大模型(如GPT、BERT)的全量微调需更新数十亿甚至上万亿参数,带来了极高的计算、存储成本------这成为中小企业落地大模型的核心障碍。参数高效微调技术 由此成为主流:通过冻结预训练语言模型(PLM)的主参数,仅训练少量新增组件,即可实现下游任务适配。图中展示的5种方法是这类技术的典型代表:Adapter通过插入串行小型分支实现轻量适配;Prefix Tuning给注意力层添加可训练前缀引导任务;LoRA利用低秩分解压缩微调参数;Parallel Adapter将分支改为并行以提升效率;Scaled PA则在并行基础上增加缩放策略优化效果。这些方法在"低成本"与"高适配性"间寻找平衡,是当前大模型落地的关键支撑技术。
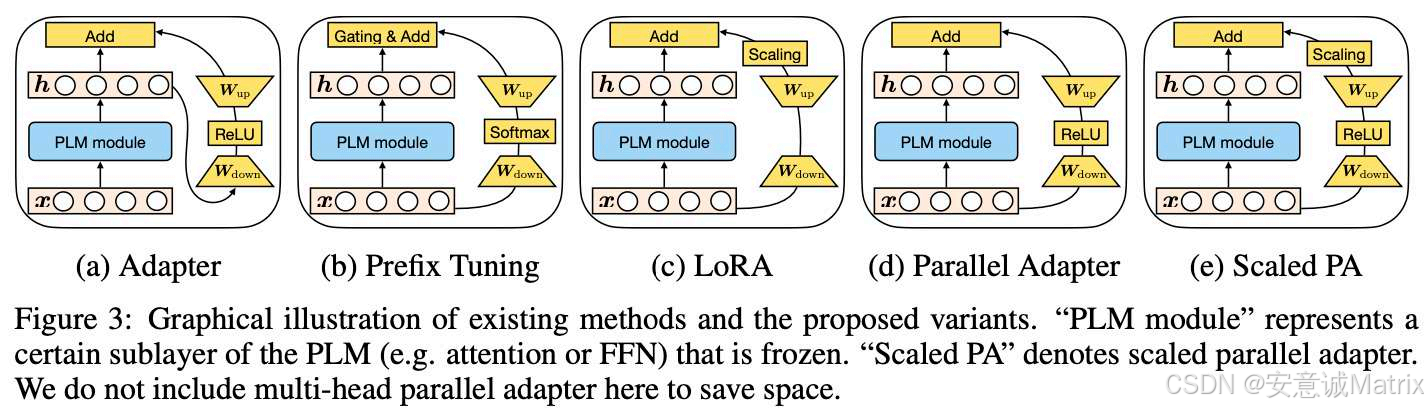
一、Adapter:串行轻量分支适配
原理
在PLM的子层(如注意力层、FFN层)中插入串行小型全连接分支 :输入x经冻结的PLM模块得到中间特征h后,流经w_up(低维升维)→ReLU激活→w_down(高维降维),最终将分支输出与原特征h相加,得到最终输出。
优势
- 微调参数极少:仅训练
w_up/w_down(通常占PLM参数的1%-5%),计算/存储成本大幅降低; - 部署友好:PLM主参数完全冻结,可直接复用预训练权重,无需额外适配。
劣势
- 推理延迟增加:串行分支会额外占用计算时间,高并发场景下性能受限;
- 适配能力有限:分支容量较小,复杂下游任务(如多模态生成)的效果弱于全量微调。
二、Prefix Tuning:注意力前缀引导
原理
在PLM注意力层的"键/值(K/V)向量"前,添加可训练的前缀向量 :输入x经PLM模块后,分支路径为h→w_up→Softmax激活→w_down,最终通过"门控融合"将分支输出与主路径结合,让前缀向量编码任务信息,引导模型输出。
优势
- 贴合注意力机制:前缀直接作用于注意力计算,在文本生成任务(如摘要、对话)中效果突出;
- 无结构侵入:不修改PLM主结构,仅新增前缀相关参数,兼容性强。
劣势
- 超参敏感:前缀的长度、插入位置等需针对性调优,调试成本高;
- 场景局限:对分类、命名实体识别等非生成任务适配性较弱,训练稳定性不足。
三、LoRA:低秩矩阵分解适配
原理
将PLM的权重矩阵分解为两个低秩矩阵(w_up/w_down) :微调时仅训练这对低秩矩阵,推理时将低秩输出与原权重合并(等价于更新原权重的低秩部分)。分支中h经w_up→缩放→w_down后,与原特征h相加。
优势
- 参数极致压缩:低秩矩阵参数通常仅数十万个(占PLM的0.1%以内),训练成本极低;
- 推理无额外延迟:可将低秩矩阵与原权重合并部署,不增加推理耗时;
- 效果接近全量微调:在多数下游任务中,性能与全量微调差距小于5%。
劣势
- 低秩假设限制:依赖"权重更新具有低秩性"的假设,复杂任务(如多模态理解)中表达能力不足;
- 对高秩权重适配弱:若PLM权重的更新需要高秩特征,LoRA效果会明显下降。
四、Parallel Adapter:并行分支优化
原理
将传统Adapter的串行分支改为并行结构 :输入x同时流经PLM主层和Adapter分支,分支路径为h→w_up→ReLU激活→w_down,最终直接将分支输出与主层输出相加。
优势
- 消除串行延迟:并行结构避免了串行分支的额外耗时,推理效率与原生PLM接近;
- 适配能力增强:并行分支的容量比传统Adapter更大,复杂任务的效果更优。
劣势
- 少量冗余参数:并行设计会新增比传统Adapter略多的参数,成本略有上升;
- 通用性略弱:不同任务的分支结构需要针对性调整,缺乏统一的调优范式。
五、Scaled PA:缩放并行适配
原理
在Parallel Adapter的基础上增加缩放操作 :分支路径为h→w_up→ReLU激活→缩放→w_down,通过缩放因子稳定训练过程,再将分支输出与主层输出相加。
优势
- 训练更稳定:缩放因子可缓解梯度波动,提升微调过程的收敛速度与最终效果;
- 保留并行优势:既继承了Parallel Adapter的低延迟特点,又增强了适配能力。
劣势
- 超参依赖:缩放因子需针对不同任务调优,增加了调试成本;
- 落地验证不足:目前在大规模工业场景中的通用性尚未充分验证,适用范围有待拓展。
总结:参数高效微调的选型与未来
参数高效微调技术的核心价值,是让大模型从"实验室的高成本模型"变为"可落地的实用工具"------5种方法各有侧重:LoRA因"低参数、低延迟、高效果"成为多数场景的首选;Adapter适合资源极度受限的轻量部署;Prefix Tuning是文本生成任务的专用方案;Parallel Adapter与Scaled PA则是"低延迟+强适配"场景的优化方向。
这些方法的局限也很明确:相比全量微调,它们的表达能力仍有差距,复杂任务需结合多方法(如"LoRA+Adapter")提升效果。未来的发展方向将聚焦于"自适应参数分配"(根据任务动态调整微调组件)、"多模态适配优化"(突破单一文本场景),以及"硬件-算法协同"(结合AI芯片优化微调效率)。
对于开发者而言,选型的关键是平衡"任务复杂度、计算资源、推理延迟":轻量场景选Adapter,通用场景选LoRA,生成任务选Prefix Tuning,低延迟复杂任务选Scaled PA------这些技术正在让大模型的落地门槛持续降低,加速AI技术的产业化应用。