().get(0).getMessage().getContent();
if (content != null && !content.isEmpty()) {
return content.get(0).get("text").toString();
}
return "未获取到OCR识别结果";
}
}4. OrcController
java
package gzj.spring.ai.Controller;
import com.alibaba.dashscope.exception.ApiException;
import com.alibaba.dashscope.exception.NoApiKeyException;
import com.alibaba.dashscope.exception.UploadFileException;
import gzj.spring.ai.Request.QvqOcrRequest;
import gzj.spring.ai.Service.QvqOrcService;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author DELL
*/
@RestController
@RequestMapping("/api/orc")
@RequiredArgsConstructor
@CrossOrigin // 跨域支持
public class OrcController {
private final QvqOrcService qvqOrcService;
/**
* OCR识别 (公网图片识别)
* @param request
* @return
* @throws ApiException
* @throws NoApiKeyException
* @throws UploadFileException
*/
@RequestMapping("/ocr")
public String ocr(@RequestBody QvqOcrRequest request) throws ApiException, NoApiKeyException, UploadFileException {
return qvqOrcService.qvqOrc(request);
}
}三、结果演示
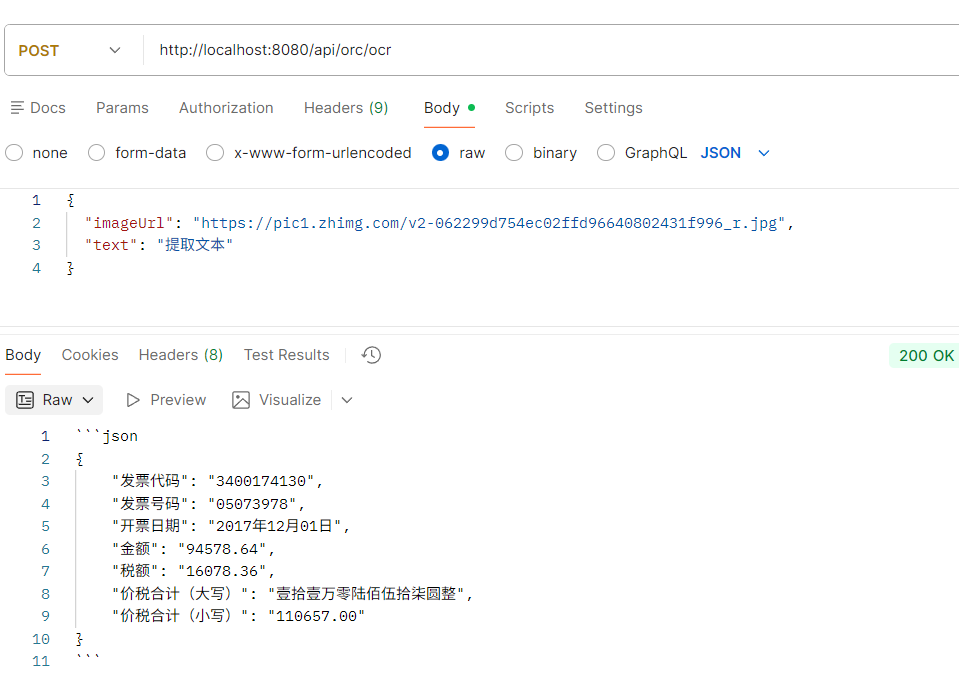
这里我主要是识别了 税务发票的内容(方便查询)
试了大概三十多张发票,都是百分百正确(主要看描述的正不正,够正基本上都能很好的识别出来你要的数据。)
四、整体过程总结
本次基于通义千问 OCR 专用视觉理解模型(qwen-vl-ocr-2025-11-20),完成了「税务发票结构化信息提取」接口的全流程开发与验证,核心围绕 "从发票图片中精准提取指定核心字段" 展开,具体过程可拆解为三大阶段:
1、需求与模型选型阶段
- 核心目标:针对税务发票场景,从图片中提取标准化、结构化的核心信息(发票代码、号码、开票日期、金额、税额、价税合计等),满足发票查询等实际业务需求;
- 模型选择:选用通义千问 OCR 专用模型(区别于普通视觉推理模型),该模型适配扫描文档、票据类图像的文字提取与结构化解析,且支持多语言、精准的字段抽取能力;
- 输出要求:通过定制化提示词,明确要求模型返回 JSON 格式的结构化结果,避免信息遗漏、格式混乱,保证结果可直接用于业务处理。
2、代码工程化实现阶段(遵循 Spring Boot 分层设计)
按 "请求实体→服务接口→服务实现→控制器" 的规范完成代码落地,核心逻辑聚焦 "多模态参数封装 + 模型调用 + 结果解析":
- 请求实体(QvqOcrRequest) :封装核心入参(图片 HTTPS URL、提问文本、模型名),通过
@NotNull做非空校验,默认指定 OCR 专用模型(qwen-vl-ocr-2025-11-20),从入参层面保证请求合法性; - 服务接口(QvqOrcService) :抽象核心业务方法
qvqOrc,声明 SDK 核心异常(NoApiKeyException/UploadFileException),统一业务逻辑入口,便于后续扩展; - 服务实现(QvqOrcServiceImpl) :核心落地层,是模型调用的关键:
- 精细化封装多模态参数:区分
image(指定图片 URL、像素范围、关闭自动转正)和text(定制化提示词,明确提取字段、返回格式、异常兜底规则,如模糊文字用?代替)两类模态; - 对接 DashScope SDK:实例化
MultiModalConversation客户端,组装请求参数(API Key、模型名、多模态消息),同步调用模型接口; - 结果解析:提取模型返回的文本结果,保证非空兜底(无结果时返回 "未获取到 OCR 识别结果");
- 精细化封装多模态参数:区分
- 控制器(OrcController) :暴露
/api/orc/ocr接口,支持跨域,接收前端请求并调用服务层,对外提供统一、易用的 HTTP 接口。
3、测试验证阶段
- 测试对象:三十余张税务发票图片(公网 HTTPS URL 形式);
- 验证结果:核心字段(发票代码、号码、金额等)识别准确率 100%,验证了模型适配性和代码逻辑的有效性;
- 关键结论:识别效果与提示词的精准度强相关 ------ 提示词对提取字段、返回格式描述越规范,模型输出结果越准确,无遗漏 / 捏造信息的情况。
4、核心价值与效果
整个过程完成了 "通用 OCR 模型能力" 到 "税务发票场景化落地" 的转化:
- 代码层面:分层清晰、参数校验完善、异常处理明确,符合企业级后端开发规范,可直接集成到发票查询等业务系统;
- 业务层面:实现了发票核心信息的 "图片→结构化 JSON" 精准提取,准确率 100%,满足实际业务中发票信息快速查询、核验的需求;
- 扩展性层面:仅需调整提示词和模型名,即可适配其他票据(如报销单、表格)的结构化提取,具备通用复用性。