文章目录
-
- [1. 环境配置与浏览器启动](#1. 环境配置与浏览器启动)
- [2. 文件上传操作](#2. 文件上传操作)
- [3. 搜索框交互](#3. 搜索框交互)
- [4. 图片批量下载](#4. 图片批量下载)
- [5. 分页数据抓取](#5. 分页数据抓取)
- [6. 商品信息抓取](#6. 商品信息抓取)
1. 环境配置与浏览器启动
首先需要配置 Selenium 环境并启动浏览器。以下是使用 Microsoft Edge 浏览器的基本设置:
python
import os.path
import time
import requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)2. 文件上传操作
Selenium 可以模拟用户上传文件的操作。以下代码展示了如何通过文件输入框上传本地图片:
python
driver.get("https://graph.baidu.com/pcpage/index?tpl_from=pc")
input_element = driver.find_element(by=By.NAME, value="file")
input_element.send_keys(r"D:\Code\PythonTest\Picture1\1.jpg")
time.sleep(5)
element = driver.find_element(by=By.CLASS_NAME, value="graph-guess-word")
print(element.text)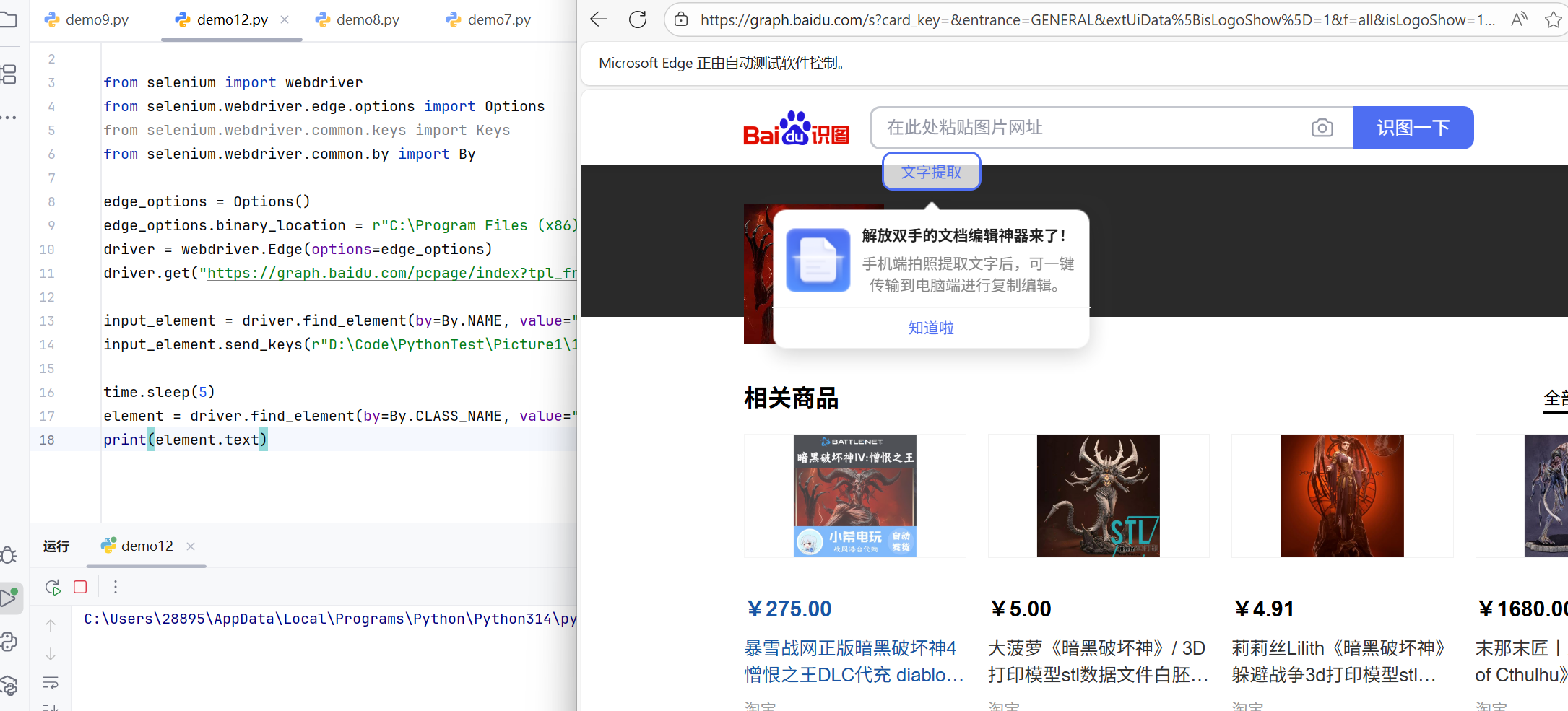
分析:
send_keys()方法用来向文件输入框传递本地文件路径
3. 搜索框交互
自动化搜索是常见的 Web 交互场景。以下示例展示了如何在 B 站搜索内容:
python
driver.get('http://www.bilibili.com')
driver.find_element(by=By.TAG_NAME,value="input").send_keys("python"+ Keys.RETURN)
time.sleep(5)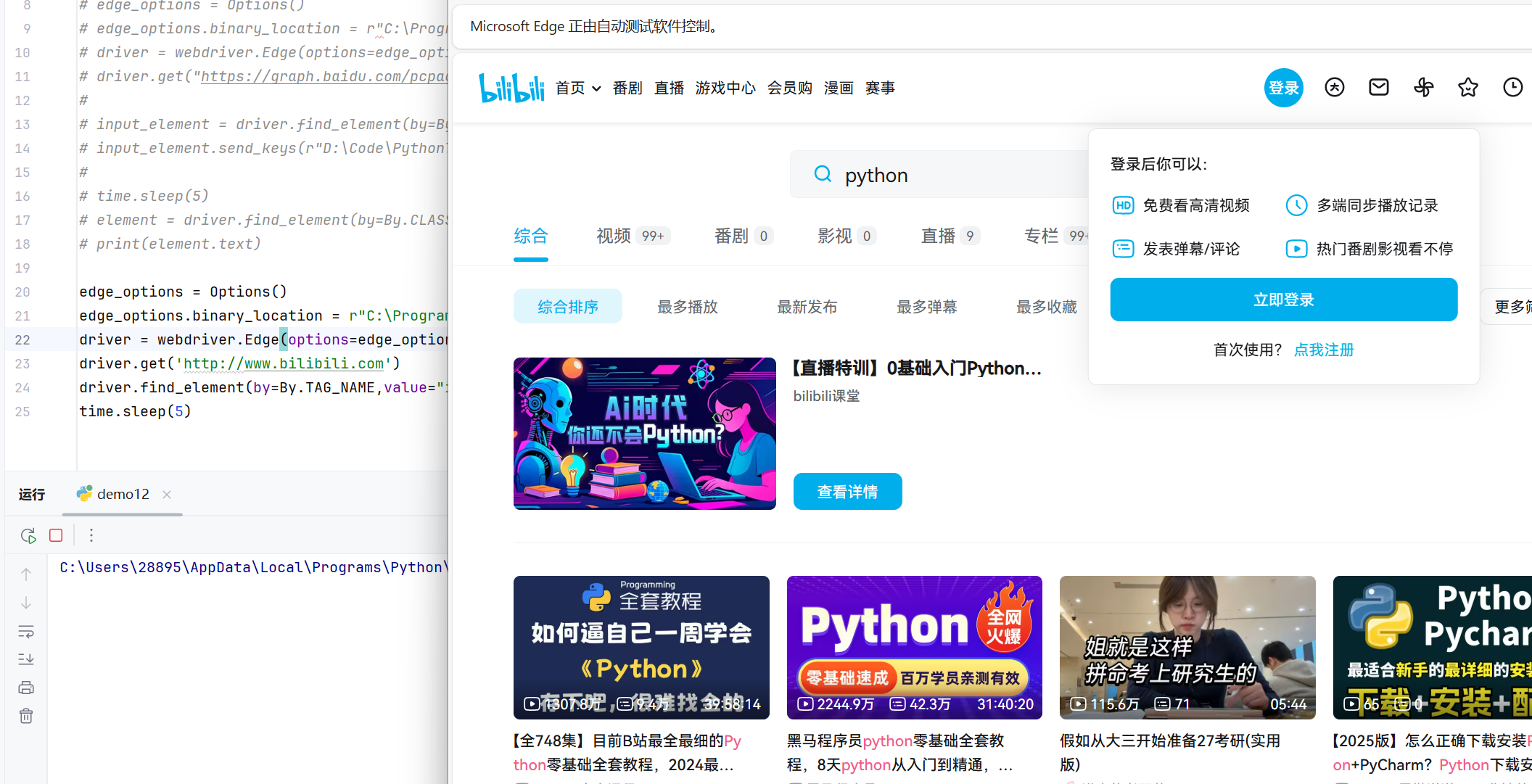
分析:
- 使用
By.TAG_NAME定位器找到第一个<input>元素 send_keys()方法不仅发送文本,还可以发送特殊按键Keys.RETURN模拟回车键,提交搜索表单
4. 图片批量下载
自动化下载网页图片是数据抓取的常见需求。以下代码展示了如何从百度图片批量下载图片:
python
if not os.path.exists("./Picture2"):
os.mkdir("./Picture2")
driver.get('https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=迪丽热巴')
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(8)
img_list = driver.find_elements(By.XPATH, value="//img[@class='img_7rRSL']")
i = 1
for img in img_list:
img_url = img.get_attribute("src")
img_data = requests.get(img_url)
with open(f"./Picture2/{i}.png",'wb') as f:
f.write(img_data.content)
i += 1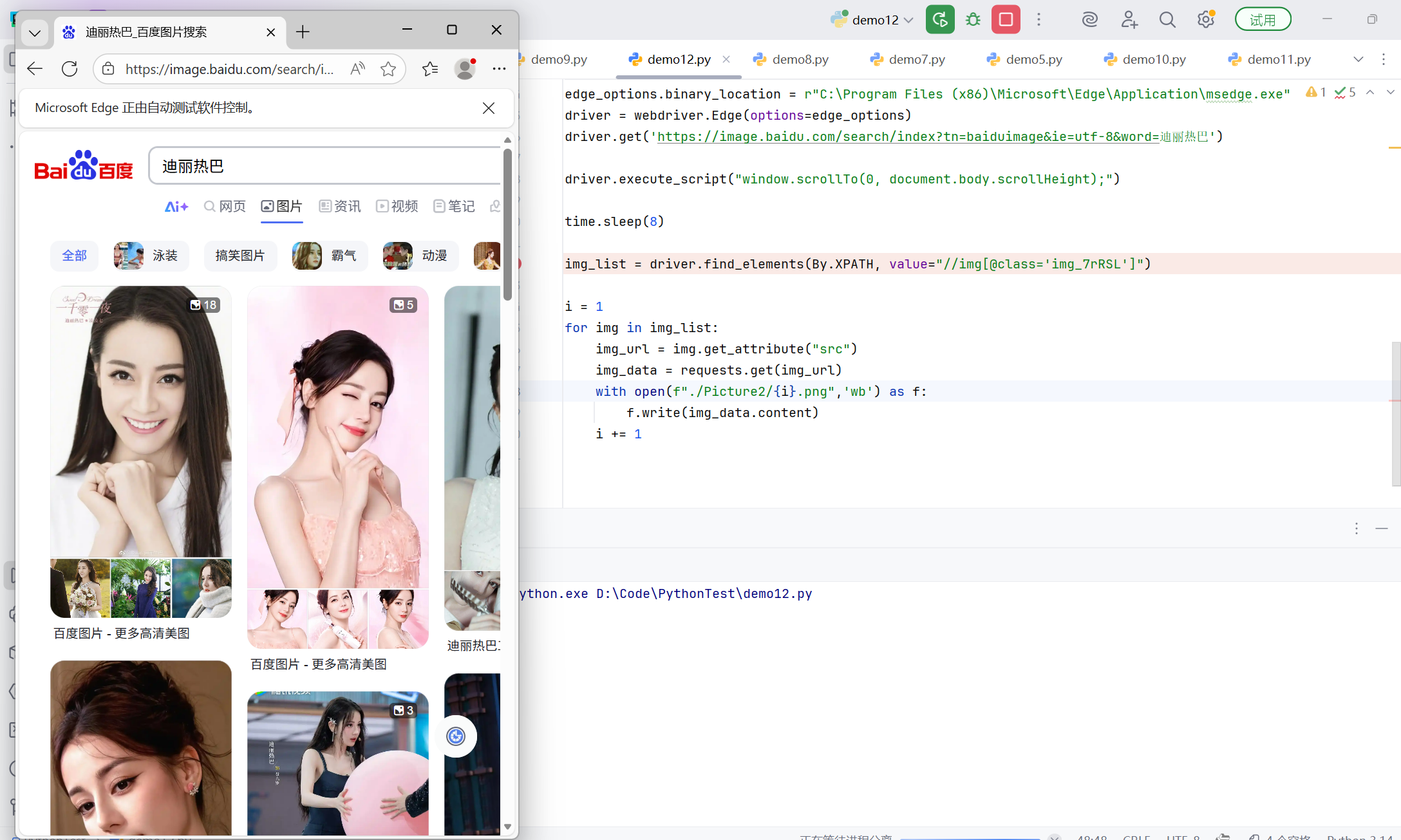
分析:
-
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")使用 JavaScript 执行器滚动页面到底部 -
document.body.scrollHeight获取文档总高度,确保滚动到底部
5. 分页数据抓取
处理分页内容是 Web 抓取中的常见操作。以下代码展示了如何抓取苏宁易购的商品评价:
python
driver.get("https://review.suning.com/cluster_cmmdty_review/cluster-38249278-000000012389328846-0000000000-1-good.htm?originalCmmdtyType=general&safp=d488778a.10004.loverRight.166")
hp_file = open('好评1.txt', 'w', encoding="utf-8")
def get_py_content(file):
pj_elements_content = driver.find_elements(by=By.CLASS_NAME, value="body-content")
for element in pj_elements_content:
file.write(element.text + "\n")
get_py_content(hp_file)
next_elements = driver.find_elements(by=By.XPATH, value='//*[@class="next rv-maidian "]')
print(next_elements)
while next_elements != []:
next_elements = next_elements[0]
time.sleep(1)
next_elements.click()
get_py_content(hp_file)
next_elements = driver.find_elements(by=By.XPATH, value='//*[@class="next rv-maidian "]')
hp_file.close()
关键方法分析:
- 使用 XPath 定位器精确查找下一页按钮:
//*[@class="next rv-maidian "] find_elements()(复数)返回元素列表,即使没有找到元素也不会抛出异常next_elements[0].click()点击第一个符合条件的元素- 循环条件
next_elements != []检查是否还有下一页
6. 商品信息抓取
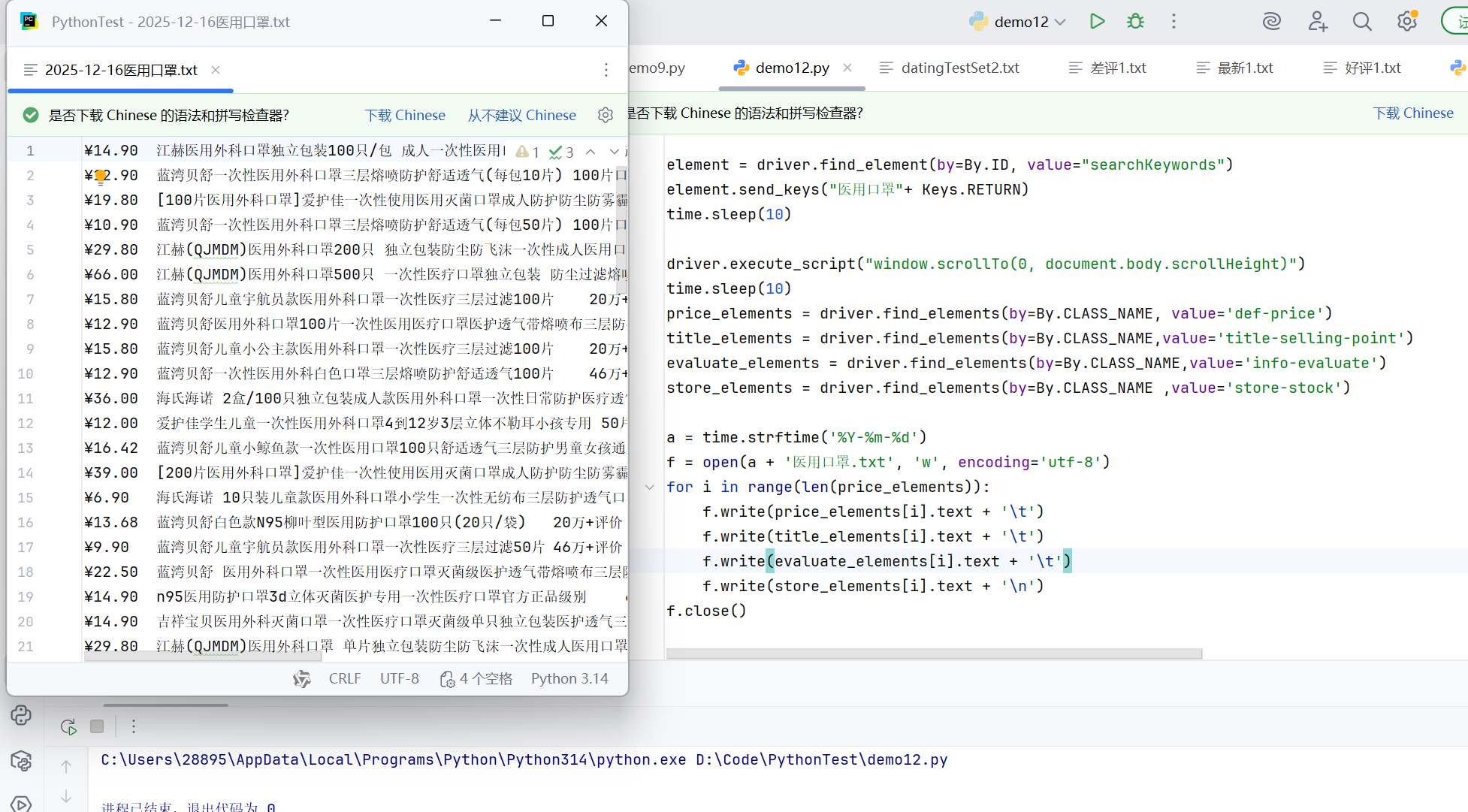
综合示例-抓取苏宁易购上医用口罩的商品信息:
python
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("http://www.suning.com")
element = driver.find_element(by=By.ID, value="searchKeywords")
element.send_keys("医用口罩"+ Keys.RETURN)
time.sleep(10)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(10)
price_elements = driver.find_elements(by=By.CLASS_NAME, value='def-price')
title_elements = driver.find_elements(by=By.CLASS_NAME,value='title-selling-point')
evaluate_elements = driver.find_elements(by=By.CLASS_NAME,value='info-evaluate')
store_elements = driver.find_elements(by=By.CLASS_NAME ,value='store-stock')
a = time.strftime('%Y-%m-%d')
f = open(a + '医用口罩.txt', 'w', encoding='utf-8')
for i in range(len(price_elements)):
f.write(price_elements[i].text + '\t')
f.write(title_elements[i].text + '\t')
f.write(evaluate_elements[i].text + '\t')
f.write(store_elements[i].text + '\n')
f.close()