在日常工作中,"截图"是我们保存信息比较高频的动作了。但业务做久了,难免遇到过下面这几种特殊场景:
- 数据就在屏幕上,但系统没有"导出Excel/PDF"按钮
- 不仅需要获取数据本身,还必须完整保留其呈现方式。比如:客服/售后纠纷中,不只要聊天内容,还要:时间顺序、头像、气泡位置、上下文连续性**,只导出文本会失去语境;**
- 数据量超过了显示器的显示范围,特别在ERP、CRM或财务系统,这类复杂界面比比皆是,字段多到横向要拉滚动条,记录多到纵向翻了好几屏,手动拼图拼到手抖,低效且极易出错
这种时候,普通截图无法承载全部信息,而一旦转为数据导出,页面原有的结构和语境又可能会被抹平。一旦页面被拆解成碎片,信息的价值也会随之下降。
因此,在强调效率与交付质量的当下,自动化的滚动长截图便成为一种自然的选择。
然而,真正落实到"滚动长截图"的自动化实现时,很多人可能会先想到**"获取滚动条位置"、"滚动到可视区域"、"网页截图"、"截屏"、"元素截图"、"元素长截图"指令,以及"缩小网页之后再截图"**等方法
但只要亲自尝试过就会发现,它们往往难以满足实际需求,要么功能本身就不支持、要么瞬时滚动丢失大量画面、要么以牺牲画面清晰度为代价、或者适用性较低......
有没有更稳的实现思路呢?
一、大致思路
今天介绍的这个方案,主要是借助**PixPin软件自带的"长截图"**功能实现的,**软件本身支持通过【长截图、更改滚动方向、自动滚动】**来实现横向滚动或者纵向滚动。
该功能的长截图实现步骤:按下截图快捷键 Ctrl + 1进入截图界面 → 框选滚动区域 → 点击长截图图标进入长截图模式 → 使用鼠标滚轮或控制滚动条滚动内容,PixPin 会自动拼接滚动内容成为一张长图片。
二、核心逻辑
在这套方案的实际自动化流程中,我们要处理的核心逻辑有两个:
- 如何确定截图可视区域的坐标,以此来实现"PixPin自动化框选截图区域"
- 如何判断滚动结束,执行下一步的"保存"
1. 关于"获取坐标/区域框选"
获取截图区域的坐标,我这里提供两种思路:
思路01:通过一段"鼠标屏幕框选的Python代码",唤起全屏遮罩供用户手动框选截图可视区域,自动处理DPI缩放,返回影刀通用的逻辑坐标。
示例输出结果:{'x': 210, 'y': 225, 'width': 1187, 'height': 582, 'left': 210, 'top': 225, 'right': 1397, 'bottom': 807}
python
# 使用此指令前,请确保安装必要的Python库:
# 无需安装额外库,使用Python内置 tkinter 模块及影刀内置 xbot 模块
import tkinter as tk
import ctypes
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def get_logic_region_selector() -> dict:
"""
title: 鼠标屏幕框选(返回逻辑坐标)
description: 唤起全屏遮罩供用户框选区域,自动处理DPI缩放,返回影刀通用的逻辑坐标。
inputs:
- 无
outputs:
- region (dict): 包含逻辑坐标的字典,格式: {'x': int, 'y': int, 'width': int, 'height': int}。取消则返回None。
"""
# 1. 获取屏幕缩放比例 (Scale Factor)
# 影刀逻辑坐标 = 物理像素 / scale
try:
hdc = ctypes.windll.user32.GetDC(0)
dpi_x = ctypes.windll.gdi32.GetDeviceCaps(hdc, 88) # LOGPIXELSX = 88
ctypes.windll.user32.ReleaseDC(0, hdc)
scale = dpi_x / 96.0
except:
scale = 1.0
selection_result = {}
class ScreenSelector:
def __init__(self, scale_factor):
self.root = tk.Tk()
self.scale = scale_factor
# 设置窗口属性:无边框、半透明、置顶
self.root.overrideredirect(True)
self.root.attributes("-alpha", 0.3)
self.root.attributes("-topmost", True)
# 使用 winfo 获取的是逻辑尺寸,正好覆盖逻辑屏幕
screen_width = self.root.winfo_screenwidth()
screen_height = self.root.winfo_screenheight()
self.root.geometry(f"{screen_width}x{screen_height}+0+0")
self.canvas = tk.Canvas(self.root, width=screen_width, height=screen_height, cursor="cross", bg="gray")
self.canvas.pack()
self.canvas.bind("<ButtonPress-1>", self.on_press)
self.canvas.bind("<B1-Motion>", self.on_drag)
self.canvas.bind("<ButtonRelease-1>", self.on_release)
self.root.bind("<Escape>", self.on_cancel)
self.root.bind("<Button-3>", self.on_cancel)
self.start_x = None
self.start_y = None
self.current_rect = None
def on_press(self, event):
self.start_x = event.x
self.start_y = event.y
self.current_rect = self.canvas.create_rectangle(
self.start_x, self.start_y, self.start_x, self.start_y,
outline="red", width=2
)
def on_drag(self, event):
if self.current_rect:
self.canvas.coords(self.current_rect, self.start_x, self.start_y, event.x, event.y)
def on_release(self, event):
# 获取选取的逻辑坐标(Tkinter 在未开启感知时默认返回逻辑坐标)
left = min(self.start_x, event.x)
top = min(self.start_y, event.y)
right = max(self.start_x, event.x)
bottom = max(self.start_y, event.y)
width = right - left
height = bottom - top
if width > 5 and height > 5:
selection_result['x'] = int(left)
selection_result['y'] = int(top)
selection_result['width'] = int(width)
selection_result['height'] = int(height)
selection_result['left'] = int(left)
selection_result['top'] = int(top)
selection_result['right'] = int(right)
selection_result['bottom'] = int(bottom)
self.root.quit()
self.root.destroy()
def on_cancel(self, event):
self.root.quit()
self.root.destroy()
def start(self):
self.root.mainloop()
# 2. 执行框选
print(f"正在启动框选工具(当前系统缩放: {scale*100}%)...")
selector = ScreenSelector(scale)
selector.start()
# 3. 结果处理
if not selection_result:
print("用户取消了框选")
return None
else:
print(f"成功获取逻辑坐标: {selection_result}")
return selection_result思路02:获取目标区域元素,得到其逻辑坐标。示例输出结果:Rectangle(left=211, top=225, right=1396, bottom=810, center_x=803, center_y=517, width=1185, height=585)。

PS. 通常我们并不希望把滚动条载入截图区域,但在某些网页,滚动条和截图区域并不容易完整分割开来,就没法写Xpath表达式,针对这种情况,推荐使用"思路01"来实现,可以无视网页结构来获取区域坐标。
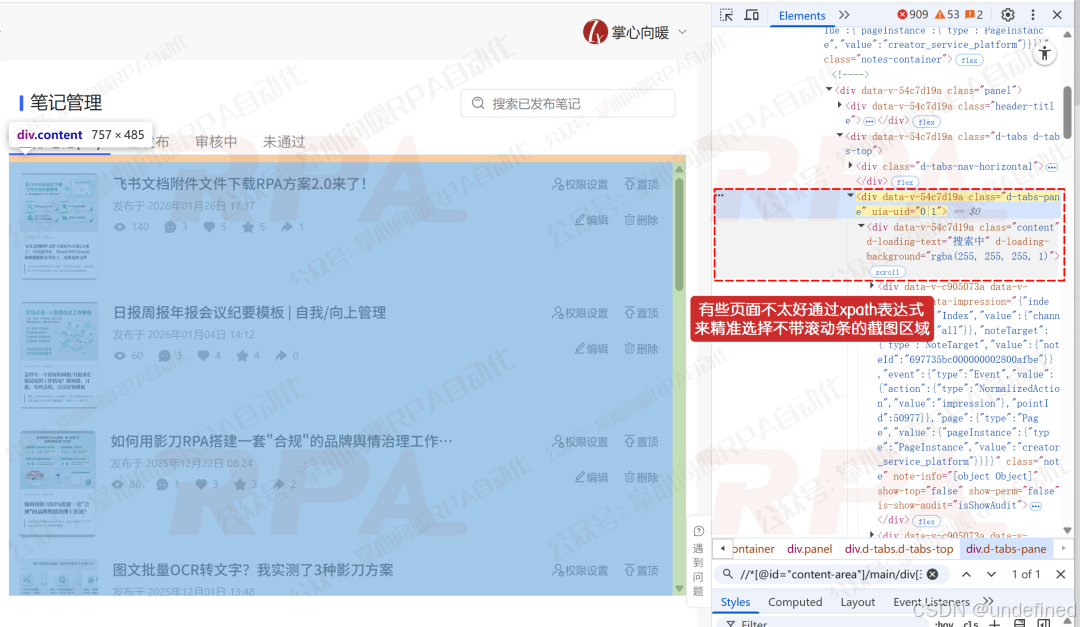
得到区域坐标后,下一步就是唤起PixPin的截图功能,并自动拉选区域,这里使用下述代码来实现:
python
# 使用此指令前,请确保安装必要的Python库:
# 无需安装额外库,使用影刀内置 xbot 模块
# 开发者:掌心向暖RPA自动化
from xbot import win32
import ctypes
import time
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot.app.logging import print
def get_screen_scale_factor() -> float:
"""获取主屏幕的缩放比例 (例如 1.0, 1.25, 1.5)"""
try:
user32 = ctypes.windll.user32
# 获取逻辑分辨率
user32.SetProcessDPIAware() # 临时开启感知以获取真实分辨率
w_phys = user32.GetSystemMetrics(0) # SM_CXSCREEN
# 获取设备上下文
hdc = user32.GetDC(0)
# 逻辑像素密度
w_log = ctypes.windll.gdi32.GetDeviceCaps(hdc, 118) # HORZRES (逻辑宽度)
user32.ReleaseDC(0, hdc)
# 如果无法直接获取,尝试更简单的比值计算
# 实际上,GetSystemMetrics(0) 在 SetProcessDPIAware 后返回物理宽
# 我们通常假设标准 DPI 是 96
# scale = 物理像素 / (逻辑像素 * 96 / DPI) ... 比较复杂
# 简化方案:直接获取 DPI 缩放
# LOGPIXELSX = 88
hdc = user32.GetDC(0)
dpi_x = ctypes.windll.gdi32.GetDeviceCaps(hdc, 88)
user32.ReleaseDC(0, hdc)
scale = dpi_x / 96.0
print(f"检测到屏幕缩放比例: {scale * 100}%")
return scale
except:
return 1.0
def auto_drag_with_dpi_fix(region_data: dict, speed: str = "middle") -> bool:
"""
title: 自动拉选区域(修复DPI偏移)
description: 自动根据屏幕缩放比例修正坐标,模拟鼠标从左上角拖拽到右下角。
inputs:
- region_data (dict): 包含坐标信息的字典
- speed (str): 鼠标移动速度,'instant', 'fast', 'middle', 'slow'
outputs:
- result (bool): 执行成功返回True
"""
try:
# 1. 获取缩放因子
scale = get_screen_scale_factor()
# 2. 解析原始坐标
raw_start_x = region_data.get('left', region_data.get('x'))
raw_start_y = region_data.get('top', region_data.get('y'))
raw_end_x = region_data.get('right')
raw_end_y = region_data.get('bottom')
if raw_end_x is None: raw_end_x = raw_start_x + region_data.get('width', 0)
if raw_end_y is None: raw_end_y = raw_start_y + region_data.get('height', 0)
# 3. 进行 DPI 坐标换算 (物理 -> 逻辑)
# int() 取整防止小数坐标
start_x = int(raw_start_x / scale)
start_y = int(raw_start_y / scale)
end_x = int(raw_end_x / scale)
end_y = int(raw_end_y / scale)
print(f"坐标修正: 起点({raw_start_x}->{start_x}), 终点({raw_end_x}->{end_x})")
# 4. 执行拖拽动作 (使用修正后的坐标)
# 移动到起点
win32.mouse_move(start_x, start_y, relative_to='screen', move_speed='instant', delay_after=0.2)
# 按下
win32.mouse_click(button='left', click_type='down', delay_after=0.2)
# 拖拽到终点
win32.mouse_move(end_x, end_y, relative_to='screen', move_speed=speed, delay_after=0.2)
# 抬起
win32.mouse_click(button='left', click_type='up', delay_after=0.1)
return True
except Exception as e:
print(f"操作失败: {e}")
return False2. 关于"判断滚动结束"
网页端 :如果目标截图区域有滚动条,则使用**"魔法指令-网页自动化"捕获包含滚动条的截图区域**,输入如下图中的话。
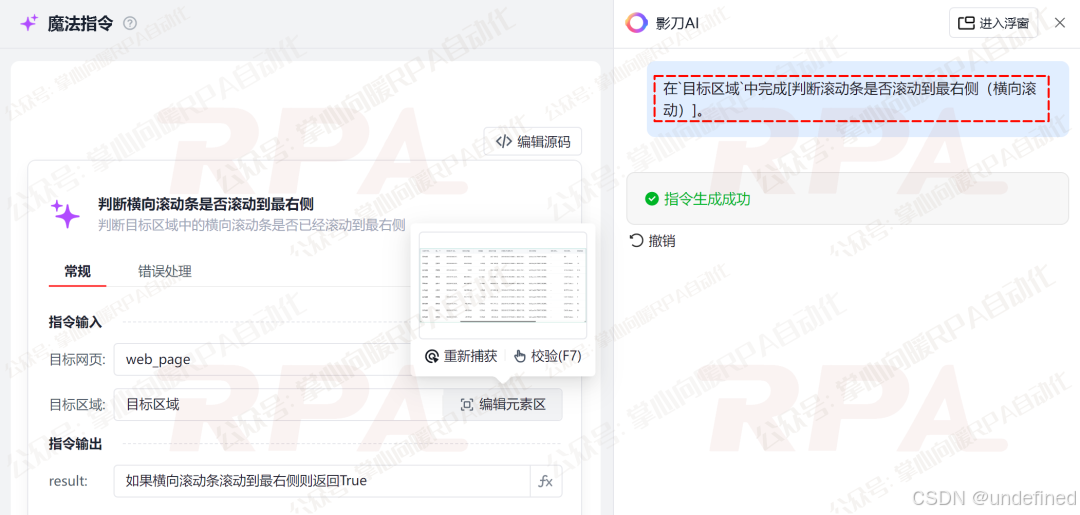
生成的指令会:执行JavaScript获取滚动条位置信息,判断横向滚动条是否滚动到最右侧。我们可以根据其判断结果,来判断PixPin的"自动截图"功能是否执行结束。

桌面端 :桌面端有滚动条,但是很多时候我们很难捕获到,这里可以【基于起终点计算出离散坐标列表 ,利用'按住鼠标'配合'Foreach循环'进行分段位移 ,并通过实时比对当前Y坐标与终点Y坐标】来判断是否滚动到底,这是一种非常底层、稳定可控的方案,同样适用于网页端。
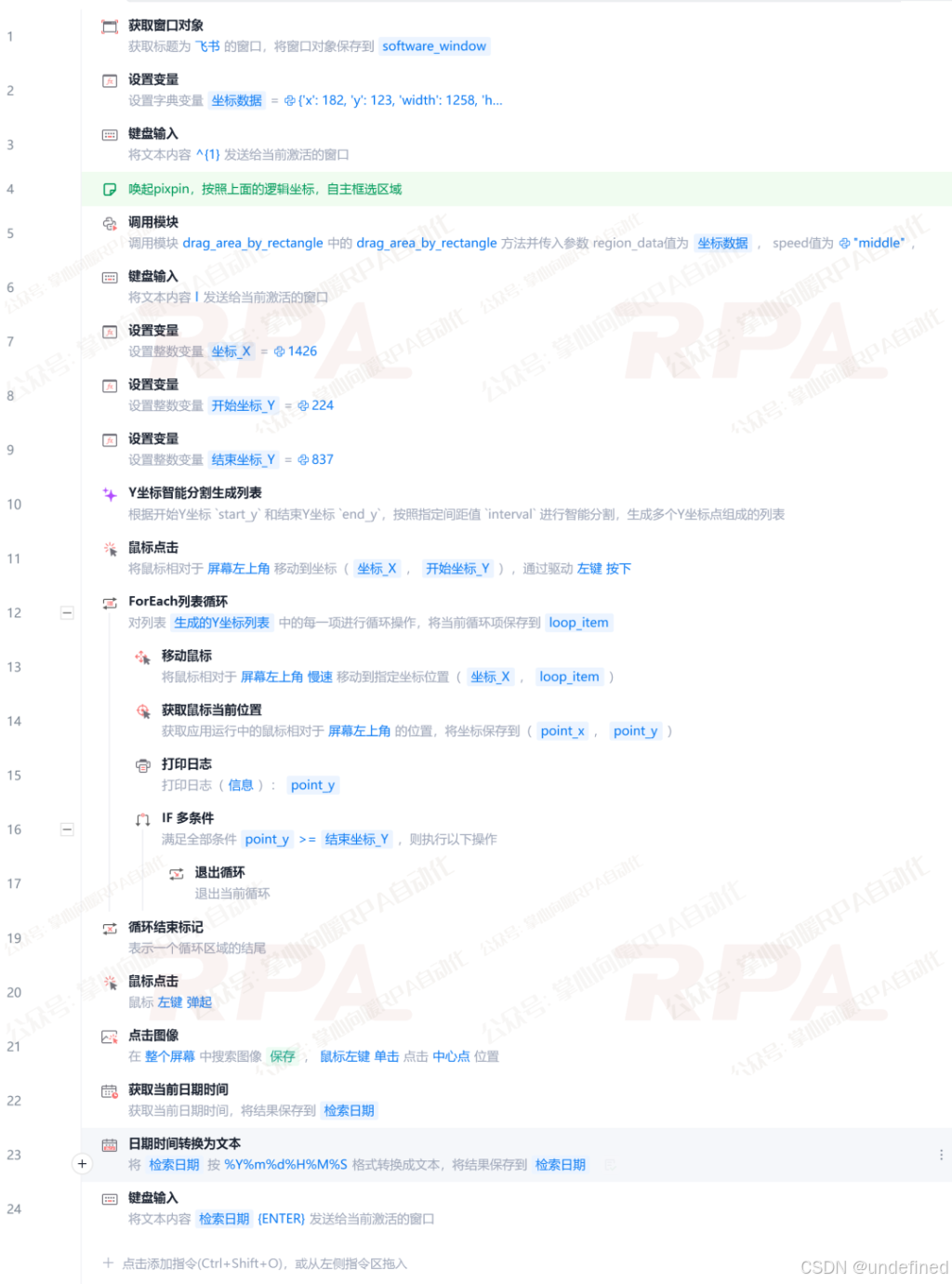
下面我换种更结构化的表达,将该流程分为4个阶段,来进一步阐述这个方案的核心逻辑:
第一阶段:数据准备与轨迹计算
- 定义好滚动条的水平位置"Scroll_x"(*下面案例中该值为"1426"),滑块的初始高度"Start_y"(*下面案例中该值为"224")和目标底部的极限高度"End_y"(*下面案例中该值为"837")。

- 利用"魔法指令",根据开始Y坐标 `Start_y` 和结束Y坐标 `End_y`,按照指定间距值(*下面案例中该值为"70像素")进行智能分割,生成多个Y坐标点组成的列表/后续鼠标移动的所有落脚点,例如 224, 294, 364, 434, 504, 574, 644, 714, 784, 837。
python
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def generate_y_coordinate_list(start_y, end_y, interval):
"""
title: Y坐标智能分割生成列表
description: 根据开始Y坐标 `start_y` 和结束Y坐标 `end_y`,按照指定间距值 `interval` 进行智能分割,生成多个Y坐标点组成的列表。
inputs:
- start_y (int): 开始Y坐标,eg: "0"
- end_y (int): 结束Y坐标,eg: "100"
- interval (int): 指定间距值,eg: "10"
outputs:
- y_coordinate_list (list): 生成的Y坐标列表,eg: "[0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100]"
"""
if not isinstance(start_y, int) or not isinstance(end_y, int):
raise ValueError("开始Y坐标和结束Y坐标必须为整数")
if interval <= 0:
raise ValueError("间距值必须为正数")
def _generate_y_points(start, end, step):
"""根据起始点、结束点和步长生成Y坐标序列"""
points = []
if start <= end:
# 正向递增
current = start
while current <= end:
points.append(current)
current += step
# 确保包含结束点
if points[-1] != end:
points.append(end)
else:
# 反向递减
current = start
while current >= end:
points.append(current)
current -= step
# 确保包含结束点
if points[-1] != end:
points.append(end)
return points
# 生成Y坐标列表
y_coordinate_list = _generate_y_points(start_y, end_y, interval)
return y_coordinate_list第二阶段:初始定位与抓取
**使用"鼠标点击"指令,**先将鼠标指针精确移动到滑块的起始位置,"点击方式"选择"按下",此时,鼠标状态变为"拖拽模式"。
第三阶段:分步拖拽与实时监测(核心)
- 进入**"For Each循环"**,依次取出坐标点列表中的每一个Y坐标。
- 移动鼠标:在保持左键按下的状态下,将鼠标移动到下一个 Scroll_x,Y 坐标 的位置点。

- 获取鼠标位置:每次移动后,立即读取当前鼠标的真实 Y 坐标。
- IF 判断:如果"当前Y坐标 >= End_y",说明已经拖到底了,执行"退出循环"。否则,继续下一次循环,往下拉一段距离。
第四阶段:释放与结束
跳出循环后,必须执行弹起鼠标,否则鼠标左键一直处于按下状态,会影响后续操作。

除此之外,我们也可以根据页面中的【其他固定标识】(不少页面在滚动到底部时,通常会出现"没有更多了"、"到底了"或者特定的底部图标,如版权信息)、**【元素列表的最后一项】**等是否出现在屏幕可视区域来判定。
如果你正在做自动化截图、报告留档、取证、数据留存,这套思路非常值得直接复用。以上,我们下期分享见!

-END-
- 爱练字的96年ISTJ型互联网人/信息整合怪/工具人/影刀高级认证工程师。
- 专注分享:RPA&AI自动化场景提效方案、效率软件安利、实用技能。"所有的生产要素都可以被构建,只有认知是壁垒",欢迎関注