最近在Github上发现了一个不错的开源项目,基于Java的ETL开发库,号称表数据导入速度是kettle的2倍,而且简单易用,推荐一波:add2ws/etl-engine-project: A fast & stable & flexible ETL tool.
🚀 项目简介
Etl-engine 是一个轻量、稳健、易扩展的面向开发者的 ETL(抽取、转换、加载)库,旨在成为 **Kettle (PDI) 的高性能替代方案。
🔥 核心优势
Etl-engine 提供以下三大核心特性:
1. 极致的速度 ⚡️
通过批量操作和非阻塞的缓存管道设计,显著提升数据处理和数据库 I/O 速度。
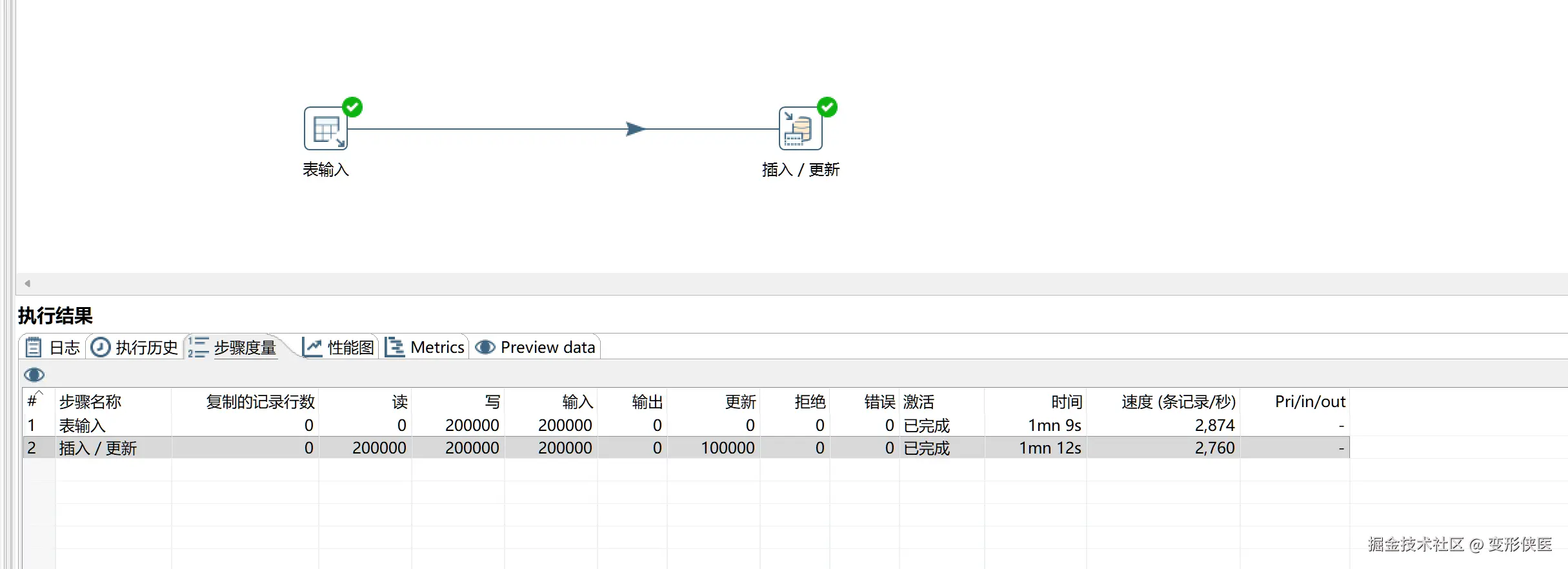
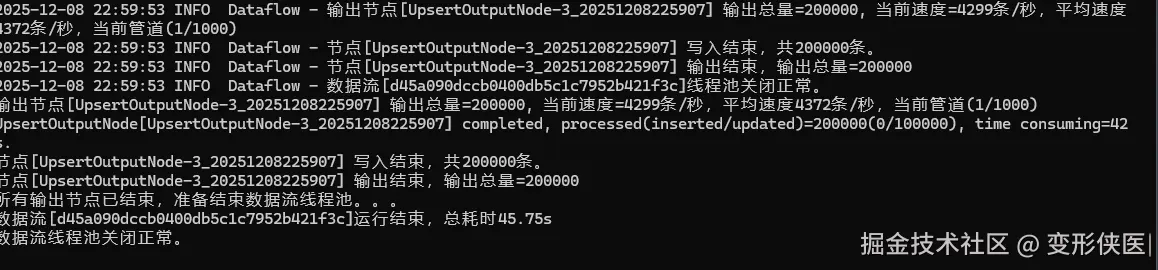
📊 实测数据: 处理 200,000 条数据的插入/更新任务,etl-engine 的速度是 Kettle 的 2 倍左右。
Kettle:
Etl-engine:
2. 运行稳健可靠 🛡️
数据流传输过程中如果遇到异常不会马上停止,自动尝试重新读取或写入数据。
3. 轻量且易于扩展 🧩
核心仅由 Node(节点) , Pipe(管道) , Dataflow(数据流) 3个主要组件构成,所有数据加载逻辑都抽象为可扩展的节点。除了内置的JDBC数据源节点,用户可以轻松继承基类,快速开发新的数据源(如 Http、Redis)或自定义转换逻辑,满足特定的业务需求。
🛠️ 使用示例
以下代码展示了如何快速构建一个将 Oracle 数据(抽取) 通过 Upsert 方式同步到 PostgreSQL(加载) 的 ETL 任务。
1. 一个表输入到一个表输出
flowchart LR
sqlInputNode --pipe--> upsertOutputNode
java
//创建Oracle数据源
DataSource dataSourceOracle = DataSourceUtil.getOracleDataSource();
//创建表输入节点
SqlInputNode sqlInputNode = new SqlInputNode(dataSourceOracle, "select * from t_resident_info");
//创建Postgres数据源
DataSource dataSourcePG = DataSourceUtil.getPostgresDataSource();
//创建插入/更新节点
UpsertOutputNode upsertOutputNode = new UpsertOutputNode(dataSourcePG, "t_resident_info", 1000);
//设置唯一标识(主键)映射,用于判断 Insert 或 Update
upsertOutputNode.setIdentityMapping(Arrays.asList(new Tuple2<>("ID", "ID")));
//创建管道,并设定缓冲区为1000条数据
Pipe pipe = new Pipe(1000);
//连接表输入和输出节点
pipe.connect(sqlInputNode, upsertOutputNode);
//创建数据流实例
Dataflow dataflow = new Dataflow(sqlInputNode);
//启动数据流,并设定5分钟后超时
dataflow.syncStart(5, TimeUnit.MINUTES);2. 一个表输入到多个输出
flowchart LR
sqlInputNode --pipe--> upsertOutputNode
sqlInputNode --pipe--> csvOutputNode
java
//创建Oracle数据源
DataSource oracleDataSource = DataSourceUtil.getOracleDataSource();
SqlInputNode sqlInputNode = new SqlInputNode(oracleDataSource, "select * from etl_base.t_resident_info where rownum<=50000 order by id");
//创建Postgres目标数据源
DataSource postgresDataSource = DataSourceUtil.getPostgresDataSource();
UpsertOutputNode upsertOutputNode = new UpsertOutputNode(postgresDataSource, "public.t_resident_info", 1000);
upsertOutputNode.setIdentityMapping(Arrays.asList(new Tuple2<>("ID","ID")));
//创建csv文件目标
FileOutputNode fileOutputNode = new FileOutputNode("E:/output_" + System.currentTimeMillis() + ".csv", FileOutputNode.Format.CSV);
//创建管道并连接Oracle和Postgres
Pipe pipe = new Pipe(1000);
pipe.connect(sqlInputNode,upsertOutputNode);
//创建管道并连接Oracle和csv文件
Pipe pipe_2 = new Pipe(1000);
pipe_2.connect(sqlInputNode,fileOutputNode);
//创建数据流并启动
Dataflow dataflow = new Dataflow(sqlInputNode);
dataflow.syncStart();🏗️ 架构概览
Etl-engine 核心仅由以下3个主要组件构成:
- Node (节点): 数据的起点、终点和数据转换逻辑载体。
- Pipe (管道): 负责在节点间传递数据的非阻塞缓存队列。
- Dataflow (数据流): 任务的编排器和执行入口。