最近在做一个 Text-to-SQL 的 Agent 项目 EasySQL,这篇文章就把我langfuse的score应用整理一下,代码都是从项目里直接搬的,请小伙伴们高抬贵手点点star,欢迎共建、交流。
什么是score
Score 是 Langfuse 中用于存储评估结果的核心数据对象。你可以把它理解为:给一次 LLM 交互打分。它可以挂载到 Trace(一次完整请求)、Observation(某个具体 Span/Generation)、Session(多轮对话)上。
三种score类型
| 类型 | 值域 | 典型场景 |
|---|---|---|
| NUMERIC | 浮点数flaot(如0.92) | 相关性得分、SQL 质量 0-1 |
| CATEGORICAL | 预定义字符串 string(如 "correct", "partial", "wrong") | 分级标签:correct / partial / wrong |
| BOOLEAN | 0 或 1 | sql验证通过/不通过、用户点赞/踩 |
Score的四种来源
| 来源 | 说明 | 典型场景 |
|---|---|---|
| User Feedback | 用户显式反馈(点赞/踩、评论) | 前端 thumbs up/down |
| Model-Based Evals | 用另一个 LLM 当评委打分 | LLM-as-a-Judge 自动评估 |
| Manual Annotation | 人工在 Langfuse UI 中标注 | 人工审核队列 |
| Custom / Programmatic | 代码计算后通过 SDK 提交 | 验证通过率、检索精确度 |
Score的数据模型
| 字段 | 类型 | 说明 |
|---|---|---|
| name | string | 分数名称标识(如 "sql_validation") |
| value | float/int/string | 分数值 |
| data_type | enum | NUMERIC、CATEGORICAL、BOOLEAN |
| trace_id | string | 关联到哪条 trace |
| session_id | string | 关联到哪个 session |
| comment | string | 附加说明 |
Score的三层关联
Session(会话)
└── Trace(单次请求链路) ← trace-level score
└── Observation(单步操作) ← observation-level score
- Trace-level: 评估一次完整的请求响应
- Session-level: 评估整个会话的满意度
- Observation-level: 评估具体某一步(如检索、生成)
Python SDK 创建 Score 示例
直接调用底层 API
python
from langfuse import Langfuse
langfuse = Langfuse(public_key="...", secret_key="...", host="...")
# 数值型 score
langfuse.score(
trace_id="trace-xxx",
name="retrieval_precision",
value=0.85,
data_type="NUMERIC",
comment="retrieved=10 used=8"
)
# 布尔型 score
langfuse.score(
trace_id="trace-xxx",
name="sql_validation",
value=1,
data_type="BOOLEAN"
)手动指定 trace_id 和 observation_id 来打分。最灵活,但需要你自己管理这些 ID。
通过上下文管理器中的 span 对象打分
python
# Method 2: Score current span/generation (within context)
with langfuse.start_as_current_observation(as_type="span", name="my-operation") as span:
# Score the current span
span.score(
name="correctness",
value=0.9,
data_type="NUMERIC",
comment="Factually correct"
)
# Score the trace
span.score_trace(
name="overall_quality",
value=0.95,
data_type="NUMERIC"
)通过上下文管理器中的 span 对象打分
with ... as span 做了两件事:
- 创建一个 span 并将其设为"当前上下文"(current context)
- 把这个 span 对象赋给变量 span
context(上下文) 的含义:Langfuse内部维护了一个线程级别的上下文栈。start_as_current_observation 会把新建的 span 压入栈顶,with块结束时自动弹出。这样在 with 块内部,Langfuse 就知道"当前正在执行的操作是哪个 span"。
- span.score() --- 对这个具体的 span(即这一步操作)打分
- span.score_trace() --- 对这个 span 所属的整条 trace(即整个请求链路)打分
通过全局上下文函数打分
python
# Method 3: Score via the current context
with langfuse.start_as_current_observation(as_type="span", name="my-operation"):
# Score the current span
langfuse.score_current_span(
name="correctness",
value=0.9,
data_type="NUMERIC",
comment="Factually correct"
)
# Score the trace
langfuse.score_current_trace(
name="overall_quality",
value=0.95,
data_type="NUMERIC"
)langfuse.score_current_span给当前的上下文的span打分langfuse.score_current_trace给当前上下文的trace打分
和 Method 2 的区别:不需要持有 span 变量的引用。Langfuse 从内部上下文栈中自动找到当前的 span和trace。 这在深层嵌套调用中很有用------你在某个被调用的函数里,拿不到外层的 span 变量,但仍然可以通过langfuse.score_current_span() 给它打分。
Span 和 Trace打分的使用场景
| 打分对象 | 适用场景 | 示例 |
|---|---|---|
| Span | 评价某个具体步骤的质量 | "检索步骤"的相关性得分、"LLM 调用"的准确性 |
| Trace | 评价整条链路的整体质量 | 最终回答的用户满意度、端到端的正确性 |
简单类比:trace 像一次考试的总分,span 像每道题的得分。(那么session就是一次月考的所有科目的总分和)
Easysql项目实战使用案例分享
Langfuse 连接配置
配置定义在 easysql/config.py文件中
python
class LangfuseConfig(BaseSettings):
enabled: bool = Field(default=False, alias="langfuse_enabled")
public_key: str | None = Field(default=None, alias="langfuse_public_key")
secret_key: str | None = Field(default=None, alias="langfuse_secret_key")
host: str = Field(default="https://cloud.langfuse.com", ...)
def is_configured(self) -> bool:
return bool(self.enabled and self.public_key and self.secret_key)在 .env 中设置:
python
LANGFUSE_ENABLED=true
LANGFUSE_PUBLIC_KEY=pk-lf-xxx
LANGFUSE_SECRET_KEY=sk-lf-xxx
LANGFUSE_HOST=https://cloud.langfuse.comTrace的创建和Handler的绑定
在每次请求都会创建独立的 CallbackHandler
python
def create_langfuse_handler(*, session_id=None, tags=None):
from langfuse.langchain import CallbackHandler
kwargs = {}
if session_id:
kwargs["session_id"] = session_id
if tags:
kwargs["tags"] = tags
return CallbackHandler(**kwargs)将 handler 注入 LangGraph 配置:
python
def _make_config(self, session_id, thread_id=None):
config = {"configurable": {"thread_id": effective_thread_id}}
if self.langfuse_enabled:
handler = create_langfuse_handler(
session_id=session_id,
tags=["text2sql"],
)
config["callbacks"] = [handler]
config["configurable"]["_langfuse_handler"] = handler
return config这样 LangGraph 执行过程中所有 LLM 调用、工具调用都会被自动记录为 Langfuse trace 下的observations。
在API服务中提取traceid并提交相关score
获取traceid
python
@staticmethod
def _extract_trace_id(config: RunnableConfig) -> str | None:
"""Extract the Langfuse trace ID from the per-request callback handler."""
handler = config.get("configurable", {}).get("_langfuse_handler")
if handler is None:
return None
try:
trace_id: str | None = handler.get_trace_id() # type: ignore[union-attr]
return trace_id
except Exception: # noqa: BLE001
return None获取到trace后,将traceid传给前端(这是为了方便用户进行生成质量的评分),同时会自动对生成的内容进行评分并提交到langfuse
python
# Submit automatic scores to Langfuse
trace_id = self._extract_trace_id(config)
if trace_id:
response["langfuse_trace_id"] = trace_id
get_scoring_service().submit_query_scores(trace_id, result)trace_id 同时被返回给前端(通过 SSE 的 complete 事件或 JSON 响应),以便前端后续提交用户反馈。
项目定义的 Score 指标详解
自动指标(submit_query_scores实现)
sql是否成功生成:sql_validation
Score 名称: sql_validation
数据类型: BOOLEAN
值说明: SQL 是否通过语法/语义验证(1=通过, 0=失败)
python
# 1. SQL validation (boolean)
self.score_trace(
trace_id,
"sql_validation",
1 if validation_passed else 0,
data_type="BOOLEAN",
)作用:衡量 LLM 生成的 SQL 是否在语法和语义上正确。这是 Text2SQL 系统最基本的质量指标。在Langfuse dashboard 中,你可以看到 sql_validation 的通过率趋势------如果通过率下降,说明 LLM或prompt 出了问题。
sql生成重试次数:retry_count
Score 名称: retry_count
数据类型: NUMERIC
值说明: SQL 生成的重试次数(0 表示一次成功)
python
self.score_trace(
trace_id,
"retry_count",
float(retry_count),
data_type="NUMERIC",
)作用:记录 SQL 生成了几轮才最终通过验证。retry_count=0 表示一次性生成正确 SQL。这个值直接反映
- LLM 的生成质量:retry 多说明初次生成容易出错
- 修复能力:能否在 2-3 次重试内修好
- 成本:每次重试都是一次 LLM 调用,retry_count 直接关联 token 消耗
一次就成功:first_attempt_success
Score 名称: first_attempt_success
数据类型: BOOLEAN
值说明: 是否首次尝试就成功(retry_count<=1 且 validation_passed)
python
# 3. First-attempt success (boolean)
self.score_trace(
trace_id,
"first_attempt_success",
1 if retry_count <= 1 and validation_passed else 0,
data_type="BOOLEAN",
)作用:这是最核心的"黄金指标"。它衡量系统是否能一次性给出正确 SQL。在 Langfuse 中可以直接看到first_attempt_success 的百分比趋势------这是向业务方汇报的最直观指标。
rag检索精度指标:retrieval_precision
Score 名称: retrieval_precision
数据类型: NUMERIC
值说明: 检索精确度 = 实际被 SQL 使用的表数 / 检索召回的表数
python
# 4. Retrieval precision -- overlap of retrieved vs actually-used tables
retrieval_result = result.get("retrieval_result") or {}
retrieved_tables = set(retrieval_result.get("tables", []))
sql = result.get("generated_sql") or ""
if retrieved_tables and sql:
used_tables = _extract_table_names(sql)
if used_tables:
precision = len(retrieved_tables & used_tables) / len(retrieved_tables)
self.score_trace(
trace_id,
"retrieval_precision",
round(precision, 4),
data_type="NUMERIC",
comment=f"retrieved={len(retrieved_tables)} used={len(used_tables)}",
)作用:衡量 Milvus 语义检索 + Neo4j FK 扩展后,召回的表有多少真正被 SQL 使用了。例如:
- 检索了 10 张表,SQL 只用了 3 张 → precision = 0.3(低,说明检索了太多无关表)
- 检索了 5 张表,SQL 用了 4 张 → precision = 0.8(好)
这个指标直接反映 retrieval pipeline 的质量:
- 低 precision → filter chain(semantic→bridge→LLM filter)需要优化,减少噪声表
- 高 precision → 检索准确,context 中无关信息少,LLM 更容易生成正确 SQL
这里如果一味的追求召回精度可能会使得sql生成质量下降,这是一个权衡和调节的过程,正因为有了langfuse的监控,我们可以去根据数据去追求这个平衡点而不是根据个人感觉。
few-shot命中情况:few_shot_used
数据类型: BOOLEAN
值说明: 本次生成是否使用了 few-shot 示例
python
few_shot_examples = result.get("few_shot_examples") or []
self.score_trace(
trace_id,
"few_shot_used",
1 if few_shot_examples else 0,
data_type="BOOLEAN",
)作用:记录本次生成是否利用了 few-shot 示例。结合 first_attempt_success 可以分析:
- few_shot_used=1 时的成功率 vs few_shot_used=0 时的成功率
- 如果差异显著,说明 few-shot 示例质量高,应该继续积累
用户反馈指标
用户对单次生成的评价
Score 名称: user_feedback
数据类型: BOOLEAN
触发方式: 用户点击 👍(1) 或 👎(0)
python
@router.post("/feedback/message", response_model=FeedbackResponse)
async def submit_message_feedback(
request: MessageFeedbackRequest,
) -> FeedbackResponse:
"""Submit user feedback for a single generated SQL (trace-level score)."""
scoring = get_scoring_service()
scoring.score_trace(
trace_id=request.trace_id,
name="user_feedback",
value=request.score,
data_type="BOOLEAN",
comment=request.comment,
)
logger.info(
"User feedback submitted: trace_id=%s score=%d",
request.trace_id,
request.score,
)
return FeedbackResponse()作用:这是最真实的质量信号。即使 SQL 语法正确(validation_passed=true),用户仍可能不满意(SQL逻辑不对、返回的不是想要的数据)。user_feedback 捕获了 validation 无法检测到的语义正确性。
用户对整个会话的评价
Score 名称: session_satisfaction
数据类型: BOOLEAN
触发方式: 用户对整个 session 打分
python
@router.post("/feedback/session", response_model=FeedbackResponse)
async def submit_session_feedback(
request: SessionFeedbackRequest,
) -> FeedbackResponse:
"""Submit user feedback for an entire session (session-level score)."""
scoring = get_scoring_service()
scoring.score_session(
session_id=request.session_id,
name="session_satisfaction",
value=request.score,
data_type="BOOLEAN",
comment=request.comment,
)
logger.info(
"Session feedback submitted: session_id=%s score=%d",
request.session_id,
request.score,
)
return FeedbackResponse()作用:评估多轮对话整体质量。一个 session 可能包含多次 SQL 生成,session_satisfaction反映用户对整个交互流程的满意度。
总结
本项目的 Langfuse Score 集成覆盖了 Text2SQL 系统的完整质量评估链路:
- 数据流: 前端 → API → ScoringService → Langfuse SDK → Langfuse Dashboard
- 5 个自动指标覆盖了从检索到生成到验证的全流程质量
- 2 个用户反馈指标捕获了自动化指标无法检测的语义正确性
- 所有 score 都是 fire-and-forget 模式,失败只记录日志不影响主流程
- trace_id 通过 SSE stream 的 complete事件传递到前端,使前端能将用户反馈精确关联到对应的 Langfuse trace
以上所有代码示例均来自我的开源项目 EasySQL ------ 一个 Text-to-SQL 智能体分析应用,项目地址:github.com/zaizaizhao/...。项目主要技术栈包括:
- LangGraph:构建多步骤 Agent 状态机,支持条件路由、Human-in-the-Loop 澄清、SQL 生成→验证→修复的迭代循环
- LangChain:LLM 调用抽象与 RunnableConfig 配置传递
- Langfuse:Callback + 手动 Span 双模式可观测性,实现全链路追踪与业务汇总
- PostgreSQL + AsyncPostgresSaver:LangGraph Checkpointer 状态持久化,支持多轮对话上下文
- FastAPI + Uvicorn:异步 API 服务层,提供流式 SSE 响应
- Milvus:向量数据库,用于 Schema 语义检索
- Neo4j: 图数据库,用于知识图谱构建
- Pydantic Settings:类型安全的配置管理,支持环境变量覆盖
项目示例
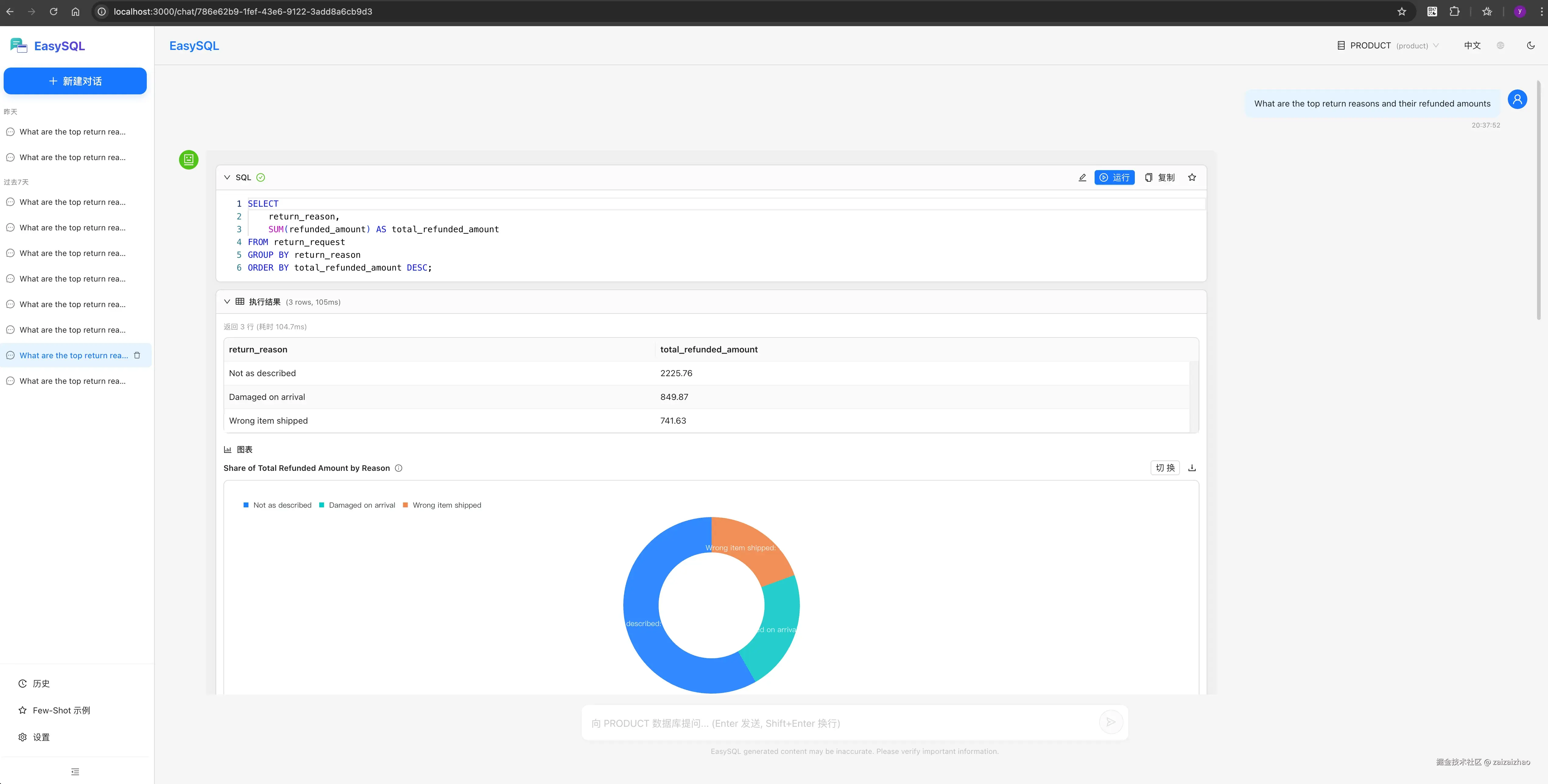
欢迎 Star ⭐ 和交流、共建!