目录
[4.1 MaskDecoder.predict_masks](#4.1 MaskDecoder.predict_masks)
[4.1.1 hs, src = self.transformer(src, pos_src, tokens)之前做了什么](#4.1.1 hs, src = self.transformer(src, pos_src, tokens)之前做了什么)
[objectness 打分 是什么](#objectness 打分 是什么)
[4 个 mask 原型是什么?](#4 个 mask 原型是什么?)
[iou 打分是什么?](#iou 打分是什么?)
[# sparse_embeddings: torch.Size(1, 3, 256) output_tokens = output_tokens.unsqueeze(0).expand( sparse_prompt_embeddings.size(0), -1, -1 ) # output_tokens: torch.Size(1, 6, 256) 这什么意思?](# sparse_embeddings: torch.Size([1, 3, 256]) output_tokens = output_tokens.unsqueeze(0).expand( sparse_prompt_embeddings.size(0), -1, -1 ) # output_tokens: torch.Size([1, 6, 256]) 这什么意思?)
[src = torch.repeat_interleave(image_embeddings, tokens.shape0, dim=0) 什么意思?](#src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0) 什么意思?)
一、前言 
下面是第一帧情况下的函数调用顺序。因为一篇文章太长了我感觉会卡顿,所以只能分多篇了。还有就是很多基础函数调试进不去,所以说不是很清楚进不去的函数内部发生了什么,这个问题以后再看看能不能再挖深一点。
2.12 <重点> add_new_prompt
2.13 <重点> _run_single_frame_inference
2.14 <重点> track_step
2.15 <重点> _prepare_memory_conditioned_features
2.16 _use_multimask
2.17 <重点> _forward_sam_heads
2.18 提示编码器:类PromptEncoder.forward
2.19 类PositionEmbeddingRandom.forward_with_coords
2.20 类PromptEncoder.get_dense_pe(这篇开头在这)
2.21 掩码解码器 类MaskDecoder.forward
2.22 类MaskDecoder.predict_masks
2.23 TwoWayTransformer.forward(这篇结束在这)
2.24 TwoWayAttentionBlock.forward
2.25 Attention.forward
2.26 <重点> MLP.forward
2.27 Attention.forward
2.28 LayerNorm2d.forward
2.29 MaskDecoder._dynamic_multimask_via_stability
2.30 MaskDecoder._get_stability_scores
2.31 fill_holes_in_mask_scores
2.32 _get_maskmem_pos_enc
2.33 _consolidate_temp_output_across_obj
2.34 _get_orig_video_res_output
二、_forward_sam_heads
@torch.inference_mode()
def _forward_sam_heads(
self,
backbone_features,
point_inputs=None,
mask_inputs=None,
high_res_features=None,
multimask_output=False,
):
"""
完整的 SAM 风格「提示编码 + 掩膜解码」一条龙:
把 backbone 特征与用户提示(点/框/mask)一起送 SAM,
输出多组或单组掩膜 logits、IoU 估计、对象指针等。
参数:
backbone_features (Tensor):
已融合记忆的图像嵌入,形状 (B, C, H, W),
其中 H=W=sam_image_embedding_size(默认 64)。
point_inputs (dict | None):
{"point_coords": (B, P, 2), "point_labels": (B, P)}
坐标为**绝对像素**(会在内部归一化),label: 1=前, 0=背, -1=pad。
mask_inputs (Tensor | None):
低分辨率掩膜提示 (B,1,H',W'),与点提示互斥。
high_res_features (list[Tensor] | None):
额外两层更高分辨率特征 [4H,4W] 与 [2H,2W],供 decoder refine 边缘。
multimask_output (bool):
True → 输出 3 候选掩膜 + 3 IoU;False → 1 掩膜 + 1 IoU。
返回:
tuple:
0. low_res_multimasks -- (B,M,H/4,W/4) 低分多掩膜 logits
1. high_res_multimasks -- (B,M,H,W) 高分多掩膜 logits
2. ious -- (B,M) 各掩膜 IoU 估计
3. low_res_masks -- (B,1,H/4,W/4) **最佳**低分掩膜
4. high_res_masks -- (B,1,H,W) **最佳**高分掩膜
5. obj_ptr -- (B,C) 对象指针(用于记忆)
6. object_score_logits -- (B,) 对象出现置信度(可软可硬)
"""
# backbone_features: torch.Size([1, 256, 64, 64])
# point_inputs: {
# 'point_coords': tensor([[[421.3333, 540.4445],
# [654.9333, 921.6000]]], device='cuda:0'),
# 'point_labels': tensor([[2, 3]],
# device='cuda:0', dtype=torch.int32)
# }
# mask_inputs:None
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# multimask_output: False
B = backbone_features.size(0)
# B: 1
device = backbone_features.device
# device: device(type='cuda', index=0)
# --- 1. 输入断言:尺寸必须匹配 SAM 预设 ---
assert backbone_features.size(1) == self.sam_prompt_embed_dim
assert backbone_features.size(2) == self.sam_image_embedding_size
assert backbone_features.size(3) == self.sam_image_embedding_size
# --- 2. 构造点提示 ---
if point_inputs is not None:
sam_point_coords = point_inputs["point_coords"] # (B, P, 2)
# sam_point_coords: torch.Size([1, 2, 2])
# sam_point_coords: tensor([[[421.3333, 540.4445],
# [654.9333, 921.6000]]], device='cuda:0'),
sam_point_labels = point_inputs["point_labels"] # (B, P)
# sam_point_labels: torch.Size([1, 2])
# sam_point_labels: tensor([[2, 3]], device='cuda:0', dtype=torch.int32)
assert sam_point_coords.size(0) == B and sam_point_labels.size(0) == B
else:
# 无点提示时,用 1 个 pad 点(label=-1)占位,保证 prompt encoder 正常 forward
sam_point_coords = torch.zeros(B, 1, 2, device=device)
sam_point_labels = -torch.ones(B, 1, dtype=torch.int32, device=device)
# --- 3. 构造掩膜提示 ---
# mask_inputs: None
if mask_inputs is not None:
# 若外部 mask 分辨率不符,先双线性下采样到 prompt encoder 期望尺寸
assert len(mask_inputs.shape) == 4 and mask_inputs.shape[:2] == (B, 1)
if mask_inputs.shape[-2:] != self.sam_prompt_encoder.mask_input_size:
sam_mask_prompt = F.interpolate(
mask_inputs.float(),
size=self.sam_prompt_encoder.mask_input_size,
align_corners=False,
mode="bilinear",
antialias=True, # 抗锯齿,减少下采样 aliasing
)
else:
sam_mask_prompt = mask_inputs
else:
# 无 mask 时,prompt encoder 内部会加 learned `no_mask_embed`
sam_mask_prompt = None
# --- 4. 送进 SAM 提示编码器 ---
sparse_embeddings, dense_embeddings = self.sam_prompt_encoder(
points=(sam_point_coords, sam_point_labels),
boxes=None, # 框提示在外部已转成 2 点,不再走这里
masks=sam_mask_prompt,
)
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings: torch.Size([1, 256, 64, 64])
# backbone_features: torch.Size([1, 256, 64, 64])
# multimask_output: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# --- 5. 送进 SAM mask 解码器 ---
(
low_res_multimasks, # (B, M, H/4, W/4) M=3 or 1
ious, # (B, M) IoU 估计
sam_output_tokens, # (B, M, C) 解码器输出 token
object_score_logits, # (B,) 对象出现/消失 logits
) = self.sam_mask_decoder(
image_embeddings=backbone_features,
image_pe=self.sam_prompt_encoder.get_dense_pe(), # 固定 2D 位置编码
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
repeat_image=False, # image 已 batch,无需再 repeat
high_res_features=high_res_features, # 高分特征供 refine 边缘
)
# --- 6. 对象 score 后处理:若模型预测"无对象",把掩膜 logits 置为 NO_OBJ_SCORE ---
if self.pred_obj_scores:
is_obj_appearing = object_score_logits > 0 # 硬阈值
# 记忆用掩膜必须**硬**选择:有对象才保留,否则置极大负值
low_res_multimasks = torch.where(
is_obj_appearing[:, None, None],
low_res_multimasks,
NO_OBJ_SCORE,
)
# --- 7. 数据类型转换:bf16/fp16 -> fp32(老版本 PyTorch interpolate 不支持 bf16)---
low_res_multimasks = low_res_multimasks.float()
# 上采样到图像原分辨率(stride=1)
high_res_multimasks = F.interpolate(
low_res_multimasks,
size=(self.image_size, self.image_size),
mode="bilinear",
align_corners=False,
)
# --- 8. 选取最佳掩膜 ---
sam_output_token = sam_output_tokens[:, 0] # 默认取第 1 个 token(单掩膜时即自身)
if multimask_output:
# 多掩膜时,选 IoU 估计最高的那个
best_iou_inds = torch.argmax(ious, dim=-1) # (B,)
batch_inds = torch.arange(B, device=device)
low_res_masks = low_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
high_res_masks = high_res_multimasks[batch_inds, best_iou_inds].unsqueeze(1)
# 若解码器输出了多个 token,同样要选最佳
if sam_output_tokens.size(1) > 1:
sam_output_token = sam_output_tokens[batch_inds, best_iou_inds]
else:
# 单掩膜时,最佳即唯一
low_res_masks, high_res_masks = low_res_multimasks, high_res_multimasks
# --- 9. 从最佳 token 提取对象指针(用于记忆)---
obj_ptr = self.obj_ptr_proj(sam_output_token) # (B, C)
# --- 10. 对象指针后处理:若模型认为"无对象",指针也被削弱或替换 ---
if self.pred_obj_scores:
if self.soft_no_obj_ptr:
# 软削弱:用 sigmoid 概率加权
assert not self.teacher_force_obj_scores_for_mem
lambda_is_obj_appearing = object_score_logits.sigmoid()
else:
# 硬削弱:0/1 加权
lambda_is_obj_appearing = is_obj_appearing.float()
if self.fixed_no_obj_ptr:
obj_ptr = lambda_is_obj_appearing * obj_ptr
# 剩余权重用"无对象指针"补齐,保证指针和为 1
obj_ptr = obj_ptr + (1 - lambda_is_obj_appearing) * self.no_obj_ptr
# --- 11. 返回打包结果 ---
return (
low_res_multimasks, # 0 低分多掩膜
high_res_multimasks, # 1 高分多掩膜
ious, # 2 各掩膜 IoU 估计
low_res_masks, # 3 最佳低分掩膜
high_res_masks, # 4 最佳高分掩膜
obj_ptr, # 5 对象指针(记忆 key/query)
object_score_logits, # 6 对象出现置信度 logits
)三、PromptEncoder.get_dense_pe
--- 5. 送进 SAM mask 解码器 ---
(
low_res_multimasks, # (B, M, H/4, W/4) M=3 or 1
ious, # (B, M) IoU 估计
sam_output_tokens, # (B, M, C) 解码器输出 token
object_score_logits, # (B,) 对象出现/消失 logits
) = self.sam_mask_decoder(
image_embeddings=backbone_features,
image_pe=self.sam_prompt_encoder.get_dense_pe(), # 固定 2D 位置编码
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
repeat_image=False, # image 已 batch,无需再 repeat
high_res_features=high_res_features, # 高分特征供 refine 边缘
)
sam2/modeling/sam/prompt_encoder.py
python
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image embedding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
# 1. 以图像嵌入空间的分辨率生成整张网格的位置编码
# self.image_embedding_size: (64, 64)
dense_pe = self.pe_layer(self.image_embedding_size)
# dense_pe: (embed_dim, 64, 64) 即 (256, 64, 64)
# 2. 在最前面加 batch 维,变成 1xCxHxW,方便后续与图像特征直接相加/广播
return dense_pe.unsqueeze(0) # final shape: (1, 256, 64, 64)解释
作用:给 64×64 的图像特征图提供同样大小的"位置图",以便 SAM 的 mask 解码器在做逐像素预测时知道"我在哪"。
只算一次,调用时直接返回,节省重复计算。
输出形状
1×256×64×64,与图像 embedding 完全一致,可直接相加。
类初始化里面有这么一句:
embed_dim: 256
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
这段代码就是"给 64×64 的图像特征网格每人发一张'身份证'"------这张身份证里写的就是每个像素在整张图里的"坐标"对应的 256 维正弦-余弦向量(positional encoding)。
步骤拆开看:
self.image_embedding_size预先存了(64, 64),表示 SAM 把原图压到 64×64 的 embedding 空间。
self.pe_layer(...)内部会:
生成 64×64 个二维坐标
(y, x);对每个坐标用正弦/余弦函数做不同频率的编码,得到 256 维向量;
拼成
(256, 64, 64)的张量。最后
unsqueeze(0)加一个 batch 维,变成(1, 256, 64, 64),这样后续可以直接和同样形状的image_embeddings相加或重复展开,而不用每次都临时再扩维度。一句话:
get_dense_pe()返回一张"固定地图"------64×64 位置编码,供后面把"点/网格"坐标信息喂给 transformer。
self.pe_layer调试进不去,标记一下
四、MaskDecoder.forward
sam2/modeling/sam/mask_decoder.py
python
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
repeat_image: bool,
high_res_features: Optional[List[torch.Tensor]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
torch.Tensor: batched SAM token for mask output
"""
# 输入:
# image_embeddings: torch.Size([1, 256, 64, 64])
# image_pe:torch.Size([1, 256, 64, 64])
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings : torch.Size([1, 256, 64, 64])
# multimask_output:False
# repeat_image: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
# >>> 1. 先把所有 embedding 喂给 mask decoder,拿到 4 个输出
masks, iou_pred, mask_tokens_out, object_score_logits = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
repeat_image=repeat_image,
high_res_features=high_res_features,
)
# mask: torch.Size([1, 4, 256, 256])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# mask_tokens_out: torch.Size([1, 4, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
# Select the correct mask or masks for output
# multimask_output:False
if multimask_output:
# >>> 2-a. 训练/多 mask 模式:只要后 3 个 mask(跳过第 0 个"默认" mask)
masks = masks[:, 1:, :, :]
iou_pred = iou_pred[:, 1:]
# iou_pred: tensor([[0.8732]], device='cuda:0')
# self.dynamic_multimask_via_stability:True self.training:False
elif self.dynamic_multimask_via_stability and not self.training:
# >>> 2-b. 测试阶段且开 stability 筛 mask:自动挑一个最稳的
masks, iou_pred = self._dynamic_multimask_via_stability(masks, iou_pred)
# masks: torch.Size([1, 1, 256, 256])
# iou_scores_out: tensor([[0.8732]], device='cuda:0')
else:
# >>> 2-c. 默认单 mask 模式:直接取第 0 个通道
masks = masks[:, 0:1, :, :]
iou_pred = iou_pred[:, 0:1]
# multimask_output: False self.use_multimask_token_for_obj_ptr:True
if multimask_output and self.use_multimask_token_for_obj_ptr:
# >>> 3-a. 多 mask 且要把 token 当 object pointer:用后 3 个 token
sam_tokens_out = mask_tokens_out[:, 1:] # [b, 3, c] shape
else:
# >>> 3-b. 其余情况(包括单 mask)一律用第 0 个 token 当"物体记忆"
# Take the mask output token. Here we *always* use the token for single mask output.
# At test time, even if we track after 1-click (and using multimask_output=True),
# we still take the single mask token here. The rationale is that we always track
# after multiple clicks during training, so the past tokens seen during training
# are always the single mask token (and we'll let it be the object-memory token).
# mask_tokens_out: torch.Size([1, 4, 256])
sam_tokens_out = mask_tokens_out[:, 0:1] # [b, 1, c] shape
# sam_tokens_out: torch.Size([1, 1, 256])
# Prepare output
# masks: torch.Size([1, 1, 256, 256])
# iou_pred:tensor([[0.8732]], device='cuda:0')
# sam_tokens_out: torch.Size([1, 1, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
return masks, iou_pred, sam_tokens_out, object_score_logits代码整体流程一句话总结
用
predict_masks一次性生成 4 组 mask 及其对应 IoU、token、objectness。根据
multimask_output标志和dynamic_multimask_via_stability策略,决定到底留几个 mask:
训练/多 mask 模式 → 留 3 个;
测试开 stability → 自动挑 1 个最稳的;
其余 → 直接拿第 0 个。
再按同样逻辑挑一个(或 3 个)token 作为后续跟踪用的"物体记忆"。
把最终 mask、IoU、token、objectness 分数一起返回。
4.1 MaskDecoder.predict_masks
sam2/modeling/sam/mask_decoder.py
python
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
repeat_image: bool,
high_res_features: Optional[List[torch.Tensor]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# 输入:
# image_embeddings: torch.Size([1, 256, 64, 64])
# image_pe:torch.Size([1, 256, 64, 64])
# sparse_embeddings: torch.Size([1, 3, 256])
# dense_embeddings : torch.Size([1, 256, 64, 64])
# multimask_output:False
# repeat_image: False
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
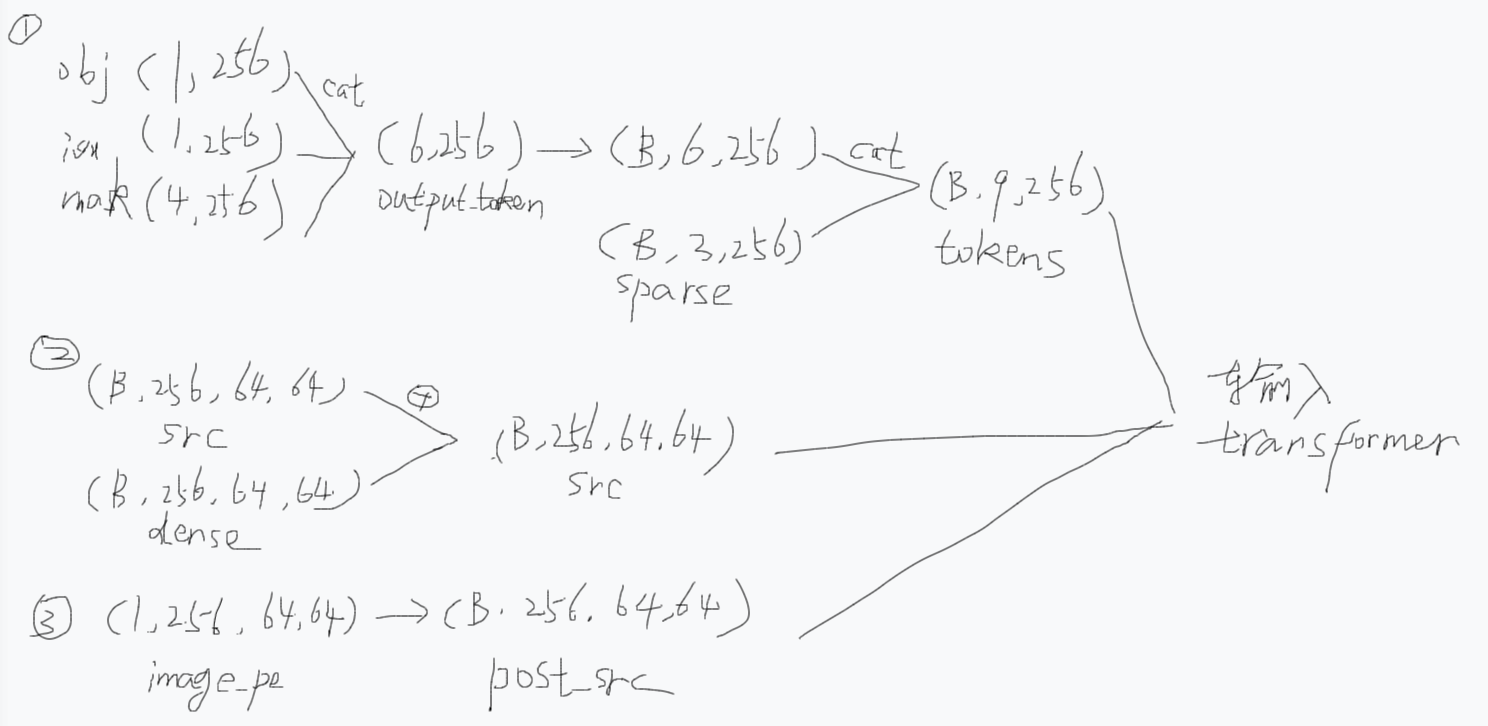
# Concatenate output tokens
s = 0
# self.pred_obj_scores: True
if self.pred_obj_scores:
# self.obj_score_token.weight: torch.Size([1, 256])
# self.iou_token.weight: torch.Size([1, 256])
# self.mask_tokens.weight: torch.Size([4, 256])
output_tokens = torch.cat(
[
self.obj_score_token.weight, # >>> 0 号 token:objectness 打分
self.iou_token.weight, # >>> 1 号 token:iou 打分
self.mask_tokens.weight, # >>> 2~5 号 token:4 个 mask 原型
],
dim=0,
)
# output_tokens: torch.Size([6, 256])
s = 1 # >>> 后面拿 hs 时跳过 0 号 token
else:
output_tokens = torch.cat(
[self.iou_token.weight, self.mask_tokens.weight], dim=0
)
# sparse_embeddings: torch.Size([1, 3, 256])
output_tokens = output_tokens.unsqueeze(0).expand(
sparse_prompt_embeddings.size(0), -1, -1
)
# output_tokens: torch.Size([1, 6, 256])
# >>> 把"可学习 token"和"用户稀疏提示(点/框)"拼在一起
# sparse_prompt_embeddings: torch.Size([1, 3, 256])
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# tokens: torch.Size([1, 9, 256])
# >>> 如果 batch 里每张图要重复多次(跟踪里常见),就 repeat;否则直接拿
# repeat_image:False
if repeat_image:
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
else:
assert image_embeddings.shape[0] == tokens.shape[0]
src = image_embeddings
# src: torch.Size([1, 256, 64, 64])
# >>> 把"用户 dense 提示(低分辨率 mask)"也加到图像特征上
# dense_prompt_embeddings: torch.Size([1, 256, 64, 64])
src = src + dense_prompt_embeddings
# src: torch.Size([1, 256, 64, 64])
assert (
image_pe.size(0) == 1
), "image_pe should have size 1 in batch dim (from `get_dense_pe()`)"
# image_pe: torch.Size([1, 256, 64, 64])
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
# pos_src: torch.Size([1, 256, 64, 64])
b, c, h, w = src.shape
# b:1 c:256 h:64 w:64
# >>> 2-way transformer:token ↔ 图像特征 交叉注意力
# src: torch.Size([1, 256, 64, 64])
# pos_src: torch.Size([1, 256, 64, 64])
# tokens: torch.Size([1, 9, 256])
hs, src = self.transformer(src, pos_src, tokens)
# hs: torch.Size([1, 9, 256]) -> 精炼后的 token
# src: torch.Size([1, 4096, 256]) -> 精炼后的图像特征(flatten)
# >>> 拿 1 号 token 去做 IoU 回归
iou_token_out = hs[:, s, :]
# iou_token_out: torch.Size([1, 256])
# >>> 拿 2~5 号 token 去做 4 个 mask 原型
# s: 1 self.num_mask_tokens: 4
mask_tokens_out = hs[:, s + 1 : (s + 1 + self.num_mask_tokens), :]
# mask_tokens_out: torch.Size([1, 4, 256])
# >>> 把 4096 个 token 再 reshape 回 64×64 空间特征图
# src:torch.Size([1, 4096, 256]) b:1 c:256 h:64 w:64
src = src.transpose(1, 2).view(b, c, h, w)
# src: torch.Size([1, 256, 64, 64])
# >>> 上采样到 256×256,同时融合高分辨率 skip 特征
# self.use_high_res_features:True
if not self.use_high_res_features:
upscaled_embedding = self.output_upscaling(src)
else:
dc1, ln1, act1, dc2, act2 = self.output_upscaling
# high_res_features:[
# torch.Size([1, 32, 256, 256]),
# torch.Size([1, 64, 128, 128])
# ]
feat_s0, feat_s1 = high_res_features
# feat_s0: torch.Size([1, 32, 256, 256])
# feat_s1: torch.Size([1, 64, 128, 128])
# >>> 第一层上采样 64→128,同时加 128 分辨率 skip
upscaled_embedding = act1(ln1(dc1(src) + feat_s1))
# upscaled_embedding: torch.Size([1, 64, 128, 128])
# >>> 第二层上采样 128→256,同时加 256 分辨率 skip
upscaled_embedding = act2(dc2(upscaled_embedding) + feat_s0)
# upscaled_embedding: torch.Size([1, 32, 256, 256])
# >>> 4 个 mask token 各自过一个小 MLP 得到 32 维"超向量"
hyper_in_list: List[torch.Tensor] = []
# self.num_mask_tokens: 4
for i in range(self.num_mask_tokens):
# 进入MLP.forward
# mask_tokens_out: torch.Size([1, 4, 256])
hyper_in_list.append(
self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :])
)
# i=0 加入 torch.Size([1, 32])
# i=1 加入 torch.Size([1, 32])
# i=2 加入 torch.Size([1, 32])
# i=3 加入 torch.Size([1, 32])
hyper_in = torch.stack(hyper_in_list, dim=1)
# hyper_in: torch.Size([1, 4, 32])
# >>> 用"超向量"与上采样特征做 1×1 卷积等价运算:矩阵乘 + reshape
# upscaled_embedding: torch.Size([1, 32, 256, 256])
b, c, h, w = upscaled_embedding.shape
# b:1 c:32 h:256 w:256
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# masks: torch.Size([1, 4, 256, 256])
# >>> IoU 头:拿 1 号 token 回归 4 个 mask 的质量分数
iou_pred = self.iou_prediction_head(iou_token_out)
# iou_pred: torch.Size([1, 4])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# >>> objectness 头:拿 0 号 token 判断"图中到底有没有物体"
if self.pred_obj_scores:
assert s == 1
# 进入MLP.forward
# hs: torch.Size([1, 9, 256])
object_score_logits = self.pred_obj_score_head(hs[:, 0, :])
# object_score_logits: tensor([[20.2533]], device='cuda:0')
else:
# Obj scores logits - default to 10.0, i.e. assuming the object is present, sigmoid(10)=1
object_score_logits = 10.0 * iou_pred.new_ones(iou_pred.shape[0], 1)
# mask: torch.Size([1, 4, 256, 256])
# iou_pred: tensor([[0.8732, 0.6970, 0.7946, 0.8747]], device='cuda:0')
# mask_tokens_out: torch.Size([1, 4, 256])
# object_score_logits: torch.Size([1, 1]) 即 tensor([[20.2533]], device='cuda:0')
return masks, iou_pred, mask_tokens_out, object_score_logits代码整体流程一句话总结
把"可学习的 object/iou/mask token"和用户稀疏提示拼成 9 个 token。
与图像特征一起过 2-way transformer,得到精炼后的 token 和图像特征。
用 transformer 输出的 mask-token 过 MLP 得到 4 个 32 维"超向量",再与上采样到 256×256 的特征图做矩阵乘,一次性生成 4 张 mask。
同时用 iou-token 回归 4 个 mask 的质量分数,用 obj-token 给出"图中是否有物体"的 logits。
把 4 张 mask、4 个 IoU、4 个 token、1 个 objectness 分数一起返回,供上层
forward再做筛选。
4.1.1 hs, src = self.transformer(src, pos_src, tokens)之前做了什么
把"提示"和"图像"都变成 Transformer 能吃的格式,然后让它们在注意力里互相"打听"消息,最终吐出更好的 token 和图像特征。
逐句翻译:
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)把「可学习的 6 个任务 token」和「用户给的稀疏提示(点 / 框)3 个向量」拼在一起,得到 9 条"查询向量"。
形状:
[B, 9, 256]。
src = image_embeddings / repeat_image / + dense_prompt_embeddings图像特征本身
[B, 256, 64, 64],再把用户画的"低分辨率 mask"逐像素加进去,让网络知道"我大概想分割哪一块"。
pos_src = ...给每个像素加上"位置编码",让 Transformer 知道自己在图的左上角还是右下角。
self.transformer(src, pos_src, tokens)这就是 SAM 的 2-way transformer:
token 作为 Query,去图像特征里找"我该关注哪几个像素";
图像特征也作为 Query,去 token 里找"我该听哪个指令"。
跑完一圈后:
hs:[B, 9, 256]→ 9 个 token 被图像信息精修过,后面分别拿去预测 objectness / IoU / 4 个 mask。
src:[B, 4096, 256]→ 64×64=4096 个像素向量也被提示信息精修过,后面拿去上采样生成高分辨率 mask。一句话总结
"把提示和图像都拉进同一个 Transformer,让它们互相问问题,出来就是'被提示精修过的 token'和'被 token 精修过的图像特征',再各自去做预测。"
objectness 打分 是什么
objectness 打分
= "这张图里到底有没有我想分割的物体" 的置信度。
具体说:
输出形式
一个标量 logit(代码里叫
object_score_logits),越大代表"肯定有物体"。经过
sigmoid后落在 0~1 之间,可直接当概率用。跟谁学
训练时,如果当前样本至少有一个有效正提示 (前景点击 / 正例框),label = 1;
如果所有提示都是"背景点击"或空提示,label = 0。
用简单的二分类交叉熵 loss 去监督。
怎么用
自动过滤垃圾预测 :推理阶段
sigmoid(objectness) < 0.5时,可以直接返回"未检测到物体",避免把整张图当 mask 甩给用户。跟踪场景:第一帧用户只点了一下,objectness 很低说明可能点到了背景,系统可以拒绝开始跟踪或提醒再点一次。
速度优化:objectness 极低时,后面 4 个 mask、IoU 都不用解码,直接省计算。
一句话
objectness 就是 SAM 的"门禁保安"------先快速判断"这里到底有没有东西值得分割",再决定要不要把 mask 拿出来。
4 个 mask 原型是什么?
在 SAM(Segment Anything Model)中,4 个 mask 原型 是模型用来生成分割掩码(mask)的初始模板或基础向量。它们是模型学习到的、用于表示不同分割可能性的特征向量。
详细解释
定义
mask 原型 :这些是模型在训练过程中学习到的、用于生成分割掩码的特征向量。每个原型向量是一个 256 维的向量,存储在
self.mask_tokens.weight中。形状 :
self.mask_tokens.weight的形状是[4, 256],表示有 4 个原型,每个原型是一个 256 维的向量。作用
生成分割掩码 :在推理阶段,这 4 个原型向量会被用来生成最终的分割掩码。具体来说,每个原型向量会通过一个超网络(hypernetwork) 转换为一个 32 维的"超向量",然后与上采样后的图像特征图进行矩阵乘法,生成一个分割掩码。
多样性:这 4 个原型向量提供了不同的分割可能性,使得模型可以生成多个候选掩码。这些候选掩码可以被进一步筛选,选择出最佳的一个或几个。
具体流程
超网络转换:每个原型向量通过一个 MLP(多层感知机)转换为一个 32 维的"超向量"。
矩阵乘法:这些"超向量"与上采样后的图像特征图进行矩阵乘法,生成分割掩码。
形状变化 :上采样后的图像特征图形状是
[1, 32, 256, 256],经过矩阵乘法后,生成的分割掩码形状是[1, 4, 256, 256],表示有 4 个候选掩码。总结
4 个 mask 原型 是 SAM 模型中用来生成分割掩码的基础向量。它们通过超网络转换为"超向量",并与上采样后的图像特征图结合,生成多个候选分割掩码。这些候选掩码可以被进一步筛选,选择出最佳的一个或几个,从而实现高质量的分割。
iou 打分是什么?
IoU 打分
= 模型对自己预测出来的 mask 与真实前景区域重叠程度的"自信分"。
具体一点:
数值含义
网络输出 4 个 mask,就会对应输出 4 个 IoU 分数,每个分数都在 0~1 之间:
1.0:模型认为这个 mask 跟真值 100% 重合(极端自信)。
0.2:模型觉得基本不准,只能覆盖 20% 左右。
怎么来的
在 Transformer 里专门留了一个"iou_token",它的 256-d 输出被送进一个小 MLP(
self.iou_prediction_head),直接回归出 4 个标量,无需真值即可在推理阶段给出。训练监督
用真值 mask 当场算一次"真实 IoU",再用 L2 或 Smooth-L1 损失去拟合,让网络学会"我预测得越好,自己的打分就越高"。
推理用途
多 mask 输出时,按 IoU 打分排序,把最高的那个给用户。
上层逻辑(如 dynamic_multimask_via_stability)用 IoU 打分当权重,做加权平均或筛选。
如果最高分仍很低,可直接报"未检测到可靠物体"。
一句话
IoU 打分就是网络给自己打的"成绩预测",告诉上层"我这几个 mask 哪个最靠谱"。
为什么无需真值呢?
"无需真值"指的是推理阶段 ------模型一旦训练完成,在实际使用(inference)时,它只靠自己的内部特征就能立即吐出 4 个 0~1 的分数,不需要把预测 mask 拿去跟真值 mask 算一遍 IoU。
训练阶段当然必须有真值:
先让网络把 mask 预测出来
用标准代码算一次"预测 mask ∩ 真值 mask / 预测 mask ∪ 真值 mask"得到真实 IoU
再把网络自己输出的 IoU 分数拉过来,用 L2/Smooth-L1 损失逼它逼近这个真实值
训练结束后,网络已经把" mask 长什么样就该对应多少 IoU"这一映射学到了。
推理时它只要看一眼自己的 mask-token 特征,就能直接给出估计值,所以对用户端来说"无需真值"。
# sparse_embeddings: torch.Size(1, 3, 256)
output_tokens = output_tokens.unsqueeze(0).expand(
sparse_prompt_embeddings.size(0), -1, -1
)
output_tokens: torch.Size(1, 6, 256)
这什么意思?
expand并不是"复制数据",而是返回一个"视图" ------把原来那 1×6×256 的张量**广播(broadcast)**到更大的形状,但底层内存里仍然只有一份参数。
output_tokens = output_tokens.unsqueeze(0) # [6,256] -> [1,6,256] output_tokens = output_tokens.expand( sparse_prompt_embeddings.size(0), -1, -1) # [1,6,256]
sparse_prompt_embeddings.size(0)就是 batch 大小,这里等于 1。第二个
-1表示"保持这一维原来的长度",也就是 6。第三个
-1表示 256。因此
expand的形状请求就是[1, 6, 256],而原张量已经是[1, 6, 256],完全匹配 ,于是expand什么也不做,直接返回原视图。你看到的大小还是[1, 6, 256]。如果以后 batch 大小变成 N(例如 N=4),同一行代码就会把那张量视图变成
[4, 6, 256],而实际内存里依旧只有一份self.obj_score_token.weight、self.iou_token.weight和self.mask_tokens.weight,从而达到"同一份可学习 token 被所有样本共享"的目的。
unsqueeze(0) 是干嘛的?你的意思unsqueeze(0)是把 6,256 -> 1,6,256,而expand是把 1,6,256变成B,6,256,并且内存其实只有一份而不是B份,而这里只是因为B刚好是1,所以才会1,6,256->1,6,256?
完全正确,一句话总结:
unsqueeze(0)给"可学习 token"加了一个 batch 维,变成[1, 6, 256];
expand(B, -1, -1)再把这一份数据广播视图 成[B, 6, 256],内存始终只有一份 。因为当前
B=1,所以看上去"没变",但代码已经准备好了任意 batch 大小。
src = torch.repeat_interleave(image_embeddings, tokens.shape0, dim=0) 什么意思?
torch.repeat_interleave不是"广播视图",而是真正复制数据。
src = torch.repeat_interleave( image_embeddings, # [1, 256, 64, 64] tokens.shape[0], # B(当前=1) dim=0)含义:
把
image_embeddings在第 0 维(batch 维)逐份重复tokens.shape[0]次,然后拼成一个新的张量。
当
B=1时,重复 1 次 → 形状仍是[1, 256, 64, 64],看起来没变化,但已经是一份新的内存(不再是原张量的视图)。若
B=4,就会把原来 1 份[1, 256, 64, 64]变成[4, 256, 64, 64],且 4 份数据在内存里连续存放,每一份完全相同。目的:
后面 transformer 的
src需要与tokens的 batch 大小一致;而
image_embeddings通常只做了 1 次前向提取,因此在这里按需物理复制成 B 份,保证每个样本都能独立参与交叉注意力。
image_pe: torch.Size(1, 256, 64, 64)
pos_src = torch.repeat_interleave(image_pe, tokens.shape0, dim=0)
pos_src: torch.Size(1, 256, 64, 64)
什么意思?
和刚才那行
src = torch.repeat_interleave(...)完全同理,只是这次操作的对象是位置编码image_pe。
image_pe的形状是[1, 256, 64, 64]------1 份 64×64 网格的 256 维正弦位置编码。
tokens.shape[0]是当前 batch 大小(这里 =1)。
torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)把这份位置编码在第 0 维重复tokens.shape[0]次。
因为
B=1,重复 1 次后形状仍是[1, 256, 64, 64],看上去"没变",但内存里已经是一份新的、与tokensbatch 大小严格对齐的张量。如果
B=4,就会得到[4, 256, 64, 64],4 份完全相同的 64×64 位置编码,供 transformer 里每个样本使用。目的:
transformer 的
pos_src必须与src拥有同样的 batch 维,于是把单份位置编码也复制成 B 份,保证后续逐样本做 attention 时维度一致。
大概是这样